This meme is a silly amateur-hour wheel re-invention and ignorance of history.
The fact is, pre-forking a pool of processes without implementing a per-process multiple-connection event mechanism is going to be grossly inefficient in terms of memory utilization (ie, you need to use select, poll, kqeueue, etc.).
You can claim otherwise (COW pages et al), but history is not on your side (look at the scalability of existing pre-fork/connection-per-process network daemons). Think about it -- how much of the runtime can truly be shared across connection handlers?
The fact that this model doesn't scale is not news. It doesn't require rediscovery. It shouldn't be surprising. Anyone who has run Apache, sendmail, or any 80s/90s networking software -- much less authored something similar -- will know better.
Moreover, there's nothing wrong with threads -- threads are a low-level tool that can be used to implement high-level concurrent systems. They're cheaper than processes because they do support mutable state where it's useful, but you don't have to use fork() to avoid avoid mutable state.
If you don't want shared mutable state (and you don't), then don't use it.
> This meme is a silly amateur-hour wheel re-invention and ignorance of history.
Just a note on the tone of the discussion:
Everyone is a silly amateur at one stage when learning something – there is nothing wrong with it. You have to do things that are silly and immature to learn. Most of us did some silly things in areas where we are not yet specialists.
I think it's a responsibility of everyone in any scientific or engineering field -- specialists and "not-yet-specialists" alike -- to think long and hard about advocating an approach without studying the large body of academic and practical work that exists for nearly every subject imaginable.
Yet, on the other hand, the first versions of Linux were written without consulting the extensive literature (which was all about microkernels) [1].
As another example – a guy studying with me made his own circuit boards (had his own acid production line project going on in his dorm room). You would never use such a circuit board in any professional setting. Yet he learned a lot about other stuff with his electronics projects.
Sometimes the goal of learning isn’t really implementing something directly. As an example, a recursive function isn’t really the best way to calculate Fibonacci numbers. If someone wants to learn about forking by writing a simple web-server thingy then it may be a good idea?
Most of these projects were probably done in their free time. Who would be the better programmer – the guy that wrote this, or the guy that knocked back a beer and sat in front of the TV?
[1] I am not an operating system expert, but this is at least the impression I got after reading the flame-wars email.
Yet, on the other hand, the first versions of Linux were written without consulting the extensive literature (which was all about microkernels) [1].
In the early 90s nearly all of the operating system research was going into Microkernels, but there was already 30+ years of standing research to borrow from (and Linux very much did -- the fact that it's similar enough to run the same software as Solaris and BSD systems is not due to spontaneous re-invention).
Despite the fact that Linux and the BSDs did not adopt the microkernel architecture -- and pure microkernels, for most purposes, died out -- quite a bit of value did come from that research, such as the Mach VM system, which was then borrowed by 4.4BSD operating systems and others.
Most of these projects were probably done in their free time. Who would be the better programmer – the guy that wrote this, or the guy that knocked back a beer and sat in front of the TV?
Rather than taking an incredibly assertive but misguided blog post at face value (and propagating it further), what is wrong about reading the widely available, easily discovered literature and implementing an event-based/event+thread-based implementation instead?
You've spent a lot of effort commenting on this post, and I think you've missed the point entirely. In Jacob's and Ryan's originals, the point wasn't to assert that preforking is the right way to structure a server -- that's not really the salient issue. (And I'd suspect that these two -- serious Web devs who are familiar with deployment -- probably are well familiar with {epoll, select, kqueue}-based and similar non-blocking, concurrent I/O servers.)
The point was that, as Rubyists and Pythonistas and Perl hoo-has, we shouldn't be afraid to delve into POSIX syscalls and take advantage of the wealth of functionality they provide, and that our languages have thin wrappers over those bare syscalls that make it easy to write idiomatic code that utilizes them.
The examples were echo servers, for murphy's sake -- are you really worried that we'd have a rash of poorly-thought-through, inefficient echo servers bogging down poor servers across the Internet? They're clearly intended to be simple examples about syscalls not the (yes! very important!) issue of how to handle concurrent connections efficiently.
And I'd suspect that these two -- serious Web devs who are familiar with deployment -- probably are well familiar with {epoll, select, kqueue}-based and similar non-blocking, concurrent I/O servers.)
Given the self-professed low level of familiarity with UNIX systems programming, I don't image that to be the case.
The examples were echo servers, for murphy's sake -- are you really worried that we'd have a rash of poorly-thought-through, inefficient echo servers bogging down poor servers across the Internet? They're clearly intended to be simple examples about syscalls not the (yes! very important!) issue of how to handle concurrent connections efficiently.
The original post was a strong assertion that fork(2) is correct, and threads are not. The follow-up posts in the 'meme' stretched this idea (with great elation) to fork(2) as a general network concurrency model.
This sort of public disinformation does strongly influence future technical decisions.
Disagreed - it's the responsibility of those who are professionally or academically publishing such materials, not "everyone." It's also important for readers to consider their sources and realize that personal blogs are hardly to be taken at face value.
Publishing things that are imperfect or incorrect is essential in order to get feedback and to improve. If it were necessary to do significant study before making a blog post or a similarly ephemeral statement, hardly anyone would bother and the field would be dead for lack of newcomers.
Publishing on a blog is still publishing, not a short-lived ephemeral aside to an audience of peers.
The fact that this misguided meme was picked up here and echoed rather widely over days is indicative of the non-ephemeral impact of blogs, despite how you (or I) believe they should be perceived.
It would be bizarre if you would only make a blog post after "studying [a] large body of academic and practical work" relating to the content. Almost no-one outside of an elite of developers or researchers would have the time, let alone the inclination.
I'm glad people - amateurs and professionals alike - have the freedom to publish what they want. There are cons ("reader beware!") but the pros outweigh them. If I want peer reviewed scientific papers, I know where to find them.
It would be bizarre if you could only make blog posts after "studying [a] large body of academic and practical work" relating to the post. Almost no-one outside of an elite of developers or researchers would have the time, let alone the inclination.
Reductio ad absurdum; you don't need to read the compendium of human knowledge -- spending an afternoon with Google getting a solid grasp on the state of the art is usually enough to get started.
For most subjects, there's even a seminal book that's easily acquired.
I'm glad people - amateurs and professionals alike - have the freedom to publish what they want. There are cons ("reader beware!") but the pros outweigh them. If I want peer reviewed scientific papers, I know where to find them.
Yes, and we're also free to point out significant fallacies, as well as ignorance of standing research and implementations. This is healthy.
What I said left the definition of 'study' up to reasonable interpretation.
You chose to interpret 'study' as an absurd application of labor leading to undesirable consequences, and then argue against it. In the sense of non-formal logic, 'reductio ad absurdum' applies.
This meme is a silly amateur-hour wheel re-invention and ignorance of history.
Yeah, well fuck you too.
As it turns out, I am an amateur, at least when it comes to POSIX, but more importantly I find this stuff fun. I hadn't realized that having fun and learning about new topics was such an offensive thing to do.
Maybe this is just frivolity, but it's surely a better way to spend a few minutes than crapping all over somebody else's fun.
Right on. I'm all about learning, sharing knowledge, and having fun. Kudos to you and Ryan for having the balls to study in public.
What I find interesting, and somewhat alarming, though, is that experienced web developers such as yourself seem to only now be learning the fundamental, bedrock principles of how the technology you use every day actually works.
Maybe it's because high-level abstractions weren't widely available, or because the books I had on hand were Stevens' classics, but I learned network programming starting with socket(2), and to this day still ask what each of socket/bind/listen/accept do when I'm interviewing sysadmins, much less developers.
It's remarkable to me that a whole breed of web developers today might not have any exposure to networking below the HTTP stack offered by their favorite programming language.
Off-topic but...we need a proper computer science/programming collection of papers, books, etc. built up so that people can go off and learn things from the past instead of learning about them independently and then spawning blog posts about it.
For learning this side of Unix, I've found the following very helpful (note that this is a bit BSD-centric):
1. _The Unix Programming Environment_ by Kernighan and Pike. The best overall intro to the pipes, shebangs, and other assorted command line stuff in Unix. Very old school, but still very relevant - those are the root of many of Unix's strengths. (K&P's _The Practice of Programming_ is also excellent, though not as specific to Unix.)
2. _Advanced Programming in the UNIX Environment_, 2nd ed., by (the late) W. Richard Stevens. This and man pages will go a long way.
3. The man pages themselves. It's generally understood that OpenBSD's man pages are particularly well written, but if you're using Linux and the GNU userland, there will be lots of differences in the details.
4. The 4.4BSD "Programmer's Supplementary Documents" (PSD) - This is a collection of papers and man pages. While some are out of date, and some are mainly of historical interest, the introductions to tools such as make, lex, yacc, gdb, etc. are quite good, and often a tenth the length of the corresponding O'Reilly book. (These papers may be installed with your distro. OpenBSD has them in /usr/share/doc . I bought the book used for a couple bucks.) There are also "User's Supplementary Documents" (USD) and System Manager's Manual (SMM) collections, with papers on configuring sendmail, using vi, etc.
5. _The Art of Unix Programming_ by Eric S. Raymond - I recommend this one in spite of finding ESR incredibly irritating. It's a very good conceptual overview of the big design ideas in Unix and their ramifications, albeit one interspersed with narcissistic soapboxing by the author.
In general, using a Linux distro with a strong emphasis on having a friendly GUI layer can keep you at arms length from really learning Unix. Dig around in /etc. Learn to use cron and ed. (No, really.) Get your hands dirty.
I would also highly recommend learning a scripting language that integrates well with C (some people like Perl, Python, or Ruby, I prefer Lua), because really using Unix well is going to involve some C. Working with C isn't scary unless you're trying to build a large system in C - try instead to break it up into a suite of smaller programs, rather than one monolithic one. Take advantage of pipes and all the other existing Unix infrastructure. It's there to help keep complexity at bay.
For Unix systems-level/network programming, I'd also add to the list:
1. UNIX Network Programming: Networking APIs: Sockets and XTI; Volume 1 (W. Richard Stevens) - the books is considered the bible of the BSD networking APIs, and if you're interested in writing network software at any scale, in any language, you should start with this book -- everything else builds from here.
2. Write Great Code: Volume 1: Understanding the Machine (Randall Hyde) - At the end of the day you're writing code that will execute on a machine. Understanding how the machine works will help you understand your code.
3. The Design and Implementation of the FreeBSD Operating System (Marshall Kirk McKusick, George V. Neville-Neil) - If you've ever wondered how copy-on-write pages work (some of the magic behind the fork(2) model), or how your processes get scheduled, this is a good place to start -- even if you aren't using a BSD, the tenants hold.
Computer programmers are never taught how to read papers. Someone should write a paper on how to read computer science papers.
(For me, the issue was with getting over the "this is too hard for me" mentality. Some papers are hard, but you have to read them once, keep them in mind, and then read more. Then come back to the original paper, and it makes sense. The first paper that I noticed this effect on was "Applicative Programming with Effects". The first time I read it, it made no sense. Functor? Application? Category? A few months later, I read it and thought "this is brilliant". Like everything, practice makes perfect.)
As an aside, you can usually find a lot of papers behind the ACM paywall by searching on CiteSeer or Google Scholar, particularly searching with the authors' names.
If you find a paper hard to follow, start with the others it references. I've found a few niche papers that were worthwhile just for their bibliographies. (I didn't know what the issue was typically called.)
It's a wiki where people can summarize published papers (both publicly available and paywalled). Seemed like a good idea, both for people to practice summarizing what they've learned and for quickly finding relevant papers.
Sure, but people will still rediscover things independently, unless they choose to read everything ever written before actually doing anything.
I don't think that blog posts (or any form of writing) needs to be restricted to sharing new information only. Writing can serve as a mechanism for demonstrating what you have learned to potential clients/customers... it can serve as a means of solidifying concepts in your own mind... it can serve as a journal to help you remember things you were thinking in the past.
We need a snappy name like "analysis paralysis" that is focused on people who spend all their time studying rather than doing. They (we) intend to do, but never fell like they know enough to start.
I think most of the reaction to your response was due to your tone. I've seen a lot of blog posts where someone was mind-bogglingly astray* , and coming in saying "You're all wrong, you idiots, they solved this problem in the 70s, ..." just makes people ignore you. I think suggesting leads for further exploration (in this case, libevent, nginx, etc.) is more helpful, without being a slap in the face.
* Whereas this series seems to be people getting excited about using Unix syscalls from their preferred scripting languages, probably for the first time.
Indeed. I hate to contribute to this, but when I get home, I am going to blog about my coroutine-based echo server. Fewer lines of code than the original, scales linearly over active connections (and constant time over idle sockets), and my tiny eeepc laptop can easily handle 1,000,000 open connections.
use EV;
use Coro;
use Coro::EV;
use Coro::Handle;
use AnyEvent::Socket;
tcp_server undef, 1234, sub {
my ($_fh, $host, $port) = @_;
# this makes <>, print, etc. non-blocking on $fh
my $fh = unblock $_fh;
# this creates the new thread
async {
while(my $line = <$fh>){
print $fh $line;
}
};
};
EV::loop;
This code, a client and alternative server implementation are available on github for perusal:
I do not have time to write up the details now... but basically, I run out of file descriptors before the client or server use a measurable amount of memory. This is around 30,000 connections. With 100 connections, it does around 8000 requests a second (client and server on same dual-core machine). With 30,000 concurrent connections, it does about the same. That is O(1) at its finest. (The 1 is the 1 connection we are actively using in the client.)
The EV-only server in the github repository performs about the same, but keeps track of all the open connections so you can trivially shutdown the server cleanly.
While I agree in general, there are of course exceptions. "look at the scalability of existing pre-fork/connection-per-process network daemons" -- exactly, look at SER/opensips/kamailio - while they work on a per-packet, not per-connection basis, the architecture is mostly the same - fork a pool of processes on startup and share the sockets. And they could probably still handle a small city's phone connections on a single average machine ;)
Well, not exactly. Per-event delegation of processing to subprocesses (as in the case of opensips) is an multiple-connection-per-process event-based model. It's also a very complicated way to achieve it, and not what's being discussed in these "... is UNIX" blog posts.
I attempted to address both pre-fork and fork-per-request above -- both involve mapping one connection to one process -- this is resource intensive, and should be replaced with more modern event-based multiple-connections-per-process (select, poll, kqueue, etc.) approaches.
Ok, just so it's clear that Apache's prefork mpm forks to handle concurrent connections, but does not simply fork() each and every time a new connection comes in, which some people naively believe. It does use select to handle requests that are arriving, and then farm them out.
This model does scale pretty well though - you can saturate a T1 with Apache just fine. Also, it's a pretty decent model for when your connections are causing something to do work (like running a script which hits a database). If you have everything in one big poll()-happy process, you still have to farm things out to separate processes if they risk blocking. Well, unless you're using Erlang, which has a scheduler of its own so that its processing doesn't block.
Moral of the story: event based servers are faster/smaller/more efficient when it comes to serving static content. When you start doing more than that, things get more complicated and you generally need to offload work to processes/threads/something in any case.
Which is one reason why Apache has always been quite popular, despite the presence of whichever select/poll based server du jour.
I love an in-depth, technical blog post as much as anyone, and kudos to Ryan for dissecting Unicorn, but I didn't know whether to laugh or cry when I read that Unicorn has, "teh Unix turned up to 11". zOMG! fork!
This series of blog posts underscores my point that the Rails community, perhaps the Web 2.0 community at large, is just now learning things the rest of us have known for years. accept(2)-based pre-forking socket servers are not news.
The alternative to preforking is select(2), which lets you get away with a single-process server and avoid IPC in certain scenarios: http://www.lowtek.com/sockets/select.html
I think Boa and thttpd use select instead of forking for clients.
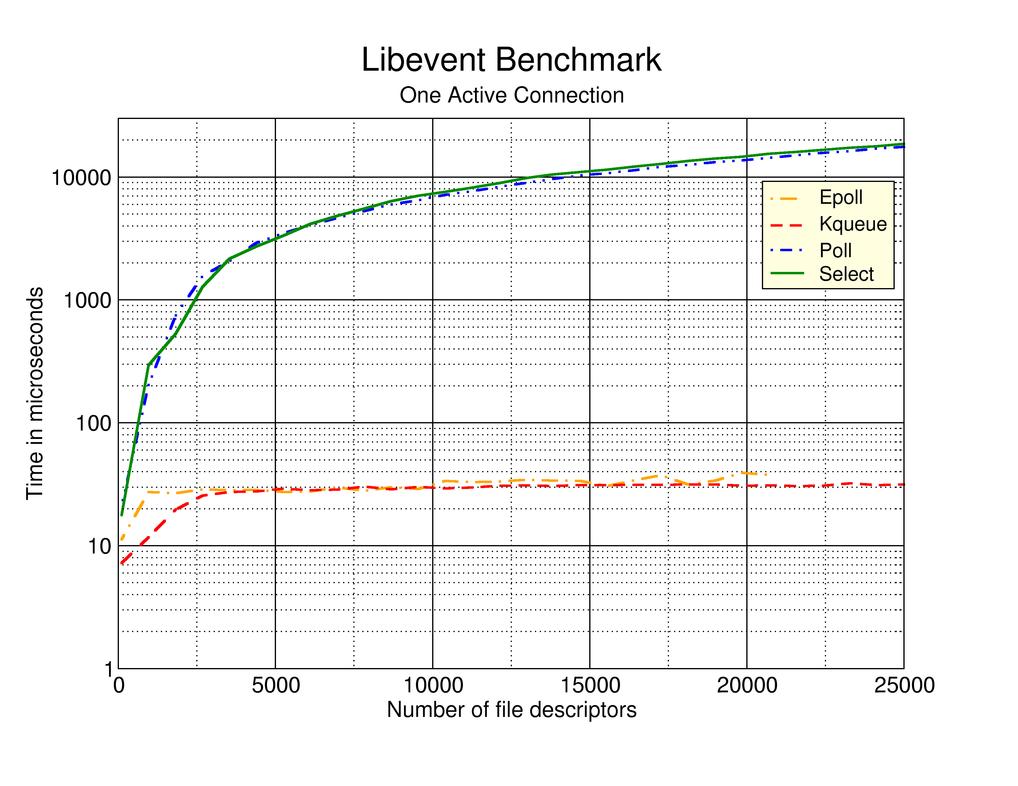
select doesn't scale particularly well, though. (And I'm not wild about its interface either; poll conceptually similar but much nicer to program to.) http://www.kegel.com/c10k.html (a now fairly old document, by internet standards) discusses a number of other options.
{kind=link}
The fact is, pre-forking a pool of processes without implementing a per-process multiple-connection event mechanism is going to be grossly inefficient in terms of memory utilization (ie, you need to use select, poll, kqeueue, etc.).
You can claim otherwise (COW pages et al), but history is not on your side (look at the scalability of existing pre-fork/connection-per-process network daemons). Think about it -- how much of the runtime can truly be shared across connection handlers?
The fact that this model doesn't scale is not news. It doesn't require rediscovery. It shouldn't be surprising. Anyone who has run Apache, sendmail, or any 80s/90s networking software -- much less authored something similar -- will know better.
Moreover, there's nothing wrong with threads -- threads are a low-level tool that can be used to implement high-level concurrent systems. They're cheaper than processes because they do support mutable state where it's useful, but you don't have to use fork() to avoid avoid mutable state.
If you don't want shared mutable state (and you don't), then don't use it.