I really want to applaud backblaze for publishing these reports and stats. Too many companies closely guard this information that really helps the larger community. Based on the previous blogs from backblaze, when I built out our new hadoop cluster, I purchased 1450 Hitachi drives. I plan to gather our failure rates and publish them as backblaze does.
Thanks for blazing the path!
Yev from Backblaze -> Thanks! That really is one of our goals with these updates, is for others to join us and start sharing this data. It makes a lot more sense if everyone is doing it, then we can start comparing environments, and all sorts of fun stuff!
Have you been able to reach out to anyone at Seagate in their drive FA group to see if they'd be interested in you sending back samples of the failed drives?
Isn't using very similar drives a problem because their failure rates are not statistically independent, so there is an high probability that they will all fail at the same time?
I've seen it. RAID5 with 5 similar disks failed during weekend. All but one drive were dead. Of course disk failure also prevented daily backup run and all hell broke loose on Monday morning. The exact reason of death is unknown. Important fact is that the raid was configured on Thursday. So I guess the same time death is most probable when drives are really new and from same batch.
I saw that once in an array that was on 24/7 for years. 1 drive was failing so they shut it down to replace the drive (perhaps hot swap was not an option?) and almost all of the rest of the drives did not come up. Basically the heads stuck to the platters. Aka "stiction".
I would guess in your scenario something like that happened. Or perhaps trying to migrate tons of data to a new disk caused an issue. Just seems unlikely otherwise.
In practice the only time I've ever heard of something like that bite are serious firmware bugs (i.e. a counter overflow causing drives to cycle after 45 days of uptime - source: I work for a major CDN with a six figure drive count).
There are some statistical properties I recall that will make mechanical failures spread somewhat nicely, maybe someone can elaborate if they have a background in stats.
Yes, there is a concern in getting a bad batch, or having several drives fail all at once. Interestingly enough, while opening those 1450 anti-static cases and seeing the manufacture date of them, they were in separate batches (some with more dust on the cases than others), so we have some heterogeneous-ness on them. HDFS with its various levels of replication factors, and our backups/DR for high-value data takes care of the rest.
Since annual failure rate is a function mostly of age, it would be interesting to see a line chart of cumulative failure rate vs age. But since new drives are continually being added to the population, there would be fewer drives in the data set as you moved up each curve.
I guess you could calculate confidence intervals at quarterly intervals, and so the error bars would get larger as age increases and 'n' decreases.
How would you calculate the CI for failure rate? It's not binomial or poisson, since failure rate goes to 1 over time...
A little searching turns up http://rmod.ee.duke.edu/statistics.htm which I'm sure completely explains how to do this... (rolls eyes). I hate that this is how statistics is commonly taught. Knowing which distribution to use and applying it correctly can actually be intuitive if taught properly. It doesn't always need to be an exercise in alphabet soup / deriving from base principles.
Undergrad version: the lifespan of a single drive should be exponentially distributed with some rate lambda. The time to first failure from among k drives would then have an exponential distribution with rate k * lambda. The confidence interval for lambda is: http://en.wikipedia.org/wiki/Exponential_distribution#Confid...
Grad-level version: drive lifetime is exponential with an inhomogeneous (increasing, presumably) rate function lambda(t). Inferring lambda(t) is difficult without additional assumptions on the functional form. But potentially do-able.
I'm not a statistician, but what you are describing is a situation in which the survival of the "subjects" (SSDs) is the crucial variable. How quickly the population declines is the question.
This is similar to studies in medical research, e.g., how long do subjects live after an experimental cancer treatment. What I've seen used is the Kaplan-Meier non-parametric method (Kaplan-Meier plot) for the purpose.
The "Drives have 3 distinct failure rates" graph is the most interesting, as it shows the result of the expected "bathtub curve" on the cumulative failure rate.
Here's a blog post giving a tutorial on survival analysis using a relatively recent (and IMO very compelling) python library. Could be what you're looking for.
It's been 20 years since I took a reliability engineering class but I believe the go to curve is the negative exponential. Here is a link from a quick Googling:
The exponential lifetime distribution is the model for ideal memoryless failures: the probability of failure in a dt interval is independent of current lifetime and have value lambda*dt. Those are as "random" failures as they get. I suppose hard drives are better modelled by a variable failure rate lamba(t), which should have a peak for the first few hours/days, settle down and then start growing quickly after a few months.
The financial analogy is to think of failure rates in drives as equivalent to defaults on a pool of securities (say mortgages). obviously there are a number of ways to do this but the most simple is that since origination standards for loans vary through time (think build quality and design changes in the drive context) it seems to make sense to think about this from a vintage standpoint. i.e. are seagate drives installed in Dec'12 failing at the same rate as ones installed in March '13 after six months...
One of the challenges I have with this analysis is that a 'failure' isn't just that your drive is no longer working, it is that your drive isn't working and you have to go replace it. The operational costs of replacing a drive have three parts, loss of production while the drive is offline, operator time to physically replace the drive and prep it for re-entry into the system, and transactional costs of doing a warranty replacement (filling out the RMA form, getting a valid RMA, shipping the and receiving replacements). We minimize the latter by doing RMAs in batches of 20 but its still a cost across those 20 drives. (and the population of 40 drives which exist as spares are effectively not available for production). It isn't as simple as 'sure drives fail a bit more often but we don't expect to use them that long.'
That's a good point but also requires a more complicated analysis since it requires you to account for your ops capacity (e.g. the marginal cost increase of doing 10 drives instead of 5 is probably a lot less than 2 unless your ops team is almost completely booked) and also requires some guessing about whether there actually is a better option. They addressed that second point with the discussion of enterprise drives, which certainly matched my own experience.
I don't believe reliability has ever necessarily been an "enterprise" feature.
The concrete features I understand "enterprise" drives as having are:
1) firmware is built with RAID in mind. This might sound weird, but consumer drives are more likely to have problems with RAID, just because they aren't designed for it. See, for example, the first WD Green drives crashing RAID clusters because some timeout was too high.
2) Longer warranty period
3) This may not be true anymore, but I believe they typically feature larger cache
At every sales-pitch I've ever attended, the enterprise vendors mention “reliability” about every other word – the message that your boss will fire you for taking risks unless you buy their hardware is communicated with the subtlety of a solar eclipse.
As for the RAID point, you'd very much want to find real data for that. I've heard similar folklore but have also heard plenty of lost data stories from enterprise disks in enterprise RAID. If I were building out a large storage farm, I'd strongly consider forgoing hardware RAID altogether and using something like ZFS so it'd be observable.
You don't work in the HDD division, right? Someone seriously needs to look into ADM (advanced power management) on your 2.5" drives. It is currently set too low and the drives power down instantly after each instruction, resulting in simply astonishingly terrible IO (and seriously lag spikes).
It is so bad even running HD video off of some 2014 HGST laptop hard drives causes distortion. There's also no way to increase the ADM value indefinitely that I am aware of (it reverts after every sleep).
And thats whats weird, who is the audience for the article? I know what enterprise drive means and I know the author is smart and knows what it means, so why the weird implications in the article that have nothing to do with "enterprise"?
For those not "in the know" the hardware is the same, but desktop firmware drives will sit there for 10 seconds or whatever it is beating the drive when there's a read (or write) fail on the assumption that if your machine only has one drive you're better off trying as hard as possible to keep retrying until it works, and possibly the slowness will motivate them to replace (god forbid an end user have backups lol)
Enterprise firmware, when it has a soft fail, just croaks as fast as possible. That lets the raid array hurry up and do its thing, or maybe even higher level replication do its thing.
(edited to add the old startup adage of "fail quickly". Thats what enterprise drives do to keep overall array latency low, which is counter productive for consumer non-array drives)
Aside from the firmware load the prices are different because usually enterprise has better guarantee and better service and unlike consumer drives which statistically are never replaced under guarantee so you can claim anything on paper for marketing purposes it won't cost anything, enterprise drives WILL get replaced and there will be a papertrail etc. So the guarantee for an enterprise drive actually costs something.
Sometimes the firmware has some other subtle differences like how it handles recalibrates and scrubs (consumer home drives are like "too bad you get to wait on my schedule" and again, enterprise will go to some effort to eliminate array latency)
My guess is the article is subtle astroturf by the winning drive mfgr?
o Enterprise and Consumer Drives are the Same Hardware.
o Enterprise Firmware causes the drive to fail fast on physical errors
rather than endlessly retrying.
o Enterprise Drives are more likely to be RMA'd?
Do you have any citations, evidence, reports, articles, white papers, research - anything (beyond random anecdotes, or miscellaneous blog entries) to back up these claims?
TLER is exactly what you want in a RAID. You have another copy of the data in question on the array, why fight for it on a disk when the data may be corrupt anyway.
Fair enough - that's a good article, though it explicitly calls out "RE" drives - "RAID Edition" - which I can imagine having particularly properties associated with "RAID" behavior.
What I'm interesting in hearing, (honestly - I not doubting right now, just interested in being educated) - is if anyone authoritative has described "Enterprise" drives as having these behaviors.
Do you have any data to back up any of these claims?
Because now I have a problem: should I believe guys who have been running 38 petabytes of storage for several years now and regularly present the data they gathered, or should I believe you?
I've read his blog posts before. He's a good author. I don't believe anything factual/technical in my post disagrees with reality or any of his historical posts.
I am open to the idea I'm misinterpreting how he presents enterprise vs consumer firmware loads. I assume its open knowledge that their secret sauce is using consumer hardware so assumptions about 15K fibre channel isn't relevant.
Enterprise firmware, when it has a soft fail, just croaks as fast as possible. That lets the raid array hurry up and do its thing, or maybe even higher level replication do its thing.
Except that also only works "most of the time".
Anyone who works at scale with drives and (RAID-)Controllers
knows that even "enterprise" drives can and do take
entire controllers down.
It's not uncommon to lose a full set of
daisy chained JBODs to a single disk acting funny.
Consequently, and since storage clusters have to be
redundant at the node-level anyway, it makes a lot
of sense to skip the markup for enterprise firmwares
and instead design for quick node failure detection
and ejection (short timeouts).
"They're never replaced because regular consumers statistically don't ask for replacement and simply eat the loss?"
There is another paradox as well. Some people won't ask for replacement because assuming you have to send in the bricked drive there is the chance that someone might get at your data somehow.
What about that? (It's why I would never send in a drive that has failed.) [1]
[1] My assumption is that I would have to send in the bad drive (and there is no way to reformat or for me to easily destroy what might be on there). Anyone have experience with what happens here?
Question (not a statement). Doesn't encrypting the drive also prevent you from recovering some of the information on the disk by way of drive recovery utilities?
So for example you might want to encrypt something super sensitive (which I do) but decide to not encrypt something less sensitive (say photos or perhaps a wiki with notes or letters to your grandma or wife or sig other).
Point being that if the drive isn't encrypted you might be able to get at some of that data. (If you need to). If you've encrypted the drive then can you still do that?
Yes, the data will probably be completely irrecoverable from an encrypted drive. However, instead of hoping that you will be able to recover data from a broken drive, back it up.
I strongly recommend Tarsnap[1] for that. All your data is encrypted before it leaves your machine, it is run by our very own 'cperciva, and the key used for encryption (which you need to store securely somewhere, like your parents' house or a bank) can even be printed so hard to destroy accidentally.
The key itself can be encrypted, too. You can use the same password you use to encrypt the drive and now you safely and securely store all your data in such a way that only you can ever access it by remembering a single, longer phrase.
(Although to be fair, another backup would probably be a good idea if the data is really important. Maybe another encrypted hard drive kept at work.)
I think that looks good but I have to tell you that the idea of committing data to what appears to be one person who could get "hit by a bus" worries me.
I'd like to see on sites like that some kind of continuity plan.
Unless you are suggestion that this is just another "redundant array of backups that you have to assume can fail".
But even in that case it would be a good idea if cperciva had something posted on the site which showed there was someone else who had access and kept on top of the system.
Yes. I have an old 250 GB sitting on my desk at home. Waste the time arguing on the phone and getting a RMA and package it up and drive out to ship it back to get a "new" 250G drive (uh ... thanks?), or order a new 2TB, about the same cost. And this is only with technologically inclined consumers, most are just going to return the whole computer or get a new computer.
At a business that is probably some MBA metric and has been budgeted for and is salaried anyway, and you need to prove I'm not just taking drives home to put in my basement server, so they have to be destroyed or sent back, and there may or may not be PCI / CPNI type concerns, so yeah, they get sent back.
i am a statistical anomaly, then, as someone who tracks warranty expirations in a spreadsheet and always makes sure to wipe & sell old drives before they go out of warranty. in the 20 years i've owned hard drives, i've always had failed drives replaced!
drives with longer warranties generally cost more in the consumer segment, and data like this could help people identify the "sweet spot" balancing cost with risk of failure, warranty length, and depreciation curves for storage. my "ancedata" suggests somewhere between 2 and 3 year warranties seems about right for consumer drives these days...
In twenty years, how many hard drives have you had, and how many failed? I've had eight or ten (counting home and work) and just one failed. I had one I used daily for over a decade.
I'm not sure who the audience is, but thank you for your explanation of the differences between consumer and enterprise drive firmwares. That runs counter to my naive assumptions, which was that "enterprise" targeted things tend to be of higher reliability and quality than the consumer-targeted alternatives.
I imagine someone in the drive / enterprise storage business would know better, but many of us might not have known that.
Oh I should preface my remarks with "in family, same technology level" etc.
I'm talking about the same package with the same storage where different firmwares are loaded. Thats the business model the OP is in, he makes posts about stripping consumer drives out of external cases and I don't want to speak for him but he radiates the impression of their whole secret sauce being reliability at the system level not the hardware level.
It is true in my experience that "exotic hardware" marketed as enterprise grade is different physical hardware and is going to be a different level of reliability than consumer hardware.
So the difference between an office NAS SATA 1 TB enterprise and consumer grade is a firmware load, and I think thats what the article is talking about. There is a big difference between a 15K SAS enterprise server drive and a 7200 SATA consumer drive at the hardware level, but that's not the article author's "thing".
I think "times have changed" can be generalized into "times will change".
My experience has been that any rule about "brand X is the best" or "brand Y is the worst" only lasts for a short time--each hard drive technology "generation" seems to reshuffle the reliability matrix. Whoever was on top in 2009 has almost no bearing on who's on top in 2014, or who will be in 2019.
At some point, Hitachi Diskstars were referred to as "Death Stars", and that was all I knew about disk reliability. It is great to have some real information.
Dell, Google, and Amazon can never write reports like this because the vendor relationship is important. Because these guys have no relationship and are buying consumer disks, the world finally gets brand level reliability reports. Kudos to Backblaze.
> Dell, Google, and Amazon can never write reports like this because the vendor relationship is important. Because these guys have no relationship and are buying consumer disks, the world finally gets brand level reliability reports. Kudos to Backblaze.
Dell maybe, but Google and Amazon consider what goes on in their data centers to be part of their secret sauce. It doesn't have to do with vendor relationships, it has to do with a competitive edge. Google and Amazon will drop a vendor without a second thought if it's even slightly more advantageous.
If I remember correctly they didn't name names, but Google did publish a very useful paper on their experiences with disks. The two big takeaways were that in only half the disks the self testing signaled a future failure, and manufactures seemed to have solved heat problems.
I had four of the three Death Stars I bought fail (yes one of the replacements failed too). 133% failure rate is quite an achievement. They were great drives when they worked.
Related: Intel's SSD is the only SSD I've ever lost data with. It happened due to a power outage that bricked the drive, and the only reason it happened was because of a flaw in their firmware, not their drive, which they hushed up. I was very surprised because Intel had the reputation of being the best SSD at the time. (It was the 300-something series.)
Don't be ashamed: for a pretty long time Seagates really were very reliable, the 7200.9 and 10 series were a staple in my systems throughout the last couple years. Seagates also used to have a 5 year warranty period. I'm actually thankful that the Seagates I've bought more recently tend to suffer from crib death: better it dies immediately rather than die once I've put my trust in it.
As others have said though, these things tend to go in cycles. One manu. gets a bunch of bum drives, people react and they start cracking the whip on QC. I think it's also a product of what we're asking of our drives today: SSDs are eating away at the low end so their only recourse is to pack more and more data into smaller and smaller spaces leading to a greater reliance on error correction.
I will say though, the BackBlaze report led me to try out HGST drives for the first time and I've been overwhelmingly satisfied with them.
That said, will that trend continue? I guess we'll see when the 2015 report comes out.
Yev from Backblaze here -> No reason to be ashamed! Truth is we still buy Seagates! Most likely they will work well enough in a home environment. All drives fail eventually. If you can get 3-4 years out of one, that's great!
Yes but usually people come to me because I'm the tech guy and they expect something better then "Take whatever you want. They'll all make it through the first 3-4 years" ;)
The worst part of it is: my own HDs are all Seagates and I use them longer then that...
I don't know if I was just lucky or what, but I've always had far worse experiences with Seagates than WDs.
I got into building PCs on the side in about '96 or so and did break/fix support through college - it always seemed (I didn't keep records - I can't quantify) that Seagates accounted for more than their share of the "it won't start and is making a clicking noise" cases. So much so, that I have recommended against Seagates and towards WDs for as long as I can remember (15+yrs).
I've only had a small amount of direct experience with Hitachi drives, so I can't speak to them too much.. Though I do have a Hitachi in an enclosure that's been kicking around since about 2004, so I guess that says something...
I choose drive brands almost exclusively based on warranty duration. After Seagate bought Maxtor, they started lowering warranties on all of their drives. The results, as you can see, were predictable.
Their "enterprise" disks (except for Terascale HDD/Constellation CS models) apparently still have 5 year warranties†, and I just had to exchange a big Constellation drive, so I can attest their warranty service is still very good.
†They apparently dropped this to 3 years for the first 6 months of 2012 at least for the big drives who's technology base is consumer ... I suspect that change was not well received.
Unfortunately, you are generally correct that we've seen a race to the bottom.
They bought Maxtor and kept the crappy Chinese plants. Interestingly they don't sell the Chinese 3.5" drives at Costco (where they can easily get returned) right now...
The 7200.11 debacle! It was unbelievable that it happened- as far as I remember, Seagate was the leader in reliability before then, I had created five or six RAIDs with Seagate drives with 100% reliability.
But when they released the 7200.11 versions....ALL 7200.11 models would spin down after idle for X minutes and then start clicking...the data was still intact, but for the drive to work again you had to pull the power.
I unfortunately built an eight drive RAID5 with these drives before the issue was know, which made it very difficult for me to diagnose the issue. (All drives seemed perfectly fine when powered and working for the first 5-10 minutes or whenever they were in use, but as soon as a single drive of the RAID idled, the RAID5 acted like a drive was bad).
I still have a box with eight 1TB Seagate 7200.11 drives that I never updated. I have never bought another Seagate drive for RAID since, always WD or Hitachi.
Yup. I had built a gaming/workstation desktop using 2x 7200.11's in RAID-0. It started acting up, at a lan party of all things, which made me suspect the RAID controller on the motherboard, especially after using the drives separately seemed to work ok. But then one of the drives died and then the other, both at pretty much the least convenient moments possible.
I manage a computation cluster for an oil and gas exploration company. We have a 50% failure (and rising!) of Seagate Constellation drives in 250GB, 1TB and 2TB configurations. My sample size is fairly small at a few hundred drives but man does it keep me busy.
They've been purchased over a span of a few years so I doubt that's the case. They did have a single exposure to 110F ambient temperature for a few hours when the A/C to the server room went out which may be a contributing factor.
Not that I use even 0.001% of the disks that BackBlaze go through, but my anecdata suggests the same. The only dead hard disks I have on my desk at the moment are Seagate, and they dominate the disks I've sent back in the last few years.
However, they are cheap, and they do honour their warranties. Would just be nice if they didn't have to quite so much.
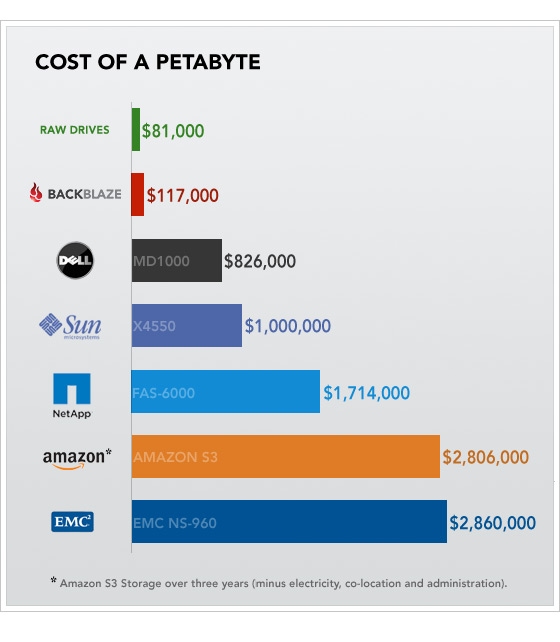
That's only cheap because it's a small block. If you need larger ones, you can get much cheaper. I pay 0.64c/GB/month on my 2TB storage with TransIP: https://www.transip.eu/vps/big-storage/
Amazon S3 is US$0.0275/GB per month at high volumes. I assume Backblaze's operational cost of keeping each Backblaze pod hooked up and online is much much less than US$0.05/GB/month.
There is, roughly. This is a lab test as opposed to production monitoring, but it is still interesting. Obviously SSDs and HDDs are quite different technically, so the appropriate test is quite different. They write data continuously to see how long they last.
We've now written over a petabyte, and only half of the SSDs remain. Three drives failed at different points—and in different ways—before reaching the 1PB milestone[1]
Hardware.info did a "Write until it dies" test for a couple of 250GB Samsung SSDs last year. They found that the drive consistently exceeds the 1000 writes per cell spec.
After a few hundred drives, our anecdata is that failure over time on SSDs is generally related to drive endurance. Make sure you use a SMART utility which can read (and translate to English) the current net usage of the drive. Throw them away when you get to 100% usage.
I recently examined a set of Crucial m4s which were at 130% of usage. There was no lost data, but write bandwidth was hilariously bad (around 10-20MB/s).
I'm talking about the "endurance" spec. Because Flash Memory can only be erased a finite number of times[1], SSD manufacturers specify the drive's endurance -- defined as the number of bytes which can be written to the SSD over its lifetime.
The SSDs helpfully keep track of how many bytes you've written and report that in the SMART info. For example, on my Windows dev system, HDD Guardian reports that I've used up 42% of my SSDs endurance (it's a Crucial m4 512GB). So by "usage", I mean the percentage of the endurance which has been burned.
[1] Each block of flash memory must be erased before it can be written. Each time you erase it, it "uses it up" a bit and will be harder to erase next time. So each time, the SSD controller is forced to erase it with just a bit more voltage. As the blocks become harder to erase, it takes more time to erase them and the SSD write bandwidth decreases.
Anyone have any reliability information on hitachi's new NAS drive series? They're supposed to build on the 7k3000 etc, but specifically tailored for NAS / raid situations, like WD reds. One major difference is that they're 7200 rpm instead of 5400 which is most non-high-end NAS drives.
There are well established methods for time-to-failure and time-to-event data not used here. The author makes no effort to control for the multiple, obvious biases created by the analytical approach employed. A few simple graphs would give a much more telling view of these data.
Would you mind listing some of those time-to-failure and time-to-event methods and how the author might control for them, and which graphs in particular the author should have included?
first, i should've mentioned from the outset that these are really interesting and useful data, and that i'm glad you took the time to generate them. i really wish consumers could systematically report these data in a way that was reliable/trustworthy...!
cox proportional hazards models and KM survival curves are the big kahuna with a data set like this. basically, my impression is that you'd want to pretend that you're doing a cohort study and essentially analyze it like a big clinical trial.
and re: graphing, since you have sub-samples of the different drive models and relatively different but still small numbers of models for each brand, the big take-away graph comparing manufacturers leaves out a lot of useful nuances that could be pulled out of the table, e.g. that most of the hitachi drives are newer and you have fewer of them. it also doesn't portray how consistent failure rates are across models produced by the same brand might be, and it looks like there's a significant range of failure rates across different seagate models. so even just seeing IQRs of pooled failure rates for each manufacturer in box plots might be eye opening..
immortal time bias may be something to consider here as well...when you have some sample groups that mostly include newer individual drives that you have not yet had for a year on average, subtle differences in how the failure event is described can make a big difference in the conclusions you draw...especially in terms of uncertainty. if i have 10,000 hitachi drives and 5 of them fail in the first 6 months, the robustness of conclusions i can draw from those data are different in some important ways from similar insights drawn from a sample of 1,000 hitachi drives i've used for 5 years.
it's also not clear to me how you've dealt with replacement drives. based on what i gather from the post (and i could be totally wrong), if you have a bunch of one model of a drive failing and then get replacements for them... some might argue that refurbed drives should be analyzed almost like a separate drive model, since they often have physical differences compared to those bought via retail channels.
i'd be quite curious to dig into these data a bit further if you're willing to post the original data set...
thanks again for posting information that's quite useful and interesting
Yev from Backblaze here -> We've talked about posting the raw data, but haven't quite decided on that yet. I'll make sure to forward this to Brian so he can take a look and see whether or not any of the above would be feasible for the next one!
I'd be interested to see what a graph of percentage remaining versus time since installation looks like for these. Might give a better picture of what's going on.
Thanks for sharing such useful data. I just had a Seagate drive fail. Was able to recover data since the last local backup with various tools. It took hours of repair work.
I've been procrastinating about getting off-site backup. This post on HN reminded me that I've been meaning to get an account going with your company for a while. I just signed up and will test on my machine before deploying to other machines in my business. Thank you.
Used in a small file server, my net failure rate on Seagate's consumer 3TB drives has been over 50% thus far. The pair of their SAS drives I currently have in use have been fine, although both of them are still below a year of service life...
Edit: Just checked my drive status, and yet another one has dropped. If I'm doing my math correctly, that's 75% of the drives that weren't DOA...
The 3.5" desktop and server Hitachi drives are all manufactured by Toshiba. WD wanted to buy Hitachi's drive division so there would be a WD/Seagate drive duopoly, European regulators said they had to sell Hitachi's 3.5" to someone else before they would approve the merger. Toshiba stepped up and got it.
So yes it is somewhat confusing. You buy one of these drives and it will say "HGST a Western Digital company" on the box, when in reality it's all made by Toshiba, probably in an old Hitachi factory.
First, Toshiba had their own 3.5" drives long before the merger with Hitachi. For example, Toshiba MK2002TSKB 2TB 3.5" hard drive was on sale since 2011.
Toshiba's own design and factories wouldn't magically disappear after acquiring Hitachi's assets. So, after the merger, Toshiba sells some ex-Hitachi drives, for example toshiba DT01ACA300 3TB is obviously a relabeled Hitachi drive. But I believe that Toshiba MD03ACA300 3TB and Toshiba MD04ACA300 3TB drives are based on Toshiba's own design because they don't look like Hitachi or DT01ACA300. I suppose reliability and performance will be different between these three Toshiba 3TB drives. And it would be interesting to get some info on this.
Also, HGST is wholly owned by Western Digital. Despite regulators requirement, they didn't sell all 3.5" assets to Toshiba, only some of them. Most of the good stuff (that is, everything currently sold under HGST brand) still went to WD. So, even ex-Hitachi drives sold under Toshiba brand (by Toshiba) and under HGST brand (by WD) might have different reliability.
There's a much less sinister reason for WD buying HGST: SCSI/SAS support. Way back when in the '90s WD tried to enter that market, and a company I was at even got some of those drives, but from what I heard while their read rate was OK their write rates weren't competitive with Seagate and IBM (which sold their disk drive business to Hitachi after the Deathstar screwup). And they exited that segment of the business, and hadn't, last time I checked, returned to it.
My main Linux box has quite a few hard drives in it from a large range of time. About 4 weeks ago the oldest of them all died: it is from 2007, so about 7 years old, which I think is pretty good for a consumer drive that's on 24/7. It was a Western Digital Caviar SE WD3200JB, 320GB. I replaced it with a 2TB drive.
I just replaced a WD Black 640 3 years into its life. Blacks have a 5 year so they RMA'd it and sent me a 750 in its place.
I do however have a Seagate drive laying around somewhere that has almost 10 years on it and it still functions flawlessly. But it is admittedly smaller given its age and that may contribute to lifespan. Either that or Seagate has slipped in the last decade.
Seagate apparently has slipped in the last 2-3 years. (Could this be related to the hard disk shortage due to flooding in Malaysia?)
Hard drive failures tend to happen more for drives that are power cycled a lot, and for drives that undergo big swings in temperature (even when the temps are all within the rated temp range).
I back up my RAIDs to JBODs - so hard drive backups for hard drives, just fewer. I only use tape for vital and frequently backed up things - not entire drives, and generally not large.
I keep seeing this stuff over the years, so I go buy something other than Seagate like WD... and they fail within a year. So I replace it with a Seagate and no problems for years. See another report that says Seagate is terrible- repeat process.
I'm just going to keep using Seagate until my anecdata refutes the reality I live in.
Yev from Backblaze here -> all of the drives in our datacenter will fail. We just report on the timing of those failures. We still buy Seagates in droves because they are a great value. As long as you have backups of the data, any drive is great!
Do you burn in new drives before using? I typically will take any new drive and do some type of stress test [1] on it for 18 to 24 hours to see if it fails with that initial constant use.
[1] Constant reformatting for example writing 0's to the entire disk 7 times etc.
Yev from Backblaze here -> Yes, we do burn in the drives before deploying them. So the drives in the study are ones that have at least made it past that state.
Doesn't that negate a lot of the usefulness of the data? If most Hitachis fail in the burn-in but all Seagates pass it then the expected failure of a drive would be wildly different to that suggested by the charts.
Do you have the figures for raw losses including at burn-in?
I mean, sure, you burn-in and do warranty returns so buying Hitachi would still seem better - but if one needs a drive to just work then it's key to know the overall failure rate.
Brian from Backblaze here. Let's call that "DOA Failure rate", where the drive is either dead on arrival, or does not survive the 2 day initial burn in test. I'll ask the boots on the ground for more data, but my impression is the 2 day burn in doesn't catch many drive failures, let's say less than 1/2 of 1 percent. We have even proposed skipping it, but we gain confidence the REST of the system is wired up correctly and other components like power supplies also have infant mortality.
Very interesting. It might be an idea to do some post mortems on the failed drives. [1]
Why not take apart some failed drives and see what you can find out as to why they failed vs. ones that did not. Perhaps info that might be of interest to the manufacturer but in any case would make an good blog post. Or maybe you can cannibalize and use again.
[1] I did an "air crash investigation" on a RC Chopper that had crashed. I found out that a servo failed because a part in it was plastic (a gear) (as opposed to, I think, brass). Consequently the jerky move that I made was enough to cause the plastic gear to loose a tooth and then I lost control.
I have a feeling that with Backblaze that ALL of their drives are mostly powered on continuously until they fail (i.e. they might sit for a bit at their data center waiting to go into one of their pods, but after that they pretty much run until they fail).
Backblaze Employee here - this is correct. Pods get powered up, then pummeled with customer data until full. Then they stay spinning forever, but the rate of writes drops to "churn" rates for the rest of the drive's life. This use pattern is all we have experience with, so if your application is different (maybe a database that gets heavy load forever) then your outcomes may vary.
This is extraordinarily useful and unique. My compliments to Backblaze for making this available. This is the type of empirical data I would love to have for as many things as possible: SSDs, monitors, TVs, kitchen appliances, tablets, cars, etc.
Let's get a blog post describing how they handled reimbursements for the drive farming. I imagine it to be incredibly complicated to cross reference a receipt with a product at that scale , especially since all the products were the same.
My small datacenter results mimic BackBlaze too. Dead/dying seagates all over the place. So I notified management that we will only be purchasing Hitachi drives from now on. I have a BackBlaze server that I recently converted to FreeBSD & ZFS. I love the drive-density that Backblaze offers but I HATE the lack of physical notification when a drive dies.
Most ofther file-servers have a front-facing drive caddy, that usually has LEDs on the front to indicate disk access or errors. This is great because you can walk into the datacenter, and SEE which disk has failed. With the backBlaze system you can get /dev/DriveID but not know where in the array that particular disk is.
You definitely don't want to use drives from the same manufacturing run (batch) on the same array, since they are the most likely to fail all at the same time.
Second to that, you probably don't want to go single-source for your drives -- maybe use Hitachi with a mix of WD.
Because then a single firmware bug could wipe you out. Once the drives all hit 4500 hours or 700 bad blocks or some other trigger, they die. It's happened before.
Could also be caused by bad grease, or shoddy bearings, or pretty much anything.
{kind=link}
{kind=link}