IPv6 has been one of the biggest failures in the last couple of decades.
And I don't mean adoption, I mean the standard itself.
If IPv6 were IPv4 with more octets, then we would all have been using it for like a decade.
Yes, I understand it would still require some breaking changes, but it would have been a million times easier to upgrade, as it would be a kind of superset of IPv4 (1.2.3.4 can be referred as 0.0.0.0.1.2.3.4).
Not having two sets of firewall rules and two sets of everything. I always disable IPv6 because it can bite you so hard when you don't realize that you are wide open to IPv6 connections because of different firewalls.
Edit: To make everything a bit clearer, the idea with this "ipv4+" is that you don't need the complexity of running both ipv4 and ipv6 as you do now.
And regarding compatibility, with ipv4+ if you have a 0.0.0.0.x.x.x.x ip address you would be able to talk to both ipv4+ aware and legacy ipv4 devices natively without any tunneling (because you also own the legacy, non quad 0 ip address). If you don't have such "quad 0 ip" (you are 1.1.1.1.x.x.x.x), only ipv4+ aware devices would be able to to connect to you, and for you to connect to non ipv4+ aware devices you would need either tunneling, or having a secondary, cgnat, "quad 0 ip".
> And regarding compatibility, with ipv4+ if you have a 0.0.0.0.x.x.x.x ip address you would be able to talk to both ipv4+ aware and legacy ipv4 devices natively without any tunneling (because you also own the legacy, non quad 0 ip address).
This exists:
> Addresses in this group consist of an 80-bit prefix of zeros, the next 16 bits are ones, and the remaining, least-significant 32 bits contain the IPv4 address. For example, ::ffff:192.0.2.128 represents the IPv4 address 192.0.2.128. A previous format, called "IPv4-compatible IPv6 address", was ::192.0.2.128; however, this method is deprecated.[61]
You still need to upgrade bit of networking kit between the source and destination to understand "IPv4+", and this (lack of) upgrading and enabling is what is hampering deployment.
What makes you think that companies would have been willing to make the effort to deploy "IPv4+" any more than IPv6?
> What makes you think that companies would have been willing to make the effort to deploy "IPv4+" any more than IPv6?
I'm pretty sure that those who built new protocol were aware of this and were like "anyway we are gonna have to upgrade network devices. Why don't we build a new protocol while avoiding pitfalls of older one"
Any comittee that sat down to solve IPv4 issue would have thought of compatibility first.
I am shocked that so many people agree with OP's armchair solution here.
They took much more on with IPv6 than IPv4 replacement. The spec goes much deeper than IPv4 did, replacing ARP, DHCP, etc. It's a product of its time, including a lot of over-engineering by committee. Many of the problems they tried to address didn't pan out to be real issues. You can read the RFCs and compare.
IPv4 w/ more bits is a lot more simple. Yes, older network gear wouldn't deal with it well, but that's not a real issue today because that same network gear supports IPv6.
Buuut, one of the biggest problems with app-level issues is just that the app doesn't bother dealing with IPv6 addresses and AAAA records. It would be the same issue with an imaginary IPv4*2.
No kidding - they got rid of dhcp and more but it’s a nightmare getting networks to work with just ipv6 concepts- everything from provisioning phones (dhcp options to push config / NetBoot stuff) and more. Layer in privacy extensions, renumbering on uplink wan flapping (slow too - the failover is pathetic compared to NAT wan failover) - icmp traffic differences - firewalls need to be much more careful with ipv6 and related protocols because things can easy break (it’s fragile) or you create risks. Even min subnet sizes mean crazy 2 node subnet sizes (think isp and cpe management subnet for a customer). Also curious why not 48 or 64 bits or 96 bits? 128 bits is ludicrous
128 bits was probably picked to give 64 for "MAC address-based locals" and then the reasonable thing is to have 64 more bits on the other side, if you only had 32 you're just IPv4 with more steps.
Layer 3 exists as a layer of routing and aggregation on top of layer 2. Aggregation necessarily consumes address space, so L3 needs to be bigger than L2 to accommodate the full L2 address space. The L2 address space is 64 bits and the next power of 2 up from 64 is 128, so here we are.
96 bits would probably be enough too, but having large subnets has a few benefits -- it allows for securing NDP by using the extra space for a cryptographic key, and also it makes it much, much harder to scan for active hosts from outside the network.
Plus, can you imaging the wailing and teeth gnashing we'd be getting if v6 wasn't a power of 2 bits long?
Mayne RFC exists, but it os not used in teal world anywhere. In all servers, I configure IPv4 and IPv6 separately. Network setup is separate. DHCP daemons are separate. Firewall rules are separate. Network monitoring is separate.
I would switch to that "IPv4+" system if it existed.. I am willing to use latest software/standards to future-proof my setup, but duplicating all the work is too much for me.
> I would switch to that "IPv4+" system if it existed.. I am willing to use latest software/standards to future-proof my setup, but duplicating all the work is too much for me.
And exactly how would you accomplish this switch to a larger address space? Please explain the steps exactly how they would be done.
Because IPv4 has 32 bits of address. Anything after IPv4 needed >32 bits of address. How exactly do you fit in >32b in a data structure that is only 32b? You cannot.
So you have to go and replace every bit of networking code out there to change the data structures. You know, like was done to deploy IPv6.
In theory this could be handled by stuffing the extra 96 bits in an IP extension header. But this solves nothing because then any switch that isn’t IPv4+ aware will route packets incorrectly. Literally every single switch on the internet needs to be updated/replaced before you could start generating IPv4+ traffic otherwise the one outlier will send your IPv4+ packets off to Uzbekistan.
OR
Maybe you don’t use those 96 bits for routing. But then it becomes nothing but a sort of subnet address and you haven’t fixed the routing table size problem. And actually every endpoint needs to upgrade too because endpoints that don’t recognize the header extension will generate crazy responses and confuse TCP packets from different computers as coming from the same machine.
There’s no useful and backward compatible way of extending IPv4.
1) Instead of stuffing the extra 96 bits in an extension, you stuff all 128 in the extension and use a reserved unrouted address in the v4 header field. Devices with no clue will just drop those packets.
2) Pedantically, switches are layer 2 devices. Some some of them act as routers also, but only routing is relevant.
Devices with no clue of IPv6 also just drop those packets. What have we gained?
The only thing I can imagine is that while you still need to alter or replace every piece of equipment on the net, software adoption would likely have been much easier and thus immediately higher if 128 bit addresses were the only change (I still don't see the benefit of tucking it in as a field into IPv4, but if IPv6 was just IPv4 with wider addresses), and all the other protocols and semantics that were changed with IPv6 stayed the same. But arguably, since you do need to change every piece of equipment, this was the time to make desirable, fundamental, not-backward compatible changes, and possibly the only opportunity at that.
Or you extend on network level, and even kernel level, but keep programming API compatible. I don't think people like IPv4 packets that much, it is all the APIs which are giving problem.
I bet if we kept everything about IPv6 the same, but (1) made IPV6_V6ONLY mandatory and default to zero (2) did not use colon in IP address representation (3) recommended firewalls use same config rules for IPv4/IPv6 address.. then IPv6 would have significantly higher adoption right now.
On Windows firewall matches ip4 and ip6 with the same rule. The address field there isn't numeric, but text, and can be ip4 address, ip4 network, ip6 address, ip6 network, address range, gateway or "any". Most rules specify "any" for addresses and focus more on ports, application paths and subprotocols like TCP/UDP.
Let's use "IPv4+" scheme as described by redox99: we still have dotted-decimal, and IPv4 addresses are guaranteed to be accessible via IPv4+ interface.
Right now, most application software need non-trivial rewrite to add ipv6 support: it has to support 2 sockets instead of 1, and ":" in address breaks basically every address parsing function out there. With IPv4+, you do search/replace "sockaddr_in"->"sockaddr_in4plus" and AF_INET->AF_INET4PLUS. That's it -- since backward compatibility guaranteed, my software still works on IPv4 system, and hostname parsing is not broken. There might be some minor breakage (unexpected dependencies on struct size or ipv4+ address string length), but it would be way, way smaller than the mess IPv6 is in too.
Right now, I have to set up my firewall twice for ipv4 and ipv6. But with ipv4+? I should be able to write "-m tcp --dport 80 -j ACCEPT" once and have it work with both.
Right now, all the network monitoring tools have to have separate "ipv4" and "ipv6" codepaths. But with ipv4+, there could be only one codepath. Yes, packet parsing will have to handle two different IP header format, but once it's parsed, old and new are treated identically.
Sure, the network layer will be more complex. The IP stack in kernel would need to determine if the address is "short" or "long", and format packets differently (either old or new format). The high-performance routers would need to be rewritten. The TCP/IP network card offload will need to accommodate new format.
But this would be way, way less intrusive than current IPv4->IPv6 transitions, because for each line of low-level network code there are millions of lines of application-level code, and for some totally stupid reason the app code transition was made way harder than needed.
> I should be able to write "-m tcp --dport 80 -j ACCEPT" once and have it work with both.
Kind of like how PF does it?
tcp_services = "{ ssh, smtp, domain, www, pop3, auth, pop3s }"
udp_services = "{ domain }"
block all
pass out proto tcp to any port $tcp_services keep state
pass proto udp to any port $udp_services keep state
Similar functionality is provided in nftables for linux ('inet' filter applies to both ipv4 and ipv6). But, outside of the most trivial use cases of just block/allow a port, it doesn't really work out to be that useful because of other restrictions. E.g., if you are collecting IPs that have e.g., created new connections to some set of ports greater than n times within a time period to rate limit them, you are out of luck and will need separate rules for ipv4 and ipv6 since you cannot save a mix of ipv4 and ipv6 addresses to the same list.
How you represent the address is arbitrary, using a colon instead of a dot matters little as underneath it's just an integer with the only difference being 32 or 128bit.
Using a dot causes its own problems, because it conflicts with DNS. DNS allows fully numeric domain names, but they conflict with legacy ip so are not used on a the public DNS. Using hex would make the problem worse as it's perfectly valid to have an ipv6 address ending "de" for example, which is the TLD for germany.
Legacy addresses can be represented via hex too - try ping 0xdeadbeef.
The socket apis between v6 and legacy ip are largely as compatible as they can be, you need to use sockaddr_in6 and AF_INET6 which is the same as you propose. You can open an AF_INET6 socket and still connect to legacy addresses with it.
For higher level languages that don't deal with fixed size memory structures directly it's pretty much fully compatible, you can just say "connect www.google.com tcp/443" or equivalent, and the system takes care of resolving what protocol and address to connect to.
> Right now, most application software need non-trivial rewrite to add ipv6 support:
That's not right.
If you've been using the platform network libraries for things then IPv6 will just work with anything more recent than Windows XP. Unless you've been hardcoding IP length expectations then there is basically nothing to do.
Seriously, use the platform libraries. They handle all the edge cases and stop storing IP address in a uint32.
Unless you are doing something super trivial, like making http/https requests to pre-defined URLs, your platform libraries will not help you.
Your network servers need two explicit bind() calls for two different protocols, and some logic to select which ones to call, and your main accept() code needs to be able to handle two listening sockets... Theoretically you could create IPv6 socket only and accept both addresses but.. (1) apparently it is disabled on many BSD's by default and (2) even on Linux bind() will fail if you have no IPv6 addresses assigned at all.
Your network client would be better, as there are some libraries which let you connect to ipv4 or ipv6 address, but then IPv6 colon-separated format will trip you. How many clients split on ":" to get port number? Or concatenate (IP, ":", PORT) in the logs / settings? All of those would break.
The really annoying part is that all of these problems were 100% predictable from day 1, and yet someone decided to go ahead with this implementation.
Sorry. What? You’re claiming that the hard part is the parsing of textual ipv6 addresses to binary representation but these same algorithms would work on a hypothetical hand-wavy ipv4+ how? It’s extended so you’ve either got numbers > 255 (breaks parsing routines) or more dots (again breaks parsing routines). Either way you slice it you have to upgrade the parsing routines. And the hard part has not been the parsing routines. And you’d need to justify that what you describe about bound addresses doesn’t apply to a non-existent ipv4+.
It’s getting all the middleware routers, services, and websites to support both that’s been the challenge because it was a chicken and egg. ISPs didn’t want to do it. Websites wouldn’t do it because there were no customers. Carrier grade NATs bought another decade or two. Manufacturers didn’t bother prioritizing the ipv6 stack because carriers weren’t demanding it so HW had very immature and buggy ipv6 stacks which further prohibited ISPs from turning it on because it was another 1-3 purchase cycles before the stack actually worked correctly. And none of that solves the chicken/egg problem of the lack of eyeball supply / customer demand.
The complexity of IPv6 contributed to some of it. Carrier grade NAT did most of the harm though and that would have been a thing regardless.
I am not sure why you are downvoted, since you do make some valid points. I myself am not sure whether the very fundamental changes that IPv6 brings did not hamper its adoption than if it was just extended IPv4.
From a network administration perspective, sure, "you need to replace every piece of equipment". But from a software modification perspective (thinking more about the software on network infrastructure equipment than endpoints like applications), you have two very different stacks.
On the other hand, if there was ever a time to make (assumedly so) highly desirable compatibility-breaking changes, that was it.
It's like no protocol has ever been extended or revised. Ever.
Let's pretend there isn't an Options and Padding section in the IP header:
"Options and Padding - A field that varies in length from 0 to a multiple of 32-bits. If the option values are not a multiple of 32-bits, 0s are added or padded to ensure this field contains a multiple of 32 bits."
Wow, like I CANNOT think of how that would be used to add more bits. More 32 bit sections? No use for that for ipv4+ or ++ or +++.
There is in fact an options section in v4, and I think it's pretty obvious how it could be used: you could put extra address bits there.
The problem is... how do you get those extra address bits to work?
If you think through that question and produce a working answer, your working answer is going to be roughly the same as v6 -- and have the same issues v6 does. Almost as if the people that designed v6 weren't completely clueless.
A lot of mobile telcos use IPv6, but there are virtually no telcos around the world that don't force the use of some form of NAT (CGNAT, NAT64) for connecting to legacy sites. NAT64 is effectively another form of CGNAT, you only have a proper end to end connection if you're using IPv6 directly.
TMO US has 110 million customers, but they don't have 110 million legacy IP addresses, and most other telcos are in the same boat.
Mea culpa. I'm away right now, but I'm like 95% sure that T-Mobile Home Internet is NATing, or at least was awhile back when I had trouble. Googling around it sounds like it may operate differently than the mobile phones do.
Ok. How do you increase address space without breaking the protocol? IPv4 just doesn't have the space in the header. Something like "v4+" can't happen for this reason.
You could argue that pervasive use of NAT beginning in the late 90's was "v4+". It bought us decades of Internet growth, at the expense of true end-to-end connectivity.
There are viable transition mechanisms other than dual stack, that put some kind of translation layer between protocols, rather than expect native IPv4 connectivity on all hosts.
This is perfectly viable, and is how many mobile networks handle IPv4 (ie. there is no native IPv4 on the handset at all), and how many cloud providers are handling it these days too. You have to do NAT at the border anyway, why not NAT to/from an IPv6 address?
The adoption problem doesn't have that much to do with the technology, it's simply that it provides little value to most individual entities participating in the network, even if the benefit in aggregate is clear, so it's difficult to achieve the critical mass to make it valuable. It's the same thing behind climate change and so many other societal issues.
> What makes you think that companies would have been willing to make the effort to deploy "IPv4+" any more than IPv6?
Way less resistance from tech teams. Ultimately companies are made of people, and ipv6 is partly a failure because working with it requires a wholly new skillset
Maybe it’s different on the software side but coming from a network VAR it’s the same skill set. You still have subnets and routes and netmasks and DHCP or automatic assignments the difference is the size. If you know IPv4 all you need to learn is “the subnets are all /64 in size, addresses are 128 bits, and you don’t need DHCP if you don’t want”.
Yeah, but I have to say, even as someone who wants IPv6 to succeed and supersede IPv4, from the perspective of building that network infrastructure software, I think this "IPv4+" would have been massively simpler to add, extremely so, and that may have aided adoption a lot.
It's really hard to overstate how much simpler tacking on 128bit IP addresses to an otherwise unmodified protocol would have been in the software stack of network infrastructure.
But, as I also said a few times here, the time to make desirable compatibility-breaking changes was exactly then, when every piece of network equipment needed massive alteration or replacement anyway. And I look forward to the day IPv6 hopefully becomes predominant, and the advantages it brings.
The majority of the problems seem to come from the fact that v6 addresses are longer than v4 ones. That's why we need socket(AF_INET6)s and AAAA records and a DNS API that supports multiple address families and dual stack and new firewalling and updates to all protocols that embed v4 addresses.
You're going to have the exact same problems with any protocol that has addresses longer than v4's.
BSD Sockets ensured that we have problems using anything other than what the software was originally written for, unless it's a program recent enough to use the one bit of API that got back ported from OSI-oriented Ed networks, the getaddressinfo() call.
Otherwise there's a ton of low level IPv4 details leaking all around the basic idea of connecting from one service to another.
I find that hard to believe. That may be true for endpoints, but I'm talking about the network infrastructure in between. There, I believe that the vast differences in the protocols on higher level (autoconfiguration, link-local addresses, temporary addresses, Neighbor Discovery as part of ICMP6 instead of ARP, ICMP6 itself, and so on and so forth) are much, much more work to implement than dealing with new DNS records and APIs, and the new struct sockaddr variants.
My point is exactly that I have a strong suspicion that the longer addresses are not the problem for slow adoption, the different network protocols and semantics are.
We've tried to roll out IPv6 at my work, and after several years of it causing more issues than it help we turned it all off again... We're gonna get back to it again this year, but I can see many organizations just not doing that until absolutely forced.
Thank you to share a real world story. Failure is usually more interesting to study than success. Real question (no trolling): Is there any business value upgrading to IPv6 or is this a forced upgrade? I think that is number one reason that delays IPv6 upgrades: no business value (or so limited compared to cost of IPv6 impl).
If you're running something that isn't absolute shit it's not this much of an issue to upgrade to ipv6. There's business value in that simply because ipv4 addresses are expensive.
> What makes you think that companies would have been willing to make the effort to deploy "IPv4+" any more than IPv6?
The hallmark of a good IPv4+ solution is that it autodeploys without anyone at the network configuration and administration level having to think too much about it. IPv6+IPv4 by contrast generally doubles the configuration complexity of more things than you can count.
It is true that for IPv4+ to be successful nearly everyone currently using IPv4 would need some sort of behind the scenes upgrade to be IPv4+ compatible first before the extended address space would be portable. And that includes incremental upgrades of just about everything that touches IPv4 or IPv4 compatible addresses.
One of the ideas of ipv6 was to reduce routing tables, those tables that backbone providers have to keep in memory and look up for incoming traffic. With ipv4's fragmented allocation scheme, these routing tables are huge. With ipv6, even huge companies like amazon only have a couple of global allocations. A "ipv4 with more octets" scheme would have kept that fragmentation around.
That being said, Amazon currently has 2880 ipv4 allocations and 946 ipv6 allocations... not much gained I guess? :p https://asnlookup.com/asn/AS16509/
Also, there are definitely some horrible ipv6 warts, like that the only standard for local ipv6 addresses forces you to adopt a scheme where your local address is horribly long, for the sake of global uniqueness, which is something that most people don't really need.
Amazon is really not a great example, I don't think. The giant cloud providers are outliers with respect to DFZ announcements, as they have many, many POPs and also allow their customers to announce address space. They're more like transit networks at this point than what could be reasonably considered a representative end user.
More reasonable to look at announcements per AS, where it's currently about half of IPv4, but trending upwards at a faster pace.
So Amazon with its 3-fold ratio is in fact giving a better argument for ipv6 than the average, nice. Generally a factor of two doesn't say much about ipv6 creating less allocations at all, given how ipv6 is roughly within a factor of two in terms of adoption in general.
> One of the ideas of ipv6 was to reduce routing tables
That idea was abandoned about 20 years ago. One fairly quickly discovered that hierarchical routing does not work well in the real Internet, where redundancy is done on the IP level with everybody and their dog having provider-indepent IP space.
> like that the only standard for local ipv6 addresses
Which one is the only standard? Link-local, site-local, ULA, or using a non-routed netblock with or without DHCPv6 (or RA)?
site-local addresses are deprecated since RFC 3879. Link-local addresses are indeed another standard, but have the very same length problem. You have these horribly long ipv6 addresses... those can't reasonably be parsed by humans...
There is no 192.168.* equivalent in ipv6. Why don't we have something like fd00::1 being the router and fd00::2, fd00::3, etc being the devices in the local network, assigned by DHCP. You can absolutely configure your router that way but it is violating a MUST requirement of RFC 4193. That's my point. There is no non-routed netblock where you can just use it for local purposes, outside of the one for SLAAC and the one for ULA, both creating these horribly long monsters of addresses. All the others have purposes attached that are not meant to be used for local networks.
Why do you care how long the addresses are? That's what DNS is for. Within a link - most home networks are only one, and those are the ones that need to be simplest - there's even mDNS.
DNS is great but it is not available in all settings. Eventually you need to type in ip addresses, there are gazillions of workflows where you have to do that.
There's only a very few places where typing IP addresses actually makes sense. Configuring DNS is the main one. Trying to isolate problems is another - if you can ping 8.8.8.8 but not google.com you can reasonably infer that the problem is DNS. I really can't think of any others.
That latter one is admittedly kind of a pain, but a wallet-sized cheat sheet can solve it for you. Might be a good idea to try to convince vendors to include a reliable entry or two in the hosts file for that purpose? You can always add it yourself for now, when you're on your own workstation.
> where your local address is horribly long, for the sake of global uniqueness, which is something that most people don't really need
Apart from debugging where you can copy-paste anyway, does it matter? I've got a few services on the local network and over zerotier that all talk IPv6. In the last 3 years or so I've never used an ipv6 address directly. There's enough DNS and discovery protocols that I never needed to.
Plus if you're using enough IPv4 addresses it is going to be the same problem anyway. I can barely keep track of what I've assigned everything to in just a /24 so I have local DNS and I don't need to.
Any sysadmin for a medium sized company with their own servers are likely to end up having to type in IP address or get them off shitty management consoles that don't support copy paste in any way.
Using IP addresses directly is a bad practice in general, it introduced security risks in many scenarios.
SSL - usually cannot verify the cert, defeating the point of SSL
SMB - windows will fail over to less secure ntlm auth instead of kerberos
If your using IP addresses instead of hostnames to reference machines, you're doing it wrong.
Also IPv6 is easier to remember in general... We have a single large IPv6 allocation (eg 2001:db8::/32), and everything sits under that in a logical layout. For legacy IP, we have several different allocations in different class A blocks (104.x, 66.x, 62.x etc) plus all the RFC1918 space used internally
Sure, but most places are not setup to using DHCP on servers or automated installs. So you will be typing in IP addresses through some kind of console to configure the machine in the first place and you will be typing in that IP address in the DNS system and when someone remotely fucks up the routing or IP config then you will be manually typing in lots of IP addresses to fix it.
If you have enough nodes to care and manually assign and at the same time don't automate deployment that sounds like an issue in general... and not with IPv6. You're likely to typo IPv4 just as well with enough entries.
Yep, but in my experience you have to manage about 2000+ machines before management will allow you to spend time on setting up deployment automation. So around the time you are setting multiple new machines a week.
Of course it is, automation is very nice, I use it for the handful of machines I have my personal stuff on. I am just saying that from my days as a sysadmin it was usually a years long uphill battle to get approval for automating even minor things.
> That being said, Amazon currently has 2880 ipv4 allocations and 946 ipv6 allocations... not much gained I guess? :p https://asnlookup.com/asn/AS16509/
I remember the line being "the IPv4 routing table is 3x as big as it needs to be due to fragmentation", so that seems pretty in line with that.
I'm not up to date, but when I knew about this stuff the cost of memory for routing tables was only a tiny, tiny fraction of the cost of a network. Most of the cost is burying and maintaining fiber.
So unless something big has changed, it seems like a terrible choice to twist the whole system into uselessness to try to save a small amount of RAM cost.
According to this Stack Exchange post from last year a full IPv4 routing table requires on the order of a few hundred MBs of RAM. This is indeed a tiny fraction of the cost of maintaining the global internet infrastructure.
The problem is that the routers that have to hold the routing table can only handle a limited number of routes. There is a good article from APNIC about the topic.
And besides, there is no need to keep the whole routing table in RAM. Instead all that's necessary is a single integer per route representing which port packets to each route needs to be sent down. So even for a large router with 64 ports, the whole routing table fits inside 1 megabyte.
Sure they can create routers with more space for the routing table but you still have to replace all the old ones which isn't cheap.
A single port of a router at an internet exchange can reach more than 1000 different routers. A router has to decide to which IP it should forward a packet not just the port.
> That being said, Amazon currently has 2880 ipv4 allocations and 946 ipv6 allocations... not much gained I guess? :p https://asnlookup.com/asn/AS16509/
How many clients can those IPv4 allocations serve? How many clients can those 946 serve?
If Amazon had 2880 IPv6 allocations, how many clients could they serve?
I'd say a lot was gained. Someone asking for a random PI IPv6 allocation gets, at minimum, a /48 for a "site". That's the equivalent of a Class A (16 bits for subnets).
Are you saying everyone being able to get their own Class A equivalent is 'nothing gained'?
Let's not forget about the idea that ISPs would distribute a /56 range to residential users. You could split it in /64 ranges according to your requirements and everything would work fine.
There is only one "minor" issue: all major ISPs in my country ( Brazil ) only provide a single /64. You can't get another /64 unless you upgrade to a very expensive business plan.
That makes IPv6 not only useless but also a huge security issue.
1) I can't use my Mikrotik as a firewall. Trying to split a /64 range breaks things and some devices ( specially IOT ones ) will simply not work.
2) Routers provided by the ISPs here are very limited, specially for things like firewall rules. Some of them will only provide a On/Off switch, with Off option between the default one.
Although IPV4 + NAT had some issues, it ( accidentally? ) created a safe/sane default config for non-technical users. In order to open a port and expose a device, you have to explicitly add a rule on the firewall.
IPv6 is the other way around. In practice, all devices and ports are exposed unless you explicitly block it.
In the last 3 years I've noticed criminals focusing more and more on IPv6 scans to compromise devices and create botnets since it's much easier to find exposed/unpatched devices as most users don't understand how to correctly configure a firewall.
Most of the time, the only viable solution is to disable IPv6.
Those ISPs are broken and not following the RFCs or RIR guidelines.
There's nothing stopping you from using NAT with IPv6, people just don't do it because the only benefit of NAT is conserving limited address space. NAT on IPv6 just brings all downsides and no benefit because you (should) have no shortage of address space. In any case v6 with nat is no worse than legacy ip with nat, its just stupid because they're forcing a newer and better protocol to run in a degraded mode.
Consumer oriented routers and firewalls do not allow arbitrary inbound IPv6 connections by default, you have to explicitly enable them.
I still don't get scanned over IPv6, despite having a static /56 range for more than 10 years. Everything that's reachable over legacy IP is also reachable over v6, and i have several v6-only devices because i simply don't have enough legacy addresses for everything. Scanning v6 is extremely difficult, while the legacy blocks get scanned continuously.
Modern operating systems are not sitting there with exposed services by default, you have to manually open them up if you want. Simply connecting a win11 box to an open IPv6 connection is not going to get you joined to a botnet like connecting a winxp machine directly to a legacy connection did.
Modern devices are often exposed to hostile networks/users - every time you connect a portable device to a public wifi network you are exposing your device to the operators and other users of the network. Depending how that network is configured, you might be exposed to the internet too. You don't have any separate device between you and the hostile network, you are relying on the configuration of your machine itself.
ISP supplied routers are limited and generally garbage, this is a problem for legacy ip just as much as v6.
> It's also a privacy feature which ensures I am able to hide the number of unique devices in my network.
A combination of: (a) my Asus AC-68U not allowing non-reply, inbound connections for IPv6, and (b) my clients using rotating, randomly generated addresses, accomplishes the exact same thing.
NAT doesn't add much over a decent stateful firewall with a default-deny rule on incoming connections.
Why can't you use it as a firewall? It's weird, and against RFCs for your ISP to only give you a /64, but that should still be routed address space is routed through your router/firewall box, and therefore trivial to firewall with the normal tools. This is also pretty much the necessary topology, because if the box needs to do NAT for IPv4, it needs to terminate the address on the firewall too. You'd need separate interfaces to do some scheme where IPv6 was layer-2 to the ISP, and IPv4 terminated at the firewall.
Most/all such boxes, especially those deployed by ISPs, have a stateful firewall with an allow-out deny-in policy in place by default. I've never seen otherwise, but I guess it's possible?
Back in the day, cable modems didn't include a 'router' and lots of users plugged their Windows XP PCs into them and got compromised. Most weren't really blaming the ISP for this; go buy a router they said. And some providers will still just give you a public IP with full access by default when you plug into their demarc equipment; indeed many users want this because that's what Internet access should be. Security is on the end user. I don't see this situation as any different, though your ISP should know better than shipping insecure-by-default, this isn't really a problem with the protocol.
Originally (2002) a /48 per site was recommended in RFC3177.
More recently (2011) RFC6177 took a more pragmatic / softened approach, but it does say:
- it should be easy for an end site to obtain address space to
number multiple subnets (i.e., a block larger than a single /64)
and to support reasonable growth projections over long time
periods (e.g., a decade or more).
I don't really understand why ISPs choose to be so stingy with allocations. An extra 8 bits of address space to allocate /56 instead of /64 costs them effectively nothing and has considerable operational benefits, simplifies CPE configuration etc. Just minds still living in IPv4 land I guess.
I suspect it's to make business plans artificially more appealing. After all, why offer a better service when instead you can just make your cheaper one worse?
RouterOS v7 supports DHCPv6 prefix delegation. You can request a delegated /64 per downstream interface and announce itself as router using these prefixes. You can still use your MikroTik device as router, stateful firewall, proxy. You don't have to mess with smaller than /64 allocations on links unless your provider forces a broken CPE on you that doesn't support DHCPv6 prefix delegation.
Have you actually seen any large scale deployments of CPEs without an active IPv6 firewall blocking incoming connections by default?
> There is only one "minor" issue: all major ISPs in my country ( Brazil ) only provide a single /64. You can't get another /64 unless you upgrade to a very expensive business plan.
And my ISP gives me a /56. What's your point? What you say is not a knock against the protocol, but stupid ISPs.
In fact, you're actually better off compared to IPv4. At least you now have publicly available IPs with can easily be connected to if you wish, rather than having to go through the silliness of port forwarding with NAT.
> IPv6 is the other way around. In practice, all devices and ports are exposed unless you explicitly block it.
Not on my Asus AC-68U: it has a default-deny rule on incoming connections. Only replies to existing connections are allowed.
Again: your critique is not against the protocol itself, but stupidity.
> There is only one "minor" issue: all major ISPs in my country ( Brazil ) only provide a single /64. You can't get another /64 unless you upgrade to a very expensive business plan.
I'm curious why you need multiple subnets at home; I at one point had separate subnets because I was using a wifi client as a ip level router, but was wondering what your use-case is.
> Although IPV4 + NAT had some issues, it ( accidentally? ) created a safe/sane default config for non-technical users. In order to open a port and expose a device, you have to explicitly add a rule on the firewall.
> IPv6 is the other way around. In practice, all devices and ports are exposed unless you explicitly block it.
I would like to humbly suggest that you don't remember what the internet was around the turn of the century with devices configuring IGD via UPnP so every device you hooked up to your home router automatically setup a port-mapping to put itself on the open internet.
Eventually everyone realized this sucked and UPnP NAT traversal was disabled everywhere. The same will happen (and actually more-or-less has already happened) with default-allow home routers switching to default-block.
>I'm curious why you need multiple subnets at home; I at one point had separate subnets because I was using a wifi client as a ip level router, but was wondering what your use-case is.
Not OP, but there are many use cases. First is device isolation so untrusted devices can be put in their own network while you can selectively add ressources from your main network via VLANs and add simple firewall rules because the untrusted network is a different interface on your VM than the others.
Second, you might want to put any managment interfaces (and ssh-enabled IPs) on a seperate network both for ease of organization and security.
Third, if you want to have your network services configured differently for different clients (think VPN vs local clients, adblocking DNS for mobile only) it's a lot easier to do that for whole subnets.
> If IPv6 were IPv4 with more octets, then we would all have been using it for like a decade.
I don't really think so: it woulds still be completely backward incompatible and still require replacing a lot of costly network equipment. I think that's the main reason why large ISPs and enterprises have been postponing the upgrade since forever but operating systems, smartphones and other new devices didn't really have a problem with it.
It's been decades. The vast majority of network equipment already has been replaced multiple times since IPv6 became a thing that people "understood" we would switch in the future.
The difference is that instead of their ipv6 being broken, partial, or correct but non functioning because it needs additional configuration, it would properly work and support with the much simpler "ipv4+"
But IPv4+ is incompatible, so it requires to maintain two network stacks until reasonably everything has moved over to it. You need to duplicate the configuration for DNS, routing, firewalls etc., exactly as for dual stack IPv6. I don't really see a difference.
Imagine I own a company and I already have a bunch of IP4. I upgrade my network equipment to IP4+, and then keep all my routing and firewall configs. Everything just works the same as before. Now I want to access IP4+, so I add a route entry for all the IPs above 255.255.255.255. In fact, if that entry is just "send everything to my upstream" it might already work!
Now I want to add some new resources but I'm out of IPv4 space. So I get some IP4+ space and a new host with a new firewall rule for the new octet and a DNS entry. Of course only other people on IP4+ can reach it, so I use it for my internal tools since I know all of my clients support IP4+.
Then I want to use it for a public service, so I add a dual DNS entry of 0.0.0.0.1.2.3.4 and 1.2.3.4. IPv4 clients get 1.2.3.4 and IP4+ clients get 0.0.0.0.1.2.3.4. Now I can start collecting data on how many people support IP4+. When it gets high enough, I can shut off the v4 address and move it to IP4+ only.
It would make the transition just soooo much easier, because the changes are much more incremental. I don't have to set up a whole new dual stack. I can just make a few dual entries.
The evidence at this point I think refutes your argument. It's been the case for a while now that basically all the hardware, all the networking stacks, all the major libraries and software supports IPv6. So the reason people haven't switched to IPv6 as quickly is because there's all sorts of hidden IPv4 assumptions that take significant effort and energy to get rid of--and there's relatively little resources being devoted to rooting those out.
The kinds of things I'm talking about are places where an IP address is stored in a uint32_t in the middle of your core business app somewhere. Or maybe you've got some log sniffing that only looks for four dotted octets and can't pick an IPv6 address. Those are the sorts of things that if you move to any system that's not IPv4, it's just not going to work period. And you're often not going to discover that you have these issues until you try forcing things to use not-IPv4.
A migration I've been working on--admittedly not in networking--has been LLVM's opaque pointer migration, and the vast majority of the time has been spent not figuring out how to get rid of every "pointer_type->getPointerElementType()" call, but in quashing all of the assumptions like "this input operand has to be a bitcast of a global variable" that is violated by the pointer migration. I have no reason to expect that the IPv4-to-IPv6 migration is not similar, in that most of the effort is going to be spent on code that you didn't think would assume it is using IPv4.
> Imagine I own a company and I already have a bunch of IP4. I upgrade my network equipment to IP4+, and then keep all my routing and firewall configs. Everything just works the same as before. Now I want to access IP4+, so I add a route entry for all the IPs above 255.255.255.255.
It does not. Because 255.255.255.255 only covers 32 bits and "IP4+" is >32 bits. You'd still have to touch every rule to to tweak the mask.
Oh, and your IP4+ idea already exists:
> Addresses in this group consist of an 80-bit prefix of zeros, the next 16 bits are ones, and the remaining, least-significant 32 bits contain the IPv4 address. For example, ::ffff:192.0.2.128 represents the IPv4 address 192.0.2.128. A previous format, called "IPv4-compatible IPv6 address", was ::192.0.2.128; however, this method is deprecated.[61]
You still need to upgrade bit of networking kit between the source and destination to understand "IP4+", and this (lack of) upgrading and enabling is what is hampering deployment.
What makes you think that companies would have been willing to make the effort to deploy "IP4+" any more than IPv6?
> You'd still have to touch every rule to to tweak the mask.
No you wouldn't. 0.0.0.0.1.0.0.0/40 and 1.0.0.0/8 are the same thing. If the rule says 1.0.0.0/8 then the router converts it to 0.0.0.0.1.0.0.0/40. If you happen to have 1/8 as your rule, then an easy fix is to say ip4+ translates shorthand rules at ipv4 if the mask is under /32.
> What makes you think that companies would have been willing to make the effort to deploy "IP4+" any more than IPv6?
Because when they went to upgrade their router, as they often do every decade, it would just support IP4+ with no config changes on their end. They would pull their config from their old router and it would just work.
Then they would discover they had IP4+ support and maybe start using it.
The reason it is easier is because it's a small incremental change.
> No you wouldn't. 0.0.0.0.1.0.0.0/40 and 1.0.0.0/8 are the same thing.
I don't see why the CIDR would make a direct difference. Whether it's converting 1.0.0.0/8 to 0.0.0.0.1.0.0.0/40 or 2002:c000:0204::1.0.0.0/96 doesn't seem to matter to me. The only difference I can think of is local networks (10/8, 192.168/16, 172.16/12) but your suggestion would fail in the same way.
Several compatibility systems for IPv6 exist. 6to4 is the most common one I've seen. It all works on a technical level until DNS gets involved.
> Then they would discover they had IP4+ support and maybe start using it.
If your business network is managed by "hey, this feature exists, let's see what happens if we turn it on" then your network admin needs to be more professional.
> If your business network is managed by "hey, this feature exists, let's see what happens if we turn it on" then your network admin needs to be more professional.
I think this is why you don't understand how IP4+ would be easier. 99% of companies make their "IT guy" manage the network. They aren't network professionals. They are mostly desktop professionals who also get forced to manage the network and firewall. Same with most schools -- they can't afford to hire network professionals. Sometimes they get lucky and someone is excited about learning networking, but that's not true in most cases.
If they already have a bunch of IPv4 rules that some contractor wrote once, and they have a vague understand of how those rules work and why, they don't want to learn a new scheme or run 6to4 or anything else. They just want it to work by copying the old config and then maybe if they have time they can explore the new features of their new equipment.
If it's just "The IT guy", then IPv6 will work out of the box for outgoing traffic and will block all incoming traffic. This is why almost half of the USA is using IPv6 right now, it's just turned on by default.
Hosting stuff is harder, but it's also that different. Theoretically, you can NAT IPv6 traffic to an IPv4 server inside your network no problem, but it's a pain and nobody really needs it anyway, so it's not widely used.
I think you're missing the point. You're a network engineer and know what you are doing. Most people aren't.
IP4+ would be easier because it's more incremental and less change than IPv6.
Yes, there exists solutions to all the problems that IP4+ would solve, but the point is backwards compatibility and incremental change is always easier than doing something new.
But, correct me if I'm wrong, IP+ doesn't do anything differently from IPv6, except that it changed the 6to4 prefix?
Host 1.2.3.4.5.6.7.8 still can't communicate with a "legacy" host 4.5.6.7 without some kind of bidirectional translation mechanism. Just prepending 0.0.0.0 to an address (or 2002:c000:0204, for that matter) doesn't fix the problem.
I still don't understand why they shifted from 0:: to ffff::
but point stands, ipv6 is exactly ipv4+, except yes, they did redo arp. I don't think its really that much better...but really? that's what turns something from great into awful?
> I still don't understand why they shifted from 0:: to ffff::
I think the most reasonable explanation is probably because they thought ::1 being loopback (otherwise it would have to go above 255.255.255.255) was more important (since it would exist as long as IPv6 does) than the transition encoding that presumably would die off over time.
If you really wanted you to could keep you old addressing scheme in IPv6 (arbitrary IPv4 addresses can be embedded into IPv6), you can disregard all best IPv6 practices about subnetting and do everything like you did for IPv4, DHCP and all, heck even NAT. The problem is that as soon as you're turning it on you need to maintain two sets of routing and firewall configs, even if they were identical.
Also you need proper support from all those lazy vendors (both hardware and software) that did the absolutely minimal amount of work to advertise their products as IPv6 ready when it fact the support ranges from subpar to practical unusable.
As soon as you make a one bit incompatible change to the protocol routers aren't able to communicate anymore: it's the same situation again. It doesn't matter how similar the two protocols are, they're incompatible.
This comes up every few years. I remember there was even a link about it, but I can't remember what to search for :)
Naive approaches all assume that there is some incremental step, and IETF was just too idealistic to go with a completely new second system. But as others mentioned, it's a coordination problem. Since IPv4 does not have any signaling mechanism for upgrade, or for somehow encapsulating variable/longer length addresses ... adding that is the minimal change size.
Of course if your argument is that the RFCs and the whole v6 world is just a big unfriendly abstract wall of text, not "accidental IT guy" friendly, then of course you are right. But that can be remediated by writing better docs, providing better UX via better tools. (All the usual linux tools are horribly user hostile, and then they have an additional stinking pile of v6 tools, or the occasional -6 parameter.... but that's not exactly the IETF's fault.)
IPv6 is a slightly different model, different enough that you can't just copy the configuration from IPv4, and that adds a significant implementation burden. If IPv4+ had been created instead, we'd probably all be already using it.
That said, it's obviously way too late to go that direction. The only successor to IPv4 is IPv6. Choosing the wrong model just made sure we'd have to go dual-stack for a loong time.
It's already more or less how IPv4 addresses are embedded in IPv4 (except its 128bits and they use an FFFF prefix between the 0 and the IPv4 address).
IPv6 doesn't solve anything for the sake of it. Anyone who had to debug ARP caused issue on a network knows it's complete garbage for example.
Providers who explain that they are dragging their feet because of the complexity would have said exactly the same thing even it was only IPv4++. They just don't want to invest any money in something which is working for them.
It’s the firewall rules that always creep me out. The nice thing about NAT is open ports on your internal network are hidden to the outside world by default. You have to think about which ports you want the NAT gateway to forward.
With IPv6 the entire network is reachable outside by default. Granted I assume you can probably create a default DENY rule for inbound traffic and selectively open ports up as exceptions. Right?
> With IPv6 the entire network is reachable outside by default.
The entire network might be routable, but it often isn't reachable. My router had a default deny rule, so everything in my network for sure wasn't reachable by default despite having IPv6 addressing.
If anything, I like firewalling in IPv6 far better than dealing with NATs. Just imagine having multiple boxes you'd like to reach by SSH or HTTPS from the outside. With NAT, you can only run one on a standard port. With IPv6, there's no need to NAT, everything can just use one of their many public IPv6 addresses, and then I can firewall to allow traffic to each of those boxes at the standard ports.
In fact, this gets even cooler. I can then have multiple services all bound to different IP addresses and have different firewall rules related to each of those services. There's so much more possible using IPv6 that you just practically can't do in IPv4, unless you just happened to have a /8 assigned to you back in the day.
Think about this: every device in my home network gets more IP addresses assigned to it than there are IP addresses in IPv4. I can have every container on my cluster have its own publicly routable IPv6 address, every application I run could theoretically have its own address and have its own network rules applied. And then I can look at my network edge and immediately identify any and all traffic flowing through that edge.
I can't wait until IPv4 is dead and I never have to deal with NAT issues again.
What makes you think that, for critical systems, "IPv4 + NAT + bad firewall" is the default IPv4 deployment paradigm, rather than "IPV4 + bad firewall"?
Sure, big IaaS providers like AWS put you in a VPC by default. But most servers on the net are not hosted in an IaaS; they're hosted using a VPS or bare-metal hosting provider, or just coloed in a DC by their owner. And in all those cases, what that kind of deployment gets you, is a public IPv4 per VM/machine, that anyone on the Internet can march right up and talk to, where it's the responsibility of the machine itself to reject incoming packets (i.e. at the OS level with a kernel firewall.)
NAT on IPv4 is only really a default assumption for residential networks. Anywhere else, it's pretty much like the movie WarGames: even the mainframe has a phone number you can call. Staying on IPv4 isn't making anyone safe.
While I don't have any factual proof to refute your statements, in my personal experience almost every organization uses NAT & RFC1918 address space. The only client I can think of in my 20 years of experience that used a public IPv4 per VM/machine was the DoD, specifically, the U.S. Army.
From your very last statement, I think you've confused self hosting (like buying a VPS from Digital Ocean and hosting your own blag) and how the real world works (like going to Dell.com and ordering a new laptop). "The mainframe" these days is almost always behind a L4/L7 load balancer or other network device and very rarely directly addressable.
People assume that RFC1918 is not routable, but that's not the case... It's fully routable, but there is no global route.
Have you ever tested routing to your RFC1918 address space from the ISP, or from a customer in the same neighborhood?
On some ISPs, all the customer routers in a given area are placed in a large legacy subnet, so if another customer adds a manual route to RFC1918 space using your router as next hop - the traffic will arrive on the WAN interface of your router. Some routers will actually route this traffic inside.
Have you ever tested this and verified that your router doesn't do this? Probably not, because most people haven't. They just assume that it can't, and get a nasty surprise if someone demonstrates that it can.
My company runs an API SaaS; my impressions come from a hobby I have of looking up the hosting providers behind our customer IPs as seen in our request logs (to find out what people think is a good idea for hosting a production web- or mobile-app service backend these days.)
By and large, our very-much "real world" customers are "self hosting" — usually on bare metal rather than a VPS, and usually with providers you've probably never heard of (ColoCrossing and ServerMania seem to come up fairly often among our US-based customers.) These hosting providers are all very much in the style of "you lease each machine as a separate contract; each machine gets one public IPv4 address included in the cost; private networking [i.e. an explicit VLAN] is an extra optional feature you can enable after the fact, and only works between higher-end machine types, rather than being a given, because our lower-end machines only have a single NIC in them [besides the one that's part of the BMC used for IPMI]."
What I assume is happening here isn't literal "self hosting" — these random non-IT-oriented customers wouldn't know the first thing about it — but rather that a given customer of ours has paid some "vertically-integrated IT consultancy" to both build and host their service for them; and said consultancy has chosen to use bare-metal hosting to host the resulting service, to minimize their own OpEx, and therefore maximize their margins. (In fact, I bet they're often packing several such customers onto a single box.)
---
Also, in a more professional capacity, I investigate the hosts behind IP addresses behind bulk-registration / DDoS attacks against our platform, in order to create signatures for them. Given the way some of these attacks seem to work, a large number of machines on the Internet — especially in Russia and [some parts of] Africa — seemingly aren't only un-NATed, but in fact have a public /24 or even /22 directly attached to a single box! (If traffic was originating from a random subset of a /24, it could just be someone spinning up a hundred VMs on top of some small colo's OpenStack deployment, sure. But tandem traffic from every IP in a /24, and only exactly said /24? That looks pretty much exactly like the sort of tandem IPv6 traffic that is generated when a box has a /48 or /56 assigned to it.)
Big universities (at least in my experience in the USA) are the other ones that would have a public IP address for every device, at least until rather recently. They were online very early and got allocated huge blocks of addresses, before anyone really imagined future scarcity.
In the mid-90's, every system at my university had a public IP address, including those on the campus residential networks. There were no firewalls. It was also a flat address space (/16, 255.255.0.0) for the whole campus! The 90's were certainly a different time.
I use an old Parallax Propeller server as my DMZ, with instructions to log everything and answer "OK" to everything. It's funny what people try to do to it.
Depending on the NAT implementation this can be incredibly naive. Many home routers will send ANY traffic incoming on a port to the NAT'd IP address, even if the sources don't line up.
So say Alice is behind a crappy NAT and wants to talk to Bob. Alice's router opens a port on its edge, lets say 1234, and sends traffic to Bob on port 80.
Let's say Charles knows Alice's IP address. Charles starts spamming Alice's router, eventually hitting port 1234 with bad data.
Alice's router is dumb. It sees traffic on port 1234, checks its NAT table, and sees that data is supposed to go to Alice. It happily rewrites that packet and passes it along to Alice. Now Alice is getting traffic from Bob *and* Charles. Uh oh!
Many game consoles are explicitly designed around this bad, broken behavior. You'll open a port to the matchmaking server and then the matchmaking server will tell people to connect to that IP address and port combination. Crappy home routers will happily route that data through its NAT configuration to the console despite the console never explicitly opening up traffic to those other parties. This is why some game consoles will complain about closed NAT versus open NAT.
> Alice's router is dumb. It sees traffic on port 1234, checks its NAT table, and sees that data is supposed to go to Alice.
While in principle that is possible, in practice almost all home routers are based on Linux, and Linux netfilter NAT implementation distinguish connections based on port and IP, not just port, so this would not work.
The poke a hole to outside world to a random server, log the port allocated to you by your router and have someone else use this to connect to you is the basis of STUN protocol.
Home routers often greatly simplify the interface.
BT, one of the largest ISP's in the UK, only allow the configuration of destination IP and external/internal ports[0].
I've never expected my NAT to do anything other than map ports. I can see why the ability to map source IPs to different ports would be useful but relying on that as a security feature feels like a foot-gun. I wouldn't feel comfortable exposing an application that doesn't have some form of authentication and/or blacklisting.
I gave an example just a few comments above this. Alice never wanted Charles' traffic, the firewall should not have let it through. But because the NAT is dumb, and the firewall rules are often tied to the NAT on these crappy home routers, it's allowed. So now because Alice wanted to talk to Bob, she opened a port to the world that she never wanted opened as wide.
This is straight up untrue. The only thing NAT does is change the apparent source address of outbound connections. Inbound connections aren't outbound connections, so it does nothing to them.
My shitty cable modem which is also a router does not expose its web interface to the world by default.
I don't understand why you'd need a firewall if
- you trust devices on your network (yes, big if, but even then: the only reachable ports of a machine from the outside are those explicitly open to the outside, most stuff listens to 127.0.0.1 anyway)
- you only configure your NAT to forward ports you would open on your firewall
I didn't think of my cable modem as a firewall. Maybe technically it has one to provide the feature of blocking access to its web interface from the world, or maybe it just listens to the right network. I don't know, but for all intent and purposes, setting up a firewall myself does not seem necessary.
To be fair, I was also a bit annoyed by staringback's phrasing.
I make sure what I build supports IPv6 (and I'll use tunnels if it's what it takes) but I can't make the only cable ISP available at my place support IPv6. I wish it did. I wish I didn't have to use its garbage hardware.
> It’s the firewall rules that always creep me out. The nice thing about NAT is open ports on your internal network are hidden to the outside world by default. You have to think about which ports you want the NAT gateway to forward.
Have you never had more than a handful of IPv4 addresses? IPv6 works the same in this regard as a router IPv4 network e.g. universities, large/old enterprises etc. NAT started as a workaround to make the available public address space last longer.
The address (and port) translation wasn't intended as a security feature on its own. These days lots of protocols automatically deal with NAT and mostly manage to establish bidirectional communication over UDP or TCP through NATs. I rather deal with stateful firewalls and public IPv6 addresses end to end instead of gluing the segments of flows between IPv4 translators back together.
NAT wasn’t started as a way to make the address space last longer. A few decades ago you could get hundreds of thousands of IP’s by filling out a form with ARIN without any serious justification if you wanted them. I worked at an ISP and IP’s weren’t a scarce resource.
NAT started because having a network didn’t mean you were necessarily participating in the Internet. Globally unique addresses weren’t that important. At some point you had this decentralized situation where local networks wanted to bridge their users address space to the Internet without renumbering everything and thus NAT was born.
Every consumer and professional router I've seen comes with a deny rule for incoming traffic by default, unless the device is configured as a "router router", like inside an ISP.
NAT has many problems because people rely on it for security. For example, many shitty IoT devices and even consoles (looking at you, Nintendo Switch) tell you to put their device in the DMZ to make them work.
The norm for IPv6 in practice is that you've got your firewall on and need to make exceptions for ports you want open, just like on IPv4, except that with IPv6 you don't need some kind of interactive state machine attackers can confuse and abuse running inside your router's kernel (ALG).
- NAT punching does require cooperation of programs on the protected machines, though, no? How is it different from them inviting traffic in any other way (like, requesting a page via https from an infected server could hijack the client on the protected machine if the client has security holes in the right places; the https client is willing to get traffic here, just as some VoIP program is willing to receive a call)?
- And is it any different from a stateful firewall on IPv6?
> NAT punching does require cooperation of programs on the protected machines
As does listening to a port.
> And is it any different from a stateful firewall on IPv6?
Hum, not much. And that's the point, all of those are basically the same. NAT doesn't give you much security, and NAT without a firewall usually gives you less security than a firewall, since NAT usually is configured for connectivity, and a firewall for protection.
> > NAT punching does require cooperation of programs on the protected machines
> As does listening to a port.
Listening on a port is for incoming connections, exactly the kind that we're blocking with either a (stateful) firewall or NAT. Listening on a port is a declaration of a program (a server) to communicate with whichever counter party can connect to this port (until the server program decides to close the connection), and limiting that reach is the topic here.
NAT hole punching is more like an outgoing connection in that the client agrees to communicate with a particular single counter party for each punch. That's why I made the comparison to opening an https connection to a server. The risks look basically the same to me (the client has to trust the server in the https case, and the client has to trust the intermediating server in the NAT hole punching case to intermediate with the right client; admittedly it additionally has to trust the other peer (e.g. that its compressed data doesn't try to break decoders), but in cases where it communicates with another party via a server the situation may be the same again (unless the server re-encodes the data and does that securely)).
> And that's the point, all of those are basically the same.
That's a relief for me to hear, as I started to doubt myself whether I am missing something ("why is it not OK to use NAT to block incoming connections?").
> since NAT usually is configured for connectivity, and a firewall for protection.
Sure, a firewall can add additional restrictions. I have always understood NAT's protection to be limited to prohibiting incoming connections (unless when adding port forwarding), while allowing outgoing connections including NAT hole punching.
I'm also talking in the context of configuring a Linux machine via iptables (where you configure both NAT and other firewalling rules). Maybe you're thinking more in terms of consumer "NAT" vs. consumer "firewalling" devices and their respective capabilities. Or maybe this whole "don't consider NAT to be a security feature" movement is just to pull people towards IPv6 by saying they don't need NAT to be as secure (or better if they configure additional restrictions)?
The point here is that the movement against IPv6 for security reasons is disingenuous or even outright dishonest. Those security reasons don't exist.
Personally, I have never seen any argument for IPv6 based on security (except for some very fringe ones about address enumeration). But if anybody makes one to you, well, it would be disingenuous, or maybe even dishonest too. There is no security-based argument either way.
> I have always understood NAT's protection to be limited to prohibiting incoming connections
It doesn't actually do this. NAT rewrites the source address of outbound connections. Inbound connections aren't outbound connections so it does nothing to them, which means it doesn't prohibit them.
That is why you don't need NAT for security: it doesn't give any in the first place.
OK. I want to dig down into this. Let's say I have a router `R`, which I'm running NAT and optionally other iptables rules on. I've got a client machine `C` sitting in a private network "behind" `R`. `R` is connected to the internet via a gateway `G`. `A` is some machine out there owned by an attacker. There's a vulnerable TCP service running on `C` listening on *:1313.
A
|
internet
|
G
| 4.3.2.1
|
| eth_public 4.3.2.77
R
| eth_private 10.0.0.1
|
| 10.0.0.2
C
`A` can't connect to 10.0.0.2:1313 since it's not routable from their position. Thus, the fact that NAT on its own doesn't prohibit traffic to `C` doesn't matter in this scenario, practically `A` still can't reach it. So far so good?
The only issue I can see is that if `A` can hack `G`, because `G` doesn't have to depend on routing to reach `R`, it can send traffic to `R` with a target address of 10.0.0.2, which `R` then forwards to `C`. I haven't verified that this works (don't have enough devices with me). Is this what you're after? Fair point.
If I'd add the following rule to `G`, `C` would be safe even if `G` is hacked[*]:
iptables -A FORWARD -i eth_public -d 10.0.0.0/16 -j REJECT
[*] Of course that requires that any outgoing connections that `C` makes are not vulnerable against the possible packet manipulation from `G`.
Am I missing anything?
Edit: simplified the rule
PS. I'd welcome a good pointer (book or other) on network security and also IPv6; I'm a software developer, and only occasionally dealing with networks.
That's basically it. In that network, G can connect to C just fine. You need the firewall rule to block inbound connections, because NAT just does nothing to them.
I don't have any good learning resources for this stuff, sorry. I mostly picked it all up by running it on my home network and Googling for stuff when I hit something I didn't get.
I just started University, and as a result I have had my first experience of Internet without NAT. The firewall rules provided are simply On or Off, which has been very strange to me, and it doesn’t seem all that secure.
Of course if you are on someone's else network (typical for hosting when you aren't provided with your own v6 subnet, instead you have a bunch of addresses) then you should configure firewall on each your machine... which is what you need to do anyway?
> How do we teach every client on the Internet to talk to servers on public IPv6 addresses [and vice versa]?
> Answer: We go through every place that 4-byte IPv4 addresses appear, and allow 16-byte IPv6 addresses in the same place.
> ...
> Unfortunately, the straightforward transition plan described above does not work with the current IPv6 specifications. The IPv6 designers made a fundamental conceptual mistake: they designed the IPv6 address space as an alternative to the IPv4 address space, rather than an extension to the IPv4 address space.
> ...
> This might sound like a very small mistake: after all, once IPv6 is working, we can move everything to IPv6, so who cares about IPv4? The problem is that this mistake has gigantic effects on the cost of making IPv6 work in the first place.
That is the exact right reason, none of the other BS that’s been written (notice the lack of complaints about new IPv6 features). It’s purely about v4/v6 interop. I’m still not 100% sure how you would have solved some of these problems though. It’s easy to state that’s the problem. A lot harder to show how you have these things interconnecting seemlessly.
It provides a lot of improvements actually. Stating the obvious, NAT isn't needed anymore. Also with modern Firewalls rules need to be written only once. At this point I'm just surprised why it's not adopted
The most obvious case is multi-homing (for redundancy, fail-over, and policy-routing reasons) without an AS available and thus without BGP. In other words, a typical case when a user has a fiber connection and LTE as a backup. Then it is the router who should pick the correct source address, according to the link which is up.
Another reason is to deal with dynamic addressing from the ISP. Let's suppose we have an ADSL PPPoE connection, with prefix delegation. The modem connects, gets a prefix, devices grab IPs from it. Then a rat chews upon the line, causing a disconnection and a reconnection - but the ISP now delegates a different prefix. Or worse - the modem crashes and reboots, also picking up a different prefix. Devices are still not picking up such unexpected renumberings well. So they continue using old addresses, which don't work. Using a layer of network prefix translation solves the problem, as now only the router needs to be aware of the renumbering that has just happened due to the rat.
"IPv6 Multihoming without Network Address Translation"
Network Address and Port Translation (NAPT) works well for conserving
global addresses and addressing multihoming requirements because an
IPv4 NAPT router implements three functions: source address
selection, next-hop resolution, and (optionally) DNS resolution. For
IPv6 hosts, one approach could be the use of IPv6-to-IPv6 Network
Prefix Translation (NPTv6). However, NAT and NPTv6 should be
avoided, if at all possible, to permit transparent end-to-end
connectivity. In this document, we analyze the use cases of
multihoming. We also describe functional requirements and possible
solutions for multihoming without the use of NAT in IPv6 for hosts
and small IPv6 networks that would otherwise be unable to meet
minimum IPv6-allocation criteria. We conclude that DHCPv6-based
solutions are suitable to solve the multihoming issues described in
this document, but NPTv6 may be required as an intermediate solution.
I just did a quick read but I don't understand how this would help the case of your Gateway ethernet link going down temporarily and switching to Cellular WAN?
The client would still need some smart steering to select the correct route no? Does the gateway invalidate the ethernet address somehow?
But with NAT you don't need to worry about it.
The correct way to do this is to advertise the fiber connection's prefix to devices on LAN as long as that connection is available. When it fails, the router should send RA with zero as the expiry time for that prefix, and include the LTE prefix. This way, all devices will immediately start using the new prefix. You can use ULA in addition so local connections don't fail.
This can work with the fiber + LTE example, and with the rat example, but does not cover the "modem crash" example. The ADSL modem does not know its old prefix, and thus cannot send zero-expiry-time announcements for it.
Also consider a case where there is an ADSL modem (with the ISP giving out /56 via prefix delegation) and a home lab with virtual machines, that are behind a virtualization host, which grabs a subprefix (let's say a /64, separate from the main home LAN /64 prefix) for its VMs from the modem via DHCPv6. While there is indeed a mechanism for flash renumbering over SLAAC, which may work for devices in the home LAN, there is also a need to invalidate the subprefix delegated for virtual machines via DHCPv6 through the virtualization host. Last time I checked, this is not implemented anywhere.
ISPs love NAT because it is an artificial distinction between producers and consumers, which means they can call the producers ‘pro’ of ‘enterprise’ and charge them through the nose while the consumers can’t cause trouble and just pay for download speed.
Going by my current experience of managing an ISP, the number of people that care at all about producing anything is almost zero. Out of thousands of accounts I can count on two hands the number of people that want anything outside of the standard ipv4 symmetric 1gb we offer.
When infrastructure makes it really hard for people to produce things, then there's no ecosystem for it and very few people get interested in producing things.
At-home hosting would open up tons of applications. You could have at home video cameras that are actually private (no third party connection). You could share photos with family and friends from a home photo frame - directly. There could be tons of applications that normal people would be interested in.
Perhaps the don’t say they care about producing content but surely they care about accepting (voip) phone calls, being able to torrent twice as fast (because they would be able to connect to twice as much peers) and they’d also like all these services that just don’t exist anymore because too many people are behind NATs they can’t control.
The popularity of uPnP for automatic port forwarding should be a clue, anything that uses that is blocked by cgnat.
OMG! What were we all thinking! Thank you redox99 for figuring this out. Only now that you have pointed out this idea is it suddenly obvious.
But, since this is, you know, the entire internet, can you maybe write a more detailed specification?
So like, when my TCP stack creates a presumably backwards compatible IPv4 header, where does it put the extra 4 bytes? Or do we only send these IPv4+ packets to devices that we also know are IPv4+? If we add four bytes at the end of the IPv4 header, then when I send to 12.4.1.0.8.8.8.8, then the legacy server will read it as 8.8.8.8 and send my information to Google. That seems bad.
Or will we create a new IP header format? If so, how will we make sure that all the software on a given box understands the new format? How do we incrementally roll out these new applications, kernels, modules, etc, in such a way that we dont break the internet in interesting and fatal-for-real-people ways? Maybe we could deploy IPv4 and IPv4+ side-by-side, so that both are running, and so the new IPv4+ can fail with no risk to the IPv4 services?
How about parsing IP addresses. What if I send to 10.44321? This is a valid IP address. Are we going to say that the various short-hand representations only apply to IPv4, so you an't shorten 127.0.0.0.0.0.0.1 to 127.1? How will we handle scripts where the subnet is specified as /24 independently of the address, such that IPv4+ subnets will contain 32 billion IPs instead of 256? Or do you imagine that IPv4 and IPv4+ scripts must be kept separate?
I am looking forward to your specifications! While you are addressing all these issues, could we also look at expanding the number of ports available too? Also, what if IPv4+ used sixteen bytes, instead of eight?
Please look at the structure of an IP header. Note the "options and padding" section.
Also SECTIONS of the internet (that is, routers) can have IPV4+ packets wrapped in IPV4 packets that will transmit them through "IPV4-old" only branches.
We pretend like the major routing backbones aren't known and fairly set in stone, and that routers don't know about each other.
Yeah, his approach doesn't fix the Comcast-doesn't support-IPV6 and is stuck in old IPV4. But those places are using NAT of their own.
If we have all these cgnats and other address translations happening, well shit how is that different that the IPv4 wrapping ipv4+ and other things.
Also, oh yes please give me more fucking ports. IPv6 keeping the same number of ports is stupid. Please give me 64 bits of ports. Ok, I'll take 32.
If you use 10.44321 for a port number these days, well I have no sympathy for you. As for /24, clearly that will mean "IPV4 /24", and whatever new protocol will use some other convention like /000024. But /24 maps to a bit mask. You just interpret the bit mask differently.
Yes I am handwaving a ton of stuff. A ton. But ipv6 basically said "fuck you our way or the highway" and here we are.
At this point, maybe we need a superprotocol ipv8 that will wrap the ipv6 address space, the old ipv4 address space, into an even bigger address space. Get the router vendors and designers back in the room.
I don't think you are refuting my claims. If you put the extra 4 bytes of address at the end of the header, telling the legacy software that the header is now bigger doesn't mean that it will use those bytes for routing. Hence it will route to the IPv4 address. Hence if we send to a.b.c.d.8.8.8.8, it will actually get sent to 8.8.8.8.
IPv4+ packets wrapped in IPv4 is just 6in4.
And all the handwaving is exactly that. It doesn't solve the actual problems that OP claims, e.g. being able to keep existing scripts and everything just works. If anything it makes those systems far more fraught. IPv6 does allow an admin to keep all those scripts for IPv4 and have them still just work.
If anything, what this whole thing shows is that many network admins don't know what the fuck they are doing and are relying on existing scripts and cargo culting.
>If IPv6 were IPv4 with more octets, then we would all have been using it for like a decade.
The only real reason v4 is being replaced after decades is that it has a single showstopping flaw - the lack of addresses. v6 solves this forever with its massive address space. We've seen how incredibly hard replacing v4 has been. Without a similarly huge flaw to drive a replacement it's very possible that v4's successor could be the universal internet protocol for hundreds or even thousands of years. With that in mind, even though progress has been frustratingly slow, going for something closer to the global maximum in design and avoiding ease-of-adoption hacks might be the right thing to do.
That's not necessarily to say that your suggestion of still using dot-separated numeric values would be objectively worse, but bear in mind that doubling the number of fields from 4 to 8 as you've done only gives you a 64-bit address space, whereas IPv6 as it exists has a 128-bit space, so would require something like 0.0.0.0.0.0.0.0.0.0.0.0.1.2.3.4.
that will cause state and can hurt performance since it needs extra memory. one of the main selling point of IPv6 is try to be stateless as much as possible to ease up on routers and switches
Where's the need for state? Please excuse the abuse of terms below, but you can probably figure out what I mean.
A v6 only host would send a v6 packet from it's full address to the v4+ address. A router on the path that has access to v4 internet would pull the v4 destination out, and reframe as a v4 packet (source ?, dest the v4 address), that's got the v6 packet, or maybe just the addresses, I dunno. This router would burn a lot of CPU doing this, but doesn't need any state.
The v4+ host has a little harder job, it needs to know a v4 address to send the tunneled packets to. But again, it's sending a tunneled packet, and whatever is processing that doesn't need state, it just needs cpu to inspect and untunnel. Of course, if the v4+ address is rfc1918 (or otherwise unroutable), then that's problematic. You _could_ do NAT at the router, but I'd say don't do that.
It might be useful for the v4 host to keep the v4 tunnel sender IP from incoming addresses to reframe on the back end.
You might also do something special with routing to the v4+ prefix... if you advertise the v4+ address, it indicates you want v6 -> v4+ traffic to go to your network as v6 and you'll encapsulate it, otherwise it would go a (hopefully local) router that advertised the /96 prefix. If this encap/decap turned out to be popular, you might see router ASICs accelerate it, but likely it's expensive, so the work should be distributed to end points as much as possible.
Of course, there was Teredo that kind of tried to do something like, but it didn't really work out, did it?
IPv6 is the Python 3 of networking, although adoption is taking far longer than Python 3. Hopefully the lesson has been learned and this won't happen again.
> Not having two sets of firewall rules and two sets of everything. I always disable IPv6 because it can bite you so hard when you don't realize that you are wide open to IPv6 connections because of different firewalls.
nftables gives us a dualstack firewall, and it's so far the only one I've seen. It's not that bad, but I have occupational damage so I don't mind :D
I think the big problem of ipv6 is, that it’s not backwards compatible. You can’t just switch to ipv6 only and have a some network box rewrite ip addresses for example 1.2.3.4.5.6.7.8 to 10.6.7.8 or simple kernel module that translates it.
Just imagine if ipv6 stacks could just completely replace ipv4 stacks on every system, with full access to all ipv4 resources, as long as the first 12 bytes are all 0.
> Edit: To make everything a bit clearer, the idea with this "ipv4+" is that you don't need the complexity of running both ipv4 and ipv6 as you do now.
I find that very wild optimism.
- You will still get two incompatible address space V4 and V4+ and that would imply:
-> You still need to modify your software to adapt for V4+ for the transition.
-> Most of your middlebox and firewall rules will get in the way for anything served over V4+. Exactly like for V6
-> DNS would still need to be updated with new record and it will be the same mess
It would be mostly the same mess.
IPv6 has its quirks, but let's be honest: the main problem with Ipv6 is not technical any-more.
The main reason the switch does not happen is that there is no business incentive to switch to IPv6 for most companies and consequently, most companies do not give a fuck.
Which is weird, because there is a business incentive: money. But instead, companies seem to be willing to pay out huge amounts of money to not deploy v6.
There have been no experiments to show why this is any better than IPv6 given that you still need to modify routers and end user devices to route traffic, nor does it address the fact that IPv6 has additional features such as flows and prioritization to handle the modern Internet's traffic requirements.
The scheme you propose had already been proposed by Elad Cohen, but with "evil" intentions as they're linked to a IPv4 misappropriation scheme[1].
The IPv4 dotted quad format carries a lot of baggage. You also have to handle forms with two numeric fields with a mixture of 8, 16, and 24-bit numbers and implicit zero octets. Support for the full syntax is sporadic. IPv6 deliberately uses a new text encoding to make a clean break.
I always joke with "We figured out how to move from Python 2 to 3 but we still cannot figure out how to do IPv6" :). What a catastrophic failure it has been. Should we just stop using it altogether and retire or are there people still advocating ?
Yes, people are using ipv6 for real deployments. See any large scale mobile network deployment. Funny thing is most people never realize because it all just works…
What are you going to use instead? IPv4 is already bursting at the seams and starting over from scratch at this point means at least a decade before a new solution could even be considered.
I don't want to be rude, and I'll assume good faith. But it seems naive to think the syntax of an address would be the sticking point.
128 bit addresses, NDP, SLAAC, etc., there are many huge changes that I don't think syntactic sugar would have saved.
Maybe though? Perhaps it would have been doable but I simply don't know.
We, the world, should ha e legislated some of these standards. The fact that in 2022 I have to worry about if I will get a /60, /64 or /128 from an ISP is criminal. That I can't get a consumer router with prefix delegation available.
I don't see how this has any advantage over just deploying more NAT like people are already doing. Plus it adds IP options which routers hate.
They claim "EnIP supports end-to-end connectivity, a shortcoming of NAT, making it easier to implement mobile networks." but I don't see where mobile network operators would care about end-to-end connectivity?
I always thought to start they should have just allowed each octet two-ish more bits, so you could have 999.999.999.999. I know it’s the hackiest of all hacks, but it sure would have been an easy upgrade from the software perspective. And it would have given about a 256x increase in the number of ips. Which I kinda think actually might have served us for a long time.
In this thread, lots of people seem to think in terms of 255.255.255.255 and fail to recognize the IP address is 32bits and the textual representation of 4 octets means very little.
But the confidence and armchair expertise offered… wow.
I am not a network engineer, but for about 20 years I have wondered why we didn't 'just' do something like:
1. Include an extra 32-bits of address information as an IP options header. Call it an IP4.4 packet.
2. (I think?) IP4.4 packets would therefore happily travel over existing IP4 infrastructure.
3. Each existing IP4 address becomes a potential IP4.4 network with 32-bits of address space behind it.
IP4.4 aware routers at the network border could swap inbound IP4 destination with the .4 address before forwarding on to the internal network. Basically like NAT, but you can allow inbound connections without maintaining state.
What happens when your 4.4 packet hits a router box somewhere out there that doesn’t understand 4.4? Where’s it going to send that packet? To the wrong address (or potentially even create an infinite loop). Now what?
It routes it as an IP4 packet, because it still is a valid IP4 address. Think of it as a way to let a stateless IP4.4 aware NAT router at the edge join two 32-bit networks together. An IP4.4 client could send a packet to a destination in that network by putting the address of the IP4.4 router in the usual IP4 destination, and the 'internal' IP address in the IP options header. No 'entire Internet update' necessary
I understand what you're saying, but isn't IP supposed to be about routing things around failure points? So routers that "know" IP 4.4 would "know" what routers aren't 4.4.
By definition you’re trying to retain back compat. So you have a 4.4 source IP address. You try to establish a TCP connection to a legacy IPv4 website that isn’t 4.4 aware. What address is that website sending the response back to? Even if it is 4.4 aware, how do you guarantee it’s taking a path back through 4.4 aware servers? The whole point of adding an option header is to allow unmolested transit through existing IP stacks. If you’re saying you’re routing around them, then you’ve bifurcated the networks and you’re back to IPv6.
You're basically doing carrier grade NAT for that, the same thing that is apparently tooootallly acceptable to the ipv6 people for their big success story: mobile.
The only success story of ipv6 leads us to the solution: backbone-level CGNAT and other hacks, then impose the economic cost on IPV4-only carriers and endusers.
Indeed, your system would require NAT4.44 as a transition mechanism, just like NAT64 is needed now. It gets no benefit over IPv6, and none of the other benefits like SLAAC.
So, what's the point? It's no easier to migrate to, and once we're migrated is worse.
If a source behind an IP4.4 router sent a packet to an IP4 destination, then yes, the source router would need to apply NAT to the source address. But this is already a standard IP4 router capability, and I think that most connection origins on the internet are already behind a NAT.
I don't agree that it wouldn't have been easier to migrate. No changes would have been needed within retail ISPs for starters. Source code changes to existing IP4 stacks would have been minimal, without requiring a whole new stack like IP6. Practical migration requires only that the source and destination networks be IP4.4 aware.
The idea might make less and less sense over time, but if we'd done this 20 years ago we would have reliably had all the address space we needed 10 years ago, no further transition necessary. So much money spent on IP6 could have been saved, not to mention the opportunity cost of IP4 space being hard to get in recent years.
How would changes not have been required in the ISPs? An IPv4 router wouldn't know what to do with a 4.4 packet. At best, it'd route it to the wrong place - 1.2.3.4.5.6.7.8 and 5.6.7.8 are totally different hosts that may well not even be on the same continent.
Additionally, the only reason so much code had to change for ipv6 is that Berkley sockets is a terrible, terrible API that has abstractions so leaky they might as well not exist. Sure, in other APIs (what few exist) low-level code had to be rewritten somewhat, but that's going to be true for any protocol change, because that's kinda what change means.
I think you have missed that a IP4.4 packet would be a valid IP4 packet. The first 4 octets of the 4.4 address are where IP4 expects them to be. The router at this IP4 address needs to understand IP4.4, but routers before do not. The additional octets are smuggled within the IP4 options header.
I didn't claim it to be a new idea - I asked why we didn't do something simple like that (as the solution) instead of all the expensive complexity of trying to upgrade the entire Internet to IP6 over multiple decades.
That was my point: we did. It turns out people prefer to deploy v6 natively.
(Also, I don't think it's fair to call it simple. Many of the things we've done to deploy v6 are things which need to be done to deploy any IP protocol with bigger addresses than v4. If you count those things against v6 while ignoring them for any alternative, you aren't doing a fair comparison.)
Thanks for that. As a transition-to-IP6 technology that makes a lot of sense, but I think it required a lot of prerequisite technology and work (i.e. IP6 itself). The hack I described could have been implemented on top of existing IP4 codebases.
Sure, we could have had hacks that would have been faster to implement, but there isn't reason to believe it would have helped. The bottleneck was never in the code. Routers and OSes got v6 support ages ago and it's been working in lots of edu & gov networks all over the world for 20+ years. ISPs just haven't been enabling it.
Lukewarm deployment incentives for ISPs, lack of pull from device/app makers, etc have been the main problems. Apps adapted to the NAT world quickly, users forgot what capabilities they lost and started to fall into the NAT = security cognitive trap.
It’s a chicken and egg problem. It would have been nice if everybody everywhere agreed to build and use an entirely new network at the same time, but that was never going to be practical.
The actual problem at hand was lack of address space, and I think this could have been addressed with a more viable upgrade path - turn every IP4 address into x number of addresses behind it, and allow retail ISPs to remain IP4 only.
Happily traverse the existing IP4 Internet, to an IP4.4 aware edge network. The point is that you don't need to modify any IP4 networks between the IP4.4 aware origin and destination routers.
Because on the wire it's encoded as four bytes. If you can make eight binary digits count up to 999, you can do a lot more than just make IPv4 last longer.
Clearly ipv6 is very flawed and by now the community should consider it a failure and work on a viable replacement.
We need an internet protocol that is backwards compatible with ipv4 and does not require deploying and maintaining entirely parallel
networks, interfaces, firewalls, routing, etc.
If ipv6 actually was viable, the internet would have cut over. Instead we’re on a path to support ipv4 and ipv6 in parallel essentially forever.
There is no “backwards compatible with IPv4”. If you have to modify the existing packet headers, you no longer have backward compatibility. If you change anything involving how a flow is identified (like the source/address destinations and ports) then you have broken backward compatibility. Firewalls need to understand new address formats, routers need to understand new address formats, end systems need to understand new address formats, BGP needs to be extended to support new address formats.
IPv6 is perfectly viable and it is in many ways cleaner than IPv4 is. It’s just that transition is expensive and apathy is easy.
That cost will continuously rise up until migration to ipv6 comes out cheaper and enables access to the developing market as well. At which point it is a business no brainer.
Short .com domains actually have an intrinsic value to their prospective owners though, since the domain is the human-readable address, and a shorter address is more memorable to customers. The version of the underlying network protocol is just an implementation detail that the vast majority of companies (basically everyone besides possibly 1.1.1.1 and 8.8.8.8) would happily drop if it became totally unnecessary.
Just like IPX. It's still necessary and in use for some things -- so it hasn't reached its end of life -- but when was the last time you ever thought about it?
By this metric, we still haven't finished migrating to v4.
True. I could see a world where IPv4 is only for legacy, internal systems and it is not routed externally, but that feels like decades away. There would need to be a coordinated effort of major ISPs to turn it off, but why would that happen if people are willing to pay for it?
I have no doubt there's an internal application running on a Novell server somewhere that we'll never hear about. It's still running on a machine in a closet just like it was in 1997, or possibly imaged and migrated to a VM because nobody wanted to touch it.
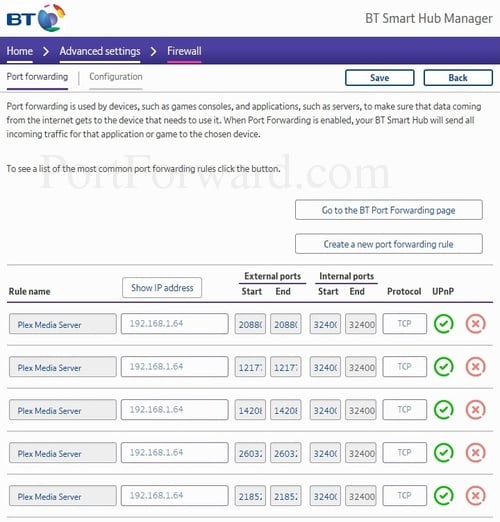{kind=link}
{kind=link}
And I don't mean adoption, I mean the standard itself.
If IPv6 were IPv4 with more octets, then we would all have been using it for like a decade.
Yes, I understand it would still require some breaking changes, but it would have been a million times easier to upgrade, as it would be a kind of superset of IPv4 (1.2.3.4 can be referred as 0.0.0.0.1.2.3.4).
Not having two sets of firewall rules and two sets of everything. I always disable IPv6 because it can bite you so hard when you don't realize that you are wide open to IPv6 connections because of different firewalls.
Edit: To make everything a bit clearer, the idea with this "ipv4+" is that you don't need the complexity of running both ipv4 and ipv6 as you do now.
And regarding compatibility, with ipv4+ if you have a 0.0.0.0.x.x.x.x ip address you would be able to talk to both ipv4+ aware and legacy ipv4 devices natively without any tunneling (because you also own the legacy, non quad 0 ip address). If you don't have such "quad 0 ip" (you are 1.1.1.1.x.x.x.x), only ipv4+ aware devices would be able to to connect to you, and for you to connect to non ipv4+ aware devices you would need either tunneling, or having a secondary, cgnat, "quad 0 ip".