> Because of this excess baggage, an x86 chip needs more
> transistors than its ARM-based equivalent, and thus it
> consumes more power and must dissipate more heat.
This is true but it ignores the primary reality of "desktop class" processor design today: RAM is the bottleneck in a really major way and most of a desktop class CPU's transistors are dedicated to overcoming this.
In the ancient days, CPUs ran synchronously (or close to it) with main memory. Hasn't been that way for decades. CPU performance has ramped up so much more quickly than that of main memory that it's ridiculous.
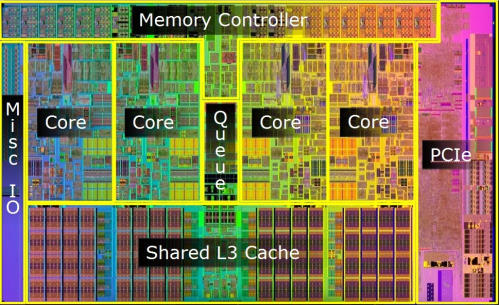
And this is where most of your transistors are spent these days - finding ways to allow the CPU to do some useful work while it sits around waiting for main memory. Look at a modern i5 CPU die:
Things to note:
- Tons of L1/L2/L3 cache so we can keep things in fast memory. The transistors dedicated to cache dwarf those allocated to the actual processing cores, let alone the parts of those processing cores dedicated to those crufty ol' x86 instructions
- Lots of transistors dedicated to branch prediction and speculative execution so we can execute instructions before we've even waited around for the data those instructions depend upon to arrive from slow-ass main memory
Sure, mobile ARM chips are tiny and efficient! They run at 1-2GHZ while paired with fast RAM that's not that much slower than their CPUs. They don't need to devote gobs and gobs of transistors to speculative execution and branch prediction and cache.
But all that changes if you want to scale an ARM chip up to perform like a "desktop-class" Intel chip. You want to add cores and execution units? If you want to keep them fed with data and instructions you're going to need all that extra transistor-heavy baggage and guess what -- now you're just barely more efficient than Intel, and you can't match Intel's superior process technology that's been at least a transistor shrink or two ahead of the competition since the dawn of the semiconductor industry.
Eventually, yes, the ARM chip makers will solve this. RAM will get faster and processes will be enshrinkified. Just understand that transistor size and pokey RAM are the bottlenecks, not that nasty old x86 instruction set.
The "excess baggage" argument being made in the article dates back decades, to the earliest RISC vs. CISC days, and within the Mac ecosystem that argument ended when Apple ditched PowerPC and went to x86.
Back in the 1990s you could make a pretty good argument for RISC architectures vs CISC ones like x86, because the circuitry for all those "extra" instructions took up a lot of die space. But new processes have meant that the percentage of die space that must be devoted to the x86 instruction set gets smaller and smaller with each generation. In other words, if x86 was going to lose out to RISC architectures, it would have happened in the 1990s. Their advantage has only eroded since then.
Problem here is that you are mixing memory latency and memory bandwidth together. We have memory that can easily sustain 16 simultaneous cores in bandwidth (and honestly, memory bandwidth potential is mostly untapped - you only see higher bandwidth benefits for integrated GPUs because they have many more execution units demanding more data).
Meanwhile, the latency has been getting worse. The refresh rates increasing abates it slightly but all the indirection to make high bandwidth ram, plus the commoditization of ram to make high capacity rather than "fast" (transitor only memory like cache shows what is possible for orders of magnitude more complexity and cost).
Adding more cores doesn't impact that latency at all, it just demands more bandwidth. If anything, the diminishing returns of what Intel has done - dedicating a lot of per-core die to prediction just to throw away computations because the per core power is too high - make less sense than just putting a lot more dumb cores on the die.
But then you get GPUs. Shitty latency, huge bandwidth, huge flops, terrible context switching, etc.
It is worth mentioning that both sides of the equation are doing the same thing, though. RAM makers are dedicating a majority of the silicon on ram modules to controllers to accelerate lookup, rather than actual capactive storage.
For the average user, you don't need that hugely complex Haswell logic. Tablet class performance for the web, office suites, and even programming sans compiling are all perfectly competent. If we wrote better software that utilized all the available cores sooner, we would have gone down the route of 16 - 32 core main CPUs instead of extreme precomputation. That has a lot more potential performance, but it requires the software to use it.
ARM is kind of uniquely poised to do that as well. Most of its ecosystem is fresh, it went through an extremely fast multicore expansion, and its architecture lends itself to more cores instead of trying the "dedicate everything to offsetting slow memory" problem. If software architects started writing their programs to be core-variable as possible, ARM might be the first realistic platform to break consumer 16 core computing, because the Windows world is frozen in time.
1. Memory isn't just slow because they went for capacity not performance (except vacuously), it's slow because of the laws of physics. c.f. L3 memory is made of the same stuff as registers but takes about 30 times longer to access.
2. No, adding lots of dumb cores makes no sense.
3. GPUs are useful because many tasks are embarrassingly parallel. Many more are not.
4. 'If we wrote better software' adding many more cores increases the difficulty of reasoning about software hugely. Many tasks are not easily performed in parallel, or the speedup is not impressive enough. Most operating systems (my guess is that OS X is included) will choke if you give them too many threads - performance drops hugely, or many threads are left totally idle. This is due to lock contention etc.
5. Of course no-one 'needs' that Haswell logic - but it's sure nice having my computer do stuff quickly. My top-of-line phone struggles to play through its animations properly, and loading websites frequently takes a while. Good-enough is not really a good place to be. Furthermore, greater performance motivates more demanding applications.
6. We dedicate everything to offsetting slow memory because it's the only way to get good performance from the majority of tasks. Sure if your task can be handled by a GPU, by all means run it on a GPU. For those that cannot, we have a CPU.
There's a reason why the iPhone and iPad only have two cores - it's not worth their while adding more but does add lots of cost and complexity.
> Memory isn't just slow because they went for capacity
> not performance (except vacuously), it's slow because
> of the laws of physics.
Yes. The farther away RAM is from the CPU code, the more stuff needs to happen before it can get into those precious, precious registers. Even if data from main memory didn't have to travel over a bus/switch/etc between the DIMM and the CPU, it's not physically possible (in any practical sense) to have main memory running at anything close to the speed of the CPU once we're talking about multi-GHZ CPUs. DIMMs and the CPU are running on separate clocks, you have the sheer distance and the speed of electrons through the metal to consider, etc.
> There's a reason why the iPhone and iPad only have two
> cores - it's not worth their while adding more but does
> add lots of cost and complexity.
Yes! There's a reason why the A7 in my iPhone 5S blows away the quad-core ARM chip in my 2012 Nexus 7. That reason is because "adding more dumb cores" is not the answer to anything, aside from marketing goals.
> Problem here is that you are mixing memory latency and memory bandwidth together.
Yes, I intentionally did. You are of course correct that latency and bandwidth are two different things. I stopped one level of abstraction above that, so to speak. The concept I was trying to get across was the reality that most of the transistors on a x86/64 die are spent compensating for memory performance either directly or indirectly and the price we pay for the x86 "cruft" these days is still there but is pretty small.
> If software architects started writing their programs to be core-variable as possible,
And cars will be a lot more reliable when car designers simply design them to be engine-variable! When you invent a convenient way for software to use all those cores, be sure to remember us when you collect your Nobel Prize. Seriously though, writing code to take advantage of multiple cores has been one of the hardest things in computer science since forever.
The reality is that a great many computing problems simply don't lend themselves to parallelization. Some things are embarrassingly parallel (like a lot of graphics work) but a lot of algorithms simply aren't able to be implemented in a very parallel way since each "step" depends heavily on things you need to calculate in the previous "step." (Example: simulations, games, etc)
Things will improve a little bit, as our languages support easier parallel/concurrent code and our compilers get better at things like auto-parallelization, but this won't magically make stubbornly sequential algorithms into things that scale to two cores, much less "a lot more dumb cores."
> just putting a lot more dumb cores on the die
I wish it was as simple as putting a bunch of dumb cores on the die. Thing is, they can't be "dumb." You still have to spend serious transistors on things like cache coherency and so forth.
The "lots of dumb cores" thing has been tried before. Like this: http://en.wikipedia.org/wiki/Connection_Machine and Intel's Larrabee and things like that. Seriously, don't you think that hardware designers have thought of this before? They have. There's a reason why Intel doesn't just throw 100 Pentium cores onto a single i7-sized die and dominate the entire world.
Notice the size of the L3. Now look at a core- each core is probably 50% L2 by area, and the L1 + branch predictor/prefetcher probably occupies another 25%.
You're actually wrong with regards to the branch prediction. the A7 is (according to anandtech [1]) closest to the "big processor" designs that intel makes with aggressive branch prediction (massive issue width, huge branch prediction buffer, huge caches).
{kind=link}
In the ancient days, CPUs ran synchronously (or close to it) with main memory. Hasn't been that way for decades. CPU performance has ramped up so much more quickly than that of main memory that it's ridiculous.
And this is where most of your transistors are spent these days - finding ways to allow the CPU to do some useful work while it sits around waiting for main memory. Look at a modern i5 CPU die:
https://www.google.com/search?q=intel+core+i5
Things to note: - Tons of L1/L2/L3 cache so we can keep things in fast memory. The transistors dedicated to cache dwarf those allocated to the actual processing cores, let alone the parts of those processing cores dedicated to those crufty ol' x86 instructions - Lots of transistors dedicated to branch prediction and speculative execution so we can execute instructions before we've even waited around for the data those instructions depend upon to arrive from slow-ass main memory
Sure, mobile ARM chips are tiny and efficient! They run at 1-2GHZ while paired with fast RAM that's not that much slower than their CPUs. They don't need to devote gobs and gobs of transistors to speculative execution and branch prediction and cache.
But all that changes if you want to scale an ARM chip up to perform like a "desktop-class" Intel chip. You want to add cores and execution units? If you want to keep them fed with data and instructions you're going to need all that extra transistor-heavy baggage and guess what -- now you're just barely more efficient than Intel, and you can't match Intel's superior process technology that's been at least a transistor shrink or two ahead of the competition since the dawn of the semiconductor industry.
Eventually, yes, the ARM chip makers will solve this. RAM will get faster and processes will be enshrinkified. Just understand that transistor size and pokey RAM are the bottlenecks, not that nasty old x86 instruction set.