I build a zfs based NAS last year[1], after 10 months of usage, I have nothing but positive things to say. One thing I didn't understand conceptually at first is that ZFS is standalone and not dependent on the host OS. This was not clear to me and it is not explained anywhere. You can wipe out the entire OS, move the drives to a new system, mount them on a new OS and run `zpool import` to import them. All the information (raid config, snapshots, etc) about ZFS is stored on the pool itself and not on the host OS, especially if you have an alias setup for invidivual drives in `/etc/zfs/vdev_id.conf`.
There is no need for FreeNAS or any of that stuff, I don't use all those features. Just run like 3 commands to create a zpool, install samba service and that's all I need from a NAS. Cron job to run a scrub every month.
If ZFS file system made a sound, it'd make a satisfying and reassuring "CLUNK!" sound.
I've been a ZFS user for maybe 6 years. I had data loss this year.
It was quite interesting. Writes would fail on multiple disks at the same time. That's why it was data loss. A normal disk failure wouldn't look like that, failures should be spread out and redundancy would help.
It turned out to be a bad power supply. I was able to predictably get it to corrupt writes with the old PSU. Then I replaced the PSU. No longer failed after that.
I wouldn't have guessed to suspect the PSU. It was a frustrating experience but in the end, ZFS did help me detect it. On ext4 or ffs I wouldn't have even been aware it happened, let alone could confirm a fix.
Jesus same happened to me so frustrating! Everything working ok, then slowly increase of writing failures and power resets, and strange clicking, eventually all disks drop, scary every time it happened
I swapped every server part before the PSU. Updated Linux, downgraded, tried kernel options... At some point I thought btrfs was the problem so I created an mdadm ext4 raid but got the same problem
It was a btrfs raid 1, lots of fs errors, and files missing until restart, as some disks were down. But didn't lost any data (take that ZFS!) besides the one being transferred as the disks/array went down anyway
A bad PSU is not at all comparable to a hard reset. A bad PSU can cause individual writes to fail without the entire computer shutting down, and these failures can and will happen simultaneously across multiple disks since they are all connected to the same faulty PSU. If a filesystem wanted to guard against this kind of failure, I suppose it could theoretically stagger the individual disk write operations for a given RAID stripe so they don't happen simultaneously. (Implementation is left as an exercise to the reader.)
I don't mean to be critical of you, restic, or your backup strategies, but it doesn't seem like you know. ZFS is the I really need to know filesystem. I think it's pretty great and I use it where I can. But if it's not for you, it's not for you.
And FYI, an power supply failure does not manifest the same as a power outage.
As mentioned, it was not usually manifesting as power outage. Random components would fail. Presumably because the PSU was able to keep the system nominally "running" but not delivering the right power to components.
I also experienced some random reboots, things that also looked to me like bad memory... I suspected bad memory at some point. But swapping the PSU did the trick.
Yep, designing around the write hole is hard, especially with non-enterprise equipment. Lots of firmware does unsafe things with cached data and will tell you data has hit disks that has not. The file system can't really do anything about this either, other than tell you after the fact that the data that should be there isn't (which ZFS is very good for).
You can disable write caches for safety, but note that this is very hard on performance.
I was a little imprecise on my words. It would lose recent writes seemingly randomly, and reading those back would fail. It seemed that caches could mask this for a while.
POSIX systems are pretty lax with this sort of failure. write(2) and close(2) can succeed if you write to cache. If the actual write failure occurs later there is typically no way to let your process know.
What did that look like in terms of error messages etc? I'm guessing ZFS would try to write the checksum, which wouldn't work and then throw an error? I assume it never impacted data that already resided on disk?
zpool status showed an identical number of checksum failures across drives, and status -v would list certain files as corrupt. Reads on those files would return EIO. It was always recently written files.
A large file copy would predictably trigger it. Other times it was random.
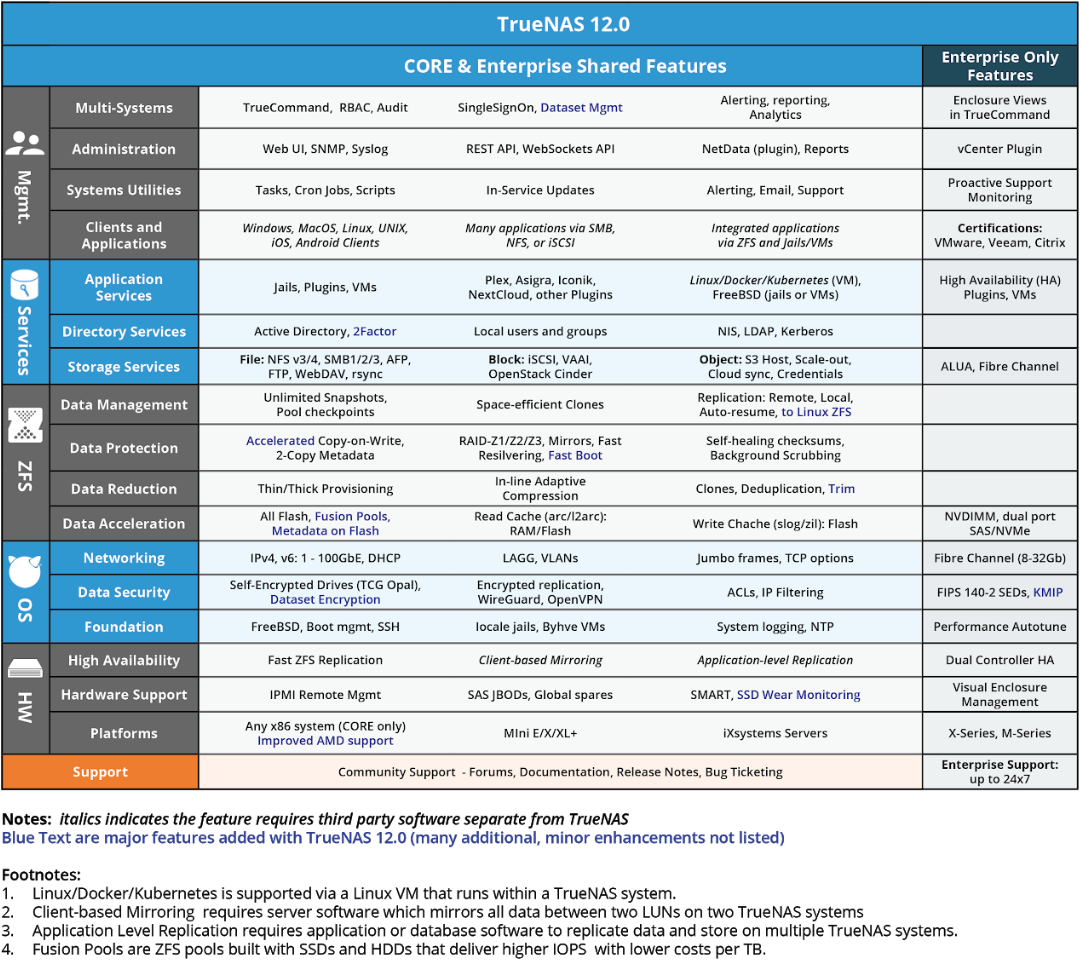
TrueNAS ensures that different versions of different software fit together. So you update your OS, and your setup doesn’t break.
The common tasks are made easy: snapshot scheduling, snapshot replication, Samba share with a few clicks, backup to cloud, users management, one click install of applications, SMART tests, etc. Config management can be a headache.
As GP said, all these features are nice, but if you don't need them, they're just overhead.
I'm in the same boat, all I have on my NAS is Samba, zrepl (ZFS snapshots and backups) and node exporter (monitoring agent for Prometheus - handles SMART, etc). It's running Arch, and I've never had my setup "break" in more than 10 years of using this distro (though this particular NAS is not that old).
I don't care for a DB, web server and god forbid random applications doing who knows what on my NAS. But if you want your NAS to do everything, it should be great. To each their own, I guess.
Also, TrueNAS is FreeBSD which may or may not work on dinkier hardware. I'm specifically thinking of random watchdog problems on some older Realtek Gigabit NICs, where you had to use a specific patched driver which, at one point, didn't support the latest version.
Plus the setup now gets intricately coupled with the host OS. That's a big no for me. I want to treat the host OS as disposable, ephemeral and decoupled for peace of mind. The host's only job is to serve files over samba protocol and run scrub cronjobs. That's it. It gets 2 vCPUs and 24GB of ram. Stays put.
That's basically how SmartOS does it, as long as you're doing SMB or Samba. And boy, is it ephemeral: the entire OS is loaded into RAM from a USB stick (usually) on boot, and everything gets loaded from the zpool, as OC said, and if you need anything, you put it in a zone. Even VM hypervisor goes in a zone, because it's essentially free and gives you nice clean separation (and quotas, reservations, etc.).
Though NFS can only be shared from the global zone, so if you need NFS you don't get to play with zones.
> the whole thing should be marketed more like "Proxmox with batteries included".
It's not though. Even if you make all the "NAS software" part of the jails (or the half-baked Kubernetes in TrueNAS SCALE), it's not even close to Proxmox when it comes to managing VMs, containers/jails, firewall, networking, etc.
I use zfs-auto-snapshot for snapshots, it works great. I think the only thing I would want is early warning for a disk failure. I'll probably automate that. TrueNAS feels extremely heavy with too many features I don't need. There is a web server, database, etc which feels overkill for a simple home NAS IMO and having to manage the management system.
>One thing I didn't understand conceptually at first is that ZFS is standalone and not dependent on the host OS.
This is true for every mature/production file system. You can do the same with mdadm, ext4, xfs, btrfs, etc. The only constraint would be with versions in that it would be a one way street. Can't necessarily go from something new to something old, but other way round is fine.
My one complaint about ZFS is that I'd repeatedly googled for "what's the procedure if your motherboard dies and you need to migrate your disks to a new machine?" since that's super-easy with single non-ZFS disks but I was worried how ZFS mirrored pools would handle it, especially since the setup was so fiddly and (compared to other filesystems I've used) highy non-standard (with good reason, I'm sure).
And yet, this thread right here has more and better info than my searches ever turned up, which were mostly reddit and stackoverflow posts and such that somehow managed never to answer the question or had bad answers.
The one complaint is that I found that to be true for almost everything with ZFS. You can read the manual and figure out which sequence of commands you need eventually, but "I want to do this thing that has to be extremely common, what's the usually procedure, considering that ZFS operations are often multi-stage and things can go very badly if you mess it up?" is weirdly hard to find reliable, accurate, and complete info on with a search.
The result was that I was and am afraid to touch ZFS now that I have it working and dread having to track down info because it's always a pain, but I also don't really want to become a ZFS wizard by deeply-reading all the docs just so I can do some extremely basic things (mirror, expand pools with new drives, replace bad mirrored disks, move the disks to a new machine if this one breaks... that's about it beyond "create the fs and mount it") with it on one machine at home.
The initial setup reminded me of Git, In a bad way. "You want to do this thing that almost every single person using this needs to do? Run these eight commands, zero of which look like they do the thing you want, in exactly this order".
I'm happy with ZFS but dread needing to modify its config.
As someone who is a total ZFS fan, I think the `zfs` and `zpool` commands are some of the best CLI commands ever made. Just immaculate. So this comment was a head scratcher for me.
> I also don't really want to become a ZFS wizard
Admittedly, ZFS on Linux may require some additional work simply because its not an upstream filesystem, but, once you're over that hump, ZFS feels like it lowers the mental burden of what to do with my filesystems?
I think the issue may be ZFS has some inherent new complexity that certain other filesystems don't have? But I'm not sure we can expect a paradigm shifting filesystem to work exactly like we've been used to, especially when it was originally developed on a different platform? It kinda sounds like you weren't used to a filesystem that does all these things? And may not have wanted any additional complexity?
And, I'd say, that happens to everyone? For example, I wanted to port an app I wrote for ZFS to btrfs[0]. At the time, it felt like such an unholy pain. With some distance, I see it was just a different way of doing things. Very few btrfs decisions with which I had intimate experience, do I now look back on and say "That's just goofy!" It's more -- that's not the choice I would have made, in light of ZFS, etc., but it's not an absurd choice?
> "what's the procedure if your motherboard dies and you need to migrate your disks to a new machine?"
If you're setup is anything like mine, I'm pretty certain you can just boot the root pool? Linux will take care of the rest? The reason you may not find an answer is because the answer is pretty similar to other filesystems?
If you have problems, rescue via a live CD[1]. Rescuing a ZFS root pool that won't boot is no joke sysadmin work (redirect all the zpool mounts, mount --bind all the other junk, and create a chroot env, do more magic...). For people, perhaps like you, that don't want the hassle, maybe it is easier elsewhere? But -- good luck!
IDK. I'm an ex-longtime-Gentoo user and have been known to do some moderately-wizardy things with Linux, and git for that matter, and in the server space I have seen some shit, but I managed to accidentally erase my personal-file-server zfs disks a couple times while setting them up. I've since expanded the mirrored pool once and consider it a miracle I didn't wipe out the whole thing, edge of my seat the whole time.
Haha... yeah, I didn't intend that as a brag or badge of honor or anything—more like a badge of idiocy—but you don't play Human Install Script and a-package-upgrade-broke-my-whole-system troubleshooter for several years without learning how things fit together and getting pretty comfortable with system config a level or two below what a lot of Linux users ever dig into. Just meant I'm a little past "complete newbie" so that's not the trouble. :-)
> In the future, you may want to try creating a sandbox for yourself to try things? I did all my testing of my app re: btrfs with zvols similarly:
Really good advice, thanks. I was aware it had substantial capabilities to work in this manner, but using it this way hadn't occurred to me. Gotta get over being stuck in "filesystems operate on disks or partitions on disks that are recorded in such a way that any tools and filesystem, not just a particular one, can understand and work with" mode. I mean I'm comfortable enough with files as virtual disks, but having a specific FS tools, rather than a set of general tools, transparently manage those for me, too, seems... spooky and data-lossy. Which I know it isn't, but it makes the hair on my neck stand up anyway. Maybe my "lock-in" warning sensors are tuned too sensitive.
Now to figure out how to run those commands as a user that doesn't have the ability to destroy any of the real pools... ideally without having to make a whole VM for it, or set up ZFS on a second machine, and—initial search results suggest this may be a problem, for the specific case of want unprivileged users to run zfs-create without granting them too much access—on Linux, not FreeBSD :-/
Yeah I get your feeling. I had it similarly at first, dreading to make changes because I was afraid I'd mess up.
And to be fair, I think ZFS could be better in this regard. Some commands can put your pool into a very sub-optimal state, and ZFS doesn't warn about this when you enter those commands. Heck even the destroy pool command doesn't flinch if by chance nothing is mounted (which it may well be after recovery on a new system).
I found it helped to watch some of the videos from the OpenZFS conferences that explains the history of ZFS and how the architecture works, like the OpenZFS basics[1] one.
But I agree that the documentation[2] could have a lot more introductory material, to help those who aren't familiar with it.
That said, I echo the suggestion to try it out using file vdev's. For larger changes I do spin up a VM just to make sure. For example, it's possible to mess up replacing a disk by adding new disk as a new single vdev rather than replacing the failing one one, so if I feel unsure about it I take 15 minutes in a VM and write down the steps.
Again, this is something I feel they could improve. Adding a single-disk vdev to a mirrored or raid'ed pool should come with a warning requiring confirmation.
On the bright side, I've been running my pool since 2009, and have never lost data despite a few disk failures and countless unexpected power-outages without PSU. And I just run it on consumer hardware without ECC because that's what I got. Been up to 8 disks, now down to 6 and will soon go down to 4 once the new disks arrive. Send/recive ensures the data is just as it ever was on the new configuration.
Right, what was not clear to me was that raid configuration and snapshots are also part of the file system. Usually, that's done through hardware cards or software raid where the configuration sits not on the file system (?) (Intel VROC, vSAN, etc), at least that was my wrong conceptual model. I used to make multiple copies of the USB stick of FreeNAS 8 back in the day because I didn't want the USB drive to fail and not knowing how to recover the zpool. Messing around with the file system directly cleared up everything.
That's more common for Linux storage. Whether you're using zfs, btrfs, or lvm, all the configuration required to read it is stored in the header somewhere rather than in a detached configuration.
It has to be stored out of the band, otherwise you would have chicken-and-egg problem: what's the shape of the array, when the info is in a file stored inside the array?
It's not stored in a file inside the array of course, but there are two types of out of band: next to the data, or completely disconnected. For example you only need to mount a single btrfs partition - in the header it already contains the information about other copies and will mount the whole raid setup as necessary. It doesn't matter if you move the drives somewhere else to a new system - mount one of them and it works.
On the other hand, if you move drives from a hardware raid and put in new drives, some (all?) controllers will read the raid config from memory and offer to build the same raid on the new drives. That's completely-out-of-band. Depending on the controller, even changing the order the disks are plugged in can give you weird results.
The OS needs to implement zfs, like any other filesystem/host combination. Any filesystem can be "moved" to another host simply by attaching the drives, assuming you have hardware level compat and filesystem level compat.
OK the exception is when you have host-based hardware level encryption (ie, key in TPM or other security chip). In that case, zfs and otherwise, you can't just move the drives.
Oh, it's better than that! If you're crazy enough, you can even multiboot multiple OSs on the same pool:) You do need to ensure that the pool features are sufficiently compatible between ZFS drivers (ex. you can't create a fully-featured pool with OpenZFS 2.1.6 on Linux and import it on OpenIndiana, last I checked), but it does work, empirically;)
A friend of mine suggested this and I didn't like the idea of putting the OS on there especially that it is a virtual machine. There are a couple of things that made this setup nice though: PCIe bifurcation (4x4x4x4) lanes straight to the CPU and PCIe passthrough in ESXi. From what I read that ZFS needs direct access to the underlying hardware. So, I just treat the OS as totally disposable and not worth backing up. I can spin up a VM in less than 2 mins if something were to happen to it.
Anyone using ZFS on a daily-driver desktop computer?
Fedora + BTRFS + Deja dup daily backups have been my default for months now, but I am tempted to give it a go to perhaps Ubuntu JJ + ZFS + Deja dup. Not that I have any issues with my current setup. It's just for the sake of, you know, try new things.
I've used ZFS on my daily desktop computer for almost 3 years. I'm using it with ArchLinux. The overall experience is great but here are some notes:
* The cpu usage can be higher if you use compression.
* I used to setup the main pool with SSD cache with HDD data store. It's okay for most use case except slow first time open of applications. But for demanding games it usually has very bad performance.
* ZFS also manage cache by itself so it needs some memory. Personally I'd like to set a cap for it, because otherwise when I open some memory hungry program it tries to write cache onto disk which sometimes makes the system slow. This happens when I only use SSD as cache. Not sure if it can be better with all SSD solution.
* I ran into problem with docker as well. But after change some configurations it works perfectly.
I have been using ZFS on my daily-driver Ubuntu laptop for six months or so. Also been using ZFS as the backing store for a heavy update postgres database for a few years before that. Haven't had any issues with it at all, generally it seems like a very solid bit of software.
I'm not familiar with Deja dup, but the usual method of backing up a ZFS filesystem is to snapshot it and then stream the snapshot (just a file, can be compressed) into the remote store of your choice.
Streaming ZFS snapshots to a file and storing that in a remote of your choice is not the usual way of backing up ZFS data at all (it’s actually recommended against).
The usual way is ZFS send and receive to another ZFS server. But almost no cloud storage provider supports that, other than rsync.net (and zfs.rent), which starts with $60/month. So you have to set up and manage another ZFS server with secure remote access, PIA if you ask me.
It seems to work well. Am I carrying some unrecognised risk that I wouldn't be carrying if I were backing up into another ZFS filesystem? How does that risk balance against the risk of data loss on the backup server? i.e. I am pretty sure GCS won't lose my data, but not quite so sure about the other services you mention.
If your monolithic backup suffers single a bit error, it's unrecoverable. If you zfs recv, though, you can recover all pristine files. And if you zfs recv to a redundant filesystem (mirror, RAID-Z), you can periodically zfs scrub and recover from those errors completely.
I've been running ZFS continually since about 2009, currently using its replication as a major part of the disaster recovery strategy for my employer, and in the intervening time having been through a number of disk failures, controller failures, etc.
Just chiming in here to say that I endorse every aspect of the answer that 7e has given you.
Have you restored any data using this system? A backup isn't a backup unless you've practiced a whole cycle.
Snapshots are incremental, so management of your retention period is an active process and may require combining older snapshots together when you drop them.
With a zfs server on the other end you can zfs send / recv the other way to restore, and it correctly manages deleted snapshots.
They are but, unless the -i flag is specified (it isn't in my example above) then zfs send will send a complete replication stream, not an incremental.
ZFS receive checks the stream to ensure correctness. The stream can be easily corrupted, due to even a single error, if ZFS send is used without ZFS receive.
The error occurs in transit or on client side, not necessarily on remote.
Also managing a chain of incrementals can get unwieldy.
Thank you for answering! Deja dup it's just a GUI over duplicity (https://en.wikipedia.org/wiki/Duplicity_(software)). It allows me to have encryption, differential backups and restoring files in a granular way (even from Gnome context menu) with no effort. Very pleasant experience similar to Time machine in MacOS. Anyways, I'll definitely give it a go to ZFS.
using it on my notebook with native encryption and I'm quite happy - there are some things missing / work in progress for quite a while - unfortunately it looks like it's not a priority at the moment for the current sponsors or there is a lack of time - not a criticism of zfs but I'd love to see these features merged sometimes in the future:
- no overlayfs yet (https://github.com/openzfs/zfs/pull/9414) - the docker zfs driver is very slow and buggy - best to create a sparse zvol with ext4/xfs/btrfs and use this for /var/lib/docker
- async dmu (https://github.com/openzfs/zfs/pull/12166) - complicated patchset would transform a lot of operations into callbacks and probably increase performance for a lot of workloads.
- namespace delegation was recently merged: https://github.com/openzfs/zfs/commit/4ed5e25074ffec266df385... with idmapped mounts it should be possible to have zfs datasets / snapshots inside a unprivileged lxc-container which could be super cool for lightweight container things.
caveats:
- no swap on zvol at the moment (https://github.com/openzfs/zfs/issues/7734) - this is some hairy memory allocation problem beneath it and I don't really use swap - just something to be aware off.
That's great. I had a conversation with the owner of rsync.net about why they require zfs-enabled customers run on a separate bhyve VM (thus requiring a large minimum). Iirc it boils down to zfs destroy permissions somehow affecting other tenants. I see mention of zfs destroy in the linked patch, I'm curious how that relates to rsync's experience and requirements.
I'm using ZFS on my desktop (Arch Linux). 1 'Pool' is just an SSD that my OS root drive. (Booting off ZFS is a bit harder but putting /boot on your ESP works).
And a hard disk array with 4 drives in raidz (like raid 5).
Main advantages:
* I moved my root drive to another drive and did it entirely online without needing to cp or dd everything just add new drive to pool, remove old drive (and wait until it's done, but you can keep using it while it copies)
* It's way faster than MD, md spends 10s of hours initializing or resilivering big drives. zfs just formats it and your good to go.
* Subvolumes and snapshops are great. You can give a folder different file system properties. (Eg make /var/log compressed and disable it for /var/cache/pacman because it's already compressed)
* Docker is quicker.
* Although BTRFS has snapshots I do find ZFS's more intuitive. (eg subvolume can be nomount in ZFS which allows you to organize and apply options recursively easier)
Check for bugs in Ubuntu ZFS before installing updating. They do it differently than other OpenZFS options.
I'm not currently using ZFS send for backups. So I can't compare it to Deja dup.
Yes, I have Arch on a ZFS root pool. rEFInd + ZFSBootMenu to boot it.
The only thing I don't use ZFS for is a Windows (gaming) VM. I tried numerous different setups to keep the NTFS disk image on a zpool, but it's ultimately pretty hard to beat the performance of PCIe passthrough for a modern NVMe drive. I use syncoid/sanoid + ZFS delegations for backup management.
No real complaints except that it complicates updating Arch: kernel updates usually have to be delayed 24-48 hours while the ZFS packages get rebuilt, or in some cases patched upstream. syncoid/sanoid also poses a problem because it relies on a few Perl packages from the AUR that are a pain to rebuild.
I know the Arch devs loathe people doing partial updates, but occasionally delaying a kernel update for the sake of ZFS has yet to bite me in the ass. I would strongly advise against DKMS, though. Use a binary module or build the package yourself. The majority of problems I had with Arch+ZFS boiled down to misuse of zfs-dkms.
Specifically zfs-dkms + the stable kernel package ("linux") can often be an issue because I have seen the kernel version updated by Arch without ZFS support for that version (obviously not something that the Arch kernel package maintainers should care about, but it's a bit inconvenient).
zfs-dkms + "linux-lts" (longterm kernel) seems to work better than zfs-dkms + linux (stable kernel) if you're intending to do frequent system updates - I've been running this on several machines for years with no issues.
Yes, I have been using it for the bulk storage part of my desktop for the last 7 years, in a 3-drive RAID-Z configuration. I don't think any of the drives in the pool are the originals, as they have been swapped out for larger models as and when they started showing errors, with a scrub happening once a month. I have OS, swap, /home, /var, /tmp and ZFS log on an NVME drive separate - the ZFS pool is only used for the large stuff.
Separately, at work I managed to persuade them to configure our two new servers with ZFS, each with 168 drives for a total (after RAID) of 1.5PB each. Works like a charm, and is quite happy to saturate a 10Gb ethernet connection when accessing from another server, with transparent compression turned on. I would not hesitate to recommend ZFS to anyone.
I would worry a little about going above 90% space usage. ZFS slows down fairly dramatically when it starts running out of contiguous space and there is no defragmentation tool.
On the other hand it's not that hard to export and re-import a ZFS file system from a workstation or laptop to defragment manually - it's harder to do that with a NAS with lots of drives when you don't have a second set of drives just hanging around.
I have been using ZFS as root FS since the first release of ZFS on Linux (2013) on all my machines (laptops, NAS, server) and I can't imagine going back.
Checksums if the mobile hardware is damaged, snapshots if you delete something in your daily driver, native encryption if laptop is stolen, backup of work data via ZFS send if you have a ZFS server, compression to use limited disk space in laptops, errors can be fixed with copies=2, etc.
ZFS still gives benefits with one disk. Ignoring the data integrity stuff (which is better with ZFS even if you have no ECC), you also get snapshotting, potentially boot environments, you can backup your data to another machine using zfs-send, you get native encryption (including encrypted backups for free), highly performant compression, and (depending on your system) a nice memory cache algorithm.
I have, for more than two years, and my remote backup has been an encrypted ZFS for a year and a half. [1]
The scripts in that post are a little outdated, so if you would like to see updated ones, contact me [2].
The end result is a setup that:
* Has parallel upload to saturate my slow upload connection.
* Allows resume with `make -j<cores>`
* Allows me to backup things that are only on my server, such as my Gitea instance [3], to my desktop, thus having my server and desktop serve as backups to each other.
* Allows me to delete snapshots older than a certain number of snapshots (set to 60).
* Has automatic loading and unloading of encryption keys, to reduce the exposure time. (However, I wish raw sends on encrypted datasets worked. But it is nice that I can load the keys and download individual files instead, which I've already had to do.)
Perhaps I should add an update post to [1]. If there's enough interest, I will.
Edit: I should make clear that my ZFS is only my home directory. I do not use it as a root or boot filesystem because it runs off of a mirror of hard drives, and my root/boot drive is an SSD and can be destroyed without pain because all of my configs are in a repo in my home directory. Thus, it would be trivial to rebuild my system.
I installed Ubuntu 20.04 with ZFS for the root and user storage, with ZFS encryption, and frankly found the performance to be annoying. Keep in mind: I'm a huge ZFS fan. One of the packages I had installed, I forget which, made basically all apt sessions take much, much longer because of snapshotting, and my system load was basically always 1-3. I ended up reinstalling with ext4+LUKS when 22.04 came out. This is on a Dell XPS 15 with i7-10750H and 32GB RAM and "PC611 NVMe SK hynix 1TB" SSD.
It's a different layout of RAID, it's also not expandable vdev for now since it's made for enterprise. RAIDZ expansion is here https://github.com/openzfs/zfs/pull/12225
Anyone know if there is a way to install this on a Ubuntu 16.04 system? Would like to update from 0.8.4-1 but jonathonf hasn't build anything newer for this version of Ubuntu.
Wouldn't it better updating OS. I mean, I'm all for stability and if it's isolated no problem it not getting patches, but it if you're going in for kinda hackish updates to 16.04 kernels then maybe bumping to a later OS version might be better? You're already adding volatility and potential issues, but at least with a supported build it reduces the latter (and former really)
I think you can just download the source and build it as if Ubuntu didn't support ZFS. https://openzfs.github.io/openzfs-docs/Developer%20Resources... I haven't done this on Ubuntu, but I can attest that it works on Debian so unless Canonical did something "interesting" to break things it should Just Work™.
At the very least, you can do (and I have done) something similar with `apt source --build zfs-linux`. I wasn't terribly worth it for me (it takes some work?), but it's definitely possible/reasonable create backported native packages relatively easily.
I've had good results with this PPA for using later versions of ZFS on earlier Ubuntu versions (though it's only at zfs 2.1.5 at the moment, but it should be updated in not too long): https://launchpad.net/~jonathonf/+archive/ubuntu/zfs
You can install the Nix package manager on other Linuxes (or Mac) and use it to manage some packages. It keeps ZFS up to date and that may be an option for installing it on Ubuntu. I’ve never done this before so not sure, ask in the Nix community to verify.
I would suspect Nix wouldn't be the optimal way to manage Ubuntu kernel modules; I suppose you could use it to build them, but I don't think Nix without NixOS will e.g. configure DKMS for you.
ZFS needs to be kept in sync with the kernel version. If you use Nix on Ubuntu, Ubuntu manages the kernel, so Nix can’t do anything.
ZFS on NixOS is pretty neat though. The exact version pinning means that ZFS and the kernel can be updated together and only once both packages build at a new version.
There’s also an open issue for more extensive checks, so hopefully eventually NixOS CI will be able to check not just that the ZFS and kernel are compatible (header-wise), but actually go through the motion of creating test ZFS dataset and make sure it actually works.
Yeah makes sense. I use ZFS on NixOS and it mostly just works. Sometimes there's a lag of a few weeks between when the kernel gets a minor update but ZFS isn't yet updated to match, and rebuilding NixOS will fail during that time. Not a showstopper, just a temporary annoyance, but it sounds like that CI pull request will fix this.
Oh, strange I’ve never had issues with this. Do you use unstable? If so that might explain it.
I tend to use stable for everything then overlay the unstable/git master versions of the packages I need.
EDIT: Actually ignore me, of course stable won’t have problems because updates are held back….
I don’t think the CI thing will help. I think what’s happening here is a build time check that prevents any new kernel version with ZFS until the upstream announces support. I don’t think this check will be removed even if there was better CI.
Also, possibly your issues might go away if you used ‘config.boot.zfs.package.latestCompatibleLinuxPackages’ (from NixOS wiki for ZFS). I think that version is only updated once upstream announces support for a newer kernel.
Can someone explain what the relationship between openzfs and the zfs in opensolaris is? Are changes to openzfs backported to zfs in illumos or have they completely diverged? I think one thing that broke opensolaris' neck is, is how hard it is to set up a development environment compared to just building the linux kernel.
IIRC, OpenZFS is the ZFS in Illumos. It's just not the ZFS in Oracle's Solaris.
OpenZFS was created as a way to combine development of all the versions of ZFS across Linux, FreeBSD, Illumos, and others. If you're using a (fairly) recent Illumos, you're using OpenZFS.
Disclaimer: Not an OpenZFS developer; just a happy user.
Not exactly, take a look at the list of supported platforms in the releases notes of TFA -- OpenZFS 2 as a unified codebase is currently only ported to Linux and FreeBSD. Illumos is still using the older ZFS code with fewer features.
The whole history is pretty convoluted, since I'm fairly certain "OpenZFS" has been used to refer to several completely different source trees, with the Linux, FreeBSD, OS X, NetBSD, and Windows ports of ZFS all being separate forks off of the ZFS code from early OpenSolaris releases.
Despite the licensing drama and general distaste most distros and Linus have/had for ZoL, the Linux port had sort of become the de facto "standard" for ZFS development, with more work being done on that version of the source tree.
I only followed the "drama" from a distance, don't use ZFS or FreeBSD very frequently, but I know there was an internal discussion a while back within FreeBSD where they decided to pull commits directly from the ZoL tree instead of Illumos, because that tree was more active, and otherwise they had to wait on any improvements from Linux to be merged to the upstream Illumos tree.
The elephant in the room was the lack of activity in Illumos and the gradual decline of industry sponsors and development over the years. I don't know what the current state is, and I'm not saying Illumos is "dead", but it's definitely a shadow of its prime back when Joyent and a lot of companies were really pushing and developing on it. Several big names dropped out of Illumos development, including some NAS companies IIRC.
Anyway, OpenZFS 2, AFAIK, is essentially a rebranding of ZFS on Linux, but with CI/CD pipelines testing every commit against FreeBSD as well, basically unifying the work for Linux + FreeBSD.
The other versions (Mac, NetBSD, Windows, others?) still use separate forks AFAIK.
> Despite the licensing drama and general distaste most distros and Linus have/had for ZoL, the Linux port had sort of become the de facto "standard" for ZFS development, with more work being done on that version of the source tree.
This actually happened because of one feature: ZFS encryption. That feature was developed for ZoL first, and had to be ported to other platforms. The developer of the feature for ZoL did not want to write it for Illumos first and port it to Linux later.
The consequence of that is that the Linux port got its first significant feature the others didn't have, and there was no real assistance to bring it into the other platforms quickly. That led to a bit of a political mess where the fallout was the "new" OpenZFS codebase where Linux and FreeBSD are maintained in one tree.
Source: I observed the whole thing while working at the place that wrote ZFS encryption for ZoL.
It's very convoluted, and I probably got some details wrong, but that's the gist of what GP was probably thinking about.
Not sure what the Illumos guys ended up doing in response, either. My memory from browsing their mailing lists was they were pretty surprised by FreeBSD's decision, and didn't seem particularly happy about it, since Illumos/OpenSolaris is the "proper home" of ZFS, but...
I've been enjoying my experience with zfs this far. I just wish removal of vdevs was a thing for raidz setups. I could never fully understand why removing a full vdev that happens to implement raidz isn't as easy as removing a mirror one (which is supported). I suppose vdevs don't fully abstract the away the underlying mechanism.
There was some discussion about waiting for 6.0 in the pull request for 2.1.6, but they chose to ship this and instantly open a branch for 2.1.7 pull requests.
This concern doesn't make any sense. There are always new kernels on the horizon bydl definition, and there's nothing special about 6.0 at all. By this logic nothing should ever be released as it should always be waiting for the "on the horizon" kernel.
{kind=link}
There is no need for FreeNAS or any of that stuff, I don't use all those features. Just run like 3 commands to create a zpool, install samba service and that's all I need from a NAS. Cron job to run a scrub every month.
If ZFS file system made a sound, it'd make a satisfying and reassuring "CLUNK!" sound.
[1] https://neil.computer/notes/zfs-raidz2/