I am using a LaTeX pipeline for creating text, invoices, forms, etc. from snippets stored in a database. It was quite complicated to set up, but the results are very satisfying. In principle, I would like an easier markup language, but am afraid to wast my time trying out something new, just to run into limitations after awhile.
Here are my most important requirements: Multiple columns configurable for meaningful column and page breaks (minimum number of lines in a new column or page). Reliable automatic hyphenation for multiple languages (at least English and German, perhaps French, Italian and Spanish in the future). Pictures in columns with dynamic placing according to the available space. Complex tables and forms with sensible automatic page breaks. Background images. Different areas on the page which are treated like mini-pages. -- Is Typst capable of all that?
Now, this isn't really an alternative, but I can recommend using pandoc instead of pure LaTex. Personally, I think text blocks are much easier to handle and read in markdown and pandoc allows you to use in-line LaTex wherever markdown is insufficient, without making basic text styling unnecessarily verbose. In my opinion, the result is a better/friendlier LaTex, or limitless markdown respectively. Especially for writing papers and such, you can always start actually writing in basic markdown, which is trivial and almost-WYSIWYG, and later worry about presentation. In my experience, with pure LaTex you easily get lost in sidequests and it's much harder to get into a writing flow and find your way around your own words in the editor.
I wrote my dissertation this way. As long as you’re already comfortable with latex, it’s amazing. Huge time saver not to have to write latex formatting when you don’t have to, but an equally huge time saver to be able to control formatting when you need it.
It's a bit of a weird thing, really. I think, I have not seen any comprehensive, basic tutorial on the matter. I presume a lot of people who've become victim of the LaTex bug, but dislike its overhead, independently found bliss in this pandoc compromise. It's definitely a bit of coping with LaTex Stockholm syndrome, you probably need a specific set of experiences, know some struggle to fully appreciate it.
If anyone here hasn't messed with it, but thinks "I wonder, if LaTex could ruin my life, too", I suggest to start learning pandoc first (it can do various markup conversions, it's useful by itself). Get familiar with pandoc metadata headers on a RTFM basis. A LaTex intro is all you need after that, if you are up for a bit of trial and error. Or learn LaTex first, but not both at the same time, as the layered processing involved is a bit confusing (e.g. pandoc showing pdflatex errors). In any case, I strongly advice to bite the bullet and install the full LaTex package of your distro (no idea about macOS, or windows), as fighting dependencies is suuuper annoying. However, the trade-off is it's truly a behemoth, consequently frequent upgrades for a lot of packages you don't ever use. (I configured dnf to download upgrades automatically, so I can do a quick `dnf upgrade --cacheonly` when opportune.)
Speaking of... I wish pandoc could do Tex package management and dependency resolution.
I ended up just downloading the texlive image and letting it go slightly stale while I wrote. Latex plays poorly with OS package managers and I decided I preferred to be out of date.
I made each chapter a separate file and compiled each one to latex. I had a top level latex file that did an \include{} for each chapter, and a big old Makefile to tie everything together, including figure generation.
All this, and it was still easier than writing every latex command by hand.
If you're going to do this, might as well go with AsciiDoc instead. It's vastly superior as a syntax. Markdown breaks down at the mere mention of something as trivial as a nested list item containing a table of blockquotes.
Not that it couldn’t be trivial in the abstract, but I’m struggling to imagine a use for a nested list item containing a table of blockquotes. It doesn’t seem at all surprising that a tool wouldn’t anticipate that.
Absolutely! The writers are generally not highly technically experienced, but have to produce highly technical documents that need to be regularly reviewed and changed for years at a time.
If you're going to do this, why not generate Pandoc ASTs directly? You can do so from a number of languages and they support (by definition) a superset of any given markup's features, with blocks to call out directly for things you can only do in Latex.
I assume the original question is asking about programmatic document generation, in which case working with a real AST is probably also a productivity and reliability win as well.
> "given this winning streak in particular, what's the probability of him cheating in this set of games"
I think the problem lies in the antecedent. Given all chess tournaments played, how often would we observe such a winning streak on average? If the number of winning streaks is near the average, we have no indication of cheating. If it is considerably lower or higher, some people were cheating (when lower, than the opponents).
Then the question is, whether the numbers of winning streaks of one person are unusually high. If we would for example expect aprox. 10 winning streaks, but observe 100, we can conclude that aprox. 90 were cheating. The problem with this is that the more people cheat, the more likely we are to suspect an honest person of cheating as well.
Again, this would be different if the number of winning streaks for a particular person were unusually high.
Cause the codebase wasn't in my scope originally and I had to review in emergency due to a regression in production. I took the time to understand the issue at hand and why the code had to change.
To be clear, the guy moved back a Docker image from being non-root (user 1000), to reusing a root user and `exec su` into the user after doing some root things in the entrypoint.
The only issue is that when looking at the previous commit, you could see that the K8S deployment using this image wrongly changed the userId to be 1000 instead of 1001.
But since the coding guy didn't take the time to take a cursory look at why working things started to not work, he asked the LLM "I need to change the owner of some files so that they are 1001" and the LLM happily obliged by using the most convoluted way (about 100 lines of code change).
Thank you for your explanation. I wondered what might motivate someone to devote so much time to something like this. An emergency due to a regression in production is, of course, a valid reason. And also thank you for sharing the details. It brought a sarcastic smile to my face.
The quality of the maps depends on the region, though. But for me it is typically good enough. I not only like the local maps, but also that I can save waypoints locally. And I can contribute things like points of interest to Open Street Map directly via the app. In my opinion, the biggest disadvantage is that there is no traffic information.
Interestingly, f-droid doesn't initially show CoMaps but does show Organic Maps because apparently CoMaps doesn't pass an antifeature filter for depending on a tethered service on codeberg. I don't quite understand why this is an issue; they both need to download their maps from somewhere, don't they?
Thanks for recommending. I was not aware that a fork of Organic Maps had been created, or that longtime contributors to OM had concerns about the project.
Another vote for Organic Maps. I use it as a lightweight maps app for backcountry or traveling in foreign countries where I don’t have a sim card. You can also record tracks in the app, or import .gpx files. In airplane mode it has low impact on battery consumption.
I was also pleasantly surprised to find out iOS Star Chart app (https://apps.apple.com/us/app/star-chart/id345542655) functions entirely offline. Recently used it while camping, and it just needed a GPS coordinates fix to adjust sky map to location.
// Automatically iterates through all the user's
// departments and assembles a single list of all
// their employees.
Perhaps a note should also be added explaining why the domain model opted for u.departments and not for something more natural like u.company.departments. And the comment should also explain, why we do not filter for duplicates here.
I insert many such comments into my own code when I use a rare language feature or a somewhat peculiar element of the domain model. This makes refactoring my own code much easier, faster and more bug-resistant. When composing code, it is generally simple and quick to add such a comment, as it is merely a matter of writing down the result of my immediate thought process.
Id argue the function name and placement are bad. I have coworkers that arent in my department. If its not obvious what the method is doing from the name and requires a comment then its a bad name.
I would say that this is only true for very, very simple use cases. Even moderately complex code should at least be accompanied with a concise documentation. Here is an example from my work:
Consider the case were two database fields should either both be NULL or both must have a value. Instead of 'amount' and 'currency' and documenting the relation, should we really name the fields 'amount_if_currency_is_not_null' and 'currency_if_amount_is_not_null'?
And is it really sufficient to define 'amount' as INTEGER without any documentation and then demand that everyone new to the project and not familiar with financial calculation immediately understands that the value is given in the lowest unit of the associated currency, i.e. cents for US dollar vs. one hundred millionth of a bitcoin vs. Icelandic króna (which has no subdivision).
Good luck to find a short name that makes that obvious.
One of the best things Germany ever did. We already have produced enough poison for a million years. Renewables and perhaps nuclear fusion is the future.
Radiation poisoning. Fossil fuels fall into the same category. The alternative is not nuclear vs. fossil. We should focus entirely on renewable energies. Of course Germany is now in a transition period, and there are a lot of conservative politicians who have been shying away from the high investments required for a fast transition. I think the main problem here is that the fossil-nuclear advocates shift the main problems to future generations (climate change, long-term storage of nuclear waste), the general public (large subsidies, minimal security standards, no or unsufficient insurance of power plants against desasters) or other countries (placing nuclear plants or waste deposits at the border, relaying on other countries for long term storing of nuclear waste). Together with extremely optimistic estimates, this makes their energy costs appear low on paper, when in reality the overall costs are immense. In contrast, there do not appear to be many cost elements of renewable energy installations that can be concealed or embellished. The reserve funds for their demolition are perhaps the only exception. But these only account for a small part of the costs at any rate.
And nuclear could have drastically reduced that production of "poison" by the way. Arguments about how much we've contaminated with X are sort of immaterial to arguments in favor of a different thing with its own much more specific (and useful) dynamics.
It's a bit absurd, what you say, like arguing that it's good to stop using a stove in your apartment and just eat food raw, because one of your neighbors already did enough bad because they burned their entire house down while trying to make a bonfire with piles of coal in their yard.
Using renewables makes a lot of sense, but the sun doesn't shine all the time, you can't control the wind or the rain, and batteries don't have unlimited capacity. You still need something that starts producing electricity at a flip of a switch. Fusion might do that in the future, but until then, you'll be burning coal or something like gas (which you don't have locally) because the alternative isn't perfect?
Geothermal energy is constantly available. Offshore wind parks can provide a stable basic supply. Energy storage and grids that connect distant places can mitigate local variability a lot.
I would not advocate against having some fossil emergency backups. I think the planet can cope with a few percent of that. If this were our only concern, then we would have basically solved the problem.
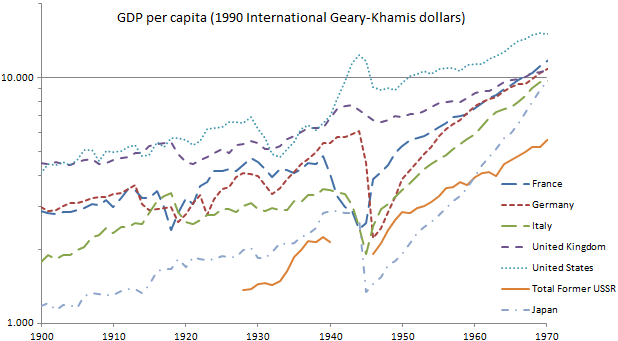
East Germany definitly never was. And even West Germany was considerably behind the UK in per capita GDP in US$ after WW2.[1] It had catched up at around 1970. Since 1970 the two were roughly equivalent: some years one was ahead some years the other.[2] However, Germany is now considerably ahead of the UK in terms of per capita GDP measuered in PPP (ie. adjusted to local prices: aprox. 20% now, or 10 to 15 years (depending on your reference point).[3]
> East Germany definitly never was. And even West Germany was considerably behind the UK in per capita GDP in US$ after WW2.[1]
Germany was behind the UK even before WW2. Just the UK outproduced Germany in (e.g.) aircraft production, and that was even before the US got involved.
Yep. -- I noticed that the first link of my comment is somehow not working. Here is another reference for those who want some numbers. It is a German publication ("Deutschland in Daten", PDF) but the relevant tables should be understandable anyway:
For GDP per capita in "International dollar"/"Geary-Khamis-Dollar" for Germany, France, Italy, Japan, Great Britain, USA in the period 1850-2019, see p. 312 and 313.
According to this publication, 1930, 1940 and 1950 the German GDP per capita was about 75% of that of Great Britain. However, there was a big dip right after 1945 shown in the second table.
The German "economic miracle" ("Wirtschaftswunder") of the 1950s and 1960s was in essence not an outperformance of other western countries in absolute terms, but a catching-up process with them. The same holds for Japan. The process lost momentum, when parity with most of the other major economies was reached.
However, the USA have always been considerably ahead since WW2. -- So much to the slogan "Make America great again". It seems to be based on a very distorted self-image of having a backward economy, for which I have no sound explanation as an outside observer. And even if it were not about the general economic situation, but about a growing disparity inside the country, then a solution to better the situation, when the country is already so much ahead economically, cannot come from outside, but must be domestic.
I have long desired such a language feature. It is a great addition to the language, because a single such expression helps to avoid potential bugs caused by mismatching double references in the conditional test and the execution statement of the traditional version, especially when refactoring longer code blocks.
For example, if we have something like this:
if (config?.Settings is not null)
{
... Multiple lines that modify other settings.
config.Settings.RetryPolicy = new ExponentialBackoffRetryPolicy();
}
and we introduce another category SpecialSettings, we need to split one code block into two and manually place each line in the correct code block:
if (config?.Settings is not null)
{
... Multiple lines that modify other (normal) settings.
}
if (config?.SpecialSettings is not null)
{
... Multiple lines that modify other special settings.
config.SpecialSettings.RetryPolicy = new ExponentialBackoffRetryPolicy();
}
With the new language feature the modification is easy and concise:
config.Settings?.RetryPolicy = new ExponentialBackoffRetryPolicy();
becomes:
config.SpecialSettings?.RetryPolicy = new ExponentialBackoffRetryPolicy();
and can be made for any other special setting in place, without the need to group them.
Furthermore, I find the "Don't Overuse It" section of the article somewhat misleading. All the issues mentioned with regard to
if (customer is not null)
{
if (customer.Orders is not null)
{
if (customer.Orders.FirstOrDefault() is not null)
{
customer.Orders.FirstOrDefault().OrderNumber = GenerateNewOrderNumber();
}
}
}
or:
if (customer is not null)
{
var orders = customer.Orders;
if (orders is not null)
{
var firstOrder = customer.Orders.FirstOrDefault();
if (firstOrder is not null)
{
firstOrder.OrderNumber = GenerateNewOrderNumber();
}
}
}
If it really were a bug, when customer is null here, etc., then it would of course make sense to guard the code as detailed as described in the article. However, this is not a specific issue of the new language feature. Or to put it more bluntly:
{kind=link}
Here are my most important requirements: Multiple columns configurable for meaningful column and page breaks (minimum number of lines in a new column or page). Reliable automatic hyphenation for multiple languages (at least English and German, perhaps French, Italian and Spanish in the future). Pictures in columns with dynamic placing according to the available space. Complex tables and forms with sensible automatic page breaks. Background images. Different areas on the page which are treated like mini-pages. -- Is Typst capable of all that?
reply