This paper is a good illustration of what I see as a critical shortcoming of modern NLP work: it is all about math and algorithms, there is nothing about actual language.
The paper has lots of information about: neural network architectures, parameter update equations, learning rules, and inference algorithms.
There is nothing about: part of speech categories, relative clauses, morphology, affixes or compound words, the theta criterion, the content/function distinction, verb tenses, agreement, or anything else related to actual linguistic phenomena.
To me this seems a bit like the Aristotelian thinkers who tried to reason about physics based on pure mathematical analysis, without any empirical work.
Fred Jelinek famously quipped: "Every time I fire a linguist, the performance of the system goes up." Here are two hypotheses that could explain this observation:
1) Linguistic knowledge and theory is not useful for NLP work; instead, people should rely entirely on machine learning techniques.
2) Linguistic knowledge is useful in principle, but the field of linguistics has not yet obtained a sufficiently high-quality theory, and it is better to rely on ML than on low-quality theory.
Almost everyone in NLP adopted hypothesis #1; I believe hypothesis #2 is true.
I'd extend hypothesis #2. We might not have a sufficiently high-quality theory, but we might also not know how to integrate the benefits of the theory we have with the benefits of data-driven approaches to NLP like those described in this paper.
It's clear to me that data-driven techniques are an essential part of the answer to the problem of language understanding. It's infeasible to design a complete set of rules for understanding natural language with all its exceptions and fuzzy relationships. I'd point to Wittgenstein for a stronger philosophical argument on this.
That's not to say that theory has no place in language understanding, but it's not immediately obvious how to combine rule-oriented theory with data-driven ML.
There has been work in this area though, and actually several important, state-of-the-art-moving contributions have been inspired by linguistics. My favorite are recursive neural nets, which benefit from the linguistic insight that language has recursive structure. This paper[1], for example, describes a system that combines a dependency parser with a recurrent neural net (gross oversimplification) to yield a state-of-the-art sentence understanding model.
> which benefit from the linguistic insight that language has recursive structure.
Really? You needed an entire _field_, and not just, and by just I mean, in an, but not too, extended, sense, really, trivial observation, to get to that conclusion?
Not OP, but Wittgenstein covers this in his Philosophical Investigations. In the Tractatus, he tried to create an all-encompassing system for language, but in PI he more or less says it's impossible. It's an amazing read in any case, it has totally changed the way I approach philosophy.
> it is better to rely on ML than on low-quality theory.
Isn't ML (and especially deep learning i.e. neural networks) itself a low-quality theory? From what I understand, nobody really knows why it works so well but uses it anyway.
I love your work on #2, it's a really interesting avenue, but I wonder if both approaches are close to the point where reasoning about the sentence and its meaning becomes necessary anyway if we want to go beyond the current state of the art.
The linguistic patterns that you mentioned (parts of speech, etc.) are too simplistic to describe language's idiosyncrasy and they ignore language acquisition.
Machine learning and data-driven methods require models with millions of parameters. Linguistic theories have traditionally not used such models.
> There is nothing about: part of speech categories, relative clauses, morphology, affixes or compound words, the theta criterion, the content/function distinction, verb tenses, agreement, or anything else related to actual linguistic phenomena.
When you learned you native tongue, you didn't need to know all of these. You just learned. So, maybe the problem IS about math and algorithms instead of linguistics.
"When you learned you native tongue, you didn't need to know all of these. You just learned."
Learning your native language is not at all the same task as translating between languages. People who do translation are usually quite knowledgable in questions of grammar. This is particularly true of people who pick up languages later in life.
Even if you know multiple languages "natively", it's often difficult to translate accurately without thinking about grammar. Or, for that matter, to speak/write your own language with any degree of competency -- we study grammar in grade school for a reason.
Who's to say that neural nets aren't implicitly learning these concepts as they train? In fact, I'd be very surprised if nothing about the networks' internal state corresponded to linguists' models of how language work.
Nothing about focusing on the math and not the language means that these concepts don't have a role in how the models learn language. Just as nobody is told about parts of speech as they're acquiring their native tongue, we don't necessarily need to explicitly tell machine learning models about parts of speech in order for them to learn how to use that aspect of language correctly.
Christopher Manning, a somewhat famous NLP researcher before and during the deep learning craze, has a great perspective on this that echoes your statements which I recommend reading:
The article directly suggests that isn't the case. There's a (debatable) improvement over Google's existing phrase-based system on these benchmarks, but the whole paper is about the huge effort they've had to put in to get past the shortcomings of the method.
A more realistic assessment is that state-of-the-art neural translation is maybe getting as good as phrase-based systems.
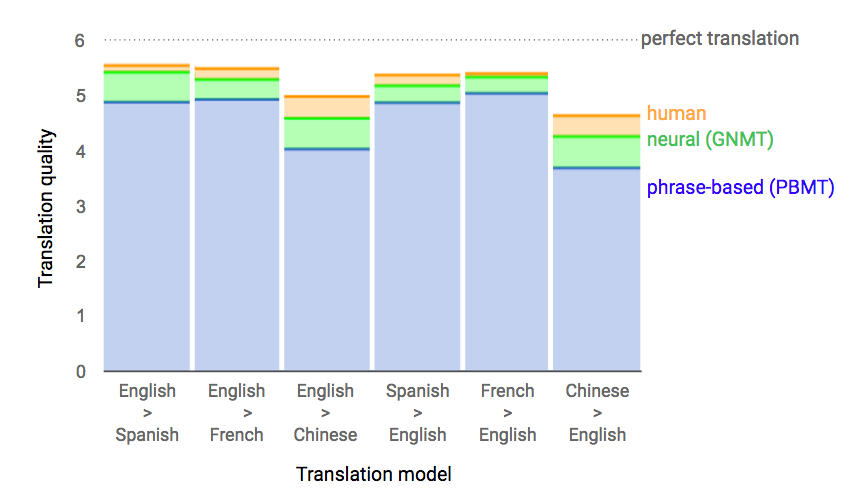
On French > English and English > Spanish it's almost indistinguishable from human translations. On the rest it still gets greater than half the distance between the previous best method and human quality translations. This is a massive step forward.
Take it easy. The graph you're linking to is for a limited survey of 500 isolated sentences, and it's a comparison of mean scores without confidence intervals. The authors themselves admit that it has serious problems as an evaluative tool:
"Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately. Also note that, although the scale for the scores goes from 0 (complete nonsense) to 6 (perfect translation) the human translations get an imperfect score of only around 5 in Table 10, which shows possible ambiguities in the translations and also possibly non-calibrated raters and translators with a varying level of proficiency. Testing our GNMT system on particularly difficult translation cases and longer inputs than just single sentences is the subject of future work."
When you look at the other evaluations in the paper, it's clear that it's about as good as the current best phrase-based tools. In other words, this may be a massive step forward for neural nets, but it puts them at about par for the field.
I don't see any problem with this evaluation. Both human translators and the machine were subject to the same conditions and evaluators, making it possible to do an objective comparison. 500 samples is more than enough to get an accurate score.
If phrase based was really so good, it should have gotten approximately equal scores on this simple task. Instead in every case it did way worse than the neural translations.
Unless you think Google's existing phrase based system is significantly behind the state of the art (possible, but I doubt it's too far behind), 60% better is a pretty great improvement.
I only skimmed the paper briefly, but it seems like they don't depart significantly from the NMT literature, but they do need to tweak a few things to get their results.
Like I said, it's debatable. It was honestly the weakest part of the paper. The specific claim comes from a vaguely specified "human evaluation" (i.e. how many evaluators? based on what criterion? did you just ask folks at google to compare stuff?) on a tiny sample of 500 basic sentences, and the results were presented as differences between mean scores without so much as a confidence interval or a power calculation to back them.
Moreover, from the paper:
"In some cases human and GNMT translations are nearly indistinguishable on the relatively simplistic and isolated sentences sampled from Wikipedia and news articles for this experiment.
Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately. Also note that, although the scale for the scores goes from 0 (complete nonsense) to 6 (perfect translation) the human translations get an imperfect score of only around 5 in Table 10, which
shows possible ambiguities in the translations and also possibly non-calibrated raters and translators with a varying level of proficiency. Testing our GNMT system on particularly difficult translation cases and longer inputs than just single sentences is the subject of future work."
Basically, you should ignore the claims of improvement, and replace them with a big question mark.
One of my favorite college courses was a translation course.
One of the key points repeatedly hammered home (I took the class twice) was that languages do more to constrain what must be communicated than what can't be communicated.
Consider gender in Romance languages vs. English as a simple example.
Additionally, each language gets it subtleties in different ways. With English, it's vocabulary by and large. Supine, lying down, flat on his back, prone, recumbent ...
Even with my own poor language skills in Russian, I can say that the subtleties are different. You must be more precise with your verb tenses, for instance, but in exchange you can communicate quite a lot more about the status of an action. Getting that into English can be unwieldy: prochital = something like "we totally and completely talked it over." Of course, that's horseshit as a translation, and here we have the problem of rating translations.
There will always be quibbles from translators because the languages have slippage between them. I don't think "perfect" translation exists for anything but the simplest of sentences in rare circumstances.
Another awesome example: "i-e" (pronounced "ee-ay") in Japanese = "No" in English. Except not really, because in Japanese it means something more like "contrary to your expectations". In English "no" can be the affirmative when we ask about a negative. "You didn't go did you?" "No."
In Japanese that would be "Hai" as far as I understand it.
As a nerdy sidenote, even worse, English does shit like turning double positives negative but only sometimes.
That's sarcasm, which is not a grammatical construct but a cultural(?) one. "Yeah, yeah" is a positive statement (grammatically, a double positive never turns into a negative in English), but a statement said sarcastically implies that you meant the opposite of what you said.
This reminds me of the DeepMind bit where the AI beat human players despite not knowing about the edifice of built up knowledge in that domain. I'd expect that an AI could be a great chess player with enough gameplay info and not knowing particular strength scoring, types of famous defenses, etc. In some ways the way that humans have constructed these relationships may actually make learning more difficult. We certainly don't teach 3-year olds about theta criterion, we just speak in 'correct' language and may correct them when they make mistakes.
That's the best part of this style of machine translation: the code knows nothing about parts of speech or other categories that linguists try to force-fit language into.
Instead, it learns the structure of both languages from training data (sentence pairs in source and target languages).
> There is nothing about: part of speech categories, relative clauses, ...
Because it's not the best level of abstraction. Human generated features don't capture all the nuances. In vision there used to be heavy engineering and math involved in feature creation. Now it's all neural nets end to end. Same thing happened to language.
Because this isn't linguistics work. It's AI work. We are bypassing the impossibly hard problem of natural language processing. Instead we build AIs that can do the hard work for us, and much faster and better than any human linguist ever could.
It's better than previous machine translation systems, I mean. Sure humans can translate better, but they can't describe how in a useful way. Linguists have spent decades trying to come up with hand designed language models, input knowledge about the world in computer readable formats, etc. But this simple AI model can learn to do a better job in a week from raw data.
My hunch is that the more apt analogy is to Skinnerian Behaviorists, or apostles of the Hilbert Program. Deep learning is a very a powerful tool, and the current zeal for it has yielded rapid progress in previously stagnating fields. That said, we have yet to see what its limits are in this space; it's still too young to know. It may be that, like in so many cases beforehand, synthesis is the path forward, and there are no silver bullets.
Maybe it's your expectation that anything interesting in linguistics
needs the language of part of speech categories, relative clauses, morphology ... Maybe that assumption needs to be updated? Maybe the
language of network architectures, parameter update equations, learning rules ... is a better way of talking about language?
Given the successes that Google's machine translation has had, and the lack of success of traditional linguisitics, it might appear to be the case that this paper is directly about language.
It's not a better way of talking about language: it's a better way of talking about how to build a computationally useful model of language with features primarily extracted from data than building language explicitly in is. Pretty much by definition.
Google's paper isn't talking about language -- it's talking about how to tune a generalized computational device to build a computationally useful model from a large corpus of data. Of course it sounds different than talking about language, per se.
There is a problem that arises in this case that isn't present in the analogy you gave. The physics they were using pure mathematical analysis was logical. Language, and how humans always change the way they use language is largely illogical.
You're right in saying that we can't really get anywhere trying to analyse language piece by piece. But pure mathematical analysis is not getting us great results either.
Linguistics fails to come up with a competitive alternative that leads us to better real application, that is why. In a data driven world, that is nothing to complain about except themselves.
> There is nothing about: part of speech categories, relative clauses, morphology
This is an interesting and deep question. I believe that there are multiple ways to tell the story of a phenomenon. Using POS categories or verb tenses helps us to organize and learn about the medium. It is important for humans to know what a verb tense - in theory and practice - is, to be able to form not just grammatical sentences, but also ones, that express things clearer.
However, there is no rule that says that these concepts must be learned first before you can do anything else. In a sense, I see the (neural) machines taking a step back.
Whereas earlier attempts at language modeling took into account a lot of linguistic concepts, maybe even tailored to a specific human language, the more end-to-end approaches ignore these things and get better results. What can this tell you about the concepts? They are certainly useful and have been established by a scientific community. The machine, as it reads not just tens or hundreds of sentences but billions, creates a mathematical model, that happens to have aspects, that have very useful real world sides to them. A machine that learns a language model - or that learns translation, can teach us new things about words, and ultimately also about the world. I believe this is a beautiful aspect of the current neural renaissance.
----
Kanerva in a preface to Geometry and Meaning writes:
> We think of some sciences, by their very nature, as being more mathematical than others. We even refer to physics and other heavily mathematical sciences as "hard sciences," as if to imply that social sciences and humanities are somehow soft or easy. Another way to see this picture, however, is that mathematics itself is hard and that it would be applied first to sciences that themselves are relatively easy. [...] It matters greatly that the mathematics be appropriate. [...] Mathematics is a tool for coping with complexity. [...] This brings us to the substance of [this] book: the exploration of mathematics that would be appropriate for describing concepts and meaning. The branch of mathematics that has traditionally been associated with meaning is logic. Logic is also discussed here, yet the main emphasis is on identifying mathematical spaces that would lend to modeling of meaning. (http://www.puttypeg.net/book/chapters/foreword.html)
Google's recent language modelling paper achieves state of the art performance on exactly these tasks, and it's based on a somewhat vaguely similar architecture.
It's becoming pretty clear that many of these concepts may not be fundamental 'things' but just things that make it easy to talk about.
Actually it seems a little like the opposite. Their software is actually translating language quite well in the real empirical world, while the the programs built with language rules were never able to do nearly as well.
Why do think any of those labels are critically important? They are entirely derived from human desire to understand, process, and define a taxonomy for language. There is absolutely no reason to think that they are inherently necessary to achieve the goal or high fidelity translation (or anything else in this domain). Similarly they might be meaningful but inferred naturally through the learning process.
If your goal is to map machine learning processes to established dogma, this makes sense; if it is just to build an effective learning machine that solves an extant problem, then it's not.
No seriously, this is exactly empirical work. It works somewhat at translating texts.
On the other hand, attempts that tried to use linguistic categories failed.
A nice new development is multilevel deep networks with explanatory states built in. It will tell you why it detected the thing it did. It may of course be lying or wrong. :)
I hate when people judge machine translation progress by looking at Google translate. Google translate is really old and is no longer state of the art. But the best neural network based systems like this are much too expensive to use in production, at least for free. They say their new neural network ASICs will make it more practical, at least.
Anyway the scale of these neural nets is quite incredible. Google is getting far ahead of what any individual researcher with a few consumer GPUs can do.
You're right - a $3k k80 is generally inferior for most DNN applications than a $1k Titan X. The primary reasons that big companies use K80s have to do with achieving high computational density, and licensing issues, more than the performance of a single GPU. Sticking 8 Titan X boards in a machine is a bummer job if you want to pack them closely together. But for academic researchers, a quad Titan X box is pretty solid and quite affordable.
A quad Titan X is still $4k for the GPUs alone, and was only possible in the past few months - people might have wanted to get stuff done in the years in between the last generation and the current generation...
> The training setup follows the classic data parallelism paradigm. There are 12 replicas running concurrently on separate machines. Every replica updates the shared parameters asynchronously.
So it's actually 96 GPUs for a model. And they have many languages to train, and probably don't use cheap GPUs, either.
If it's just expensive to train the model, I wouldn't expect that to stop Google. They don't have to do the actual training that often, after all. Right?
They would have to do that for each language (or language pair), but they can afford it. I think the training the network is cheap compared to running it for user queries, at Google scale.
What’s " If you look at Ursula von der Leyen and Jean-Yves Le Drian before the meeting of defense ministers in Bratislava, one might think that Berlin and Paris would never prefer liked." supposed to mean?
Or "Individual states can not prevent the European Council may decide by a qualified majority, the SSZ."
I think you're getting downvoted because you picked one of the hardest language pairs there is for machine translation. German grammar is really hard to parse, e.g. verbs being split with one part at the beginning and the other at the end of the sentence. Generally, figuring out which part of the sentence refers to which other part is quite hard.
Google Translate works a lot better with many other language pairs, so people might be downvoting because your opinion sounds exaggerated and doesn't line up with their own experience. It's also quite dismissive of the submission, which is never nice. The guidelines ask us to "avoid gratuitous negativity". I often find your comments to be quite negative, often unnecessarily so.
The French/English language pair was the problem machine translation research started with and has seen the most work. There are also greater similarities than most language pairs between those two due to the Norman conquest in 1066.
I accept your first point, but I disagree with your second - 1066 and all that notwithstanding, English is still very much a Germanic language, and grammatically very different from French.
You're right; I was arguing that French and English are more highly correlated than a pair of languages chosen uniformly at random and therefore easier for MT, but I could have made that more clear. I think the difference in accuracy between English <--> French and English <--> German does largely come down to historical academic preferences and data availability, as opposed to linguistic reasons. English <--> French vs. English <--> Mandarin (for example) is a different story.
There is clearly a lot of room for improvement. This is what I got translating from Russian:
I personally think that this program is not so bad works. Sometimes she makes mistakes, but this is fairly rare.
The grammar is bad, but you can understand the meaning here.
Some people don't realize it, but perfect translation is actually an "AI-complete" task:
For example, "program" is a "she" in Russian and "it" in English. To translate such pronouns correctly (among other challenges), one needs to figure out what they refer to, and for that one needs common sense.
That actually seems pretty impressive for machine translation. Also, you have to look at the rate of improvement in machine translation -- not so long ago, it was much, much worse. And Google is leading the pack here, and due to the rate of improvement so far (and this article!) we expect it to continue to improve, and it is exciting and positive to see this improvement, and surprised that we're being told how the improvement is performed!
What do you propose as an alternative? Human translation of everything and no research in machine translation?
I don't think that matters will improve unless machine translation systems are built which understand the meaning of the words in the text which they are translating, and know the grammar of the source and target texts, just like people do.
On French > English and English > Spanish it's almost indistinguishable from human translations. On the rest it still gets greater than half the distance between the previous best method and human quality translations. This is a massive step forward.
"If you look at Ursula von der Leyen and Jean-Yves Le Drian before the meeting of defence ministers in Bratislava, you could never have liked to have liked Berlin and Paris."
which is still doesn't convey the true meaning of something like: "you might think Berlin and Paris had never liked each other more."
However, the second sentence comes out as:
"Individual states cannot prevent this: The European Council can adopt the SSC by a qualified majority."
which is significantly better than Google translate.
This is not (at the time of publication) the production backend for Google Translate:
"In addition to testing on publicly available corpora, we also test GNMT on Google’s translation production corpora, which are two to three decimal orders of magnitudes bigger than the WMT corpora for a given language pair. We compare the accuracy of our model against human accuracy and the best Phrase-Based Machine Translation (PBMT) production system for Google Translate."
It’s crazy how bad Google translate is, try it with any German text, and you’ll get 90% understandable garbage out.
But that could have more to do with how crazy the German language is ;)
Downvoter(s): German sentences -are- intrinsically more complex ("crazy") on average, than English sentences. This is a known, and fairly basic point. So it's not surprising that they should be correspondingly difficult for translation algorithms to "chew on", and provide 1-1 mappings for.
"In addition to releasing this research paper today, we are announcing the launch of GNMT in production on a notoriously difficult language pair: Chinese to English.... we will be working to roll out GNMT to many more of these over the coming months."
interesting news for all the translation startups... like yc's unbabel.
"Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system."
Does this mean that after checking the translation by a human it becomes 60% better than the phrase-based production system? (by which they presumably mean Google Translate...?). That seems rather disappointing.
I interpret this to mean "new system delivers 60% improvement. 'How did we measure this improvement?' you ask? Well, we asked humans to evaluate the old system and the new one."
I've been attempting to use this system for a while today to converse with a native Chinese speaker and it seems to be better but still very far from human-level translation. Maybe they've been using especially bad human translators in their comparisons?
If its performance is dependent on proximity of words in the sentences of the two languages, its output for Chinese would be better than you'd otherwise expect. Chinese and English have similar word orders (though the underlying grammar's different).
{kind=link}
The paper has lots of information about: neural network architectures, parameter update equations, learning rules, and inference algorithms.
There is nothing about: part of speech categories, relative clauses, morphology, affixes or compound words, the theta criterion, the content/function distinction, verb tenses, agreement, or anything else related to actual linguistic phenomena.
To me this seems a bit like the Aristotelian thinkers who tried to reason about physics based on pure mathematical analysis, without any empirical work.