I was really excited to see these benchmarks until I realized:
1. The Ryzen setup has twice the ram
2. The Ryzen setup has twice the cpu cores
3. The Ryzen setup has 3x the power envelope (in watts) as the M2[1]
4. They are using Asahi Linux on the M2.[2]
Too bad I missed the window to downvote.
If this said: Apple M2 (Linux/8gb/4c) vs. Ryzen 7 Pro 6850U (Linux/16gb/8c)... it would have been more honest, and potentially interesting, as it would also be an indication of the progress of Asahi Linux.
(edited to add line breaks)
[1]: Ryzen 46w (not sure if this includes the GPU) vs M2 15w (not sure if this includes the GPU)
[2]: Asahi Linux is super cool, but most M2 chips in the wild are not running it. So it's not a useful comparison.
It all makes a lot more sense if you remember that this is Phoronix we're talking about. This is the rest of today's posts:
* Radeon ROCm 5.2.3 Released (...)
* Mesa 22.2-rc3 Released (...)
* [bootloader project] Updated With Improved SMBIOS Support
* GCC 12.2 Compiler Released With 70+ Bug Fixes
They're a Linux-centric outlet through and through, and the Phoronix Test Suite (the benchmark they're running) is Linux-based. Of course they're running the benchmarks on Linux, that's whole point!
As for the hardware, the Air is just the entry level model, and AFAICT the X13 they're using is roughly the same price as the Air. About as fair a comparison as you could make it. They also specifically call out the power thing:
> Due to the Apple M2 currently lacking any power/temperature sensor support under Linux, this is simply looking at the raw performance of the M2 and Ryzen 7 PRO 6850U with not being able to accurately compare the M2 power efficiency / performance-per-Watt at this time.
It's important to look at the context: Lenovo laptops have been a staple in the Linux world for a long time, and people in the Linux world are genuinely excited about the Apple Silicon laptops, hell even Linus is running Asahi. For the target audience, this comparison is exactly the benchmark they want.
> They also specifically call out the power thing:
saying "we can't measure the power on M2" isn't the same thing as pointing out that in broad terms the M2 is only using 1/3 of the power of the 6850U. These are really different power classes and yeah, you'd expect the processor with triple the power budget to pull ahead.
Triple isn't my number, but, Ryzen is allowed to boost extremely high during short tests like Phoronix is doing, where a MBA is always 15W max, period the end, even in max clock states.
This is just completely false. You have no idea what the actual max power consumption of an MBA is.
15W is it's TDP, and various companies release chips that run at triple their TDP - including repeated by Apple in the past. Saying it's never going to exceed it's TDP is just blatantly ridiculous, and Phoronix were completely right in treating it as a useless number (which it is).
The only reliable way to measure power draw is either to monitor the exact voltages and amperages on each power lane - which is not made available by Apple - or wire into the motherboard. Anything else is not serious, least of all taxing the TDP to its word.
I think you're overstating the issues here; and it's necessary to take what you can get in hard-to-do comparisons like this. There are caveats: certainly.
The Ryzen chip's TDP is configurable between 15W and 28W, which would include the GPU (but I doubt most of these tests touch the GPU anyhow). There will be power usage differences, but the TDP difference won't be huge - most differences will be due to utilization differences, which might be large.
The RAM issue usually doesn't affect most benchmarks, but it's something to consider if there are odd outliers.
The CPU core count number represents the reality of these chips (but M2 has a 4+4 config, apparently?).
Using linux is likely far from ideal, but probably necessary for them to run such an extensive and mostly comparable set of benchmarks. It's a significant caveat, but for CPU-limited benchmarks it's hopefully merely of reasonably limited impact (on the order of 30% on average rather than 300%, say?). OS differences tend to be larger for I/O, GPU, and some niche things like context-switching benchmarks. Of course, the power scheduler stuff matters.
It's worth pointing out that phoronix itself (on different hardware and slightly older OS versions) looked at some linux vs. macos benchmarks: https://www.phoronix.com/review/apple-m1-linux-perf - and while there were a few unsurprising macos wins, there also were some (far fewer) linux wins.
I think the benchmark is very interesting for what it is. Despite limitations, it _is_ informative. You can't always get a shrinkwrapped answer to whatever question you really have; so extra data-points such as this are helpful.
You know what they say: there are lies, damn lies, and benchmarks. Or something like that; caveat lector anyhow.
Yep; I know. But for most people interested in this comparison that's nevertheless likely to make the comparison less representative of their workloads.
Hats off to phoronix; it's not meant as a criticism - just an expectation that the benchmark results may not satisfy everyone.
Feels like it makes perfect sense to compare performance on the same system. Is someone going to switch systems for some minor performance gains? I really doubt that. Usually it's something else that motivates people to switch.
That said people pick different manufactures for their next device all the time (at least in the Linux/Windows world) and having performance comparison for these devices on your favorite system helps you choose.
> The Ryzen chip's TDP is configurable between 15W and 28W,
TDP isn't a relevant number since the Ryzens will exceed their "configured TDP" for an unlimited period of time.
see, eg, Anandtech's Tiger Lake review where a "15W cTDP" Renoir chip pulls 23W, and it is allowed to sustain that boost for an unlimited period of time, going against Intel chips that actually obey the 15W configured sustained-power limits...
The relevant number for comparing Ryzen against Intel/Apple SKUs is what AMD calls the "PPT" which is their sustained-boost TDP. The "cTDP" number is basically pure marketing these days, nobody is running at base clocks outside of contrived scenarios.
(the Intel boost TDP is allowed to exceed the rated TDP too, but they only allow it for a limited time, it's a "sprint" feature on their chips, where AMD has just turned it into their new sustained TDP number, with the advertised TDP being essentially fake for marketing purposes it's specified at base-clocks that nobody ever runs.)
As far as I understand it, it's up to the device manufacturer to pick the exact TDP. It's by design that some devices might structurally exceed the base cTDP.
I don't know the figures for lenovo's thinkpad, which is why I quoted the full range AMD offers. And even then, TDP is just a long term target for the purposes of cooling - workload, implementation and environmental (i.e. temperature) details might leave two chips with identical TDPs to nevertheless consume vastly different amounts of energy.
In any case, we simply don't know how much power these systems used under this load. The expectation certainly is that the AMD system used more, but it's not clear how much more.
The focus on _power_, as opposed to _energy_, always annoyed me. When I'm using a notebook away from home, what matters to me is how long I can keep working.
Phoronix should have measured how long each notebook could run the benchmark suite sustained and scaled the benchmark results accordingly.
There is no sane universe in which we lie about how fast we can do something in order to account for differences in how long we can do it. If you have two models identical save for one having twice the battery we don't account for this by pretending the lesser endowed unit is actually only half as fast.
While these things are interrelated you actually want both pieces of data and you don't want them complected by using them to forge some number made entirely useless and incomparable by incorporating both facets in one useless whole.
The 4800U hit north of 65w in a NUC device[0]. The 5800U hits 52w in a laptop[1]. AMD runs their chips hot.
TSMC N6 is a 7nm++ node. The even more advanced 5nm node only offers either 15% performance increase OR 30% power reduction vs N7. The 6850 clocks 10% higher, so the power shouldn't be dropping AT ALL.
The 6850H has an identical turbo clockspeed of 4.7GHz and a TDP of 45w with real-world power consumption according to other reviewers being north of 65w. The base clocks for these chips is 2.7 and 3.5GHz respectively.
In the case that they really are getting those numbers, they are certainly only at base clockspeeds (2.7GHz) which raises the impossible question of how Zen 3 suddenly got such a huge performance per clock advantage going from desktop to mobile.
As the sibling said those numbers are very configurable. e.g. around the x86 handhelds there are tinkerers running their U/P class chips at anywhere from 5W configured to 30+W configured (and with the appropriate cooling could totally go to 60W+ if configured to do so. Silicon-wise there is very little difference between AMD's U and H class chips, mainly just stuff like binning and some configuration in the firmware). Typical reasons to configure this would e.g. be cooling or battery restrictions from the OEM.
Furthermore note there is a difference between SoC package power and power pulled from the wall. That depends on the rest of the device, but 5-10W isn't unreasonable. (So e.g. at 22W package power, pulling ~32W from battery is pretty common). Looking at the detailed graph in the NUC review, that difference is particularly large though, the package only pulls <20W in steady state and maybe 30W at boost[0], but this device somehow seems to have significant power draw coming from somewhere else, this is pretty atypical wrt laptops & battery draw at least.
I'm not sure what performance per clock advantage going from desktop to mobile you're referring to? The mobile chips are slower due to the lower max boost and power limits, but due to non-linear power scaling it tends to be not that* much worse than the desktop parts.
As an aside I find the Anandtech Zen3 review[1] a pretty good resource when I want to have a clue about reasonable clock/power expectations on zen3 (though it is only a single workload)
(Also not sure where the 52W claim comes from, my searching on the linked page seems to yield no results?)
*: With the notable exception that pre-6000 series AMD had some horrible delay clocking up the cores when on battery, hitting short tests like geekbench. That said even on AC the chips should be adhering to configured power limits.
If that NUC CPU is using 30w, then what else is using the other 40w? Where is that heat dissipating to when the ONLY heatsink is on the CPU itself?
What is missing in that story? Is it more likely that a mystery chip is dissipating 40w into that tiny chassis or that something isn't reported correctly?
Perhaps the answer is something to do with the chipset using a massive 40w of power. That isn't likely as even the actively-cooled desktop chipsets don't use that much power. Even if that's true, not only does the dissipation issue still go unanswered, but the SoC it is being compared to also moves everything on-chip, so adding in that power consumption is necessary for an equal comparison.
There's no suitable answer to this problem other than the reported numbers being wrong.
> I'm not sure what performance per clock advantage going from desktop to mobile you're referring to?
M2 peak performance at 3.5GHz is equal or better than desktop Zen 3 chips running at 5+GHz.
The second link you post shows the 5950X (with the best binned chiplets with the lowest power/core numbers) requiring 7.5w per core at 3.7GHz. That means you could barely get HALF your cores running at 3.7GHz at 30w. All of them at that speed (1GHz less than turbo) would take around 60w of power (by the way, 6850H has a 45w TDP and claims base clocks of 3.7GHz, so something doesn't quite match up there either).
Even hitting 8 cores at 2.7GHz seems to be a stretch within that 28w TDP limit. EPYC with it's top-binned chiplets requires around 4-4.5w per core to hit 2.45GHz base clocks.
Adding between 700MHz and 1GHz to the clockspeed plus a well-known 60% faster per clock design plus cutting cache in half for Zen 3 mobile (which increases total power usage too) makes the benchmark results super fishy as they would require massive increases in IPC (or massive crippling of the M2 chip). This is of course not true, which indicates something is wrong somewhere.
Firmware can set the power limit to whatever it wants. With the exact same processor, one computer may hit 65 W while a different one is limited to 28 W. There's also huge diminishing utility when it comes to power, so it's possible that the chip is only slightly slower at 28 W than at higher power.
When you look at per-core performance of desktop chips, things aren't rosy. Looking at the 5950 (most power efficient per core), it's taking almost 7.5w PER CORE to hit 3.7GHz. It hits 4.7GHz (peak frequency of 6850U) on just 4 cores while using 110w to do it. That's almost 23w per core.
Based on these numbers, taking 8 cores up to 3.7GHz would require 60w of power and that's just to hit the "base" frequencies of the 6850H which they say can be done with a TDP 25% lower than that (maybe dropping half the L3 cache makes that possible, but at an overall performance loss as moving stuff from RAM takes more energy than keeping it in L3 and I don't know that losing half the cache saves more energy than the addition of a GPU adds back to the chip).
Even if we assume a 12% energy efficiency bump (two thirds of the 18% transistor reduction and roughly inline with the 30% efficiency at N5 with a 45% transistor reduction), we aren't doing anything multithreaded anywhere near peak frequency. In fact, we aren't doing anything multithreaded past those terrible 2.7GHz base clocks at best.
Meanwhile, the M2 TDP didn't really increase. They can hit 3.5GHz on 4 cores while using 60% less energy than those AMD cores at 3.7GHz despite being about twice as wide and over 60% faster per clock. Back of the envelope calculations seem to indicate that 4 M2 big cores at 3.5GHz should be more than 2x as fast as 8 Zen 3 cores at 2.7GHz without even using little cores and completely ignoring Amdahl's Law.
Of course, all this just goes back to the question of how questionable this entire article really is.
If I remember correctly, benchmarks of the ryzen 6800u (not quite this chip, but close) showed that the perf/watt sweet spot was probably _less_ than 15W. Even at 28W there were clear signs of diminishing returns, and anything north of 50W is largely pointless.
The intel competition in the form of alder lake scales for much longer if you just pump more juice into it. Scaling varies from chip to chip.
Edit - I might be misremembering, because 6900HS's sweet spot was at 20W: https://www.anandtech.com/show/17276/amd-ryzen-9-6900hs-remb... But anyhow, they also noted that "going from 50 W to 80 W is a 60% power increase for only +375 MHz and only +7.7% increased score in the benchmark".
But TL;DR: 15-28W probably really is the ideal range for a chip like this. Which won't stop ODMs from pushing well beyond that, of course.
I highly doubt those 50 or 60 watt examples are representative of the power use of those U-series CPUs in a 13" laptop. Perhaps it has been configured differently in a NUC.
Anecdotally, my work laptop has a previous-generation Ryzen 7 5850U (8 cores, 16 logical) in a 14-inch ThinkPad chassis. I just tried a 16-thread xz compression on it a few times and eyeballed the average power use with powertop. The baseline power with no load (except for what little idle load there was from whatever I had open) of the entire system was around 5 W with display brightness at a minimum. The battery discharge rate rose to between 21.5 and 22.5 watts for the couple of minutes the compression took.
This was on battery since I had no tools for monitoring power use at hand otherwise. (Turbostat reports detailed per-core and per-package wattage from the CPU at least on Intel but the distro I've got for work apparently doesn't have that packaged and I'm not going to be hunting for a source package for this.)
However, the compression took pretty much exactly the same amount of time on AC, so I doubt having it on battery affected CPU clock rates significantly.
A 13" laptop chassis would also have serious trouble getting rid of 50 or 60 watts of prolonged heat production from the CPU.
Also, where did you get the 52 watts in a laptop figure? The only reference to 52 on that page w.r.t the 5800U that I can find is a results of 51.9 points per watt, whatever those points are, in some kind of a power efficiency test. The power consumption test above that reports 42.9 watts, measured with an external monitor, so probably including more than the CPU. I also can't immediately find a reference to what kind of a chassis the CPU was in, laptop or otherwise.
> raises the impossible question of how Zen 3 suddenly got such a huge performance per clock advantage going from desktop to mobile
What kind of a PPC increase did Zen 3 get going mobile? I've only read about PPC comparisons between Zen 2 and Zen 3.
- 3 GHz 16 threads consuming 25W, ramping down to 2.94 / 23W after a couple of seconds
and when compiling Linux on 16 threads it stays at 2.85 GHz / 23W
In performance mode it does run at 80 degC under sustained load, so usually when undocked I just leave it in balanced mode where it's capped at 20W short / 15W long
Also worth noting is that in low-power mode (11W / 11W) it'll still hit max single core frequency possible.
> it would also be an indication of the progress of Asahi Linux.
Other than power management support, the progress of Asahi doesn't really impact CPU performance.
> Asahi Linux is super cool, but most M2 chips in the wild are not running it. So it's not a useful comparison.
Clearly this is aimed at an audience who wants to run Asahi. It's a perfectly useful comparison for that.
Prices weren't mentioned, but I suspect the prices of the two systems being benchmarked were similar. (Edit: I take that back, the AMD system looks considerably more expensive - it would be interesting to see a more price-matched comparison)
Maybe these benchmarks aren't useful for you personally, but I think a lot of people (myself included) consider it to be an interesting and useful comparison.
> The Ryzen setup has 3x the power envelope (in watts) as the M2[1]
TDP does not represent the power envelope of the chips. It's the sustained load target at best, but mostly even that is kinda made up and the rules don't matter. But for any short (where short is less than a minute or even 5 minutes) burst, that TDP figure is completely irrelevant. Nothing respects it. Also for single threaded tasks, neither one is even going to pull that high.
You have to compare actual power used during the specific test in question to make any such comparison. Otherwise trying to judge power consumption by looking at TDP is like trying to judge performance by only looking at clock speeds. Within the same manufacturers same generation you can kinda infer something useful. Other than that? Not a chance.
It's also interesting that the maximum power consumption eked out of the Ryzen 7 Pro 6850U was a touch under 32W. Where did this 46W number of the parent comment come from? Or the 50-60W in the comment below? They must be thinking of a different CPU/APU.
But again it's not. TDP isn't a defined thing. There's no standard for it. It's literally a made up value by the SoC manufacturer, and in the case of laptops the laptop manufacturer even gets to fiddle with it.
That said in this case it is a small difference regardless. The 6850U's TDP per AMD's spec is 15W-28W. That's bang on the same as M2 basically. There's no 3x difference here. Unless there is because again TDP is a made up number with no formal definition.
> AMD and Intel chips usually max out at around 50-60w real-world power.
That's a sweepingly broad claim that's not at all well supported. AMD & Intel both make CPUs that top out far below 50-60w real-world power and also top out far, far above 50-60W real-world power.
From a different review of the same CPU (didn't check if same laptop, could be though)
"The Ryzen 7 PRO 6850U with the Linux 5.18 kernel had a 18.4 Watt average (or 16.6 Watt average with Linux 5.19 Git) while the Ryzen 7 PRO 5850U average on Linux 5.18 was up at 21.96 Watts."
https://www.phoronix.com/review/amd-ryzen7-6850u/8
So no, this isn't a 50-60W real-world power CPU. That's the non-U SKUs.
But if this AMD was a 50-60W CPU that'd exactly prove my point that TDP is a stupid number to compare and you always, always have to look at actual power consumption used (which this M2 vs. 6850U didn't do because as noted briefly in the intro power monitoring of the M2 doesn't work on Asahi yet)
Here's the 4800U running in a tiny NUC at over 60w and the 5800U running at almost 52w. They absolutely DO hit very high real power usage.
TSMC N5 only offers 15% performance OR 30% lower power vs 7nm. Peak clocks on the 6850U are 10% higher than the 5xxx generation AND is on N6 instead of N5 which offers a significantly lower advantage than what I stated. N6 offers an 18% reduction in area vs N7 while N5 offers a 45% reduction in area, so you can do your math from there.
Why are you using peek instead of average? The average power over the test is what matters, not the instantaneous spikes. And did you miss the whole "configurable TDP" thing? The OEM gets to change the power targets. They aren't fixed. Saying the 4800U in a NUC uses power X, therefore all 4800U's use power X is flat out wrong. That's not how it works, different usages will set different power limits.
> Saying the 4800U in a NUC uses power X, therefore all 4800U's use power X is flat out wrong.
If the TDP is only configurable up to 28w, but they're pulling almost 70w total system power (when there's simply no other real power users in the entire system), then there's a serious problem with their default "average" power usage not respecting TDP in any real way.
A lot of AMD laptops have historically dropped 30+% of their performance when you unplug them (a notable example would be the MS Surface 4s) so they can look better than they really are as reviewers tend to be lazy about this and test performance while plugged in then do a rundown test to push out a "review" within the couple day window they can still make ad money.
Comparing to other Zen 3 chips (I've gone into that elsewhere in this thread), top-binned EPYC uses 4-4.5w per core to do 2.45GHz base clocks (that's 32-36w for 8 cores at ~2.5GHz while they claim base clocks of 2.7GHz). If you lower that max TDP even further, those clocks go down even farther.
I disliked when Intel started going with TDP as a recommendation rather than a limit 15 years ago. I disliked when AMD followed suit so they wouldn't seem to be at a disadvantage (well, at less of a disadvantage as they were getting crushed at that time). I dislike the M2 Air which throttles back rather quickly.
The only good thing in recent times has been Intel's 12th gen adding a peak power consumption metric (no doubt because the difference between that and their normal TDP would have basically guaranteed a lawsuit).
> Why are you using peek instead of average?
Many (most) benchmarks are short-lived, but people infer long-term performance from these.
If a chip is getting N marks at 60w, long-term performance where power adjusts down to 30-40w isn't going to be anywhere close to that number.
M1/M2 when actively cooled can run at peak clocks/performance all the time. This means that performance expectations are in line with what reviews show. This is good for consumers (and they need to be more upfront about the air thermal throttling).
To you and all the rest saying the same: do you really think that when trying to judge a processor speed you should run benchmarks with different OSes? So, why not benchmark Lenovo + Windows vs MacBook + macOS? Those are the most sold configurations for both laptops, no?
To me, it makes sense try to compare the raw HW with the same layer of software, unless there is some big glaring missing feature in Linux, inhibiting the use of some HW capability of the M2 processor.
Usually these comments are by people that are angry that their preferred choice didn't win the benchmark and try to find a rationale to invalidate the finding.
Considering the context, they probably wanted apple to clearly win and not just be basically on par or slightly behind.
Often these people aren't even aware of this themselves.
I found the stats to be missing the most important datapoint for laptops however. If performance/wattage is irrelevant you really don't need a laptop after all, and they're even using the low energy /underperforming ryzen chipset...
I know they couldn't get the data from the drivers on Linux, unfortunate nonetheless.
Raw hardware comparison is interesting, but it’s also valid to want to test overall system performance, which Apple have demonstrated is a collaboration between hardware and software (particularly for battery life).
OTOH 8GB RAM is Apple's own self-inflicted limitation. Why should the other CPU be given artificially less RAM only because Apple chose a design that limits how much RAM their chip can use?
M2 is not limited to 8GB. 8GB is only the base Macbook Air M2 model. You can buy one with 16 or 24GB. Most people who buy 8GB Macs these days complain about performance, while people with 16GB praise it.
That is, however, an artifact of how Apple is pricing the models. The price difference between 8GB and 16GB is $200. This is absurd -- there's no way the added cost in ram is more than $50 for them and due to their market position and massive volume, it's probably quite a bit below that.
ThinkPad X13 Gen 3 starts at $1919. Macbook Air M2 with 8GB RAM is $1199. Macbook Air M2 with 16GB RAM is $1,399. So even at 16GB it's still a lot cheaper than the Lenovo laptop used. Price doesn't explain the disparity in the hardware used in the benchmarks.
(the 6800u ~= 6850u unless you're deploying them en masse in the enterprise, in which case there's extra management features in the Ryzen pro that the Mac doesn't have)
So, you're comparing a lower build quality on the Lenovo side against the Apple? Yeah, of course if you start cutting costs out of other places, the price comes down, that's not a particularly interesting or insightful point, you've just loaded the comparison.
Also seems to be 16:10 instead of 16:9, and have a different set of ports. Honestly I don't see what those two laptops have in common beyond both being Lenovo.
no one is paying Lenovo listing price. In fact, there is a 40% off coupon right there on the page, bringing that $1919 down to $1151. You may even be able to get deeper discounts through your employer corporate discount plan.
This statement is not even wrong, in the sense that it is nonsensical. If you intended to say that the RAM is integrated on chip, that is incorrect. Apple marketing made that statement early on, but teardowns very clearly show that the RAM is soldered on package, not on integrated on chip. This is still a leap forward in power from other common devices, but a much smaller one than integrating the RAM on the chip.
Furthermore, the RAM on M2 is bog-standard SK Hynix LPDDR5. 2x 32gbit chips for the 8GB model, 2x 64gbit for the 16GB model, and 2x 96gbit for the 24GB model. I can buy the exact same chips that are used in 16GB Macbook Air for ~$70 each, and I am not Apple.
If the SKUs had the same level of markup, the price difference between 8GB and 16GB would be less than $50.
> I can buy the exact same chips that are used in 16GB Macbook Air for ~$70 each, and I am not Apple.
Makes me think of licensed trades. Anything a plumber or electrician installs for me will be significantly marked up from what I could buy it for myself.
It feels weird that 8GB is the entry level for a $1000+ ultrabook in 2022. I remember 4GB being standard 10 years ago. That whole "doubling every two years" thing really tapered off.
I haven't written my comment in the spirit of entering a competition of who can get more RAM, but in the spirit that the Phoronix benchmark compares completely different computers, one with 8GB, the other with 16GB of RAM and gives a title suggesting that it's a comparison between chips, when the chip with 8GB isn't limited to 8GB. They could have gone for the 16GB option and made the comparison more honest. The chip doesn't have any such limitation.
The apps they use for comparison are limited by the CPU performance not memory size, so 8/16 shouldn't matter here. Unless you can point at something that's likely losing due to swapping?
This is kind of true for desktop and maybe high end laptops but here we're talking about a chip for ultrabooks. Those laptop designs don't have a lot of headroom for cooling and power delivery. The listed spec is accurate.
Note that it is possible to basically overclock the chip and raise this limit up to around 50W for the combo GPU/CPU if you really want to. This requires enhancing the cooler as shown in [0] and no OEM does that out of the box.
Are we sure this is actually 4 cores and not a reporting error? AFAICT with some surface Googling Apple doesn't sell the M2 with cores disabled does it? Also 4 cores 8 threads is suspicious given that AFAIU the M2 doesn't have SMT. So you'd have 4 big and 4 little cores for 8 total. (at which point I think that part is fair. This is a chip to chip, not an uarch to uarch comparison)
This is not the case. All 8 physical cores of the M1/2 can be utilized simultaneously, since each is a full physical core, independent of the others. The statement about only being able to use 4 at a time is true of threads, such as those found on SMT enabled processors that have core/thread counts like 4c/8t. In those systems, the threads share logic and decoding circuitry with each other, which would make your statement correct. You can see this in the M2 die shots. Both banks of 4 cores are in separate areas of the die. https://semianalysis.substack.com/p/apple-m2-die-shot-and-ar...
(edit): Granted 4 of the cores are lower powered "efficiency" cores, this is by no means equivalent to having just 4 cores
I don't see any value in this comparison. These processors are consuming vastly different amounts of power. Not only that, but they are using a passively cooled Macbook Air (ultraportable) and a nearly twice as thick, actively cooled Lenovo X13.
They are not even price equivalent: The base price of the X13 is $1,800 compared to $1,200 for the M2 Macbook Air. And they aren't even comparing base model to base model. They are comparing base model Macbook Air to a ~$2,500 X13 Lenovo that has been upgraded with additional memory and the faster processor.
So the Lenovo is twice as expensive, uses twice as much power, is actively vs passively cooled, and is twice as thick. What are we comparing?
Why should this be held against the Ryzen? It was the competitive advantage that they had against Intel, and if Apple choose not to compete then it should be to their disadvantage. It's as ridiculous as this hypothetical argument:
The M2 air with the smaller SSD configuration (tested here) is also at a big performance disadvantage from all the other models with bigger disks[1]. AFAIK it is due to the low end config coming with a single physical chip for the disk, where other configs have two and can do dual channel. It also has no active cooling - apparently more performance can be squeezed out of it by disassembling and applying nerdcore thermal paste.
It's not even running the same compiler (x86 is a GCC 12.1.1 snapshot, ARM64 is GCC 12.1.0), so even before you get to some of these tests having hand optimised x86 codepaths, you're already potentially skewed.
No, I don't expect it accounts for the differences, but there's a ton of procedural flaws in this benchmark that make using the results for any purpose very tricky.
The other one that really concerns me is that the M2 was tested in the MBA. The MBA is thermally constrained and throttles. They have zero data on what temperatures it was (because it's not implemented yet!) so they don't know when/if the MBA was throttling in each test. The M2 MBP would have been a better comparison.
I'm wary of trying to draw any useful conclusions from this article about the M2's general performance vs the new Ryzen 6xxx lineup, the methodology is just too flawed.
What do you mean by specialised chips and functions? The tests here are running pretty generic code where there's no M2 magic that could speed them up. The unsupported hardware in Asahi currently is just extra hardware, not the basic CPU operation.
My understanding is that using the XCode compiler and libraries means that your could could very much wind up using co-processors that other compilers and codebases aren't aware of and aren't able to take advantage of.
Absolutely not. The M architecture with their Firestorm and Icestorm cores are basically a big.LITTLE architecture. Some cores are made for low power, energy efficient work with a lower frequency, while others are made to run at full blast. There are no magic coprocessors to run on.
The goal of the benchmark is to run the two exact same binaries, not to make one that uses all of Apple's ARM extensions and one with AVX-512 to see who can go fastest in the best conditions.
This isn't strictly true. Apple has other co-processors and some custom instructions (eg, matrix instructions). If you use their compiler and code, they can offload some calls to these while if you used another compiler and different libraries, these co-processors will be completely unused in all cases.
That may explain why is crushes Apple on some benchmarks. I wonder what causes Apple to crush Ryzen on other ones. This was the strangest comparison I've ever seen with large wins going to both contenders.
With cross-arch benchmarks like this, you find a lot of software that has hyper-optimised x86_64 implementations does better on AMD/Intel because of that.
It skews the numbers and makes a good comparison really annoying to do, unless you do your own comparison on your own workloads.
The exact same binary saw crushing victors in different directions, though, depending on what it was testing. Look at the GNU Radio results for example.
It's not the exact same binary - that's the point. It is different instruction sets, with potentially different optimisations. They're even compiled with different compilers - what looks like a GCC 12.1.1 snapshot for x86, and GCC 12.1.0 for ARM64.
It might be the same C, it might have hand-coded assembly for important bits in x86 but not in ARM, or vice versa, it might be just one specific algorithm executes particularly well on one CPU rather than the other, it might be that the slightly different version of GCC did a new optimisation.
edit: they're also comparing an actively cooled laptop to a passive one - so you would expect M2 to throttle in longer benchmarks, for extra distortion.
The methodology is flawed. It lets you cherry pick some individual results, and if your particular usecase is in there, great. But you don't know what state the M2 was in when a test started (eg if it was already hot and throttling, etc).
It's basically impossible to draw any useful generalised conclusions from these benchmarks.
Picking individual use cases is exactly how you should be reviewing benchmarks. You should be picking a laptop based on what you do. If you don't do certain things, why would you care that some other CPU is faster at what you are not doing?
If you're looking for a "general" comparison, there is none. General usage of a laptop computer for who? What do you consider general usage? What exactly are you looking for? For 99% of what people do, they won't even be able to tell apart a Celeron from an M2.
Why do you think we have things like discreet GPUs? You buy certain hardware for certain tasks.
Or do you just want to say that your CPU is better than someone else's? Who gives a shit? That's really all you get from a "general" performance review, a bunch of vague crap.
This review was great. It shows what Linux users can expect under certain workloads on two laptops that cost the same amount of money. You can then decide which one is best for you as a Linux user who may be interested in an M2.
Drawing general comparisons is exactly what this article tries to do at the end, that's one of my concerns with it.
They don't know what state the M2 was in at the start of each test (because the hw monitoring support isn't there yet), and this is a system that is known to thermally throttle, so the individual results are potentially flawed too.
The laptops don't cost the same amount. This is comparing an $1100 laptop to an $1800 laptop.
FWIW, I don't actually care which is faster (I own both AMD and Apple hardware that I use for different things) - I just think the review is flawed.
> It's not the exact same binary - that's the point
I think you misunderstood. "GNU Radio" on M2 was sometimes screamingly fast, and sometimes embarrassingly slow, depending on which test it was.
I'm not saying that "GNU Radio" was the same on M2 and AMD, obviously it's not. I'm saying the performance results for GNU Radio specifically were insanely inconsistent - M2 won by a stupidly huge amount in one of the GNU radio results, and AMD by an equally absurd margin in the other GNU radio results.
Same "GNU Radio" compiled binary on the respective platforms, huge swings in performance depending on what that binary was doing.
There were a couple other similar examples, where performance for the same program swung wildly depending on the exact task.
That's not necessarily unexpected and still follows most of what I've said - if one particular algorithm is hand-optimised and one isn't, you will see wild swings - especially if one has been hand-vectorised and one is failing to auto-vectorise during compilation.
Without examining the behavior of the specific wins my guess is memory. The M1 and M2 have amazing memory bandwidth. That's something their design needs as clock for clock they would be massively pipeline starved if they didn't because of how wide the apple design is.
Seems to me the real story here is that even with those disadvantages, the M2 is very much holding its own in the comparison. It's not blowing away the Ryzen, sure, but neither is it being left in the dust.
The RAM difference probably isn't material to tasks which use less than the 8GB involved, the power envelope is part of the difference between the parts involved, and the m2 mac air has 8 cores. Not sure where they would have bought hardware that never existed like a 4c m2.
If one wanted to know what the difference in performance per watt or per core it would be useful to constrain the matter but that isn't the most useful question for measuring performance.
Honestly I think the important takeaway is that both chips are in the same ballpark.
Sorry but this is completely fair. Despite the Ryzen system having far more resources on paper, they're going to be pretty similar on price and on silicon area.
I don't see how Asahi is going to limit performance in those benchmarks.
TDP is a complete garbage metric and doesn't mean anything.
I think this is a more than fair comparison. They are both the high end, low power chips.
What is the state of compiler optimization for Apple Silicon under Linux? I’ll wager it’s far less mature than amd64. Indeed the whole point of Apple Silicon is its deep integration with macOS. These benchmarks are interesting, but of little practical value. No sane person should make system purchase decision solely based on this.
this is a straightforward, real-world use case for two systems. while memory could have been set equal perhaps, even doing so would not make it all even. you are only focusing on capacity while ignoring memory speed/timings and channel.
if Apple can advertise their findings and compare to desktop CPUs, then the TDP debate is completely pointless. moreover, each chip maker has their own way of calculating what they call "TDP".
to the intended reader (Linux users), this is a great guide to decide which options works best from actual performance standpoint.
CPU micro benchmarks aren't typically affected by memory quantity, especially at these levels.
> The Ryzen setup has twice the cpu cores
The Ryzen chip has eight homogeneous cores, the M2 has eight heterogeneous cores. [0] All else being equal, having high performance and low power cores in the same package _should_ result in better performance and efficiency.
I do note that the machine specs in the article show the M2 as having 4c/8t, so I wonder if there's an SMP issue in Asahi on the M2 currently? They don't make it clear if this is the case, or why all eight cores aren't being reported/used.
Doing some preliminary searching, it seems the M2 doesn't employ SMT, so perhaps this is misreported, or Asahi does something weird with scheduling.
> The Ryzen setup has 3x the power envelope (in watts) as the M2
> Ryzen 46w (not sure if this includes the GPU)
The 6850U is reported by the manufacturer as having a configurable TDP of 15-28W [1]. I believe this is total package power usage, so using either the CPU or GPU would allow better performance than maxing out both, and this probably applies to both chips. Some board/laptop manufacturers will also extend these limits, especially when plugged in, and design their cooling solutions to handle the increased power usage accordingly. Intel, for example, has published a TDP of 125W for some chips that can consume up to 230W while boosting [2]. I'm curious what both of these pull from the battery under load. I would expect the M2 to be more efficient, being manufactured on a newer, denser node.
> They are using Asahi Linux on the M2.
Any other comparison would be wholly meaningless. You (probably) can't run macOS on a Ryzen 6850U. Running benchmarks built by different compilers to run on different kernels wouldn't really be comparing the same thing.
In the end, this benchmark, while interesting, measures what it measures. The results should be taken with a grain of salt, and should not be extrapolated to predict the performance of other applications on these platforms.
I think it's a legitimate question to ask how long Apple's ARM advantage continues. I could totally see a repeat of Apple's PowerPC experience, where they do the transition, and just smoke the competition for a generation or two, and then get dragged under by the market effects of the x86 duopoly.
The next generation Ryzen series (7000 series) looks like it's going to be absolutely insane. That window may end up being shorter then expected.
The PowerPC problem for Apple was that IBM was not interested in advancing the architecture in the personal computer market, and Freescale had left the market as well. I don't think there was anything intrinsic to the PowerPC ISA itself that made it a hot and slow chip. It was simply the lack of R&D and commitment to fab on new process nodes, etc. The switch to Intel was necessary because they literally had no quality supplier for chips and at that point x86 was practically the only supplier for desktop computer MPUs.
Note that their portable / consumer devices have always been ARM. Like, back to the Newton even.
Apple now makes their own chips. They've dealt with that vulnerability. And they're fully onboard the ARM bus in a big way and they've managed to bring their customer base with them without a lot of hassle.
Over the last 40 years Apple has been burned multiple times with having their key ISA be dropped by its manufacturer. 6502 became a deadend (quickly.) Motorola dropped the ball on the (relatively successful) 68k, and tried to get people onto the ill-fated 88k and then pulled the eject cord and everyone went PowerPC. That lasted maybe a decade and Motorola/Freescale&IBM started to flee the ship. I think Apple has learned their lesson. They don't want to be vulnerable on this front anymore.
The difference here is that Apple makes more money by using their own silicon regardless of whether or not they have a technical advantage.
Apple's systems may very well end up being slower. From a business standpoint, I am not sure that will matter.
Neither AMD nor Intel have shown much indication of catching up to Apple's (well, ARM's) mobile device battery life advantage. Apple doesn't sell systems that go in data centers, they don't need to smoke anything.
I agree. I don't think the broader Arm ecosystem is comparable to the Apple-IBM-Motorola alliance of the Power era. Arm is ubiquitous in ways that Power never was. Even if Apple had to start buying chips from Qualcomm (yuck) they'd be okay.
This is definitely the key takeaway, here. Macs will always be a different kind of computer for a different class of consumer; people will either love them or hate them, regardless of processor speed or battery life. A Macbook is a Macbook, and if you want the benefits then you have to also live with the downsides.
Consumers already know this. They'll buy the new Mac even if it's worse (see: 2016), the new iPhone even if it's slower (see: 2022), and the new Magic Mouse even if it's still broken. It doesn't matter how fast or slow the Mac is, Apple has long proven that they exist in a market segment of their own, for better or worse.
Essentially this was because PC volumes supported Intels R&D and investment being greater than anyone else could afford. We’re no longer in 2000 though. Apple sold 240 million iPhones last year which is not far off global PC sales. Meanwhile TSMC has overtaken Intel with a broader and growing product base whilst Intel is shrinking.
It's not market effects from x86, it's just process. We've entered a period where (1) Apple is able to command higher margins for its silicon and thus pay for "The Best" of whatever is available, even monopolizing the best processes and (2) "The Best" process isn't Intel, so it's available for purchase.
So Apple bought themselves a win, which makes perfect sense. And they had already chosen ARM for iOS (for historical reasons, really -- the original iPhone picked an off-the-shelf Samsung SOC), so that's what they dropped in the Mac.
But indeed, this is probably transitory. Eventually TSMC will either lose its lead or ramp its best processes to the point where other manufacturers can buy it. Already, as we see here, they're only mildly ahead of the rest of the pack.
I don't think it's fair to say that it's just process, Apple has invested very heavily in their core design and their perf/w + total perf is still unmatched by companies like AMD or Qualcomm on the same process node. It's certainly not a one-horse race but Apple is definitely has world class CPU design capabilities regardless of node.
The "same process node" isn't correct. Nothing from AMD is available in TSMC 5nm yet, and the Snapdragon 888 is on Samsung's clearly struggling 5nm node. Apple is alone at the top of the process ladder right now, and they're getting pretty much exactly the performance[1] benefit you'd expect from that. Certainly the M2 is not a bad SOC, and there's no reason it shouldn't be and remain competetive with everyone else's offerings as the industry evolves.
But I do think there's a certain amount of kool aid being drunk by the Mac community about these chips. They're great. But maybe not insanely so.
[1] It's absolutely true that Apple's whole-system power integration story remains at the top of the industry. But that was true even when they weren't on the best process.
> The "same process node" isn't correct. Nothing from AMD is available in TSMC 5nm yet, and the Snapdragon 888 is on Samsung's clearly struggling 5nm node.
Sorry you are totally right and my phrasing was poor, what I was trying to say is that Apple's TSMC 7nm chips (A13) are still very competitive with Qualcomm and AMDs offerings on the same node. They beat out AMD (5000 series) on perf/w while tying perf and beat Qualcomm (865+) on perf handily with (iirc) similar wattage. M1 and M2 are certainly benefitting from TSMC 5nm compared to everyone else currently and AMD in particular is a lot closer than I think many Apple fans give credit.
The core problem (from an Apple business perspective) is that they were using chips that were a group project by ibm and Motorola, where IBM made money primarily off the server class Power chips, and I’m not sure if Motorola ever made money?
That meant that the performance requirements of a laptop were simply never going to be IBM or Motorola’s priority. The last PowerPC Mac was the G5 tower, and that was an amazing case with incredible cooling setup because it needed it. The G5 used a ton of power, and generated insane amounts of heat (seriously those G5 heat sinks were larger than most pc gamer/modder heat sinks if there era, before considering the enormous airflow, and even a flow shroud. Simply put there was no way a G5 was ever going to be in a laptop that was actually portable.
That’s what led to Apple migrating to intel - intel at least was interested in consumer hardware, and portable computing as well.
So the important thing is that Apple’s own cpus are presumably always going to be aligned with what Apple wants, in a way that they can’t rely on others to do.
I feel that we are at or already crossed the point where we don't need much more powerful CPUs. This is especially true for majority of Apple's customer base lies.
The only game in town that Intel/AMD can really play now is to make their chips cheaper and more palatable (reduce power consumption, offer better integrated GPUs, etc) for x86 based consumer products or slowly see Apple's share in the laptop market increase more and more.
Apple is getting smaller lithography from TSMC than AMD chips are, so they'll probably have an advantage in their M3 or M2 pro/max by the time Ryzen 7000 comes out.
There are some cool takeaways from this massive collection of benchmark results.
But before we get to them, things we already know:
* You cannot buy Apple Silicon without buying a Mac (and you can't get the unique characteristics of a Mac and macOS without Apple Silicon)
* Apple Silicon is optimized for macOS (and vice versa)
* Apple Silicon is remarkably efficient (particularly under macOS)
This comparison, of course, is focused on Linux users. It is not going to determine some sort of ambiguously defined but ultimate superiority of silicon across all scenarios. However, if you use Linux on one of the laptops used to compare the CPUs, it can give you insight on performance for those specific use cases.
So what are the takeaways?
* The fan-less M2 (4p/4e) in the Air with 8GB performs about as well as an air-cooled 15-28W Ryzen 7 Pro 6850U (8p) with 16GB on average (and vice versa)
* The performance of the M2 is likely more than satisfactory despite Asahi Linux not being the absolute optimal operating system for the silicon
* The performance of the Ryzen is likely more than satisfactory despite lower efficiency compared to Apple Silicon
* Laptop APU performance in 2022 is really remarkable (even at these low TDPs), and any user (regardless of preferred OS or chosen CPU designer) will likely have a good experience with one of these high performing chips
I think running these benchmarks appeals to our curiosity about the state of hardware. It is not a perfect, controlled experiment, but it compares two real-world CPUs (APU and SoC respectively) and gives us insight into their performance given the actual hardware configurations tested.
What this does not tell us (again): that Ryzens are better than Apple Silicon, or vice versa, in all cases or in every metric. That if one CPU beats another CPU in some benchmarks, it's the one you want, regardless of all the other considerations you have to put into purchase decisions. That either of these CPUs are "bad".
> Apple Silicon is optimized for macOS (and vice versa)
> Apple Silicon is remarkably efficient (particularly under macOS)
It is actually quite possible that Apple's advantage was more about being on TSMC's 5nm before everyone else, than something intrinsic about their processor.
> The fan-less M2 (4p/4e) in the Air with 8GB performs about as well as an air-cooled 15-28W Ryzen 7 Pro 6850U (8p) with 16GB on average (and vice versa)
The air cooled M2 MBP doesn't do significantly better than the fan-less MBA; so the results will probably still stand.
I'm curious what Linux vs Android power efficiency looks like. I would think Apple's experience with mobile could translate back to laptop efficiency.
It seems on the Linux front, things are a bit more mixed. Androids optimizations include things like app background usage limits that are harder to integrate in a Linux distro
One thing I always miss in these benchmarks are noise levels. Being completely silent is a major selling point for me and I would be willing to sacrifice some performance for it. The Air should be silent as it doesn't have any active cooling. I assume that's not the case for the Ryzen.
But it's not a comparison of these 2 laptops in particular. They are only comparing the CPUs in a similar deployment form factor and with a (mostly) comparable power envelope.
Nothing about the laptop quality (fan noise, build materials, speakers, display, track pad, keyboard, etc etc etc) is ever discussed. That's not the comparison here.
How can you compare CPU without handling variables like cooling? The MacBook Air and MacBook Pro both use an M2, but they tested the one without active cooling versus a competitor that does have active cooling. Wouldn't the MBP be a better comparison between the CPU? The MBP performs better with the same CPU as the MBA due to additional cooling capabilities.
That wasn't the OP's complaint. OP's complaint was that noise levels weren't compared. We don't know if either of them throttled, which is yet again a distinct question from noise levels. It takes the M2 Air a few minutes to throttle, it's quite plausible that phoronix just had cooldown pauses between tests and this wasn't an issue at all.
An M2 13" Pro would have been a better comparison point though sure.
Yep. Even the 14 & 16" MBP with M1 Pros stay much cooler & quieter than your typical AMD/Intel Windows laptop.
Silence is golden, and even on the odd occasion where the fan on the 14" M1 Pro starts spinning (e.g. running Cinebench to purposefully max all cores), it's extremely difficult to notice without your ear right up against the laptop.
By comparison, my Windows work laptops (previously an XPS 15, now a ThinkPad T14 Gen2) become plainly audible from 10ft+ away just attending a Teams meeting.
> Being completely silent is a major selling point for me and I would be willing to sacrifice some performance for it. The Air should be silent as it doesn't have any active cooling.
If you're willing to tolerate a low amount of noise, I find that laptop coolers with very large fans (200mm) work great. The large fan generates a high volume of airflow, but the the low fan speed means that it's almost silent.
Sure, but tell me where I can find a laptop that is as thin, light, cheap, and has the battery life of a MacBook Air, while also having this Ryzen part and your favored large fans.
They are talking about using an external laptop cooler, I believe. Not feasible for some but if you do 90% of your work at your desk then it certainly makes sense as a suggestion.
Meaningless question when they don't sell the M2 chip separately
> Hmm .. Doesn't "for both" negate the argument
I guess "for each" would be better ? But OPs point still stands, if you put me on a race car you are not breaking any records no matter how good the car is
Simply, that you can’t compare laptops solely on a cost basis easily.
Does the Ryzen system come with a full aluminum enclosure?
Does it come with a screen with P3 color, 400 nits peak brightness, and HDR support?
What is the battery size on both machines, and how long do each last?
How thin is it? How light it it? How fast does it charge? How much does this affect you daily?
If it was only about CPU performance, I could grab the cheapest Clevo with a Core i9 and it would beat every other manufacturer in the “bang-buck” spec as you are defining it, but it would be an awful experience.
> Simply, that you can’t compare laptops solely on a cost basis easily.
But they aren't doing that!*
They're specifically comparing performance between two similarly-priced laptops[1]. That's what "benchmark" means.
If this was a review between the two laptops I'd agree with you, but it isn't a review, it's a benchmark suite.
> Does the Ryzen system come with a full aluminum enclosure?
> Does it come with a screen with P3 color, 400 nits peak brightness, and HDR support?
> What is the battery size on both machines, and how long do each last?
> How thin is it? How light it it? How fast does it charge? How much does this affect you daily?
All of these are valid questions, just not for a benchmark. The benchmark is one set of inputs a potential purchaser would take into account, with the other inputs being all those things you mentioned.
[1] I assume that they're similarly priced - I skipped the introduction and went straight to the benchmarks.
> Does the Ryzen system come with a full aluminum enclosure?
If you really want one you can get one.
But if you are buying a laptop on the basis of how shiny it is does the CPU performance really matter?
When I bought a car for my wife she picked it out on the basis of how cute it is. She isn't going to run around being upset that it doesn't have 0-60 time of a Subaru WRX. To her the Subaru is ugly.
> Simply, that you can’t compare laptops solely on a cost basis easily.
Yes, people might be searching for the best performance, and cost comparison here is fair.
> If it was only about CPU performance, I could grab the cheapest Clevo with a Core i9 and it would beat every other manufacturer in the “bang-buck” spec as you are defining it, but it would be an awful experience.
Evey user has his/her requirements and things he/she is okay to comprmise on.
It’s still pretty silly because the price is the easiest thing to compare. Just show the prices of 2 systems as closely specced as possible and list power, thermal envelop blah blah. As it is, this doesn’t change my mind about if I’m making the right trade offs by getting the M2
Final laptop price isn't that important when this is a CPU comparison, "Apple M2 vs. AMD Ryzen 7 PRO 6850U"
> Hmm .. Doesn't "for both" negate the argument.
What I meant is that they don't use the OS which is most stable and most mature on each platform independently (i.e. some flavour of linux, or even windows, for the Ryzen and macOS for the M2). Either choice will introduce OS differences, but I believe that using the most optimized OS is the better choice as it allows each CPU to show off its best performance.
Hypothetically - a diesel BMW m3 may cost the same as a Camaro with a V8 engine, but what's the point of talking what engines they have... if you are purchasing these items for other reasons.
I agree, but this is a CPU benchmark. They don't benchmark the screen, or the ram speed, or the battery life, or anything else in the laptops. All they compare is the CPU
Linux has supported AMD CPUs for decades and AMD has engineers creating kernel patches to ensure their CPUs work correctly on Linux.
Linux support for Apple chips is in its infancy and what little support it does have has been provided by a ragtag team of volunteers that have reversed engineered the M-series chips.
It's reasonable to assume that the AMD chip might be at a slight advantage on Linux.
You've posted this a few times. But now the devices are actually available and X13 starts at $1097... That's $103 less than cheapest MacBook. What a difference 5 days makes, right?
For those not familiar with Lenovo's pricing, basically the sticker prices are insane but routinely get ~50% discounts after the products have been available for a few weeks. Those are brand new models that do not yet get steep discounts.
It makes comparing them on prices almost impossible.
at work I got a m1 pro with 16GB of RAM just because they offered the 14" managed device with 16GB only, while they offered 32GB on the 16" devices. When I complained about this, the response was "but is 16GB unified memory" as if I was disputing the performance of the RAM and how it is handled within the M1 chip while my issue was filling the 16GB. I'm happy that at least in HN people seem to be more aware on RAM sizing
More ram = more performance if there's a cost in going across a bridge to keep the pipeline full. 16gb of _unified_ RAM that can be accessed by the CPU and GPU without a performance hit in going to the motherboard is a factor in some workloads. Whether you agree or not, it's an effective test comparing two architectures.
So the question is: are you spec benchmarking, or are you interested in the performance of the workload, because it's the actual work that matters, not how the bits are stored under the keyboard.
Only if your datasets, in aggregate, extend beyond what can be compressed into 16Gb...an what's the performance of the device you're swapping to? There's a GREAT BIG DIFFERENCE between an RLL 80 Gb drive and What you're swapping to on the motherboard today...
(In fact, you could consider the on-die RAM to be a really big Cache and the Flash storage to be REALLY REALLY big Non volatile addressable RAM.)
> as long as both systems have their memory channels filled out and the workload fits in memory.
Those are big ifs. We don't know how much of those 8GBs were used, and how much swapping the OS was forced to do. But either way, it's a silly thing to have different.
I am sure Michael Larabel knows what he is doing, given how long he has been benchmarking. I think both devices have soldered memory though, so the amount of installed RAM isn’t flexible.
Not to mention the usual problems with Phoronix benchmarks: it doesn't say how many benchmark runs were done, where are the error bars, was the software actually compiled properly etc. Phoronix folks don't understand what they are measuring; they also don't really care - I remember one of their benchmarks measured the execution time of a command that was erroring out.
Phoronix Test Suite isn't a benchmark, it's a marketing tool.
Every result graph there has the error indicated. If there are any significant errors then bars are shown. You can see this on the very first result page for LeelaChessZero.
It also shows you the number of runs. It also shows you the compile options used. All this info is included in every graph.
The complete system setups are described. The test suite is also open source.
I remember a recent "gaming on linux" article from them where they were computing "summary" geomeans including benchmarks across different resolutions... from the same game. So you might have:
* SOTTR 1080p
* SOTTR 1440p
* SOTTR 4K
* F1 1080p
...
And this wasn't like they had a 1080p geomean and then a 1440p geomean and a 4K geomean... they just had one geomean with a bunch of different resolutions thrown into it, including duplicates of the same game at different resolutions. And sometimes different combinations of resolutions for different games (they might skip 4K for a particular game, etc).
That's pleb-tier benchmarking, pick a random redditor and they know not to make that kind of mistake, it's obviously and facially incorrect.
It just goes to show the power of community goodwill... UserBenchmark's actual sub-scores are reasonably accurate, but because the owner is a massive fucking twat they're persona-non-grata in the internet community (I'm sure I'm going to be regaled with NO THEIR BENCHMARKS ARE TRASH AND HE CHANGES THINGS TO MAKE INTEL but nope, the subscores are accurate, topline "summary" score weights are what he fucks with). Michael Larabel is a very nice guy and frankly doesn't seem to understand the first thing about benchmarking, or score weighting, or mathematics, and constantly puts out trash-tier results with obvious defects, and he's revered in the community, basically a saint.
I know, nobody else is really benchmarking Linux and he's what we've got, if you don't like it then be the change, etcc. But, his results are given incredibly disproportionate weight to the quality there, he's no anandtech. And sadly anandtech is no anandtech anymore.
Games are benchmarked at different resolutions for the same game because that shifts the CPU/GPU burden. It's a great thing to do and many benchmarks do it too, and yes in the same average.
If you don't include a game at those resolutions for no good reason that's one thing, but varying the resolution in the same mean is a good idea.
The macbook ram is on the same package as the processor...there's an additional latency cost for the Ryzen...I don't think it invalidates the tests if they're not tied to memory latency for swapping in and out of RAM.
You'll get no argument from me on the OS...that's an interesting test decision.
Yeah, the U series are the correct comparisons against the basic/pro M1/M2, the H is much more like the Max, and the M1 Ultra, if you're actually using that additional power, is somewhere between a H series and a desktop CPU.
It's telling that people don't know this is comparing the performance on Linux in the comments just based on the site.
It tells you how much the culture of HN has shifted away from technical and engineering types. It's also telling that they think 16gb of ram changes the outcome of very trivial tests that don't use 8gb anyway.
A typical programmer knows what phoronix is and does and shouldn't be surprised by how it performs tests since it has done so the same way for a decade...but then I suppose most people on this site are not technical people anymore.
I actually broadly agree with you, but it's just a difference in specializations. Web developers make up a large percentage of the current HN population and they don't need to know the low level details of an OS or the hardware to do their jobs effectively.
Specifying that knowledge of a benchmarking site is required for those having a technical background is just a weird hill to die on though.
I wouldn't expect so many not knowing what Phoronix is and how it works. It's a linux enthusiasts web site and Michael has to purchase by himself a lot of tested hardware. Considering those limitations and being alone, its work is quite remarkable.
A lot of these look more like suboptimal implementations on ARM (or incredibly good implementations on x86). There is a lot of odd performance gaps all over the tests.
It exists. E.g. on macOS it’d actually use the AMX matrix multiplication units (for benchmarks that use BLAS) and blow away most x86_64 CPUs that have to rely on AVX2.
Fair, but phoronix is a linux site, and thus performance under macOS won't be of interest for most readers. The performance as stated is the actual performance one currently gets under linux, regardless of potential.
Which is deeply interesting to people who want to run Asahi Linux on an M2.
I found the data compelling--M2 silicon under Linux is generally competitive against contemporary strong x86 laptops, but if you are sensitive about the performance of a particular workload, choose your device carefully.
With every benchmark there is an objection, because every benchmarks measures a specific thing, and that specific thing is not the thing everyone wants to see measured.
These benchmarks tell you what performance you get with this array of programs, on linux, with these machines. You want to know something about the inherent performance capabilties of each cpu, which is very hard to figure out, since we will never know when/if any of these programs has had a totally optimal solution for each piece of hardware.
Usually the best you can do is just measure actual programs people use.
Lammps molecular dynamics is by Sandia national labs, they probably have a good ARM implementation. LeelaChessZero is also a SIMD-implementation IIRC. Both are SIMD-accelerated, but LeelaChessZero is faster on M2, but LAMMPS is faster on AMD.
I don't get it at all. Its really hard to see the pattern. Furthermore, its hard for me to imagine that LAMMPS would be much worse on one system over another, given the authors.
---------
Then comes the "in-between" benchmarks. DaCappo is slower on low-power settings for M2, but high-power setting M2 faster than any setting. Very strange behavior, I can't imagine why this would happen.
ZSTD compression is faster on AMD, but decompression is faster on M2. Same codebase, same authors, but different results over two different runs.
It's certainly what Cloudflare found when they were evaluating early ARM server chips.
>the first benchmark would be the popular zlib library. At Cloudflare we use an improved version of the library, optimized for 64-bit Intel processors, and although it is written mostly in C, it does use some Intel specific intrinsics. Comparing this optimized version to the generic zlib library wouldn’t be fair. Not to worry, with little effort I adapted the library to work very well on the ARMv8 architecture, with the use of NEON and CRC32 intrinsics. In the process it is twice as fast as the generic library for some files.
Does that excuse apply to LAMMPS, a Sandia National Labs highly optimized set of code?
Look at the benchmarks in the post. Some are consumer programs, but others are supercomputer programs with an enormous amount of optimization effort put into them for a variety of platforms.
If both code bases have had the same level of hand-optimization for the instruction set they run on.
For instance, in the example above, Cloudflare doubled the speed of the code by taking advantage of ARM specific instructions in the same way they had previously optimized their code for x86 specific instructions.
Of course, using the availible instructions isn't the same thing as putting in a heavy investment of time to make the code as efficient as possible.
As an example, look at x86 AV1 video encoders. The early ones were incredibly slow, but through many iterations of hand written SIMD code, recent versions have been getting much faster on the same hardware.
SIMD compute isn't a mysterious kind of beast though.
ARM / Apple M2 here is just 128-bit vectors. AMD / Intel AVX is 256-bit vectors, which is harder to optimize for (!!) due to the increased parallelism.
NEON itself is kinda crappy, missing a few good data-movement instructions (pshufb doesn't exist in ARM world), but IIRC, there are hard-coded swizzles in NEON that reach high levels of performance. So in this case, its simply easier to write pshufb style code in Intel/AMD systems.
Then again, I don't expect that a BLAS library would use pshufb too much. So you'd probably just have a simple dot-product like vector going up-and-down RAM to maximize your matrix-multiplication speeds.
----------
That's what I mean. LAMMPS isn't "easy" but it should fundamentally be a matrix multiplication (which is highly studied, and well optimized on all platforms). Indeed, the best performing BLAS libraries these days are on NVidia, not Intel or ARM for that matter. (Though Intel's AVX512 matrix multiplications are probably next best, they don't apply to this Apple vs AMD comparison).
You can't just assume a problem exists in general. There's some benchmarks in here that are sufficiently well optimized in ARM yet still come out better for the AMD chips. And vice versa for that matter (I'd expect LeelaZero to favor AMD, so I was surprised to see it better on the Apple M2).
---------
Assuming a Russell's Teapot just because there was a teapot from an unrelated benchmark years ago is kind of a bad form of argument. SIMD-compute (AVX, NEON, SVE, etc. etc.) has become more popular today, and there are more NEON_optimized libraries today than even just 5 years ago. And there are plenty of applications in this Phoronix benchmark where we'd reasonably expect good ARM-NEON optimizations.
> SIMD compute isn't a mysterious kind of beast though.
I'm reminded of the Handbrake people back in 2018 telling users that the current open source implementations of AV1 encoder ran 6,000 times slower than h.264 encode, and that they wouldn't be adding support for AV1 encode anytime soon, as the code base needed time to be optimized.
I'm not familiar with Zstandard and the Zstandard site doesn't discuss how they use threads in compression vs decompression, but I know that for gzip the parallel implementation in pigz is able to split the workload across threads for compression but not decompression.
So it could be that similarly in Zstandard, decompression is not an operation that is identically implemented to compression in reverse. There could be differences in thread utilization that shift the balance to being more sensitive to single-core performance.
It's not "their" linux support it's linux software support for ARM. A lot of software has x86 SIMD acceleration but doesn't necessarily have ARM SIMD acceleration.
You'd have the same ARM performance on Linux questions/problems when run under virtualization though, no? That doesn't actually change the complaint or situation here.
Now the existing discovered ones may not, but I'm sure in time there will be ones for Apple Silicon too. Just like how people for the longest time thought AMD was safer than Intel in this regard, or that ARM wasn't vulnerable.
ARM (and IBM POWER) was vulnerable to meltdown, the huge practical bypass that AMD wasn't vulnerable to at all. Nothing about these attacks have been ISA dependent.
There have been some issues with power management, load distribution and stability. A quick googling will show you more.
Regarding the other point: run lscpu and compare enabled mitigations on Zen3 and M2. We still need a proper analysis to figure out which ones must be enabled on M2.
It's weird how many absolutely landslide victories there are back and forth even within the same program. Like usually AMD vs. Intel it's mostly neck and neck, eeking out an edge here and there.
But here there's quite a few >2x wins and not even consistently within a given program. Like GNU radio can't make up its mind which one will utterly dominate.
The M1 is a very different chip from traditional x86. It only has 128 bit vectors, which can be a major bottleneck in software that is perfectly vectorized, but it also has way more out of order execution and decode bandwidth.
This Ryzen only has 256 bit vectors, though, it's not like the avx512 monsters that Intel randomly pushes. And in specfp2017 the M1 was overall stronger than even a 5950X ( https://www.anandtech.com/show/16252/mac-mini-apple-m1-teste... ). It was specint2017 where it fell behind, almost the reverse of what you'd expect.
I think this is a thorough and interesting set of results. Others have commented on the spec differences (2x ram, 2x cores, whatever x power envelope), but I’m not as bothered by them despite being generally pro-Mac :)
I don’t think 2x ram matters in many (any?) of these, as for that to impact things you really do have to be using all the ram, and once you started doing that I would expect to see noticeable cratering in perf.
2x core count is more problematic, esp. for things that do max out threads, but many of these benchmarks clearly didn’t (or the M2 is insanely fast in specific tests :) ). Many of those benchmarks that do use thread count == core count allow you to cap the thread count independently which I would hope was done if possible.
Power envelope I just don’t really care about, if thermals force the laptop to throttle that doesn’t mean the performance numbers don’t match reality. I did go into this knowing it’s a desktop va laptop benchmark and know there will be trade offs involved.
I think it’s also worth doing a performance per dollar comparison here as well, though I have no idea what the result would be in this case.
So the hardware stuff out of the way, a few of the benchmarks showed such a massive performance delta (in both directions) that I wonder if we’re seeing code/codegen differences.
The reality is that the M2 is an arm system, and most projects have only ever really had x86 to worry about for performance, so they have “if x86 do vector stuff; else do it old skool one at a time”, which can have massive perf impact.
In the reverse I’ve seen code that goes arm==float32 x86==float64, which has obvious perf impact.
Anther huge killer is anything that uses long double. For everything other than x86 long double basically means float32 or float64. On x86 (everywhere I think except win64?) long double is float80, which is much much slower than the alternatives for far to many reasons to list. So that seems like it could easily footgun code that’s being benchmarked as well.
All in all I thought this was a good article and it was an interesting read.
This article mistakenly calls the M2 a 4c/8t part. However, the M2 (and M1) have 8 physical cores with no SMT, which makes them 8c/8t. 4 of the 8 cores are performance (big) cores while 4 are efficiency cores. This makes the comparison less unbalanced than other commenters have said.
Also comparing both on linux when one is having active work done to port linux to it also makes the entire comparison dubious at best, just like most of phoronix's articles.
> Also comparing both on linux when one is having active work done to port linux to it also makes the entire comparison dubious at best, just like most of phoronix's articles.
Perhaps we could use these numbers to measure progress on the m2+ linux port and m2+ linux performance?
Certainly, there is great work being done by the Asahi team. I'm sure Phoronix will return next year and post an article measuring the year over year gains on Asahi
Great work by Phoronix as well posting the initial results, as well as creating the open-source test suite so anyone can run it on their own hardware any time they would like.
The price of the Ryzen computer seems to be much higher, unless I'm missing something: $3 310 vs perhaps $2 100 (both models with their disks = 2TB, couldn't find the 512GB Lenovo model so moved the MBA up too).
The fact you are probably missing is that not many people pay the Lenovo sticker price. They routinely get heavy discounts once they have been available for a few weeks.
This is also true for other enterprise brands such as HP and Dell.
I guess they do that because they target mostly businesses and it gives them more flexibility when negotiating bulk deals.
Makes sense, thank you for the explanation. And now that I know I see that there is a banner ad in that website about a coupon for a weekend deal which brings down the price to around $1 985, which seems more reasonable.
I wonder what's the appeal for bumping up the prices but routinely offering discounts. I guess they might sell some fully priced computers.
I see! I just went by the model name mentioned in the article but I admit I don't know much about Lenovo (even though I have one, which I rarely use). Thank you!
While it's not currently available to purchase on that page, the version tested was 16GB (not 32GB), and presumably screen, storage, etc. factor into the higher price. I'd expect closer to the $2,195 Ryzen 5 Pro / 16GB system price. Somewhere in between that and $3,309.
But given the way this testing was done, there's little reason to step up from the $1,499 Air, either, though testing the $1,699 Air with 16GB would've alleviated any potential concerns about RAM affecting benchmark scores.
Given the likelihood that each side could see improvements from code changes and optimizations, and that the results are similar-ish, that leads me to say that one is just as good as the other in general.
This is especially true for most people, because most people will not be doing any one of those workloads _most_ of the time. Most of the time of computer use is doing many different things (at the human level and the software level), so the final compute comparison is basically comparing the difference of a small percentage of overall human time.
So the choice between M2 and Ryzen is really about everything else - the use case, the hardware styling, the OS features, etc.
It's good to know this benchmark info, though, because it means we can cross that concern off mentally.
Does anyone know what the reasons might be to compile the Ngspice benchmark with -O0? Oh, nothing nefarious, it seems to be the (IMHO misguided) default settings:
"--disable-debug
This option will remove the '-g' option passed to the compiler
and add -O2 optimisation (instead of default O0).
This speeds up simulating significantly, and is recommended for
normal use."
I'd love a more direct and comparative benchmark set though e.g. Apple M2 on macOS vs. Ryzen Pro 6850 on Linux, and with at least identical RAM.
To me Apple M1 (and maybe M2, have not checked it out yet) remains an absolute leader in performance per watt. Combine the amazing displays and it's almost not a contest. Of course, like every programmer I started getting irritated by macOS because a lot of tinkering and experimentation is simply not possible there.
I really hope for at least comparable Linux competitor. Even being behind the M1/M2 with 30% for the same power envelope would be a huge win.
None of these comparisons manage to sink the Apple chip which is what Intel/AMD ultimately wants. If the myth that x86 is always going to be better isn't quelled enough then it starts to become irrelevant as ARM takes hold. So a lot of this is to try to support it through proof in benchmarks. I'm not saying that's the intent of phoronix.com - far from it. But that's a general philosophy which skewing benchmarks one particular way.
> "the myth that x86 is always going to be better"
> "a lot of this is to try to support it through proof in benchmarks"
There is no myth that x86 is always going to be better. Apple created a great architecture, but we can't all migrate to Macs, and sometimes we can't even afford to migrate to ARM. Not because of ideology, but because of legacy systems.
So these benchmarks are not to support any kind of propaganda, just trying out new chips to see if we can finally get the same generational leap on the PC as well.
Who cares about what Intel/AMD wants. Phoronix isn't the puppet of any of them, just another enthusiast user trying to inform.
There is a lot of enthusiasm for M1/2 on hn. A majority of it justified on technical merit, but also a decent dose of Reality distortion field involved I think.
I have two flagship ryzen 7 5800 series OMEN HP gaming laptops. I love them. The graphics of the RTX laptop cards allow me to run things like STRAY and CONTROL at epic graphics for a laptop...
What SUCKS is Windows 11. This bitch crashes more than any other Windows I have used in history dating back to 3.11
Jeasus, this OS sucks.
The AMD v Intel BS means nothing to me. The guts are good, the body is strong, but the soul is too soft.
> Due to the Apple M2 currently lacking any power/temperature sensor support under Linux, this is simply looking at the raw performance of the M2 and Ryzen 7 PRO 6850U with not being able to accurately compare the M2 power efficiency / performance-per-Watt at this time.
Really surprised that anyone would consider this a fair comparison. Thermal management is a huge factor to consider with these tests given safety limiters reduce CPU performance.
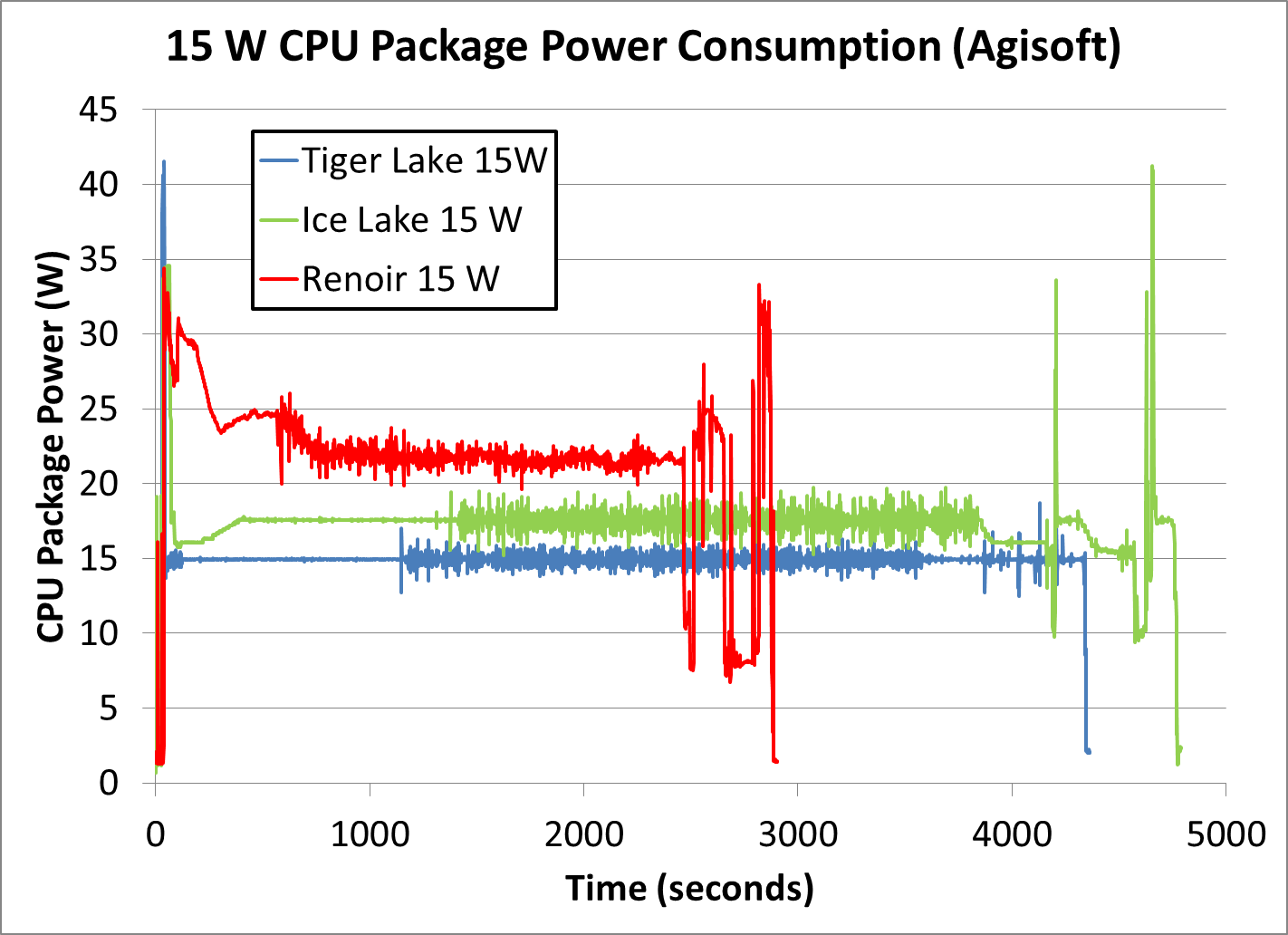{kind=link}
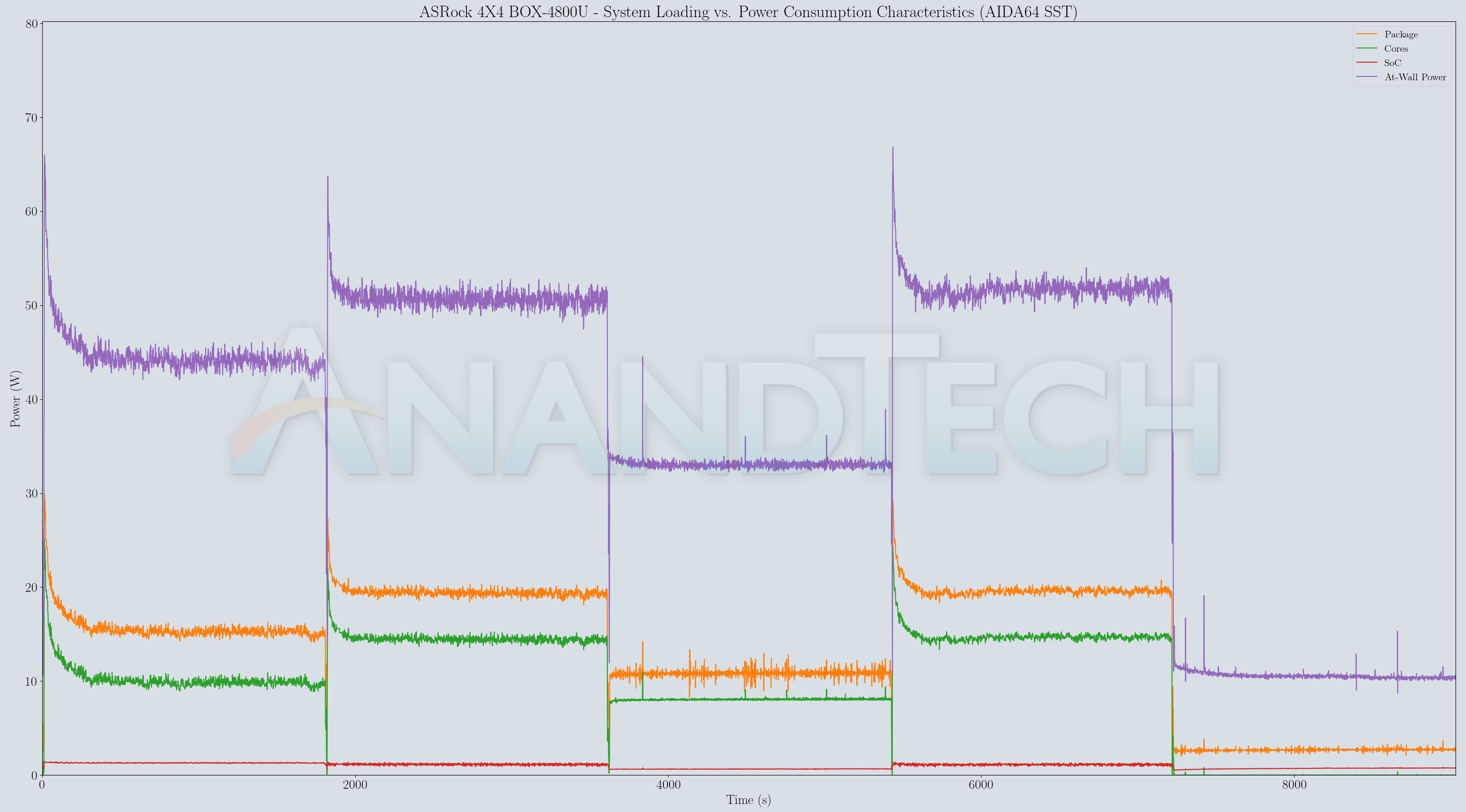{kind=link}
{kind=link}
{kind=link}
1. The Ryzen setup has twice the ram
2. The Ryzen setup has twice the cpu cores
3. The Ryzen setup has 3x the power envelope (in watts) as the M2[1]
4. They are using Asahi Linux on the M2.[2]
Too bad I missed the window to downvote.
If this said: Apple M2 (Linux/8gb/4c) vs. Ryzen 7 Pro 6850U (Linux/16gb/8c)... it would have been more honest, and potentially interesting, as it would also be an indication of the progress of Asahi Linux.
(edited to add line breaks)
[1]: Ryzen 46w (not sure if this includes the GPU) vs M2 15w (not sure if this includes the GPU)
[2]: Asahi Linux is super cool, but most M2 chips in the wild are not running it. So it's not a useful comparison.