The big benefit the author is describing comes from content negotiation and hypermedia types. The idea behind content negotiation is that a client and a server should decide and agree upon the media type that will be used in the communication without any human intervention (even a developer). This is accomplished with the Accept header, where the client tells the server, "Here are the media types that I understand." Most times, we developers use the Accept header as "Here is the media type I want you to send me." If we use the former, the server will figure out what media type to send based on the clients acceptances and preferences.
Here's the great thing about it. If APIs are built this way, and if clients are built to read and understand common and registered hypermedia types, there could be a time where clients and servers are able to communicate in such a way that the media type becomes seemingly invisible to the developer. We see this with the most popular REST client/server combo, the browser and the web server that serves up HTML. As the user, you can traverse the RESTful HTML API that websites have while the media type, HTML, is mostly concealed to the user. In other words, there is a chance that a good number of HTML websites are more RESTful than most of the APIs we see today.
In reducing REST to simply RPC over the web and skipping over the ideas of content negotiation and hypermedia types, we are missing out on the genius behind how the web was designed to be used. The author is really wanting us to go back to that instead of progressing toward the current patterns of fracturing your resources into separate APIs.
I respect sites that provide data dumps (e.g., Wikipedia) far more than ones that design "API key" systems.
If these API keys are for "developers", then why is there an assumption that the developer cannot (or does not want to) work with raw data? Or, at least, why is there no demand from "developers" for raw data? I have never understood this "API key" phenomenon.
With today's storage space prices and capacities (physical media, not "cloud"), in many cases a user could transfer all the data she ever needed to her device and have the fastest access possible (i.e., local, no network needed) for all future queries/requests. Not to mention the privacy gains of not needing to access a public network.
Using a bakery as an example, implementing API keys is like making customers fill out ID cards and come to your bakery and present ID every time they want a slice of bread. Your policy is "Sorry we do not provide loaves to customers."
This might be palatable if your bread is something truly unique, a work of culinary art. But in practice the "bread" of web sites is data that they gathered somewhere else in the public domain. They are like the "bakery" who buys from a bulk supplier and resells at a markup. Except, with web sites, the data they obtained to "resell" cost them nothing except the electricity and effort to gather it.
The easiest way to stop "web scraping" is to make data dumps available. Because then you really have no obligation to provide JSON or XML via an "API key" system. It is less work, less expense and it's far more efficient.
> Using a bakery as an example, implementing API keys is like making customers fill out ID cards and come to your bakery and present ID every time they want a slice of bread. Your policy is "Sorry we do not provide loaves to customers."
Even in this mysterious bakery that gives away bread for free, can the first customer in line take all of the loaves and leave none for anybody else?
Some APIs serve up dynamic data that is expensive to generate, or they perform expensive and complicated operations on the data to save everyone downloading a dump and reinventing the wheel.
Others serve up static data that is valuable in monetary terms.
So the "bakery" either charges for loaves (API Key = money) or it limits how many loaves a person can take (API Key = individual identifier).
Indeed, API keys make a lot of sense for a lot of cases.
The API key is to prevent someone from coming and taking all the bread at once and leaving none for everyone else (i.e., computation/network capacity).
Your bakery gives out slices of bread, but it only dispenses these slices at a set rate (i.e., the anti-DDOS mechanisms built into most large sites). If you want to get a lot of bread at once, that's okay, but you need to let the bakery know.
This isn't an adversarial system, in most places this is a cooperative system. Without a key, if someone is taking too much bread, everyone suffers and the bakery has to start banning people they suspect of taking too much bread. They might ban the wrong people, and the only solution is adversarial.
With a key the bakery at least can know who's been taking the bread, and call them up to ask them to slow down. Nobody has to get banned, and the solution can be a win-win for everyone instead of a win-lose. In a lot of cases the bakery can even figure out what the person is doing with all that bread, and figure out solutions where less bread is required to begin with - thus increasing availability without actually stopping anyone from doing what they want.
"The API key is to prevent someone from coming and taking all the bread at once and leaving none for everyone else (i.e., computation/network capacity)."
I disagree. The data dump gives the developer/user the ability to download and make the data available to the user's device locally, perhaps even via direct attachment thereby obviating the need for network connectivity to access the data.
Consider all the resources needed to stay online and serve myriad API requests 24/7 to consumers all over the globe. Add the resources to develop and maintain an API key system. And then consider behavioral issues like denials of service.
Now contrast this with the resources needed to periodically upload and host data dumps via FTP, Bittorrent or some well-suited protocol; the dumps can also be mirrored, reducing the strain on one set of servers and providing some level of DoS protection.
The key difference is that a data dump can be mirrored by third parties, while API calls must stay with one source.
Downloading a data dump is not "taking all the bread and leaving none for everyone else". Bread was a poor analogy, because customers do not take the original loaf, they merely take a copy of it. If the "bread" is data, then the "baker" never runs out.
The finite resource you allude to is the computation and network capacity.
With a data dump, the developer can provide users with another source for the data: the user's own local storage. As more developers make the data available, user access increases. The costs of the computation and network resources are redistributed. With an API, develpers merely point users at the same data source. That sole source has to foot the bill for the computation and network resources.
It is difficult to discuss this at length without referring to any concrete examples. Keep in mind I gave Wikipedia as one, and let me be clear I only have public data in mind (e.g., government data or user generated content). I am not suggesting that anyone give away proprietary data in a data dump. What I'm saying is that the way in which people are accessing a great deal of publicly available data today (via "APIs") confuses me; it make poor use of the current computational and network resources available.
I'll admit I'm biased. I like working with data dumps. I do not "reinvent the wheel" when I work with data dumps (as someone else suggested), but I do use a simple, more robust wheel than any "API". I like giving users speed, simplicity and reliability. Data dumps give me the freedom to do that in a way that APIs do not.
Good question. The answer is that it depends on how frequently the data changes. Some data might change often, some might not. If the data falls into both categories, there will be a trade off if we treat all data as "dynamic" or all as "static" over a definite period. What might make more sense is to separate these two categories of data.
API calls (piecemeal data retrieval) makes better sense for "dynamic" data that changes frequently. Whereas periodically downloading a data dump makes better sense for "static" data that does not change very often.
For example, some of the data in a telephone book was subject to change from time to time. But for the majority of data, changes were not frequent enough to justify calling the operator (=API call) every time one needed to look up a telephone number, or printing new telephone books every hour. Distributing new telephone books periodically, once evry few months or once a year, was sufficient to keep up with changes to the data.
An analogous situation exists with the data in the DNS. At one time, before the DNS, the Internet's "telephone book" was the HOSTS file. Perhaps a majority of entries were likely to change frequently. Periodically downloading a new HOSTS file was reputedly insufficient to keep up with changes to the data.
Let's say, for discussion purposes, "frequently" means more than once a month.
Today, I would guess only a minority of the total data stored in the DNS changes "frequently". The sampling I've done over the years supports this assumption. In my research, the majority of data stays the same for at least a month at time. As such, downloading new data once a month would be sufficient to keep up with changes to _this portion_ of the data.
As stated above, one approach might be to split the database up into "entries that are subject to change frequently" and ones that are not: a "frequently changing" DNS (for those who need it) and a "regular" DNS (where all needed data is stored locally, not accessed remotely via a network) for those who are not changing IP addresses more than once a month. Based on my research, _most_ websites are not changing their IP address more than once a month.
Returning to the telephone book example, we know that _most_ persons and businesses did not change their telephone number very frequently. This is why the telephone was still useful even though we only updated the data (by getting a new copy of the book) once every few months or once a year.
> Using a bakery as an example, implementing API keys is like making customers fill out ID cards and come to your bakery and present ID every time they want a slice of bread. Your policy is "Sorry we do not provide loaves to customers."
You don't need ID cards because you can see the customers faces (biometric). If a customer is disruptive, you can easily enforce a policy of banning them.
API keys do make sense if charging money for usage. This way, the right person is charged the right amount of money. The other case is when the API keys are protecting private information. Otherwise I agree, not much point to API keys.
+ Use content negotiation headers instead of explicit content extensions for resources.
+ Don't pass auth tokens as part of the URL (you monster).
+ Don't have onerous processes for obtaining API keys.
+ Web scraping is totally a legit way of providing programmatic access to data.
~
Sadly, the author is kind of wrong in these cases.
First, as I've run into on some of my own projects, specifying desired content type (.html, .csv, .json) in the URL is actually pretty handy. In Rails, for example, you just you a respond-to-format block. This lets clients using dumb web browsers (and you'd be surprised how many of those there are) download easily the type of content they want. Accept headers are useful, but they don't solve everything.
Second, I do agree that auth tokens should go in the header--that's just reasonable. If I'm doing something that needs an auth token, I probably am curl'ing, and so I can easily set headers.
Third, keys are a necessary evil. They are the least annoying way to track access and handle authorization. That said, it shouldn't be awful to get a hold of one--in our previous startup, api keys were similar to auth tokens, and that worked out fine.
Fourth, web-scraping is not a good solution. "Herf derf just have your dev scrape the thing" is cool and all, but if the document is not marked-up in a friendly way, that information can be very brittle. Moreover, you run the risk of having cosmetic changes break scrapers silently. It's far better just to expose a machine-friendly API (which is handy for testing and monitoring anyways) and let your frontend devs do whatever wacky stuff they want in the name of UX.
EDIT:
I am all for rate-limiting as a basic step where keys do not suffice.
As for scraping, the article is a bit weird on this point. The author's insistence on "DONT USE APIS EVER RAWR" and then on "hey, let's use application/json to provide documents under the same paths for machines" is goofy. It's like they don't want you to use an API, except when they do.
The wording and phrasing just really gets in the way of the article--had the tone been a bit less hyperbolic, it would've been a decent "This is why I find web APIs frustrating to work with" with examples.
EDIT EDIT:
The author is a Semantic Web wonk. That explains it.
You're missing the whole point. He's not proposing "Web scraping" for data at all. He's proposing to use a single unique identifier for a resource, its URL. This identifier should provide both the presentation, and the data. So you wouldn't "scrape" this URL for its data, you would simply content negotiate a machine-friendly version and use that instead.
I'd even go further and say that a resource should also be linked to other data. This is the idea behind Linked Data which is essentially building a distributed database of datasets using this exact technique. This is why unique identifiers are important, because then people can reuse them and link to them.
Counterpoint to First: What is comfortable to you as a Rails dev is immaterial to what's the better solution, so that's a moot argument. My take on that particular issue is that you accept headers, offering them as the supported way of interaction, but extensions or other content-type declaring suffixes as convenience
Counterpoint to Third and Fourth: Scraping was mentioned as to why keys are not necessary, not as a real solution. If you can scrape the content without a key, why should you need a key to get the JSON version? Nonsense. If you are worried about misuse and abuse, you should put in place throttling and other countermeasures regardless of it's standard HTML version or JSON.
To your first point, was just offering an example from Rails--I'd do something different in Node or Laravel. I think that you need to handle both, ultimately, and you need to document which takes precedence (your request was for '/cats.html', but content-type was 'application/json'...what do?). That said, the author seemed to dismiss suffixes out of hand.
The author fairly explicitly seemed to suggest that writing a RESTy API was a fool's errand, and that you could simply emulate it by scraping content. The key stuff was a red-herring, honestly--and again, I do agree that you should be doing rate-limiting unless, perhaps, a valid auth token is supplied with the requests.
The author's screed here was poorly titled, and the sound arguments one could make against REST APIs are not present.
The author is indeed suggesting writing RESTy APIs are fool's errands, where the operative word is "RESTy" (ie, misinterpreted REST, which is the most common REST implementation, sadly)
I mostly agree with that author's sentiment.
I disagree with your interpretation that the author is suggesting scraping as a proper alternative to an actual REST (not RESTy) API.
Barring that, I tend to think you, the author and myself have more agreements than disagreements on the subject at hand.
Regarding content negotiation, the idea is to put all of the media types in the Accept header that the client can understand (instead of saying I want such and such representation). You then request a URI and the server decides which representation of that resource to return in the response based on those headers. I think you may have mentioned most of this, but I reiterate to say that if a client cannot do this, it's to the fault of the client. The web was built to work with content negotiation and it does this beautifully.
With that said, there is nothing wrong with linking to the HTML file with .html, but the developer (or user) consuming the API (or website) should not be adding suffixes to get the representation they want... the API should be returning those URLs in the response.
Additionally, regarding screen scraping, HTML coupled with something like RDF, Schema.org, or other microformats/microdata allows you to parse the HTML looking for that data without breaking clients on HTML changes. It really is a good media type for REST, which does seem odd at first and does feels like screen scraping, but you're just parsing the HTML like you would XML. The difference is HTML is a hypermedia type and XML knows nothing about hypertext.
> My take on that particular issue is that you accept headers, offering them as the supported way of interaction, but extensions or other content-type declaring suffixes as convenience
This is exactly what Rails offers by default, actually. Although you (can) declare your code using a `wants.csv { … }` format, it's mapped to both the extension and the corresponding Accepts MIME type. (with the Accepts header taking precedence over the extension, I believe)
This article doesn't recommend web scraping - he discusses making URLs for your 'API' resources and your human-consumable resources shared, with different 'accept:' content types.
Which is the parent's point. The actual content type you are sending is irrelevant. HTML, JSON, CSV, it is all the same from a computer's point of view.
What is relevant is that the content's structure remains stable. If you are sharing URLs, the structure of the 'API formats' and the structure of the HTML page should be consistent with each other, which means that any big changes to the HTML form could potentially break the API across every format in order to maintain that consistency.
If you are going to make your JSON structure stable but then radically change the structure of your HTML page at the same address, then the URI becomes a misnomer and you've lost the reason for having the same resource address for multiple content types in the first place.
Tell that to Facebook and Twitter. Both are notorious for making changes to their API without informing their developers , especially the former. With site scraping, at least they have a better chance of telling you when a redesign is coming. And b/c they rely so much on CDN's, JS, caching, etc, changes to their site structure probably don't change as much as their API.
Not really. In both cases it's not desirable for the URLs to change in case a client/other website is linking to it. Versioning is just adding more URLs in the same namespace.
Unless I'm misunderstanding you, URLs do not have to change to break a scraper. If the HTML of the site is significantly changed (ie: redesigned) it will likely break any scrapers using it, without having to change any URLs.
Of course the guarantee isn't absolute; that would be silly. But so is thinking that this isn't an absolutely crucial distinguishing factor.
I can run programs written 17 years ago on my current Windows box, not even needing a VM. In computer terms, that's almost forever, and it was made possible by Microsoft's commitment to API compatibility.
API versioning is a mindset. It means that once you've published something, you can't change it without carefully managing the effects. It potentially means maintaining bug compatibility; it sometimes means detecting the client of the API, and specifically accommodating client bugs. Other APIs, even internal APIs used by rich web apps to communicate with their back ends, are not written with the same mindset. And rightly so; the constraints that come along with a public API are not to be taken lightly, and do hamper agility.
Code can last forever; there are people playing thirty-year-old games via emulation. The only problem is that we now have a plague of people who don't take their responsibilities seriously as contributors to the Web, and they randomly break their own resources out of laziness or ignorance.
tl;dr - APIs are necessary and are not a lie, contrary to the first thousand-or-so words of the article, but the author would prefer you had API resources at the same URIs as your user-facing web content, and allow user agents to switch between them using the 'Accept' http header.
Which in fact is a massive headache, incredibly complicated and you'll wish you hadn't.
/start rant about REST
I'm also sick of people believing that REST is some magic pancea to the API problem.
Go look over any project you did before you heard of REST. Did you just have 4 methods on your objects called Get, Create, Update, Delete? With loads of extra parameters you can optionally pass in?
Do you think that would make a good API for an actual library?
No, of course not.
So why on earth would you use that very bad library design just because it's going over HTTP? HTTP was meant for documents, not programming APIs.
RESTful APIs was always a stupid idea. And don't even get me started about the nonsense that a GET doesn't modify anything, of course it does to even the most basic objects, I just logged your access to it. I may have checked whether you were logged in and updated your last access time. The amount of views that object has has just increased. The system changed in many different ways, possibly including the object.
I'm tired of APIs that try and contort a complicated API into some crazy REST structure by using loads of parameters. Google, I'm looking at you. You guys are smart programmers, how have you not realized the entire concept is intellectually vapid.
> This definition of safe methods does not prevent an implementation
> from including behavior that is potentially harmful, not entirely
> read-only, or which causes side-effects while invoking a safe method.
> What is important, however, is that the client did not request that
> additional behavior and cannot be held accountable for it. For
> example, most servers append request information to access log files
> at the completion of every response, regardless of the method, and
> that is considered safe even though the log storage might become full
> and crash the server. Likewise, a safe request initiated by
> selecting an advertisement on the Web will often have the side-effect
> of charging an advertising account.
I'd suggest that you become more informed about something before having such strong feelings about it.
You have variants in:
the HTTP method, the URL path, the URL query params, various HTTP Headers (cookie, content-encoding, content-language, ...), the Body (with various forms of content encoding) , did I miss something ?
If you think of a request as a function call then it's all parameters and it's completely crazy.
Yup. That's why requests aren't function calls. REST is a different architecture than RPC, which is why you need all of these conventions to do RPC over HTTP: you're mapping one architecture onto another.
A HTTP request is a function call. A function call is message passing. No matter if you use RPC, SOAP or what not. It's conceptually all the same - the caller sends a message to the callee which responds with another message.
Yes, if you map the concepts over. Which is what you just did. The RESTful architecture is explicitly _not_about function calls. It's about manipulating state diagrams. Yes, you do that through a message, but it's different than a function call, unless you define 'function' and 'message' in a way that's completely meaningless. If any message is a function call, a UDP packet is a function call.
If you can require your client to behave in a normalized way then all this complexity is not necessary and you're probably avoiding some bugs along the way.
No wonder you hate REST HTTP APIs. Take a look at FreshBooks API. They have a more complicated application (in terms of model complexity and ACL complexity, not scale) than most of Google APIs and besides the fact that they only support XML, their API is really fucking good. It is unsurprising and it it's been around a good long while.
Would you really rather FreshBooks use an RPC API? /setup_payment_for_invoice
/pay_payment_on_invoice
/allow_contractor_to_submit_expenses
/create_new_time_tracked_amount
It's a computer asking for an action talking to a computer asking for an action.
Call them whatever you want, the concept is extremely simple and pretending it's anything more complicated is obfuscating the underlying simplicity of the intent of the programmer. i.e. I want the other computer to do something or the other computer to send this computer some information.
The intent is simple, but there are many ways to express that intent. Some of them work well when there are two components sitting right next to each other in memory on one machine; others work well for an unknown number of components interacting with each other over a slow, unreliable network.
Even if RPC is a fundamentally, unambiguously simpler way to express that intent (and I think that's arguable), it does not meet the same technical requirements that REST does.
>>And don't even get me started about the nonsense that a GET doesn't modify anything
It is not nonsense. It is a very useful convention. If you stick to it, you get some system properties ... for example, you can very easily put a caching layer (nginx, varnish, etc ...) which can reduce a huge amount of load to your backends, without worrying that it will change the behaviour of your backend.
"People get worried about .NET and decide to rewrite their whole architecture for .NET because they think they have to. Microsoft is shooting at you, and it's just cover fire so that they can move forward and you can't, because this is how the game is played, Bubby. Are you going to support Hailstorm? SOAP? RDF? Are you supporting it because your customers need it, or because someone is firing at you and you feel like you have to respond?"
This "API over HTTP" stuff is something I've been noodling on for awhile. If you've got some suggestions for, I don't know, "RPC over HTTP" or just exposing typical library calls over HTTP (neither involving SOAP, please, dear $DEITY...) I'd personally be interested in reading them.
And as I write this and think on it a bit more, I'm realizing that 'serializing' APIs over HTTP probably isn't the best idea in the world. But it makes things "easier" - firewalls don't need configuration to let your customers access your remote API, HTTP traffic tends toward human-readable text, etc.
"the author would prefer you had API resources at the same URIs as your user-facing web content"
I thought one of the principles of RESTful design is that the internal structure of URLs shouldn't really matter - you should be able to navigate to any resource from being given a single base URL. So i struggle to see what difference it makes if RESTful API consumers see different URLs to browser users....
It's because your parent is making a different claim than the author. The author is saying that you shouldn't be running two different services to expose the exact same data, which is not the same claim as "your API has the same URLs as your web content."
A lot of this comes down to what you mean by "API"...
This is probably stupid (I'm not a web developer), but how about using Javascript on the (human, in a web browser) client side to convert API results into DOM elements?
It would probably be less than fun to write and maintain such a monster, but it would at least make it possible to expose a single API from the server's point of view ... Yay?
If you're just referring to building an API and then consuming it to build your client-side web site, then it's not stupid at all -- this is called "API first" architecture and more and more developers are using this approach. (myself included)[0].
The only tricky part with this approach for small-scale sites is getting authentication right. REST architecture is fundamentally stateless, which means it's tricky to implement a "Remember Me" checkbox. The simplest way around this (which does involve saving state server-side on the DB) is to issue a nonce once the user authenticates via whatever means you want, and then using that nonce to authenticate each request until the user logs out or a specific period of time passes.
All of this assumes you're serving everything over HTTPS, of course.
Anyway, if you do it right, it's no less difficult to maintain than anything else. Since all of your DOM interactions are client-side, this means you end up with a large JS application, but tooling is getting better, and JS isn't a bad language to work in (however, I am actively looking into both Dart and Typescript as more robust alternatives).
That's not the only tricky part with this approach. Pages take ages to load because all rendering has to be done in the browser and can't be cached. The site completely breaks when JS isn't enabled, which discounts search engines and users who disable JS (whether you like it or not, some users do this). It's a brittle solution to a rare problem.
Isomorphic Javascript should be able to give the best of both worlds. I've been playing with Meteor and Derby recently. Of the two, Derby seems like the closest to what I'd want from a modern web framework.
Less than 1% of users have JavaScript disabled. Search engines don't care about pretty, so it's pretty easy to render just some data inside a NoScript tag.
This is not at all stupid: in fact, it can make a ton of sense for sites where the content changes quickly because you can have the browser cache the framework code for a long period of time so the page loads quickly and then your server only needs to deliver small amounts of current data rather than a large collection of HTML which mostly hasn't changed. This is particularly nice for news sites when the headlines are the same even if there's one part of the page which is customized for your account.
The catch is that search engines won't see any of that content unless you provide an alternative. Some places use the same API but either run the JavaScript on the browser or in a separate server process to avoid this.
I think you didn't catch the author's definition of an API: If the machine and the human can access the same resource on the same URI - it's one API. Don't need to convert the Json on the client side - it can be done on the server side whenever a client specifies that it wants the resource returned as application/json in the HTTP header.
You can even go so far as to write a web server that queries your API and renders static HTML to clients--which is what we did at my last startup.
This sort of thing is referred to as a Service-Oriented-Architecture.
It's a great way to sandbox a lot of stupid--you setup a little Sinatra app to be a fake API server while your buddy builds out the real backend, and one day you flip a switch and everything comes to life correctly.
(j/k that doesnt happen everything is always terrible the first time)
you could also do the opposite... the machine version can parse the HTML. despite the myths to the contrary this is extremely easy since the various bits of the web stack which are poorly implemented don't really cause an issue if you just want to extract text content, especially if you control the form of it (e.g. you could use class or id to identify data).
it is after all a markup language and this is exactly what it is meant for (the web browser does this...)
really this is a symptom of how terrible web architecture is...
the concrete examples make this painfully obvious - the API referred to is the 'modern hipster' flavour of it, nothing to do with any of the APIs I use day to day which don't go across the web.
there is a much more classical programming problem at the root of this. clients asking for what they want as implementation details instead of what they want from the result. couple this with a lack of sensibility about encapsulation and interfaces and sprinkle in the use of 'REST' as a buzzword and voila...
There is a scene where the father of the boy "translates" what the German officer is telling to the prisoners. This is essentially what all UI (API included) does. Yeah, it's a lie, but it's a lie that actually shields us from the awful truth of how everything works.
I'm Italian and I've seen that movie in Italian. I didn't know there was a dubbed version. It loses so much value. The original version is so much better.
Them: I need you pull data from a web site to integrate with our system.
Me: Neat, how is the data exposed?
Them: It's a website. Web pages.
Me: I'm going to stab myself in the head now.
After spending days pulling messy HTML, attempting to navigate around with whatever method this site uses (JavaScript only maybe), and hammering everything into some sort of cohesive form you'll be seriously wishing they wasted money and time putting and API on their site.
Well he isn't advocating that you parse html here. I thought that he was originally too, but later on you'll see he is talking about using the same URI's and content negotation.
I didn't understand it as advocating scraping, just a reasoning why API keys are useless in case you are serving the same content as HTML without requiring a key.
This is mostly a really long-winded promotion of the "Accept" header. The article's gripe about APIs is basically a gripe about poorly thought-out design in general. Bad design isn't an artifact of the system in which you see it. Bad design exists everywhere. Keep APIs out of it. It's like saying that people should stop using cars because Lada keeps making fuel-inefficient outdated crap.
It's not just the Accept header. It's thinking less of APIs and more of hypermedia, which happens to be in a machine readable format. It's about creating the conditions for service-independent agents to discover and use new services, without having to be custom-coded to support them.
Right now, we're doing the equivalent of having to extend the browser for each single site we want to access. Imagine that if Chrome users wanted to access HN, the browser had to have a "HN module" to interact with it. It's ridiculous, but that's where we're at with automated web agents.
An automated web agent isn't a replacement for a browser. It's a replacement for a browser plus person.
And a person using a browser to access HN does need to learn how to interact with HN. This is helped somewhat if the person in question is familar with the general concepts used in web fora.
Yes and no. Sure, the automated agents would need to perform some of the roles that are now performed by the user, but it's just one more layer: before, we just had text viewers, and all the formatting was interpreted by the users (add we still see in plain-text emails). Then came document viewers and that whole layer moved from the human to the machine. This is just one semantic layer above.
And no, I'm not suggesting that were must build agent capable of human-like learning, that's why much like we had to transition from ad-hoc formatting marks to some kind of standard, we must also help our agents by tagging the information in our websites with standard marks.
But the widespread conception of REST is actually an RPC architecture with more endpoints, and that's holding us back from building a smarter web.
Except that URL's (visible pages) often don't map 1-1 to "content", and while they originally were "supposed" to, reality is far more complicated than that.
People like to be able to browse pages in an "intuitive" way. This means often combining multiple pieces of content onto a single page, or splitting up a single piece of content onto multiple pages, or often both.
In the real world, URL's are human-friendly pages which generally try to hit a sweet spot between too little and too much visible information, not unique identifiers of logical content.
Which is exactly why API's are useful -- they are designed around accessing logical content. But this is not what normal human-readable webpages are generally designed for, and rightfully so. They serve different purposes, and insisting that they should be the same is just silly.
It doesn't have to be a 1:1 mapping; there are certainly valid scenarios where it might not make sense (or it might be prohibitively difficult) to provide a particular representation of a particular resource, but that doesn't mean you shouldn't use consistent URLs where possible. This is what HTTP 406[1] is for.
The author's point is that URLs are not pages -- they are just pointers to information, and that (a) by design, they should be static and uniform, and (b) there is no reason that URLs cannot be used for both person- and machine-readable information.
Not all APIs are resource-specific or public. While the arguments may be valid in many cases, I think the author may be confused between the web and software in general.
It’s the same content, why would you need two interfaces, just because your consumers speak different languages?
Because you then can change one without affecting the other. If your html is parsed automatically, the parsing can break when you update your html to fix a design flaw.
OP has some good points though, those APIs look retarded.
Content negotiation could be nice, but it doesn't remove the need for keys in most cases, and adding this to your stack could be harder than just making a simple API.
Ask for new representations on your existing URLs.
Only by embracing the information-oriented nature of the Web, we can provide sustainable access to our information for years to come
Yes. But won't the answer, in most cases, be a simple "API"? (not a real API, in the programming sense)
If your "API" is literally just a machine parsable version of data you have on your HTML, well, yeah, doing it the way the OP described as better will work.
But if you're writing an API to access a proper web application, it needs more than just data retrieval, and it needs ACL, and it needs to not show things to certain people, and allow bi-directional communication, and all sorts of other things.
That's where what the OP is asking for breaks down, and I don't think APIs are a "lie", perhaps they can be a leaky abstraction and sometimes the wrong choice, but they can also be super useful.
Its funny he brought up Amazon early on: they run entirely on SOA, APIs everywhere, controlling everything. Seemed cute to me :)
But if you're writing an API to access a proper web application, it needs more than just data retrieval, and it needs ACL, and it needs to not show things to certain people, and allow bi-directional communication, and all sorts of other things.
And HTML webpages don't have that? Let's take HN:
* ACLs: ✔ I have an account and I can't post as other people.
* Hide things from certain people: ✔ I can't see your email
* Allow bi-directional communication: ✔ I can post this very message.
My big reason to have a separate API falls under "all sorts of other things": The machine API exposes data objects. The human API (HTML web pages) defines interfaces to manipulate the data objects. In the presentation layer (human API) I manage collections of data objects, conditional inclusion of other data objects, etc. The human API is not a simple resource-access system, but contains logic governing interaction and relations between data objects. The machine API layer is basically a controlled data access layer.
The human API also exposes data objects. It also sends extensions (CSS, Javascript) to the client that allow it to present the data and make additional API calls. This idea of extending the client program is part of REST.
The machine API also handles interaction and relations. The representation of a collection object will contain URLs of the elements. There should be hints on how to compose a request that updates the object.
So I just spent half an hour trying to illustrate a simple counter-example, but for each of the half-dozen apps I have considered I see how it could be organized into a unified structure differentiating machine/human API by the requested content type. I'm not sure if I would prefer that in practice, but I think I am going to have to try it. The idea of having a single structure for the API is too elegant not to try.
The comments on this one are worth a read; there are some well thought-out rejections of this.
(Like so many of the ranty genre, it's taking a single use-case and insisting it covers all cases. Yes, some APIs could be replaced by a negotiated machine-readable version of an HTML page, but other APIs serve specific machine access patterns that don't (and shouldn't) map neatly to the pages humans see.)
Lazy loading is a good one. Perhaps you're letting someone scroll through a list of items, and as they near the bottom you load another 10. What forever-maintained page with a permanent URI does that map to?
Even if the API returns just a list of the relevant items, and then you make a separate call to get those objects in your desired representation, there's still a need for the API to serve up the transient bit.
Let's say you put those itens on the /itens?page=5&itens_per_page=10 URL, is there any problem with a site where I type that same URL on my browser and get a HTML page with those same itens, while your Javascript gets JSON? Because that's what the article recommends, and I can't see any reason not to agree with the author.
Even more, it would be great to add an "X-Content-Version" header, and get the right version of the API.
There's not a problem, but is there a point? It means creating an essentially useless HTML page. There's expense and overhead to doing it, in both initial dev and maintenance.
That expense has to be justified, and what is the justification? "Some guy says you shouldn't have an API, just alternative representations of your HTML, therefore we must have HTML versions of our entire API, even if their content is fully dynamic and doesn't need a permanent static URI".
This sounds like a good idea, but it's not. For an example like a single image, or a product page, it works well. But most of the page views that you want to offer don't correspond neatly to a single REST entity - think "dashboards" and shopping carts and all the varied pages that exist in a modern application. And conversely many REST entities that you want in your API model simply don't correspond to frontend pages.
The notion of a single canonical URL for each object is attractive, but it breaks down as soon as you want to use many-many relationships efficiently. Like databases, APIs are and should be denormalized for efficiency. Given this, there's very little benefit to keeping the human- and machine-readable URLs for a given object the same, and there are downsides - do you really want every AJAX request to include all your user's cookies?
The value of API keys is that they give you a point of contact with the developers using your API. If you want to redesign the web page, you can just do it - users might get annoyed, but they'll be able to figure out how to find their information on the new page. If you want to redesign your API, you'll break existing clients. By forcing developers to provide an email address and log in every 6 months to get a new key, you get a way to give them fair warning of upcoming changes.
(And the gripe about multiple interfaces is a red herring; the webapp (whether traditional or client-side) should be one more client of your API.)
Article makes no sense to me. He is just advocating for RESTful architecture in API design, which hardly matches the controversialist tone. At the same time it completely ignores anything but the simplest read-only API with a 1:1 mapping to public resources. It's like trying to make an argument about aircraft design whilst referencing a bicycle.
I see these "embrace my programming paradigm via my awful, mixed-context, confusing argument" on HN more and more. Seems to me it's just some project-managment-type thinking in abstract high-level ways of how much easier his business would be if everyone thought just like he did.
Well, guess what, there's nothing particularly valuable about your perspective. In fact, it sucks and it's wrong. Even Jeff Bezos perspective is wrong and stupid, but he paid 10,000 developers to embrace it. Just because your job would be so much easier if everyone architecture their data so you wouldn't have to doesn't mean anyone has a reason to. Maybe instead of me creating a single standard API for you to scrape my content, you fuck off and take your money with you? How does that sound? I think we have an agreement. (this is what every website ever has said).
I don't understanding why having two different URLs is such a big deal.
It's not about having different URLs, it's about having different code. If your "API" is just your website with a different view/template, why would you have different URLs?
And how do I open the new API thing in my browser?
It's already open: it's the website. If you want to see the data that your code is getting, you get your browser to ask for it, using for example: http://jsonview.com/
I agree with the public limited API vs HTML point: Github limits their API to 60 requests per hour[1] without authenticating - or I can just scrape it for the simple boolean value I need.
Web scraping is buggy and unreliable at best. Modern HTML is designed for browsers to interpret and display the same way, not to communicate data. If web scraping were to be at all viable, the HTML would need to be in a consistent, easy to parse, format that didn't require any dynamic evaluation.
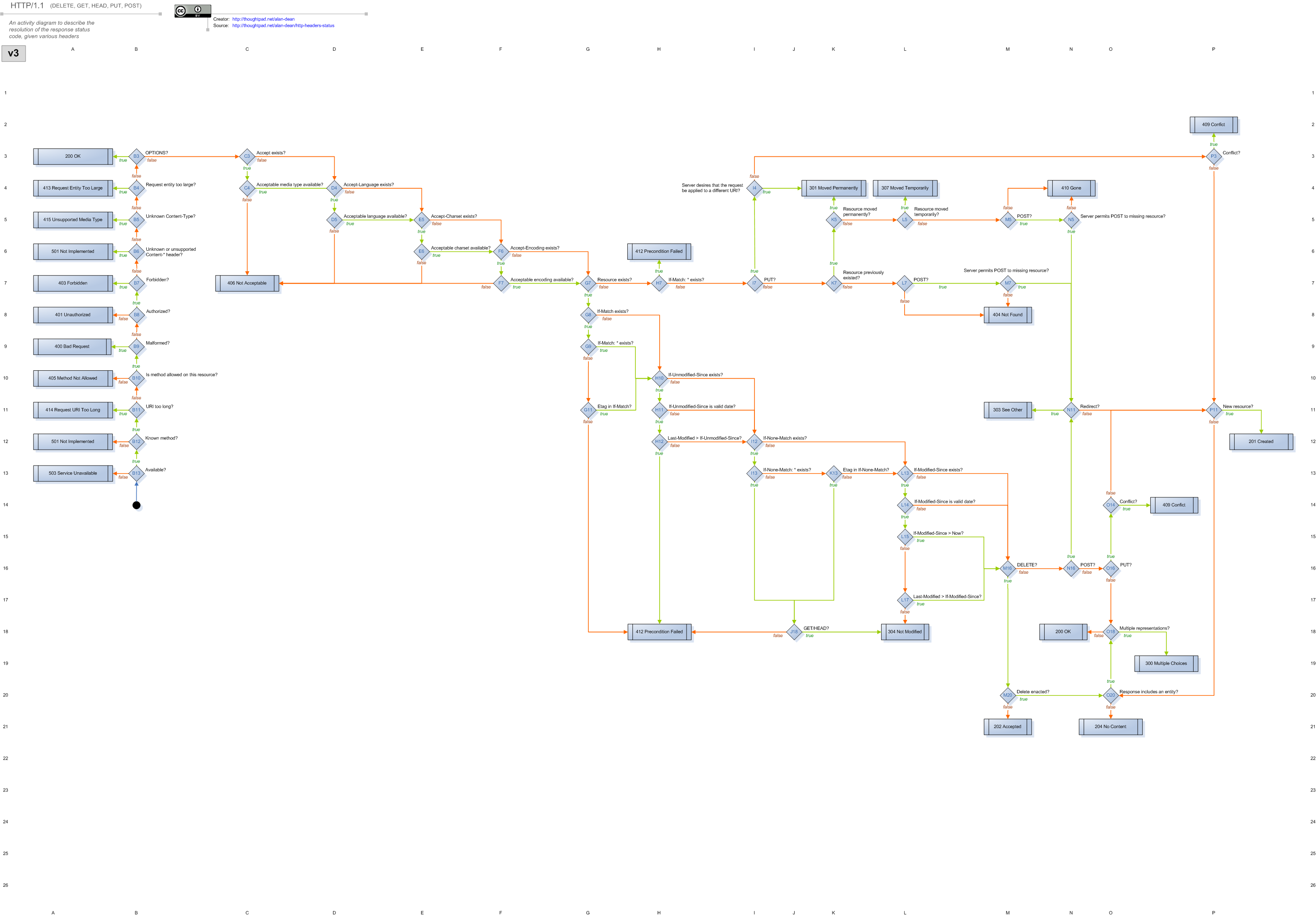{kind=link}
Here's the great thing about it. If APIs are built this way, and if clients are built to read and understand common and registered hypermedia types, there could be a time where clients and servers are able to communicate in such a way that the media type becomes seemingly invisible to the developer. We see this with the most popular REST client/server combo, the browser and the web server that serves up HTML. As the user, you can traverse the RESTful HTML API that websites have while the media type, HTML, is mostly concealed to the user. In other words, there is a chance that a good number of HTML websites are more RESTful than most of the APIs we see today.
In reducing REST to simply RPC over the web and skipping over the ideas of content negotiation and hypermedia types, we are missing out on the genius behind how the web was designed to be used. The author is really wanting us to go back to that instead of progressing toward the current patterns of fracturing your resources into separate APIs.