Furthermore, what you mean with `Javascript pages supported`?
Could I just specify where it has to click or do I need to make a reverse engineering of the ajax calls?
There is a phantomjs fetcher that can render the page as WebKit did.
Furthermore, you can have some JavaScript running before/after page loaded to simulate a mouse click.
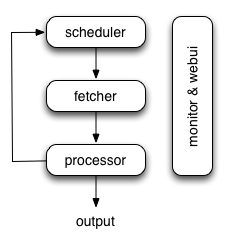
And yes for centralized queue which is in scheduler. It's designed to satisfy about 10-100 million urls for each project.
scheduler, fetchers, processors are connected with rabbitmq(alternatively). Only one scheduler is allowed. But you can run multiple fetchers or processors as needed.
Will it be a good fit if I, running on a hundred servers, need to scrape just the home page of a million sites? No analysis of the pages, that is done later.
{kind=link}
What is the roadmap?
I am really inside scraping, it is one of my daily job. I could consider to integrate it in one of my architectures