Well, with SO, at least you can search on Google and view the version cached by Google just fine.
With Reddit however, these days almost all comments are locked behind “view entire discussion” or “continue this thread”. In fact, just now I searched for something for which the most relevant discussion was on Reddit; Reddit was down so I opened the cached version, and was literally greeted by five “continue this thread”s and nothing else. What a joke.
Reddit's attempts at dark patterns are embarrassing from all perspectives. If you use dark patterns it's a laughably abysmal implementation. If you abhor dark patterns, it's a frustration.
They've actually done a masterful job of finding this balance. I've been on reddit for 15 years and would have quit if they didn't leave the old interface available.
I honestly thought Reddit would die when they introduced Reddit awards, it seemed like such an obvious cash grab. You can't underestimate the amount of community momentum that the site has though.
Yeah it's crazy how bad user-hostile reddit.com has become. Fortunately old.reddit.com is still available, but for how long? If only Javascript did not exist, it would be impossible for UX people to come up with something that bad.
> only Javascript did not exist, it would be impossible for UX people to come up with something that bad.
Arrange the html so that the list of comments is at the end (via css). Keep the http connection open, have the show more button send some of request, and when you receive that request send the rest of the page over the original http connection.
As usual, solve people problems via people, not tech.
② A submit button or link to a URL that returns status 204 No Content.
(CSS image loading in any form is not as robust because some clients will have images disabled. background-image is probably (unverified claim!) less robust than pseudoelement content as accessibility modes (like high contrast) are more likely to strip background images, though I’m not sure if they are skipped outright or load and aren’t shown. :active is neither robust nor correct: it doesn’t respond to keyboard activation, and it’s triggered on mouse down rather than mouse up. Little tip here for a thing that people often get wrong: mouse things activate on mouseup, keyboard things on keydown.)
“Continue this thread” links don’t depend on JavaScript at all.
“View entire discussion” couldn’t be implemented perfectly with <details> in its present form, but you can get quite close to it with a couple of different approaches.
I think the infinite scrolling of subreddits is about the only thing that would really be lost by shedding JavaScript. Even inline replies can be implemented quite successfully with <details> if you really want.
Why wait? Teddit has been a great substitute for reading in a mobile browser, and making an iOS shortcut for transforming Reddit links was pretty straightforward.
Impossible? Man, it's crazy how fast people forget things like good old fashioned <form> GETs and POSTs. It would obviously be a full page refresh, but other than that the same awful UX could still be implemented.
I guess there is a market for search engine (maybe accessed through tor) which does not care about robots.txt, DMCAs, right to be forgotten etc. Bootstrapping it should not be that hard since it can also provide better results for some queries since nobody is fighting about the position until it's widely known.
I'm not sure how far are we from being able to do full text internet search. Or rather even quote search, preferably some fuzziness options. That would be cool, Google's quotation marks were really neat back when they were working.
That's the good old Easter eggs, perhaps a memory from when Reddit was a nice place. They stop appearing and are replaced by dark patterns once sites jump the shark.
I reod some people use false slugs in the robots.txt as a honey pot of sorts. IPs that actually read the robots.txt, ignore the disallow, and still access the uri are outright banned.
It might be related to the time few years ago when Google added exclusions for user agent t1300 in regard to its founders. Gort seems to be a robot from old scifi and bender might be something similar.
> I guess there is a market for search engine (maybe accessed through tor) which does not care about robots.txt, DMCAs, right to be forgotten etc. Bootstrapping it should not be that hard since it can also provide better results for some queries since nobody is fighting about the position until it's widely known.
There is a solution for all this mess and I'm blocking HN and a few different domains until I implement at least the first step after which I can share it here.
Also, even if search engines are allowed, old.reddit.com pages are not canonical (<link rel="canonical"> points to the www.reddit.com version, which is actually reasonable behavior), so pages there would not be crawled as often or at all.
Is this a call for competition? I regard Cloudflare as state-of-the-art in terms of security and ease-of-use. I certainly hope their knowledge replicates across other organizations. As of now they're still building highly impactful tools that are easy to use and that noone else quite provides. I don't really expect another organization to match them given the strength of their current leadership. I think they've built in a head start for awhile.
> Cloudflare as state-of-the-art in terms of security and ease-of-use
Depends whose security. I value my security dearly and that's why i use the Tor Browser. Cloudflare has decided i cannot browse any of their websites if i care about my security (they filter out tor users and archiving bots agressively) so i'm not using any cloudflare-powered website. Is it good for security that we prevent people from using security-oriented tooling, and let a single multinational corporation decide who gets to enter a website or not? In my book creating a SPOF is already bad practice, but having them filter out entrances is even worse.
Also, are all of these CDNs and other cloud providers are solving the right problems?
If you want your service to be resilient against DDOS attacks, you don't need such huge infrastructure. I've seen WP site operators move to Cloudflare because they had no caching in place, let alone a static site.
If you want better connectivity in remote places where our optic fiber overlords haven't invested yet, P2P technology has much better guarantees than a CDN (content-addressing, no SPOF). IPFS/dat/Freenet/Bittorrent... even multicast can be used for spreading content far and wide.
Why do sysadmins want/use CDNs? Can't we find better solutions? Solutions that are more respectful to spiders and privacy-minding folks with NoScript and/or Tor Browser?
Speaking for myself here, I don't see how people can use the web without javascript. As for Tor, you're routing other people's traffic while they route yours, so I can understand how such connections would be blocked given that blocking IPs is still a method for mitigating security issues, and you can't determine the IP of a Tor browser.
I prefer tech that I can use both at work and on hobby projects at home.
To that end I've only used cloudflare and netlify. The others have too much friction to try out. I expect I would get experience on the job if necessary.
Fair point. Maybe Fastly is more akin to Akamai given it seems to be more enterprise-y. By market cap, Cloudflare is 26 billion, Akamai is 18, and Fastly is 6.
Fastly's free offering gives you "$50 worth of traffic" whereas Cloudflare has a perpetually free option. And for Akamai you have to apply for a free trial.
Akamai is balls deep in video streaming, which is probably the most bandwidth/traffic intense thing for a CDN to dabble with. My guess is that CF has much more diverse traffic. Hence the fallout from an interruption would be quite different.
Not quite, Akamai is more large corp centric (they don't serve average Joe) besides that they do also security. If it went down you would get all of sudden e.g. a lot of DDOS possible.
That doesn't take away their embarrassment. It's mean how many websites rely on fastly. Twitter hasn't been loading emojis in a while, and I believe it's for the same reason.
We use Fastly (and our site is down too) but I asked them about this a couple of years ago.
It is deliberate.
They said it was so they can tell if it is their Varnish service or the customer's Varnish service that is down
Fastly modified the Varnish error to ensure that it is known if the error is returned by Fastly's Varnish or by the origin's Varnish should the customer run their own Varnish on the origin.
Someone (I can't unfortunately due to IP block) needs to change that. The part about the spelling is false, apparently [1] it's an intentional change by Fastly so that they can tell if it's their own Varnish or a customer's Varnish that is throwing an error.
Cloudfront, by Amazon's own admission, specialises in high bandwidth delivery (ie huge videos). Fastly has consistently better performance as a small object cache, which makes it the choice for web assets
I imagine it works well for the whole business that they allow product teams to use the best cloud tools for the job rather than requiring them to use AWS for everything. If AWS is forced to compete even for Amazon.com's custom, that should make the whole company more resilient to long term technical stagnation.
really, m.media-amazon.com seems to have a very short TTL (showing 37 seconds right now) and has been weighted to cloudfront now.
Amazon is also known to use Akamai. Sure, Amazon relies heavily on AWS, but why should it surprise anyone that a retail website obsessed with instant loading of pages decides to use non-AWS CDNs if the performance is better.
Even if CloudFront became the default, I'm certain amazon.com would keep contracts with fastly and akamai just so they can weight traffic away from CloudFront in an outage.
Their CSS and JS were down for a few minutes. I was able to login to Amazon but the entire site was in Times New Roman, but was fixed a few minutes later
Good thing we use Cloudfront and Cloudflare where I work.
> Statuspage Automation updated third-party component Spreedly Core from Operational to Major Outage.
> Statuspage Automation updated third-party component Filestack API from Operational to Degraded Performance.
Oh, right. :-D
Don't get me wrong, I love the proliferation of APIs and easily-integrated services over the past 20 years. We're all one interdependent family, for better and for worse.
Yikes seeing just a "connection failure" on Paypal is something else.
edit: PayPal looks be back up at least in US East but when I turn off my VPN and access from Asia I get "Fastly error: unknown domain: www.paypal.com."
> Monitoring
The issue has been identified and a fix has been applied. Customers may experience increased origin load as global services return.
Posted 4 minutes ago. Jun 08, 2021 - 10:57 UTC
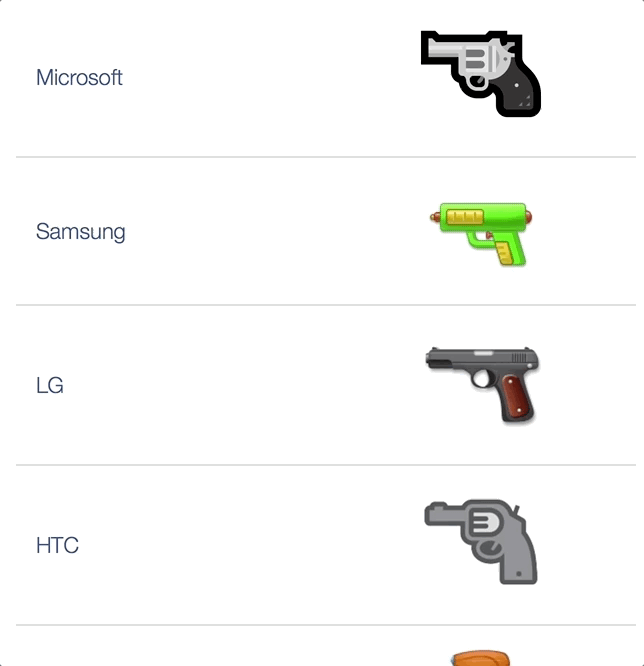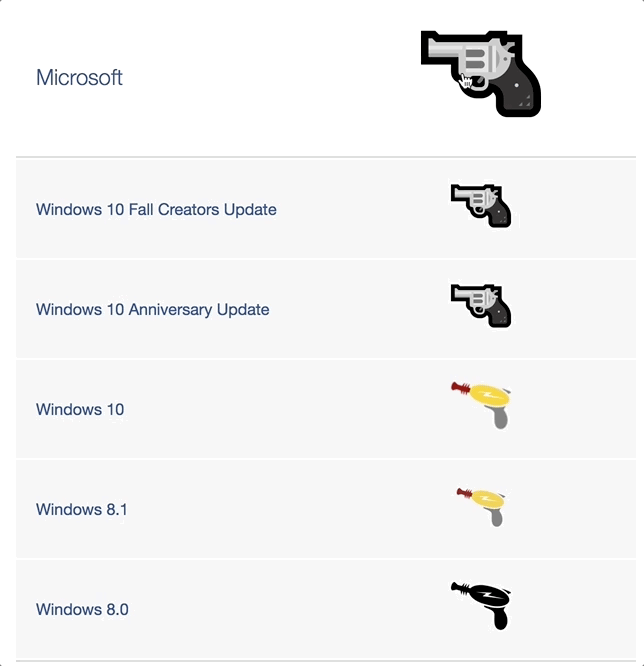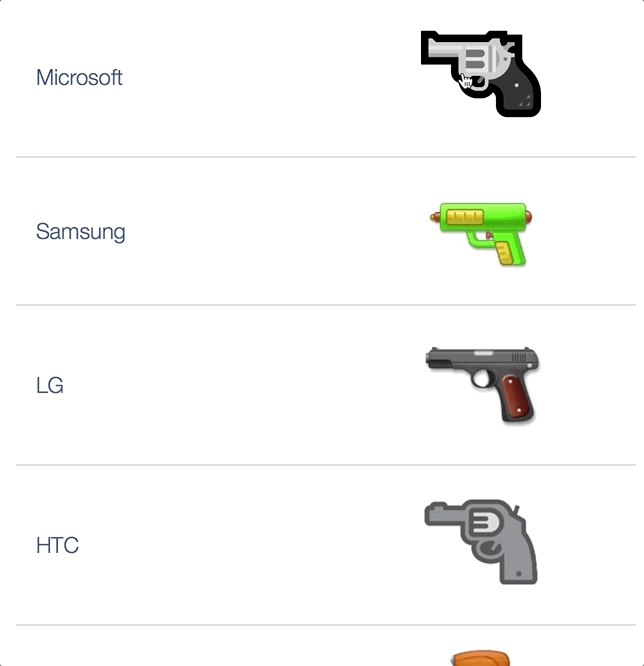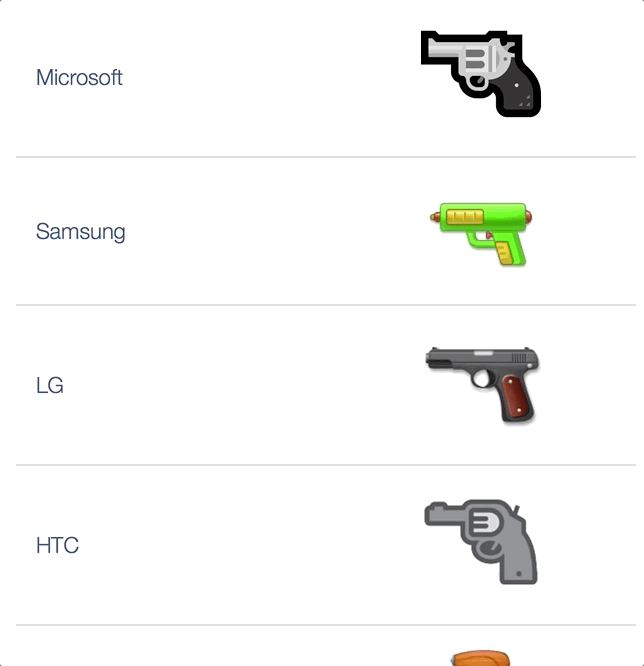
Vendors don’t even agree on whether the :gun: is a revolver or an automatic or space ray guns or even water guns, btw it’s an 1911 in original DoCoMo emojis
Sure, that's a benefit of emojis being semantic. If you want 'SFW' emojis, you can get them. Converting them to images makes that impossible. And uses vastly more bandwidth, makes them impossible to copy+paste, probably has accessibility issues, etc.
Same reason why Gmail uses their own emojis rather than the system ones — (as said above) branding. When you send a tweet, Twitter wants it to look identical across all devices. The classic native UI vs cross-platform UI debate in a nutshell.
Cool, so instead of actually serving text, they could also just serve up little SVGs for each letter. Because god forbid the recipient chooses a different font than Gmail!
Twitter is a media between people. Removing emoji representation differences on user devices is a way to hopefully reduce misunderstandings between users.
What's far worse than half of the internet being down was that Hacker News also had problems. If I waited long enough on a comments page I got an error message. I don't quite understand what happened there. The communication between my system and HN must have been working otherwise I would never have gotten an error message, so it must have been some internal HN problem. But since HN should only need its own internal "database" to generate comment pages, I don't understand why it should be impacted by the Fastly problems.
I could not tell from the fastly status page. What caused the fault? Could anyone point to any past stories which may be of similar nature other than DDos?
Please don't call it a lie. It means that they knowingly presented something they knew to be false as the truth. So far I have seen no evidence to support that.
It is definitely a lie, but it's the same lie sold by all cloud offerings. Can you name a single cloud/CDN operator without downtimes?
It's normal to have downtimes but they are usually scheduled and quick (think <10 minutes per month for rebooting and/or hardware parts replacement). I'm pretty sure most non-profit hosts like disroot.org or globenet.org have similar or better 9's than all these fancy cloud services.
How is having a large chunk of the internet using the same CDN provider not "centralizing"? It's not a hard monopoly obviously but still it meets the definition of centralization.
how is private companies choosing to use a common supplier in a competitive market centralization? monopolies are not centralization either. you need to read a better book.
How is a market competitive when there's a quasi-monopoly on infrastructure? When public money is used to irrigate the same corporations with huge $$$, while non-profit network operators are left to rot?
it's centralization because they all use the same provider. Why do you care about incentives here? The result is the same, just like capitalism and free market tend to monopolies in the long run.
For what its worth, I'm having these problems also with cnn.com, reddit and many others, however when I switch away from WiFi to use my cell provider network, they work fine.
If you aren't prepared to do CDN changes on a whim when something like this happens, it's often better to wait for the problem to be resolved instead of making things worse for yourself due to misconfigurations, revealing your origin IPs, etc.
Can always improve the process for the next outage.
For sure, similar to other industries all changes come after big troubles like this. But would be interesting to heard about how them (paypal) deal with that
Is their anything these big sites could do in this situation, or must they choose between running and maintaining all of their own infra or relying on a single CDN?
If you have absolutely vanilla CDN requirements, you can run multiple CDNs and fail-over or load balance between them using DNS.
Quite a few Fastly customers have more than vanilla requirements though, and may have a lot of business logic performed within the CDN itself. That Fastly is "just Varnish" and you can perform powerful traffic manipulation is one of it's main selling points.
I suppose it’s still a bad experience for the user if some % of attempts to connect fail or if some % of scripts/styles/images fail to load. So I think that means dns information about failures needs to somehow be propagated quickly. Not sure how well that works in practice.
Use two CDNs and DNS providers for redundancy. Gets expensive, but at scale, probably doesn't make a huge difference. More complexity for the site operators to manage, however.
That's the problem with these black-box cloud offerings, that you can never know what will work (or not) and from where. You get semi-random, pseudo-localized outages that are not accounted for in all the 9's of availability.
With a standard TCP/UDP session, it mostly just works or doesn't and you can get a proper traceroute to know what's up. With these fancy CDNs, there's a whole new can of worms to deal with and from a client's perspective you have no clue what's happening because it's all taking place in their private network space where we have no "looking glass".
Same here in central Poland (Łódź area), no problem with any of linked websites.
edit: My whole Twitter timeline is full of posts saying "Twitter outage? what outage?". Same on Reddit and Twitch chat, feels like for a short time I was invited into some exclusive circle lmao. StackOverflow and other StackExchange sites also work so I can look stuff up for you.
>At the core of Fastly is Varnish, an open source web accelerator that’s designed for high-performance content delivery. Varnish is the key to being able to accelerate dynamic content, APIs, and logic at the edge.
I think Fastly is the one having problems (they happen to use varnish but I haven't seen anything which says varnish is the root cause) - so all sites using it are down.
It's OK though, because large swathes of this discussion seem to have turned HN into reddit, at least temporarily. Normal service will no doubt resume in due course.
Edit: I didn’t mean anything negative here! Just slightly shocked that as the UK is opening up under 30 vaccinations, the US is struggling to find any more willing takers. It’s really probably a sign that there’s fewer anti-vaxxers in the UK more than anything. And that universal healthcare is more efficient at distribution than an inherently for profit system. I don’t know, but I just didn’t realize it was so different in the UK
I think this may be because we've had much higher uptake as far as I know, so getting down the age ranges has been slower (by which I mean, yes, maybe the US has made it available to all adults, but how many (as a proportion) have taken it up)
I have seen the argument made that one of the reasons for high vaccine confidence in the UK is as a result of Andrew Wakefield's MMR fraud, which was perhaps debunked more effectively in the UK than the US.
US and UK have very similar vaccination rates despite the US being open to more age ranges. This indicates that a higher percentage of eligible people have gotten the vaccine in the UK, and the US has somewhat hit a wall in terms of vaccinations (though there is the concern that the rates will slow down in the UK also).
I must admit, it has been strange seeing my US peers getting the vaccine months before I can in the UK, but I guess I take comfort knowing that both countries are still doing pretty well!
Fascinating. So those rates are including only ages 30+, which means that once it’s unrestricted the UK should have a very high vaccination rate while ~15-25% of the US will still remain unvaccinated entirely by choice. Wow. So you’re absolutely right, the UK is in reality far far ahead and the US is completely broken as far as public health is concerned because of willing ignorance.
Yeah so it's been mentioned in the comments already, but to everyone in Fastly right now: I feel for you. Something like this must be insanely stressful, and not just during the outage. There will be (should be) a massive post-mortem. People will be losing sleep over this for days, weeks, months.
:(
Edit: There seems to be a major empathy outage in this thread. Disgusted but not surprised, unfortunately.
Meh. Losing sleep sounds like an over-reaction. No system is foolproof. Of course Fastly should do what they can to prevent downtime, but it's still expected that they will go down.
I would blame anyone who claimed otherwise or couldn't deal with it while not having a fallback.
I hear that you're suggesting that those involved shouldnt feel bad because its a systemic / just a job / etc. But the reality is that incidents like this can be very traumatic for those involved and thats not something they can control. If it was that simple to manage, depression and anxiety would not be a thing.
Think its best to show a large amount of support and empathy for the individuals having a really bad day today, and how awful they may feel. Some will probably end up reading this thread (I know I would).
And of course, still hold Fastly the business accountable for their response (but objectively, once we understand what the root cause was, and the long term solution).
I don't see how it's so traumatic for the engineers involved, unless the company culture in Fastly is really awful and there are punitive repercussions, or attempts to pin responsbility on individuals rather than systems, which I doubt.
Many here have been responsible for web service outages albeit on much smaller scales, and in my experience it feels awful while it's happening but you quickly forget about it because so does everyone else.
I guess it very much depends on your personality. I screwed up a a not very important project for a client 4 years ago while working at a different company, and I still feel bad when I think about it, despite the fact that my company had my back through the entire process and literally everybody involved has moved on and probably forgotten about it.
I wanted to show support to the engineers in the sense that I don't think you should encourage a working culture where you have "massive post-mortems" and expect people to feel bad for extended periods of time over simple mistakes. By not making a big deal out of it, you can also support your staff.
But I think our disagreement mainly stems from how we interpreted the parent comment. I thought it was very double, at one hand claiming to show support, at the other hand emphasizing how big of a catastrophy this was.
I just wanted to say that I think it most likely was a completely natural mistake, only exerbarated by the scale of the company, and that while you should take some action to prevent it in the future, you should not spend so much time dwelling on it. Shit happens, it's fine.
I think the government websites being down (UK ones for example) are the bigger issue. Reddit/Stackoverflow etc being down isn't that big of a deal imo.
Imagine losing sleep over a corporate problem where you're just the next Joe Engineer, to be fired the second you're not needed. Have some perspective people.
I'm confused, why isn't being fired something to lose sleep over in your eyes?
I get that you're implying that the job itself is not worth that much concern, but it seems you're ignoring that jobs bring in income, pay your mortgage, etc.
People rarely get fired for outages. The comment you are replying to is saying that engineers shouldn’t stress out over an outage that only impacts a corporation.
It’s a commentary on work / life balance and the all-too-common phenomenon of employees sacrificing for a company (in this case, feeling such personal stress that they would lose sleep) and contrasting it with the fact that most employers will fire you without a second thought if it’s what’s best for the business (they won’t lose any sleep).
It’s a critique of the asymmetry that often exists and is frequently exploited by companies. This is often seen in statements like, “we are one big family so put in a few more hours for this launch” coupled with announcements like, “profit projections didn’t meet expectations so we are downsizing 5% of the work force.” You are family when they need you to work hard, and an expendable free market agent when your continued employment might risk hitting the quarterly goal.
It is, of course, reasonable to lose sleep if you think your employment is in jeopardy. Very few companies, especially in the competitive SV market are firing engineers because of a single outage, even a bad one, because you just paid a bunch of money to train those engineers how to see this coming and fix it.
I have worked for one of their competitors (I'm not saying which) for quite a while. I've indirectly caused multiple outages that were maybe 1% this bad before, that didn't make the news only due to luck. Code that I owned (but did not write) was once a key cause of a severe outage that did make the news, and it would have been worse if I weren't coincidentally halfway through replacing that code with something more modern. I also had to do some very rapid work on internal failsafes around the time of the infamous Mirai botnet, to minimize service degradation in case it was pointed at us.
It sucks. Working on CDN reliability is like working on wastewater management: the public forgets you exist until something breaks, when they start asking why you weren't doing your job. Fortunately, internal people at least seem to get it -- I hope this is the same as Fastly.
Everyone's got responsibilities and aspirations. To be fair, I was thinking more of the jobbing engineer who's going to face anxiety about losing their job over this, but it extends to all levels. Having a fat bank balance helps get through periods without employment, but it's not just about money. There's anxiety, shame, embarrassment, the whole gamut. Going through a major incident at work is a shitty experience.
Well, not much, I mean all our competitors are also using Fastly. I would be more worried if we were the only one using Fastly and everybody else was fine. But as we are all in the same boat, we lose the same :-)
I feel for the Fastly workers, who managers are probably currently harassing to get things back online. I certainly don't feel any sympathy for Fastly administrators/managers who make business out of exploiting other people.
Call me old fashioned but the latest trend of showing "empathy" for a serious incident, then proceeding to dance around the aftermath of it, whilst people give themselves a pat on back in a retro/post-mortem, isn't the way to do it.
People need to be blamed, and responsibility for actions taken (without covering asses)
The point isn't to dance around the incident, but to not blame people. You can blame systems, design, engineering culture, processes, but don't blame people. Even if someone accidentally pressed the 'destroy prod' button, that's not the fault of that person, it's the fault of that button existing and being accessible in the first place.
I have no empathy for Fastly-the-company. I hate the fact that the Internet is centralized around CDNs. I wish this idea of 'but we _must_ run a CDN for our 1QPM blog!' would die in a fire. But I can still empathize with the Fastly engineers handling this shitstorm right now.
> I disagree. People implemented those systems, so if you are correct that it is the systems fault, then it is also a persons fault.
How do you make sure that mistakes don't happen, then? Do you blame and fire people who make mistakes, and hope that the next person put in the same spot doesn't make a mistake? Or do you figure out what caused that person to make the mistake and ensure there are processes in place so that next time this is less likely to happen?
Extrinsic motivators like 'we will give you a bonus' or 'we will fire you' are surprisingly bad at getting people to not fuck things up.
Lets hope you don't ever go into management. You clearly have no idea how to motivate and retain people or have any insight on how hard it is to hire good people to begin with. And no, I'm pretty certain this is not how Netflix's culture is.
Riiiight... Anyways, you kept complaining of being downvoted, here's a clue: you're being an ass and no one likes you or what you have to say because you're wrong. So go scurry back to reddit where you belong troll...
> you're being an ass and no one likes you or what you have to say because you're wrong. So go scurry back to reddit where you belong troll...
Okay? some proof please? This is not far off from a baseless character attack which isn't really effective when trying to convince me about your point on you knowing about Netflix's culture.
If you really want a proper answer, the truth is, unfortunately for you I am in management (previously was an engineer) and have always known Netflix to have a stellar performance oriented (and fear driven) culture, their playbook operates like a sports team. Not for everyone, but that's the point and it works for them.
Maybe you should look inward to yourself if you're so vexed with me to call me silly names, that you can't handle the truth or the culture about why some companies like Netflix adopts this.
You think downvotes and character attacks present as a good argument? Doesn't count as proof IMO if there isn't a valid argument presented, you're going to have to do a lot better than that.
And back to the main point, So I assume you agree that Netflix did go completely down the other day then right? It seems according to you that you know better of Netflix's management culture.
> I'm pretty certain this is not how Netflix's culture is.
Would you be willing to share your expert insight of this if you know better then?
I'm not arguing Netflix, its mostly your attitude towards management and engineering culture. Basically your reply to the user "q3k". "Extrinsic motivators like 'we will give you a bonus' or 'we will fire you' are surprisingly bad at getting people to not fuck things up". You don't fire people just because they made a mistake. You find out what caused it, how to prevent it in the future, and you move on. That's what blameless post-mortems are about. No one is perfect and if you really are a manager that expects perfection, you really just suck as a person.
But now getting back to Netflix, they have post-mortems and they don't fire people willy-nilly over mistakes. Sure it's not hugops (a term I don't care for either), but they don't just up and fire people over a mistake. I never said anything about netflix going up or down on that day, but they also have problems just like everyone else. Their SLA is not 100% uptime and neither is Fastly.
In closing, you are being a pedantic little bitch who wants to argue minutia and I'm done with your trolling. I'm done responding to you, feel free to have the last reply as I really don't care anymore.
v2. "The issue was caused by a previously unidentified pathway that caused a feedback loop and overloaded our servers in a cascading fashion (or whatever). We have implemented a fix for this and updated our testing and deployment processes to stop similar cascades."
Which solves the problem long term?
As an architect making product choices, v2 wins every time.
(With the caveat that if the cause was something that reveals a fundamental problem with the larger processes/professionalism/culture of the company, especially to do with security concerns, then I'm not buying that product and migrating away if we already use it.
If an employee does something actively malicious, you should absolute remove them. This is very rare though - incompetence /broken systems is much more likely.
Otherwise you develop internal process that's entirely scar tissue, and only stops your teams doing their jobs.
I feel it is somewhat obvious and goes without saying that malicious action results in personal responsibility & repercussions. However I don't have any evidence or past experience that malicious action by an internal employee is a likely scenario for most outages. It may well occur but most examples I've heard of seem apocryphal.
The scar tissue: this is where good choices come in because it's certainly not a rule that a change as a result of an incident review is an impediment to work. These definitely occur, and sometimes linger after the root cause is phased out. But best practices often reduce cognitive & process overheads.
A rough example is that there are still people out there FTPing code to servers, having to manually select which files from a directory to upload. Replacing this error prone process with a deployment pipeline leads to a massive reduction in the likelihood of errors and will actually speed up the deployment process. It's all about making the right choices, not knee-jerk protections, and sometimes the choice is to leave things as they are.
> People must be held accountable to have good incentives to reduce such outtages in the future.
Holding specific people "accountable" for outages doesn't incentivize reducing outages; it incentivizes not getting caught for having caused the outage.
As a result, post-mortems turn into finger-pointing games instead of finding and resolving the root cause of the issue, which costs the company more money in the long run when a political scapegoat is found but the actual bug in the code is not.
Loss of trust in a service provider and the afterwards loss of business is quite an incentive. Having someone drawn and quartered just provides an incentive to scapegoat.
Don't blame an IC for introducing a bug or misconfiguration that led to the outage.
Do consider blaming (and firing!) management if, during the postmortem, it turns out that it was in the way of fixing systemic problems.
Ultimately, rule #1 should be: don't blame somebody unless malice or gross negligence is proven. Rule #2 should be the assumption that ICs will not have done either. Rule #3 is that sometimes, individual responsibility is required.
Do a post-mortem, work out root causes, work as a unit to ensure this doesn't happen again.
Obviously if there are levels of gross negligence or misconduct discovered during post-mortem, that will need to be dealt with accordingly, but coming into this with an attitude of "we must find someone to blame and incur repercussions" isn't healthy at all.
> Do a post-mortem, work out root causes, work as a unit to ensure this doesn't happen again.
And if this happens again? They advertised they had failover and mitigations for this in the RAREST of cases:
> Notices will be posted here when we re-route traffic, upgrade hardware, or in the extremely rare case our network isn’t serving traffic. - status.fastly.com
The extremely rare case happened for an hour, which is a very long time in internet time.
I think what you said is exactly why people have different opinions on this topic: what counts as "gross negligence" and what doesn't? Different people draw lines at different places.
There's, to me, no obvious clear cut line. But here are some indicators that make me consider someone was being grossly negligent and/or even malicious:
- ignoring warnings
- acting against known-to-them best practices
- repeating a previous mistake
But, again, these are just indicators, not a checklist.
Interestingly, any of these can happen also due to stress, burnout and generally broken company/team culture. Including something like a CYA culture where if they don't do something fast, they will be blamed for it, and thus they need to move fast and break things.
The problem is a blame culture ensures the near-misses are never reported. Air safety discovered this many years back - a no-blame culture ensures anything safety-related can be reported without fear of repercussions. This allows you to discover near misses due to human error and ensure that the overall system gains resilience over time. If you blame people for mistakes, they cover the non-obvious ones up, and so you cannot protect against similar ones in future, so your reliability/safety ends up much lower in the long run. It's all about evolving a system that is resilient to human error - we will make mistakes, but the system overall should catch them before they become catastrophies. In air travel now, the remaining errors almost never have a single simple cause, except in airlines/countries that don't have an effective safety reporting culture.
I recommend reading about "blameless postmortems" [1]. Our natural tendency is to look for who is responsible for an incident and point the finger of blame. Over time this leads to a cover-your-ass culture, whether you like it or not. Therefore such a tendency needs to be actively fought against to keep the focus on quality engineering and not politics.
"An atmosphere of blame risks creating a culture in which incidents and issues are swept under the rug, leading to greater risk for the organization."
The best way (in a team), to tackle mistakes, is to ensure the process in place corrects these mistakes. The only way to do that, is a post-mortem/learning from the mistake. If you blame it on some engineer who did it, that guy will eventually be replaced by some other guy, who may make the same mistake.
You also need to be proactive about other possible failure modes. Avoiding a culture of blame may or may not help. There needs to be a strong incentive for the organization to expend the resources to do so, and a mere "oops my bad" doesn't provide that without SLAs with teeth.
We need to learn from our, and other mistakes, or else we keep repeating them. Nothing "old fashioned" about that.
And we, especially companies, typically only learn if there is something at stake. Stock-price, a job, customers, liability etc.
(Call me old fashioned, but what I learned from it, having no stake in the game, is we are truly demolishing the resilient, decentralised nature of the internet; or already have done so)
I don't agree about the blame, but I do also find the empathy cringeworthy. Something's broken; someone's job is to fix it; they'll fix it; it will work again. /shrug/
Post-mortems make far more interesting submissions IMO, but I suppose people up-vote 'yes down for me too'.
the attitude that "people need to be blamed" will never improve reliability in the long run. people come and go; systems and processes endure. blaming people is the best way to avoid making durable improvements to systems and processes.
Doctors that make too many mistakes resulting in too high of payouts can't get individual malpractice insurance. Doctors that can't get individual malpractice insurance go to hospitals. Hospitals that hire too many doctors that make too many mistakes can't get hospital level policy. Hospital has to fire those doctors. That's how the system adjusts.
I hear you, but I just want to point out that this rarely happens anywhere else. It's great if tech (and people in general) hold themselves to progressively higher standards than what is out there already, but I don't think tech needs to be that much better, I'd settle for just doing a good honest retro (without throwing anyone under the bus, and without covering their asses)
A good leader will take the hit (and the repercussions) for their underlings, compensate customers where compensation can make it better (and offer to make it easy to use fallbacks if this happens again) -- and internally fix the problem so it can't happen again, without throwing anyone to the dogs.
Scapegoating in those situations happens more often than not. In an operations team all problems are systemic - having to do with decision makers throughout the process, sometimes acting on perverse incentives set up by others. Blame then gets diluted but still tends to fall upon the organization responsible rather than an individual, which is where it should be. Gross negligence is not so cut and dry.
> People need to be blamed, and responsibility for actions taken (without covering asses)
This. When people talk about "HugOps", "empathy" and all that when a worldwide incident affecting a huge amount of time critical customers (e.g. trading, hft, cargo, food delivery, etc.) is happening for an hour, it has catastrophic consequences.
I hope the engineers also understand the other side and why we are paying huge sums of cash for their service.
It's empathy towards people managing the incident, not towards the company. It's a sign of solidarity from SRE to SRE, not a sign of solidarity with a company.
Well, while engineers are getting paid $100K/yr to post #HugOps, I know someone in HFT and their dashboard uses the Fastly service, so this has had a huge impact on them for sure.
Flag and downvote all you want, you know this is true.
I suspect you'll have trouble convincing a forum of primarily engineers that a high frequency trader is more worthy of sympathy than an engineer. They're both pretty privileged jobs and HFT is not known for having tons of benefits to society
> I suspect you'll have trouble convincing a forum of primarily engineers that a high frequency trader is more worthy of sympathy than an engineer.
Engineers are paid because their companies have customers. The it is pure madness that #hugops is the thing. I sincerely hope that Fastly's customers wack it $$ wise so hard that it actually affects #hugops engineering culture.
> I suspect you'll have trouble convincing a forum of primarily engineers that a high frequency trader is more worthy of sympathy than an engineer.
At least HFT traders don't get paid to spy on their own customers with trackers littered everywhere, I find that very unethical that engineers get paid to even do that sort of thing, and every damn website has these trackers because engineers put them there.
> They're both pretty privileged jobs and HFT is not known for having tons of benefits to society
So HFT firms don't have their own foundations and grants to give to charities and organisations then?
And ignore the pre-agreed SLA targets and compensation for not meeting those targets that's in the contract they signed right? If you're going to say you're losing $X/minute of downtime, then either deal with it, architect around it, or negotiate the necessary SLA and compensation.
The fault is theirs and they have said that they have failover, this worldwide outage caused by them just goes to show you that Fastly does not actually have a failover system in place.
> "Fastly’s network has built-in redundancies and automatic failover routing to ensure optimal performance and uptime." - status.fastly.com
Even their status page was down. Very embarrassing, Fastly did not work as advertised and mislead its customers.
Edit: Offended flaggers circling around silencing misled Fastly customers. How pathetic.
Even when they said this was a rare [0] case, they knew this case should be handled, but didn't handle it.
> or in the extremely rare case our network isn’t serving traffic.
reports also came in that this was a service configuration[1] issue, so not only there is no failover system, not even any validation automation was in place that could have prevented this.
So why didn't the 'automatic failover' kick in during the outage? Where was it then? I don't see anything about 're-routing traffic' anywhere in the status page [0]
We don't know, but the usual scenarios would be "issue impacts failover mechanism too", "failover mechanism overloads other system components leading to cascading failure" or "something causes failover mechanism to to think all is fine".
So, the rarest of cases (our network isn’t serving traffic) just happened right now, and their failover system just took a snooze then, but 'it exists apparently' according to you.
Tell that the huge clients that lost sales because of this, and all you have to say is: "wE DoN'T kNoW..."
Not the point. They were also told that a failover system would kick in and re-route traffic had there been any issues, but this was where to be seen.
A worldwide outage happened that affected almost all locations and everybody, so actually SLA is meaningless in this case. Where was the extra redundancy? Where was the failover system? Why was other companies indirectly affected?
As far as I know Fastly's status page was even down during the outage, the fact that the best answer to this 'is we don't know' tells you everything you need to know. Maybe stop victim blaming this situation and focus on the main culprit.
Just assuming things will always work because the marketing copy said so is recipe for disaster. It's hoping that things never go wrong, and when they inevitably do, being caught pants down.
Everything fails sometimes. You must know how much your SaaS provider contractually promises, ensure that any SLA breach is something financially acceptable for you, and ensure that you can handle failure time within SLA.
You've just witnessed almost the entire internet break because of a catastrophic cascading outage that affected lots of huge companies, since third party services used and trusted Fastly.
Shopify stores couldn't accept payments on their websites, Coinbase Retail/Pro transactions and trading apps failed to load, and delivery apps stopped loading all of a sudden. These are just a few that this outage has caused, and now you are trying to blame this onto me for not checking their SLA when millions were indirectly affected by this?
Fastly offered a product, their main product which is a CDN which took down lots of websites. I don't care if everything fails sometimes. There are sites that should NOT go down because of this configuration issue which they messed up.
You can say you don't care for reality, but it's not going to help you have better systems.
> There are sites that should NOT go down
Then they surely either engineered their system to not 100% rely on Fastly or negotiated appropriate terms with Fastly (Or decided Fastly going down was an acceptable business risk, which it is for nearly everybody). Everything else would be negligent, and surely nobody would be negligent when operating a site that "should NOT go down"?
> You can say you don't care for reality, but it's not going to help you have better systems.
No where in my sentence I said this so quit the strawman argument.
I know a client using a service that has 100% uptime for the year, that also relies on huge clients, I don't understand why Fastly can't guarantee at the very least and a failover system to counteract this, but clearly didn't work. (or even existed)
> (Or decided Fastly going down was an acceptable business risk, which it is for nearly everybody).
Then why did this cascade to almost everybody even indirectly? Surely their advertised failover system would have prevented this from prolonging further but lasted longer than it should have.
I don't think a store, exchange or trading desk not accepting payments from people for an hour is acceptable at all.
> You've just witnessed almost the entire internet break because of a catastrophic cascading outage that affected lots of huge companies, since third party services used and trusted Fastly.
Blame the companies that relied on Fastly being up 100% of the time, even though Fastly explicitly states that they might be down any number of hours, and they will even give you money back for that [1]. If they did offer 100% SLA, it would probably be out of budget for most users, as that kind of systems are prohibitively expensive to run.
Depending on a single CDN like Fastly is building an SPOF into your product. It is not less of a design blunder that whatever Fastly did internally to have an outage. If Shopify lost millions because of a short, simple third-party outage they have at least as much of a high-priority postmortem to write and issues to address as Fastly.
If companyA got affected by this, then either:
1- Its companyA's fault for not having a contingency plan
or
2- Its companyA's accepted risk that this might happen.
We understand you're upset and passionate about this, perhaps now when more information has been published you understand better the circumstances that caused this problem.
True. But the vast majority of use goes via "WWW".
For example email - the other big "internet-user" is technically not part of the WWW, but most (? I don't have any stats, just a guess) of our mailclients run on the WWW, nonetheless.
I think that's the point the other person was making: The Internet is still fine, regardless of whether or not the content gets delivered.
There are roads (or shall I say tubes?). There are cars and busses on the road. Over time, almost everyone has migrated to just a few bus companies. One of them suffers a complete collapse for a few hours. Yes, this means chaos when it comes to transporting people. But the roads are just fine.
This doesn't mean that the situation is fine and that people aren't affected. But it would be entirely different if the roads had been washed away or something.
I'm not sure what the native clients for Netflix and Spotify actually run, but I use their WWW clients mostly. Making most of my internet bits&bytes go over the WWW.
It’s the equivalent to JIT manufacturing. Cheaper when everything is going fine, and devastating when it’s not. And then when everything goes down at once there’s not enough advantage to being the only one still up.
Interestingly, server side rendered pages worked well during the outage. Most of the issues were caused by sites that are relying too much on Javascript.
The Web (World Wide Web) build atop of the Internet, is not impervious.
ps. "The Internet was build to survive attacks" is not true. It's a myth made popular by Robert Cringely in the early 1990s. The Arpanet was simply a protocol for mainframes used by computer scientists to connect. The Internet is relatively resilient against attacks, but that was not the "whole idea". It was not in the design at all.
Bob Taylor: “In February of 1966 I initiated the ARPAnet project. I was Director of ARPA‘s Information Processing Techniques Office (IPTO) from late ‚65 to late ‚69. There were only two people involved in the decision to launch the ARPAnet: my boss, the Director of ARPA Charles Herzfeld, and me. The creation of the ARPAnet was not motivated by considerations of war. The ARPAnet was created to enable folks with common interests to connect with one another through interactive computing even when widely separated by geography”.
Vint Cerf says the same about invention if TCP/IP transport protocol.
BGP has its problems (that time centurylink blackholed traffic but wouldn't drop their connections, bgp hijacks etc), but it's not centralised in single (or very few) points of failure
Oddly their homepage rendering an error was a more accurate description of the problem than "investigating potential impact to performance with our CDN"
> Fastly’s network has built-in redundancies and automatic failover routing to ensure optimal performance and uptime. But when a network issue does arise, we think our customers deserve clear, transparent communication so they can maintain trust in our service and our team.
I didn't know so many sites were depending on Fastly. Stack Overflow, GitHub, reddit, .... Even pip is unavailable. My development workflow is completely janked up. It is a bit scary that we are putting too many eggs in one basket.
Bit pedantic, but it's PyPI that Fastly gives services to, not pip (and PyPI that's down, not pip). The two are only loosely related – pip is a piece of software.
You would think sites like Github and key government sites would at least have a fall back at the ready. It reasonable to use a CDN like Fastly, but having a single point of failure seems silly if you're the BBC or Gov UK. Although, it does seem BBC managed to get back up and running pretty quick so perhaps they were prepared for this.
Gov.UK is back up too. They have a mandate from government to be able to provide emergency communications so I expect they did have a backup and have managed to switch over, but just took 30 mins to do so.
Gov.UK is supposed to be a bit like BBC 1 or Radio 1 – in a national emergency they can be taken over to disseminate critical information, like if there was a nuclear attack launched on the UK.
For sites of any complexity with any dynamic content having CDN redundancy is akin to being multi-cloud -- it is not worth the effort.
A lot of dynamic sites use Fastly for its programmatic edge control and a near immediate ( ~1s-4s, typically around 2 ) global cache invalidation for any tagged objects with a single call to the tag. That feature alone simplifies backend logic significantly. To make this feature portable to CDNs that do not support it and provide only regular cache invalidation requires a complicated workflow setup which significantly increases the cache bust time, which in turn removes all the advantages of the treat dynamic content as static and cache bust on write approach.
>> For sites of any complexity with any dynamic content having CDN redundancy is akin to being multi-cloud — it is not worth the effort.
I proposed and lead our multi-CDN project at Pinterest for both static and dynamic content and I can tell you, many many times over, it has been well worth the effort. Everybody should do this if not only for contract negotiating leverage.
Cache invalidation is fast enough on all CDNs now for most use cases (yes, including Akamai). But realistically, most sites (Pinterest included) are not using clever cache invalidation for dynamic content because it’s not worth the integration effort (and it’s very difficult to abstract for large 1k+ engineering teams). Most customers are just using DSAs for the L4/L5 benefits (both security and perf). In that case, it’s not complicated to implement multi-cdn.
I was going to link the appropriate XKCD where organised attackers are panicing as they realise they're dealing with a sysadmin muttering about uptime..
At least that's accurate. "Degraded performance" would imply to me that things are functional, but slow. increased error rates can be anything from "try again" to ":shrug:"
Yeah, I also wrote a bot that chooses to create a status incident with the lowest key neutral message when it detects continued healthcheck fails (outside of maintenance) that steps in if an operator hasn't already created an incident. Maybe they're too busy fixing.
>North America (Ashburn (BWI), Ashburn (DCA), Ashburn (IAD)), Europe (Amsterdam (AMS)), and Asia/Pacific (Hong Kong (HKG), Tokyo (TYO), Singapore (QPG)).
Amazon.com was completely broken here (Europe) and they're back, I was observing from where the assets were loaded from and they switched from EU to NA as a failover. Homework well done.
> "But with small object delivery, like images loading fast on Amazon’s home page, it’s the opposite. Customers will pay for a better level of performance and in this case, Fastly clearly outperformed Amazon’s own CDN CloudFront. This isn’t too surprising since CloudFront’s strength isn’t web performance, or even live streaming, but rather on-demand delivery of video and downloads."
Amazon (like a lot of others) use several CDNs for redundancy. You can see from dig that it resolves to combinations of cloudfront, akamai, and (presumably, based on your reported experience) fastly.
You're right, I should've said *partially* back. At least the CSSs now load, but a few products images are still gone. However it was completely broken here before (literally loading just the main HTML).
“This basic architecture is 50 years old, and everyone is online,” Cerf noted in a video interview over Google Hangouts, with a mix of triumph and wonder in his voice. “And the thing is not collapsing.”
The Internet, born as a Pentagon project during the chillier years of the Cold War, has taken such a central role in 21st Century civilian society, culture and business that few pause any longer to appreciate its wonders — except perhaps, as in the past few weeks, when it becomes even more central to our lives.
Unless you're browsing reddit without logging in, you can just set the old reddit theme from your account settings so you don't need to use the old. prefix :)
And if you're browsing on mobile, you need to request a desktop website, otherwise it switches to the new version anyway. Took me so long to figure out, so many annoying attempts to replace www with old in safari, and losing the selection after misclicking.
Seems to be mixed for me, BBC News and Sport works but stuff like Weather, iPlayer (video streaming) and Sounds (audio streaming) have died. I guess the BBC is big enough that different bits of the site run off different solutions (perhaps news and sport are still in spirit running off "news.bbc.co.uk" instead of the main servers?).
This has got to be even bigger than when cloudflare went offline, in terms of big companies affected. Clearly they have way more F500 customers than CF.
The funny part is that it isn't uncommon for sites to depend on both cloudflare and fastly in one way or another, due to buying services from saas companies that also depend on them.
This outage made me realize that github is served over a single IP address (A record) for my point of origin (India). Stackoverflow has 4 A record listing, but all of these belong to fastly.
The internet is designed for redundancy. Wonder why these companies don't have a fail over network. Makes me wonder if cost is factor considering their already massive infra. But a single point of failure ... <confused>.
> The internet is designed for redundancy. Wonder why these companies don't have a fail over network. Makes me wonder if cost is factor considering their already massive infra. But a single point of failure ..
Well, Internet was indeed designed for redundancy, and it worked as intended. A no point in time it failed to make you reach the server it was supposed to make you talk to.
What are failing are all the application protocols that are running on top of the network.
Github's DNS likely will serve up a different IP for github when there is an outage. I can't talk about the details but GitHub and the rest of Microsoft use a global load balancing system that works through DNS.
Would be interesting to know what these fail over patterns are. As DNS takes a while to propagate, I thought DNS records already indicate fail over addresses.
I think only MX records indicate any priority for each additional record returned, for A records theres no indication of which records have priority over others and the usual behavior of authoritative DNS servers is to rotate the order in which records for the same thing are returned, so effectively returning more than one record for the same question results in a distribution of requests to the IPs returned rather than any sort of failover behavior.
In the case of the software Microsoft uses, it monitors endpoints for the websites in question and then changes which IP(s) are returned based on the availability of those endpoints, the geographic region and other factors.
we had that experience when cloudfare was down for sometime lastyear. We now setup a minor own static server as a backup, if at all this happens again. Althgh we hadn't so far had to use it.
StackOverflow and all the StackExchange family of sites are down. I suspect the lost productivity from that will be more costly over the whole economy than potential lost sales via Shopify. People can go back to shopify so those transactions not definitely blocked for ever, any time "lost" due to reference resources being unavailable can't so easily be claimed back.
A very significant amount of people won't go back. It's why the most effective marketing campaign by far is retargeting those people to convince them to come back. Unfortunately that's not possible in this case since you can't track the users as the site is unusable.
> I don't think you understand how ecommerce works ... people won't go back
I was talking about the economy in general, not specific e-commerce sites. People that actually need what they were looking for but don't go back will buy it elsewhere. The money still flows, just somewhere else. And if they don't need the item(s), they'll perhaps use the money for something more useful.
Here is lesson to learn for shopify talented staff. Don't put all your eggs in the same nest. I'm sure they can build something better than that. Hopefully, they will learn from this outage.
Such a huge number of sites. It seems like it's mostly US based sites and Australians are okay. Sending good vibes to whatever poor person is on support right now.
As per report above - most (or all?) of Asia/Pac servers are down.
This incident affects: North America (Ashburn (BWI), Ashburn (DCA), Ashburn (IAD)), Europe (Amsterdam (AMS)), and Asia/Pacific (Hong Kong (HKG), Tokyo (TYO), Singapore (QPG)).
Interesting thought. I had not thought about this before. If there is a cyclic dependency (not saying there is at the moment) how would things play out? Do you just ssh into your own servers to deploy the fix?
I’d love to see a breakdown of what single point of failure causes these worldwide network outages. They even brag about redundancy in their marketing materials. I hope we see a post mortem on this
Stupid question: why didn't sites "just" fail over to their actual servers to handle the traffic, albeit slowly? I guess they won't be sized to handle the load in a lot of cases, and Fastly was responding, so DNS fail over didn't work?
Probably a different answer for each site. I'm not a DNS expert but I think you're right on both counts. Having failover also requires a duplicate CDN architecture at the fallback location, which is an increase of costs in time, money & maintenance for relatively little benefit. Often there's a fair amount of background integration with a CDN, and each function slightly differently, so it's not simply plug & play.
yeah. the dns was up. the problem was the servers weren't able to proxy the traffic. Also, as you say, you'll probably end up bringing down the upstream servers if you just fail open (and not even sure that'd be a possibility with fastly in it's "down" state that we saw).
This is one of the things that excites me about IPFS: in a world of decentralized data storage, yes self-hosting and control over your data is nice and all, but serious resilience to most random infrastructure outages is a much bigger deal.
It's still early days, but I'm hopeful that it can provide a real solution to today's CDN centralization.
> Agree, but currently, ipfs would serve as a fallback, since it's about files.
Isn't a CDN fundamentally all about files too?
> Decentralized/distributed generally has slower network performance. Unless most nodes are high performance, I guess?
There is definitely more work to do here before this is really useful, but it's well within the realm of things that IPFS should be able to do at reasonable performance for production sites in future. Good performance still requires a serious CDN node network similar to traditional CDNs today (to seed your content for day to day use) but with IPFS if that CDN goes down then existing users on your site can _also_ serve the site to other nearby users directly, or other CDNs can serve your site too, etc etc. Your DNS wouldn't be linked to any specific CDN in any way, just to the hash of the content itself, so anybody could serve it.
> Decentralizing the internet works if it financially makes sense for platforms to build such tools.
There's a platform company called Fleek who already do this today: https://fleek.co/hosting/ (no affiliation, and I've never even used the product, just looks cool). Seems to be designed as a Netlify competitor: push code with git and it builds it into static content and then deploys to IPFS.
The benefits don't exist today of course, because no browsers natively support IPFS, so most users can only access the content via an IPFS gateway, which means you're back to fully centralized server infrastructure again... If we can get IPFS support into browsers though then fully decentralized CDN infrastructure for the web is totally possible.
I mean, yes, absolutely, and that works to start with, but I'm willing to bet the overall uptime and performance of a raspberry pi in your living room is quite a bit worse that Fastly's :-).
Apparently they switched from CloudFront after determining Fastly was faster for this use case. CloudFront is focused on large streaming services, not small HTTP resources.
Various bits of GitHub on the Web (committing edits, editing releases) were broken for the same reason. Failure modes of JS-heavy GUIs are interesting.
Some people are claiming online that this is a cyber attack. I contract for the UK Gov and I'm hearing reports that traffic is going through the roof right now.
The fastly monitoring/status page says: "Customers may experience increased origin load as global services return". Which sounds like the increased traffic is to be expected.
I did not realise fastly adoption was so wide-spread. Can anyone more enlightened tell my why or have some resource on which use-cases fastly is superior to other CDNs such as CloudFlare?
This incident affects: Europe (Amsterdam (AMS), Dublin (DUB), Frankfurt (FRA), Frankfurt (HHN), London (LCY)), North America (Ashburn (BWI), Ashburn (DCA), Ashburn (IAD), Ashburn (WDC), Atlanta (FTY), Atlanta (PDK), Boston (BOS), Chicago (ORD), Dallas (DAL), Los Angeles (LAX)), and Asia/Pacific (Hong Kong (HKG), Tokyo (HND), Tokyo (TYO), Singapore (QPG)).
FWIW, Fastly ~8 hours ago (3am UTC) reported another incident: https://status.fastly.com/incidents/1glxxb8sf2zv and deployed a fix—either the fix made it worse or wasn't sufficient to mitigate the problem.
I think the honorable thing would be for them to have a statement easily findable.
So many companies sweep this sort of things under the rug if it’s only customer data that’s been breached. If they can’t sweep they have a high priced PR agency do the communicating.
I do not trust companies who handle things this way.
Holy smokes these Wikipedia writers are quick! I'm sometimes impressed by how fast a page on a super recent happening gets populated with all of the currently known details.
I got that, then a 'Fastly unknown domain' error (on Reddit), then the 503s on multiple sites (I also had an API I use return a 502 then a 500 error, but I don't know what the full response was as it was just a quickly thrown together script I was using).
Anyone want to talk about half the internet going out because one provider couldn’t keep their service up instead of SO jokes and feels for the engineers? the entire internet is like a stack of cards from the protocol to the economic model.
Normally you configure your a record to point at the cdn as the cdn is the thing that gives you multiple points of failure (caches all over the world). Hard to have a fallback to that. Running multiple cdns would be extremely expensive. Cdn caches are kept useful by traffic running through them, so hard to have a backup for that too.
Ah yes, the wonders of centralized internet infrastructure.
Let's use a handful of providers for everything, they said. It will be cheaper, they said. It will be easier to manage, they said.
And it was cheaper, until downtimes began to affect more and more sites when central SPOFs got hit.
And I wonder how much of that need for these centralized SPOFs actually comes from the sheer absurd amount of bloat, ads, code and assets that sites these days "have" to deliver to the customer. I 'member times when pages had 100kb total size, loaded in an instant and were perfectly usable.
What is fastly? Why are a huge number of web sites dependent on them? They are some kind of web host for companies that don’t want to run their own servers/data centers?
Basically the closer the server serving the webpage is to the end user the faster it is for the end user to see and interact with.
But running servers all over the world 1) isn't efficient 2) costs a lot of money.
So a few companies (fastly, cloud flare, akamai) figured, hey, why don't we build a bunch of small data centers all over the world and then provide a distributed way to serve web traffic from it.
It originally was brought about for services like Netflix, but has expanded greatly.
You still host your servers, but a copy of the webpage/media is given to the CDN to serve to customers.
Wouldn’t you build in a failsafe that bypasses Fastly and sends traffic to your own servers in the case of this kind of outage? Or outages are so rare that it’s not worth the trouble?
The number of serious CDN outages in the world are incredibly rare.
In fact, you can probably remember most of them if you were given dates.
Plus, going around the CDN can be very complex (depending on the type of content), very expensive (all of a sudden you have a massive data out network traffic that didn't exist previously), and not guaranteed to work (DNS updates can take longer to get to everyone than the actual CDN outage lasts).
There are places where it is worth it and useful, but for a lot of the sites listed it's not useful.
That's the fallback, but the original stack is not designed with the volume of traffic in mind. So it gets overwhelmed very quickly and makes the website practically unavailable.
> Or outages are so rare that it’s not worth the trouble?
This, I can't remember the last Fastly outage in this dimension, so the time spent on setting up a secondary server serving your assets is probably not really worth it for small-medium companies. Although i'd think otherwise for a company like Shopify.
Many sites do this; Amazon's failed over to their own servers for images for me, it appears. It typically just takes some human intervention, I suspect.
Tangential question, but with services like these, is there a known way to handle failure gracefully? Some way to automatically bypass these services if they are known to be down?
You have to have two separate cdns and use DNS to fail over. The problem is that means paying for a CDN that just sits dormant for the 99.999% of the time that your primary is down.
Alternatively you could use DNS to fail over to the content you host, instead of another CDN. But in many cases that would be the same as an outage since the CDN exists to reduce the impact of all those requests on your infra
None of the ES/NQ/RTY/YM futures contracts took kindly to the outage! This could have had a much wider financial impact. Most seem to have recovered now.
That time to find the issue is always the stressful part. < 1 hour is pretty good for weird stuff, and fortunately the east coast of the US is barely online this early (sorry Europe!).
https://www.bbc.com/news/technology-57399628 is rendering and reporting on the story, but BBC itself was down at the start of the outage, with the same 503 varnish error message.
Presumably the BBC has some kind of fallback in place.
The journalists ought interview their own techies :)
What happens when there is excessive centralization.
I thought that one of the principles behind the Internet is to be able to reroute around failures, but neither these service providers nor their clients ever seem to learn.
I guess in their mind that only applies to packet routing not services. SMH
I was wondering why my Tidal app just stopped mid song and won't connect, after much googling and absolutely no help or even notifications from Tidal explaining there's an issue it seems this outage is the culprit. Bugger.
I got a push notification from the CNN app telling me a bunch of the internet was down due to a cloud provider. I clicked the link only for the app to open to a 503. In hindsight not surprising, but quite amusing.
Their status page keeps claiming that my region, Chicago (ORD), is either Degraded Performance, or Operational. But clearly it's down. Is fuzzing metrics like this how they hit their SLA targets?
It's funny, I searched Twitter for "Ebay down" and the top result was an Ebay tweet with some not coincidentally broken Twitter emoji SVGs (as another person mentioned)...
GitHub?
I had some issues, checked the service status page said no issues, but images were returning a 503.
Maybe they host their service status page elsewhere including using fastly.
I don't think moving to digital is the issue here. The issue is relying on third parties, which can have an issue at any moment, taking down whoever relies on them with them.
A government should not rely on CDNs like that. In fact government websites should not have any traffic going over third parties. When I want to use/view a government website, I should not be subjected to sharing any data with unwanted third parties and the government should not be affected, when some private company makes mistakes or has outages. It is an unacceptable situation.
They can set up their own state-owned CDN, using the same underlying technology. Compared to where they spend all that tax money, some servers and some engineers would be a very cheap investment, in relation to the independence achieved.
We've got Cloudflare sitting in front of our Firebase/GCP instance (which I've just found out is Fastly-cached :/). Getting 503s at the origin but we're up on our URL with an always online notice thanks to CF. Double dip isn't all that bad.
These issues are in your control - not for the centralised service but your use of them. You can build appropriate redundancy for the components/providers in your stack and the budget you have.
When viewing a meditation session you can see a download button in the upper right (at least on iOS).
I always have a small stash of my favorites saved locally in case of internet outage or I’m caught in a situation where I don’t have internet but need a few minutes.
On top of that I’ve been really trying to rely less on an app. So I throw a lightly guided or unguided session in every couple days at least where I focus on going solo so I don’t need an app and just need a timer.
Every other comment about what's down in this thread -- as if we needed dozens of site-by-site accountings of this outage in the first place -- is a bitch about reddit. Why is reddit so important to this crowd? The specific topics I used to read the site for (half a dozen years ago) have all been overrun by "bucket people," there is literally never an answer to any question I find a google link to there, and the site's design is actively user-hostile. Seriously: what's keeping that place afloat? Porn, I suppose.
Of course, the Enlightened Folk of this site can no longer use their leisure time on lowly activities such as the "Reddit".
Teach me your ways, master! /s
Jokes aside, people can do whatever they please. Reddit has a bunch of niche communities around many hobbies and fun things. No need to be bitter about it.
You have put your finger on it. I AM bitter about it. It used to be really cool, and really nice to use, before the Taylor/Pao dustup, and the redesign.
old.reddit still a thing and there is a plenty of educational subreddits with really nice community around them, it's just like the internet just pick the things that suits you.
reddit taught me to never trust a mod, so it does have some purpose still. i think without glaringly bad examples of how (not) to run a community based site, we would be doomed to repeat it's mistakes.
{kind=link}
[0] https://www.gov.uk/
https://m.media-amazon.com/
https://pages.github.com/
https://www.paypal.com/
https://stackoverflow.com/
https://nytimes.com/
Edit:
Fastly's incident report status page: https://status.fastly.com/incidents/vpk0ssybt3bj