Wget does not validate certificates by default because there's no CA bundle provided with wget. It does check for /etc/ssl/cert.pem, but it doesn't provide one. So you have to provide one or set up /etc/ssl/certs/ as OpenSSL libraries expect.
Curl does provide a CA bundle (/usr/share/curl/ca-bundle.crt) and by default libcurl validates certs against it.
cURL doesn't provide a CA bundle any more [1], it's the job of your OS to provide this. As I understand it, all tools that provide SSL support will fail safe if there are no root CAs on your system.
[1] http://curl.haxx.se/docs/sslcerts.html
But the point halfasleep is making is important: Don't assume either wget or curl will validate your SSL connection because it may not have been set up by your OS/distribution.
I dislike this whole trend. How about we start thinking in terms of leaving the user's default environment, and system, alone, and “installing” software into nice sandboxed areas where we can easily enable/disable it, or delete it with a simple “rm -rf directory/path”
I put all my sensitive files under my home directory. Every subdirectory of my home directory is non-world-accessible, and I have a cron job which chmod's world privileges away from new files and directories that don't match a whitelist of directories I wish to publish (e.g. ~/public_html).
I've started giving each application its own user and group, and do the git checkout, compile, and install as that user. (You don't need root for "make install" if you ran configure with the --prefix option.) Then I know it's not going to be able to write anywhere but its own directories, and won't be able to see my browsing activities or sensitive files, because UNIX permissions won't let it. For added security, once the software is built, move it to a location where only root can write, and chown -R root:root.
You can also use VM's for added security. With the new namespaces in 3.8 (the kernel for Ubuntu Raring Ringtail), it should (in theory) be safe to let untrusted software have root in a Linux container (LXC). (LXC is like chroot but you can virtualize stuff like the network, and since the guest uses the host's kernel memory allocator, you don't have to dedicate a block of memory to running the guest as you would with Xen or Virtualbox.)
It seems like you've been putting a lot of effort in, but posix uid/gid isolation is increasingly pourous with the typical desktop environment these days. It sounds like you are ready for real RBAC - if you put the time in selinux (or apparmor or grsec) is leaps and bounds more effective.
uid/gid is generally a sound system, the problem IMO is basically that no one uses it for serious security, so a lot of things are not set up to be properly careful by default.
To be fair to Homebrew (the example I'm picking on here), it does install to a nice sandboxed area. That area is named "/usr/local", but you can give it its own path and everything works pretty well. (I find I have to completely remove and reinstall Homebrew about every two months, generally because libgettext changed yet again.)
Homebrew is ok, and it has arguably improved the situation on Mac OS X a great deal, but I think we can do better still.
Using homebrew, one tweaks recipes in ruby code until they work.
Why do we not have a common (and widely adopted!) way for software projects to tell other software how to install/uninstall them, and what other projects they depend on for what particular operations (e.g. configure, build, install, test etc), with reusable data rather than code.
Why is (some of) this information captured in bits of ruby, useful for a particular OS X package management system, but not when you want to deploy a similar stack to a IaaS provider where you'll use a different incompatible system like Puppet or Chef to set up the same stuff.
I think we have made this whole situation more complicated and fractured than it needs to be.
Code is reusable data, and regardless of language is much more useful than an arbitrary data format. There was an attempt to port homebrew to linux, but it didn't go far.
dotCloud has just open-sourced Docker[1], an attempt at solving the deployment issue.
> There was an attempt to port homebrew to linux, but it didn't go far.
Linux already has more package managers than you can shake a stick at. To gain traction on linux, homebrew would have to offer useful features that other package managers don't have. Even then, people are more likely to copy the features into an existing linux package manager.
I don't think people tend to shop around when it comes to package managers; you use whatever your distro provides. If it sucks, you find a better distro or submit patches, depending how involved you are.
I don't know why anyone would want Homebrew on Linux anyway. The whole point of it is that OS X is a mostly-serviceable UNIX without a decent package manager. So if you have a handful of UNIX packages you just want a lightweight way to install them using the system headers where applicable.
But if you need to install tons of stuff the cracks start to show, because you have no conflict resolution or sophisticated versioning. Linux leans heavily on its package managers, so I just don't see what Homebrew has to offer.
Homebrew formulas are much more frequently up-to-date than other package managers due to the crowd-sourced pull-request updates - there isn't a package mantainer that has to do all the work. Formulas are straight-forward and don't have a million conditionals for different system configurations (this would be hard to maintain on linux). These two things already make it much more pleasant to use than apt-get/yum/pacman.
Yes, I am familiar with homebrew and use it every day including submitting pull requests back. However you missed the point of my comment. The point is, it's more pleasant until you run into a conflict which existing Linux version managers tend to handle much better (out of experience and necessity). At that threshold of complexity you need something more sophisticated than homebrew to avoid pulling your hair out. OS X benefits from a certain homogeneity that puts homebrew in a sweet spot.
I don't know about "widely adopted", but we do have a common language for expressing how to build/install/test software across Linux, Unix, Windows and OS X:
The tools to read this are in most Linux distribution repositories already (usually under the name "zeroinstall-injector"), and do dependency resolution, conflict resolution (via a SAT solver), GPG signature checking, etc. And each package unpacks to its own directory, so they don't interfere with system packages.
That's not a sandbox. If you have ten programs installed in /usr/local, and you want to uninstall one of them, rm -Rf /usr/local is not the tool for the job. (At least on Linux. I'm assuming UNIX-like Macs are the same.)
Like I said, Homebrew installs in its own directory pretty well. I chose /usr/homebrew, explicitly so I can rm -rf. I think for most Homebrew users their Macs have nothing else in /usr/local and so that's why it's not an unreasonable default.
Homebrew actually uses /usr/local/Cellar, so rm -Rf /usr/local/Cellar/pypy is what you'd want, except that it won't remove symlinks to /usr/bin, launch scripts and such; you still need some kind of uninstall script (brew uninstall).
You can't just enable/disable software if it depends on other software or vice versa. But your package manager may have facilities for that, like Nix [ http://nixos.org/ ].
That's just bad administration as even on Windows, you can easily disable them (msconfig). With Linux, this isn't even an issue unless you're blindly installing dozens of daemons (which, again, can easily be disabled) as Linux doesn't have hundreds of application launchers that install themselves like Windows does (again, daemons being the exception).
The only example I can think of where you might run into problems is if your desktop environment is doing some weird sessions. But that's usually fixed pretty easily in the system settings for whatever desktop environment you're running.
This is all pretty basic stuff; you shouldn't need a sandboxed environment to prevent applications from auto-launching unless you're going around installing malware (and if you are deliberately installing malware on your main bare-metal OS, then you're insane).
That's a problem systemd is trying very hard to solve.
/sarcasm
SysV init may be old, crufty, and inelegant, but it's reasonably straightforward to parse and troubleshoot manually (and BSD-style rc inits are even more straightforward). Making the bootstrap process nondeterministic strikes me as tremendously unwise.
> I will probably be proved wrong as systemd matures, but right now it's just not the case.
Yeah . . . I doubt it. I made the switch to FreeBSD as my primary OS of choice back in 2005 or 2006 without being 100% certain why I decided to try to live on BSD Unix pretty much full-time right then (there were reasons, but I think the timing of the migration was largely whim). I never even missed the Linux world for the next half decade or so. I then tried living with Debian again for a while (long story why), and I discovered that everything of substance that had gone on in the Linux world since then seemed almost tailor-made to annoy the shit out of me. It was a real shock that destroyed the fondness I still harbored for Debian.
I poked around at some other Linux distributions I hadn't tried, or handn't used in years, and discovered they were even worse -- and systemd is sorta the apotheosis (no relation) of exactly the sort of nondeterministic, "the software knows better than the user" BS that I remembered with severe loathing from my distant past primarily using (and fixing, for a living) MS Windows. Between Red Hat developers like Drepper and Poettering, the agenda of Canonical and Ubuntu, and the GNU project's strange synthesis of superficially opposed concepts like stagnation and invidious undermining of anything related to the (so-called) Unix philosophy of system design, I ultimately came to the conclusion that outside of a professional capacity (that is, writing code and/or managing servers, and that only if I'm paid) I'm simply not interested in screwing around with Linux-based systems any longer.
Your tolerance may be higher than mine but, given your comment about what you dislike about systemd, I rather suspect you'll only grow more frustrated with the direction of Linux development community efforts over time. You might want to think about diversifying your OS experience in the near future (if you haven't already) so you have a place to ready and waiting for you to go when the Linux world has finally pushed you to the point of just wanting to escape.
Yeah . . . it looks like Arch has gotten to the point where it just kinda violates all the points of the so-called Arch Way wholesale, even worse than the mainstream (supposedly) Unix-like OSes tend to violate the so-called Unix Philosophy these days.
I wasn't particularly aware of systemd's emergence and the squabbling that went on at the time, but I got exposed to it a gen or 2 after it first hit fedora through a fedora centric project. At first I was non-plussed and sort of annoyed that I didn't know how things worked, and primarily relied on the compatibility bridge with service that worked well enough.
At one stage I ended up having to do some tweaking with rc init scripts would have required a fair amount of haks (in the pejorative sense) and since these wouldn't work in systemd i decided it was the time to get to know it.
It only took me a couple of hours to get a good overall sense of the system and mindset, and the minor things I needed to get accomplished ended up being much cleaner in systemd once I "got it".
Once I had a good new mental model of it, I found that I liked working with systemd much more than the old guard. Ignoring the technical and performant advantages, I find the framework for discovering and resolving problems to be much more effective and easy to deal with once you got over the hump of the confusing bits of information overload and changed grammars.
I've never been a huge fan of Lennart Poettering in the way that he seems to optimize for friction in certain communities, but I think systemd is a real step forward and we need people like him to drag up forward kicking and screaming at times.
I user a lot of different posix systems day to say, and it's gotten to the point that I now groan when i have to deal with one still using a traditional init approach.
I'm not saying systemd is without issues, but if you give it some time with an open mind I think you may find out it has a lot going for it (and not just the marketing bullet points - thats part of lennart's problem)
This may have been true 5-10 years ago, but modern desktops are removing the ability to manage services, sessions, and startup apps easily and clearly.
To be fair, some of this is driven by real needs. People want fast boots, so you have to work tightly in parallel. That requires a clear and complex dependency graph. That requires significantly more than some symlinks in /etc/rc?.d/.
Also as distros aim to pare down their default installs, you end up in a situation where there is very little that you actually can disable without breaking your ability to boot.
Furthermore, given typical CPU/RAM overheads on modern hardware, disabling something that takes a fraction of a second to start and consumes almost no RAM can seem slightly pointless!
I'm not familiar with systemd, but upstart takes a similar approach to sysvinit - don't want something to start? Just move it out of /etc/init/ like you would have rm'd the symlink in /etc/rc?.d/ :)
I'm referring more to the GUI sessions, startup apps, etc. It seems when I first started using Linux, most of the DEs made it very clear how to edit menu entries, where startup apps were located, what data and apps were restored when a session was restarted... At least in the Ubuntu variants, those options are less obvious.
Unless they're blocking access to [insert your favourite terminal emulator] and deinstalling su, rm and unlink, then they are not removing any such ability.
You are trusting some third-party everytime you download a proprietary or just big open-source app. Even on Open Source, you just have trust in the public review.
In that example you can read the source before, the chances of an evil change just when loading it with your terminal is quite limited, MITM doesn't work that well on SSL, too.
So you're trusting opscode to provide the primary centralized control system of your entire server ecosystem but you're concerned they might be embedding something malicious in their installer shell script?
Don't get me wrong, i'm no fan of the practice especially sans tls, but this seems like a poor example.
just like they could replace a binary, backdoor the Makefile or hide something bad deep in the repo. And of course their hash of their signing key for their apt repo and any shasums are provided on the same webserver.
Of course that is always a risk, but with most FOSS software being maintained in public revision control systems, it's difficult to truly hide something.
Even if you discard the security angle of wget | bash (which you would be a foolish choice) there is the simple problem of repeatability.
If you are deploying 50 new servers and OpsCode releases a new version of Chef after 25 of the servers have performed the wget, the next 25 will get a different client that might be incompatible with the server.
For what it's worth, that curl install is a "beachhead" install. When you provision servers you load chef on them using knife bootsrap, which carefully ensures it installs the revision of chef on the server that you're using on the management workstation. You have to go out of your way to get a brand new release installed on a node if you haven't installed it on your workstation.
Know better... in order to do what? They also provide an APT repository, which you can choose to use instead of the curl command. The curl command exists solely for convenience, because it autodetects your OS, distro version, and automatically registers the right APT repository for you if you're on Debian.
As I've mentioned here (https://news.ycombinator.com/item?id=5508680), people often freak out at curl commands, yet at the same time I've yet to see a viable proposal for an alternative.
Well, the downloaded bash script does all that, and a user is always free to leave the last piping-into-bash command off. They can review it first, and then run as sudo (or whoever) if it passes muster.
It's not that much different, so I don't understand the huge problem. Most likely if tutorial writers added a second step, the user would just copypasta the second step also.
Thankfully I followed this procedure after a co-worker sent me this: `curl -L http://bit.ly/10hA8iC | bash` ... was able to turn my speakers down first ;)
As I've mentioned in https://news.ycombinator.com/item?id=5508680, for any alternative to be viable it must "work on all major platforms". APT is only used in Debian derivatives. How do you want to handle OS X users?
It would be lovely if there was a One True Software Distribution Format, but it's not going to happen. wgetting into a bash script is a terrible way to not really support any users properly :)
Neither is it going to happen that every developer spends considerable resources on creating packages for every platform. Just look at the popularity of curl installs, or even at the number of developers who don't bother to provide binaries and stick to source tarballs.
For me, the method of installation is one of the less important reasons why I started using rbenv instead of rvm. rbenv's simplicity and speed appealed to me, and the trigger for switching was rvm destroying itself again (or otherwise rendering itself unusable) after updating it.
Are you going to type that string into your terminal manually, or are you just copy/pasting that line from a web page, still leaving yourself open to this issue?
I find it hard to believe anyone will be reading that line on a web page, then typing it out correctly in their own terminal instead of just saying, "ok that line looks fine copypaste"
There are legit criticisms against the copy-paste-curl-command style of installations. But on the other hand, I've yet to see a critic proposing a viable alternative. With viable I mean that said proposal must:
1. Work on all major platforms.
2. Be easy for the developer to create.
3. Be easy for the user to execute, with as few steps as possible.
There are those who advocate that the developer should create a platform-specific package for every platform. While this fits their purist views in which only their own platform matters, this is not a good solution for the developer, who often has users from multiple platforms. Creating platform-specific packages places an unbelievable maintenance burden on the developer.
This is not to mention that platform-specific packages, too, have their own security flaws.
The most viable alternative is "apt-get" which provides simple downloads from a central package repository with signature checking. I believe pip and cpan are comparable. In this case I'm picking on homebrew, and the quoted curl command is the command to install that very package tool. The brew package manager does some lightweight checksum verification on subsequent downloads.
I look forward to you boiling the ocean. (Sadly, the only reason I know about this Homebrew stuff at all is that the APT-based Fink, for MacOS, is not very popular.)
The only difference between "wget | sh" and "download and run our installer" is that you could inspect the installer before running it. You can still do that, "wget | sh" just simplifies the process for most users.
You can also inspect the wgetted/curl'ed script if you so choose. It's just a URL. I don't understand your point.
Even with the "exploit" in the article, it will be detected as soon as the user pastes the URL in his browser location bar. People who don't inspect what they run are screwed no matter what.
The point, especially in a non-SSL environment, is not that you're not trusting Opscode or Homebrew. It's that a malicious attacker has a vector, because he knows people will be doing something with that URL.
If I own Opscode and I'm smart, I plant something like this on that URL:
if request.user_agent.startswith("Curl or wget or..."):
return deliver_malicious_script(request)
return deliver_everything_is_fine_script(request)
Nearly everybody's workflow for "checking" this is putting the URL in your bar, looking at it, then jumping over to terminal and running it. (Sounds suspiciously like what you just described.) I just owned that with three lines of effort.
We can do this dance all day where people point out specifics, or we can all just recognize it's a bad idea (a lot of people are saying it's a bad idea; might be worth considering it's a bad idea).
I like very much the "copy-paste-curl-command style of installations" because it is as simple as possible, and it invites to be more creative during installation. I do not envisage to perform a copy-paste-curl-command installation, except perhaps in a not throw away VM. I generally perform the curl toward a temporary file, read the file and if it does look suspicious, I do not run it.
Bash and Zsh provide shortcuts to open a text editor where commands can be pasted and edited before running (Ctrl-x Ctrl-e in bash, need to enable in zsh [2]). I've been using this on Linux not for security but because I'm still confused by X11's primary and clipboard selections [1]. It seems like every time I try to paste a github repo link, I get the last chunk of code I copied and vice versa.
Out of interest, what is confusing? If you select text it always goes into the selection buffer. If you also press the clipboard copy shortcut (so, Ctrl-C most of the time, sometimes Ctrl-Shift-C in a terminal) the selection is copied into the clipboard buffer.
Ctrl-V (or, again, sometimes Ctrl-Shift-V in a terminal) pastes the clipboard buffer. Middle mouse button (or shift-Insert) pastes the selection buffer.
I think "confusing" in this context doesn't mean that the concepts are hard to enumerate or understand, it means they're hard to apply with low error rate in a practical setting.
I don't have a problem with X selection+paste if I'm just using Linux. But using it when connected to a remote machine via various remoting technologies (NX, Chrome Remote Desktop), and then mix in that the host machine is a Mac with its terrible command/control split, and the result is pretty confusing.
I use rxvt and never figured out how to paste the clipboard buffer, so I use shift-insert to paste the primary buffer. Unfortunately, the primary buffer can be overwritten without my consent, e.g. an autofocused web input field.
Vim and emacs also have their own shortcuts for accessing the clipboard buffer.
Thanks for the link. I'll find a place for uxvrt-perls in my hacky copy-paste workflow. I'm currently using tmux paste buffers and shell functions around xclip to move around text.
> If you select text it always goes into the selection buffer.
But as far as I can tell, if text is selected for you that's not always true. I sometimes have difficulty with text boxes which insist on self-selecting as soon as I click them, and which I just can't seem to pull into the selection buffer.
Github doesn't seem to have this issue, but I had recently when trying to get a google maps permalink, for example.
Yeah, copying GitHub URLs sucks. You cannot actually select it with your mouse, since some creepy JavaScript interferes and selects it for you. the result is that it's selected, but not copied to PRIMARY, as you'd expect. I fall into this trap every single time.
Ctrl-x e in zsh is '_expand_word'. The function you are talking about is 'edit-command-line', which is not loaded or bound to any key by default in zsh. You have to load it manually.
Every once in a while I think I have my shell environment set up exactly the way I want it. Then I find out about something like this - thanks for the tip.
<p class="codeblock">
<!-- Oh noes, you found it! -->
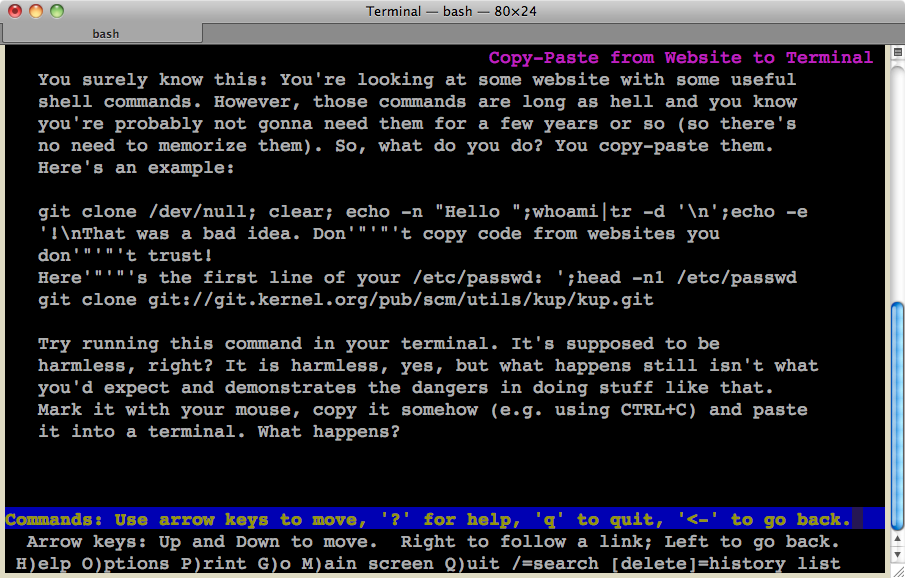
git clone
<span style="position: absolute; left: -100px; top: -100px">/dev/null; clear; echo -n "Hello ";whoami|tr -d '\n';echo -e '!\nThat was a bad idea. Don'"'"'t copy code from websites you don'"'"'t trust!<br>Here'"'"'s the first line of your /etc/passwd: ';head -n1 /etc/passwd<br>git clone </span>
git://git.kernel.org/pub/scm/utils/kup/kup.git
</p>
I was expecting it to be done with Javascript, which is, afaik, how the horrible websites that tack a URL and a "this quote came from blah" attribution, work.
I hate all of this stuff and it is greatly saddening that browser vendors are not protecting us from it. It's like the pop-up-on-click days of old and it must stop.
If I select some text and copy it, I am taking a very explicit action. I am giving the computer a very explicit instruction. There is no room for interpretation. It must not disobey me!
Yes, I got the idea from all the sites that do it using Javascript, but I wanted to post the example to ##security, and half of the people there probably has the browser set to "block JS by default" :D
Definitely, I didn't even know that command :D - but I had to `apt-get install sl` on my machine first. Maybe just do a telnet to a nonstandard port on my server and then send special characters to do the animation? That could work...
I always install sl because it helps me. If I'm frustrated from typing too quickly/angrily to even get "ls" right, the little train breaks me out of my fugue state and I have to laugh and shout "choo choo!" in the office :D
>If I select some text and copy it, I am taking a very explicit action. I am giving the computer a very explicit instruction. There is no room for interpretation. It must not disobey me!
From the point of view of the browser, it very explicitly does what you told it to, without interpretation, obediently. The problem is that yours and the browser's opinions differ on what you intended to do.
Then it needs to adjust its worldview to match mine. It showed me some text, I selected the text it showed me. If its simple layout engine thinks I saw some text that was rendered hundreds of pixels outside the viewable area, that is its bug, not mine.
It's infeasible for the browser to know "what you see" in the general case. What if the text was in position, but very small and almost the same color as the background? Does the browser need to know if you're red-green colour blind? If you're farsighted?
That's a pretty narrow view. Sometimes I want a site to capture selections or right-click (think: WYSIWYG editor widget). Your beef is with the site owners who put that obnoxious stuff on their site, not with the browser that displays it. There is no limit to the number of ways a site owner can do dumb and annoying things to their readers.
Since site owners are often not trustworthy on petty issues like this, it would be nice if browsers would make an effort to protect from the more obvious forms of malice rather than telling the user that it's their fault if anything happens
> capture selections or right-click (think: WYSIWYG editor widget)
Why, no, not the same.
I think it is ok for a webapp to be aware that I selected some text, and which text, so a further click on "boldface" would have a context.
But it is not ok for a webapp to interfere with the text selection itself.
For instance, well-intentionned chrome always add "http:// when I select the url. It gets in my way very often and it is not what I intended: I did select google.com with my mouse very carefully, I do not want Chrome to be clever and add "http://. By the way, this issues comes from the excessively minimal UI: Chrome should not hide "http:// in the url bar, point-barre.
I do not use Evernote because it messes with my selections.
I have to use Trello at work but this bully don't even let me select a card title.
"I have to use Trello at work but this bully don't even let me select a card title."
It does if the card is open, are you referring to it assuming you're trying to drag a card on the board view? I'd rather have that than sometimes it drags, sometimes it selects the text.
No my beef is with my web browsers for allowing obnoxious things to happen. They take stands on things like blocking popups, why not clipboard interference and context menu blocking?
At least in Firefox you can prevent sites from blocking the context menu. Preferences -> Content -> [Enable JavaScript] Advanced... -> Disable or replace context menus
If you're using Firefox, you can prevent this kind of behaviour by going into about:config, and setting the dom.event.clipboardevents.enabled flag to false.
Would that look at the screen layout to remove a span that is positioned too far to the left? Or just disable JS control over copy-paste, which doesn't solve this problem?
FYI, most of that bullshit "Read More: <URL>" injection garbage can be blocked by adding "tynt.com" to your favorite adblock extension. I believe it's already in ghostery, just not enabled by default.
If ever there were a company that just needed to be nuked from orbit, it's tynt.
There is a way to fix it: don't select text in document order, but only in visual order. Apple does something like this in their PDF reader. This would probably break things people do today, and there would be whining.
I suspect that the only way to effectively mitigate this is in the terminal application, by displaying a confirmation with the pasted text before accepting any multi-line[1] paste. For example here: https://code.google.com/p/iterm2/issues/detail?id=594
[1] There may be other dangerous characters besides newlines, e.g. escape sequences. I'm not sure if it's possible to make an exhaustive list for something like Bash. Perhaps one has to guard against any paste?
It's still possible to circumvent this by creating a one-liner using semicolons. Just grab a code like [2] and append `; rm -rf` to the selection. If the original selection was a one-liner, it'll still be.
I've just realized that you meant the fact that multiline pastes are often immediately executed, right?
I've tried various ways of input to my console (MINGW/WinXP) for multiline pastes, and the results are as follows:
1. Right-click multiline paste: unsafe (executes immediately)
2. Windows paste (alt-space, e, p): unsafe (executes immediately)
3. Insert or Shift-Insert: safe (pastes only the first line)
Perhaps the real problem here is that, as noted by Ted Nelson back when the concept started to gain popularity, "[the computer clipboard is] just like a regular clipboard, except (a) you can't see it, (b) it holds only one object, (c) whatever you put there destroys the previous contents." The presented vulnerability hinges on (a), and, Glipper [1] notwithstanding, (a)-(c) is still the default behavior in every GUI I use.
Because of b and c, I would go nuts trying to use a text editor that didn't support an emacs-like "clipboard"[1] ring. I'm constantly dumping stuff in and pulling it out in arbitrary order. It is nice to have a solution to a in the process, too.
Well... yeah, but even without hidden text, what are you going to do after you clone the repository? Probably `make` or `ruby something.rb` or any number of other commands that can run arbitrary code. If you don't trust someone, you shouldn't be trying to clone their git repo in the first place.
It's not so much about cloning a repo than spilling this trick on blogs that explain how to run alsamixer to get skype recording running or install a package that is needed to debug a random joe's scrolling mouse problem. For things that requires a sudo for instance. Or a malicious `rm $HOME -rf`.
i think gizmo686 is aware of that. what he says is that he trusted the source where he c&p's from.
if you don't trurst the source you should not blindly copy any command. Even one flag/parameter that you might not know can do harm. There do not have to be hidden characters to make it harmful and dangerous.
But do you trust the website, email, or other source, where you copied the command? If someone can spoof this link on the official kernel website, they may as well have access to other, way more sensitive resources.
One of many examples by which making the web a better "application-delivery" platform makes it less secure, less reliable, less predictable and more tedious in its original role of sharing text, images and links.
My big point is that this is one of the many ways that the ambitious goals of the browser makers and authors of web standards screw up the workflows of those trying to use the web for reading and "allied activites" like navigating, scrolling and cutting and pasting.
These ambitious goals include assisting app developers and assisting design professionals (design professionals on the internet intersecting very strongly with "professional persuaders" on the internet).
Note that I am not saying that these ambitious goals are worthless or nefarious, just that maintaining a smooth and reliable way to share static documents over the internet is important, too.
The reason that the web is popular is because it supports these features for design-delivery and application delivery.
You could probably implement an online text reading system with basic markup and hyperlinks over a weekend, but the problem would be that nobody would use it because it would be seen as strictly inferior to the web.
I hope you are not setting up a false dichotomy in your mind between the web as it is now and an online text-reading system with no design touches.
I would want this "text-reading system" for example to have something like CSS. The difference would be that instead of creating ever-more powerful versions of CSS and Javascript, the architects and implementors of the text-reading system would pay attention to gotchas like the gotcha described in the OP (changing browsers so that what is copied into the clipboard is exactly the visible text the user has highlighted).
Thing is that the ever more complicated web is a response to demand, from developers and from users.
If at some point we had said "the web is powerful enough now, let's stop" then inevitably somebody like Microsoft or Google would have developed some other system that incorporated everything that the web does + extra stuff. In fact that's basically what stuff like Flash/ActiveX was in the late 90s.
Then gradually people would have switched to this new thing and the web would have gone the way of gopher and usenet.
Of course, if we could have redesigned the web from scratch right now with all the benefit of hindsight we could have (in theory) designed a better system. But as with most open things they rely on evolution rather than intelligent design.
Maybe I am wrong, but I have been assuming that if the maintainers of the browsers cared only about readers and writers (and not about application users and application developers, or potential customers and marketers) they would change the browsers so that what is copied into the clipboard is exactly the text that has been highlighted and is visible on the page and nothing more. Even if browsers worked that way, they can have text positioning.
If browsers were pure document viewers, I think it's much more likely that they would simply have only a maintainer or two, and most developers currently maintaining browsers would be doing more valuable and interesting work, like developing application platforms.
And that couple of maintainers would probably still have more important things to fix than what's essentially a curious but not really problematic bug.
And another good reason to not work in root shells routinely. As damaging as something like this might still be, it will be confined to just one account if you are not running as root.
Sadly this is not complete protection. Many Linux distributions configure sudo to prompt for the password only once every 15 minutes or so. If you have successfully executed sudo in your terminal within the last 15 minutes, any malicious code that you run can silently escalate its privileges to root just by starting with "sudo -i;".
You need to have the following in /etc/sudoers in order to be truly protected by not being logged-in as root:
No, he did not: typing rm -rf / into a root shell will delete the OS and your home directory.
It is a little more complicated than that, but the complications do not really affect very much. Last time I installed Debian around 2005 the documentation encouraged me to give /home its own partition, in which case rm -rf / will not get it. But on OS X the default is to put everything in one big partition and I kind get the feeling that Linux has moved that way, too. And even if /home is on its own partition, there are many ways for the malefactor to get /home, e.g., rm -rf /home.
Yes, you both did. To a user losing / is just as bad as losing ~, because ~ is all she cares about, not her OS settings, hence why I think the idea that running as root is worse than running as an unprivileged user is silly in this context.
They are effectively the same: an unknown script executing "rm -rf ~" with an unprivileged user is going to cause as much grief as root running "rm -rf /".
I couldn't care less that the system is still up if all my data is gone.
Not to mention that it's sysadminny-types that you turn to when your OS is hosed and you want to recover data from your drive - having little or no sysadmin skills means recovery and reinstall is very much not trivial.
Even if you're not root, if you're having trouble setting something up (which is why you're copying things off the web in the first place), you likely have a fresh sudo timestamp, so the attacker could become root anyway.
Well, if I had really wanted to build a serious attack instead of a harmless PoC, I'd have downloaded a second stage via `curl <url> | sh`, and that script would, for example, set aliases in your shell for `su` and `sudo` that call the real commands but log your password in the background. Unless you're using requiretty, of course, but I don't assume that you're using a real tty.
>One of many examples by which making the web a better "application-delivery" platform makes it less secure, less reliable, less predictable and more tedious in its original role of sharing text, images and links.
Or, in other words, "examples by which making the web do something useful, makes it less reliable and predictable that just letting it stagnate at the original goal it has in 1991 that people don't really care about".
I'm confused why this is even allowed by the browsers, you shouldn't be able to send something else to the clipboard. Are there any browser extensions that can 'fix' this issue?
Problem is , as far as the browser knows you meant to copy the whole thing.
If you look at the source the actual text of that paragraph is what gets copied, they just use some sneaky CSS to make it not visible. It's not explicitly marked as hidden.
Yeah -- I mean, it would be easy enough for browsers to not include text marked as display:none or visibility:hidden.
But there are so many other tricks to hiding text -- margin-left:-10000px, font-size:0, color:white, and so on, that there's really no way to avoid this.
So I can't even imagine how a browser extention would 'fix' this -- no matter how clever it tried to be, there would almost always be some way around it.
AFAIK Google fails to penalize you if there is any difference between your background and foreground colors, even if it's 1 unit (e.g. bg #000000 fg #010101). There's always a way around these things :)
So, I know that was a joke, but now I'm trying to figure out why it's a bad idea.
The browser can generate some kind of map for which region of the screen is what font. If you don't have to guess the font, OCR should be easy and reliable. That takes care of the hidden text issue. But second, it means one would be able to copy/paste text that is in an image (because some web designers hate you).
The best option I can think of, which is not ideal, is to flash a message of the total copied text. This of course won't be very useful if you're copying a large amount of text but this sort of attack seems to require appending to the beginning of the text which should be easy enough to catch.
In this particular case, the characters that get copied are clearly rendered far outside of the area selected by the mouse (in fact, outside the visible area), so I don't see a reason why the browser should think I meant to copy them.
Yes, it's probably not easy to fix, and once fixed there are probably a dozen different ways of cheating. I'm just pointing out that it's certainly possible to fix this particular attack vector.
I often copy things away from my mouse. Consider hitting control-a, or grabbing a region with the mouse and then expanding it with some keyboard navigation. It's very much a non-trivial problem.
The browser knows that the text is not visible, because it is the browser which is not displaying it. Yet the browser is choosing to include it in the copy. Why?
It is displaying it, just in a place your eye doesn't happen to see it due to a load of wonky CSS rules.
You could probably modify your browser to defeat this trick, but doing so you would run the risk of breaking existing sites and making CSS even more complicated than it already is.
And malicious code writers would simply switch up their code to a new trick.
It is rendering it, but not displaying it. The browser knows how wide the view port is, and knows that some of the text sits outside the viewport, so it does not display it. The same check could easily be performed upon OS copy event; it just isn't because the browser authors did not think they needed to.
There is a good use case for this. For example, if you copy a link from Twitter, you instead get the shortened URL so you're protected from malware when you click through:
No, they're actually using this trick to do the exact opposite.
If you right click and say 'copy link' you'll get the t.co URL, but if you select the partially rendered URL and ^C you get the full (non-shortened) URL in your clipboard.
I wonder if you could do the same with Unicode control characters. There's probably something in the depths of the library that would have a similar outcome.
git clone
/dev/null; clear; echo -n "Hello ";whoami|tr -d '\n';echo -e '!\nThat was a bad idea. Don'"'"'t copy code from websites you don'"'"'t trust!
Here'"'"'s the first line of your /etc/passwd: ';head -n1 /etc/passwd
git clone git://git.kernel.org/pub/scm/utils/kup/kup.git
I usually put a # before anything I paste into a terminal. Mostly because I sometimes get a newline at the end, but it will disarm this behavior too. I'm not sure if it works in all situations though. Edit: Won't work! Use a heredoc (<<paste) or the editor method suggested above instead.
It won't work in this situation. Multiple commands here are separated by newlines (like pressing enter on your keyboard) and putting # will only comment out the first one.
Yep, you're right. This one had a " char on the second line that made me confused. A heredoc will still work though, I should start doing that instead :)
Actually, since I tried to copy it by triple clicking, which selects one line (at least, I expect it to. It's what sublime text does). That didn't copy any of the malicious text, and it just stopped between the clone and the url.
I feared someone would do that. :D Well, it'd be easy to work around this if you have JS enabled... without it, it would probably not be so easy to trick you into copying multiple lines.
Definitely the browsers fault here for the unexpected behaviour and one that could easily trip up those that are not aware of this sort issue (probably those copying and pasting from random sites).
What constitues as visible though? There is the obvious non-visible CSS modifiers like display: hidden; - but at what point does an off screen rendered text actually count as hidden? If you were wanting to copy the entire contents of a page, and the browser assumed anything off screen was invisible then you would not be able to copy everything at once when it goes below the fold. Different screen resolutions and devices would cause other issues there as well.
The text isn't just not visible right now. It can't become visible. It lives above and to the left of the start of the page. Surely the browser's aware of that.
Wow, crazy, never really thought about this as an attack vector but it seems pretty obvious. I must confess that as a person who solves many problems by Googling I have directly pasted terminal commands from unknown websites countless times...
This is what I do with anything I'm copying or pasting from anything into anything else, mostly because of the obnoxious and ubiquitous "let's copy and paste formatting as well as text" that presumably came from some insane desire for ubiquitous rich text.
Or alternately, the solution is to paste it into your terminal, then take the time to read over what you pasted and make sure you understand what is going to happen before you hit enter. This is doubly important if the first word is 'sudo'!!
Not only is this a good habit as far as security goes, it's also the best way I can think of to learn from problems.
wonder if there's something that would be copyable from the browser to the clipboard/pastebuffer/what-have-you (and pasteable to your terminal emulator) that would constitute a ^C?
Oh, wow - you're right! It does work, and trivially so. That is, I created chr(3), opened it in a text editor, and copy/pasted. Poof! No longer in the cat.
I then put sample command line in HTML, with an embedded  . Yep, copied and pasted just fine.
Which means my SOP for dealing with untrusted text isn't anywhere near as good as I thought it would be.
This is really just an extension of clickjacking - modifying the UI to trick the user into performing an undesired action. This is a pretty novel idea, and considering how many websites make use of this to slap their permalinks into copied text (albeit with flash, usually), I'm surprised this hasn't been thought of before.
It would be an interesting experiment to sneak a harmless command after every snippet on a site like commandlinefu.com.
Edit: Also while playing around, I remembered irssi actually has a defense against this. If you try pasting multiple lines, it can detect this. It presents you with a prompt asking if you really intended to paste >5 lines into the text field. I wonder if something like this could be implemented in a shell?
> This is really just an extension of clickjacking
That's was my first thought too, but in fact, it's quite the reverse of clickjacking (even though the same basic idea is used).
With clickjacking, you would positionate some opacity:0 link on top of some apparently legit link. Here, on the contrary, the malicious content is within the apparently legit content, then moved away with css (setting opacity to 0 would not do the trick).
Not a big difference, but that would deserve a dedicated name, IMO.
This is another reason I always type a '#' before copy/pasting any long commands. The main reason is that I sometimes want to edit a long copied command and sometimes a newline get caught in my 'copy'. The '#' prevents it from accidentally executing.
As explained above, this will help only against the first line of the attack (until the first newline character). The subsequent lines will be executed.
A better solution would be to paste the text in to an editor.
I mean, untarring a downloaded tarball from somewhere and running `make` is just as dangerous, right? Only there you can make sure the checksum matches, but people skip that step all the time.
Matches against what? If the website is compromised the checksum can be compromised as well.
If the tarball is not pgp signed by the author (e.g. Bazaar and Tor Project do that), checking the checksum is basically checking if the server you’re downloading from didn’t have any silent data corruption (see recent KDE hosting incident), because in transit TCP does its own checksumming anyway.
My point exactly. No one is ever actually going to read all the code, so you have to start your trust somewhere. Especially if you're going to type `sudo make install` at the end (which is why I advocate things like ~/.local to prevent the need for that, but I digress).
I was just thinking it might be cool to have a service that site owners could include via JS that would ensure that the content in a div is the content seen by the user. It could have a little stamp that says "Verified by SuchAndSuch" in the corner of the div. Should I try to make this? Any obvious issues? Is it worth it?
You have one of two ways to combat this:
1) always copy things to notepad first so whatever it is that you copied you can verify is what you meant to copy
2) Use the inspection tool of your browser to copy it from source where things can't really be hidden.
I usually do #1 anyway because of weird formatting and characters
Did it stop working for anyone the second time? I tried it once, and it worked (gave me the warning and first line of my /etc/passwd file). I wanted to show it to a coworker but it mysteriously stopped working. It is just copying the displayed text now. Kinda weird..
Using Google Chrome 26.0.1410.43 on ubuntu 12.10 64bit.
Out of interest, does anyone know of a Mac utility which will intercept the default paste shortcut and pop up a confirmation of what is going to be pasted, with a really quick interface to the previous few items that were copied to the clipboard?
Jumpcut is fairly close to what you're asking for. I guess you could map command + v to Jumpcut & override default paste functionality. Personally I prefer to use option + v.
There is a subtle hint that all is not well if you try to select the code using triple-click: it will only select one half at a time, suggesting it is not the one-liner it appears to be...
Yes, but not just that. It's also important to make an effort to understand what commands you are typing into your shell before typing them (Google them first if you don't know).
Right... for a real attack, you'd have to hide the evil commands near the end of the normal-looking one (the string you see there is truncated). I thought about doing that, but it'd give you a few seconds to react in this example because you'd have the git command run first. Hmm, maybe it'd be doable using backticks or so? Those could be put at the end and would evaluate first anyway...
what I usually do before pasting insecure clipboard content to a terminal is that I start with a double quotes character "
Once I see the real output, I just have to remove the quotes (<ctrl-a> <del><return>)
ok, honestly, where is the ability to disable clipboard manipulation or similar techniques? Browsers need to do this. I have NEVER seen value if a website's ability to modify my clipboard.
That's a different issue from the one here, actually. View the source. No JS in the page at all; just an invisible span in the middle of the code to be copy-pasted.
{kind=link}
{kind=link}
ruby -e "$(curl -fsSL https://raw.github.com/mxcl/homebrew/go)