It really cuts to the heart of it when you looking at the “devops cycle” diagram with “build, test, deploy” …and yeah, those other ones…
I remember being in a meeting where our engineering lead was explaining our “devops transformation strategy”.
From memory that diagram turned up in the slides with a circle on “deploy”; the operational goal was “deploy multiple times a day”.
It was about speed at any cost, not about engineering excellence.
Fired the ops team. Restructured QA. You build it you run it”. Every team has an on call roster now. Sec dev ml ops; you’re an expert at everything right?
The funny thing is you can take a mostly working stable system and make fast thoughtless chaotic changes to it for short term gains; so it superficially looks like it’s effective for a while.
…but, surrrrpriiiisssseeee a few months later and suddenly you can’t make any changes without breaking things, no one knows what’s going on.
I’m left with such mixed feelings; at the end of the day the tooling we got out of devops was really valuable.
…but it was certainly a frustrating and expensive way to get there.
We have new developers now who don’t know what devops is, but they know what containers are and expect to be able to deploy to production any time.
I guess that’s a good way for devops to quietly wind up and go away.
DevOps and releasing multiple times per day does not always mean to PROD and in most industries that is impossible. Continuous Integration and Continuous Deployment should and do mean to the development branch and container.
Locally I can write code and skip all the tests, skip the linter, skip prettier, etc.….
When I do a commit prettier is run. When I PR into develop other dev’s review the code. When its approved and completed a build is run (including all tests and sent to Veracode and SonarQube for analysis). The build is deployed to the development container where the developers can smoke test and then when SQA is ready promote to Integration for real testing. Fail fast! If the tests fail, we can fix them. If code quality goes down, we can fail the gate === no deployment. Without DevOps and CI/CD these steps get skipped.
Not sure where the idea that software is released to production multiple times per ever came from. Yes, the develop branch should in theory be ready to be promoted at any time but we know that is not reality.
The big advantage to deploying to prod constantly is trunk-based development.
Any system where you maintain a separate development branch is one where you're invariably going to be asked to cherry pick feature B to production but not feature A. This is a problem because you tested everything on a version of the code where B follows A, but now B needs to stand on its own. Can it? Maybe. But you didn't test that.
With trunk-based development you have one main branch that everything goes to all the time. If you need something to not go out to real users then you put it behind a feature flag. If something needs to go out to users today, then you merge a change on top of your main branch that unconditionally shows the feature to users.
This way all code that ever makes it into production exists at a point along a single linear commit history, each merge commit of which was checked by CI and is the same history that devs developed against locally.
In my experience eliminating cherry picking makes a huge difference in reliability, and the only way to do that reliably is to constantly deploy to prod.
Congratulations on moving fast! If possible ‘trunk’ is best.
Long lived branches are a problem if you are doing hot fixes to prod. The goal is the process avoids hot fixes and critical bugs.
Some industries would not allow software to be released more than every few months. SQA needs to sign off. Users need to UAT. 2-week notice, 15-minute notice to log off. Downtime needs to be communicated to multiple time zones. Software versions need to be auditable for regulatory.
The only point I was trying to make is ‘publishing’ multiple times per day with a team of developers requires ‘devops’ and that release does not always mean to prod. The same setup for releasing to prod multiple times per day is the same as releasing to develop multiple times per day.
> Some industries would not allow software to be released more than every few months. SQA needs to sign off. Users need to UAT. 2-week notice, 15-minute notice to log off. Downtime needs to be communicated to multiple time zones. Software versions need to be auditable for regulatory.
As a person who works in a heavily regulated field ($$$), all the audit / traceability requirements apply. We still move fast (multiple releases a day) because we have demonstrated that it reduces risk and promotes stability — something regulators are very interested in. In concrete terms, faster release rates are correlated with lower sevs (or incidents). But the underlying cause is really that faster release rates cause teams to adopt more reliable delivery practices, such as automated testing, gradual deployments, and so on.
Eight years ago this was a hard sell to some regulators, no more. You still need to walk them through the outcomes but even in black letter jurisdictions it’s being accepted.
that doesn't work at scale though. the difference between dev, staging, and prod when there's a handful of services is fine. when there's 300 of them, and 200 of them are broken in the dev environment at any given time, that means you can't actually use the dev environment to do development in because the 300 other teams are also trying to do development in that same environment so their stuff is just as broken as your stuff.
so then you either have to accept that sometimes it's broken and just wait on it, or otherwise agree that staging should always have a working copy of Kafka, except that means the Kafka team can now no longer use staging to stage Kafka changes, so then they have to setup their own separate staging environment and then plumb sufficiently representative test data into that new staging, and then and then and then.
Development should never be broken, ever. Ready to ship and broken are two different things. By ready to ship it more like v2 has 8 total new endpoints and only 2 are ready, then 4, then 6, then 8.
When the tests fail, or the code quality goes down, the deployment fails. I would rather have DEV broken than PROD. Not sure how going directly to PROD would make anything better in this scenario. That is what Integration is for never broken always ready for promotion to prod. Plus a few broken dependencies means ‘yellow’ === impairment not unusable. If the app is unusable for any one dependency that is another issue.
Mocking data when you are ahead of another team is always the reality…
And devs should just not write bugs in their code, ever. Development mostly works, but is going to be broken in subtle ways that other teams are going to pull their hair out because their thing doesn't work, but their thing doesn't work because your team has broken development in a very subtle way that only that one team tickles. Your tests didn't catch it and the rest of your team didn't catch it during code review.
Just want to add that these are all good points and good discussion. Ultimately, I think we agree that DeOps is needed no matter how it’s used. The details of how exactly it’s used per product, per team, per organization is always ‘it depends’. Some of us need to jump through more hoops and there is no way any of our products would be updated in production multiple times per day much less multiple times per month unless it was a hot fix of a critical bug. CI/CD is something to strive for as if you can release to develop multiple times per day it’s only the surrounding process that prevents you from releasing to production multiple times per day.
We have environments with thousands of services and it scales fine. Why would dev (or your lowest integration environment) be broken most of the time?
> except that means the Kafka team
That (a Kafka team, or a DB2 team) is a bit of a red flag for me. Many (but not all) “tech” teams like that are part of the problem. Cross functional delivery teams work much better, because running tech X in isolation is often not valuable.
The one exception to this is “x as a service” teams. Eg DBaaS teams, Or even a team that offers a pub/sub service. But in those cases such teams are literally measured by uptime SLOs, so if a pub/sub team can’t deliver uptime, they’d need to improve.
Where are you that has thousands or services and it scales fine? Twitter and Facebook famously both don't have a separate staging environment because they have thousands or services and it doesn't scale fine. They do canary releases and feature flags so as to do gradual deployment and testing in prod. If they can't solve the problem but you're somewhere that has, my next question is are you hiring?
Dev is broken because devs are doing dev on it. I mean, it generally works, but it's the bleeding edge of development so there's no real guarantee that someone didn't push something that doesn't work in a way that the rest of the company is relying on.
What is the DBaaS or pub/sub team's commitment to uptime in the staging environment? It's staging. if they have to commit to a reasonable uptime, they can't actually use it as staging for themselves. Saying they need to improve is trying to handwave out the fact that they need a staging environment where they get to run experimental DBaaS or pub/sub things.
I worked at AWS. Each team/service had their own alpha/beta/delta/gamma development environments, as well as one-box and blue/green production deployment environments, and deployed to waves of regions from smaller groups at the start to bigger groups at the end.
It’s possible in many even heavily regulated domains, because there’s enough data now for regulators that it reduces risk.
Releasing multiple times a day in itself isn’t the point though.
The point is — adopting good practices to ensure trunk based development is pain-free. It’s about ensuring the release process is as automated as possible (if you’re releasing once a month, you are exercising your deployment process 12 times a year. When you’re exercising your deployment process 12 times a day, it really encourages you to work the kinks out.)
It’s also ensuring that your monitoring and alerting can keep up. Essentially it’s a signal to the entire org that “We will move fast. Deal with it.”
There’s data out there from even large non-FAANG orgs now about how this approach reduces sevs instead of increasing them.
> Not sure where the idea that software is released to production multiple times per ever came from.
UX-focused development. Your concern is mainly about user journeys, acquisition tunnels, etc. So you rely on user feedback a lot. So you ship, A/B test, iterate.
Also, if your service consists of lots of microservices, you don’t want to wait to ship them all at the same time.
The most fitting example to both is probably Netflix. I guess they ship to prod every day a lot.
I bumped into a DevOps job at Teradata, did it for two years, then left for where I belong, in gaming as a backend developer. It was a corporate with good pays and perks including international travel etc. Some friends are still there doing DevOps very happily. Talking to them it never feels a like a dying field.
I hated my DevOps role so pardon me for only reading the headings of the article, but talking about it in past sentences seemed very delusional.
I think hiring SRE makes sense. I think hiring 'platform engineers' makes sense. People still do that, and will, as far as I know, far into to the future.
...but I think hiring devops means you never understood, even vaguely, what devops was; you're just using a buzz word in your job ad.
This. I see ads for DevOps roles as a signal that “this org doesn’t get it”.
DevOps is about people and culture. Your teams embrace automation, fail fast, lean — all the good stuff. DevOps is about concrete business outcomes. Not Ansible or bazel.
> hiring devops means you never understood, even vaguely, what devops was; you're just using a buzz word in your job ad.
I honestly don't get this thread and the complaining. Yes, I was one of those empowered engineers at an org that did ALL of the DevOps. But do ya'll seriously think you don't sometimes need people who do ONLY DevOps? Cause I can tell you there are absolutely orgs that deploy dozens, if not hundreds of servers sometimes by region and in those cases you absolutely do need full time DevOps engineers to tune, configure, and deploy these fleets. And yea it's a full time job just to do that.
Correct, except generally they aren’t even good at ops. They tend to know a highly specific slice, or how to operate an abstraction. But troubleshooting Linux? Good luck.
A regurgitation of Sysadmins that knew some scripting?
Cloud Native Sysadmins?
Patrick Dubois said "a systems administrator working with an Agile mindset", and this guy started DevOps Days; which is where we get the term.
The "merged teams" spiel is from the "10+ Deploys a day" talk from Flickr, and it's but one definition of what devops means.
This is why I personally consider it failed, it's meaningless because it means different things to different people. You can never "do it wrong" if you don't even have a definition that everyone agrees on.
> Devops is when you have developers who are empowered.
That’s just half true. If something doesn’t work in production, guess who can get mysql production logs? Not the developers. Can you access production dbs (not that that’s the way to fix things, but I have seen that in many orgs)? Nop. And if there’s anything you can do yourself (like changing things via TF files), you’ll need to wait until the gatekeepers approve your request.
The gatekeeper are usually called platform engineers.
But in any case, I don’t want all that power (and responsibility) either if it does not come with an increased compensation.
What parent commenter says that when you have "devops", there are no such gatekeepers.
I always got higher compensation in such companies/teams, because they weren't dying. At least, when I joined :) They needed efficiency instead of control and keeping salaries down.
This is entirely predicated on the issues this person experienced. Irrespective of whether or not devops teams end up with solutions that look like this, none of them are meant to.
My first experiences had to do with the ability to add new services, monolith or not, and have their infrastructure be created/modified/removed in a environment/region in-specific way, and to be able to safely allow developers to self-service deploy as often as they want, with the expectation that there would be metrics available to observe the roll-out, and safely revert without manual intervention.
If you can't do this stuff, then you can't have a serious posture on financial cost, while also providing redundancy, security, or operating independently of one cloud provider, or one specific region/datacenter. Not without a lot of old school, manual, systems administrator work. DevOps hasn't gone away, it has become the standard.
A bunch of pet servers is not going to pass the appropriate audits.
> adopt much more simple and easy-to-troubleshoot workflows like "a bash script that pulls a new container".
This style of thinking let's developers learn every nitty gritty pain of why we have frameworks. I see the same challenge with static site generators, they are all kinda annoying so people write their own, but then theirs is even worse.
I think a lot of Kubernetes hate is misplaced. It is a great piece of software engineering, well supported and runs everywhere. You certainly don't always need it but don't create a bunch of random bash scripts running all of the place instead of learning how to use it.
It's basically a prototype that industry ran away with. It leaks implementation details everywhere and pushes way too many config options up to the developer. Because industry ran away with it before it could be good, it takes projects like Cilium to push it in the right direction, but those take forever to get adopted and are really hard because they don't live in the product itself.
You'd need like 10 more Ciliums to make Kubernetes actually good, and they'll never all get adopted. The tech is a dead end that demonstrates some nice tech/patterns but got overhyped. It's like the Hadoop of containers
Can you clarify what you mean by "leaks implementation details everywhere"?
I like to think of kubernetes as a big orchestration platform that you can choose to use what you need. If an ingress and pods work then use that, otherwise extend an throw an operator up for what you need (it likely already exists).
Cilium for instance is great for that, so is Istio and the like. They aren't hard you just have to understand networking... which is nearly the same energy of running it on another orchestration tool or raw on a network device.
You shouldn’t have to think about all the implementation details of your deployment target. There shouldn’t be platform engineers or Kubernetes experts. Nobody should be writing YAML, or getting paid to set up Istio. Nobody should have to learn the Kubernetes architecture or know about the kubelet or EBPF. The tools should be simple enough with good defaults that application developers just click a button and have their code run somewhere. Right now platform engineers fill that gap, because the underlying tech doesn’t.
IMO you are thinking too much like an engineer if you are saying you “just have to understand networking”. Why? It’s always better when the problem gets solved in a way that allows you to not think of it too much. Right now SREs and the platform team do that for application developers because Kubernetes only does it halfway.
Infrastructure/devops/SRE is a pure means to an end of getting actual applications (the ultimate source of all the value in software) to run. It’s an obstacle. Right now the obstacle is bigger than it needs to be
So there should be magic on every layer except for the application?
That will never happen, the only thing you can do is pay someone like heroku to take care of that for you. Or if your project is small and plain enough you run “serverless” which is just routing to another platform team, as I’m sure you’re familiar.
It’s complicated because there’s a lot that goes on, kubernetes or not.
You literally use magic like that all the time with Linux, compilers, language runtimes. Magic is perfectly good when it works. Being able to do anything you want with a quick “presto” is amazing. Nobody should have to learn arcane spells, study the ancient tomes, and communicate with beings of the ethereal plane - somebody just needs to figure out the next “presto”. And historically speaking, usually somebody does when there’s an incentive to do so.
In other words - Serverless is another platform team in the same way Linux is another OS team or Java is another language team. And for 99.9% of companies a language team or OS team would be absurd. There’s a big incentive for platform work to go the same way.
Ops here, In a simple Kubernetes environment, you don't have to know networking. However, few environments are simple and abstracting X away becomes extremely difficult job once business requirements collide with abstraction.
Obstacle is big most of time because most applications are not easy to run. Most DevOps mostly came around because Devs flinging balls of mud over the wall and landing on the Ops side with a splat and then screaming when we can't build nets to catch the mud ball and Ops is covered with mud. Sure it failed just like DevSecOps fails because most of time, Devs don't care about anything other than closing Jira tickets and going home.
I think that devs really should have a decent understanding of Kubernetes. It is essentially the operating system for any app that needs more than one computer.
You don't need any of that, EKS works out of the box with Fargate.
But companies don't want that, they want to support EKS and data centers, which means supporting the "implementation" side of all of the interfaces, which means getting down into the details.
The real problem is that every platform team, deep down, wants to rewrite EKS and they often do, which I would describe as "a giant money pit".
I think those products are much better than k8s for many use cases, but I don’t think that anybody has really delivered the right thing in that space yet.
Just look at the release notes for every major release. They focus on what's new within Kubernetes architecture instead of what's new that benefits users.
Things like having to remove finalizers appended onto resources when you delete them and they hang.
Damn near everything about Custom Resources.
This isn't a dig at Kubernetes; I love using it. However, I agree that it leaks implementation everywhere.
Kubernetes is just a poor Linux clone with extra steps. Seriously, it has all the basic parts of an OS, just half-assed: the scheduler, the networking, the state management. We already had way better operating systems that can, you know, schedule workloads and talk to the network, and it didn't require gigabytes of YAML and string templating to make it happen.
Yes. I actually wrote another top line comment about this which I deleted. Kubernetes is like someone decided to create a distributed Linux where you had to configure and learn about every part of the operating system. Linux proves it’s possible to provide simple “deep interfaces” to OS-class, hard problems.
Most people in industry have never used Borg or something like it, and so think Kubernetes is like apex technology rather than a step backwards. And to most people working directly on tech like Linux/containers/low-level infra is something they don’t even consider doing because they subconsciously think it’s off limits. So to them Kubernetes is amazing rather than riddled with fixable problems.
Agreed. If we didn’t use kubernetes, we’d have to reimplement a bunch of its features. Back when we were getting started I tried docker swarm because it was supposed to be simpler, but I had weird issues with its networking.
The best part is multiple environments. I can run our full stack on my laptop with k3s and one call to make. We use the same yaml (with kustomize) for all three cloud environments.
The argument against Kubernetes is not that you should go backwards from it, but that there is a huge need for something better than it. Many big tech companies have platforms that are better than it which aren’t properly (if at all) externally productized.
And the fact that many medium companies have “platform teams” configuring Kubernetes and gluing together basically the same set of tools (source, build, test, release, ops, obs) together in basically the same way is a huge smell that something better is needed. Basically, doing things the right way is actually a big operational/engineering/monetary burden for most companies that just want to write applications. And K8s is a big part of that
Big tech companies are willing to invest in those platforms and mold them to work like they want to work. Few other companies do so and Kubernetes becomes the way to get big tech like platform.
I do agree it could be better but it's Un opinioned nature also let's these companies shape it in a way that matches where they are. Also, probably biggest issues with it only come up if you are not in managed Kubernetes which many are.
K8s does solve a huge set of problems. But I agree with GP that all the non-application-specific parts on top, especially observability, are a huge time sink. The industry could use a Rails for the cloud. We built ours from the ground up and we’re in a good place now, but we kind of had to reverse engineer things like logging requirements from security questionnaires. I suppose these are things that consultants and saas companies can charge a lot of money for, so there’s no desire to open source it.
Whoever has worked with bash scripts would know that relying on a bunch of bash scripts for your infrastructure is extremely naive. At the end of the day, Kubernetes is just a tool with complexities in place for companies with larger workloads
The whole ecosystem around it is an example of Conways law and and a Google product.
None of the people using it are google.
Google, also, runs its own hardware.
Shockingly it is a great product if you rent hardware, autoscaling is autospending. No one knows what a feature costs any more because its all just a big bucket your pouring money into for amazon to have 30 percent margin on.
We need operations people again, we need to stop using containers as bags for shitty "software" ... Do actual engineering.
Kubernetes is actually extremely popular all around the world. Chickfila if I recall correctly deploy it in every single store!
A lot of big dinosaur corporations are implementing it actively. Unfortunately VMs or Kubernetes or whatever tooling is still going to suck if you have shitty people using them.
>The whole ecosystem around it is an example of Conways law
This is such an inaccurate take.
>we need to stop using containers as bags
Containers and container orchestration are a NEEDED and REQUIRED piece of the technology stack in the current reality. That doesn't mean people need to be ignorant of the details that make them work.
As someone who's been around for a while we are in a better place than when we had "dedicated operations people" that just gatekept everything.
What you hate are teams just parroting what other people are doing with the tech, not the tech itself. But let me tell you, if you're going to have teams of people pretend to know what they're doing wrapping it in a standard "bag" sure does make it a hell of a lot fucking easier to unfuck when things go wrong.
> Containers and container orchestration are a NEEDED and REQUIRED piece of the technology stack in the current reality.
That is not remotely true. Containers (and their orchestration) are a choice. Obviously people have their reasons for making that choice, but it is in no way a requirement. To say otherwise is either profound hyperbole or ignorance.
> Containers and container orchestration are a NEEDED and REQUIRED piece of the technology stack in the current reality.
If you're deploying NODEjs apps to the cloud, they sure are.
> if you're going to have teams of people pretend to know what they're doing wrapping it in a standard "bag" sure does make it a hell of a lot fucking easier to unfuck when things go wrong.
No one looks in the bag, they just roll back, the bag is opaque, the bag breeds more bags, less trnasparency and higher costs.
Step back and read what you wrote, if you described any other relationship in your life in these terms, your friends would be having an intervention. The codependent circle jerk has enabled so much bad behavior. The tooling you're advocating for is an enabler.
I want App Store like software roll outs. The infrastructure we have is kind of like that, if you don't look too close. We need to start doing the hard work to make it not suck. We need to stop pretending that this is a good place and put in the work to make it better.
That's the problem. Yes, I'm the old man yelling at cloud, but indeed 'kids this days' don't know Linux, they know how to provision things from Terraform. In fact it feels like logging in via ssh and checking process with with `strace` is a lost art. Checking PCAP? That's a black magic!
This is the elephant in the room: all "new" technology isn't fundamentally new. Terraform is just curl with state management for lots of different websites, Andible is just a YAML to Bash converter, and so on. If you have good fundamentals, not only are these things easy, they're also incredibly frustrating, because you can easily see their limitations. You can always tell how experienced someone is by how well they know what a given tool is actually doing under the hood. People who exhibit shock and awe will just mess up your codebase, because they have no clue how the machine actually works.
No, I want to hire the grumpy, cynical greybeards, because they know their fundamentals, and they're immune to shiny bullshit.
There's no substitute for skill and experience, despite what the modern tech discourse says. "Anyone can program!" And yet, we have threads like this, where we find out, SHOCKER, that the best codebases are the ones maintained by like... four senior developers, half of whom contributed to several Internet RFCs, and half of whom used to work at Bell Labs.
> There's no substitute for skill and experience, despite what the modern tech discourse says. "Anyone can program!"
I’m told this is gatekeeping. Yes, and…? I’ve always found it amusing that I see little to no anger being directed at kernel devs for their gatekeeping. Almost as if deep down, people know that they shouldn’t be fucking with the thing that runs the world unless they are actually good at it. Or maybe they’re just afraid of Torvalds.
I agree that "gatekeeping" gets a bad rap. Sure, it can be taken too far. But at the end of the day, one needs to actually be qualified. And if they aren't, well sorry but you aren't good enough for the job. It doesn't make you a bad person, it just means you need to work on your skills before you're a fit.
Right. I don’t apply to jobs that cite a need for a decade of experience with data center-scale networking, for example, because I don’t have that. Not even close. I don’t view that as gatekeeping, it’s wanting people to be able to quickly ramp up to whatever quirks the environment has, without needing to learn fundamentals of the craft first.
Ansible is a lot more than just "YAML to Bash". For instance, Bash scripts are not idempotent. Ansible playbooks are. Sure, you can hack together a way to ssh and run commands very easily but it will break at some point
Ansible playbooks are as idempotent as bash scripts.
You need to include checks when writing them so they actually are idempotent, just like with bash script, and they happily leak idempotency-breaking details like "restarting a service" works only if a) service currently runs b) because "restart" is a command, not expected state of "the service was restarted and is now running
I think this comment is a bit unfair. A lot of work goes into not having to do those things. Good immutability often means less need for babying a specific server.
It’s been a long time since I’ve had to do those things, so yes it’s becoming a lost art to me. However, on the rare occasion I need this sort of insight I do fine with JIT research.
It’s the logical outcome for most when you don’t grow up being told to RTFM, you’ve never had to recompile a kernel to get an expansion card to work, and you’ve never touched hardware.
Many things are 'great pieces of [software] engineering'. That does not mean they are a fit solution to any problem. Many times a script or simple ansible playbook, or docker-compose is just a better fit.
> The cause of its death was a critical misunderstanding over what was causing software to be hard to write. The belief was by removing barriers to deployment, more software would get deployed and things would be easier and better. Effectively that the issue was that developers and operations teams were being held back by ridiculous process and coordination.
So many arguments are based on strawmen...
I like devops / daily deploys, because they're part of the puzzle leading to higher quality code being deployed on production, and associated less stress.
The point is (for any individual developer) not to actually deploy their progress every day on prod, but to have the option to do so. This leads to code going on prod when it's ready, but no sooner. If the problem is more difficult than anticipated, code still sucks and needs refactoring, well, you're just going to work on it as long as it needs it and deploy it only then.
Meanwhile if you have let's say monthly releases, you will get the death marches, because delay of one day can mean delay of one month / quarter / whatever. Everyone feels the pressure to deliver, leading to suboptimal choices, bad code being approved etc.
The main thing the author gets wrong is that it's now much better understood amongst engineering leadership that development teams need at least one person with ops/infra skills. Development teams shouldn't wait for a centralized DBA team to pick up their schema change request, but neither does it make sense to ask frontend developers to learn all the ins and outs of running databases. Teams do need somebody to specialize in that skillset. This person with ops/infra skills is the modern Site Reliability Engineer (i.e. for most companies, a term that was inspired by Google's book, but distinct from Google's implementation of the concept).
As startups grow into enterprises, eventually there are benefits to be had from getting all the different SREs on the same page and working according to the same standard (e.g. compliance, security, FinOps...). Then, instead of each SRE building on top of the cloud provider directly, each SRE builds on top of the internal platform instead.
The successor, the platform team, is also really only accessible to enterprise companies.
Hiring an entire team to build great dev-tooling and deployments, monitoring, application templates, org level dependency management etc is just too much to swallow for any medium sized or smaller business, so in that reality you wind up with a few heavily overworked devops folks who take up unhealthy habits to cope with the associated stress and risk.
In my 10 year career thus far none of the startups I worked for, even well capitalized ones had what this article, and myself, would consider to be a platform team. I only saw my first platform team when I stepped into a role at 6000+ person company.
It's effectively an underserved (and under-appreciated imo) area and responsible for a lot of pain and land-mine decisions companies make around their software product.
If you can afford to make the user the tester, you should. There is no moral hazard, only an economic one. If you have 5 million customers paying $1 / year, make the user do the testing via canary deployments, metrics, etc. If you have 5 customers each paying $1M / year, be sure to test it yourself.
The problem seems to be that people forget which regime they are operating in.
Er... No? If you take someone's money in exchange for goods and services, you have a moral duty to give them what you said you would. Not a broken version of it– what they bought. If you explicitly state they're getting an unstable product, then sure. If you actually do your best within reason and your service is broken, shit happens. Nobody is perfect, but you made a good faith effort to deliver on your promise. But if you don't, and deliberately don't bother checking if it actually works while happily pocketing people's cash, that's unambiguously negligent. Ripping off small groups of customers is no morally different than ripping off all of your customers— it's the same immorality at a smaller scale so you're more likely to get away with it.
The point is that you confused moral hazard with economic hazard in claiming that there was an economic hazard but not a moral hazard. When you have 5 million users paying $1/each, then pissing off a hundred of them makes very little difference to your bottom line, i.e. low economic hazard. But morally, because you sold them a product for $1/each, you owe them warranty of fitness, therefore the low economic hazard, i.e. the low economic consequences, introduces high moral hazard. When the situation is flipped, with 5 customers paying $1 million each, your high economic hazard in the risk of losing a customer aligns your moral incentives to do correctly by them, and you therefore have a low moral hazard.
I largely agree with you, except that you flipped the terms.
I'd like them to be clear about their own thinking. Something occurs in their mind once money is exchanged. If time is exchanged (i.e. advertising), on the other hand, no such pact is created. Why? Isn't money essentially a proxy for time?
I should have known better then to take that bait. I'm not interested in pedantic philosophical debate about theoretical obligations skewed by imaginary prices that don't reflect real world business scenarios. In fact, I'm opting out of this entirely. Have a good night.
2 observations, first the cynical one, but the second is optimistic.
For leadership, the whole idea of "breaking down silos" is almost always lip-service, and to the extent that is/was a core mission of DevOps, it was always doomed. Responsibility without power doesn't work, so it's pointless unless the very top wants to see it happen. Strong CTOs with vision are pretty rare, and the reality is that the next tier of department heads from QA/Engineering/DataScience/Product are very often rivals for budgets and attention.
People that get to this level of management usually love building kingdoms, and see most things as zero-sum, so they are careful to never appear actually uncooperative but they also don't really want collaboration. Collaboration effectively increases accountability and spreads out power. If you're in the business of breaking down silos, almost everyone will be trying undermine you as soon as they think you're threatening them with any kind of oversight, regardless of how badly they know that they need process changes.
Anyway, the best devops people are usually excited to code themselves out of a job. To a large extent.. that's what has happened. We're out of the research phase of looking for approaches that work. For any specific problem in this domain we've mostly got tools that work well and scale well. The tools are documented, mature, and most even permit for a healthy choice amongst alternatives. The landscape of this tooling is generally hospitable, not what you'd call a desert or a jungle, and it's not as much of a moving target to learn the tech involved as it used to be.
Not saying every dev needs to be a Kubernetes admin.. but a dev refusing to learn anything about kubernetes in 2024 is starting to look more like a developer that doesn't know Linux command line basics. Beyond the basics, Platform teams are fine.. they are just the subset of people with previous DevOps titles that can actually write code, further weeding out the old-school DBAs / Sysadmins, bolstered by a few even stronger coders that are good with cloud APIs but don't understand ELBs / VPCs.
I have long felt that DevOps was always a philosophy, not a methodology. It simply meant folding all that operations stuff into the SDLC. It was always about making Ops part of Dev, not the other way around, and especially not as a standalone discipline. The cloud made this a lot easier, as everything could be done programmatically, but the philosophy held true long before that.
It doesn't mean CI/CD pipelines, Terraform, or YAML. Those are all incidental.
The moment specialised "DevOps" teams started springing up it was all over. We just reinvented the sysadmin.
1. I feel that one big and important aspect of devops that isn’t mentioned is that smaller releases are less likely to have killer bugs. If you can release one change a day rather than 100 changes a quarter then overall I think there’s a strong argument, not to be had here, that you’ll have faster releases and less bugs overall, assuming my next point. This doesn’t take away from the article, but it’s just something I don’t see discussed much.
2. I think a huge part of the problem is that business management keeps trying to abstract away engineering management. The most productive team I’ve ever been part of was when I was able to spend most of my time planning and coordinating the work, as part of an overall vision, while my peers did the implementation and gave me feedback. One side effect of this was that productivity was actually measurable. But the value of productivity is lost on business management who saw me as just engineer - one who had the authority, furthermore, to push back against stupidity and was therefore a pain in the ass. Technical management is not valued, because it’s not understood, and this is seen in the endless cycle of fads designed to make all engineers fungible.
The problem is when hardened system administrators and DBAs were replaced by people who were certainly not worthy successors. As that transition took place, a lot of the added value was eliminated.
I don’t know. As someone who has tried to introduce the simple concept of version control to various sysadmin orgs over the years, I am fine with many of those types of sysadmins going away
A lot of those guys just couldn’t handle a reality where they couldn’t name all their systems with cute Dr Who hostnames and do all their work as local root with riced out bash prompts
Devops at least forced them to the same table with the dev org, and if they ended up getting replaced in the transition then I shed zero tears
I introduced RCS to my sysadmin team in the mid 90s but again you always had those guys with god complexes who couldn’t be bothered to ‘ci -u’ or ‘co -l’ properly because that’s not how they do things. And if your entire team isn’t onboard then it’s worse than having no VCS at all
God riddance to those guys. They thrived in silos.
Well, some people are not agreeable, do not want to be seen taking guidance from others.
They are not worried about understanding what they do, or improving their practices, they are worried about status and how others perceive them.
Those people may be able to protect their status in the short term, maybe even bluff and be promoted. But they will never truly understand what's going on.
But who needs to know what happens behind the facade of the services? It does everything for us!
I miss the days of having an expert sys admin and DBA to help with tough issues. Now we're all on our own with no training. Most of the good people got axed or thrown into other roles. Becoming good at something only to have it thrown away and undervalued pisses me off.
I'm one of those old sysadmins/DBA's, and having worked in devops for a year or two a few years back, I was able to take the best parts of it that I found useful, and leave the rest for the internet widget crowd to bicker about on here and in the workplace.
I brought CI/CD, automated deployments, and infra tests with me to what was a very "retro" non-cloud UNIX style environment. I left all the horseshit (kanban, retrospectives, scrum) for the others that are not really all that interested in actually getting shit done. While those guys had a bunch of shiny tools to play with all day long, they lacked basic UNIX skills that us old guys have, and you had to continually had to show them how it was done.
The results speak for themselves. Couldn't be happier (or more securely employed) at this stage of my life.
That's great. When my company axed the Ops people, they didn't move them onto dev teams (some did, but very few). So we ended up with DevOps teams that were whole Dev experience. The Ops part was supposed to be "easy" with AWS. It was completely a cost saving play at my company by throwing more responsibility on the existing dev - combine roles and reduce headcount.
What sort of skills does a sysadmin and DBA have that most engineers lack? Most engineers should know the basics of bash scripting, iptables, Unix logging, cron, systemd, etc. as well as SQL, debugging slow queries, optimizing them, backing up dbs, etc
_should_ know is different than _do_ know. Most engineers have little to no understanding of those systems topics and the only DB knowledge they've picked up is what leaks through their ORM
A person who competently knows all those topics _and_ how to write application code is worth their weight in gold
> A person who competently knows all those topics _and_ how to write application code is worth their weight in gold
IFF the company consistently values those skills. IME, they’ll say upon interviewing or hiring that those aren’t necessary for their workload, until they suddenly are, where you’re lauded as a hero. Predictably, the memory of hero status fades when promo season comes around, because those “aren’t core skillsets,” or something similar.
'fades when promo season comes around, because those “aren’t core skillsets,” or something similar.'
Exactly what I'm going through right now with a potential PIP. Last year I was told there was a solid basis for me being the getting the highest rating, but only if my core work was faster. Now they want to PIP me like nothing else I contribute to matters.
Yep. The speed issue they are pulling is an area that doesn't have any objective standards. So I ran a JIRA query to see how I stacked up against the other person who was my level on the team. We completed almost the same number of points over the course of this year...
Bash alone has a million footguns. If you know to use shellcheck you can probably survive those, and if you read the bash manual in its entirety you’ll almost certainly be well on your way to greatness, but getting devs to read docs – let alone boring, Web1.0 docs, is stretch.
> basics of SQL…
Have you seen the knobs Postgres and MySQL have to turn? Do you know what they all do, when you should turn them, and by how much?
The documentation for both of these is enormous and highly detailed, yet in no way covers everything that can and will go wrong. You only find those things out by using it day in and day out.
As to SQL itself, “I can do inner joins” is about as complex as I’ve seen most devs do. Hell, mention a semijoin and you’ll get blank stares.
I think in general, you’re grossly overestimating the average developer’s knowledge breadth and desire to learn these things. They simply do not matter for most, because tooling exists such that most of the time, they don’t need to know. I consider myself decent at Linux and RDBMS, but that’s mostly because I genuinely enjoy both, play with them in my off-time, and have been running Linux in some form or fashion for the last 20+ years. Also, of course, my work specializations (SRE —> DBRE) have helped.
Just like agile, DevOps has some good intentions. It's always about how it's executed and like anything in software engineering you will run into trade off situations where you have to find the best solution for your organization and product.
I really enjoy working in a deploy often and fast environment though and I firmly believe that fast feedback loops are one of the most important things for development speed. And this is what DevOps at its heart is about. How you achieve this and how reasonable it is for your situation is left for you to decide.
I think author is just wrong. I see it has a lot of upvotes so there are people who share view with author.
But every single idea I read in that post is just wrong. Like author never worked in siloed team where you had to wait blocked for a week so DBA guy picks up your change request. Then if something went wrong on prod you had to wait for SysAdmin to basically be your typist because you did not have access right.
It is not that you don’t need DBA or SysAdmin but for devops purpose they are assigned to a team - which makes companies needing more of those people NOT LESS - because earlier you had single DBA to know all of company projects which was cheaper for business. Now idea is you have people in the teams so you don’t throw stuff over the wall but single team can deploy and operate their project with full knowledge.
Well of course there are companies that take 5 jr devs and now assign them to be devops team but that is company work organization problem not devops problem.
Didn't help that we had made these components and services into commodities. Developers and organizations came to expect them. Of course you use CI/CD pipelines to build and deploy your software. Of course you use orchestration and autoscaling groups. And so on.
So that even if you're building small website for your local soccer club it's probably run through GHA on every change with a full red/green deploy process, run on autoscaling groups and so on.
Never mind that most of these applications' databases could fit into RAM on a single server with 24 cores and never even touch the system limits.
This is one of those things that still makes me scratch my head. When I started programming my code ran on a 2-4 thread machine with a couple GB of ram because that was the size of a relatively affordable commodity server. Today my code runs on a 2-4 thread pod with a couple GB of ram because... reasons I guess.
The industry has been given servers with 100x the resources and collectively said "naw I'm good". Can't wrap my head around it.
Devs don't know how to write software that doesn't immediately balloon to gigabytes of memory use for a "hello, world" application. Seriously, they've just never done it.
DevOps was breaking down silos between Devs and Ops. It was co-opted by Enterprises to instead be seen (just like with agile) as CI/CD tooling (which is just one means to an end) and they tended to completely ignore the culture and values which are arguably the most important components.
I remember dealing with ops teams. Nice people but it added a lot of delays and friction to deploying things. I very much prefer not having to deal with ops departments today. Not a thing in my life anymore. In that sense the devops movement has been a total success.
Where devops went wrong in a lot of teams though is assuming it's a full time role for a specialist that then does your devops. That's not devops. It's ops. And these aren't developers but operations people. Embedding them in teams is still progress though as it removes obstacles.
But if you do it right, this is not a full time thing at all. The wrong way is generating a lot of busywork for your devops people to develop loads of yaml files that feed into things like Kubernetes, Terraform and then enable organizations to codify their structure into their deployment architecture using microservices (Conway's law). I'd suggest not doing that and doing things that minimize the need for devops people. Like using monoliths.
I prefer solutions that minimize my time involvement. I use monoliths so I don't have to babysit a gazillion deployment scripts. I need just one of those. And since I don't have micro services, I use docker compose, not Kubernetes. The deployment script is just a few lines of bash that restarts docker compose. It kicks in with a simple Github action. The amount of time setting that up is a few hours at best. I rarely need to touch those files. We have no Terraform because our production environment got created manually and we're not in the habit of destroying and recreating that a lot since we launched it years ago. And it's simple enough that I can click a new one together in an hour or so. Automating one off things like that has very low value to me.
The problem with devops was that companies thought they could get away with training a dev to run a server farm (or training a sysadmin to code)... while it might have worked for some companies, it just smacked of being cheap everywhere else. I still see similar job postings online under the guise of "engineer".
One item the DevOps mindset missed was reproducibility.
Fast feedback loops in spirit tell to have a way to know what’s wrong but it doesn’t tell how to reproduce it as you have layers and layers where your code is run. So, you are in a spot of I kinda know what’s going on but I have no way to reproduce it because:
- the application has hardcoded paths.
- the service discovery isn’t dynamic
- the branching strategy doesn’t account for edge cases.
- the build process doesn’t account for edge cases.
- and many other things that are related to bad practices.
I recall an old boss saying he wanted stable dev environments which sounded an oximoron. I’ve always aimed to have an environment where I can reproduce a desired behavior wether is a faulty or not.
Reproducibility is one of the things we got with containers and k8s (and before that, 12-factor apps). I run k3s on my laptop with a minified stack, which is good enough to mimic nearly any behavior on prod.
Cloud-specific saas (like proprietary databases and AWS lambda) are awful for this though, and we avoid them where possible. Our S3 code was a bug farm until I discovered minio. Now we’re stuck with Snowflake because scale and speed, but the fact that I can’t iterate fast locally has caused me to lose days of my life that I’ll never get back. Hoping I can hack something together with duckdb when I get time.
> Money was (effectively) free so it was better to increase speed regardless of monthly bills.
Jesus this. No one knows where the money goes. If you can't tell me cost per customer, per user then your business is missing key metrics.
> ... "discovered" that troubleshooting Kubernetes was a bit like Warhammer 40k Adeptus Mechanicus waving incense in front of machines they didn't understand in the hopes that it would make the problem go away.
Wackamole with problems...
The part where he talks about the death of QA.. yea. This is enshitifcation in action.
I _really_ miss having a dedicated QA team / process. I noticed that the role essentially disappeared a few years back, and now developers and users have to be the ones asking "is this working the way it should be?"
Pouring out for QA over here. My first gig ever, we had lovely QA people who spent all day just... using the application and trying to make it break. When it did, they'd fail tickets back to us, and we'd fix them. It worked so amazingly well. Now? Hurried, bored devs do it to get the next release out the door, and it shows.
I worked in QA for the first 4 years of my career. There was a lot of creativity in “how to make an application/feature break”. Sure, most of the time I didn’t realize that 10 scenarios I would run through were moot because of how a feature was implemented. But often, that “creativity” would expose major issues that I had no idea about their root cause, but would drive significant (or important) changes to the product.
One of my favorites in my first couple of months in my career was testing a service that accepted user uploads and returned some value based on the upload. I thought “oh, I should just test a butt-load of invalid files”. Where am I gonna get a butt-load of invalid files for our service? I’ll just write a script that iterates and uploads everything under my `C:\Windows` folder. Discovered 2 bugs. One was that some random binary files there caused the parser the service was using to segfault and another about how the service stored those temp files before validating them. The first required involvement from a totally different team in the company because of “how serious it was”. As a fresh college hire at the time I got a ton of praise for “exposing such a critical buffer overflow” that went undetected for years (lol, I had no idea what I was doing but I took the praise). The latter was because the developer of the service never cleared their /tmp directory where they wrote user uploads before validating them. I ended up filling the VM disk with junk that took down the entire service.
Me too. Oh man, me too. Often times, the good QA people/teams were the ones who knew how a feature fully worked. It’s limitations, extensibility, interoperability with other features, etc. In the beginning of the transition/disappearnce of QA developers were told they needed to be their own QA. And this made some sense assuming the dev would be given 2x the time for each feature. But that expectation quickly changed to build an MVP, give a demo, ship it to “get feedback from users”.
This is under appreciated. What happens is that product managers are either crippled with the fallout from double duty, or, they go mad with power at the extra clout they are given to try to compensate for the nonsense position that orgs find themselves in. Both are ugly situations, and either way we lost important checks and balances. Putting anyone else in charge of quality turns into self reporting and always has a conflict of interest
Or what happened in my company where product managers were expected to take on a marketing role, and developers were the ones left with 3 roles or product management (usually left to the dev manager), development and QA on the individual developer. You’re left with product managers have no clue how the product works. They meet with 3-8 customers or other teams a day, and come back with a check-list of “must haves”. They have no idea how the existing product works, they just know that “customer is asking for X, what’s the timeframe for adding X?”. Then dev managers who have to take product management role, so they have no time for understanding how anything is actually built. Their time is spent defining timeframes, requirements, and expectations with other teams. “We trust our developers to do the right implementation”. Then developers who just get piecemeal requirements and are asked to implement it in the simplest fastest way. No time for a major redesign or refactoring of anything. Because from the PM prospective, there is a check-list of items we need and there are 2 unchecked boxes. From the dev manager prospective, we have X and Y, so having XY makes sense. Then from the developer prospective, just duct-tape them together instead of actually building Z which is what makes sense.
Yes, some K8s operators to cost your deployments so you can auto scale based on ROI of a microservice instead of raw utilization. No point in spending on five nines if nobody will even pay for two.
>> "discovered" that troubleshooting Kubernetes was a bit like Warhammer 40k Adeptus Mechanicus waving incense in front of machines they didn't understand in the hopes that it would make the problem go away
I'm not familiar with the reference but logs, events and metrics seem pretty useful. Port forward, shell into containers, view logs, etc. I don't see what is so bad about it.
The problem here is that once your in and need tooling what do you do? Your likely going to have to re-build the whole container with that tooling on board (if its even possible)...
Containers aren't problematic in themselves. There are reasons to use them. Ruby, php, JS python (fucking venvs) have this habit of contaminating a system. Containers are a great way of... containing that shit.
But the moment I'm giving you a single file binary.. why in the name of all that is holy are you putting it in a container? If it's untrusted software then there is a good reason but then why are you running it at all?
And that's the thing. Depending on what I ask you to do there are places where your not going to say "let me put this in a container" ... Most of that is "good software" and "performant" ... Its a statement about everything that comes in that "container"
Even with a single file binary, there are still reasons to put it in a container. You could do some similar things (e.g. resource limits) messing with cgroups manually, but why? So much tooling has been built up around containers that not using them often means re-inventing things that are already done.
Of course, if you have one file (or many) that you run on one server and downtime is ok during updates then fine to just do everything manually. You could even keep the code on that server as well. ssh in, edit compile and run your production app directly from the out directory. Basically run production on your dev machine. It sounds pretty silly / "non professional", but there are times where ultra low cycle times outweigh other things (like when you have one developer and desperately trying to win your first customer - you know "do things that don't scale"). The main thing is, you need to know the trade-offs you are making.
If you need a container to be mutable for a while, you can. Mount an NFS volume and run from there.
You can even checkout your code, edit in vim and re-deploy. Crazy talk for production of course, but if you need it, it is possible. Basically it is not that far off from running a binary on a server if you need it to be.
In the far future, technology is so advanced that "rituals" are invented to "appease the machine spirits." No one knows how it works anymore, and everything must support an immense galactic, perpetual war effort.
> ... "discovered" that troubleshooting Kubernetes was a bit like Warhammer 40k Adeptus Mechanicus waving incense in front of machines they didn't understand in the hopes that it would make the problem go away.
I'm so glad you quoted that because I missed it skimming the article and it's the funniest shit I've ever heard.
My hope is that declarative distros, who are a practical implementation in software of the "Datacenter as a Computer" by "ancient" Google, like NixOS or Guix System became widespread and the NixOps/Morth/Disnix model can evolve in a more structured and stable solution pushing classic distros from the late 80s to the graveyard alongside with "the product of devops" witch are not CI/CD but paravirtualization for anything pushing docker/k*s and so on as a less absurd full-stack-virtualisation just to keep ignorant able to deploy proprietary stuff knowing the outcome is Serverless http://evrl.com/devops/cloud/2020/12/18/serverless.html or the modern mainframe named cloud.
So much of DevOps is being folded back into traditional roles now that the tooling has stabilized, and people are becoming disillusioned with the build, test, deploy loop.
It doesn't scale very well: the larger the codebase/team, the more burden on each individual to make this work.
What job title will DevOps roles shift to? Will it be "platform engineering" as some in this thread suggest, or will it be the traditional title of SRE?
I still don’t really know what DevOps is. I have noticed, however, that over the last 20 years more and more power and flexibility has been taken away from me.
I used to have passwords for everything and could deploy things and get things done on a dime, now there are layers of bureaucracy and middle fingers everywhere I turn.
Who knows! Just like “SRE” you really need to know what questions to ask before you accept any position in these orgs
I briefly worked at a place where the SREs were responsible for replacing displays on the factory floor and the devops engineers took rotations approving terraform PRs all day long.
As it turns out, a lot of orgs just rebrand their job postings with whatever fancy industry term gets applicants, then they rugpull you into very mundane ops chores
DevOps, in my experience, has often been unfortunately misused to mean "no ops": developers are doing operations, and there is no dedicated ops staff. For some engineers, this works. For others, they are out of their element and it leads to outages and chaos.
That’s compliance, infosec, and arguably, just table stakes for a reasonably mature org. Sure it’s annoying sometimes but unless you enjoy the idea of randos with access to your own complete digital footprint, then everyone ought to see the wisdom in the idea of “robots only, no humans in prod”
Yeah I agree, it's unfortunate that security compliance is often just making things as hard as possible in most organizations. Often times devops get to be the face of that and trust me.. they sure as hell don't want to have to hold hands even more.
People who understand and can articulate enduring principles without going mad in a sea of bad ideas will perpetually increase their own value in an organization. Thank you for this article. I don't share so much of the cynical view of leadership intent, but I can understand it.
The funny thing is, when ZIRP ended, people realized that the original dev / ops separation was actually better & regressed back to it with an armada of new tools and acronyms.
Am I correct in understanding that microservices and DevOps are closely related - in that microservices trade code base complexity for operations complexity?
I would say they are both the fruit of the "ownership tree".
Both are solutions to big but specific problems.
(DevOps was a push against crazy corporate IT, where developers handed over the sacred tomes of operational manual and the blessed JAR/WAR files and IT took over from there. And operations was on-call, and ... had absolutely zero fucking idea what to do, the manuals were fake, and they had no expertise, and the whole handover was just burning money, etc. So dev teams got access, and things got a bit more programmatic anyway as scale kept growing. From the early days of Capistrano and Puppet to immutable images running on EC2 and nowadays to CI/CD with containers running wherever.
Microservies was kind of an organic step from that. Both to handle resource scaling and mostly to handle product/project coordination. Extremely limited scopes helps local reasoning to make okayish decisions most of the time.
See also Rust's ergonomics principles about "reasoning footprint" and the Bounded Context concept from DDD.
Of course the trick is that, it looks easy when someone gives a talk at a conference showcasing their company's a-ma-zing whiteboard-to-yet-another-webservice tempo, but it needs well-funded, good-faith constructive/supportive security and platform teams. And in practice it's famously hard to keep these complex interconnected systems/projects/orgs on track. And even when you have that many companies then try to force things [the good old hammer-nail anti-pattern] https://www.youtube.com/watch?v=PAew2jhr2zs )
"And operations was on-call, and ... had absolutely zero fucking idea what to do, the manuals were fake, and they had no expertise, and the whole handover was just burning money, etc."
This is what is we with DevOps now. The short lived dev teams had it over to the next dev team with basically no documentation. DevOps was just another stop on the shitty process parade that Agile contributed to - all about speed, forget docs, who has time for real tests, and for requirements we'll just use JIRA tickets the devs work on.
Surprise, surprise... Our bug and rework stories take about 25% of our capacity now.
DevOps predated microservices by a good bit. And DevOps was meant to reduce operational complexity, because the people who best knew how to run the software were the ones who made it. (DevOps also predated commoditization of the infra layer, we didn't know about Docker or k8s yet.) And they could use the direct experiential feedback loop of driving the car they had built to plow understanding right back into the next iteration. Or ideally anyway.
Most institutions failed to understand that devops is a practice of silo busting, not a team or a job title. The most devopsy thing you can do is treat IT service development and ownership like a product instead of a project. All you really have to do, though, is sit the developers next to the ops folks and let the law of proximate communication do the rest.
Institutions and institutional corporations generally can’t make the switch in mindset to multidisciplinary service teams, and established project managers will even fight it tooth and nail since it looks like a threat to their jobs.
Microservices are orthogonal. Architecturally they are just SOA, now with json/grpc instead of wsdl et al. Operationally and strategically they are slightly a better fit for service teams, but only at scale. Small and medium enterprises will experience inefficiency instead.
Conway’s Law is super applicable to understanding these dynamics.
Yes but in the end there was corporate capture and so that resulted in engineering teams like: dev teams create the SW but has no right, DevOps team that has no idea about what is doing the software or how to do dev btw but they have all the production rights...
I think the methodology contributed to the culture shift, or vice versa. Things like documentation and requirement capture have gone to absolute shit over the last decade at my company. You couldnhave good documentation under either model, but I feel like the shift to microservices was about speed for many companies, so they cut docs along with the shift.
Having watched the infrastructure side of things evolve from the late 90s/early 2000s, where every HP/IBM rackmount was a snowflake, configuration and releases were hand rolled and debugging server / OS / package dependency issues (not to mention scaling and managing load balancers) were exclusively manual to where we are today with Kubernetes, I would select Kube all day everyday. A consistent and now very stable substrate and API I can expect pretty much everywhere, which handles rollouts, resources, health checking/auto healing and scaling for me, and pretty much lets me sleep while infra is failing? Good luck debugging that hand rolled bash script to pull a container after whoever wrote it has left (and good luck scaling it).
I'll start by saying that I think knowledge for knowing layers underneath the application is fading in some circles, and that makes me sad.
Having been a frontend guy some 10+ years ago, into a network engineer, then infrastructure engineering and now SRE. The amount of people on both sides of the developer circle and operations circle that do not want to understand what's going on is mind boggling.
I was around when VMs were hot, when treating them as long living pets was just toil that operations dealt with. The collection of shell scripts to make that toil go away was nice. Then puppet, ansible and the like.
Now we are in the golden ages of Kubernetes and orchestration platforms. We have a set of standards for how things can be operated. The terms are obfuscated sure, but the core concepts are still the same underneath the abstraction.
I agree that platform engineering is a good place to be, and honestly it needs to be understood more by all parties including executives. They were bought and sold cloud on the idea that it's all managed, but that cannot be further from the truth, wrinkles will show as scale grows and your use cases progress in any environment, at home or in the cloud.
Unfortunately good platform teams often aren't seen. A good platform just works, metrics just exist, logs just work, tracing just works out of the box. Things don't often go down. It's really only visible when things fail. If you do a great job implementing a self service platform you're often met with executives wondering why you're there because the cloud does it all!
Applications are highly visible to all, but so are the layers underneath and they all work together if done correctly, I wish that was more understood.
For context, I'm currently running multiple environments of Kubernetes, on premise and in cloud. Our team prides itself on using open source solutions utilizing the operator model. Prometheus, Thanos, Loki, Tempo, Istio, Cert-Manager, Strimzi Kafka, Flink operator, Otel collector etc. We do billions of requests a month and TBs of bandwidth with microservices. Have at a minimum 4 9's of uptime, and our cost footprint is extremely small. This comes from a 4 man platform team that also handles on call for all applications, security, cloud budget, and operations. It's not impossible.
I guess I can't emphasize enough that understanding what the orchestration systems, the tooling and the stack are trying to do makes everything easier. As a developer you can understand your constraints and limitations. You can build off of known barriers. As an operations or platform engineer you can build things that don't require constant babysitting or toil.. you can save hundreds of thousands of dollars not offloading your observability to data dog or the like, you can make an impact. The technology is already here.
I'm interested in knowing more about how you guys implemented the operator model and decided on those tools. Was there a book or anything that was helpful in all of this?
> small and medium organizations abandon technology like Kubernetes
K8s is a complex tech that requires multidisciplinary experience that small and medium orgs cannot afford. Even if they could, there simply is not enough talent to hire. My own experience shows that k8s makes developers less productive, because running a heavy stack locally is not exactly conducive to fast development cycles. I don't feel empowered, I feel abandoned and left dealing with a steaming pile of shite that used to be the responsibility of a DBA, Ops, and security. Unfortunately, the trend for hiring "full stack developers" who can do frontend, backend, infra, and DBA aka. "I want a whole team for the price of a junior dev" is not going away.
This was a bit of a straw man argument against DevOps and normal CI/CD that describes as only safety net the PR review and forgets about automated (unit, integration and end-to-end) testing and other de-risking activities like canary releases (funny enough, this is what Facebook heavily relies on so devs can push to prod on their first day).
This guy and the person that quit the bullshit industrial complex 6 months ago should get together and launch a startup.
Better yet, we should all go and join Jeremy Howard's answer.ai pro bono. Besides being miraculously headed by a guy who is Not An Asshole, it incidentally also had the most refreshing launch post (in the warm and fuzzy way) this side of the AI bubble.
The launch post concluded with this heading:We Don’t Really Know What We’re Doing.[0]
I mean, for the finest minds in our respective fields, what else is there left to say really?
> Now servers were effectively dumb boxes running containers, either on their own with Docker compose or as part of a fleet with Kubernetes/ECS/App Engine/Nomad/whatever new thing that has been invented in the last two weeks.
No joke, containers are amazing, regardless of how quickly you try to move or how often you need to deploy.
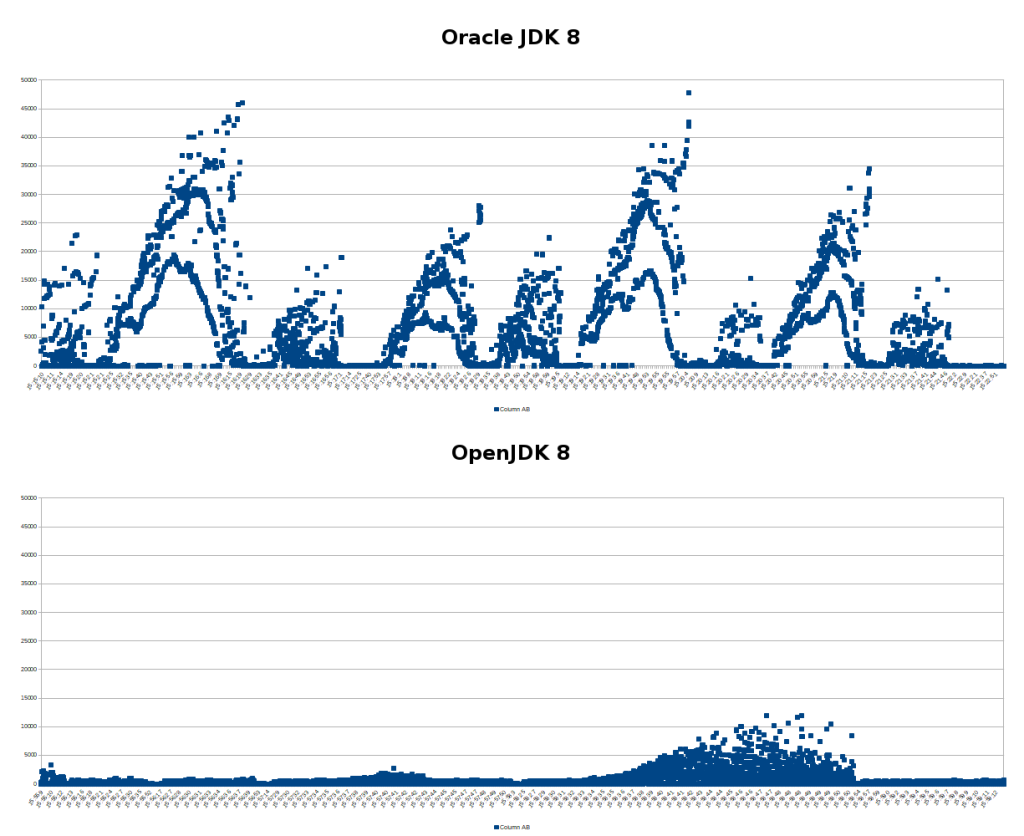
I remember a project where the performance turned out to be horrible because someone was running Oracle JDK 8 instead of OpenJDK 8 and that was enough to result in a huge discrepancy, here's an example of the request processing times during load tests: https://blog.kronis.dev/images/j/d/k/-/t/jdk-testing-compari...
That would have been solved by Ansible or something like it, of course, but containers get rid of that risk altogether, since you need to package the JDK your app needs (and that it will be tested on).
With a bit of work, using containers can be quite consistent and manageable - have Ansible or something similar set up your nodes that will run the containers, run a Docker Swarm, Hashicorp Nomad or Kubernetes cluster (K3s is great) that's more or less vanilla, something like Portainer or Rancher for easier management, Skywalking or one of those OpenTelemetry solutions for tracing and observability, throw in some uptime monitoring tools like Uptime Kuma, maybe even something like Zabbix or a more modern alternative for node monitoring and alerting and you're set. Anything that's self-hostable and doesn't tie you up with restrictive licenses (this also applies to using PostgreSQL or MariaDB instead of something like Oracle, if you can).
You don't need to have every team branch out into completely different tools because those are the new hotness, you don't need to run everything on PaaS/SaaS platforms when IaaS is enough, realistically most of what you need can be stored in a Git repo that will contain a pretty clear history of why things have been changed and even some Wiki pages and/or ADRs that explain how you've gotten here.
The situations in the article feel very much like corporate not caring and teams not talking to one another and having no coordination, or growing to a scale where direct communication no longer works yet not having anything in place to address that. If you're at that point, you should be able to throw money and human-years of work at the problem until it disappears, provided that people who hold the bag actually care.
For what it's worth, regardless of the tech you use or the scale you're at, you can still have someone in charge of the platform (or a team, where applicable), you can still have a DBA or a sysadmin, if you recognize their skills as important and needed.
{kind=link}
It really cuts to the heart of it when you looking at the “devops cycle” diagram with “build, test, deploy” …and yeah, those other ones…
I remember being in a meeting where our engineering lead was explaining our “devops transformation strategy”.
From memory that diagram turned up in the slides with a circle on “deploy”; the operational goal was “deploy multiple times a day”.
It was about speed at any cost, not about engineering excellence.
Fired the ops team. Restructured QA. You build it you run it”. Every team has an on call roster now. Sec dev ml ops; you’re an expert at everything right?
The funny thing is you can take a mostly working stable system and make fast thoughtless chaotic changes to it for short term gains; so it superficially looks like it’s effective for a while.
…but, surrrrpriiiisssseeee a few months later and suddenly you can’t make any changes without breaking things, no one knows what’s going on.
I’m left with such mixed feelings; at the end of the day the tooling we got out of devops was really valuable.
…but it was certainly a frustrating and expensive way to get there.
We have new developers now who don’t know what devops is, but they know what containers are and expect to be able to deploy to production any time.
I guess that’s a good way for devops to quietly wind up and go away.