The article directly suggests that isn't the case. There's a (debatable) improvement over Google's existing phrase-based system on these benchmarks, but the whole paper is about the huge effort they've had to put in to get past the shortcomings of the method.
A more realistic assessment is that state-of-the-art neural translation is maybe getting as good as phrase-based systems.
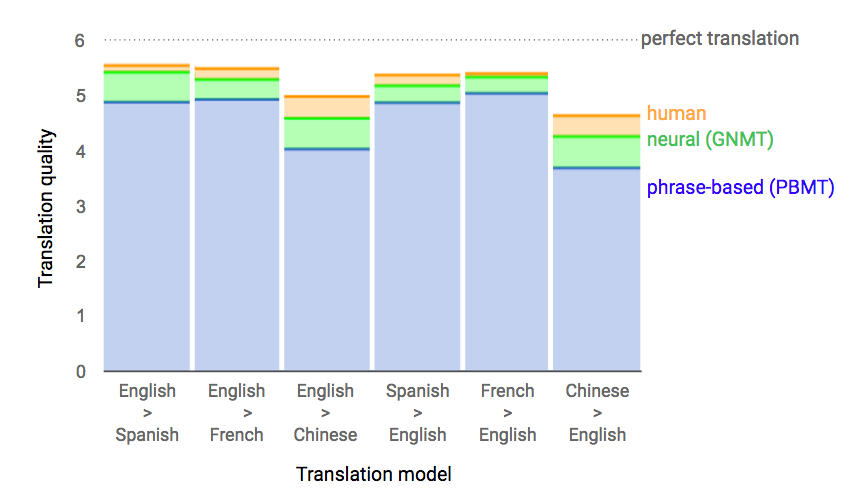
On French > English and English > Spanish it's almost indistinguishable from human translations. On the rest it still gets greater than half the distance between the previous best method and human quality translations. This is a massive step forward.
Take it easy. The graph you're linking to is for a limited survey of 500 isolated sentences, and it's a comparison of mean scores without confidence intervals. The authors themselves admit that it has serious problems as an evaluative tool:
"Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately. Also note that, although the scale for the scores goes from 0 (complete nonsense) to 6 (perfect translation) the human translations get an imperfect score of only around 5 in Table 10, which shows possible ambiguities in the translations and also possibly non-calibrated raters and translators with a varying level of proficiency. Testing our GNMT system on particularly difficult translation cases and longer inputs than just single sentences is the subject of future work."
When you look at the other evaluations in the paper, it's clear that it's about as good as the current best phrase-based tools. In other words, this may be a massive step forward for neural nets, but it puts them at about par for the field.
I don't see any problem with this evaluation. Both human translators and the machine were subject to the same conditions and evaluators, making it possible to do an objective comparison. 500 samples is more than enough to get an accurate score.
If phrase based was really so good, it should have gotten approximately equal scores on this simple task. Instead in every case it did way worse than the neural translations.
Unless you think Google's existing phrase based system is significantly behind the state of the art (possible, but I doubt it's too far behind), 60% better is a pretty great improvement.
I only skimmed the paper briefly, but it seems like they don't depart significantly from the NMT literature, but they do need to tweak a few things to get their results.
Like I said, it's debatable. It was honestly the weakest part of the paper. The specific claim comes from a vaguely specified "human evaluation" (i.e. how many evaluators? based on what criterion? did you just ask folks at google to compare stuff?) on a tiny sample of 500 basic sentences, and the results were presented as differences between mean scores without so much as a confidence interval or a power calculation to back them.
Moreover, from the paper:
"In some cases human and GNMT translations are nearly indistinguishable on the relatively simplistic and isolated sentences sampled from Wikipedia and news articles for this experiment.
Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately. Also note that, although the scale for the scores goes from 0 (complete nonsense) to 6 (perfect translation) the human translations get an imperfect score of only around 5 in Table 10, which
shows possible ambiguities in the translations and also possibly non-calibrated raters and translators with a varying level of proficiency. Testing our GNMT system on particularly difficult translation cases and longer inputs than just single sentences is the subject of future work."
Basically, you should ignore the claims of improvement, and replace them with a big question mark.
One of my favorite college courses was a translation course.
One of the key points repeatedly hammered home (I took the class twice) was that languages do more to constrain what must be communicated than what can't be communicated.
Consider gender in Romance languages vs. English as a simple example.
Additionally, each language gets it subtleties in different ways. With English, it's vocabulary by and large. Supine, lying down, flat on his back, prone, recumbent ...
Even with my own poor language skills in Russian, I can say that the subtleties are different. You must be more precise with your verb tenses, for instance, but in exchange you can communicate quite a lot more about the status of an action. Getting that into English can be unwieldy: prochital = something like "we totally and completely talked it over." Of course, that's horseshit as a translation, and here we have the problem of rating translations.
There will always be quibbles from translators because the languages have slippage between them. I don't think "perfect" translation exists for anything but the simplest of sentences in rare circumstances.
Another awesome example: "i-e" (pronounced "ee-ay") in Japanese = "No" in English. Except not really, because in Japanese it means something more like "contrary to your expectations". In English "no" can be the affirmative when we ask about a negative. "You didn't go did you?" "No."
In Japanese that would be "Hai" as far as I understand it.
As a nerdy sidenote, even worse, English does shit like turning double positives negative but only sometimes.
That's sarcasm, which is not a grammatical construct but a cultural(?) one. "Yeah, yeah" is a positive statement (grammatically, a double positive never turns into a negative in English), but a statement said sarcastically implies that you meant the opposite of what you said.
{kind=link}
A more realistic assessment is that state-of-the-art neural translation is maybe getting as good as phrase-based systems.