It could use some improvement, but it's been really great for helping people learn how Caddy 2 works at a high level. Beyond our docs, I always encourage new contributors to thoroughly explore the godoc and code: it's very well-commented and organized, especially once you know how it all comes together. A single document will never be sufficient. But it can help you map between concepts and code.
Edit: One other valuable piece is explaining why the architecture is the way it is. Our architecture.md doc links to a video that explains how I arrived at Caddy 2's architecture (and why it's not arbitrary): https://www.youtube.com/watch?v=EhJO8giOqQs
Thanks for putting that out there. It's super interesting to see what we consider architecture to be. Your approach appears operational, focused on how the completed system functions, i.e. getting a new team member up to speed on the codebase.
Typically I try to start with tiers (1, 2, n-tiers...?) that show how the system might be deployed. I then list list layers (user/facade/business/data), interfaces between these layers, and components within each layer. I do that for each tier.
After that maybe something about quality objectives and how they might be met, eg: availability (MTTF / (MTTF + MTTR) * 100), efficiency, flexibility, integrity, interop, usability and so on.
This leads to a physical delpoyment model, which shows layers deployed to tiers. And yes, I'm rather fond of Visio.
Then a bit about approach (dev/deployment and operational management) risk and stakeholder management, technical reviews (change control board maybe?), and project reviews.
To be fair I come from a predominantly critical systems world (telecoms OSS and BSS, healthcare, transport and some fintech. And in that world architecture is very far removed from actual code until eventually.
How do you distill down critical outcomes of the architecture for people considering using your project? Based on my experience so far, engineers will look at a giant document, see phrases like “stakeholder management” and nope the fuck out.
What I want to know is, what are the key performance considerations, failure modes, recovery procedures, etc.
Critical outcomes are defined by quality objectives (I mentioned some above, others are reliability, robustness and portability).
People don't consider using my project. There's a client with a business problem, there's a vendor who solves problems for clients. The vendor produces an architecture document that describes how technology will achieve a solution †.
There is no noping the fuck out, as this is a hospital asking you for a one-off to manage/settle insurance payments. Or an electoral district asking you to merge three emergency response systems into one. Or Nokia asking you to tariff calls going through a switch in real time.
† This is nuanced. Often a client's procurement department invites a number of candidate vendors to submit proposals including a design proposal/architecture and associated cost estimates. Vendors range from the high end (McKinsey, Bain & Co, Ernst & Young) to the mid-tier (Wipro, Accenture and so on) to the niche.
> Or an electoral district asking you to merge three emergency response systems into one. Or Nokia asking you to tariff calls going through a switch in real time.
I’m well aware of what it is. I’ve been on real time telecom stuff (your last example) and know for a fact that engineers nope the fuck out of these huge ass architecture documents that include stakeholders, change control, etc.
Inevitably there is some kind of outage or botched upgrade with lots of finger pointing and then the vendor covers their ass by referencing “page 248 under heading ‘assumptions about bisectional bandwidth’” or some bullshit right before the section on ‘renegotiating requirements during a government declared emergency’.
There needs to be a better way because I assure you, the people using your system are (on average) barely going to skim your document.
Being a “very serious” industry does not change this. Look at the disaster that was Healthcare.gov. That had mountains of documents like you describe they overlooked the simple requirement of scaling identity lookups.
OMG you worked on that? The blame for this one (and Universal Credit) sits with GDS. Their approach at the time was agile or die, and then try to develop an enterprise system like they did the Guardian's CMS (GDS was staffed initally by ex-Guardian devs).
I had the misfortune of reviewing their Government Gateway replacement, which at the time focused singularly on identity federation. GDS was hugely anti-Microsoft, who built the Govrernment Gateway. And so they chose the SAML protocol over the incumbent ADFS, breaking every dependency.
GDS was way out of its league. An inexperienced 25y/o will draft exactly the kind of architecture document you describe.
The people using my system never skim my document. Lawyers tend to scrutinize it. As for the document being a war-and-peace epic yes, this happens. Mostly because people cannot write technical documentation. The hugest system can be distilled down to a single diagram which should require no words of explanation.
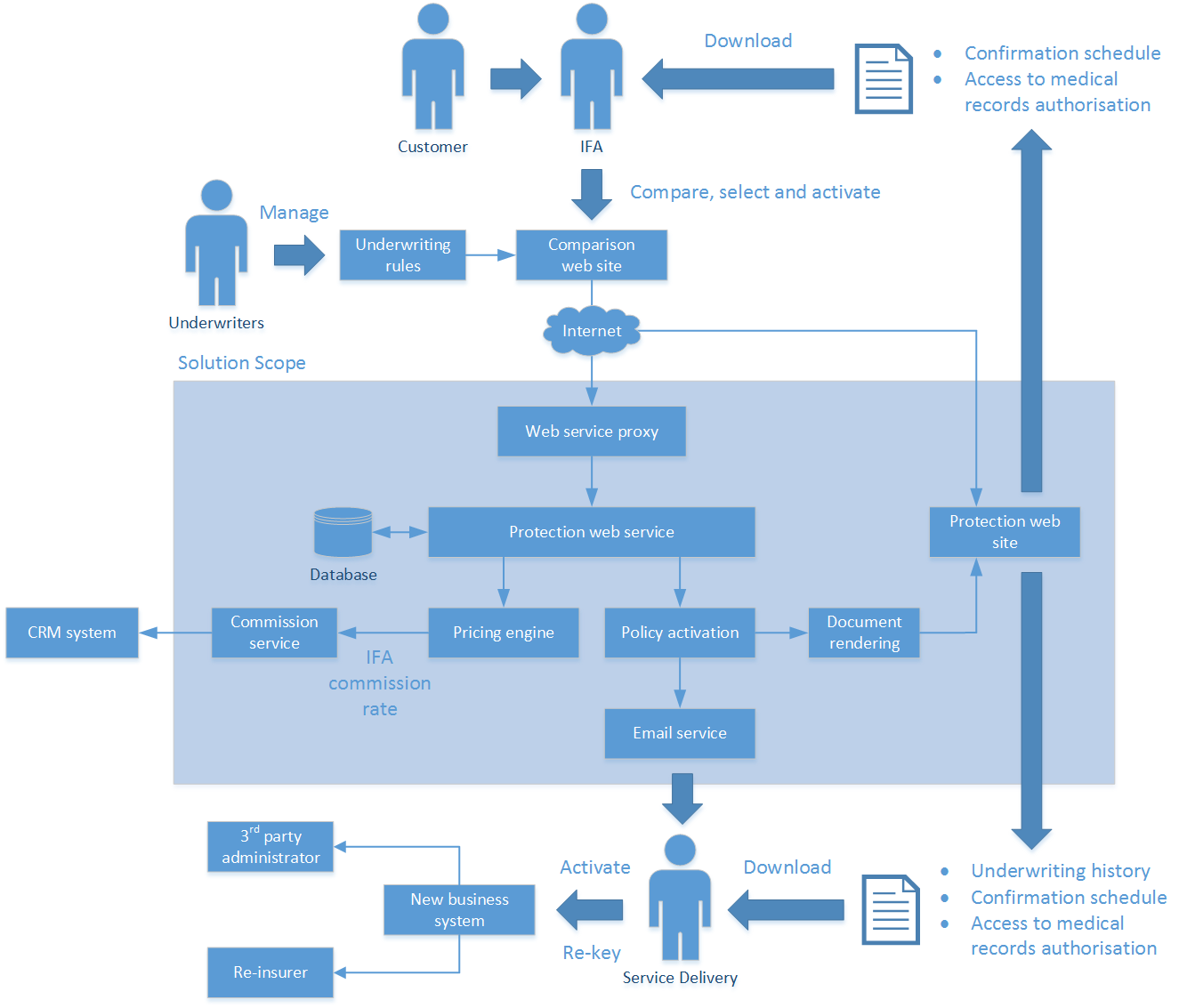
By way of example - here's a conceptual design for an insurer wishing to participate in a panel of protection providers.
If you're in this world all of it is self-evident, none of it a surprise, and you understand the flow. That document leads to other more detailed designs that each address one distinct rectangle in that image.
At some point all of this will become a specification. Again the immensity of that depends on the ability of the authors. On their ability to manage complexity, and their skill as technical writers.
Either way yes, when the wheels fall off that document becomes the truth, the one everyone goes to to settle disputes. And with a capable team it never gets to that because the documentation is succint and agreed to, and what is delivered matches what was specified.
The way to solve that is basically DevOps. DevOps being a solution to a business problem, it is implemented as an array of "features" of integrating teams that work together on a product. It's a multi headed hydra and it's not easy. But the end result is people communicating better, which is the only thing that can really address a developer noping the fuck out. There is no technical thing, no document, no policy, etc that can fix it, as far as I'm aware.
Your approach seems like it would reduce the likelihood of implementation-time surprises. It also seems like different sections would satisfy different audiences. Do you have any book recommendations?
The one that made the biggest impact on my approach to architecture is "Designing Solutions for Your Business Problems: A Structured Process for Managers and Consultants" by Betty Vandenbosch.
The one that made the biggest impact on me in ever is "Wicked Problems, Righteous Solutions" by Peter DeGrace and Leslie Hulet Stahl. Lots of forehead slapping and kicking myself ensued. Even more applicable today than it was in 1990 when written.
"Peopleware: Productive Projects and Teams" by Tom DeMarco and Timothy Lister comes as a very close second.
Not directly architecture or technology-related is "The Story Factor by Anette Simmons". It... changes you. Really useful for technical writing.
Two books I that were instrumental for me to learn how to explain the architecture of my software clearly to other people were "The Architecture of Open Source Applications" Volumes I and II (http://aosabook.org/en/index.html)
I have a similar advice, but I will go one step further: add README.md to other folders as well. It is dope to have a map of your whole system in an Architecture.md (or a README if it's not too long), but it's even more dope to be able to click through it and have submaps of how other components are structured.
Displaying the folder/file structure and explaining what is what is a must. An example from Diem[1]:
consensus
├── src
│ ├── block_storage # In-memory storage of blocks and related data structures
│ ├── consensusdb # Database interaction to persist consensus data for safety and liveness
│ ├── liveness # RoundState, proposer, and other liveness related code
│ └── test_utils # Mock implementations that are used for testing only
└── consensus-types # Consensus data types (i.e. quorum certificates)
└── safety-rules # Safety (voting) rules
I recently digged into dependabot's code, and I found it extremely well structured. For example you have an Architecture section in the first README[2] with a diagram (how awesome is that!) and with links to the README of all the sub components, which themselves live in the subfolders[3].
What I dread the most is going through a new codebase and not seeing any documentation in internal packages. Like how the fuck am I supposed to understand anything in there? By reading all the code?
When I first started programming, I thought the description next to the folder / file name on github was actually describing the item - as you did above, and not just the message from the last commit that altered the file.
Many years later, I still believe that's how it should be.
Agree! I gave that feedback many times, who cares about commit message? I want documentation here!
I think Github should really start taking a stance on convention, and come up with project structure conventions that would help project navigation. For example, youtube does that with chapters in videos, if you write a description with timestamps it will display these chapters in the timeline of the video[1].
IMO Github should do the same if you have a README in your folder, describing the folder with a certain syntax, then it should extract this info and show it next to folders.
If anyone at Github is reading this, pretty please :D?
This makes me think we should be able to put something like a standard tag for a 1-line summary (maybe embedded in some markdown in a comment) in a fashion the VCS's can detect & extract and then render in their UXs.
e.g. something very simple would probably work like the first line found that matches something like:
This will help people browsing code in github, but folks browsing code in their IDE will most likely be lost, as the documentation you advice to put into "README.md"s should, IMHO, be in the module/package documentation in the source.
One can still link to those from the global README.md
I'm not sure I understand why someone in their IDE would be lost, you can't read README.md and see the file structure in your IDE?
Documentation in the source is different from a directory organization documentation IMO. Rust has a lot of tools to write good documentation in source, and it is here to help produce good documentation for users of a library, not to explain how to contribute to the code or understand how everything is architected.
> I'm not sure I understand why someone in their IDE would be lost, you can't read README.md and see the file structure in your IDE?
Of course one can see the files. But I rarely deal with "files" in my IDE, I deal with packages/namespaces/modules/functions/classes/methods. The natural place to put architecture documentation would therefore be the top-level code unit (e.g. package/module/namespace), to which one can easily navigate when viewing docs.
> Documentation in the source is different from a directory organization documentation.
Is it, given that directories tend to be organized around code units (again: packages/namespaces/modules/classes)? It is thinkable to store code in databases (see Dylan's IDE, either implemented or it was on the roadmap, I don't remember) and all the architecture documentation not directly attached to semantic units of your code would be lost.
I still don't think this is a good idea, after having worked a lot with Golang and Rust doc, the documentation generated from comments is targeted to users of the library, not contributors.
(And Rust/Golang have the best documentation system out there of any language I have ever seen).
For example, documentation in Golang does not follow your file structure, it just pulls up any public API comment and displays it. It makes sense, why would I care about how these functionalities are implemented and architected as a user?
Second point: a system has different types of languages and ways to organize things, so it’s not always clear where to look for doc. Whereas a README is always obvious.
100% agree. A very good implementation of your ideas can be found in the Redis codebase. Most important files have a long doc comment in the beginning.
READMEs and API docs aren't mutually exclusive. But they cover different scopes. READMEs are more suited for high-level documentation, focusing on the /why/ instead of the /how/.
I also use such hierarchical style, with lower level REAODMEs refferring iddividual source files. So that user continues from READMEs to code comments.
On every level I first explain the task solved by this module and then go into the implementation details. Knowing the purpose first helps reader to understand impl details.
> Like how the fuck am I supposed to understand anything in there? By reading all the code?
This is one of the superpowers of Go: for most Go projects, this is exactly what I'd do. Just read the code. It's easy to follow, it's all formatted the same, very little implicit behavior, and I don't need an IDE to do it.
Few languages were designed to be read by others. Thankfully Go is one of them.
I am afraid, this doesn't quite cut the mustard. Code just can't replace a human readable Architecture diagram + explanations of whys of choices and hows of the system. Programming language doesn't replace this no matter how clear and modular it is. While Go is nice, you're vastly under-appreciating architectural documentation.
My standard argument regarding the criticality of documentation: no amount of code can ever explain what isn't there.
What optimizations have you tried that failed? What 3rd party tool used to be integrated but now isn’t because the maintenance burden was too high? Why is it safe to ignore this exception?
Actually I find it quite implicit the way Go structures packages. You definitely need an IDE (I use neovim + coc.nvim) to jump to a definition unless you want to grep the folder for where a struct is defined...
There's one issue I can think of, if the struct is defined in the same package then it's a bit of a pain to find which file actually defines it (in Rust you have to be explicit, each file is a module).
But that's it I believe, if it's in a different package then you'd have to explicitly write the import
As someone who is in week two of spooling up on a multi-million-line codebase where most of the original authors have moved on to other projects, please, I beg you to heed this advice. I spend the vast majority of my time figuring out where a change needs to happen. The patches themselves are no more than 10% of the work.
It's called job security bub. I'm not going to write out everything you need to know. Hire an expert and whatever time it takes him to figure out is how much it's going to cost you to churn through employees. Don't like it? Be a better employer so your employees don't leave.
Lovely - now when you get in a car accident, your teammates get to be upset by losing you and have to reverse engineer the mess you left. Hope you don't plan to ever take vacations either - you're too important to leave.
I suppose you're being sarcastic but I certainly have met people with this attitude. Sometimes its not explicit or intentional either, just the lack of time/importance from the business side of things that creates a situation where things are poorly documented/understood and it creates a dependency on certain people/companies. Ultimately I feel its up to us developers to stress the importance of investing time on documentation, but also be mature enough ourselves to realise that this is part of the job.
I like this idea a lot, but you will cause a lot of people to bounce at step 2. Or at least, that has been my experience over the years. No matter how much you reassure them that it is okay if stuff is confusing and in fact you'd like to know about it so you can fix it, they'll say "great" and then go radio silent 99% of the time.
I feel like for any long-running project, that person is at least ME. If I haven't written down some architectural information for complex projects, when I revisit a project after it being dormant for half year, I need to poke around to figure things out again.
If I have written down architecture notes in the first place, they are very helpful at this point; and if I haven't, it's a good time to start because I'll be acutely aware of the non-obvious parts as I re-familiarize myself with the code.
Sounds right to me too. One quicker way to improve the 'first process' is to change only step one - do not spend a long time, but instead write a few paragraphs with what's most important and/or top-of-mind. Often, this opens the door to more contributions and questions.
Of course, update accordingly whenever you find yourself in a discussion about something with a contributor (no matter if the architecture doc is even part of the discussion or not).
I usually reach for a friend, or someone I've met before, since using the first version of a doc is asking a lot! (And they're often part of the target audience).
Most documentation follows that first path. With a step 4. that is basically "only update this when something is broken, or when we're hiring someone new".
Doing documentation well, especially if you're working on brand new tech, is very frustrating and difficult. You're often moving too fast to find the time to retroactively update documentation, and you're right back into the viscous cycle of it constantly being out of date. I don't know what the solution is.
Yep, feedback is valuable. And the earlier the more valuable (it's like NPV...).
I love coding so much, and find it really hard to express ideas in natural language, so that in the end documentation... doesn't happen as much as it should.
What I find that really helps is the following:
1. Write down architecture specs (with interface specs etc), before coding. Not bloated, but really minimalistic.
2. Review these ideas with peers.
3. Happy coding and refine the docs.
I read the title at HN and I was like "okay seems interesting" then I saw "matklad" and went "Holy shit, must be great stuff".
I know I will sound another Rust evangelist, but people this person is the main maintainer of RA (Rust-analyzer), a LSP protocol implementation, anyone who tried RLS (Rust Language Server) then RA knows how great this tool helps you at learning and developing stuff with Rust. I use the nightly version (which updates everyday) and ohh boy... Never had the "opportunity" to caught a nasty bug or anything.
> One of the lessons I’ve learned is that the biggest difference between an occasional contributor and a core developer lies in the knowledge about the physical architecture of the project. Roughly, it takes 2x more time to write a patch if you are unfamiliar with the project, but it takes 10x more time to figure out where you should change the code.
This feels about right to me. Not sure a single doc will help solve that, but even if it cuts the time from 10x to 7x or 5x, it feels worth it.
what they suggest is very similar to Architecture Decision Records (ADR's). https://adr.github.io/
TL;DR: ADR's are a design choice for a lightweight process to store and manage the history over what architecture decisions have been made in the past and why. They should be tracked within git so that the history of decisions and how these evolved is provided for free. Just track all this within an `adr/` subdirectory at the root of each project.
ADRs are more about the "why" (and are absolutely indispensable in any long-running implementation project). Architecture.md is mainly about the "how".
I believe that an optimal architectural document should cover both "why" and "how". Having said that, back when I was writing and modifying such documents at a CMM Level 3 division of a large and well-known tech company (using the waterfall SDLC process!), relevant information was split between high-level and low-level design documents. I found it quite inconvenient and think that having relevant sections (with cross-referenced info) within the same document makes so much more sense.
You need enough "why" so someone reading it doesn't ask, but not so much you're writing a history textbook.
Mostly, think about what someone reading this in 6-24 months will think. Without some background reasoning, parts may seem over-engineered and unnecessarily complex. Say the same time, no one will care about the hours of debate that went on, or the shortcomings of the v1 prototype this replaced.
I agree with you that information (IMO both coverage and level of detail) should be balanced, for the target audience. However, I think that it does not apply to "why" information exclusively. Rather, this is pretty much a universal approach / best practice and, thus, should be applied across all categories of content.
It seems like ADRs are the deltas of architecture.md: they describe how it has changed over time. It's useful to have one document which just describes things as they are, but it's also great to preserve the history of how things came to be that way.
I thought of ADRs too, but it seems the objective here is to be a bit more high level. It doesn’t help that the term “architecture” is so wide in meaning.
I’ve adopted ADRs and it has been good for decision making, but it doesn’t help much new contributors to find exactly what module they need to focus on for a task.
If you're going to do this, you're probably going to use images. If you're going to use images, please keep in mind that GitHub now has a dark mode, so black text on a transparent background is almost entirely unreadable. Here's what the first image in the example document looks like in the markdown file, compared to the actual image: https://imgur.com/a/k2KWB57
In addition to architecture, I'd strongly recommend to add
"GLOSSARY". In many software projects, a certain common noun has a project specific meaning, and it's confusing to a first-time reader who has to figure out which one is a special term. In my own PDF parser project, for example, "stream", "trailer", and "literal" are PDF-specific terms that are different from its normal usage. A glossary also helps introducing basic concepts used in the ARCHITECTURE.
Also the author:
"A good example of ARCHITECTURE document is the one from rust-analyzer" => redirects to an architecture file that takes 32 whole smartphone screen scrolls to read
That’s a fair observation! In my defense, rust-analyzer is a deep and complex project, so there’s a lot of stuff to describe. It’s closer to the 200k end.
1. put a one line comment at the top of each code file.
2. The build extracts that comment and dynamically updates a readme.md for the directory that describes each code file.
3. The build also produces a master document that includes the same summaries in a single document.
This provides a light indication of what each code file is and how they are organized into directories. It doesn’t provide any indication of flow control or any kind of logical linking.
Since the documentation is prepared via automation you can add new files or delete files and the documentation remains current. If such a comment is missing from a code file the build fails with error messaging. Keeping each comment up to date is still manual though.
I find it useful to include an architecture diagram in the README for small projects, and the best way is to use the VSCode DrawIO extension. You can directly edit .drawio.svg files and embed them into the README. You get live editing and up-to-date images at the same time!
I've been recently using pic to draw any kind of images for documentation purposes.
Pic is a language Brian Kernighan created for troff toolchain. It's very versatile and has macros, even! Manual: https://pikchr.org/home/uv/pic.pdf
Contemporary implementations (pic2plot, dpic, pikchr) can output SVG so the results look very nice and are repository-friendly and diff-friendly to some extent.
The k8s project did this very well in the early days with their design docs. It made the codebase much more accessible than it ordinarily should have been. There are few projects that do this and I wish the JavaScript projects did this a lot more.
If anyone knows of other open source projects that do this, it would be particularly useful.
So one thing we've done is write all of our applications the exact same way with well defined terms (on a wiki) and a commitment to no more than 4 layers.
* Initiators (things that receive, decode, and validate input)
* Controllers (Business logic containers. One function refers to one business action)
* Services (Used by controllers to effectuate commands. Services absolutely cannot call other services)
* Cross Cutting concerns (Common model objects, logging, top level error handling, etc)
This allows even a new person to pick up a project and orient themselves immediately.
First: we found that it creates a spider web of dependencies if we din't have this rule. Instead, if you return control to the controller after performing a discrete action, it makes sure that business logic stays out of services and keeps service functions short and directed.
Second: it makes it easy to keep the entire design in your head.
Third: It promotes composition. This leads to easier testability with mocks rather than having to resort to full blown integration tests for even the smallest things. (We still do integration tests, but mock tests can be churned out in volume and are less fragile).
Yes. So something like a "DatabaseService" might have a database connection, which is code we don't own. But the code we do own stops at that layer. This prevents a spider web of dependencies opening up.
I would encourage people to have one ARCHITECTURE file per directory of source code files. Don't duplicate documentation in these files - if there is a well documented header file for some module, just link to that.
In a big project, when I'm hunting for code that does something and I have no familiarity of the codebase, I want to be able to follow a chain of ARCHITECTURE documents from the root of the project to the implementation of the feature I'm looking for.
If your documentation is poor enough that I resort to finding a string used in the feature and grepping the whole source tree for it, then your codebase will be tricky for someone new to get started on.
Disagree. If I have a question about the architecture, I don't want to go hunting through your directory hierarchy for the right doc file if I don't have to. Not saying you shouldn't have some kind of design doc in each directory, but I'd say it's more important to have a single roadmap than lots of little interlinked ones. If links were enough, I would just read the code.
That sounds a bit excessive. If your project is going through a lot of changes and refactoring, the multiple architecture.md files will be hard to keep up-to-date
An architecture document should be the code equivalent of a combined street map and tourist guide. Its purpose is to bring strangers up to a minimum level of familiarity with the code as quickly as possible. That includes where things are, why it was architected this way, things to look out for, and a few interesting points of weirdness perhaps.
I think diagrams are usually quite helpful in accompanying an Architecture.md doc, especially if it gets complex.
I work on a diagram maker that syncs with a Github repo. So whenever you make changes to this architecture diagram, it'll push changes to the repo, with screenshots directly in the README (turning the repo into a diagram presentation).
This also allows people to colocate the diagrams alongside the code or docs by including the synced repo as a submodule.
An alternative is to use an embedded diagramming syntax like dot or mermaid such that the diagrams are described as version controlled text and optionally rendered inline by e.g. VSCode. Cleaner than a litter of side car images in which it may be unclear what changed.
Text based diagrams definitively have their advantages over wysiwyg editors. However, sometimes the layout of a diagram also tells a story and I find it hard to express that with available text based diagram solutions.
That's what I use draw.io aka diagrams.net for.
I made an extension that helps to create markdown-embeddable/versionable draw.io diagrams in vscode:
https://github.com/hediet/vscode-drawio
(there is also an IntelliJ extension)
I have to admit that I sometimes struggle with pixel perfect layouts though and rearranging nodes is time intensive.
However, most text based systems don't have a nice github integration and rely on manual export, which you can avoid when you diagram is not a plain text file but a rich diagram editor.
How do you keep this up to date though? That's the biggest problem with documentation. Having some kind of append-only format, like ADR, can help, since the documentation specifically is tied to a decision at a single point in time.
Still, those can drift from the actual implementation to the point where they are both misleading and confusing. Such is the entropic nature of software.
Revise it twice a year. If the document gets stale faster than that, just delete the stale bits: they are probably too low level for this kind of documentation.
I find filing issues whenever I find out-of-date docs helps. They tend to get fixed pretty quickly, because they offer a nice change of pace from working on bugs or features.
I disagree with this characterization. ARCHITECTURE.md is specifically engineered to be low churn, so in this respect it is meaningfully different from other “keep docs” advise.
In practice, I personally didn’t find it difficult to maintain half-decent ARCHITECTURE.md, and I am not at all good with keeping the docs otherwise.
When doing code reviews, someone will usually say, "we need to update the docs" if it's a big change. If you can't do that now, file a bug to remind yourself, or assign it to the new guy (maybe kidding).
That’s a fair point, although given how “high level” this is supposed to be, I’d imagine that needing to update it a lot might actually be a canary that the project in question is in a lot of flux.
This seems pretty easily fixed by appropriate linting which includes link checking. Perhaps it's overkill, but personally I like to validate anything I can automatically so I try to validate syntax and links in Markdown documents in my projects.
I actually agree from my experience working with complex implementations of web analytics architecture in Adobe Launch. Especially the fact that nearly every rule (tags are called rules there) can contain custom JS code makes it sometimes hard to know when a specific change to the data happened between the data layer in the DOM and the tracking request being sent to the Adobe endpoint.
I had a client with custom code shortly below 7k LOC.
Split into many different rules.
To make a long story short: Now that I know the map (the architecture) I can find my way quite fast and am currently in the process of simplifying things as far as possible.
That's good advice, even just an architectural diagram with notes on each component. It isn't just for public projects though, all projects have new developers coming in from time to time and the easier it is to present the project in a clear way, the less time you'll end up having to spend onboarding someone.
.....although I can be as sloppy as the next person at keeping documentation up to date which is why I think even a high level design and notes is better than nothing.
I really like this DESIGN.md[1]. Might not be as code specific as what tfa is talking. I find design decisions really helpful when evaluating if a tool or solution is useful for my needs. Especially if it elaborates on priorities made in the project.
There is an important aspect of writing architectural docs (or any docs for that matter) that is often overlooked.
Write simply and clearly.
Too much verbosity and detail is difficult to follow. That's what the code is for. It is almost a superpower to be able to write succinctly and clearly. This isn't some contest to showoff your deep knowledge of a particular niche. I've seen developers get 'nerdy' with their docs for a lack of a better term.
One trick here is to keep in the source, every sentence on a separate line. That way, it's hard to miss complicated sentences. As a bonus, docs become easier to diff.
Yet another piece of documentation that will be out of date in ~1 year. I have seen and read too many pieces of internal documentation that is just outdated because it’s no longer maintained or the project changed too many hands and the internal architecture deviated from the original.
I guess it’s a nice touch, especially for personal projects that get abandoned and you need to refresh your state of mind after X amount of months/years.
> Additionally, the shorter it is, the less likely it will be invalidated by some future change. This is the main rule of thumb for ARCHITECTURE — specify only things which are unlikely to frequently change. Don’t try to keep it synchronized with code. Instead, revisit it a couple of times a year.
I this is absolutely crucial for almost any project where you can't necessarily directly instruct someone on how it works. This is after having failed to contribute anything to open source projects that I do know the language of, have read the docs, and couldn't for the life of me figure out how the bits came together.
Even on relatively small projects (1k-10k LOC), I incorporate this, broadly, into my README file for my repo: what are the various use cases, which components do what, in one sentence what are the main functions contained in each of the source files, sometimes a flow diagram showing which functions call which other functions.
Along the lines of an ADR, another useful document to have is Decisions and Opinions. Often choices are subjective, highlighting these will let contributors know about your preferences for the project. Often these relate more to linting styles, choice of libraries, etc.
An interesting systemsy difference is that missing style.md means more work for maintainers (as they need to do more cleanup), while missing architecture.md means more work for contributors.
The othe document one should put next to README and CONTRIBUTING is CHANGELOG.
Way too often I find this document missing. Especially in the rust ecosystem: I see some crate bumped their version number, but no info about what changed. (And no, a git log is not a good substitute)
I wrote an article recently about a method I use that I call the "funnel architecture". The idea is to concentrate important high-level concepts of your client app's infrastructure into a single file - the intent being to let that stand as a form of documentation of the app's infrastructure/architecture.
For my app I've started putting architecture related documents under /spec [0]. I feel documenting every aspect of the architecture is hard and time consuming, it also needs to be kept up to date. However it's worth documenting at least the trickier parts of the app.
Is there something similar for creating an overview of an entire web application to plan and communicate feature set, server stack, application structure, scheduled jobs, etc?
I've started using draw.io [1] for diagrams I want to embed in markdown files. The cool feature about draw.io is that it can embed the data structure describing the diagram in a png file. So you get a PNG file that is both source code for your diagram (so you can edit it later), as well as the presentation (you can embed png files and they will render fine in Github hosted md files).
Then I use the markdown-images package [2] for Sublime Text, and I can see those png images in my markdown files in the editor as well.
Benefits of this approach:
* Powerful diagram editor, free to use.
* Editable diagram and embedable image in one file.
I tend to prefer diagrams as code, so yoi can just embed an image that be updated, version controlled, etc, instead of ascii diagrams. Any reason in particular you want ascii instead of images?
I don't mind images, just wondering if Github would make it easier to generate those. Something like the syntax of web-sequence/uml but not limited to data-flows and something more simpler, ideally.
From my experience, you don't want to add anything too complicated or anything that's volatile to code, but in some cases a high level overview of how bits of an application fit together can be handy. These days it might be a better idea to just embed or reference a PlantUML diagram instead.
More repos need to do this. If it's not too big it can be stuck in development.md which is where I
usually stick it.
It makes it so much more likely that I'll contribute with a proper PR. There's some codebases I would have liked to contribute to but they were so complicated and with so few comments I just gave up and only reported the bug / made a feature request. Even worse when they have complicated undocumented build systems.
Thanks for the prompt – we had a rough version of this at Outline in the README but I've gone ahead and pulled it into it's own document with a pointer from the README and fleshed out the docs:
The bird’s eye view seems to be an image, at least in the example cited there. A picture can tell a thousand words and can set a good context for the words that follow. What are the easier ways (amenable to easy creation and modification) to make it accessible for people having issues with vision?
This is so useful. Even a simple description of the source code tree helps a lot. Otherwise people will have to find entry point files and recursively search the entire repository until they find what they're looking for.
Absolutely, I was just thinking about adding a similar document to my new project. Apart from contributors, it also benefits casual visitors who just want to browse around.
This is predictably unrelated but how can someone go to the effort of having such beautiful typeface selection and still have an unhyphenated ragged right?
And yes, I myself am struggling with ragged right. I really wish to have proper text hyphenation and justification, to have a book-like feel. Sadly, justification without hyphenation looks ugly, and `hyphens: auto` doesn’t work well (and wasn’t supported in chrome last time I checked).
I am pretty baffled that such basic (in terms of impact, not in terms of complexity of implementation) feature isn’t widely available.
Although I am not a web designer, so I might be missing some simple way to solve this.
I came to the comment section to compliment the choice of Garamond.
The web would look much more beautiful with proper justification. It's a pity technology is not there yet. TeX solved the problem for DVI/PDFs long ago, so maybe we should start blogging on PDFs!
You can take an approach like the Linux kernel where _one_ person is the sole arbiter and approver of all changes. This person is tasked with having complete, 100% depth and breadth knowledge of the entire system. It is their responsibility to ensure changes adhere to the goals of the system. It is of course an enormous bottleneck, and a big risk for management (the old 'what if they get hit by a bus, what do we do then?' concern).
Realistically, past the 200k lines of code point you aren't dealing with a codebase anymore; you're an _organization_. You need knowledge management--where do architecture decisions live, how are they approved, how are they taught to new developers, how are they updated as maintainers come and go, etc. It takes strong engineering management and leadership to keep it together.
I've gotten used to put 'beginning of ...' and 'end of ...' comments into a large project to demarcate large functions or collections of them, along with inline documentation. Line numbers are worthless for this.
It'd be great if there were FORMAL ways * to demarcate that are standard (yeah, what XKCD said) in ALL languages. Then anyone could just run a 'show architecture' application on the code and it would always be current.
After a few months (or thousands of loc), that map in your head starts to fade.
Some high-level property of the code which does not change as you add new features. A good example would be “the model layer does not depend on the view layer”.
{kind=link}
(The filename on disk is literally "architecture.md" -- it is a Markdown file rendered by Caddy's template handler: https://github.com/caddyserver/website/blob/master/src/docs/...)
It could use some improvement, but it's been really great for helping people learn how Caddy 2 works at a high level. Beyond our docs, I always encourage new contributors to thoroughly explore the godoc and code: it's very well-commented and organized, especially once you know how it all comes together. A single document will never be sufficient. But it can help you map between concepts and code.
Code search is also invaluable for this; I recommend Sourcegraph: https://sourcegraph.com/github.com/caddyserver/caddy
Edit: One other valuable piece is explaining why the architecture is the way it is. Our architecture.md doc links to a video that explains how I arrived at Caddy 2's architecture (and why it's not arbitrary): https://www.youtube.com/watch?v=EhJO8giOqQs