"all you have to do is read the methods section in the paper and follow the instructions."
I wish science was that simple. The methods section only contains variables the authors think worth controlling, and in reality you never know, and the authors never know.
Secondly, I wish people say: "I replicated the methods and got a solid negative result" instead of "I can't replicate this experiment". Because most of the time, when you are doing an experiment you never done, you just fuck it up.
Here is an example: we are studying memory using mice. Mice don't remember that well if they are anxious. Here are variables we have to take care of to keep the mice happy, but they are never going to go to the methods section:
Make sure the animal facility haven't cleaned their cages.
But make sure the cage is otherwise relative clean.
Make sure they don't fight each other.
Make sure the (usually false) fire alarm hasn't sound for 24 hours.
Make sure the guy who was installing microscope upstairs has finished producing noise.
Make sure there is no irrelevant people talking/laughing loudly outside the behaviour space.
Make sure the finicky equipment works.
Make sure the animals love you.
The list can go on.
Because if one of this happens, the animals are anxious, then they don't remember, and you got a negative result which have nothing to do with your experiment (although you may not notice this). That's why if your lab just start to do something you haven't done for years, you fail. And replicating other people's experiment is hard.
A positive control would help to make sure your negative result is real, but for some experiments a good positive control can be a luxury.
A lot of the commenters are trying to come up with technical solutions to the issue. It belies their incomplete study of the 'softer' sciences and the difficulty of biological studies. Tech solutions won't work, bureaucratic solutions wont work, more data wont work.
Guys, the bio side of things is incredibly complicated and trying to set controls that are achievable in your time and budget is the heart of these fields. The thing you are trying to study in the bio side of science is actually alive and trying to study you right on back. If you are going to kill the thingys, they really do want to kill you too. Look at this diagram of mitochondrial phospholipid gene/protein interactions (https://www.frontiersin.org/files/Articles/128067/fgene-06-0...). That is very complicated and that is for one of the best studied organelles in the Animalia family. There are an uncountable and evolving set of other proteins that then interact with that diagram in different ways depending on the cell-type, species, and developmental history of the organelle (to start with). All of which are totally unknown to you and will likely forever remain unknown to you up until your death. Hell, we are still figuring out the shapes of organs in our own bodies. People that have studied areas for decades spending untold millions of dollars on some of the most central questions of life have essentially nothing to say for themselves and the money spent('We dream because we get sleepy'). Trying to tease out a system that has been evolving for 4.5 billion years and makes a new generation (on average) every 20 minutes is going to be just insanely difficult.
This stuff is hard, the fields know it, and we don't believe anything that someone else says, let alone what our 'facts' and experiments tell us. But we solider on because we love it and because we want to help the world.
I think there's also a lot of confusion about what the scientific literature should be.
Outsiders think of journals as pre-packaged nuggets of science fact, with conclusions that you can read and trust.
Scientists who publish in the journals view them as a way to communicate a body of work of "I did this, here is the result I saw. I think it might mean this."
The difference between these two views can not be understated. Each group wants the literature to be useful to them, so that they can use it, and that's understandable.
For most areas of science, especially in the early days of that science, it's absolutely essential that scientist's view be allowed to persist. Is it better to share early, or to wait to publish until you've tried all possible things that could potentially go wrong? I think the answer is obviously that you share the early data, and what you think it means, even if you may be wrong about it.
If the goal is to advance knowledge as quickly as possible, I think that the scientist's view is probably a better idea of what a journal needs to be than what the outsiders' view is. In some fields, like fMRI studies, the field is realizing that they may need to go about things differently. And that means that a lot of the interpretations that were published earlier are incorrect. But that process of incorrect interpretation to corrected interpretation is an essential part of science.
Scientists and academic institutions add to the confusion with the way they promote their work. Nobody puts language like "I did this, here is the result I saw. I think it might mean this" in a press release. It's always "Breakthrough research! Is the end of cancer in sight??"
A lot of this is because of the incentives that result from grant-based funding of science. Your ability to continue to do science is contingent on your ability to find someone to pay for it; it's much easier to convince someone to pay for it if you can point to headlines that say "Breakthrough research! Is the end of cancer in sight?"
The old system of "gentleman science" (where only independently-wealthy heirs did science, as a hobby) had a lot of problems and wouldn't really be workable today, but one thing it had going for it was that the scientist could count on the funding being there tomorrow, and so had much less of an incentive to overstate their work.
Absolutely true, though I know of very few scientists that have been able to tamp down the game of telephone that the university's press office starts.
Probably, the real problem is that "the scientific literature should be". It's not the right question to discuss today, because scientific literature is just a brief approximation of scientific knowledge and this is not what we need. Whole modern scientific system is outdated and has to be upgraded: journals, citation indexes, degrees should go away and be replaced. Science should become more formal and more digital, so that it will be easier to find and validate the results. There should be databases, search engines and digital signatures of the raw data and chains of proofs. Counting citations should be replaced with counting chains of proof produced by the scientist and included in others' works. Reliability of proof and contribution to ratings should be based on independent confirmations, which should be counted too - replication of new results should be considered an achievement too. Journals may remain, but not as a primary way to exchange scientific information - more likely, they should become the portals to the data which will link the results in databases to their human-readable interpretations.
Respectfully, I think you're missing the complications outlined in the rest of the thread. The difficulty in the biosciences and even in chemistry and some physics is that they can't really be formalized in the way that is necessary to construct these "chains of proof".
The scientific literature is an ongoing conversation anchored by rigorous experimental facts and data. But rigorous doesn't mean it's clean like a mathematical proof. In fact, most science approaches its "proofs" in quite a different way than math. For example, as far as science would be concerned P!=NP in complexity theory. We've done the experiment many times, tried different things, it's pretty much true. But it's still not mathematically proven because there isn't a formal proof.
That's not to say it's invalid to expect more rigor, or that we wouldn't all love to have "chains of proof" and databases and signatures for data etc. It's that it's simply not practical given how noisy and complex biological systems are. In contrast to math, you pretty much never know the full complement of objects/chemicals/parameters in your experimental space. You try to do the right controls to eliminate the confounding variables, but you're still never fully in control of all the nobs and switches in your system. That's why usually you need multiple different experiments tackling a problem from multiple different approaches for a result to be convincing.
Formalized systems would be great, but I don't think we're even close to understanding how to properly formalize all of those difficulties and variables in a useful way. And it may not even be possible.
Whilst the experimental subjects and data collection are inherently fraught with difficulty, there's still a LOT of low-hanging fruit regarding things like automation. Many scientists use computers to write up results, to store data and perform calculations, but there's often a lot of manual, undocumented work which could easily be scripted to help those re-running the experiment. For example, running some program to produce a figure, without documenting what options were used; providing a CSV of data, without the formulas used for the aggregate statistics; relying on a human to know that the data for "fig1.png" comes from "out.old-Restored_Backup_2015~"; etc.
Such scripting is a step on the path to formalising methods. They'd help those who just want to see the same results; those who want to perform the same analysis using some different data; those who want to investigate the methods used, looking for errors or maybe doing a survey of the use of statistics in the field; those who want a baseline from which to more thoroughly reproduce the experiment/effect; etc.
The parent's list of mouse-frighteners reminds me of the push for checklists in surgery, to prevent things like equipment being left inside patients. Whilst such lists are too verbose for a methods section (it would suffice to say e.g. "Care was taken to ensure the animals were relaxed."), there's no reason the analysis scripts can't prompt the user for such ad hoc conditions, e.g. "Measurements should be taken from relaxed animals. Did any alarms sound in the previous 24 hours? y/N/?", "Were the enclosures relatively clean? Y/n/?", "Were the enclosures cleaned out in the previous 24 hours? y/N/?", etc. with output messages like "Warning: Your answers indicate that the animals may not have been relaxed during measurements. If the following results aren't satisfactory, consider ..." or "Based on your answers, the animals appear to be in a relaxed state. If you discover this was not the case, we would appreciate if you update the file 'checklist.json' and send your changes to 'experimentABC@some-curator.org'. More detailed instructions can be found in the file 'CONTRIBUTING.txt'"
I like the idea, but who the hell is ever going to go through all of that? Yes, you made some checklist, great. But no other lab is going to go through all of that. And in your field, if you are very lucky, you may have just 1 other lab doing anything like what you are doing. It would be a checklist just for yourself/lab, so why bother recording any of it? Yes, do it, fine, but how long should you store those records that will never be seen, even by yourself? Why in god's name would you waste those hours/days just going over recordings of you watching a mouse/cell/thingy to make sure of some uncountable number of little things did/did not happen? If you need that level of detail, then you designed your experiment wrong and the results are just going to swamped in noise anyway. You are trying, then, to fish out significant results from your data, the exact wrong way to run an experiment. Just design a better trial, there is no need to generate even more confusing data that has a 1/20 chance of being significant.
The checklist is not required to be on such level of detail. It just has to exist and it has to be generic enough. It's interesting to see here example with fire alarm: to me existence of such factors is the smoking gun of potential improvements to the experimental environment. Why not excluding ALL stress factors by designing something like sound-proof cage? Needs extra budget? Probably, but how about some another unaccounted noise that will ruin the experiment? This gives us an idea of better checklist: ensure that experiment provides stressless environment by eliminating sound, vibration, smells etc.
> who the hell is ever going to go through all of that?
It's not particularly onerous, considering the sorts of things many scientists already go through, e.g. regarding contamination, safety, reducing error, etc.
> Yes, you made some checklist, great. But no other lab is going to go through all of that. And in your field, if you are very lucky, you may have just 1 other lab doing anything like what you are doing. It would be a checklist just for yourself/lab, so why bother recording any of it?
Why bother writing any methods section? Why bother writing in lab books? I wasn't suggesting "do all of these things"; rather "these are factors which could influence the result; try controlling them if possible".
> Yes, do it, fine, but how long should you store those records that will never be seen, even by yourself?
They would be part of the published scientific record, with a DOI cited by the subsequent papers; presumably stored in the same archive as the data, and hence subject to the same storage practices. That's assuming your data is already being published to repositories for long-term archive; if not, that's a more glaring problem to fix first, not least because some funding agencies are starting to require it.
> Why in god's name would you waste those hours/days just going over recordings of you watching a mouse/cell/thingy to make sure of some uncountable number of little things did/did not happen?
I don't know what you mean by this. A checklist is something to follow as you're performing the steps. If it's being filled in afterwards, there should be a "don't know" option (which I indicated with "?") for when the answers aren't to hand.
I imagine it would be easy to have a git-like storage system for this information, where reproduction experiments would be a branch without the actual measurement data.
> a specification for describing analysis workflows and tools in a way that makes them portable and scalable across a variety of software and hardware environments, from workstations to cluster, cloud, and high performance computing (HPC) environments. CWL is designed to meet the needs of data-intensive science, such as Bioinformatics, Medical Imaging, Astronomy, Physics, and Chemistry.
While this is interesting to speculate about, perhaps it would be best to start with something like the machine learning literature, where everything is already run computationally, and those in the field have the skills to easily scratch their own itch to improve the system so that it works for them.
Even in machine learning, how difficult would it be to get that field to adopt a unified experiment running system? It sounds like a huge engineering project that would have to adapt to all sorts of computational systems. All sorts of batch systems, all sorts of hadoop or hadoop like systems. And that's going to be far easier than handling wet lab stuff.
I think that the lack of something like this in ML shows that there's enough overhead that it would impede day-to-day working conditions. Or maybe it just hasn't been invented yet in the right form. There are loads and loads of workflow systems for batch computation, but I've never encountered one that I like.
In genomics, one of the more popular tools for that is called Galaxy. But even here, I would argue that the ML community is much better situated to develop and enforce use of such a system than genomics.
I agree that computational fields are more well-suited to spearhead such approaches, but I don't think machine learning is a good example. ML researchers are constantly pushing at the frontiers of what our current technology can do; consider that a big factor in neural networks coming back into fashion was the ability to throw GPUs at them. The choice of hardware can make a huge difference in outcomes, and some researchers are even using their own hardware (the work being done on half-precision floats comes to mind); any slight overhead will get amplified due to the massive amount of work to be computed; and so on.
Maybe a field that's less dependent on resources would be a better fit. An example I'm familiar with is work on programming languages: typechecking a new logic on some tricky examples is something that should work on basically any machine; bechmarking a compiler optimisation may be trickier to reproduce in a portable way, but as long as it's spitting out comparison charts it doesn't really matter if the speedups differ across different hardware architectures.
When the use of computers is purely an administrative thing, e.g. filling out spreadsheets, drawing figures and rendering LaTeX (e.g. for some medical study), there's no compelling reason to avoid scripting the whole thing and keeping it in git.
I thought that statistics is the right tool to handle uncertainity? I had the impression that all the "soft" science is based on statistics. We can't prove that smoking kills people. But, given a certain confidance interval (or whatever equivalent measure for baysian statistics?), we can state that smoking is not a good idea if you want to live longer than mean expected years...
Sure, some unforseen event may interfere with your experiment. But statistics should account for that, shouldn't it? Just wondering..
Statistics is also the way to look at data in the "hard" sciences. Every measurement has error, and that's how you deal with it.
However it's not a simple thing that automatically combines different studies. It takes skilled application to understand how data connects, what's comparable, what's not, etc. Traditionally, "meta-analysis" is the sub-field of statistics that combines studies. But that only combines extremely simple studies, such as high-controlled clinical trials. It's inappropriate for the complex type of data that appears in a typical molecular biology paper is a chain of lots of different types of experimental setups.
Those who don't know the body of stats, trying to reason about application, is a lot like an MBA trying to reason about software architecture. The devil is in the details, and the details are absolutely 100% important with application of statistics to data.
Amen. You can google the controversy around the StatCheck program to really dive into why stats and their applications are beyond lies and damned-lies in their falsehoods (because you can prove the lie is right). Doing something as simple as smoking causes cancer is a very very simple experiment to interpret (hard to fund/preform though). It's the pernicious little studies on 8 cells total that get messy. Preforming a lot of experiments is hard.
I knew of a student that graduated with only 8 cells of data out of his 7 years in grad school. That may sound like a small amount, but to his committee, it was a very impressive number. He (very very) basically sliced up adult rodent brains and then used super tiny glass pipettes to poke the insides of certain cells. He chemically altered these cells' insides in a hopefully intact network of neurons, shocked the cells, and then recorded the activity of other cells in the network using the same techniques. Then he preserved and stained the little brain slice so he could confirm his results anatomically. From start to finish, it took him 13 hours total, no lunch or restroom breaks, every day, for 7 years. He got 8 confirmable cells worth of recordings total.
That is a hard experiment. But due to his efforts in adding evidence we now suspect that most adult hearing loss is not due to loss of cells in the ear, but in the coordination of signals to the brain and their timing mis-match. It is not much, bu it adds to the evidence and will for sure help out people someday.
To add, he is now a beer brewer in Bavaria and quit science. This shit takes sacrifice man.
> I had the impression that all the "soft" science is based on statistics.
In medicine, case studies are often used for low n issues. There are too many variables for meaningful statistics to be pulled out, but a "this patient had X, we did Y, Z happened" is still a way to pass on observational information. It's recognised that case studies aren't ideal, but it's still better than not passing on information at all.
Everything can be formalized, even uncertainties in knowledge about experimental environment (e.g. by making a statement that unaccounted parameters do not influence the result - indeed, this will be challenged and proof requested and things like fire alarm affecting mice behavior should be reliably excluded). Something that cannot be formalized, cannot be proven or falsified and thus is not a science. The only difficulty may be to build the necessary apparatus, but that's doable and that's the way to fix the science.
Umm, no. Look at Godel's Incompleteness Theorem. You can prove that you will always be able to make a paradox in any formalized system of logic; at least, under our current understanding of logic. Expanding that (Godel, Escher, Bach by Hoffseader goes into it well) you then can say that any theory of the universe must have holes in it and any machine or system that attempts to formalize the observations will always come up with paradoxes. You are right, you can formalize everything (maybe, jury is still out on that, but I think so), but at the risk of then making paradoxes in the system.
I'm aware of this theorem and it has nothing to do with scientific method, it only gives us an idea of possible results of research and it does not tell us that you cannot formalize life sciences or chemistry. Indeed, there are theories that cannot be proven, but they are itself subject to formalization and research.
> Guys, the bio side of things is incredibly complicated
I always find it amusing when physicists talk about how mind-blowing it is that at the quantum level, things aren't entirely predictable. Over in biology, that's the starting point for everything rather than the final frontier - you don't need ridiculously expensive tools to get to the point where you're finding unpredictable stuff.
(trained as a chemist, grad school in biostats & genetics, now mostly design experiments & clinical trials... I have physics envy, except I don't envy their funding models!)
The double slit experiment is purely random, not unknowable. There is a large difference. In Bio, we will some day conceivably know enough to get to the point where we can build up stat models like the double slit experiment. I'd say that the double slit experiment is still leaps and bounds a better starting point than anything we have in bio and only took ~2 decades to finally parse out. Bio has been chugging along since Watson for ~8 decades before we finally got CRISPR and could really do anything about DNA.
Cre-Lox systems predate CRISPR/Cas9 or CRISPR/Cfp1 approaches by quite some time. If one exists for the system you want to study, they also tend to work better. (floxing the original mouse is, however, substantially harder)
I don't think it's entirely accurate to say that conditional editing of DNA is a new thing. The ready accessibility and combinatorial possibilities, yes, but for targeted conditional knockouts, floxing mice has been a thing for about 20 years now.
My PhD work is trying to address this by developing better ways for scientists to record and communicate their methods/protocols. Methods sections are NOT about providing the information needed to reproduce the work, often even the supplemental information is insufficient. They are a best guess at what needs to be done, and the methods section is often massively condensed due to editor demands and cites other papers that also don't contain the relevant information because some aspect of the method changed between papers. (I could go on and on about this.)
I spent 7 years doing experimental biology (from bacteria to monkeys) and trying to replicate someone else's techniques from their papers was always a complete nightmare. Every experimentalist I talk to about this relates the same experience -- sometimes unprompted. Senior faculty tell a slightly different story, that they can't interpret data of someone who has left the lab, but it is the same issue. We must address this, we have no choice, we cannot continue has we have for the past 70+ years, the apprenticeship system does not scale for producing communicable/replicable results (though it is still the best way to train someone to actually do something).
EDIT: An addendum. This stuff is hard even when you assume that all science is done in good faith. That said, malicious or fraudulent behaviour is much harder to hide when you have symbolic documentation/specification of what you claim you are doing, especially if they are integrated with data acquisition systems that sign their outputs. Still many ways around this, but post hoc tampering is hard if you publish a stream of git commit hashes publicly.
Wouldn't it be hard to achieve deep consistency between experiments, in so many labs around the world, with so different conditions/cultures/etc , and when the experimenters aren't experts in consistency , but in their science ?
Wouldn't it be better to use something like a cloud biology model - where you define experiments via code, CRO's compete on consistency(and efficiency and automation) and since they probably do a much larger volume of experiments than the regular lab, they would have stronger incentives to develop better processes and technologies ?
I work at a cloud bio lab. We run all of our experiments on automation, and all protocols must be defined in code. The latter is both the power and the difficulty -- when your protocol is defined in code it is explicit. However, writing code is both new and sometimes difficult for the scientists that we currently work with (molecular biology, drug discovery). I believe what we are doing is the right model. But it comes with this overhead of transitioning assays to code, so there is that against it. This is mostly just a matter of time though. Another nice thing about code is that you can't tweak it once it's running. You can define your execution and analysis up front to guard against playing with results down the road. Now that being said, there still needs to be a significant change to how research is funded and viewed by the public because pure tech solutions can't solve everything. Our tech can't decide what you pick yo research. It can't dish out grants to the truly important research. So it will take many angles to really solve any portion of this problem.
I do agree, it seems like right model, and will have a large impact.
Between automating labor, economies of scale in purchasing, and access to more efficient technology(like acoustic liquid handling) ,etc - isn't it just a matter of time before cloud biology becomes quite cost effective and combined with other benefits - it would be the only way that makes sense to do research, so funding will naturally go there?
Also - do you see a way to add the extreme versatility of the biology lab into a cloud service ?
> it would be the only way that makes sense to do research
There will certainly be more than just one way, although I hope cloud labs are the front runner. Also cloud and automated are two separate concepts. We do both, but there's no reason that you can't just do one or the other. The automation is critical for reproducibility for many reasons. But I think the cloud aspect is mostly helpful from a business perspective -- it makes it easier on everyone to get up and running on our system. But there are many in lab automation solutions that are helping fight the reproducibility crisis. And on the flip side, there are cloud labs that aren't automated.
> do you see a way to add the extreme versatility of the biology lab into a cloud service
We let you run any assay that can be executed on the set of the devices that we have in our automated lab. So in that sense, yes its very flexible. Also, there's no need to run your entire workflow in the cloud. You can do some at home, some in the cloud. Some people even string together multiple cloud services into a workflow. See https://www.youtube.com/watch?v=bIQ-fi3KoDg&t=1682s
That being said, biology labs can be crazy places. Part of what we do is put constraints on what can be encoded in each protocol to reduce the number of hidden variables. Every parameter that counts must be encoded in the protocol, because once you hit "go" on the protocol, it could run possibly on any number of different devices each time it runs. The only constant is that the exact instructions specified in the protocol will be run on the correct device set.
1. Yes, but the idea would be that if you provide a way to communicate the variables that actually matter for consistency then you can increase the robustness of a finding. If you have one lab that can _always_ produce a result, but no one else can, then clearly we do not really understand what is going on and one might not even be willing to call the result scientific.
2. Maybe not better, but certainly more result oriented. Core facilities do exist right now for things like viral vectors and microscopy (often because you do need levels of technical expertise that are simply not affordable in single labs). If there were a way to communicate how to do experiments more formally then the core facilities could expand to cover a much wider array of experiment types. You still have to worry about robustness, but if you have multiple 'core' facilities that can execute any experiment then that issue goes away as well. The hope of course is that individual labs as they exist today (perhaps with an additional computational tint) would be able to actually replicate each other's result, because we will probably end up needing nearly as many 'core' facilities as we have labs right now, simply because the diversity of phenomena that we need to study in biology is so high.
There are already approaches in this direction e.g. such as providing a standardized experimental hardware-software interface with Antha [1]. The complexity of the problems in questions (biological domain, biophysical, biochemical) is daunting - we do not understand many things, "there is plenty of room at the bottom".
How about recording videos of the lab? People trying to reproduce the experiment can just sift through the video. That may be tedious but it's far better than nothing.
Just a little metadata would help: Experiment A, Phase N, Day X
Video and photographic evidence can play a big role and when we have the extra bandwidth to process such a dataset. Right now we barely have time to do the experiments, much less 'watch tape' to see how we did (maybe if scientists were paid like professional sports players...). In an ideal world we would be collecting a much data as we possibly could about the whole state of the universe surrounding the 'controlled' experiment. That said video and photographs are very bad a communicating important parameters in an efficient way. Think about how hard it is to get information out of a youtube video if you need something like a part number. Photos do better, but if you need to copy and paste out of a photo we will need a bit more heavy lifting to translate that into some actionable format (eg ASCII).
I didn't mean record it to use the data in your analysis, but record it to preserve the methods for others. If they have trouble getting part of the experiment to work, they can pull up the video and see how you did it (at least to a degree; I'm not expecting 360 video. You can't possible record in text everything a video could capture.
Thanks for sharing your knowledge and experience in this discussion, by the way. It's what makes HN great.
Ah, yes, things like JOVE [0] are definitely useful but they don't seem to scale to the sheer number of protocols that need to be documented (eg a single JOVE publication is exceedingly expensive). I have also heard from people who have tried to record video of themselves doing a protocol is that it is very hard to make them understandable for someone else. That said if the 'viewer' is highly motivated videos of any quality could be invaluable. Sometimes it is just better to buy the plane tickets and go directly to the lab of the person who can teach you (if they are still around).
> if the 'viewer' is highly motivated videos of any quality could be invaluable
That's what I meant. Just stick some cameras in the ceiling (or wherever is best) and capture what you can. It seems cheap and better than nothing, but I know nothing about biological research.
True, biology is a horror show full of surprises. Many experimental instructions are as reliable as astrologic forecasts. I guess that is the price of complexity and the human factor.
I would love to hear more about your work, and the strategies you propose to improve the reproducibility of scientific experiments. My email can be found in my user description.
Have you looked at Common Workflow Language (CWL), see below?
Friend of mine has been experimenting with wrapping it all up in Docker containers! :-)
> a specification for describing analysis workflows and tools in a way that makes them portable and scalable across a variety of software and hardware environments, from workstations to cluster, cloud, and high performance computing (HPC) environments. CWL is designed to meet the needs of data-intensive science, such as Bioinformatics, Medical Imaging, Astronomy, Physics, and Chemistry.
I was chatting with a colleague last summer, and asking him for more details about a method he had published that I was having trouble reproducing. After pointing me to a few papers that didn't include the relevant details, hefinally told me that "if we told everyone about how it was done, anyone could do it."
While at the time I was pretty upset with him, perhaps it's the competitive nature of science and funding that also gives people a mild incentive to be secretive.
In this case, simply publishing code would have resolved the questions.
> I was chatting with a colleague last summer, and asking
> him for more details about a method he had published that
> I was having trouble reproducing. After pointing me to a
> few papers that didn't include the relevant details,
> hefinally told me that "if we told everyone about how it
> was done, anyone could do it."
That's not science, that's bullshit. Can you please expose that? Scientists shouldn't simply get away with such malicious behavior.
That is exactly how science works. Methods sections include just enough information to get a good sense of how the experiment was done, not enough information to replicate it exactly. Some disciplines are worse than others.
People could also publish plain text data as supplementary material, but why do that when you can get away with a raster image of a plot...
That's not how science works. During my scientific career I gave code and data away to any and all who wanted them. That includes critics, competitors, and anyone else who was curious.
I felt my results were solid enough (and that my skill at producing more results was good enough) that this wouldn't hurt me. This was just how things worked in my field (physics).
Interestingly, my experimental colleagues rarely felt that they couldn't reproduce results they saw in a paper.
The way you get funded is by being able to do things that others can't do, or by being better at some technique than everyone else. Giving away all your hard won tricks by putting all of them in a methods section takes away your advantage come funding time.
The problem is that it is far easier and cheaper to produce stuff that looks like science but isn't so if you fund stuff without being able to prove it/reproduce it then you will probably end up funding 90% bullshit while starving real science for money.
Any real scientists ought to recognize that secrecy as a strategy is terrible for science as a whole even if it is very temporarily good for them.
Though it should be noted that data sharing and dissemination plans are now required for many funding types, and I've been on at least two applications recently with very strict "You will share with others" requirements in them.
What's the point of funding something that won't help anyone because the author won't tell you how they did it? How is any conclusion that they've come to useful if nobody can verify if it's correct?
This can definitely be the problem. I've seen studies where 50% of funding came from university and 50% from a private company. University required study to be published in their database, company wants the end result and don't want media to know what they are working with. So the report is obfuscated just enough to be legible for publication without giving away too much data from the company.
Especially for final masters degree projects this is very common as the students don't get paid by the university at all, so many try to find a company to sponsor. But the students still need the uni to publish the report for them to get their final degree so you get this conflict of interest again. Most of these reports are just written with the end goal of getting a degree, not of creating solid research, this really needs the stricter universities not letting through all that crap, for now they shouldn't really be trusted the same way as proper research papers.
It is more subtle than you think. It is not that you give no information about how to do things, you lay out all the steps that you took in your methods section. An example of keeping all tricks to yourself is that you do not tell others about the 100 small thing you found out, the hard way, that you should avoid doing. i.e. You explicitly say in the methods section these are the steps I took, but what others really need to know is why you ended up doing all the tiny tiny things it the particular way that you did. In many cases, you could write pages and pages about all these reasons. All these little tricks add up to much greater efficiency. Good experimentalists are the ones that have already made all the mistakes.
Edit: This is additional context for the commenters below.
I remember my teachers in high school making such a big deal about the scientific method on how important it was, how experiments must be reproducible to be useful, but today you barely hear it mentioned one way or another.
It's no more a "comforting lie" than your driving instructor telling you to check your blind spot. Not everyone does it, and bad things happen as a result, but all the more important to teach it.
I'm actually surprised to hear of high school teaching good scientific practice. I don't remember ever being taught that. Widely may it spread.
Hold on -- there's a category confusion here: "check your blindspots" isn't a comforting lie; it's a command. Converting it to "checking your blindspots will avoid collisions with careless drivers" would make it no longer a lie.
I was pointing out the category confusion. Science teachers don't purport to tell you what scientists actually do (history or sociology teachers might, I suppose, but they don't usually "make such a big deal" out of the scientific method). They purport to teach science.
As you say - it's not a comforting lie, it's a command.
Lots of insights/technologies you use today were produced by scientists working in such and even more secretive conditions, even with public funding involved (e.g. nobody at the Manhattan project would broadcast their discoveries to the world and same for many other fields, not necessarily war related).
That's an absurd degree of cynicism. I just finished my PhD in chemical engineering, and I did the reverse of this. In fact, I successfully migrated the younger members of my research group to a completely open-source software stack for chemical simulations, so that in principle anyone with a Linux box could reproduce our results. We published all our code and plain text versions of the data.
I'm not saying you're wrong about the incentives - scientists are often incentivized toward secrecy - but I deny that we have to follow such incentives.
It differs depending on the field. Biology has a reputation for being extremely competitive. I've heard of PIs telling their students what they're forbidden to reveal at conferences for fear of getting scooped. As a CS grad student it was a completely different story: I was delighted just to get someone who was willing to listen to me talk.
I agree. I was on the team at Texas A&M that cloned the domestic cat -- (circa 2001) and secrecy was very important (notwithstanding the very real physical threats we had from anti-cloning nutcases.) Even the lab location was secret. The lab itself wasn't hidden, but nobody but us knew what was going on there. It was simply called "Reproductive Sciences." There was some very high incentives to be "first" -- which we were. Unfortunately for me, as an undergraduate research fellow, my name didn't make it into the Nature paper.. but wow what an experience!
I am writing a grant proposal right now. The success rate is ~19%. Personnel (i.e. publication record) of the team is weighted at 40% of the proposal. If you don't have an H-index of >50, there is no incentive to share with other that which gives you an advantage in the science section.
Code/design/engineer are considerably different than say biology, because you can (and should) publish artefacts. The actual code/algorithms (not pseudo code) needs to be shared and archived with the journal.
There has been some work for archiving code with some journals and some allow video uploads as well for segments from the actual experiments.
> Maybe the format needs to change. Perhaps journals should require video, audio commentary or automated note taking for publication.
A 'world view' column in Nature suggested the same things last week [1]; the author described a paper of theirs [2]:
> Yes, visual evidence can be faked, but a few simple safeguards should be enough to prevent that. Take a typical experiment in my field: using a tank of flowing water to expose fish to environmental perturbations and looking for shifts in behaviour. It is trivial to set up a camera, and equally simple to begin each recorded exposure with a note that details, for example, the trial number and treatment history of the organism. (Think of how film directors use clapper boards to keep records of the sequence of numerous takes.) This simple measure would make it much more difficult to fabricate data and ‘assign’ animals to desired treatment groups after the results are known.
I thought some journals were now allowed video archives. Some of the most famous experiments, such as the Stanley Milgram studies, have excellent video documentation (and in the case of Milgram, it's been replicated all around the world .. although no it's not ethical to do so).
Most experiments run for years (literally) and no one is going to record or archive, let alone watch, years of footage to confirm that one paper is legit.
A brief experiment showing the apparatus and the collection of a few data points might be helpful for understanding the paper, but I can't see using it to verify a non-trivial experiment.
For those that study human subjects, releasing video's of the subject is not going to happen any time soon. Participants have rights, and anomyity is an important one.
Blur their faces? Some experiments might depend on seeing faces, but not all. Plus, you would at least have video of everything the experimenters do, if not the results.
The journal I work for just rolled out a new methods format; the big change is requiring all resources to be listed, with their origin (a major problem is that Chemical A or lab rat subspecies B might be very different from one company or another, even if they're theoretically identical.) What's really needed is broader standardization of all practices; requiring video wouldn't solve the issue that different labs might not know what another would think needed to be videotaped. No one is going to document and record the entire course of an experiment; that would literally be months of footage. We'd like to make sure everyone has the same understanding of procedures and techniques, but that requires communication not just through journals, but between scientists and academic institutions.
Additionally, not everything appears on video. We have found major differences between identical studies run in rooms set at different temperatures. Also, many of the procedures I do would essentially require a camera operator to capture all of the movement. I take a cage out of a rack, take a mouse out of the cage, weigh it, dose it, etc.
No, but the burden of videography is a lot higher than the burden of writing a paper. In fact, a paper isn't written for every study, so in order to write a paper, you'd have to take video of every study just in case one of them is used in a paper in the future. It's a much higher burden than people want to believe. Add to that the fact that most animal facilities won't add cameras unless you force them at gunpoint because historically, videos of that sort make for targeting by protest groups.
Or require the author to only communicate to the technicians via the same means that will be published with the paper -- i.e. Make sure anyone reading the paper has the same spec for the experiment as those who performed the original. [1]
That would help prevent such "hidden specs" from entering the experiment.
[1] Note: this implies that authors cannot be part of the experiment or conduct it themselves, because they can't "pass on their identity" in a research paper, as would be necessary to put readers on par with the technicians.
In my job, I work with an outside contract research organization. The way this works is pretty similar to what you're describing, and its a living hell. For starters, it takes 6-10 drafts back and forth to get a protocol to start with, and the resulting document is never shorter than 12 pages. Then, once they start a study, if we get any aberrant data, the question becomes "did they mess that up, or is that data real?". Of course anything we want to be sure about, we run twice, but when you have a panel of 20 compounds, you can't duplicate all of the work, so some compounds get dropped even if the data were not "real". Also, and maybe this would be different with another CRO, there are often very stressful conversations in which they are trying to avoid being blamed (because if they screwed up, we aren't supposed to pay them the full price), but we just really want to know what happened. Lastly, you can tell a lot by being hands-on with a study; there's a lot you can miss if you aren't in the room with the study. Just my 2 cents.
Well, the burden of a policy has to be judged relative to what you're trying to accomplish. If the policy is ensuring that you achieve your ostensible goals, then that burden is justified.
Based on your description, it actually sounds like it's making you do things exactly the way science is supposed to work! You quickly identify issues of "real effect or experimenter error or undocumented protocol?" -- and you prevent any ambiguous case from "infecting" the literature.
Those are the same objectives modern science is currently failing at with it's "publish but never replicate" incentives.
> Lastly, you can tell a lot by being hands-on with a study; there's a lot you can miss if you aren't in the room with the study.
I wasn't saying that you can't be there in the lab and do that kind of experimentation, just that scientists shouldn't represent this kind of ad hoc work as the repeatable part that merits a scientific conclusion. The process should be: if you find something interesting that way, see if you can identify a repeatable, articulable procedure by which others can see the same thing, and publish that.
The proposal has a problem in that it will increase the quality of results but will enormously slow down progress.
E.g., looking from the perspective of a scientist-reader, if someone has spent a few months doing the ad hoc hands on experiments and achieved interesting observations, then I would want them to publish that research now, instead of spending another half a year to make the repeatable procedure or possibly not publishing it ever because they'd rather do something else than make it up to these standards. There is a benefit from getting all the tricks to make the experiment cleaner, but the clean experiment is just means for acquiring knowledge and ideas for further research, not an end goal by itself for a researcher in that area. Outsiders may have different interests though (https://news.ycombinator.com/item?id=13716233 goes into detail) preferring "finalized and finished research" but to the actual community (who in the end is doing everything and evaluating/judging their peers) generally would prefer the work in progress to be published as-is instead of having more thorough results, but later and less of them.
Outsiders can get the repeatable procedures when it's literally textbook knowledge, packaged in assignments that can be given to students for lab exercises (since that's the level what truly repeatable procedures would require). Insiders want the bleeding edge results now, so they design their journals and conferences to exchange that.
Then maybe the problem is that the public is expecting results to be actually true, exacerbated by "hey what peer-reviewed literature are you supporting your argument with". If peer-reviewed literature is just a scratchpad for ad hoc ideas that may turn into something legit later, then the current standard is good enough, and we shouldn't be worrying that most of them are false.
OTOH, it's a problem if people are basing real-world decisions on stuff that hasn't reached textbook level certainty. That's pretty much what happened with dietary advice and sugars. "Two scratchpads say a high-carb low-fat diet is good? Okay, then plaster it all over the public schools."
I think this is the case, and it has been mentioned elsewhere in this thread. When I see a paper published that I am interested in, I have to fit it into the context what I already know about a field, the standards of the the journal its published in, sometimes the origin of the paper (some labs are much less sloppy than others), and other factors.
For a recent personal example, a company published a paper saying that if you give a pre-treat with 2 doses of a particular drug, you can avoid some genetic markers of inflammation that are in the bloodstream and kidneys. Well, I looked at the stimulus and ordered some of my own from a different manufacturer that was easier to obtain and gave it to some mice with and without pretreatment by their compound. Instead of looking at the genes they looked at, I looked at an uptick in a protein expected to be one step removed from the genes they showed a change in. Well I haven't exactly replicated their study, but I've replicated the core points: stimulus with a the same cytokine gives a response in a particular pathway and it either is or isn't mitigated by the drug or class of drugs they showed. Now, my study took 2 days less than theirs, but it worked well enough that I don't need to fret the particular details I did differently from them. If my study didn't work, I could either decide that the study isn't important to me if it didn't work my way or go back a step and try to match their exact reagents and methods.
So yes, I do think the news industry picks up stuff too quickly sometimes, but depending on the outlet, they tend to couch things in appropriate wiggle words (may show, might prove, could lead to, add evidence, etc).
Yes, the problem seems to be that the general public is expecting journals/conferences that are essentially implemented by a research community as a tool for their ongoing research workflow, to fit to the goals of informing the general public - but there reasonably would/should/must be a gap of something like a year (or many years) between the finding must be initially published so that others can work on that research, and the time when the finding is reasonably verified by other teams (which necessarily happens a significant time after it's been published) and thus is ready to be used for informing public policy.
It's like the stages of clinical research - there we have general standards on when it is considered acceptable to use findings for actually treating people (e.g. phase 3 studies), but it's obviously clear that we need to publish and discuss the initial findings since that's required to actually get to the phase 3 studies. However, the effects seen in phase 1 studies often won't generalize to something that actually works in clinical practice, so if general public reads them then often they'll assume predictions that won't come true.
Usually, if you want the full details you look/ ask for the thesis or full report that the journal article is the condensed version of. Most journals also allow supplementary sections for more detailed methods. If its too long, people simply won't read it - already most will just read the abstract and look at figures.
The 'unknown unknowns' will never be eliminated. Certainly it's worthwhile to try to improve methods communication, but there are limits.
You really have to try it yourself before you can understand the degree of troubleshooting that's required of a good experimentalist. You could have scientists live-streaming all their work, and you'd still have the same issues you do now. Even a simple experiment, something most wouldn't blink an eye at, has dozens and dozens of variables that could influence the result. The combinatoric complexity is staggering. The reality is that you try things, find some that work, and then convince yourself that it's a real result with some further work.
The methods that endure are the ones that replicate well and work robustly. Molecular biology is still built on Sanger sequencing, electrophoresis, and blotting, all in the context of good crossing and genetics, because that's what works. Some of the genomic tools are starting to get there, I'd venture to say that RNAseq is reasonably standardized and robust at this point. Interpreting genomic data is another story...
What you're talking about is the authors not reporting variables they considered, and then didn't control for. These not being reported is not universal - for example, I very frequently report every variable considered, and make my code available, with comments about variable selection within.
What the parent post is talking about is "unmeasured confounding", or a Rumsfeldian "Unknown Unknown". If there is something that matters for your estimate, but you're unaware it exists, by definition you can neither report it nor control for it.
Yeah I did an experiment with metabolism in relation to temperature with rodents in college. Our results were just absolute garbage for the most part. I think two of us owned cats, walk in temperature controlled fridge was incredibly loud and the light never turned off, and the fridge was on the opposite side of the building from the only lab with the correct equipment to run the experiment. Plus the enclosure for measuring VO2 was not very relaxing for the mice regardless.
Another group was doing a metabolism experiment with caffeine and rats. The only meaningful result they got was the half-life of caffeine. The rats were incredibly animated regardless of whether they had been dosed with caffeine or not, and they basically got garbage for results as well.
I'm an analyst now, and I've noticed biology is a second-class science in the eyes of a lot of hiring managers when it comes to analytics. Not everyone knows how to use data in bio, but if you are a data-type person, you get so much experience working with the worst data imaginable. The pure math types aren't that great at experimental design, and the physics and chem people tend to be able to control most of their variables pretty easily.
I'll admit that bio people tend to be a bit weaker in math, but almost every real-world analysis situation I've been in has been pretty straightforward mathematically. Most of the time is spent getting the data to the point where it can be used.
There's some neat software now (not sure if it was around when you were in college) to translate video into reliable data about the movement of animals. I've used it for fish, but the same software can be used to track people around a room or to track mice in a cage. I think that might be much more useful than, say, how many backflips a mouse does in their cage.
This was about 9 years ago, so it probably existed in a certain sense, but our lab computers were still apple II's because that was what the software for the VO2 sensors was written for. The lab group doing the caffeine experiment was trying to measure whether the resting VO2 went up when dosed with caffeine, so the fact that the rats were moving at all was the primary problem.
We tried using a machine vision program written by a grad student at another college to count trees from old survey photos at one point, and it did not work well at all in anything with more trees than a park-like setting. We ended up just having a human circle all the trees they saw and I wrote a program to detect the circles. It worked much better. The program I created was based on something similar used to count bacteria colonies on petri dishes.
You can add to this that if you are in a facility with both rats and mice, you should never house them in the same room, and you should probably not enter a mouse room after being in a rat room. In the wild, rats are predators of mice.
But in the wild, there aren't separate rooms for predators and prey, either. If laboratory rodent experiments are so reliant on such synthetic conditions, what's the point?
The point is to isolate variables. If you want to see whether X might be causing Y, you can't just do X in random environment while A, B, C, D and Q is happening, and claim if you observe Y that was because of X. You have to isolate X and establish a link between environment with X producing Y and the same (to the extent possible) environment without X not producing Y. Then you can make a step (still not enough to be sure but at least to start suspecting) that X is causing Y. Of course, it could turn out that X is causing Y only when A is present but B is absent, and then your experiment will be a failure. Or maybe Y just randomly happens and you had back luck to land on it exactly when you did X. Nobody said it's always easy :)
If some mice are housed near rats and others are not (or simply vary in how far they are from the nearest rat), that will introduce variation into your measurements. For experiments not specifically about mouse/rat interactions, this variation is irrelevant noise that makes it harder to detect or characterize the effects the experimenters actually care about.
That's not my point, though. Like, if you conduct physics experiments in a vacuum because interactions between objects and atmosphere isn't part of what you're studying, that's fine. If everyone in physics is conducting experiments that way, then suddenly you're left with the question of, it turns out that in real life I encounter atmosphere all the time, and how much can these experimental results tell me about the world I actually interact with? And if it turns out that all the preconditions to physics experiments can't be published because there are too many of them to list, and you're just expected to know these things, doesn't that throw the credibility of the whole enterprise into doubt? Controlling for variables is fine. But if you aren't comprehensively listing all the variables you're controlling for, if the very idea of doing so is considered a fool's errand, then are you even really doing science?
> "if you aren't comprehensively listing all the variables you're controlling for [...] then are you even really doing science?"
Mate I think that's the point of this whole thread that you're commenting in. And the tangential point to the article posted.
Science isn't some binary thing. You can do poor science, and you can do great science. Some variables are hard or impossible to control for. Some fields make this simpler than others. I'd say that as we've continually endeavored with the sciences we're probably better at it now than we've ever been before.
Synthetic conditions are absolutely critical to science. Typically, the more conditions you can specify in the experiment, the more reproducible it should be. Some of these are very difficult, and others in the thread have pointed out that some don't get labeled in the journals.
If we ran such experiments in the wild, completely outside of control, then we can never know what we're really observing. By controlling the environmental variables your observations gain meaning.
Yes, because you are trying to control your variates? Just because physics is the most amenable to experimental control does not mean that the only real science is physics.
I mean by that measure, medicine is not a science either because we don't know most of the possible confounding variables. That doesn't mean that attempting to use the scientific method still isn't the correct choice.
> Just because physics is the most amenable to experimental control does not mean that the only real science is physics.
That's not what I'm trying to say here at all. The point isn't about how amenable you are to experimental control. The point is that even when experimental control is easy to isolate out, like in the physics example above (which I don't think is true in all of physics, by the way), it's not free. You're trying to compensate for the lack of available statistical power to measure an effect in noisy data by cutting down on the noise in the data. But you're doing it by generating the data in an environment that doesn't exist outside of laboratory conditions. Writing off replication failure as not being a problem because lab conditions are difficult to reproduce misses this; if the findings are difficult to replicate in other conditions, that could indicate that the findings are more narrow in scope than the study suggests. As I pointed out downthread, for example, if all the rodents in an experiment on a drug are on the same diet, all the experiment proves (assuming it's otherwise well run) is that the drug works in combination with this diet. If the drug works independently of diet, then the findings on the drug are generalizable. If it doesn't, though, they aren't. And if you have 60 years of medical research based in part on studies with rodents who eat diets very differently than what rodents eat in the wild, or what people eat, then it raises all sorts of questions about the state of medical research. That doesn't mean that medicine isn't a real science, it just raises questions about how well it tells us what we think it's telling us.
You've gotten a couple of answers, but my answer might rely heavily on my field. I work in early stage pharma discovery research. So our goal isn't to determine the basal level of some cytokine, for example, in normal mice. Our goal is typically to see that cytokine's response to treatment, or stimulus, or stimulus then treatment. In other words, the mouse is a living system one step more complicated than a dish of cells, which is its value to us. Sometimes, once you take a drug to non-human primates or humans, you have to drastically change the type of study you run to determine efficacy.
So why aren't mouse studies done in acoustically isolated rooms? Too expensive or lack of forethought? I know metrological laboratories that are mechanically insulated with all sorts of contraptions making the space vibration free so it'd not as if buildings could not be adapted for their intended scientific use as a matter of principle.
In my experience, you're lucky if you can get space for your equipment at all.
One week, they're moving your growth cambers out into the hallway to work in the ceiling. The next, they had to cut power for 8 hours for maintenance, and by the way, it wasn't plugged into an outlet with emergency power. Oops.
Hell, they can't even keep the lab temperature steady. Solutions sitting on your bench will start to precipitate out.
So yeah, the issue is money. It's also planning; you never know what the needs of researchers are going to be in a few years.
In the end, nice facilities can certainly help with a lot, but they don't address the core issues of experimental variables and combinatoric complexity. The way you deal with this is skeptical peers that understand the methods, reliance on robust methods wherever possible, and independent methods to confirm results. Even with all this replication difficulty, it is quite possible to make compelling conclusions.
The classic ideal of controlling a single variable at a time is nice but largely impossible. Especially in biological sciences but that's true even down in chemistry and physics the systems scientists are trying to control are complex and it's not always possible to modify one variable without affecting others.
Independent experiments and controls. AKA, literally the basis of experimental science.
Let's say you want to know where a protein localizes in a cell, of a given tissue, in both mutant and wild-type organisms.
* Immunolocalization. You develop antibodies to the protein of interest, fix and mount tissue, perfuse it with the antibody, and use a secondary antibody to make it detectable.
* Fluorescent tagging. You make a construct with your protein fused to a fluorescent protein. Usually this involves trying a few different tagging strategies until you find one that expresses well. Then you can make a stable transgenic, or try a transient assay. If it works, then you see some nice glowy confocal images. Be careful, though, as the tagging can affect protein localization.
* Fractionation. In some cases, you can get a rough idea by e.g. extracting nuclei and doing a simple Western blot to see where the protein shows up.
In the real world, you might start with the FP-tag and see that your protein is absent from the nucleus in your mutant. Which would be cool, and interesting in terms of figuring out it's function. If that was presented as the only result, I'd reject the paper and think the authors are terrible investigators. I'd want to see, at least, some nuclei preps that detect the protein in the WT, and don't in the mutant. I'd love to see immunos, too, as FP often does mess up the localization.
You can take it even further and start doing deletions. You take the protein and crop bits out to see what happens. You should see stuff like removing the NLS makes it stop going to the nucleus. That's a good sanity check and a sign your methods are working. You can also try to mess with active sites, protein-protein interaction domains, etc. etc. All within a theoretical model of what you think is going on in the cell.
Ultimately, the difficulty of replication isn't that troublesome. An inability to do so is, but science has never been easy. That's what you sign up for, and that's why you need to read papers critically. You get a sense of distrust for data unless there's really solid evidence of something. And when you find that solid evidence, you get a big smile and warm feeling in nerd heart.
In some cases you use various statistical tools over many trials or in others you measure the effects of the variables in other experiments. Or you can control the important variables and allow those with small or no effect on what you're measuring to vary slightly.
There is continual progress on standardization of methodology, but it takes a while. People have vested interests in using their protocols, and there often valid disagreements about what is actually the best protocol.
Nevertheless, these kinds of standardization documents are important. But only as long as deviations from these standards are not discounted when justified theoretically.
> Think about the epistemological ramifications of this.
This this this this this a million times this. If your experiment with lab rats needs to be done this finely to be replicated, is it really telling you anything about the real world? Because of course, we don't really care about the behavior of laboratory rats, right? Not in proportion to how often we do studies with laboratory rats versus other species of animals. We care because of what it can tell us about biology in general. And if the finding can't even generalize to "laboratory rats whose cages have been cleaned recently," does the study really say what it seems to?
The point, I think, is that you want to control for things that really alter the outcome. It's not that a clean cage means that the end-product no longer works, but you want to compare "didn't have drug" vs "did have drug" not "didn't have drug" vs "did have drug but the fire alarm went off this morning". Unless your effect size is much larger than all the noise, you could easily miss a true result.
Worse, you could get a false result the other way. What if your control group had all been spooked before they were measured a few times? That could make the control group seem worse than they are!
So, let's continue with your example of a drug being given to the rodents. Now, you want to control diet -- you don't want your control group eating differently than your treatment group. This ends up being relatively easy to do with laboratory rodents, they aren't popping down to McDonalds for lunch or lying in their food diaries, like human subjects might. You buy your rodent food from one rodent pellet supplier, and you don't change brands or SKU during the experiment, and voila, control.
And this works fine if the drug you're studying works identically given all rodent diets. But you don't know that it does! You're not controlling for the variable of diet in the sense that you know the effect of the variable of interest across all possible diets. You know how the drug works conditional on one specific rodent diet. And if you're not putting what brand of rodent food you use, and that causes replication failures, that suggests that you don't understand the effect of the drug as well as you thought you did. And if you have an entire field of research that undergoes such replication failures often, it's fair to start wondering how much of what gets called "science" isn't the study of the natural world but the study of the very specific sets of conditions that happen in labs in American and European universities.
Yes but the things they mentioned would be bizarre to control for the other way.
Would you expect the tests to be done, then again but with both rats hearing the person upstairs installing a new microscope, then with a regular fire alarm, etc?
Describing the food given is quite a step away from describing how frequently the fire alarm goes off.
Exactly. The grandparent comment begs even more terrible questions about this whole enterprise of our species we call science than even the original article.
a load of variables that are needed to be controlled in order to get the original experiment to work is kind of a red flag tho. like someone could just keep trying the experiment and then adding another variable they are controlling in order to get the experiment to work. but really they are just running a bunch of experiments and getting lucky at some point. assuming they stop trying to control variables or try and replicate themselves as soon as they get a positive result :)
Yes an no. Of course, in something like an animal model it can be really hard to control everything, and the result you find could just be 'luck'.
On the other hand, figuring out what variables to control is huge part of science. Say the development of next generation DNA sequencing technologies. People tried a ton of different variables, conditions, reagents, flow cells, etc. And failed and failed. But eventually they controlled the right conditions, optimized the right things, and now the process is done in thousands of labs every day as a routine tool. This is a technology development example, but the same could be said of the conditions needed to make stem cells.
It's not a red flag, it's reality. Biology is complicated, and no matter what the synthetic biologists tell you :)
You use independent methods and good controls to deal with this. This is nothing new, it's been the basis of experimental science for decades. If you're allowed to publish without doing this, the field has failed. Molecular biology, in particular, has flourished because of the effectiveness of genetic controls. Mutants are highly reproducible (you just send out seed, cultures, or live specimens), verifiable (sequencing), and combinatoric (crossing).
Wouldn't this allow you to explain away all negative results? Say you get a negative result and you don't like it. Then you start fishing for a cause and found out someone sneezed during the experiment, so you'll delete the null result. Isn't that problematic?
I'm surprised no one mentioned the company Mousera (http://www.vium.com/). Granted, it is not a solution for all of science, but it essentially brings down many animal experiments to scripts, which can be run almost like I might run a docker container and script. The idea is incredible. You can even scale it up by running the script multiple times.
Disclaimer: I did bench and animal work 21yrs ago during undergrad, but havent used this company. So I know the field and how difficult replication is, but i'm not sure what has happened in wet science since 1997.
> I looked into the subsequent history of this research. The subsequent experiment, and the one after that, never referred to Mr. Young. They never used any of his criteria of putting the corridor on sand, or being very careful. They just went right on running rats in the same old way, and paid no attention to the great discoveries of Mr. Young, and his papers are not referred to, because he didn’t discover anything about the rats. In fact, he discovered all the things you have to do to discover something about rats. But not paying attention to experiments like that is a characteristic of Cargo Cult Science.
Even if you do know all that, it means reproducing the experiment is costly. Controlling properly an environment take times and resources, and it's not like it's easy to get those for anything, let alone for something like peer reviewing.
Heck, I've tried to reproduce CS papers with incomplete methodologies. There's always enough that that I know it will work, but they normally don't include all the tricks you need to get it to work easily or efficiently. Stuff like "we used an SMT solver with this important feature" but no mention of which solver or "a key part of this algorithm is factoring the sparse matrix with this non-standard technique that you'll have to implement yourself" but don't tell you the number of tricks they used to make it as fast as you need.
That is frustrating. In my field of cognitive neuroscience, there is often little incentive for a researcher to hide parts of their methods from their 'competitors' since, for example, my memory study is not about reporting but protecting a new technology. Indeed, prestige is often a consequence of others adopting your methods, so researchers are motivated to share scripts, and report the methods fully.
HOWEVER, certain journals can place limits on the length of the methods section, which is a damn shame.
> there is often little incentive for a researcher to hide parts of their methods from their 'competitors' since, for example, my memory study is not about reporting but protecting a new technology
If you are protecting, not reporting information (e.g., about a new technology), why would you be incentivized to share it?
Shouldn't it be the responsibility of the original experimenter to provide the information necessary to repeat the experiment? I see nothing in your list that sounds like a good excuse for not being repeatable.
I disagree. Grammar rules are a very effective checklist for clarity and precision in communication, IME. Does the verb have a subject and object? Otherwise, it's not clear who should do which to what. The instructions say, 'turn it on'; does "it" have a clear antecedent? Otherwise, what are they turning on?
I would guess that the practical benefits are a big reason that they are the 'rules'.
An alternative headline would be "Most Published Studies Are Wrong"
Am I wrong for considering this not-quite-a-crisis? It has long been the case that initial studies on a topic fail to get reproduced. That's usually because if someone publishes an interesting result, other people do follow up studies with better controls. Sometimes those are to reproduce, sometimes the point is to test something that would follow from the original finding. But either way, people find out.
I mean, I guess the real problem is that lots of sloppy studies get published, and a lot of scientists are incentivized to write sloppy studies. But if you're actually a working scientist, you should understand that already and not take everything you see in a journal as actual truth, but as something maybe might be true.
Yes! This is the point that most people miss. No scientist treats published studies as gospel. Our focus shouldn't be on exact replication, and should be on how generalizable such results are. If the results don't hold in slightly altered systems, it falls into the wastebin of ideas.
Maybe not, but these studies get swept up into meta-studies, books, think tanks and special interest groups write policy papers based on that secondary layer, which then become position papers that inform policy makers about Big Decisions. There's a lot at stake when only scientists are aware of the fallacy.
Well that shouldn't necessarily be the standard. There are lots of people I know that can't do a miniprep or run a gel. It doesn't mean that those things don't work or aren't replicable.
> No scientist treats published studies as gospel.
Unfortunately that is a problem. Imagine yourself trying to create a simulation of a biological system, which has to rely on experiments. You may come up with a plan, but every little line on the plan will be either very doubtful or outright false. The problem is that many of these doubts could be dispelled if the experiment was a lot more stringent (much larger sample size, much more controlled conditions etc). That would cost a hell lot more, but it would give you one answer you can rely on.
I don't think making experiments more stringent is the answer here (btw, I've spent a lot of time trying to build simulations of biological systems). Usually, we aren't doing the right experiment in the first place; this is hard to figure out ahead of time. Again, read the ACSB that I linked to below... it's probably the most nuanced and interesting discussion on the subject
Yes, thanks that was a good read. It seems we need a "Map" of biological sciences, in which every study could be a 'pin' in a particular location , signifying that 'this study studies this very particular problem here'. Maybe that would help figure out where are the biggest gaps. Unfortunately, most studies broaden the impact of their results too much to the point that reading the paper abstract can be misleading. Maybe people should just publish their results, but not be allowed to make any claims about them; let others and the community make those claims.
>That's usually because if someone publishes an interesting result, other people do follow up studies with better controls.
No, no, a thousand times no!
Most studies do not have follow up studies that confirm/refute the original. Often such a followup study is hard to publish. If you manage to reproduce it, you cannot publish unless it presents a new finding. If you fail to reproduce it, it often doesn't get published either. And no one writes grant applications that are for replication studies. The grant will likely go to someone else.
When I was in grad school, few advisors (engineering/physics) would have allowed their students to perform a replication study.
>But either way, people find out.
I wish I could find the meta-study, but someone once published a study of retracted papers in medicine. They found that a number of them were still being cited - despite the retraction (and they were being cited as support for their own papers...). So no, people don't find out.
>But if you're actually a working scientist, you should understand that already and not take everything you see in a journal as actual truth, but as something maybe might be true.
I agree. But then you end up writing a paper that cites another paper in support of your work. Or a paper that builds up on another paper. This isn't the exception - this is the norm. Very few people will actually worry about whether the paper they are citing is true.
When I was doing my PhD, people in my specialized discipline were all working on coming up with a theoretical model of an effect seen by an experimentalist. I was once at a conference and asked some of the PIs who were doing similar work to mine: Do you believe the experimentalist's paper? Everyone said "No". Yet all of us published papers citing the experimentalists' paper as background for our work (he was a giant in the field).
Another problem not touched upon here: Many papers (at least in my discipline) simply do not provide enough details to reproduce! They'll make broad statements (e.g. made measurement X), but no details on how they made those measurements. Once you're dealing at the quantum scale, you generally cannot buy off the shelf meters. Experimentalists have the skill of building their own measuring instruments. But those details are rarely mentioned in the paper. If I tried reproducing the study and failed, I would not know if the problem is in the paper or in some detail of how I designed my equipment.
When I wrote my paper, the journal had a 3 page limit. As such, I had to omit details of my calculations. I just wrote the process (e.g. used well-known-method X) and then the final result. However, I had spent most of my time actually doing method X - it was highly nontrivial and required several mathematical tricks. I would not expect any random peer to figure it all out. But hey, I unambiguously wrote how I did it, so I've satisfied the requirements.
When I highlighted this to people in the field, they were quite open with another explanation: It helps them because they do not want their peers to know all the details. That allows them to have an edge over their peers and they do not need to race with them to publish further studies.
I can assure you: None of these people I dealt with were interested in furthering science. They were interested in furthering their careers, and getting away with as little science as is needed to achieve that objective.
>>That's usually because if someone publishes an interesting result, other people do follow up studies with better controls.
>No, no, a thousand times no!
Most studies do not have follow up studies that confirm/refute the original. Often such a followup study is hard to publish. If you manage to reproduce it, you cannot publish unless it presents a new finding. If you fail to reproduce it, it often doesn't get published either. And no one writes grant applications that are for replication studies. The grant will likely go to someone else.
Sorry, let me be clear: If an interesting result is published, people will go to the trouble. Most results are of limited interest and mediocre.
> Sorry, let me be clear: If an interesting result is published, people will go to the trouble.
That's only true for a definition of "interesting" that is more like the sense most people assign to "astounding" or "groundbreaking", and even then it's not guaranteed, just somewhat probable. If it's both groundbreaking and controversial (in the sense of "immediately implausible to lots of people in the domain, but still managing to draw enough attention that it can't be casually ignored as crackpot"), like, say, cold fusion, sure, there will be people rushing to either duplicate or refute the results. But that's a rather far out extreme circumstance.
>Sorry, let me be clear: If an interesting result is published, people will go to the trouble. Most results are of limited interest and mediocre.
If it's in a journal, it is interesting. Journal editors will require "interesting" as a prerequisite to publishing a paper. Papers do get rejected for "valid work but not interesting".
If journals are publishing papers that are of limited interest, then there is a serious problem with the state of science.
I'm not trying to pick hairs. One way or other, there is a real problem - either journals are not being the appropriate gatekeepers (by allowing uninteresting studies), or most interesting studies are not being replicated.
> When I highlighted this to people in the field, they were quite open with another explanation: It helps them because they do not want their peers to know all the details. That allows them to have an edge over their peers and they do not need to race with them to publish further studies.
I have always suspected that, but I've never heard anyone be that open about it.
At a previous job I had to implement various algorithms described in research papers, and in every case except one, the authors left out a key part of the algorithm by glossing over it in the laziest way possible. My favorite one cited an entire linear algebra textbook as "modern optimization techniques."
>I have always suspected that, but I've never heard anyone be that open about it.
Yes, they'll just say they expect their peers to be competent enough to reproduce, and a paper shouldn't be filled with such trivialities.
To get the real answer, talk to their grad students. Especially those who are aspiring for academic careers. They tend to be quite frank on why they will act like their advisors.
Oh, and citing a whole book for optimization - that kind of thing is quite common. "We numerically solved this complex PDE using the method of X" and then just give a reference to a textbook. But usually the algorithm to implement is sensitive to tiny details (e.g. techniques to ensure tiny errors don't grow to big ones, etc).
I think the hope with these systems is that eventually there will be a preponderance of evidence that proves the study in general terms, not necessarily that everything in this study is 100%. Later scientists will follow along and prove/disprove these findings. If all the studies are 50-50, then we have no idea. If it is 90-10, findings indicate some kernel of truth in these studies. An astute grad student may also be encouraged to look at the 10% that disagreed to see why or if the 90 are too susceptible to selection bias (meaning they decided their conclusion from the beginning and are massaging the data to fit).
The wrong incentives for studies are a bigger problem. I think the only way to solve that is with a higher threshold of peer review to be required before one of these "findings" is put out to the public.
> But if you're actually a working scientist, you should understand that already and not take everything you see in a journal as actual truth, but as something maybe might be true.
I believe that's called "skepticism" which makes you a heretic and "anti-science" in certain fields.
> The problem, it turned out, was not with Marcus Munafo's science, but with the way the scientific literature had been "tidied up" to present a much clearer, more robust outcome.
I've seen this time and time again while working in neuroscience and hearing the same from friends that are still in those fields.
Data is often thoroughly massaged, outliers left out of reporting and methods tuned to confirm, rather than falsify certain outcomes. It's very demotivating as a PhD student to see very significant results, but when you perform the same study, you don't find reality to be as black and white as published papers.
On this note, the majority of papers is still about reporting significant results, leading to several labs chasing dead ends, as none of them can publish "negative" results.
I wonder if paying grad students to write a more full paper that includes all the steps and the negative results would help. It wouldn't be something that is published right away, and perhaps it wouldn't need to be published. Maybe it would simply be a follow-up to the original paper. It would be a "proof" of sorts, provided by the authors. There are many students out there that would happily do this, I think. I know so many that clamor for even the slightest bit of work in their departments. I think it would also be beneficial to their future, teaching them about reproducibility and impressing upon them to continue this practice down the road. The current climate of publish-or-perish isn't going away anytime soon, and neither are the clean, pretty papers with only positive results. And that's fine. Those are the quick highlights. But the full studies still need to be out there, and I think this could potentially be a way to approach that necessity.
For what it's worth I see the same thing in enterprise app development.
We've been doing a lot of data visualization and it often happens that someone comes to me with a thinly veiled task that's really to prove this or that person/process is at fault for delaying a project or something.
Sometimes though the numbers either don't support their opinion or even show a result they don't like and so inevitably they have me massage the graphs and filters until they see a result that looks how they want it to and that's what gets presented at various meetings and email chains.
The information at that point isn't wrong per se, just taken out of context and shown in a persuasive (read: propaganda) rather than informative way.
I've seen something similar in my field - industrial automation and testing. When a company wants to upgrade their testers, the testers we create are usually much more precise when compared to something created 20-30 years earlier. Often we have to modify our testers to match the results generated by these old, barely working testers.These companies request us to do it simply because otherwise they would need to change all of its literature, and explain to their customers why the products have slightly different specs then what they delivered last quarter.
Unfortunately, Our society is built on rotten foundations.
Yeah, I used to do a lot of financial reporting for a medical group. It eventually got to the point that after the second "those numbers don't look right" that I started asking what they wanted the numbers to show so I didn't waste any more of my time.
It gets even worse as if you produce a follow-up paper for an improvement, you're generally expected to produce something better. If the original result doesn't hold up, the only alternative is more even fraud, I mean, data massaging.
I am a social scientist studying human behavior, and this is a huge problem in the field. Myself and my statistician friends who analyze the literature have basically concluded that most extremely "novel" and "surprising" findings in the literature aren't even worth trying to replicate (remember, replications cost money to run, so before you start you have to make some judgment about the likelihood of success.) This is especially true of the "sexiest" sub-topics in the field, like social priming and embodied cognition. If you want to learn more about this, the place to look is Andrew Gelman's blog: http://andrewgelman.com/
Thank you. At first I thought puzzagate?! - I don't need that bs, but this is very different pizzagate.
I once found a good blog about mental health and science, a lot of snakeoil shown about srris, adhd etc. but I'm unable to find it now. Can anyone help me out?
This is ego, politics and career ambitions undermining modern science. Unfortunately, the fact that this is occurring so rampantly will bolster anti-intellectuals and give them a very potent argument to point to when presented with facts. This is a systemic failure of basic ethics that will hurt us all. The success-at-all-cost career mindset is toxic in all tracks, but this is one of the most dangerous for it to take hold in.
> will bolster anti-intellectuals and give them a very potent argument to point to when presented with facts
Case in point: the very first thing I thought of is, does this have any relevance to the field of climate science!
So....does it? Because we're told the reason we have to get on board with the program is because the people telling us the facts are scientists, and scientists are smart and trustworthy. However, we know this is not always true, don't we.
So what is a deliberately skeptical person to think?
Is this an intentional straw man? No, you're not told to trust the people because they have a certain job title and trustworthiness. You're told to look at the data, which is overwhelming and consistent across multiple years and teams. It is the exact opposite of lack of reproducibility.
> Is this an intentional straw man? No, you're not told to trust the people because they have a certain job title and trustworthiness.
Are you joking? Are you seriously making the claim that one of the persuasive approaches used in the "public realm" (media, discussions, etc) isn't that we should fight climate change because scientists have almost unanimously decided it is a real thing and we must do something?
If scientists are telling us something, we sure as hell should listen, at least two reasons being they are the experts on the subject (why wouldn't you listen to experts), and the subject is so immensely complicated that an average non-scientist person wouldn't have a chance of "looking at the data" and forming a reasonably correct opinion.
But now you are telling me no one is suggesting I listen to scientists? I could easily google thousands of articles/papers/blog posts/internet discussions where people are doing just that, but you are telling me no, that content does not exist.
What is it about this topic where otherwise reasonable people seem to go off the rails?
Your comment suggested that the title and reputation of a scientist was the fundamental reason you are "told" (in a somewhat conspiratorial big-brother fashion) to listen to them. And that - because sometimes mistakes are made - you can't trust an overwhelming consensus. That's obviously not true, and furthermore it's not the fundamental reason to listen: the fundamental reason is that it checks out. People have done gone and checked the papers/data. There have been multiple systematic reviews of other existing studies. It's not a single novel result. The massive consensus on this issue is the replication.
If you're not an expert and don't want to invest in becoming one, it's totally rationale to trust a network of experts to - roughly speaking - do their work properly. I'm sure you can find plenty of people advocating that. But my default position would be not to trust a single novel result, regardless of how smart or prestiged the authors were. Strong claims require strong evidence. I rarely hear any scientist or advocate saying otherwise.
The only thing that is consistent and overwhelming about that data is the amount of energy put into falsifying and massaging it to support the chosen narrative.
If you can still, edit/remove the presumption of falsification and your argument has merit. I too percieve group think in climate change narratives, while not necessarily disbelieving the data. We are wrecking our environment, exact detrimental effects are still uncertain.
I'm sorry, but given that we're gold fish looking out of the bowl from the inside; trying to predict the future from vague memories of the immediate past; we have no clue what's causing what in this mess. Any one who claims otherwise is an ignorant prostitute, doesn't matter if they're aware or not. There are huge monetary incentives to pushing this agenda, and plenty of bullying to get people to walk in line. Have a look around today, and most scientists seem to agree that we're rather heading into the next ice age.
"There are huge monetary incentives to pushing this agenda"
I couldn't agree with you more.
I also do not buy into the "it's all your/my fault" marketing, b/c it is using guilt and fear to distract focus from the financially incentivized policy makers to the easily swayed mob... one group has the power to effect change, the other has been deluded to believe it can(rare exceptions occur, often over-embellished by Hollywood). Follow the money.
I also see the brown cloud every day over the city I live near. I know from education and experience the only unchecked growth of an organism/group in the natural order is cancerous and parasitoidal in nature; ie: it ultimately kills the host element. The world is full of Thomas Midgely Jr's who would have me believe the exact opposite of what they also know is true, how to find the truth? I don't. I edify myself, I take personal responsibility for my actions and I try to stay away from these MSM and online discussions... try being the operative word.
I see your skepticism - at the same time - I take the data as 'crudely directional'.
'On the whole', it would rather seem we are doing some damage. We don't need perfect predictions to get that.
Second - is the issue of 'risk'.
If there were a 1% chance that your child would be kidnapped if you let them play at the park past 11pm, would you let them do it? No.
Given the level of existential risk inherent in climate change, even if there is a small chance that the climate-alarmists are correct, we basically have to confront the challenge.
Rationally - we should have a very low risk threshold for activities that constitute existential problems for us all.
I'm hugely skeptical of so many specific statements about climate change, especially the politicization and obvious 'group think' - it drives me nuts.
But at the end of the day - 'it looks like in general' there is a problem, and 'even if there is a small risk of it' - we have to do something about it.
Which is how I manage to swallow it all.
So we should take it 'with a grain of salt' but we have to take it, kind of thing.
"Have a look around today, and most scientists seem to agree that we're rather heading into the next ice age."
What scientists are you talking about? Also, didn't you JUST claim "we have no clue"?
By the way, global warming is not the case of some weird uptick in data correlating with some other data being interpreted as causally linked. In the case of global warming, it's really common sense (if you're trained in physics): We understand the infrared spectrum of CO2, and that by absorbing and retransmitting far infrared, it acts to slow the radiative transport of heat. This can be shown in the laboratory. Now, normally you think of the atmosphere being in a steady state, as plants grow they absorb CO2 (converting it into their cellular structure), and as plants die and are digesting or decay, CO2 is ultimately generated. A small amount is buried, but the amount buried is small compared to the overall cycle in a typical year, such that the atmosphere is roughly in equilibrium over the near term, although over the very long term (hundreds of millions of years), CO2 levels have dropped. (By the way, stars generally increase in brightness as they age, so when the CO2 levels were much higher, the Sun was dimmer). This buried carbon becomes fossil fuel, such as coal. Humans dig it up and burn it, but we've really only got good at this process on a large scale within the last 100-150 years (and even in the last 75 years, we've improved productivity by roughly an order of magnitude such that it takes a tenth as much manpower nowadays).
People about a century ago realized that the rate at which we were digging up this long-buried carbon was faster than the rate it was absorbed and buried naturally (makes sense, as the coal was produced over hundreds of millions of years), thus causing the CO2 level of the Earth to start to increase and thus the greenhouse effect to increase. It was just a side note at the time, a whimsical thought about the far future.
But today, the CO2 level has already dramatically changed since the 1800s, and we've also noticed that hey, we can see that predicted temperature rise as well, faster than would be explained just by coming out of the last ice age. This is a totally unsurprising finding if you know the infrared spectrum of CO2 and the rate at which fossil fuel is produced and burned (8-10 cubic kilometers of coal, 3.5 cubic kilometers of oil, about 4000 cubic kilometers of natural gas every year). You can reproduce the change in CO2 level over that time if you assume that roughly half of the carbon we burn every year is absorbed (by ocean, rocks, etc) and the other half stays permanently in the atmosphere.
That CO2 produces an insulating effect on the atmosphere is an indisputable fact. Earth would be much colder without this fact, and you can test it in the laboratory (and this effect is why Venus is hotter than Mercury, even though Mercury is much closer to the Sun).
That humans produce a very large amount of CO2 (i.e. significant fraction of atmosphere's total CO2 over decades) by burning long-buried fuels is an indisputable fact.
That the CO2 level has increased dramatically over the last 100 years is an indisputable fact.
The conclusion is that there MUST be some level of warming from human activity even before you look at the temperature data (which ALSO indisputably shows significant, off-trend warming over the last century), although the exact amount you'd expect depends strongly on the details of our climate system, such as feedback effects (both positive, i.e. increasing the effect, and negative, i.e. stabilizing or counter-acting the effect) from clouds, ice cover, vegetation changes, etc. We DIDN'T have to merely /guess/ at the causality direction after the fact once we saw that all the CO2 was not being fully reabsorbed, as it's a direct physical consequence of the infrared spectrum of CO2, something we can measure in the lab and even replicate from first principles quantum mechanics if we really felt like it. The fact that we observe warming is, to me, just the final validation of what we already knew would happen if we pumped a bunch of CO2 in the air.
By the way, I laugh at the idea that scientists (who can study anything and get grants one way or the other... and are pretty darned poor compared to similarly trained colleagues in the oil and gas business) have a "huge monetary incentive" to push this "agenda" but that somehow, corporations with tens of trillions of dollars worth of fossil fuel assets on the line don't have a similar agenda... I mean, the difference in financial incentive is absolutely absurd!
This to me is a really compelling argument, I wish this approach was more common.
A nitpick:
> I laugh at the idea that scientists...have a "huge monetary incentive" to push this "agenda"
I'm guessing a bit at what you're thinking here, but I think it could be argued that not losing your job could be considered a "huge monetary incentive". I've certainly experienced extreme "peer pressure" to sign off on something that I disagree with before, the idea that office politics literally doesn't exist in the field of science seems quite unlikely to me.
Oh sure, but it's not related to global warming per se. And specifically, the monetary incentive, in terms of actual dollar amounts, is absurdly tilted toward those who hold vast fossil fuel portfolios.
> Unfortunately, the fact that this is occurring so rampantly will bolster anti-intellectuals and give them a very potent argument to point to when presented with facts.
Shouldn't you be just as well happy that these "anti-intellectuals" are pointing out flaws in something you thought was true?
> Unfortunately, the fact that this is occurring so rampantly will bolster anti-intellectuals and give them a very potent argument to point to when presented with facts.
I agree with your point, but I suspect your choice of wording tells a little more of the story.
You said "facts", but given your skepticism of their veracity, I think "claims" or "propositions" is more apropos.
Consider the rhetorical difference of these two statements:
"Anti-intellectuals don't accept the facts."
vs.
"Anti-intellectuals don't accept the claims."
I would also question your use of the term "anti-intellectuals". I wonder if, at least for some of the persons to whom you apply that label, a better term is "skeptic".
Very good points. My own bias is to believe the claims of the scientific community and is thoroughly revealed in my language. Perhaps I'm the one being bilked.
Thanks. I think the discussion gets a little tricky because the groups "scientific facts" and "anti-intellectuals" are pretty broad categories.
I'm guessing that in a group of 1000 people that you would call "anti-intellectuals", some portion of them really do deserve that label.
Similarly, in the group of propositions you'd call "scientific 'facts'", some really are beyond reasonable dispute (i.e., Newton's laws in everyday-life settings). But that there are some other propositions which the academic community and their mouthpieces (New York Times, etc.) hold with unjustified confidence.
I totally agree. The third constant of life, after Death and Taxes, is Bullshit. It is preciciely why the scientific method was conceived, as a way to filter out the progress hindering bullshit that laces all passed-on information due to emebelishments brought on by ambition.
I am somewhat disappointed with the lack of replicability in the field of machine learning and computer science. I think there is not much excuse for releasing a ML paper on a new algorithm or modeling technique without a link to a source code repo. Sure, your research code may not be pretty, but that should not be a deal-breaker. I hope reviewers start rewarding papers with links to source code. This should also stimulate refactoring, documenting, and cleaning up the linked source code.
Also a standard unified process for replicability, reproducibility, and reuse is needed. Dock points for not stating random seeds, hardware used, metadata, etc.
I have tried and failed to reproduce some findings on ML papers. Sometimes graphs are being significantly smoothed or filtered which makes results look better, other times core components of algorithms are not described and the findings cannot be reproduced at all.
Source code, or at the very least proper pseudocode, should be mandatory for all published computer science research.
So I can't be the only one who has noticed the correlation between this and the field at question. As soft sciences like soc, psych, and medicine seem to have the most problems with it. I'm not saying hard sciences like physics don't, but it is less common.
The math for the soft sciences isn't as concrete and doesn't provide a good foundation. I think there are also major problems with the use of p values. It is too easy to manipulate and a lot of incentive to do so. Teach a science class (even the hard sciences) and you'll see how quickly students try to fudge their data to match the expected result. I've seen even professionals do this. I once talked to a NASA biologist who I was trying to get his chi-square value and took a little bit of pressing because he was embarrassed that it didn't confirm his thesis (it didn't disprove it though. Just error was large enough to allow for the other prevailing theory). As scientists we have to be okay with a negative result. It is still useful. That's how we figure things out. A bunch of negatives narrows the problem. A reduced search space is extremely important in science.
The other problem is incentives in funding. There is little funding to reproduce experiments. It isn't as glorious, but it is just as important.
>So I can't be the only one who has noticed the correlation between this and the field at question. As soft sciences like soc, psych, and medicine seem to have the most problems with it. I'm not saying hard sciences like physics don't, but it is less common.
It is a problem in physics, although a "different" problem. See my comment:
Yes, but there is a huge difference in degree of problem. That's what I'm getting at. It exists, but in the soft sciences it is much more rampant. Compound that with the weaker analysis and the problem starts becoming that you have to become skeptic of any result from the field.
Another important distinction between physics and, say, psychology is that the latter studies aren't testing a theory, they're testing an observation. A particular observation sometimes leads to the widespread assumption that a particular effect exists, but without anyone trying to shape a theory about its cause, only that it exists. In physics by contrast, it's all about fitting an observation into existing theory.
Soft sciences actually dont have a greater problem with replication. It is just more publicized, in part because those researchers are actually addressing the problem and making large scale replication attempts.
Well that depends. What kind of reproducibility are you talking about? If we talk about something like Higgs then it was definitely reproduced. Same with gravitational waves.
But the other problem is that the soft sciences have a compounding problem. The one I mentioned about the foundation not being as strong. As a comparison psychology needs a p=0.05 to publish. Particle physicists need 0.003 for evidence and 0.0000003 for "discovery". But the big difference is the later are working off of mathematical models that predict behaviours and you are comparing to these. You are operating in completely different search spaces. The math of the hard sciences allows you to reduce this search space substantially while the soft sciences still don't have this advantage. But give them time and they'll get to it. The math is difficult. Which really makes them hard to compare. They have different ways of doing things.
The huge huge huge majority of published papers aren't CERN-style monumental efforts with bazillions of repeated experiments that you can use to get insanely good stats on.
From my own experience in my PhD I've seen outrageous replication problems in CS, microbiology, neurology, mechanical engineering, and even physics on the "hard sciences" side of things. I've seen replication problems also in psychology, sociology, and political science on the "soft sciences" side of things.
People who come from a "hard science" background seem to have this belief that it is way more rigorous than other fields. I disagree. If anything, the soft sciences are actually making a movement to address the problem even if that means more articles being published saying that 40% of psych papers are not reproducible or whatever.
So. Having been a scientist, I observed an interesting phenomenon, several times. It's almost as if scientists enjoy leaving out critical details from the methods section, and other scientists enjoy puzzling out what the missing details are. I think there's this sort-of assumption of competence that for any reasonably interesting paper, the people in the field who are reading it, they have the level of skill to reproduce it even with missing information.
"It's almost as if scientists enjoy leaving out critical details from the methods section, and other scientists enjoy puzzling out what the missing details are."
From my experience, at least in horticulture, scientists leave out a few methods because there's some sort of potential patent or marketing process in the works and they don't want to reveal too much and be beaten to the punch.
Do you think that has anything to do with the incentives for reviewers, who want shorter papers with a length limit and prefer more details on the impact/why of the experiment?
Does the same method-hiding hold true in journals without length limits or different review processes?
In the software world, Bioinformatics has 2 page application notes[1]. That is nowhere near enough room to have a figure, describe an algorithm, and describe results. In cases where the source code is available, I've found the actual implementation often has steps not described at all in the algorithm. And these differences make a clean room implementation difficult to impossible if you want to avoid certain license restrictions.
Since it has been a decade since I worked in a wet lab, I'm less familiar with examples in that world, but I know not offending chemical vendors is a concern for some people in the synthetic chemistry world. At a poster session, they'll tell you that you shouldn't buy a reagent from a particular vendor because impurities in their formulation kill the described reaction. They won't put that in a paper though.
In applied mathematics, the idea of having a standard platform for releasing numerical experiments and standard datasets have come and gone over the years. My advisor said that in the early 2000s, there was a push in some areas to standardize around Java applets for this in a few journals, but never really took hold. Nowadays I would think some form of VM or container technology could probably do the trick while avoiding configuration hell. Commercial licensing for things like MATLAB or COMSOL etc. would be the real challenge for totally open validation in a lot of disciplines. Proprietary software is way more prevalent in scientific and engineering disciplines than I think many general software developers realize.
The good news is that you can't really fake proofs or formal analysis. But the truth is, many folks in the area do cherry pick use case examples/numerical validation as much as you see in other disciplines. Perverse incentives to publish, publish, publish while the tenure clock is ticking keeps this trend going I think.
I doubt we have any container technology today that anyone would want to use in 10 years, just like nobody would want to use a Java applet today.
And I say this having used Docker myself to make one piece of computational research reproducible. I'm not sure it helped in the end. I do encounter people who want to reproduce it, and mostly I have to teach them how to use Docker and then apologize for all the ways it goes wrong.
>The good news is that you can't really fake proofs or formal analysis.
It's my understanding that most published mathematical proofs aren't "hey look at this theorem in first order logic that we reduced to symbol manipulation"; rather, they present enough evidence that other mathematicians are convinced that such a proof could be constructed.
I work as an applied mathematician. In general, I would say that this is incorrect. Virtually all of the papers that I read I would contend have full proofs. That said, I can sympathize with the sentiment in a certain sense.
Just because a paper contains a proof doesn't mean that the proof is correct nor that it's comprehensible. Further, even if a paper went through peer review, it doesn't mean that it was actually reviewed. I'll break each of these down.
First, a proof is just an argument that an assertion is true or false. Just like with day to day language, there are good arguments and bad arguments. Theoretically, math contains an agreed upon set of notation and norms to make its language more precise, but most people don't abide by this. Simply, very, very few papers use the kind of notation that's read by proof assistant tools like Coq. This is the kind of metalanguage really required for that precise. Now, on top of the good and bad argument contention, I would also argue that there's a kind of culture and arrogance associated with how the community writes proofs. Some years back, I had a coauthor screaming at me in his office because I insisted that every line in a sequence of algebraic reductions remain in the paper with labels. His contention was that it was condescending to him and the readers to have these reductions. My contention was that I, as the author of the proof, couldn't figure out what was going on without them and if I couldn't figure it out with all those details that I sincerely doubt the readers could either. Around the office, there was a fair amount of support for my coauthor and removing details of the proof. This gives an idea of the kind of people in the community. For the record, the reductions remained in the submitted and published paper. Now, say we removed all of these steps. Did we still have a full proof? Technically yes, but I would call it hateful because it would require a hateful amount of work by the readers to figure out what was going on.
Second, peer review is tricky and often incredibly biased. Every math journal I've seen asks the authors to submit to a single blind review meaning that the authors don't know their reviewers, but the reviewers know the authors. If you are well known and well liked in the field, you will receive the benefit of the doubt if not a complete pass on submitted work. I've seen editors call and scream at reviewers who gave "famous" people bad reviews. I feel like I was blacklisted from one community because I rejected a paper from another "famous" person who tried to republish one of their previous papers almost verbatim. In short, there's a huge amount of politics that goes into the review process. Further, depending on the journal, sometimes papers are not reviewed at all. Sometimes, when you see the words "communicated by so-and-so" it means that so-and-so vouched for the authenticity of the paper, so it was immediately accepted for publication without review. Again, it varies and this is not universal, but it exists.
What can be done? I think two things could be done immediately and would have a positive affect. First, all reviews should be double blind, including to the editor. Meaning, there is absolutely no good reason why the editor or the reviewers should know who wrote the paper. Yes, they may be able to figure it out, but beyond that names should be stripped prior to review and readded only at publication. Second, arbitrary page limits should be removed. No, we don't need rambling papers. If a paper is rambling it should be rejected as rambling. However, it removes one incentive to produce difficult to follow proofs since now all details can remain. Virtually all papers are published electronically. Page counts don't matter.
In the long run, I support the continued development of proof assistant tools like Coq and Isabelle. At the moment, I find them incredibly difficult to use and I have no idea how I'd use them to prove anything in my field, but someday that may change. At that point, we can remove much of the imprecision that reviewers introduce into the process.
The problem is that many branches of science don't have any immediate pressure to produce something that is usable by people outside the field, and sometimes not even peers. So they do what is needed to get out papers, and bothering about eliminating false results goes against that interest.
I'm going to bet that in competitive research branches, for practical applications, that have objectively verifiable results, most studies will, in fact, be reproducible.
In the physical sciences experiments can be enormously expensive to run and doing them "continuously" is impractical. Groundbreaking work is usually verified independently, but it varies across fields. E.g. physics is usually quite careful about reproducing new physics before accepting it, while in the biological sciences it seems that work isn't always reproduced.
> Is there any such thing as Continuous Reproducibility?
Only in principle. Most studies are episodic -- they have a beginning, an end, and publication of results only after the end. For continuous replication to exist, laboratories would have to be much more open about what they're working on, less competitive as to ideas and funding than they actually are.
> How prevalent is this in different branches of Science?
It's nonexistent everywhere but in "big" physics, where (because of the large number of people involved) people tend to know in advance what's being worked on. But I'm only saying physics opens the possibility for continuous replication, not that it actually exists, mostly because of cost.
Well often in behavioral sciences, the alternative hypothesis in experiment A is the null hypothesis in the follow-up, experiment B. If the results in alternative A do not act like the results in null in experiment B, then there is a failed replication. The researcher observing this, begins to lose confidence in the earlier finding, and pursues other ideas. This is the kind of implicit replications currently supported by funding agencies.
I completely agree with applying software engineering skills to this. Not just CI for deployment, but also open-source collaboration. I see research and development in other fields as largely like closed-source silos, and a centralized but evolving ecosystem for information collaboration in any topic is in the works.
I know that is definitely one of my driving visions for ibGib, and I can't be the only one. Open source, open data, open collaboration.
>Constantly checking that the science can be reproduced?
Scientific experiments usually need actual things to be manipulated in the real world. So I think a concept of Continuous Reproducibility may only applicable to a subset of science that can be done by robots given declarative instructions.
While I understand that the life sciences dominate science research right now, it still annoys me when I read a headline about "most scientists" and the article is exclusively about the life sciences. Even if the physical sciences have reproducibility issues of their own, those issues may be different enough to frustrate lumping all of the sciences together.
I suggest that future articles about the reproducibility crisis should either: a) Specify "life science" in the title, or b) demonstrate that the generalization is justified.
My field (physics) is certainly not perfect, but we do have a reasonable body of reliable knowledge including reproducible effects. I work for a company that makes measurement equipment, and we are deeply concerned with demonstrating the degree to which measurements are reproducible.
At this point, since papers like Nature and Cell are so important to scientists, could it be feasible for them to simply require any submitted paper to them would only qualify for publication if the results were independently replicated?
They could even smoothen the process by giving the draft a 'Nature seal of approval' that the authors could use to get other institutions to replicate their work, and add a small 'Replicated by XX' badge to each publication to reward any institution that replicated a study.
Funders of studies might improve the quality of the research they paid for by offering replication rewards. I.e. 5% of all funding goes towards institutions who replicated results from research they funded.
Of course there would still be some wrinkles to iron out, but surely we could come up with a nicely balanced solution?
I think you vastly underestimate how much a lot of scientific studies cost. It would be ideal to be able to have studies replicated by a separate group, but there are many times labs that have specialized equipment and engineering that make replicating studies by some random group unfeasible.
In addition, if you spend too much time trying to replicate others' work, you have no time to work on the things that will actually continue to fund your own research.
The best thing is to have a healthy, skeptical, but collegial, competition in the field. That still requires more funding though!
> I think you vastly underestimate how much a lot of scientific studies cost
Do you have data for this claim? There's tons of extraordinarily expensive experiments through and through, but there's also stuff with incredibly high and time-consuming up-front design and exploration costs that is actually almost trivial to replicate on a per-unit basis.
Really, even without specialized equipment, science is expensive. And many scientists got into the field because they wanted to do their own work.
Locking a lab that can't afford to fund an independent replication study out, or who isn't prominent enough to be able to rouse someone's attention to do it, would be disastrous for a lot of early career researchers.
If it only works on a Wizbang 200 and cannot be reproduced with the Doodad 3000 then it probably doesn't work or there are other variables missing from their results. Specialised equipment should not affect results (proving that equipment is broken has some value though).
I published in nature. The results were based on a computation that was so large, no other entity in the world could have reproduced it at the time (I work for Google, we built a system that used 600+Kcores continuously for years). I don't think ,at the time, that anybody other than Amazon or Microsoft could have run the same calculation as us.
Should our publication have been prevented simply because nobody else had the resources to replicate?
We share all the results from our research, so people may inspect them in detail. We also share our methods in enough detail that if somebody was sufficiently motivated, they could reproduce the work by spending time and money
however, If you follow your logic, you would prevent CERN from publishing the discovery of the Higgs Boson, because nobody else has a particle accelerator powerful enough to detect them. You would prevent the LIGO people from publishing because nobody else has a multi-mile-long interferometer that can detect gravity waves. There are many unique resources that would be prevented from publishing under your idea.
Contrary to what most non-scientists claim about science, reproducibility is not a requirement for discovery science. What is import is scrutiny- ensuring that when people discover something using a unique resource, other people can inspect the methods and the data and decide whether to believe the results.
Though I agree for the most part, isn't CERN using multiple teams on multiple detectors, even going so far as having multiple implementations of data analyses and such, just to make sure any result they find is never a product of one person or team making a mistake in their process?
CERN has multiple detectors (CMS and ATLAS are the two best-known) but they serve different purposes and are attached to the same system (LHC). Exacycle also did something similar (we ran multiple different protein folding codes on the same infrastructure).
You're addressing another issue: they built replicability into their scientific method (which is awesome) but it's still within a single logical entity (which happens to be distributed throughout the world).
LIGO went one better and injected fake events to make sure their analysis systems were working.
Well, maybe they could not run the full experiment, but maybe they could audit the source code of the computation you ran, maybe just a small subset of the computation on for example a synthetic smaller dataset, that could maybe be used to test whether your computation works like it should.
Did you think about the replicability of your research while you were working on it?
Gromacs (the code we used) is open source. MSM, the code we used to analyze the data, is open source. We ported MSM to an internal Google framework (Flume), so the resulting code could be open sourced, but wold be lacking the Flume framework to run inside.
As for thinking about replicability, sure I thought about it. That's why we released all the data we generated and described our methods in detail- so pharma and academics could use the data with confidence to design new drugs that target GPCRs. I also decided that rather than focus on replicability, I would focus on discovery and sharing, and I think that actually is a better use of my time as well as the time of other scientists.
There are two ways that things can be reproducible: reproducible in practice and reproducible in principle. You are stating that you have a computation that is reproducible in principle (just in practice, unfeasible).
I find this an easy and useful distinction and your publication should NOT be prevented from being published by this measure.
How can there be any other answer than "yes"? The point of science was that it's reproducible; you are saying that what you did was not; therefore, it wasn't science.
What is the difference between your paper and an Uri Geller "experiment"? Both are extremely hard to duplicate for objective reasons so their results have to be accepted based on reputation. (Imagine someone trying to publish the same thing but using "Startup LLC" instead of "Google".)
Actually, reproducibility is not considered a necessity in science. It is factually false to say that a person who carries out an experiment in good faith and shares their methods and results is not scientific- they just aren't satisfying a criterion which is a good thing to have.
It's pretty clear what's different between my paper and a Uri Geller experiment. If you can't see the difference, you're either being obstinate or ignorant. We certainly aren't banking on our reputation. A well-funded startup with enough cash could duplicate what we did on AWS GPUs now. I would be thrilled to review their paper.
I would say that most scientists, at the top of their game, who have years of trusted publications behind them, should be given some latitude to publish discovery science without the requirement of reproducibility, so long as they share their results in detail, and accept postdocs who then take the resulting research materials to their new labs.
I didn't always believe this, but after spending a bunch of time reading about the numerous times in history when one scientist discovered something, published the results, and were told they were wrong because other people couldn't reproduce their results, only to be shown correct when everybody else improved their methodology (McClintock, Cech, Boyle, Bissell etc).
This ultimately came to a head when some folks critized the lack of repeatability of Mina Bissel's experiments (for those who don't know, she almost singlehandledly created the modern understanding of the extracellular matrix's role in cancer).
She wrote this response, which I originally threw on the floor. http://www.nature.com/news/reproducibility-the-risks-of-the-... After rereading it a few times, and thinking back on my experience, I changed my mind. In fact, Dr Bissel's opinion is shared by nearly every top scientist I worked with at UCSC, UCSF, and UC Berkeley. The reason her opinion has value is that she's proved time again that she can run an experiment in her lab that nobody else in the world is capable of doing, and she takes external postdocs, teaches them how to replicate, and sends them off to the world. In other cases, she debugged other lab's problems for them (a time consuming effort) until they could properly reproduce.
I believe reproducibility is an aspirational goal, but not really a requirement, for really good scientists, in fields where reproduction is extremely hard.
For those interested in learning more about excellent scientists whose work could not be reproduced:
Tom Cech and his grad students discovered that RNA can have enzymatic activity. They proved this (with excellent control experiments eliminating alternative hypotheses) and yet, the community completely denied this for years and reported failed replication, when in fact, the deniers were messing up their experiments because working with RNA was hard. Cech eventually won the Nobel Prize.
Stanley Prusiner: discovered that some diseases are caused by self-replicating proteins. Spent several decades running heroic experiments that nobody could replicate (because they're heroic) before finally some other groups managed to scrape together enough skilled postdocs. He won the Nobel Prize, too.
Barbara McClintock- my personal favorite scientist of all time. She was soundly criticized and isolated for reporting the existence of jumping genes (along with telomeres) and it also took decades for other groups to replicate her work (most of them for lack of interest). Eventually, she was awarded the Nobel Prize, but she also stopped publishing and sharing her work due to the extremely negative response to her extraordinary discoveries.
Mina Bissel went through a similar passage, ultimately becoming the world leader in ECM/cancer studies. She will likely win a Nobel Prize at some point, and I think we should learn to read her papers with a certain level of trust at this point, and expect that her competitors might actually manage to level up enough to be able to replicate her experiments.
Thanks for the lisr. I think negative effects of labeling a paper irreproducible when in fact it is not is greater than the positive effect of correctly labeling a paper correct.
Because if a piece of work is important enough. People will find the truth. If it is not important enough.. then it does not matter.
Many times it requires years to build a laboratory which can even begin to replicate the work of an established operation.
And sometimes it is impossible to solve a difficult problem using the first lab one builds in pursuit of that concept.
In these cases the true type of laboratory needed only comes within focus after completing the first attempt by the book and having it prove inadequate.
Proving things is difficult not only in the laboratory, but in hard science it still usually has to be possible to fully support your findings, especially if you are overturning the status quo in some way.
That still doesn't require findings to actually be reproduced in a separate lab if the original researchers can demonstrate satisfactory proof in their own unique lab. This may require outside materials or data sets to be satisfactory. Science is not easy.
I think all kinds of scientists should be supported in all kinds of ways.
Fundamentally, there are simply some scientists without peers, always have been.
For unique breakthroughs this might be a most likely source, so they should be leveraged by capitalists using terms without peer.
This would be a pretty big step - right now there is a big incentive to be first to publish. Often the researchers who would be doing the replication are competitors, who are racing to publish their results first.
Part of publishing is to put it out for discussion. It should be the best effort and thought to be true, but science is about the evolution of knowledge. Very few things are completely understood, especially in biological and micro/nano fields.
This would effectively lock certain fields out of publishing in those journals. For example, a great deal of population health research involves following people for huge spans of time.
CS is the craziest of them all. Those should be the easiest to replicate. "Here is the code, here is a manifest of the environment/container/disk image/etc." You should be able to take that and run it and get the same results.
Or are you saying that the code itself is the problem and that they've done the equivalent of "return True" to get the result they want?
In my other comment I mentioned the CS results I've largely struggled to reproduce is because they include enough detail for you to get the gist of how it works, but not enough to avoid going down some rabbit holes. Also, not all publications include code. Many venues don't require it.
This is a very unfortunate state of affairs for science in general, giving the amount of tools we have to make an experiment more replicable.
Replication is perhaps simplest in the field of computer science, yet many papers do not release the associated source code and configuration used in experiments. It's very easy to make the code available to all so I find it a bit dishonest and unscientific not to share an experiment.
There may be other things at play which prevent methodology being fully shared, it may get too personal, for example experimental code is sometimes developed quickly, and people may be reluctant to share their own messy code for fear it might reflect badly.
Seconding the support for COS. When they test reproducibility, they actually pair labs that are proficient in the particular technique with the original authors. The two labs (the originator and reproducer) work together to try to replicate the findings in the new environment. It's a smart way to work around the problem of labs trying (and failing) new techniques.
Submitting this because it's come up on HN before and there's a few people who think it's limited to just social psychology or similar. But this report include eg cancer treatments.
This isn't that surprising, at least based on my limited experience from reading computer science research papers. My experience has been that there's usually not enough information for you to implement something. Am I an outlier, or have others experienced the same?
I've spent hours/days/weeks implementing algorithms or data structures from journal articles. No, you're not an outlier. A lot of times they don't include source code, even in the age of Github. Certain details or assumptions are often glossed over, and often the wording of a crucial technical detail is extremely ambiguous. Sometimes the only way I'm able to successfully implement the algorithm/data structure is through sheer luck - i.e. stumbling upon some piece of information elsewhere that gave me the necessary insight to understand what the author of the journal article meant.
I mean, I can understand academic time pressure and everything, but not providing a link to source code in this day and age is almost absurd. At the very least, it certainly doesn't encourage anyone to actually use your research in industry.
E.g. I did my M.Sc thesis on methods to reduce OCR error rates, and when doing my research for it I came across it all the time. Even things like tiny papers describing simple thresholding functions for scanned pages would include a formula or two that in theory fully specified what they described, except that they'd manage to omit critical information such as values of essential parameters even in cases where giving the actual, working code would have taken up a few lines of text.
I'm not sure that this is necessarily a problem. Most working scientists know that preliminary studies are often wrong and just because it is published in some journal doesn't mean it's true. If there's merit to it then the scientific method will eventually settle upon the correct answer. This looks like someone outside the field just came across this news and had a visceral reaction, "Gasp! Most journal articles are wrong! We can't trust science!"
(Note that I'm talking only about hard natural sciences. Social sciences are another whole can of worms.)
I thought the reproducibility crisis was limited to the social sciences and some areas of health/medicine, this is the first article I've seen that claims it is a general problem through all of academia.
The Wiki article on the Reproducibility Crisis cites a Nature survey that makes it seem like the issue is widespread through every industry, including the hard sciences like physics and engineering: https://en.m.wikipedia.org/wiki/Replication_crisis#General
Oh it's general. Apart from anything else, a majority of all scientific papers rely on some form of software, be it simple R statistical scripts, to complex programs. None of those programs ever have bugs in them, right?
Then to be fair to the authors, scientific papers follow a fairly fixed format, often with hard limits on paper length (cf. Nature, etc.). Putting all the detail necessary for replication, and a decent literature review, and an overview , is simple not possible.
And then the meta-problem - which is general - every aspect of science from hiring to grant writing, to managing a phd. farm, to goofing off on ycombinator..., essentially works against anybody trying to do detailed, methodical, provable work, no matter how brilliant they are, because doing all aspects of science properly is incredibly time consuming in a world with an ever reducing attention span.
It is not a completely general problem. In the field I work in (computational physics) we very often reproduce results published by other research groups. It's very common in our field to see plots in a new paper overlaid with data from old papers showing where our results agree (where they disagree is not a reproducability issue but is instead due to our ability to do more accurate calculations).
> None of those programs ever have bugs in them, right?
On that note: I am currently enrolled in and working thru the Udacity Self-Driving Car Engineer nanodegree.
We recently had a lesson with a coding quiz, in which the writeup stated that the output we would get might vary between one of two values; this output (for the code involved) should have been consistent, not fluctuating (as far as I could see). But there was this one small bug (?)...
IIRC, it was something in Numpy or Scikit-Learn - now, that was for one small part of this class. Nothing critical - but imagine it was for something important...
"Science is facing a "reproducibility crisis" where more than two-thirds of researchers have tried and failed to reproduce another scientist's experiments, research suggests. "
Ironically, it says this as a bad thing, but in an ideal world this would be 100%.
It would be like saying "2/3rds of coders have reviewed their colleague's code and found bugs". Since bugs are basically unavoidable, the fact that 1/3 haven't found any points more in the direction that they're not looking hard enough.
edit: pretty much everyone seems to have taken this the opposite way to how I intended it, but re-reading I can't figure out why that is the case. I'll try to re-phrase:
Science cannot be perfect every time. It's just too complex. This is why you need thorough peer review including reproduction. But if that peer review/reproduction is thorough, then it's going to find problems. When the system is working well, basically everyone will have at some point found a problem in something they are reproducing. This is good because that problem can then be fixed and it will become reproducible or be withdrawn. The current situation is that people don't even look for the problems and no-one can trust results.
edited again to change "peer-reviewed" -> "peer-reviewed including reproduction"
It is a terrible thing, and it is absolutely nothing like finding bugs.
Reproducibility is a core requirement of good science, and if we need to compare it to software engineering, the reproducibility crisis is like the adage "many eyes make all bugs shallow", when the assumption that there is many eyes even looking is often untrue. Most studies are never reproduced, but are held as true under the belief that if someone tried they could.
EDIT: You claimed that in an ideal world, 100% of experiments/studies would not be reproducible. This denotes a profound misunderstanding of the scientific process, or the whole basis of reproducibility. In an idea world, 100% of studies would be vetted through reproduction, and 100% of them would be reproducible. This is essentially the fundamental assumption of the scientific process.
No, I claimed that all scientist would have had the experience of not reproducing something. Because if they do it a lot, as part of a regular process then they will eventually find something that doesn't work because the original scientist didn't document a step correctly or misread the results or just got lucky due to random chance.
Just like all developers will eventually find a bug in code they code review. This is different from all code they review having bugs.
While the wording may be vague, they aren't talking about the experiences of a subset of researchers -- they are saying that of the experiments they tried to replicate, 2/3rds weren't reproduceable. That is terrible, and has absolutely nothing to do with finding bugs.
Science publishing is based in a review by peers system. All evident bugs (and many non so evident bugs) should be catched before to appear in a journal. Is totally different to standard journalism.
I agree that there are no test suites to provide experiments to run and no make test to repeat an experiment with little effort. This accounts for the "too complex" thing.
However many experiments should be reproducible. Not making results testable is against the goal of sharing knowledge. But I understand that's an extra effort compared the current state of the art, and that must be rewarded and acknowledged. In another comment I proposed to include reproducibility in the h-index.
I think I must have expressed myself poorly, as I think my conclusion is the same as the article suggests i.e. that the science/code shouldn't be considered "done", until it's been peer-reviewed, since it's easy to fool yourself and others if you're not actually reviewing and testing your code.
Peer review does not imply reproducibility, and it's the latter that is the problem.
I can confirm, as a reviewer, that your methodology and analysis looks sensible, but the flaws may be deeper, and the fact that you didn't publish the 19 other studies that failed, but that this is the "lucky one", or that you simply cherry picked the data, is not something I can see as a reviewer.
This is especially true if the experiment is nontrivial to re-do.
" Peer review does not imply reproducibility, and it's the latter that is the problem."
I think this is the key to it, I'm suggesting that reproducibility should be part of considering something peer-reviewed, but of course as currently practised, that isn't true.
Of course in a software metaphor, that would probably cover both code review and QA, which is sometimes done by a different job role which further muddies the water.
This would be like expecting a car brand to open its code to its competitors before to release a new product. Will lead typically also to the peers rushing to publish the same discovering on disguise before the original.
After reading your explanations elsewhere, I take back my statements. Your statements are literally correct, although easy to take incorrectly, and I support them: in particular you seem to be supporting that 100% of researchers should attempt to replicate studies and do so sufficiently that all of them will eventually fail to replicate at least some studies. I think most of us took this to mean that you thought every study should fail to replicate (by analogy that every software has at least some bugs), but I see now your intent and that your original wording backed that up.
Then you risk to lose all einstein work unless you have two einsteins at the same time in fact. Genious are scarce. And you could not publish nothing about comets for example, because this would be unreplicable until the next 20 years. Is not so simple as that.
I work with principal investigators phd/mds at upenn automating some of their data analysis pipelines.
They have all have secret checklists for bs detection in papers they read. Certain labs set off red flags to them or certain techniques being too fuzzy or easy to mess up.
Every one seems to have their own heuristics, and no one seems to take any article at face value anymore.
I hear PI's say stuff is unreplicable all the time.
Quote: "The issue of replication goes to the heart of the scientific process."
Indeed it does, but some fields don't think it's very important. For example, there's a surprisingly widespread attitude among psychologists that it's either a waste of time or an attack on the integrity of one's colleagues.
Author: Professor Jason Mitchell, Harvard University.
Quotes: "Recent hand-wringing over failed replications in social psychology is largely pointless, because unsuccessful experiments have no meaningful scientific value."
"The field of social psychology can be improved, but not by the publication of
negative findings."
"Whether they mean to or not, authors and editors of failed replications are publicly impugning the scientific integrity of their colleagues."
"Because experiments can be undermined by a vast number of practical mistakes, the likeliest explanation for any failed replication will always be that the replicator bungled something along the way."
It seems not to have occurred to Professor Mitchell that the original study's result might also have resulted from someone bungling something along the way.
I have a high level question that I don't see answered, but maybe I missed it?
Are most studies conducted by folks in academia before they get tenure? That is, are most of these results that they're trying to replicate or study done by people who are rather new to doing studies? Is this even possible to know? My guess would be yes, but really I don't have much to base that on. And if that is a yes could that have something to do with the problem here?
Most studies are done by people who need high impact publications to secure funding to do more studies to produce high impact publications to secure funding to do more studies...
Not having a permanent job just serves as additional motivation to get high impact publications to secure a job.
Well... most studies are conducted by a lab run by someone with tenure. Most people doing the experimental design and research do not have tenure, but are trying to get there. Most people doing the actual grunt work of running tests, drawing blood, dissecting mice, wrangling data, and so on, are grad students or undergrads there to learn. And if that's a problem, it could only be solved by a serious overhaul of the funding model for research.
Replication needs more incentive, too: considered on par with, or even more significant than, publishing any new results in a field. The incentive should come on both sides (rewards for labs that reproduce results of other labs, and rewards for scientists that publish results that are paired with clear methods).
I’m afraid that research is starting to descend into a fight for a few measly dollars, at any cost. If the results don’t really matter, you start seeing far less important measurements like “number of publications” taking precedence, which is a huge problem. At some point, if your lifeline depends on bogus metrics and all the competing labs are publishing crap that no one reads and no one can reproduce, are you forced to also publish the hell out of everything you can think of just to “compete” and stay funded? And at some point, are you spending more time publishing useless papers and writing grants begging for money, than time spent doing useful research? It’s a race to the bottom that will harm the world’s library of scientific data.
This is an especially troubling problem in the soft-sciences. I recently learned about [post-treatment bias](http://gking.harvard.edu/files/bigprobP.pdf) which is one of the bigger problems plaguing the social sciences. Avoiding biasing an experiment when choosing the variables you control for is insanely difficult to the point where I wonder if it's even possible.
The scary thing is that people will regularly cite soft-science publications that align with whatever political agenda they may have, and anyone who dares contradict the authority of those studies are shouted down as "anti-intellectual" or other such nonsense.
I used to abhor people for leaning on their bibles to push their agendas but I'm starting to see how secular people are basically doing the same thing.
I wish they used more specific language than the blanket term "scientists". Reproducibility is highly field-dependent. In organic chemistry, for example, the journal Organic Syntheses only publishes procedures that have been checked for reproducibility in the lab of a member of the board of directors. http://www.orgsyn.org
A few years ago someone published a paper in a highly esteemed journal that was largely thought to be bunk (oxidation of alcohols by sodium hydride). A prominent blogger live-blogged his (unsuccessful) attempt to reproduce the experiment, as did others. The oxidation was in fact due to the presence of oxygen, not due to sodium hydride. The paper was retracted.
An interesting solve here is structuring research grants for outcome replicability. The article implies a real % of grant money is wasted on results that cannot be replicated.
Could look like X0% of grant money is held for future researchers who work on replicating the outcome. And, wouldn't it be cool if Y% of the grant was held back to be awarded to the researcher whose results were replicated?
This spend, while increasing grant sizes, has the effect of creating replicable science which does more for Science and Society than small grants that end up creating non replicable results.
This is what happens when you ignore the incentives. I think forcing professionals in any field to "just be moral" -- "just do the right thing" -- "just ignore the inverse financial incentive"... I think this expectation is in itself immoral; human will power has its limitations and just like everything else, we are very good a justify immoral behavior when being moral contradicts our short term needs.
Regulation is indeed complicated and imperfect.. but the solution isn't a simple one -- its certainly not complete deregulation.
Important scientific results should be replicated. My understanding is that the scientific community now recognizes this and is trying to put in place the institutional frameworks to make this possible. Assuming that gets put in place, the next task is obviously choosing which experiments are important enough to justify replicating. Would be cool to apply some AI so as to remove the politics from that decision.
How about adding reproducibility to the h-index? Let's say that a reproducible paper is worth at least three times as much as a non reproducible one, maybe more (because it's going to take more time to write.) Would that give scientists an incentive to detail their methods so other scientists can reproduce their findings? Would that give rise to reproducibility rings to game the system?
Are there projects (companies, organizations, something else) trying to solve the problem or improve the situation? Maybe focus on a specific field as I'm sure there is a lot of domains where reproduction is just too expensive or too complex.
Reproducibility is a very important part of the scientific method, I would love to contribute to or work on that kind of project.
So these results can't be replicated in controlled situations. Some of this applies to how our bodies work, with many more "uncontrolled variables" than experimenters even thought of.
In which universe should we guide our behavior and believe things based on "science" like that.
Thought Experiment: Compare a mass murderer to a scientist in cases like this.
I noticed this phenomenon recently when reading a variety of articles on evolutionary programming techniques. Each paper would present its benchmarks in comparison to other techniques, which were also described in other papers. Often, a paper would say "we could not reproduce the results in X paper."
As a experimental researcher for the last 16 years, I don't find this surprising. Publishing industry has becoming a scam. Wherein journals like Nature or its sister journals are charging $1000s to be open access. They don't care whether it is reproducible....
It's because there is a huge problem with the scientific publishing business but because people don't want to admit it because it makes science seem "weak" these issues are largely ignored because of other conflicts of (self)interest.
I'm not a scientist in anything but the colloquial term used as description for a curious and interested person, but when I spent time as a sysadmin at a genetics lab I actually had to read papers as part of the job.
I had previously held "science" up on a pedestal, but I quickly learned that bad science abounds even in reputable publications, and is rarely called out (mostly because scientists use publication to further careers largely based on name-on-paper count).
These days, every time I hear some scientist say "I've been published $largenumber of times," I think to myself 1/3 are probably impossible to reproduce, and 1/3 are probably "I developed this field specialized technique so I get a name drop but didn't actually participate in the study."
Information is always incentivized one way or another, and people will keep things that contradict their narrative and incentives out of studies. That's a key flaw in peer-review research that I think needs to be addressed.
And even if they could, they have no time or funding to do so. You get your PhD / postdoc paycheck / tenure / etc by publishing new and original research, not by attempting to replicate previous results.
Direct replication can be very important, at least in math and the hard sciences.
In physics labs, students conduct experiments that once warranted a Nobel prize. And some of the problem sets that physics grad students work on repeats work that once won a Nobel prize.
When I was in physics grad school, a scandal erupted when Jan Hendrik Schön's "breakthroughs" results on semiconductor nanostructures couldn't be replicated. [1] He'd received a fair bit of acclaim, had one a couple of prizes, and I heard there was even Nobel buzz for him. His papers were in Science, Nature, and Phys. Rev. Letters. Several groups tried and failed over and over to confirm his breakthroughs. It turned out that he had falsified data. 28 of his journal articles were retracted by the publishers and others are still considered suspect.
When a theory or experiment comes along that generates the kind of excitement and interest that can lead to new technology or prestigious grants and awards, replication is important. Science stands on the shoulders of what has come before. We need to know that we're building on a solid foundation.
I think this can be very field dependent. I am a physicist and perhaps I am overly optimistic. However, I find that the existence of supplemental materials is helping things a lot. Generally, in an paper (in experimental physics), you are trying to tell a story about your measurements and the understanding that you gain from them. So, it's nice to be able to tell that story, where you focus on the most relevant data. However, with supplemental materials, you can add a lot of the sanity checks that you did (sometimes at the prompting of referees) in the supplemental materials. For example, maybe I want to tell a story about how in some material that by applying a voltage, I can influence the magnetic properties of that material. There are a lot of baseline measurements that you perform these days to determine that. In the past, with page limits, you couldn't include all of that information, but now, you can place a great deal more in.
In my particular field, my raw data is online, so that can be checked--though without more meta data, it would be of limited use to someone without my notebook and annotations. A lot of the code for the reduction tools that we use is also open sourced as well. There have been some moves in science towards reproducible data analysis, but the problem is infrastructure/ecosystem. For example, let's suppose that I use a python code to do some statistical analysis on my data, it could be hard for someone else to try to reproduce that say 20 years from now--because they won't just need the library I wrote, but the entire ecosystem that it lives in--I don't have a good answer for that.
But, I think that for high profile results (again, I'm optimistic) in physics, there's an incentive for other groups to try to reproduce them to see if they hold or not. There have been cases where someone honestly thought that an effect was there (and it was reproducible), but it was found out later that it was due to something extrinsic--for example, many sources of Boron that you buy commercially have trace amounts of magnetic impurities, so it took some time before someone realized that this was the cause for a weak signal that people were seeing.
In some communities, such as crystallography, you have to submit a file which shows your results and it is automatically checked for chemical consistency. I think this can help weed out some sloppy errors. But, it is still possible to make mistakes.
Also, with journals like Nature Scientific Reports, it becomes feasible to publish results that aren't so exciting, but are technically correct (it takes a lot of time to write a paper and an even longer time to publish it and the cost benefit analysis makes it difficult at times to publish everything, so lowering the barrier to publication to technical correctness rather than excitement helps people to publish null results so other people don't waste their time).
There's also the question of where to draw the line as a referee. If someone is publishing a methods paper where they have made a new analysis technique that is going to be implemented in software that most people are not going to check, then I feel obligated to check their derivations, reproduce integrals, etc. For other papers, looking for consistency between different measurements and the literature is probably sufficient.
There's still a lot of work to do, but I don't think things are completely disastrous in physics. I recently had a colleague retire and he was very proud of the fact that his data had never been wrong. The interpretation might have changed with time, but the data itself was right. I think that's the best we can hope for...
Click bait from the BBC. 2/3 of scientists have failed to replicAte a study is not a statement that reinforces the headline. If 2/3 of people have had trouble sleeping that does not mean most people can't sleep.
If you've ever tried a simple science experiment out of a book, it's easy to screw one up no matter how sound the underlying science because you messed something up. A bleeding edge study is several degrees of difficulty beyond that.
> ... it's easy to screw one up no matter how sound the underlying science because you messed something up.
Yes, but when a replication fails, the question one wants to ask is whether it was the original study or the replication effort that caused the problem. J. B. Rhine's seemingly solid psychic-abilities studies couldn't be replicated, but this was because he kept tossing results that didn't fit his expectations, something that didn't come out until after he passed on.
This comment is insightful and is in line with Mina bissels views.
The immediate questions when someone tries to replicate a study is... How hard did they try? Did they go to the lab and spend one year of their life learning the technique? Or did they try it once and didn't think hard enough about being careful?
I think the problem is concentrated in life sciences, other disciplines like physics have way more strict statistical significance criteria. I wonder if a quick-but-dirty solution could be to just require stricter statistical significance criteria.
>The reproducibility difficulties are not about fraud, according to Dame Ottoline Leyser, director of the Sainsbury Laboratory at the University of Cambridge.
That would be relatively easy to stamp out. Instead, she says: "It's about a culture that promotes impact over substance, flashy findings over the dull, confirmatory work that most of science is about."
Well, maybe I'm too much of a layman, but that doesn't quite seem to add up. Is not calling it fraud about protecting people's egos and saving face?
Or is it like if an accountant completely screwed up all his work and got the numbers wrong, but it was because they were a buffoon- not a fraudster? I guess that would need a different word than fraud.
A lot of it is people over hyping their results and cherry picking their data to fit a narrative. Can you blame them? You can literally build a career off a paper or two published in Science or Nature.
Meanwhile, no one controlling funding sources or faculty appointments cares that you did amazing, rigorous work if it leads to less interesting conclusions. This is especially true if you generate null results, even though this work may have advanced your field. This puts in place a dangerous incentive system.
Another thing which is not mentioned is that the level of detail provided in many methods sections in papers is not sufficient for adequately reproducing the work. This can be due to word limit constraints or because people forget to include or aren't aware of key steps which are impacting their results. I've been on projects where seemingly irrelevant steps in our assay prep significantly impacted the resulting experiment outcomes.
Do your motivations matter if you do incorrect work? In the example I gave, an accountant can definitely face _heavy_ pressure from his employer to "make the numbers work".
But if the numbers superficially "work" without adding up, who cares what the motivation was? That is buffoonery or fraud.
> Do your motivations matter if you do incorrect work?
YES! If I'm careless my results don't match the data and someone can catch my mistake. If I'm trying to defraud you I'll fix this problem by making the data fit, and it's much harder for people to find the mistake.
If I'm a careless accountant we can audit my spreadsheets and find the errors.
If I'm a crooked accountant I'll have deliberately hidden the "error" in shell companies or offshore accounts, and this will be resistant to lower levels of scrutiny.
It's more like all the competitors in a market lowering their safety standards to cut costs. If buyers can't accurately assess value then it turn into a bad situation for everyone.
Anyone trying to do the right thing goes out of business and someone cutting corners get's their business.
So a tragedy of the commons style "collective action" problem.
It's more like if a guy went to Vegas and came back with thousands of dollars, and decided to tell his friends he's a master poker player, not that he got lucky. Interesting findings happen in scientific experiments, and it's hard to say why, but we should stop acting as if they're always true (and stop just funding quests for even more interesting findings.)
Context: You are a young scientist, under constant evaluation that may not only fire you, but also invalidate lots of your previous work. You have to produce flashy results to grow up on your career. You _really_ do not desire to get stuck where you are now.
Now, let's decide on a new experiment to proceed. Do you choose:
a - Boring important experiment that you can't hype but will surely advance your field;
b - Flashy, risky experiment that probably won't lead anywhere, but will change your life if you got lucky;
Now, let's say you go with "b" (that's a non-brainier). Four years into the experiment your results aren't going anywhere. Do you:
a - Accept it's a failed experiment, accept the failure that will set your career back 4 years, start again;
b - Insist on getting more data. Insist on getting more data. Insist on ... oh, never mind, that last data is impressive¹, publish it and go ahead.
This quandary is a great argument for never becoming an academic researcher.
It would seem to me that science needs to eliminate "career bias" or "mortgage bias" or "ramen bias" from its results. Negative results need to be just as publishable as significant results.
If I were tyrant of the Ivory Tower, I would decree that results be blinded until after acceptance for publication. I would further decree that prestige be allocated such that the first and second replications have equal prestige to an original publication, and successive replications are worth less prestige, but are still worth attempting.
The only failed experiment is one that does not advance the body of human knowledge. Negative results still let us know that one thing was tried, and it didn't work--it crosses off one line in a process of elimination. And those that fudge data and methods to produce the appearance of a result, and those that are so flawed as to be non-reproducible, are failures in that sense, even if they still allow for the career advancement of a few people.
I don't know exactly how they work, because I'm not a tenured full professor on a committee, deciding which candidate for hiring (or tenure, promotion, or whatever else) has the best CV.
I would guess that original research showing significant results, published in a major journal, with a lot of citations by peers, earns the most points. You have to ascend higher on the prestige point leaderboard to get the career advancement achievements and character perks.
Publications, funding and status are the goals, not validity. Science became theology and metaphysics - joggling with fancy concepts and theories, producing chimeras from "advanced statistics" and probabilistic models, etc. The main assumption is that no one would even try to validate or reproduce the results, because they are too messy and too costly (labor-intensive).
"Scientist" and "researches" do not even realize that things like "dimensions" are mere concepts and does not exist in reality. Most of "scientists" could not tell an abstract concept from an existent phenomena. Most of them cannot explain the Correlation Is Not Causation principle. They believe that time really exist and could be slowed down or accelerated. Or it could be part of a crystal.)
The "studies" contains naive logical flaws, non-validated references, use of statistical inferences as logical inferences, use of statistics to establish causality and even Excel errors (unwanted auto-correction, rounding etc.)
This is only the tip of the iceberg - there will be turtles^W unreplicable metaphysics-like crap all the way down.
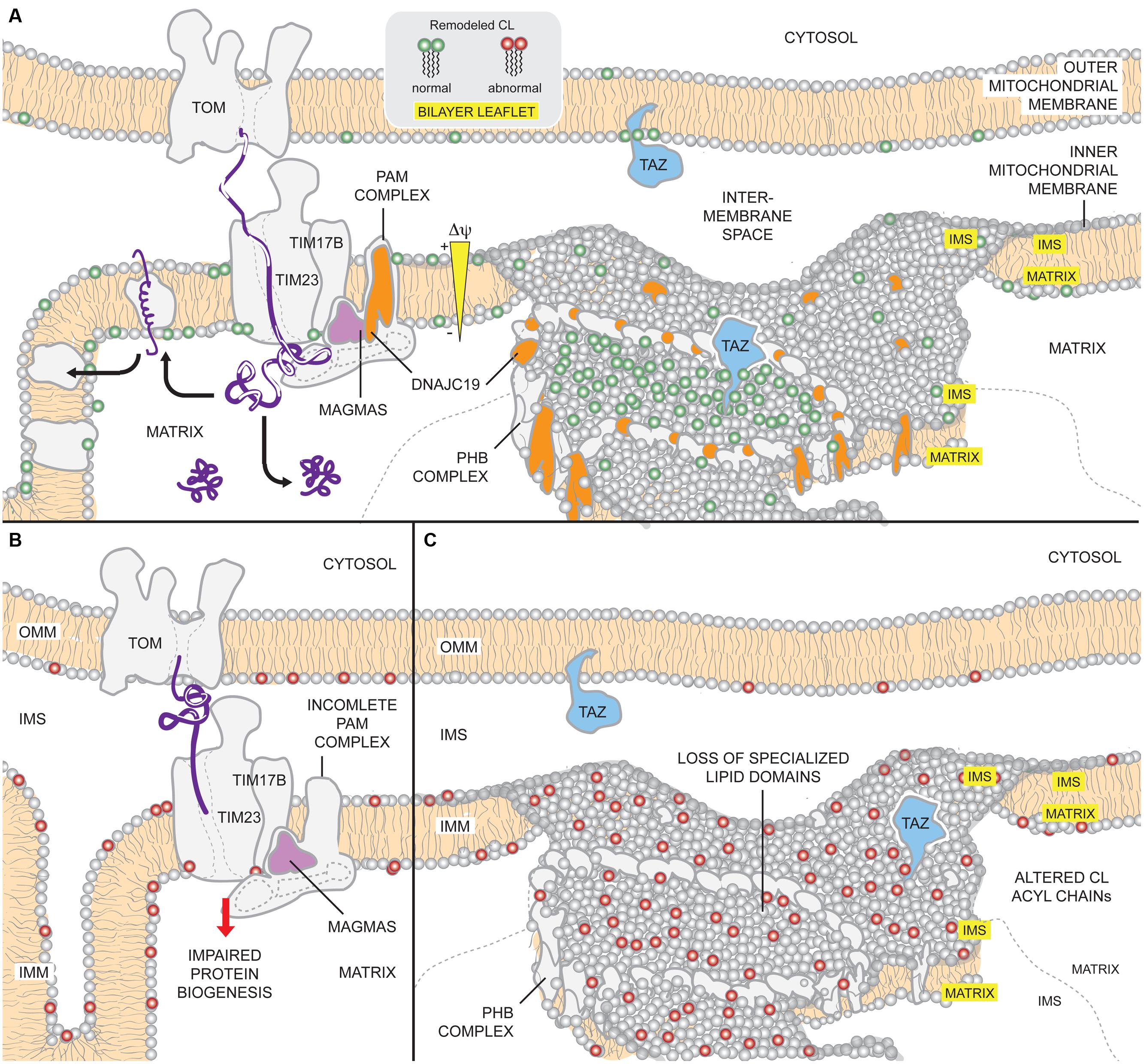{kind=link}
I wish science was that simple. The methods section only contains variables the authors think worth controlling, and in reality you never know, and the authors never know.
Secondly, I wish people say: "I replicated the methods and got a solid negative result" instead of "I can't replicate this experiment". Because most of the time, when you are doing an experiment you never done, you just fuck it up.
Here is an example: we are studying memory using mice. Mice don't remember that well if they are anxious. Here are variables we have to take care of to keep the mice happy, but they are never going to go to the methods section:
Make sure the animal facility haven't cleaned their cages.
But make sure the cage is otherwise relative clean.
Make sure they don't fight each other.
Make sure the (usually false) fire alarm hasn't sound for 24 hours.
Make sure the guy who was installing microscope upstairs has finished producing noise.
Make sure there is no irrelevant people talking/laughing loudly outside the behaviour space.
Make sure the finicky equipment works.
Make sure the animals love you.
The list can go on.
Because if one of this happens, the animals are anxious, then they don't remember, and you got a negative result which have nothing to do with your experiment (although you may not notice this). That's why if your lab just start to do something you haven't done for years, you fail. And replicating other people's experiment is hard.
A positive control would help to make sure your negative result is real, but for some experiments a good positive control can be a luxury.