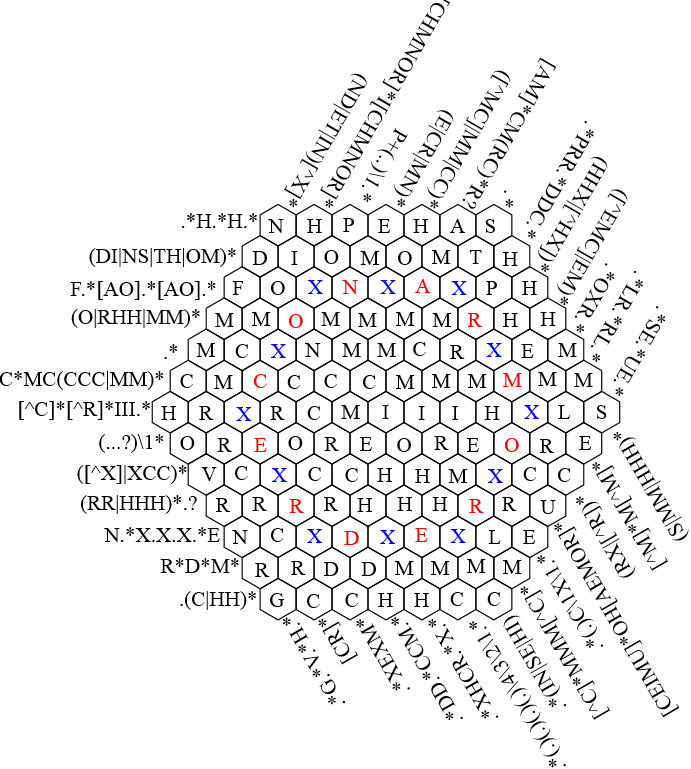
So many of these start or end with an `x*`, `(x|y)`, `[xy]` or `[^xy]` that I only see two characters I can fill in before I need to start looking at multiple constraints for the same cell and either doing combinatorics or guess-and-check.
This might be fine for hard mode, but as someone who considers themselves a regexpert it's not very approachable as a first puzzle IMO.
A more gradual introduction to the format would be to give a few clues that give you confidence on specific characters, that then let you lock in some other characters in other hints, and so on.
For instance, replacing `.*H.*V.*G.*` with `.{3}H.*V.*G.*` would go a long way because you could confidently place an `H`. And say that intersected with `(DI|NS|TH|OM)*` on the `H`, you could then place a `T` from the second clue because of what you learned from the first clue.
It could just be that I'm missing something or not as good at regex as I thought, and please let me know if that's the case. Either way though, when I'm trying a new kind of puzzle I'd like to feel like I made some sort of progress after trying for 5-10 minutes, and here 2 chars does not feel like progress.
I just completed it, and can say with certainty that it is solvable by only taking into consideration two constraints at any given time, with the exception of 3 at just one point early on (and they were the easier constraints in the puzzle). That being said, the nature of regex means you kind of need to jump around as far as which constraints you combine.
I don't doubt that, and I don't doubt it's a good puzzle, especially if you're already familiar with the format.
But since this is my first introduction to this kind of puzzle, I need some anchor points at the beginning so I feel like I have something to work off of.
I'm not even asking for a whole row, just an easier set of known chars at the start of the round so I have a hint at which of the 39 constraints I should start with.
To be honest I'm not even saying this puzzle should change so much as I am looking for a different puzzle to dip my toes.
I don't have any interest in starting the puzzle if I don't feel like I can put a foot down somewhere. It's like trying your first Minesweeper game, making two random clicks, and getting two `7`s. Where do you go from there? Or learning Sudoku from the hardest difficulty level, without having built up a library of patterns from the easier difficulties.
I did complete and enjoy it, but I'm both very competent with regex like you, but also big into sudoku variants (as in the youtube channel cracking the cryptic! [1]) so this felt like it was designed for me to enjoy. Considering it took me about half an hour, I'd expect someone who isn't into these kinds of odd puzzles already to basically have exactly your reaction.
I don't watch regularly (and I would consider myself a sudoku dabbler) but I've seen some Cracking the Cryptic videos in the past and enjoyed them greatly.
Yeah I definitely get that. I've never done a puzzle of this type before, but I have done a hell of a lot of logic puzzles (thanks to the Simon Tatham collection among others) so I was able to figure out a good attack vector. I agree, it wasn't easy to find where to start nor where to make progress in the beginning. Lots of data to ingest.
It's clearly in NP. One way to solve it is to order the squares in some order and combine all the NFAs in some nasty wreath product construction. Then we seek an accepting string. While this has an exponential state size blowup you may be able to construct lazily in the BFS and perhaps that keeps the complexity down.
Depends what you think N is doesn't it? What would be a variable parameter in this puzzle? The number of letters in the alphabet? The size of the regex expressions? The size of the board?
I fully agree. I think it's a really interesting concept but it's missing a bit of game design skill so far.
I had the same experience when I tried it yesterday. There doesn't seem to be any good "starting point", like there is on a traditional crossword puzzle or sudoku.
I think from a game design perspective it is really interesting though: Like sudoku, this kind of puzzle gives you a wide range of options to archive different player experiences and difficulty levels: You can make easy levels by mostly using constant-width regexes and non-conditional letters and you can slowly increase the difficulty level by making regexes less constrained and more ambiguous. A designer could even craft specific "paths" through the puzzle by combining easy and hard regexes.
Finally, a designer could gradually introduce more complex regex features (or other patterns, like multiple constraints) over successive leves.
There are actually four spaces that can be filled by accounting for only a single pattern. Two of those are at the end instead of the beginning.
I agree it definitely feels imposing when you first look at it, but stick with it. Look for spaces that have a very small set of possibilities, and then try to map out what neighboring spaces could have for each possibility. If you really feel stuck, take a screenshot and mark it up.
https://regexcrossword.com/ have a lot of great puzzles with a gentler learning curve but I liked the challenge of this one, so I think it would have spoiled the fun a bit for me.
I found other patterns that I thought were unsimplified, but (spoiler alert) in the end it turned out that all of the seemingly-unnecessary details were important for the solution! E.g.
[^C]*[^R]*
LOOKS unsimplified, but it actually means that if the string contains an R, the preceding characters CANNOT be C.
Not really. Maybe I'm being overly pedantic, but my point was that the first two ways of describing it are overly specific and don't include all the strings that can be matched. Only the third option really describes all the possibilities.
No, (X|H|H|[^XH])*` or ([XHH]|[^XH])* would be equivalent to .*, but (XHH|[^XH])* requires that XHH appear consecutively in that order whenever they appear at all.
Small feature request for this implementation: Highlight/bold the three impacted regex when selecting a given hexagon, trying to trace it manually by eye is a bit of a pain.
(I guess I could PR on github when I get some time later today)
I was so happy when I found it again! I was looking through my pictures folder and found this thing that I made the first time I saw your implementation https://helvetet.com/_filedump/crossword.gif
I solved this in about 1.5 hours by starting at the top left, entering any string that satisfied at least one condition, then moving on to the next condition and “fixing up” any previous entries. I was fearful that I might arrive at a nearly correct solution that I would have to massively backtrack from, but it didn’t happen - I only needed a few short backtracks. I think the large number of constraints helps a lot.
Spent a similar amount of time... Ended up with a "solution" that breaks 1 constraint. Must have erred somewhere, but backtracking is only leading to other 1-broken constraint outcomes. Sigh.
Oooh, I was stuck because I was insisting on `.(1)(2)(3)(4)\4\3\2\1.` having the middle eight characters mirror each other, which results in a clear contradiction with a few of the crosses.
Thanks for posting the answers. I think I'm done working on it for now, but that one was really bothering me.
Because of the ".*" on either end, it's just having a sequence of 8 somewhere that are mirrored, could be the first 8 or last 8, not strictly the middle 8.
Yeah, sorry for the bad formatting. I probably should've taken the time to make it not markdownify the asterisks. Without them, it is mirroring the middle eight.
This is an absolute classic! It is not just an exercise in tedium or repetition, it has an internal progression that makes it very satisfying to solve.
This is awesome. I wish there was a way to rotate the cells so you could see them straightened out. Otherwise, this is like the final boss to every Regex Golf game I've seen
The hexagonal layout allows three regex constraints to be imposed on each cell rather than two for a rectangular layout, providing additional challenge.
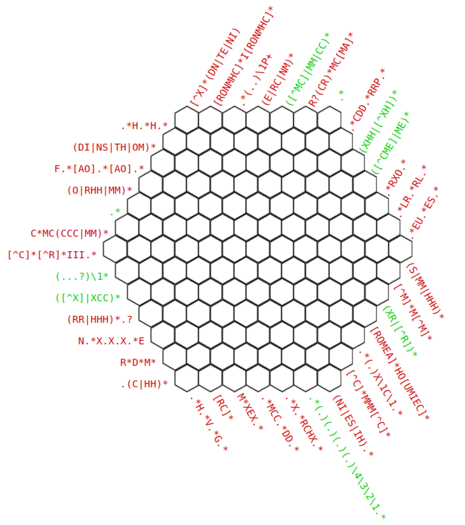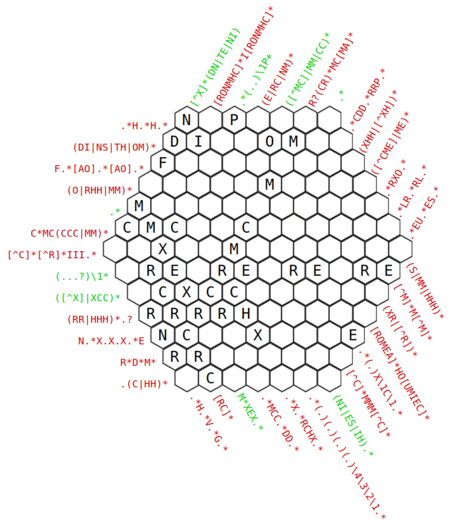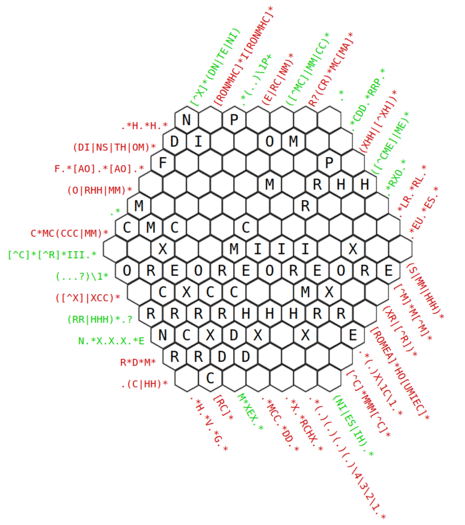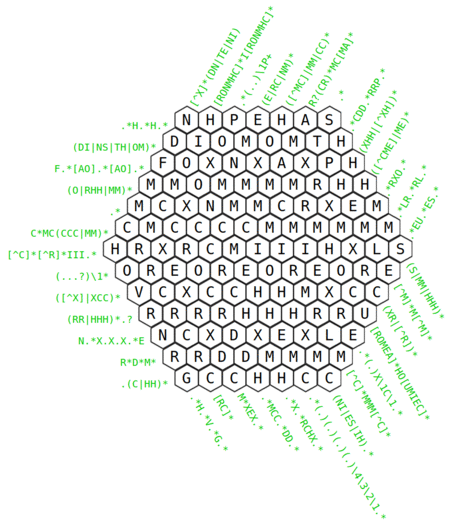
As far as I can tell, the puzzle is fully constrained.
From the start, the bottom-left cell as well as the right column can be solved just from the starting hints, and then you can derive the top-left cell per the backreference.
In particular, you can reframe the right column's hint as (AB|OO|OR), and only one of those satisfies the bottom row's hint.
Ah. The difference is that you're trying partial matches, as opposed to full matches from the specified patterns.
edit: and by full match (since this seems to be the source of some confusion in another subthread), I explicitly mean anchored with your \A...\Z or whatever you want to use.
There are plenty of normal regex crosswords out there. What makes this one special is the fact that it's in a hex format. If anything, regex is actually what allows people to even make hexagonal crosswords, I don't think it would possible to get any reasonably sized one with normal words.
They just went the extra mile to make an special puzzle.
8 spaces does not in any way match the language described by that regex. Not a partial match, not a full match.
Plugging the first space into a DFA described by the regex is an immediate failure - there is no exit from the initial state initiated by the space character. It's a non match.
Regex engines will say they do match because they are by default checking for for substrings that match the language (such as the initial empty string of each line of grep), not for strings that match the language.
I don't know what any of your three statements actually mean.
R*D*M* does not specify anything that has to be found in the string. Nor does any pattern of ()* or []* no matter what you put between the parens or brackets.
In all of those cases, any possible string matches the regex starting at the beginning of the string and ending at the end of the string.
Your clarification doesn't clarify anything for me.
The regex crossword is working on the basis of matching the entire input string (of " "), not on finding a substring that matches the regex. You can prefer to think of it as having all regexes have an implicit ^ and $, i.e., you're attempting to find a substring that matches "^RDM*$".
The issue is two different types of regex notation.
Some regex notations include "^" and "$", and some don't. A lot of software (the grep command, for example) uses the kind that does support "^" and "$". This puzzle uses the other kind.
Essentially, when a notation includes "^" and "$", it allows writing cleaner more concise patterns. These notations add an implicit "." at the beginning and end of every pattern unless you use "^" or "$" to turn that off.
As for how you're supposed to know this, the puzzle tell you, but there is a very strong clue, which is that many of the patterns have a leading/trailing ".". This would be totally superfluous in one type of notation, so it must be the other kind.
Here are some patterns from the puzzle's notation:
.*H.*H.*
(DI|NS|TH|OM)*
F.*[AO].*[AO].*
and here are how they'd look in a notation that uses "^" and "$":
To be fair, the puzzle didn't tell them at the time of their post, I added the "must be a full match" line after seeing confusion here, and it was not in the original puzzle (people doing puzzle hunts are expected to deduce more than random people on the internet, I guess!).
A full match has to exhaust all of the characters in the string. R*D*M* is indeed a match for a string of eight spaces, but it isn't a full match, because there are still eight spaces left over after matching.
I think that was between 1 and 1.5 hours to solve. Was a fun puzzle! Though for some reason my brain was expecting the NYT Crossword completion music when I filled that last hexagon...
Look at the original MIT Mystery Hunt page (and solution). It was part of a puzzle hunt. (I was one of the people who successfully solved it on my team during that very event back in 2013...)
See this comment for the link to the original, including the author's name and the puzzle in context with its official solution:
(I wish that other comment would get upvoted to the top -- this was written by an identifiable person for a specific identifiable puzzle event, so it's not like mysterious anonymous Internet folklore or something.)
Hah! I was beginning to suspect there existed some pattern or answer in the result and was looking for an answer. The better part of 2 decades of mystery hunt has conditioned me. I see a four-letter snack in there that jumps out as a possible solution. Should we call hq?
If you fancy making an online crossword, I once made a nice traditional crossword layout using CSS Grid that makes a decent basis - https://codepen.io/onion2k/full/KRQeqm
Solved it! I kept tilting my head because it was hard to see the clue and interpret it at the same time. The ability to highlight all three diagonals would have been perfect.
The final clue I had to complete was that tricky .*(.)(.)(.)(.)\4\3\2\1.*
> I kept tilting my head because it was hard to see the clue and interpret it at the same time.
Agreed, I definitely found myself doing that.
> The final clue I had to complete was that tricky .(.)(.)(.)(.)\4\3\2\1.
Interesting...I think I had the main guts of that one worked out when I was about 1/3 of the way through, but admittedly I did take a screenshot and mark it up in order to keep track of the various possibilities. It was (...?)\1* that tripped me up because I had an overly broad interpretation of its mechanics.
I wonder if it would be possible to record a bunch of 0-100% runs and then to make some sort of visualization to demonstrate different approaches...
OMG, I was having the hardest time figuring out what 3 regexes applied to each hex. Then I reloaded partway through and the HIGHLIGHTING started working.
Reload if you don't see the regexes turn bold when you click in a hex!
This confirms my long-standing annoyance with regexes: the dot is poorly visible among other characters and jumps out at me when I'm already thinking of a match.
I think it would be more satisfying if the result was some human-readable text rather than a random selection of characters. Otherwise, interesting concept!
In the context of the original MIT Puzzle Hunt, there is a single word or phrase that comes out of solving the entire thing, but, yeah, would be interesting if it were all words!
Having the words everywhere would take away some fun, because the solution space would become severely constrained. Like with those DI|NS|OM expressions or that (...?)* line.
nice, solved it in about half an hour. At first it looked impossible past the first maybe 5 free characters. I feel like there were a lot of characters that had to be solved sudoku-style by holding up to 4 constraints in mind at the same time, which was tricky.
There is an answer extraction, though, because it's a Mystery Hunt puzzle (where all puzzles extract a word or phrase as an answer at the end). It's just that the individual diagonals in the grid as a whole are not themselves words.
It has to be fake words. It's possible to see this because some of the words have to contain things like "cdd", "rrp" and "rxo", which aren't part of any real words.
Plus, now that I think about it, having a grid without the gaps usual crosswords have would be very complex to create with actual words. Even more so when using hexagons.
Right away the red and green hints are wrong. Either that or this puzzle used RegEx rules that contradict those I am familiar with. Either way, they lost my attention.
That's not the case... .(C|HH)* matches with single character followed by any number of C's or HH's. So " " or "B" would work but in the puzzle the full line has to match so those aren't possible
As you can see[1], the regex checker is based on the JS RegExp.match method. Each cell is always 1 character long (so, either a letter of some kind or an empty space). The str parameter for the check function is assembled by concatenating these cells together[2], so the input string for an empty line will look something like this: "_______"
Assuming an empty 7-cell row, the regex in question will match 7 times, once for each character. A result of multiple partial matches is not equivalent to getting just one perfect match, which is what the puzzle requires. Internally, the puzzle enforces this requirement by making each Regex rule require a full line match (see line 118: '^' + rule + '$').
Personally speaking, I felt like that was the most intuitive way to interpret the mechanics of the game, so I'm willing to give the programmer a pass when they slightly modify the regex rule prior to evaluation.
Some people would be correct to think that. That is what those regexes mean. If you are secretly prepending a ^ and appending a $, then you are not using the regex displayed.
Sorry, but you're wrong. There's nothing about regular expressions that means you have to use them to search for matching substrings. That's just one particular operation that uses regular expressions. It's not a quality inherent to regular expressions themselves. There are many different operations you can perform with a regular expression besides a substring search.
Python, for example, has a fullmatch method.[0]
libicu's matches() function returns true "if the pattern matches the entire string, from the start through to the last character."[1]
PCRE has various flags that change what it means for a regular expression to match, including PCRE2_ANCHORED and PCRE2_ENDANCHORED. Used together, these options would require a full match with no change to the regular expression itself.[2]
Another way to describe this could be that the meaning here is inherently ambiguous between "is-a" and "has-a", but the puzzle only makes sense (and only has a solution) if you interpret as "is-a".
In Mystery Hunt puzzles, which this originally was, "we have to interpret this in a way that would allow there to be a meaningful and unique solution" is not only a perfectly legitimate form of reasoning, but often necessary!
It's not really exactly the same kind of reasoning, but in a puzzle I wrote a year before this for the same event
you could look at it and say "hiragana is only ever allowed to be used to write Japanese!!!" but insisting on that rule (much as it applies in most situations) wouldn't give the puzzle a meaningful solution. :-)
Maybe a closer equivalent would be that in this year's Mystery Hunt, there was a puzzle using a set of variant Hashiwokakeru (Bridges) logic puzzles. There were hints about which rules were changed but it wasn't stated whether the rule changes applied individually (one puzzle each) or cumulatively (when rules get changed, they don't change back afterward), or some other way. So, it was necessary to make assumptions about what was meant and see whether they allowed a solution. That's typically considered fair and appropriate throughout Mystery Hunt-land.
{kind=link}
{kind=link}
{kind=link}
This might be fine for hard mode, but as someone who considers themselves a regexpert it's not very approachable as a first puzzle IMO.
A more gradual introduction to the format would be to give a few clues that give you confidence on specific characters, that then let you lock in some other characters in other hints, and so on.
For instance, replacing `.*H.*V.*G.*` with `.{3}H.*V.*G.*` would go a long way because you could confidently place an `H`. And say that intersected with `(DI|NS|TH|OM)*` on the `H`, you could then place a `T` from the second clue because of what you learned from the first clue.
It could just be that I'm missing something or not as good at regex as I thought, and please let me know if that's the case. Either way though, when I'm trying a new kind of puzzle I'd like to feel like I made some sort of progress after trying for 5-10 minutes, and here 2 chars does not feel like progress.