D&B executive's spouse: You've really got to help my little brother. He hasn't had a job since he got fired from McDonald's two years ago.
Executive: What can he do?
Spouse: He's really good at programming. He took a class in it in high school five years ago, and I'm pretty sure he didn't fail. He even has his own web page.
Executive: Hmmmmm. I think we have something he can work on....
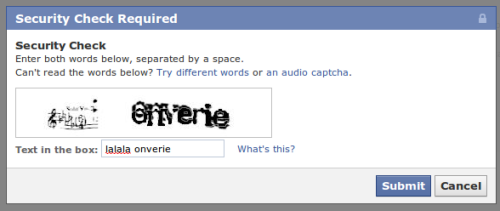
Hey D&B developer here. I'm excited to see so much interest in my work. If the captcha is correct we categorize it as a bot and don't let it through. If the captcha is incorrect then it must be a human and we let them through.
Good news: we're hiring! We have day long meetings Mondays and Wednesdays, but other than that it's great.
I don't really understand this approach. Won't the false positive rate be close to 100%? Humans are going to get the captcha right every time. If it's supposed to be a honeypot system, the input should be hidden from human users to avoid that problem.
You'd think, but what's so dumb about this captcha is that it's both easy to guess for a computer, but for a human too. If you look at it, the random parts are outside the readable text (which is just white on a gray background). I'd love to know what led to the "decision" of implementing something so dumb.
It's not an uncommon strategy (eg: fill up a comment form with hidden but obviously named form fields) and since people won't be filling in those hidden fields then bots will have revealed themselves.
This isn't by any means a complete solution however it does catch 90% of drive-by spam.
Fun tip: reCAPTCHA is actually two things, the "re" and the "CAPTCHA". In other words, one half is about testing that you're not a human, while the other half is a legitimately unknown word from a source of failed optical character recognition.
You actually don't have to get the latter one anything close to right; and I think you're given the option of at least one typo in the actual CAPTCHA test.
So when a CAPTCHA looks impossible, try doing the possible half and typing in "balls" for the other half. It actually works with pretty reasonable accuracy.
Who gives a crap about helping Google digitize books that they scanned without publisher or author permission and that we won't be able to to read afterwards because we have to respect copyright where they didn't?
Capchas are a pox on the web, and reCaptcha a sleazy immoral one, too.
Plus you can guess (with absolute certainty since they changed the domain to read the google.com cookie) they use it as an unblockable tracker to build a database of sites you're registered on.
The more immature part of 4chan has for quite literally years tried to do that with the word "nigger"[1], with no real apparent success (not that I've checked myself, though). One of the easiest things done to counter malicious input is to simply validate any unknown words with multiple people before marking them as "recognized".
It started so well, as a tool to harness collective 'intelligence' to digitize text while preventing spam. Now you're right, even the bloody accessible (audio) versions are useless. It's as if a dozen poltergeists are whispering in your ear, and you have to pick out the one that matters.
Technically somewhat true. Their source material is fragments of books being OCR'd that their program had issues on, some of which are literally impossible (I've seen math equations that require non-unicode characters). On top of this, they add extra distortions.
BUT! These are actually easy to solve. reCAPTCHA will give you two words, only one of which it knows the ground truth on (it's using you to solve the other). It will accept any gibberish for the one word it doesn't know. I've made a point of trying to guess which one is the 'real' captcha (usually the more-distorted one), but next time you see Cyrillic or an integral, just mash the keyboard.
I've had ones in this form a couple of time, where the image is clearly from a photo of someone's house number.
Not sure if they are checking house number positions from google street view with it to.
https://dl.dropbox.com/u/2461478/Images/captcha.jpg
And at the same time, most captcha solving services I've tried break recaptcha with no problem! And they aren't even expensive. Now, I dunno if they use fancy ML techniques or sweatshops with little African children receiving electroshocks when they get one wrong, but they do work to the point that nowadays captchas only repel legit users and very badly engineered spam bots, the good bots are already ahead of the game... I even thought of writing a browser extension that would use a captcha solving service to save legit users from the pain of captchas, but I'm too lazy to do it...
I think all CAPTCHA solving "services" that offer reCAPTCHA solving rely on human work, and thus work on a delay (which obviously is just a minor inconvenience for any mass spamming operation). Here's a pretty nice article about it.[1] ReCAPTCHA itself remains unbroken to date (and it sure has gotten harder over the years too).
There are some services like "Captcha Brotherhood" were you get points for solving captchas of other users, which you then can use to let other users solve your captchas.
I actually think reCAPTCHA has gotten quite good actually after they switched one of the words to a street address. Just look at the examples in this post, most are pretty easy to decode right away.
And you really have to wonder, because the last time I had to implement a CAPTCHA (around 5 years ago), it was about 5 minutes of work. Google query, found a library, downloaded the library, copied the example into a form, and I was done.
I can't imagine coming up with your own clever hacked-together bogus CAPTCHA would be simpler than that. So they actually did it the hard way?
It's like all these sites that requires you to enter your current password before you can change it, but deleting the entire account is just ticking a check box (at least twitter and dribbble worked this way back when I had accounts there).
Some things we been doing for so long that we forget why we do them at all.
Or ones that make you confirm an e-mail address by entering it twice.
The reason you confirm a password is because you can't see the password, and so you never know if you mistyped it. Confirming an e-mail address, in a normal text field, is just stupid busywork.
It does seem that way when you're a skilled typist, but I recall reading an article about a year ago where they discovered that forcing the average user to re-enter their email significantly improved their rate of invalid emails (e.g. not detectable by a regex, like jhonsmith@gmail.com or johnsmith@gamil.com).
A feature like this should probably be considered based on the expected type of user vs. the convenience of signing up quickly. Non-technical users where there isn't a significant dropoff from the signup form => probably a good idea.
I was not talking about retyping the new password, but about requesting the old password before you can change it. The reason you do this is because even if you theoretically could hijack the session, you still can not hijack the account. But the priority seems a bit off when the password is more important then the account, which makes you believe that the people behind the sites only added the extra password validation because they seen it every where else, and not because they understand the principle behind it.
Exactly. The original commenter's point is that they prevent someone from changing your password, but they don't prevent that person from deleting your account.
Or when you enter bad login info, and the site doesn't tell you if it was your email or your password. But on the reset password form it tells you when you put a bad email in.
Well, that's usually a security feature so that hackers can't harvest valid accounts by trying e-mail addresses and seeing what the error message is. It's stupid if they can do that anyway via the password reset form, though (although presumably, if you get the password reset e-mail you'll have an idea that someone else is trying to access your account).
Or the reset password form can simply say an email has been sent to the relevant address, regardless of whether said address actually exists in their database. I've always suspected this is how most of them work.
It is a protection against typos, because people are lazy and error-prone and it matters because getting it wrong means email delivery fails, whereas a misspelled name is no big deal.
So, elegantly, two different issues use the same simple solution.
It's not elegant at all - it makes the user do extra work at signup. Wasn't there an interesting blog post on HN about 5 years ago that showed that each additional field you add to the registration form cuts sign-ups in half?
The better solution is to send an e-mail with a confirmation link upon signup. This also protects against deliberately falsified e-mails, and against typing it incorrectly twice, and against folks who automatically copy & paste when they see "Confirm your..." And it's only a tab switch and click rather than having to key in a few dozen characters, which matters even more in the brave new mobile/tablet world.
I believe that extra field thing is correct. However I don't think your solution is really great either, by forcing the user to confirm their email before continuing your are interrupting their flow. In some cases when I've had this and the email has been delayed by even a few minutes I haven't bothered coming back.
Edit: Sorry I kind of misread your comment, but what I said is half relavent. None of the protections you state you get without forcing them to click the link before continuing.
Yeah, confirmation e-mails suck from a UX perspective. However, they don't gratuitously suck - they solve the problem they're trying to solve, and often users can tell why they're necessary. Extra form fields suck from a UX perspective and have the added problem of not actually solving the problem they're trying to solve.
One of my buddies worked in the accounting department at our state government. He needed to get a bunch of documents from another agency (like hundreds every month) to process claims. Well this other agency requires everyone to go through their website and download each document one at a time. They said it was to prevent abuse. For some reason they couldn't just send a batch of them to us, even a fellow state agency. So I made a scraper to download an entire month at a time. I figure it was a webforms site because it was filled with postbacks and viewstates which made it a bit of a pain, but the ridiculous thing was the CAPTCHA code:
Batman: You either die a hero or live long enough to see yourself become the villain. I can do those things. Because I'm not a hero, not like Dent. I killed those people. That's what I can be.
Lt. James Gordon: No, no, you can't! You're not!
Batman: I'm whatever Gotham needs me to be.
[cut to Gordon at Dent's funeral]
Lt. James Gordon: A hero. Not the hero we deserved but the hero we needed. Nothing less than a knight. Shining.
[Gordon is shown on top of Gotham Central. An axe is in his hand. He is being watched by an assortment of reporters and police officers. The next lines are heard in voiceover]
Lt. James Gordon: They'll hunt you.
Batman: You'll hunt me. You'll condemn me. Set the dogs on me.
no, as I understand, that part alone would be a misdemeanor (and therefore, unlikely to be worth pursuing) under the CFAA. the alleged intent to sell/defraud is what made it a potential felony.
While this captcha is truly a display of ignorance I could imagine that "corporate developers" at D&B aren't web developers. All I am saying is that if you force me to write enterprise software (which I have zero experience with) on a tight schedule I'm probably going to make a stupid mistake or two even though I hope I am not of "lower quality". I imagine someone in management refused to hire web devs because "we've already got developers inhouse". Just a wild guess though.
It doesn't matter though. This isn't just a 'stupid mistake' made by a dev rushed for time, this is literally 'not a captcha.' It's not. Not even a poorly designed and incompetently executed captcha... it just isn't even one at all.
It doesn't take long to find out that best practices exist for captchas, what they are, what the typical vulnerabilities are, and then pick one from the top shelf of existing solutions once you realize captchas are hard to do properly and you're probably not being paid what it's worth to roll your own.
The funny thing is that the dev is apparently competent enough to make it look like a captcha, yet not enough to know what the purpose of a captcha is.
Actually, even if it was real captcha, a computer could still easily guess the answer because the random parts are outside the answer text.
Yeah the regular grid and text would probably make ocr even easier if it were necessary. It wouldn't surprise me if they just used uppercase letters, too.
Maybe they assumed that bots would interpret the page the way a human being would, when they're not looking at the source code? Though my money's on someone just not caring.
Manager: Make me a captcha.
Dev: We don't really need one, all we need is a simple way to avoid dumb automatic submits.
M: Use a simple one, then.
... a few minutes later...
D: Here it is, the user just has to copy over those four letters.
M: Hey this is not a captcha. It does not look like a captcha.
... a few minutes later...
D: Here it is, now it looks like a captcha.
On the other side, it could be very true that if you don't put some annoyances behind it, "normal" people don't recognize it as a captcha... And most of the time (on most custom low traffic sites...) you don't really need much more that a static "write the result of 2+2".
With hindsight, sure. But that's not looking at the whole picture.
The problem is not how much effort to stop this one mistake, the problem is how much effort to stop every potential mistake of similar importance to this.
Or worse, perhaps they did get this from a shelf of existing solutions.
>Or worse, perhaps they did get this from a shelf of existing solutions.
I'd like to believe that was impossible but of course given how irrational it would be to go through the trouble of making this, it's probably likely. Though I don't know why you'd necessarily skip over recaptcha and securimage and how far down the list you'd have to go to get to this sort of thing... but ZeljkoS has a couple more examples like it on his site. So apparently it's a captcha anti-pattern.
It is exactly the type of software you'd expect to be developed by huge, lumbering, beauracratic corporations.
Several years ago when I was doing contract enterprise development work for various Fortune companies, EJB was all the rage in the Enterprise Java space. I started to feel a little rate pressure, so figured I'd better at least pick up a book and get up to speed.
About 3 chapters into it, I couldn't believe how bad it was (especially entity beans). I mean, it was almost like the perfect anti-pattern. Anyway, that didn't stop massive numbers of enterprises from jumping in head first, because it was sold as "the way" to do enterprise development. The tooling and app servers were insanely expensive too. But many IT managers didn't want to take any chances on not going the standard route.
Anyway, that about sums up enterprise software. Even for groups not into EJB specifically, the culture and thinking are the same. There is this meme that enterprise software must be more robust or scalable, etc., but the funny part is that consumer facing Web apps must typically be far more robust and dynamically scalable to serve much larger user bases. Enterprise software is typically run in a more tightly controlled environment too (specified required browser and OS, Intranet-based, etc.).
Yet, just labeling something "Enterprise" and targeting it as such, seems to command a premium.
Less than half of it I've seen is badly written. The bigger problem is enterprise software is all about connecting systems together. That leads to a morass of interdependencies that are nearly impossible to untangle. Worse, there is not a lot of communication between IT and the business, so the business tends to tell IT how to accomplish a task instead of telling it what it wants to accomplish. As a result, solutions tend to be short-sighted.
Extremely slow is a function of the interdependencies and the CYA (nobody gets fired for buying IBM).
And the unwillingness to replace is because nobody actually knows everything the current system does, much less how it does it. Projects that have 10+ year lifespans and touch every aspect of the business are incredibly scary to touch.
So, at some degree of distance, the internets get. the definition mostly correct, but the reason it has chosen (eg all enterprise developers are stupid) is as simplistic as every other conclusion the internets have come to. While there are many people writing code in IT dev shops who really should be analysts, there are also a lot of smart people working in environments constrained like nothing your average startup developer has ever seen.
I've been there, and the only way I'm going back is if it's the only way to keep a roof on my kids' heads. I'll go homeless myself first! :)
Haha, sadly the vast majority doesn't last past 6 years due to EOL on various components and inflexibility to changing business requirements. A more common need is the ability to have a scapegoat / fall-guy for failures of projects that have unrealistic/arbitary requirements and/or deadlines set by an upper management that is no longer in touch with technology.
If it's impossible to make the software elegant because it has to incorporate a boatload of idiotic and mutually inconsistent "business rules", then it's enterprise !
Funny coincidence, I ran into this on another website yesterday. And if it weren't bad enough that it was printed in plain text in the source code, it was only checked client side with javascript. Seriously?
Just because something is checked client-side doesn't mean it's only checked client-side. I've used JS checking on anti-bot questions[1] quite deliberately: it doesn't have any effect on 99%+ of bots, but it stops posts by humans from accidentally being flagged as spam.
[1] admittedly questions like "type someword in this box to prove you're not a spambot"[2] rather than actual captchas, which I agree would be rather silly.
[2] if this is what you meant by a "printed in plain text in the source code" question, remember that most spambots aren't customised to an individual site, they just roam the internet submitting their crap to anything that looks like a comment form. Sure, it's trivial to write a script to parse the page and find the answer to the question - but nobody's actually going to do that for a typical company's "Contact Us" form. Adding this sort of check cuts down on spam enormously (from hundreds a day to zero), and is way easier for humans than solving a captcha.
> admittedly questions like "type someword in this box to prove you're not a spambot" rather than actual captchas, which I agree would be rather silly.
This is not silly. This works extremely well for the low traffic forum I run. Since there are a huge number of phpbb3 forums out there, spammers have made spam bots specifically targeting the platform. If you make your forum epsilon different from the default then the bots don't work without manual intervention. That's enough to keep you off of autospam lists for very, very long periods of time.
And when someone inevitably adds your extra form element to their spam bot (it's happened to me 2 or 3 times over about 6 years) then you just change the answer and it stops working (and they might not even notice since it's a bot).
Updated to be clearer about this. I meant that fake captchas like the one in the OP (which put HTML text on top of a confusing background image to make it harder to read) were silly, not simple question checks.
Same! I was getting 50+ spambots a day registering to my vbulletin forum, even with a really hard captcha. I changed it to a question any eight year old could answer and I instantly went to less than one spambot per week getting through. Easier for users and nearly eliminated my spam problem, win-win.
I have indeed. Anyone have more details? At one point I recall (re)CAPTCHAs being about helping OCR slightly less-readable words from book scans. But they were actual words. They seem to be gibberish words now.
I've noticed that they occasionally have characters that are available in unicode, but are not part of the characters that are available on a 105-key keyboard with or without the shift key.
THe most common one I see is the integral symbol that used to be used as an S. On very rare occasions I see characters like:
Those are the ones googles OCR couldn't decipher. Only one word (the random characters with a asymmetric background and maybe a line through them) matter. Once you know that you stop typing the part that doesn't matter. I usually just type asd (actual captcha)
I find it hard to believe that you could be smart enough to build something like this, while also being dense enough to think that it's actually a CAPTCHA. My guess is that some pointy-haired boss really wanted a CAPTCHA and the developer didn't think it was needed. Everyone's happy.
Of course, the developer could have also just slapped RECAPTCHA on there and been done in even less time...
I've worked for managers who would've ask for features like this; they just wanted it to look like it functioned so our non-technical audience would think it was impressive.
D&B has got itself a sweet little monopoly business with these DUNS numbers. They charge $299 if you want "Expedited" service otherwise (according to the FAQ) it will take "a MINIMUM of 30 business days for a new D&B DUNS Number to be processed" (emphasis added). I get the sense they just sit on you app until the 30 days are up and no actual work is being done.
They also try to upsell you to one of the many other plans starting at $299. To somewhat soften their touch the basic service is free after all. And the expedited service is free for businesses considering doing government contracting (maybe we should all consider this as we apply to the Apple developer program).
It's relevant if being able to automate the connection allows you to circumvent the checks Apple, et al, have put in place with the DUNS number. I have no clue, so I can't render an opinion.
The shown website development bug does not make me confident about the quality of the rest of their website and data handling in general, so yes, I imply that they are not up to protect the data of their customers - which is the area of expertise of anyone handling massive amount of customer data.
I don't see the problem. It's easy for people to see the word and type it in. Lightweight but not insignificant measure of protection. Compared with no protection, this form will receive less spam.
There is no impact on the user except a better user experience.
The corporate developer may have looked at the spam levels and decided that a basic measure would be fine considering the exposure to the page, or other reasons.
CAPTCHA is anti-people. It's a step back to the dark ages every time a website asks you to type in a fuzzy word, often just a jumbled string making it even worse for reading.
Surprised some comments are taking aim at the developer, who at least isn't using the stupidly backwards, barely visible full version of captcha. Check en.wikipedia.org/wiki/CAPTCHA it's a joke that the examples posted there seem so much easier than the overly-abstract usual suspects out there in reality. That wikipedia article needs a new section, something like 'criticisms' or 'UX Fail'.
Very true, why indeed. A misunderstanding of how spam crawlers work? Btw, how do spam crawlers work?
People must prove they are people. And spam crawlers don't need to prove anything. Turing wouldn't have liked his name associated with a test that humans fail often (needing to refresh the captcha), and a test that machines must fail in order to be effective.
Two years ago I had to deal D&B's flagship product, which came packaged in a Java applet. I remember one day I upgraded to the latest version of Java(a security patch) and it broke their tool. After contacting them they said the only solution was to downgrade to the Java version with a known security hole...
There are different levels of "captcha". Some bots just fill any forms on any sites with their spam.. a simple client-side question goes a long way to mitigate this. It obviously is a very different story if it's a script created especially for this form.
Twitter does something similar with 3rd-party authentication. The user puts in their name and password but then the rest of the process can be done by a bot. 1. click on a button to confirm granting access 2. provide the code in an image to he App but the HTML for the code hass the following:
<span id="code-desc">Next, return to TrainerLists and enter this PIN to complete the authorization process:</span>
D&B is in the business of selling your corporate data to marketing companies. They claim that they never share their data base in an automated way, and to protect this information, so that it is only human readable but it is in their best interest to let companies have access. Likely this is there to allow miners, not specifically because they are incompetent, but because they are dishonest.
LOL. So someone is doing automated lookups on the D&B site, they noticed, and then they put a broken captcha on the site.
Really, the only thing wrong with this picture is that they got called out on HN, so now whoever is doing the automated lookups won't be able to kill off D&B by releasing their information.
I hate hate hate D&B. so scammy and spammy and worthless. I think their corporate structure reflects the scam... One company issues the DUNS # but another is the telemarketing spammy one that calls you for years afterward.
My company got a couple of emails from a "credit advisor" Stacy at D&B with no subject. Then in the third email, from the same person... the email was typed out in the subject and there was no body. facepalm
You know, maybe it's because they just wanted to slow down legitimate users for some reason, and spam wasn't a big problem. Ok I'm just trying to be optimistic.
One odd quirk I've noticed with CAPTCHA's is that requesting a new one almost always returns one that is far more legible to discern. Is this by design?
Audio captchas are pretty hard to solve for me personally, much harder than even almost unreadable Captchas. But maybe that's just me. Still can't imagine a bot solving the audio captchas I've heard though.
Wow yes I agree first time I hear reCAPTCHA. I am seriously wondering whether ANYBODY is able to solve this. I know it was broken before but now it seems reCaptchaing something means straight up denying it to visually impaired people.
FWIW, Google Search still uses <b> tags for byte-saving reasons. Search terms are all bolded, and the page would become significantly heavier if those were <strong> or <span class=...> tags instead of <b>.
(There's some crazyness where they actually become <em> tags in China and are styled differently, because Chinese typographical conventions avoid bolding characters and instead turn them red for emphasis. I tried to simplify this once and do everything via CSS, but it turns out to be quite complicated because you also have to handle the case of interface text that's not in Chinese and supposed to be bolded, and exceptions for single-character words, and mixed English/Chinese text, and other languages like Arabic that run RTL, and mixed Arabic/English text, and presumably mixed Arabic/Chinese text though I've never seen such a page. It turns out CSS is fairly limited when you get into the complexities of human typographical conventions across the globe.)
As I noted below, <b> and <i> are meant to be typographically-significant elements, so it's not just byte-saving. Google is using <b> and <i> correctly in that case (even if that's just a happy accident).
Nope, you're wrong. <b> is actually still being used to differentiate between <strong>. <strong> is used for accessibility reasons (making the words enunciate with emphasis, while <b> just makes the words bold by default). If you want to bold a part of the sentence without having emphasis, you'll need to use <b>.
I'd use <span style="font-weight: bold" /> for making something bold. Because that's a styling thing, so I use a style sheet.
I could even use <strong style="font-weight: normal" /> if I wanted to emphasize something without making it bold. Because that has a functional purpose with screen readers, and isn't strictly a styling thing.
<em> is for intonational emphasis, the way you'd give a little extra stress on a word when you are speaking. <strong> is an indicator of importance, and may not correspond to intonational emphasis in spoken language.
As for the older tags, they were deprecated in XHTML, but have been redeemed in HTML 5. <i> is used for elements that are traditionally set it italics but are neither emphasized nor citations. Often that will be foreign words (where one ought to use a lang attribute). Similarly <b> is used to indicate elements that are traditionally set in bold face, but which do not indicate importance (as headings or <strong> in running text would do). Both are better than the semantically-meaningless <span> tag, and vastly better than misusing the <em>, <cite> and <strong> tags for their presentation effects.
I put a super basic human authentication system on my wedding website in the online guestbook. It was just a simple form that was getting hit with spammers, so I added a super quick "What is the groom's name?" field to the form for authentication. Spam stopped completely. Sometimes, depending on the website, a super secure captcha isn't needed.
This should give you a really good idea what it's like trying to get a DUNS number (a requirement for doing contract work with the government as a business). Their entire business is basically the front-end to a scam. Somebody pulled a network contact to wedge their company in between businesses and the federal government.
You are guaranteed to get scammy-sounding emails and phone calls from D&B after signing up. Emails with subjects like "Your business is in danger!" or messages like "Your business credit report has some big issues!" and you find out that in order to get "protection" or to find out what these "issues" are, you have to pay Dun and Bradstreet a shitload of money.
That company is a SCAM and a perfect example of how completely retarded/bought-and-paid-for the United States government is.
It's not just contract work with the government. Once you are a business of sufficient size it's almost inevitable that you'll run into some random thing where you're required to have a DUNS number before proceeding (and it's always unclear why this is a requirement). So dumb.
They have the same slimy up sell tactics as every other credit reporting agency, but the core business is far from a scam.
The startup crowd doesn't see it much, but D&B is a critical component of how non-technical medium to large businesses vet each other and prevent fraud. They are effectively the Better Business Bureau for B2B.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Executive: What can he do?
Spouse: He's really good at programming. He took a class in it in high school five years ago, and I'm pretty sure he didn't fail. He even has his own web page.
Executive: Hmmmmm. I think we have something he can work on....