I previously led a significant chunk of developer evangelism at IBM. Mainframes are unbelievably powerful, feature-full, and cost-effective. You are almost certainly better off buying a low-end mainframe than hiring a team of engineers to build yet another not-great data replication/recovery/HA system. Imagine being able to hire engineers to work on your core value add instead of basic computer management problems IBM solved in the 60s.
The reason you don’t is because it is basically impossible to get access to a mainframe you can play with and learn on. And IBM’s internal incentives and financial metrics ensure that can never happen.
* My views are my own and not those of my former employer.
Sorry to say that your previous "evangelism" shows. It would be very interesting to hear what "unbelievably powerful" means (as in facts and numbers) compared to what a hyperscaler can provide. E.g. SPEC for CPU, GFLOPs, Tensor-ops for inference, latency and so on. Last I checked the consolidation story that claimed factors of savings took underutilized ancient Intel boxes as baseline.
"feature-full" is also quite a stretch when it comes to software when most modern software needs to be ported or run in a Linux LPAR.
In addition I'd question that not getting access easily is the main reason for the lack of adoption. It might be part of the problem but the other problem is that the thing is a niche product and IBM doesn't seem to be utterly successful in either explaining what the niche is nor how to extend it.
Being able to spare a couple of cores as a new partition and moving a partition to it to replace the memory and even the processor of the faulty partition with zero downtime is great.
Consider that partitions are completely isolated from each other. Not some pesky soft isolation either, it's all done in hardware. In practice, every partition in a mainframe is a different logical yet isolated mainframe.
Mainframes are built for different kinds of workloads. They are not cloud machines. They are batch machines with 6 or more nines of uptime.
In my current job, a mainframe would be useless. However, fore mission critical core services which needs predictable latencies (bank transaction engines, central big databases etc.) I'll take a mainframe all day, every day.
> Consider that partitions are completely isolated from each other. Not some pesky soft isolation either, it's all done in hardware. In practice, every partition in a mainframe is a different logical yet isolated mainframe.
"Completely isolated in hardware" as in isolated by a software hypervisor (PR/SM) that doesn't have a whole lot of hardware support?
> Mainframes are built for different kinds of workloads. They are not cloud machines. They are batch machines with 6 or more nines of uptime.
That's kind of the point. What exactly is the niche, i.e. which new customer with exactly what software and latency requirements would switch from their current system to a z? IBM won't tell you apart from buzzword bingo.
Wow. She nails his guff at the end, with one single word.
I'm nominating this video for the next Oscars, Grammies, or whatever the heck the movie awards are called (I don't keep track of such stuff). Bet it'll win gold in the under-1-minute category ;)
They’ve spent the last 60 years developing and refining everything for extreme levels of uptime and high availability. It’s truly unique to these mainframes because IBM controls every aspect of it. The closest equivalent of that kind of vertical integration is your Macbook Pro.
I highly doubt there are any brand new mainframe customers these days. But many of the biggest companies you know and use every single day have tons of workloads that will never move off of it.
I don't think I need to be reading this. The uptime and several 9s of high availability are attainable with z/OS and a parallel sysplex. No doubt systems like these are used by banks and others in the wild.
But this doesn't say anything about "unbelievably powerful" or "feature-full" as in the OP?
The niche customer claim probably is "will never move off of it because nobody ever wants to touch millions of lines of COBOL" then that's fine. It's likely sane from a business perspective to continue using them as long as maintenance burden is manageable. Luckily managers in those more conservative companies consider full rewrites dangerous, rightly so.
But in order to claim otherwise (i.e. unbelievably powerful and thus for everybody) we need to see numbers.
I’d say 15+ years ago, they were very powerful relative to other solutions on the market during those times. But I agree that’s no longer the case when compared to modern server racks.
I pointed out that Redbook about HA features since it’s a major differentiator of mainframes even today, but there are also these that document other features:
You can find 1 or more books that go into a deep dive of every chapter.
IBM has taken input from the biggest companies in the world over many decades to run as many of their workloads as possible. They’ve honed everything in their software and hardware to do so, down to developing specific cpu instructions to support specific use cases. If all of this doesn’t convey an extremely feature rich system, I’d like to hear why you think otherwise.
It is extremely optimistic, to put it mildly. You can definitely get inter-LPAR noise. I've seen it first hand, personally, on systems that I've worked on.
Moreover the norm for zLinux system is to isolate guests with zVM, not LPARs. LPARs are more likely to be boundaries for chunkier workload definitions - that advice may have changed since I last cracked open a redbook; zVM offers similar isolation to what you'd see with KVM, VMWare, or other hardware-assisted hypervisors.
An RTOS defines a stricter latency envelope than a mainframe, almost into "deterministic latency" range.
For example, you can say "this operation will take at most 3ms" in an RTOS, and it'll never exceed that number. If you're running on a fixed-frequency system, you can even say that I expect an answer in 2.8ms all the time, every time.
In a mainframe this is a bit relaxed. You can say that latency is <3ms 99% of the time, <3.1ms in 99.999% of the time and <3.5ms in 100% of the time.
IOW, you never think/say "somebody is running a heavy load on the host, and I also slowed down because of them".
What I tried to say is, a mainframe might answer late, but rarely, and very slightly. a RTOS doesn't deviate from that number in either direction. It's neither early nor late.
Some RTOS even doesn't consider late answers as acceptable.
That's true, but that jitter envelope gets bigger as the load increases. For a mainframe this jitter envelope is much narrower, and in a competent RTOS, that's basically 0.
Telum is attached to the L2/L3 so it's that bandwidth as long as the model fits into it. Afterwards you go to memory and you really don't want to compare DDR4 modules with RAIM against HBM3 or the likes that a current compute GPU uses. Latency might be closer but you mentioned bandwidth.
IIRC, with 32 MB per core (8 per die - a Telum package has two of them), one socket has 256MB of cache for 16 cores. L1 and L2 are in-core, but L3 is on-die unused L2 from other core and L4 is unused L3 on the other die.
I am not sure if that continues off-package, but if it does, a drawer with 4 chips of 16 cores each will have 2 GB of off-chip cache and a full-sized Z with 5 drawers would have 10 GB of off-drawer cache (at this level it's probably not that much faster than same-drawer memory).
As for the RAIM, I think it's safe to assume it has a very wide path (n-1 modules) to the sockets and that aggregate bandwidth will not leave the 4 sockets starved (even if latencies suffer because of the redundancy, but you can replace a defective memory module with a running computer without it having to pause.
Some more details for people who know about these things, emphasis mine:
2 chips make a dual-chip module with 512MB cache, 4 dual-chip modules make a drawer with 2GB cache, and a 4 drawer system with 32 chips makes 8GB cache.
"The L3 and L4 virtual design across the fabric provides 50% more cache per core, with improved latencies. The idea is that software and microcode still see two separate caches. These caches are shared and distributed across all eight cores via a 320 GB/s ring and across the integrated fabric. Horizontal cache persistence should further reduce cache misses as well. Specifically, when a cache line is ejected, the system looks for available cache capacity on other caches, first on the chip and then even across the 32-chip fabric."[0]
"The accelerator itself delivers an aggregate of over 6 TFLOPS of 16-bit floating-point throughput per chip to scale up to roughly 200 TFLOPS per system. 1024 processor tiles in a systolic array make up the matrix array, and 256 fp16/32 tiles make up the accelerator for computing activations and include built-in functions for RELU, tanH, and log. The platform also provides enterprise-class availability and security, as one should expect in a Z, with virtualization, error checking/recovery, and memory protection mechanisms. While 6 TFLOPS does not sound impressive, keep in mind that this accelerator is optimized for transaction processing. Most data are in floating-point and
are highly structured, unlike in voice or image processing. Consequently, we believe this accelerator will deliver adequate performance and is undoubtedly much faster than offloading to another GPU-equipped server or running the inference on a Z core. The latency of off-platform inference can cause transactions to time out, and inference does not complete"[0]
"Intelligent Prefetcher and Write-Back
– 120+ GB/s read bandwidth to internal scratchpad
– 80+ GB/s store bandwidth
– Multi-zone scratchpad for concurrent data load, execution
and write-back
Intelligent Data Mover and Formatter
– 600+ GB/s bandwidth
– Format and prepare data on the fly for compute and write-back"[1]
TBH, I don't really think they compete in anything like similar markets.
You buy a DGX A100, or a cluster of them, for training and running large deep learning models (or for doing "traditional" HPC).
IBM's solution is more a small inference engine that is part of the CPU, so you don't need to move you data off-chip when doing a little bit of inferencing as part of some other workflow. I don't work with mainframes so I could be talking out of my behind, but maybe something like DL-assisted fraud detection as part of processing bank transactions?
They are tailored to the traditional mainframe workloads (they do a lot of hardware/software co-design in their mainframe lineup), so I wouldn't expect a mainframe designed for the generic cloud hyperscale workloads.
In any case, I have played with their LinuxONE Community Cloud service (running on the previous-gen z15) and it's very fast. The impression I get is that it doesn't need to wait for IO. There is a ton of very clever engineering on those machines and the z16 is a technological wonder.
> Mainframes are unbelievably powerful, feature-full, and cost-effective.
Maybe things have changed in the last 10 or 15 years, which is the last time I had a legit mainframe at a day job, but back then none of those things were true if you looked at it more than 20 minutes.
I seem to remember nothing being included in the base mainframe… when you started to add things like DR and data duplication and virtualization, it became extremely expensive. Like on the DB side, effing Oracle was much cheaper.
Software licensing is expensive on them, but the people to keep your 99.999% uptime on your Kubernetes cluster aren't cheap either.
And software licenses are one of the reasons why LinuxONE machines exist - they don't run z/OS, so you don't pay those licenses. You can even start a dozen VMs under an LPAR and run your Kubernetes cluster as if it were running on more common hardware that just never, ever fails. IIRC, you can run a special version of z/VM to manage your Linux VMs if you don't want to run Linux on the LPAR and use KVM for your VMs.
When I moved from a tech company to an aero company who used mainframes, there were literally hordes of IBM contractors who helped maintain the mainframe environments. Getting anything done in those environments was a multi month project, even for basic stuff like patching the OS. There were probably 2 or more sysadmins per rack, employed to just keep the damn lights on those boxes.
For context, there was about 1 admin for every 400 servers at the tech company, and that was for the entire tech stack (LAMP).
Mainframes require a lot of care and feeding. In my experience, having worked at 3 different companies who relied on them (education, aero and finance), their capex is higher, their opex is higher and their uptime / reliability is entirely dependent on the facilities / staffing.
You don't think it requires some expensive mainframe admins, even with the fancy software? Anywhere I worked with a mainframe, the mainframe admin was highly distinguished within the org and extremely knowledgeable.
I would argue Kubernetes talent is cheaper than mainframe talent these days because it's ubiquitous.
Yeah, I am that super knowledgeable K8s guy, but I’d still say true mainframe admins are still a higher metric.
But in regards to K8s talent, lots of the people who think they know Kubernetes in production but have never had to actually upgrade the cluster, or go through the process of having to update manifests, deployments, and CSIs, and having to actually deal with api removals.
For many generations now, you can't run Linux on bare metal anymore, it has to be inside an LPAR. I think this is true for z/VM and the other operating systems as well.
It may be implemented in the system firmware, but it's still a hypervisor performing context switches and enforcing access to pci devices. Even if you've never looked at the processor architecture manuals you can tell this is what's happening when you can assign 0.1 cores to an LPAR. Different implementation details but the same functionality as SPARC LDOMs and Intel's vt-x & vt-d.
It took many years for Spectre and Meltdown to be discovered, and that was for CPUs affordable for individuals.
How many security researchers are even familiar enough with the concept of a mainframe to consider looking for an LPAR breakout, let alone have access to the necessary hardware?
Also consider: anyone with access to a mainframe will never ever get approval to try to hack it because companies that have mainframes will never want the risk of accidentally breaking the host in some way.
"... some mainframes have models or versions that are configured to operate slower than the potential speed of their CPs. This is widely known as kneecapping , although IBM prefers the term capacity setting, or something similar. It is done by using microcode to insert null cycles into the processor instruction stream. The purpose, again, is to control software costs by having the minimum mainframe model or version that meets the application requirements."
This whole time I just thought mainframe was an older style word for a large rack based server or server room. Like 'cloud' storage for someone's computer running miniserve.
What is the real difference between a mainframe and, e.g. a rack full of H100s, or rack full of 100GBps networking stuff, or some nice stack of 12x blades with 8x 256 core CPUs?
Why or how does a "mainframe" have more power than that?
Mainframes deliver reliable uptime. They so far are the only ones that can do it reliably, for decades.
Essentially the bunch of boxes model(k8s being the new kid on the block) has been trying (and mostly failing) to provide what mainframes have been providing for 60+ years.
Which is being able to treat your workloads as just a random virtual job you can push wherever and let it run while also giving you ridiculous uptime.
Mainframes are basically the hardware infused uptime deliver machines. They can and will offer 5 9's without any trouble. AWS, Azure, Google's cloud, none of them can deliver that amount of uptime, they ALL have failed repeatedly, so much so, that they purposely try to obfuscate their downtime records. Many don't make any historical data available.
k8s and the like have been trying and failing at reliable uptimes. Sure we've arguably been making some progress, but your average self-hosted k8s team has full-time dedicated teams of people that do nothing but babysit k8s. How many staff do your average mainframe org dedicate to keeping the mainframe alive? Usually 1 person, maybe two. Of course the price you pay IBM or whoever you choose as a mainframe provider will help offset the staff savings from your k8s team :)
It's not about raw compute power. It's about keeping a workload alive for as long as you can deliver power to the mainframe. i.e. the Mainframe promises to deliver uptime for as long as you can keep power to the machine. As parts fail, seriously any part: memory, CPU's, disks, backplanes, it doesn't matter. Mainframes can route around the failed part and you can replace it without turning anything off or affecting your workload. This means your mainframe is sized larger than your workload of course. It's not like the fundamentals of compute change in that regard.
The question then becomes, is the juice worth the squeeze? If your entire business model requires uptime, then you best really, really care about uptime. There is a reason the Visa and Mastercard networks have basically never, ever been down. It's because they know their business only exists as long as their network works. When you want uptime at all costs, you don't run k8s(or whatever the latest craze is tomorrow), you run a mainframe.
Most of us get more uptime than we need with insert favourite cloud provider here. Uptime isn't something they actually sell when you read the contracts you sign. Uptime is just marketing spam.
Well that was their last mainframe model. Yes, VMS still exists, but only on x86 now. VAX has been dead and buried for a long time now. They had a whole different compute architecture or two between then and now.
VAX -> Alpha -> Itanium -> x86.
I worked on VMS at the tail end of the VAX days and then through the Alpha days. Overall I thought VMS was pretty neat. Built in file versioning, the cluster stuff was awesome, arguably better than what k8s and the like can even provide now. They had uptimes in decades, that's not something k8s or any of the other new clustering stuff can even dream of achieving right now.
Yeah, I got an account with VMS Software a few months ago.
However, their website and staff members are so brain damaged that I just couldn't bring myself to waste time with it.
Specifically, their website can't even take apostrophe's (nor many other non alphanumeric symbols) in passwords.
Reported that to them, and their staff not only didn't give a shit, they were adamant that only "$#@!%*&" are all the non alphanumeric characters anyone might ever need (in passwords). :(
Thus my complete lack of interest in VMS from that point onwards. ;)
You oversell mainframes, not sure why you're mentioning k8s but Google which brings 10x more money than visa and MasterCard combined does not use mainframes at all but k8s or equivalent and yet they don't have downtimes either.
With k8s on a major cloud provider you get 99.99% for what? 150$/month? And there is no maintenance what so ever.
Full team managing k8s is a lie, even on prem, what exactly there is to manage on a daily basis?
You are talking about hosted k8s, which is not what I'm talking about. If you have never worked on a on-prem k8s team, you are totally missing out! :)
k8s is brittle, all the other competing tools are also fairly brittle, so it's not like k8s is really alone here. This is why we keep replacing the newest mess of virtualization every once in a while, someone eventually gets fed up with whatever the current crap is and writes a new one. It becomes popular, breaks in new and unique ways, rinse and repeat.
k8s is not even a decade old at this point. Mainframes have been around with 5+ 9's of reliability for 6+ decades.
I'm not overselling what mainframes provide. I think you just have selective memory.
99.99% is not what Mainframes provide, they provide many more 9's than that think 7+.
Most of us don't even need 99.99% uptime, so most of us probably shouldn't be buying mainframes. If you DO need severe uptimes, then you either have a huge oversubscription and dedicated teams of people around the clock babysitting things or you buy into mainframes. You absolutely don't buy AWS or Google Cloud or Azure and say, that's good enough, because their uptimes are just marketing speak, not reality.
Even if it were true what you're saying, z16 for example targets different needs. Can you scale up to seven or eight nines, and even if you could - could you for same price? That's 3 seconds or 300 milliseconds of downtime per year, reliably. Along with predictable high performance (vertical), hotswap anything including memory, resilience with hardware under provisioning, etc. That's what these beasts are for.
> With k8s on a major cloud provider you get 99.99% for what? 150$/month? And there is no maintenance what so ever.
Gross understatement of costs don't you think? Last time I checked it was a base fee of 150$/month for managed k8s + whatever computing resources you end up using.
I think a lot of people might say only IBM sells mainframes - the “z” system.
It’s designed to work as a single high-availability machine with a focus on I/O speeds, rather than a PC cluster that implements high availability at the application level and communicates over IP. You can hot swap faulty components without turning it off. I haven’t ever used one, but I believe you write application code without worrying about such details - the hardware and the libraries you link against will just “make it work”.
Many companies also still rock Fujitsu or Unisys mainframes - IBM isn't the only player in this town. But at least Fujitsu's mainframe EOL is in 2035, so that won't be more than historical trivia soon.
Well you can run Hercules, the emulator. But you will then discover that the mainframe 3270 terminal user interface experience is terrible. A funny thing is this: there is a mainframe plug-in for Visual Studio Code. The idea is you do your COBOL development in Code, and only the plugin actually talks to the mainframe.
A decade ago there was an Eclipse version of this..
> Watch a 10-year veteran insurance employee use a green screen.
Yes! I knew an Insurance customer service op who self-described as having no computer skills, but when I saw her using Reflection it was like watching a speedcuber savant.
The spit take for me was doing process documentation, screen by screen.
I would explain to them to stop after each screen or keystroke, so I could document it.
Despite being smart people and understanding the ask, almost every SME I worked with failed at some point, blazing through multiple screens without even realizing it.
> Sadly, the number of people who remember when GUIs could be driven from memory by keyboard-only has dwindled.
This is so very true, and it's tragic.
Watch an experienced keyboard user, such as many blind users, navigating Windows and it's a wonder of efficiency and speed. It makes the Vim prowess of many Linux folks look very sad, because Vim is just a single editor, while with Windows' keyboard UI, the entire OS and all its apps are operable at this speed. Desktop, file manager, all bundled apps, all 3rd party apps... everything has one global unified keyboard UI.
There was a big appliance/tv/stuff retail chain in my home country that create a fancy new web app for their sales personnel.
If you were smart you'd always look for the older salesman, that would ignore the new web app shell and use the old mainframe app from a terminal emulator. it made the sales experience like 3x faster.
This kind of thing goes back five decades, actually. One of the earliest versions of Unix was PWB/Unix, for "Programmers' Workbench". It was designed as a system for AT&T engineers to author programs for the mainframe in a more sensible (for the time) environment and included software to submit jobs to the mainframe once the programs were written.
The idea of "Unix as your IDE" is a deep, deep cut into Unix lore.
> But you will then discover that the mainframe 3270 terminal user interface experience is terrible.
I was an intern at IBM UK in the late 80s and I had a 3279 on my desk connected to a 3090 mainframe. My recollection is that it was fine for editing and running code: sharp, bright text and snappy response. The clicky keyboard was nice too - probably the best I've ever used in the decades since - although the height of the enclosure would probably hurt my wrists now. The key caps had APL symbols on them too, which was interesting and prompted me to learn about that language a bit. Mostly I was writing APL and REXX code for image processing.
Some of the f/t employees I worked with had worked on the development of the 3297 at Hursley Park. They had some interesting stories.
There's also an IBM-built emulator that has at some point shipped with Eclipse. I used to work on it. The 3270 was fine, just took a bit of getting used to. JCL was the real horror show.
The very argument that was posited by JCL creators about why it was a bad language is one that hits YAML very, very, very hard.
The creators of JCL admitted later that the original sin of JCL was that it explicitly tried to NOT BE a programming language. Everything "programmable" evolved out of real-world needs, creating the mess that it has become.
You can see it today with "programming in YAML", whether it is Ansible, Kustomize, Kyverno (K8s manifests get a pass because they are just serialization of non-programmable thing), or any other weird "we started to add functions to JSON/YAML dumps"
> Mainframes are unbelievably powerful, feature-full, and cost-effective.
I really doubt they are any more powerful than the best x86 rack servers. Their featurefulness is super dated. They are definitely not cost effective (good luck buying it from IBM without a huge contract).
I pity the company that gets into mainframes today. Does that even exist?
I also think most cloud providers are at least a vendor lock-in and maybe a proprietary nightmare. This way you at least got your own iron and ibm comes to fix parts when they break. (Without disabling your system)
I do agree it is debatable whether it is beter than x86 most of the time cost savings projected when using a LinuxOne it is based on licensing. In the past oracle licenses where per core and we did a project where 8 ifl’s replaced 140 x86 cores
I worked at a large health insurance company a few years back. They had a DB2 server running on an IBM mainframe that they were working on replacing with a data lake and cloud-based NOSQL solutions.
It seemed rather pointless to me. The DB2 server was serving queries just fine and when we were working on setting up a microservice that would allow viewing claims history, the storage and server costs for being able to provide queries against three years’s claims were prohibitive.
But they were still persisting down that road when I left.
IBM's proprietary nightmares have, historically, often been quite cost effective. AS/400 did eventually get too long in the tooth, but it had an amazing run for decades where it was extremely competitive for TCO.
"Powerful" is irrelevant if the hw isn't up when you need it.
The current sophistry is that the complexity of multiple "redundant" examples of cheap hardware always costs less than a suitable (or small number ) of better systems.
Open source software shouldn't be a problem. Pretty much anything that has been ported to 64-bit big-endian also works on s390x. The architecture is otherwise pretty non-challenging: always 4K pages, strong memory model. Pre-built binaries are a different matter, of course.
The problem with access is not access as such, but the fact that the community hardware that you can access for free tends to be heavily oversubscribed (or maybe connected to a mismatched storage system).
I've never used a mainframe, but I did manage to introduce a small performance regression in gcc that someone complained about (I did fix it, yes). ;-)
Turned out that s390 couldn't fuse cmp+jmp when the operand was a 8-bit value (_Bool). (That was a while ago, maybe current generation mainframe HW can do it?)
It should be noted that I believe you can get access to Linux s390x boxes in the cloud for not very much money.
It's the z/OS side of things that tends to be prohibitively expensive. Thats almost entirely due to software licensing and not hardware though. The hardware is really not much worse than POWER or any other non-x86 specialty hardware.
So if you are making a product that could be big in the kinds of places that have a lot of mainframes, and you are offering an on-premises version, I'd say to go ahead and get a port to s390x tested (on Linux). It's very cheap to do and a potential selling point for a lot of large companies. Then from s390x to z/OS Unix it isn't all that much more work if you decide to take it all the way and offer official support, i.e. if somebody is going to sign a big contract where mainframe integration would be the differentiator between you and a competing product. Once you've got commitment for a contract of some kind I'm sure there are ways to get the access you would need to test under the expensive software.
> I believe you can get access to Linux s390x boxes in the cloud for not very much money.
Could you say where and what "not very much money" is? Like, are we talking $5 DO droplet equivalent or only a few hundred bucks a month? (but to be clear, this is a serious question; I'm a sucker for weird options and would be interested in running a s390x Linux box if it doesn't have too bad price+caveats)
Go to https://cloud.ibm.com/vpc-ext/provision/vs and choose North America > Washington DC > Washington DC 2. Click "Change image" and choose "IBM Z, LinuxONE", then pick Ubuntu. I get $0.09/hour for 1 vCPU/4GB RAM with storage extra.
For fun, then try picking z/OS instead of Linux and see what that software license costs ($/hour). Take a guess first how much you think it'll be and then see if you're right.
> Mainframes are unbelievably powerful, feature-full, and cost-effective.
Having run IBM's own software (WAS and WAS derivatives) on both x86 and IFL, and found the same applications with the same workloads having a ratio of 1.5-2 x86:1 IFL, while the IFL itself is 1-2 orders of magnitude more expensive than an x86 core, that zVM is an order of magnitude more expensive than VMWare's hypervisors, that memory is two orders of magnitude more expensive than x86... well. I think you're long on the evangelism and short on the reality.
Cost effective is a stretch, I'm going to take a dumb example but the reliability of AWS step functions and S3 is good enough for 99.99% of most use cases for a 1/100 of the price.
Mainframes are really powerful for some specific domain which most people on HN don't work in.
Another take is that the most valuable company in the world ( tech one ) don't run their core businesses on mainframes.
> Mainframes are really powerful for some specific domain which most people on HN don't work in.
Yeah, but the cases where mainframes run the show are the ones where stuff really matters, where actual human lives and existences are at stake: banks, insurances, governments, airlines, logistics. If Google has a day long outage, not much of value will be lost... but a large US bank, stock exchange or MC/Visa suddenly failing? That can be enough to trigger an actual bank run with all its consequences.
(Of course, the argument can and should be made that no company should grow large enough to even be able to be such a threat, but that one will have to wait until at least 2028 to get solved)
You are almost certainly better off buying a low-end mainframe than hiring a team of engineers to build yet another not-great data replication/recovery/HA system.
To be clear, this only applies to regular mainframes running z/OS. LinuxONE machines, as the name implies, only run Linux where you'll have all the usual devops/SRE responsibilities.
How so? What problems have IBM solved that dell can't figure out? In my experience sysadmin/SRE work is rarely about the reliability of the hardware and much more about machine management like predicting when you're running out of disk space etc.
A modern mainframe is a system specialized in extremely high transaction throughput at extremely low cost-per-transaction, while guaranteeing data durability and computational correctness.
Sounds like a computer. Why would getting access to one to play around encourage people to buy one? In other words, it sounds like a quantitative difference rather than a qualitative one.
My understanding is that Z mainframes have a number of unique features to support those use cases. Stuff like hot swapping CPUs, and hundreds of IO coprocessors to avoid the main cores from getting blocked. Don't think they're just rebranded x86 machines, but not an expert.
> You can open a terminal and come back in a month and it will still be there. Unlikely kunernetes where containers regularly go down.
You mixing apples and oranges there, by comparing kubernetes workloads to mainframes. Kubernetes isn't really designed to serve long-persistent workloads of that fashion. Although tbf I've had VM's that last for years and real hardware (albeit Sun) that's had over a decade of uptime, so I'm not sure what all the fluff is about.
I've not worked with a mainframe, but I've worked with an IBM storage system that worked on similar principles: We could connect our systems via dual controllers, to separate bays of controllers on the storage array. You could pull whole bays of controller cards and the system would stay up. You could pull whole bays of hard drives, and the system would stay up. You could pull power supplies and it'd remain up. You could swap RAM and CPUs in the servers managing it without shutting them down, but you could also pull one of those servers, and it'd remain up. If stuff started failing, and IBM engineer would show up because the system would call home. This was around 25 years ago.
It wasn't cheap, but it made a typical "modern" high availability setup look like a crude homemade toy.
But as impressive as it was, there are just very few places where that impressiveness provides enough value to justify the cost. And having to deal with IBM.
ECC memory is widely available, you can buy it on amazon, and if you have a contract with a server manufacturer they'll be happy to sell it to you.
It's just not compatible with consumer CPUs (well, ddr5 is, but ddr4 and lower wasn't) because Intel was voluntarily segmenting the market to upcharge for server CPUs.
The IBM mainframe: How it runs and why it survives[0] from last fall.
From way back in 2004[1], Commercial Fault Tolerance:
A Tale of Two Systems compares the reliability / philosophy of IBM mainframes with Tandem Servers.
The other definition you got isn't bad, but I think it misses the point for this discussion: it is a rack or multi rack scale computer with built-in and centrally managed features for redundancy, failover, job allocation, scaling, etc.
As an example, in many main frames, you can configure them with a spare set of CPUs, and if one of your CPUs fails, the replacement is brought online automatically and transparently, the code you write doesn't have to know about anything related to the failure.
One neat thing is that the hot spares can be used during boot to shorten the time to availability. Not sure LinuxONE boxes are bought like that, but for the Z-series you can buy the machine with more capacity than you pay for and pay for it to be enabled at a later point.
> The reason you don’t is because it is basically impossible to get access to a mainframe you can play with and learn on.
Once upon a time, we made a product that was selling to Fortune 500s, and IBM loaned one of the smaller zSeries to us to make sure the product was running well in a Linux VM on it. The thing only fit in the elevator after we took it out of the wood crate...
unbelievable powerful (within certain parameters), and definitely feature-full when compared to virtually any other highly-available platform.
however, cost-effective? only if you're sitting on piles of cash.
IBM mainframes are unique. They have 75 years of incredible research (IBM is often the #1 patent inventor in the world, year after year) into a platform that they completely control. This has produced an absolutely bulletproof product. But you gotta pay for that.
Your other point that it would take a team of engineers to not-even-compete; yes, you're right about that.
I'd love to own one, but I'd rather own my house first.
I did a mainframe apprenticeship for three years at IBM. Trying to learn anything on my own was damn near impossible. And that’s not even getting into the fact that IBM basically has to pay itself for access to some things between divisions. Though that could have been because my division was mostly ignored and eventually spun off.
I've previously worked on mainframes (building business software, and worked quite low level with crypto libraries on them), and now do some of the same but for "cloud" based software instead.
Mainframes are such a weird subject to me, on one hand, the results we got out of the mainframes were pretty amazing, but the experience was painful, absolutely, painful. The tooling is some of the worst you've ever seen, official tools feel like something people dreamed up in winforms. I worked mostly with PL/1 which was a great language, stuck in the 80s but great nonetheless, I actually prefer it to C.
What killed it for me was the restrictions, you had to either dynamically or statically link programs, but do it in the IBM flavor and build system. Which made it extremely cumbersome to do, so files were 20k SoC with a single entry (main) and function calls, because creating files was a pain. Line limits of 72 characters, we even had to send in our programs to get syntax checks because the IDEs weren't capable enough (this was in 2018), now I could whip up something to emulate it in docker and neovim, but the people that taught me had no idea there was something better out there and neither did I. We had to release once a week on saturday mornings because the execution model used had to have downtime during the deployment.
Mainframes are cursed because of the lack of tooling, and the restrictions. I think Mainframes and the execution mode it uses could be useful in a bunch of other places, but IBMs business model just continuously tightness the screws and scared people away. It doesn't have wide spread appeal either, it is "Business machines" after all.
It should be said that I worked in IBMs version of Serverless (not what it was called but it was pretty much what it was), mainframes support Linux, Java, etc, etc. But you give up a lot of benefits and performance if you move off, of the native way of doing things.
I'd also argue that with todays tooling and hardware you can get comparable performance to a mainframe, the only reason that mainframes are as performant, and was so dominant, is because of the restrictions it places on the developer. You have to write low level C, PL/1 or Cobol, so often by proxy your software is just fast. Kind of like Rust or C++ is nearly always quite performant out of the box. Most business software just don't need that level of latency control and performance today.
The fact that it sorta forces you to a lower level of abstraction is actually a very interesting topic and something I think about a lot in the context of how mainframes have remained relevant.
If there were a way to restrict non-mainframe ecosystems in a similar way, I think it could provide a lot of value. Especially for large organizations where standardization and prevention of IT churn is a serious problem.
I just don't see how you do that in an open platform, and so I don't really think it's viable outside of the mainframe space (although it certainly explains part of why a lot of orgs still choose mainframes despite knowing all of inherent difficulties the platform presents). It's a people problem not a technical one at the end of the day.
I'll add that a lot of the tooling deficit has been resolved in the mainframe space, but often in a way I'm not comfortable with. It's normal these days for mainframe developers to not use the old school ISPF development environments, but the thing about the awful old tooling, is that it was brutally efficient. Now you are likely to be giving up a significant amount of that efficiency because you've replaced it with a bunch of JVMs running web services.
There is in some sense an unavoidable tradeoff between modern conveniences and efficiency that I don't think there are any easy ways to get around. We can't have our cake and eat it too, and you cannot have mainframe level performance without it just being a bunch of COBOL and C.
This applies just as much to Linux servers as it does mainframes. I'm not really even commenting about the architecture. There are similar tradeoffs involved in how we choose Linux distributions, although perhaps a little less extreme.
What exactly is considered when putting a dc together that jumps you from knowing that instead of maybe a very large/massive cluster of whatever 1024 core servers your project needs a mainframe?
I've been in cluster infra for like 15 years and couldn't tell you pretty much anything about mainframes other than a few names of them and processors.
Is it some sort of determined raw performance metric, teraflops of some processing work?
The #1 reason by far for buying a mainframe is that you already have mainframe-based applications that you need to keep running.
I’m not sure what kind of orgs (if any) are buying mainframes today as new customers, but I imagine it would have to be a use case something like… a niche scaling challenge, or an outsourcing arrangement where the relationship with IBM is not just vendor lock-in but is some kind of partnership, or you have specialist compliance requirements, or contractual service level obligations, or you need to provide absolute guarantees about the performance/availability/security of the whole stack from hardware up. Some organizations will pay $$$$$$$ to have one ass to kick rather than herd multiple vendors.
Mission criticality, insane parallelism, and a few others.
With modern mainframes, you can configure two processors (or more!) to run in perfect lockstep. If one of them disagrees, the system can immediately see why and how. Run three processors in lockstep and you have quorum: One disagrees? Kill it, clone one of the others, keep going. Or, isolate it, snapshot the disagreement, hold it hostage (but alive!) and bring in a clone of the others.
One of the guarantees of IBM Z/System is "Every read is perfect, every write works." You don't have 2-3 bits of ECC, you have nearly fully redundant RAM. Oh now it has to be encrypted in transit, at rest, and in process? Not a problem, it can do that without changes in code.
IBM's mainframes take SIMD a step further. Let's say you're parsing JSONL. With a little work, you turn a traditional serial process into a parallel one, and what would be a massive map-reduce problem is just a matter of openMP coordination. Or better yet, since it's just lines, you can make the system pretend it's a tape full of records that happens to be interleaved by, magically, a bunch of local cores! Amazing.
Oh, and now the boss says you need to have physical redundancy. Why stop there? Run your application, in lockstep, across multiple systems separated by miles. Don't need it in lockstep? That's fine, your application still thinks it's running inside one head when it's running inside many independent heads. Oh you need to take down us-west-2b? Hold on let me move that entire workload to us-west-1a.
“As businesses move their products and services online quickly, oftentimes, they are left with a hybrid cloud environment created by default, with siloed stacks that are not conducive to alignment across businesses or the introduction of AI.”
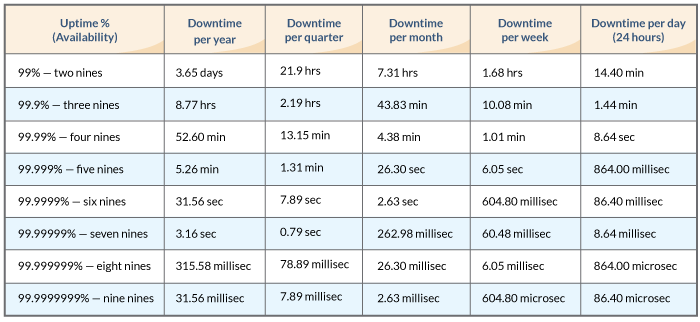
Yours for only $135k (starting)! Supposedly it's designed for eight nines (99.999999%, or ~30 seconds of downtime a year) and a MTBF in the decades. I'm curious if at that point, assuming it lives up to it, if other factors outside of it, like DC power and cooling availability or internet connectivity, won't also be difficult to achieve.
No, eight nines is 316 milliseconds of downtime per year. 30 seconds of downtime a year is six nines. (I spent a long time working on high availability at Sun, so the numbers immediately looked wrong.)
The $135k is just the hardware price for the base configuration. I'm sure you're required to license several software SKUs that are not cheap and that you have to pay annually for maintenance.
"5 This price reflects the base hardware configuration, and does not include additional items, maintenance, the operating system or other software. All prices are in USD. Prices shown do not include tax. Price will vary based on country and currency."
I don't think that's true for LinuxONE. One of the points is that it behaves as a large and fast (with lots of dedicated acceleration hardware) Linux machine.
It's a z-series mainframe and I don't doubt these reliability numbers.
The world's financial system runs on these mainframes. An undetected bit error at the federal reserve might cause IBM to appear in the news, in a bad way, like Boeing..
It will not have the fastest single-threaded performance, but that's not why you buy it.
The mainframe mindset: Of course each core is running at 100% all the time... I paid a lot for it, so I want my money's worth. z/OS is designed to make this feasible. Not sure how well that works in Linux.. but it's where the market is.
The LinuxONE line is, I believe, a series of Linux-only mainframes; z/OS is not an option on them. They're IBM's entry-level option for businesses who salivate at those mainframe reliability numbers but don't have any OS/360|OS/370|z/OS apps and don't want to pay for the support on those systems.
30,000,000 (ish) seconds in a year, 99.999999% of that is .... let me see, 99.999999% of 100,000,000 is 99,999,999 I suppose. So downtime is what's left over, about 1 second every 3 years or 300 milliseconds a year not 30s a year. I think.
I would suspect that it IS multiple boxes and with z/VM using single system image. This is the first time I've ever heard of mainframe "in a rack". In the past they come in their own cabinet, but if you open the cabinet door you won't see one "box".
Note that IFL = cores that only run Linux and cannot run mainframe OSes. The Telum CPU is 5Ghz and has some level of builtin inferencing accordong to their specs.
However the emphasis is going to be on single system image... you won't need to run/manage stuff, you just kick off VMs as if it is a single huge ESXi host, as I read it.
Would be curious to know how it compares in power consumption and heat output; licensing cost of z/VM; is PR/SM (allows you to create and configure LPARs) available? licensing cost?
I worked on multiple LinuxOne systems. You can run z/vm and pr/sm. it will also run kvm if you like.
Power consumption (of our box z13 based)is 3kwh regardless of configuration (give or take) but also consider you need a lot less san switches and networking switches to achieve the same goal as a large rack of individual servers
Hybrid cloud with mainframe in-house colo is actually quite a safe play. You are reducing your reliance on providers like AWS, which may start increasing prices in the near future.
“Compared IBM LinuxONE 4 Express Model consisting of a CPC drawer and an I/O drawer to support network and external storage with 12 IFLs and 736 GB of memory in 1 frame, versus compared 3 x86 servers with two Xeon Sapphire Rapids Platinum 8444 processors with 32 cores each (2ch/32c) with a total of 384 cores”
I’m not a math major, but that’s a bit strange to me.
For the one that wonder who is using mainframes nowadays: most banks, insurances, airlines, grocery stores, public administrations still have something running on a mainframe, maybe in their datacenter or in some outsourcer one's.
From a technical point of view, mainframes are really awesome and many things people speak about today thinking it's something revolutionary were already a thing in the 90s (or even earlier) on the mainframe, for e.g. "serverless".
But basically no one is starting a new business on a mainframe, and all sells IBM is still doing are on existing clients.
Well, I visited page, because IBM mentioned. Nothing new found.
It is known very long time, that IBM hardware is reliable and you must buy it to run their software (to be honest in this case I'm not sure what IBM software I could run on this hardware, but ok). And it is also known, IBM software and services are really good, but expensive, so cost of IBM hardware is not much important if you really need their services.
So what does a mainframe cost to buy though? I can get a 40 core server from Dell for $5000 USD so how many R7515's can I buy for the cost of a mainframe?
Have lots of on-prem hardware. Zero mainframes. Looks like just a computing device that has high uptime? Can see the value in that, but I prefer building reliability on many less-reliable machines. The incremental cost of failure is lower and unused load factor is higher.
Lol @ the marketing gymnastics. "Hybrid cloud" and of course a namedrop of AI.
What this is is a mainframe, a solution with decades of proof behind it in terms of reliability and I/O throughput. In other words, the advantages of cloud without the cruft and BS. Maybe that's what they mean by "hybrid cloud"?
I wish IBM would come out and say what they mean, but maybe they wouldn't be IBM if they did.
The Telum has a lot of its surface dedicated to an inference accelerator. Their aim is to be able to very quickly run fraud detection while processing payment operations.
"Hybrid cloud" is being able to move applications back and forth between on-prem and cloud, and scaling from on-prem into the cloud if need be, typically enabled by the proliferation of k8s on both sides of the equation.
The difference between that and your description is that it's not merely "mixing different types of servers" where each type is managed in a completely different way and running completely different applications. You're obviously correct that there would be nothing particularly special about that.
Usually, but a mainframe is an on-prem solution and can only fill that part of a hybrid cloud strategy. I get the feeling IBM thought they'd lose the CTO crowd if they didn't say "cloud" every now and then.
And good that they do, otherwise I would not get so much evergreen enjoyment from the cloud-to-butt browser extension I've had installed since forever.
I agree with the parent post in that it's mostly marketing. There was nothing preventing you from calling back and forth from cloud services on your mainframe before the recent marketing shift to "hybrid cloud". Hybrid cloud is a meaningless term on a technical level, but I guess for buisness people it means you can buy a new mainframe and that won't stop you from delivering "cloud" or whatever other initiative the suits have budgeted for.
So yes, its laughable to hear that kind of marketing if you are technical. But for the kinds of large organizations that would potentially be buying a new mainframe, its what you need to get this sort of thing budgeted.
Certainly the IBM systems group didn't come up it. They know just as well as the people trying to upgrade their mainframes that it's an on-premises strategy primarily intended for line of business applications with reasonably well understood resource utilization.
{kind=link}
The reason you don’t is because it is basically impossible to get access to a mainframe you can play with and learn on. And IBM’s internal incentives and financial metrics ensure that can never happen.
* My views are my own and not those of my former employer.