I saw this. The problem is that it's not comparing "hand-written assembly" to "not hand-writing assembly", it's comparing scalar code with vector code. If you wrote C code using AVX intrinsics, you'd get similar speed-ups without hand-writing any assembly.
And the annoying part is that there are good reasons to write hand-written assembly in some particular cases. Video decoders contain a lot of assembly for a reason: you often have extremely tight loops where 1) every instruction matters, 2) the assembly is relatively straightforward, and 3) you want dependable performance which doesn't change across compilers/compiler versions/compiler settings. But those reasons don't let you make ridiculous claims like "94x improvement from hand-written assembly compared to C".
> And the annoying part is that there are good reasons to write hand-written assembly in some particular cases.
The major, and well-known problem is that hand-written assembly is usually 100% non-portable. Maybe it is okay if you need the boost only in few platforms. But that still requires few different implementations.
> C with AVX intrinsics or C with NEON intrinsics or C with SVE intrinsics is also 100% non-portable
That’s not true because C with SIMD intrinsics is portable across operating systems. Due to differences in calling conventions and other low-level things, assembly is specific to a combination of target ISA and target OS.
Here’s a real-life example what happens when assembly code fails to preserve SSE vector registers specified as non-volatile in the ABI convention of the target OS: https://issues.chromium.org/issues/40185629
Scalar languages can go a long ways in this exercise. There are a few hiccups in trying to vectorize scalar languages, but see how well clang's latest -O3 models can do on C++.
I would love to see ISPC take off. It's my favorite way of abstracting code in this new computing paradigm. But it doesn't seem to be getting much traction.
I think the future is also going to be less "SIMD" and more "MIMD" (there's probably a better term for that). You even see in AVX512 with things like aggregations (which aren't SIMD), that there's no reason a single op has to be the same exact operation spread over 512/(data size) slots. You can just as easily put popular sets of operations into the tool set.
SIMD coders are doing DirectX / HLSL and/or Vulcan in practice. Or CUDA of course.
AVX512 is nice, but 4000+ shaders on a GPU is better. CPUs sit at an awkward point, you need a small dataset that suffers major penalties for CPU/GPU transfers.
Too large, and GPU RAM is better as a backing store. Too small, no one notices the differences.
> CPUs sit at an awkward point, you need a small dataset that suffers major penalties for CPU/GPU transfers.
Or a dataset so large that it won't fit in the memory of any available GPU, which is the main reason why high-end production rendering (think Pixar, ILM, etc) is still nearly always done on CPU clusters. Last I heard their render nodes typically had 256GB RAM each, and that was a few years ago so they might be up to 512GB by now.
Yes but GPU clusters with 256++ GB of VRAM is possible and superior in bandwidth thanks to NVSwitch.
I'd say CPUs still have the RAM advantage but closer to 1TB+ of RAM, where NVSwitch no longer scales to. CPUs with 1TB of RAM are a fraction of the cost too, so price/performance deserves a mention.
------
Even then, PCIe is approaching the bandwidth of RAM (latency remains a problem of course).
For Raytracing in particular, certain objects (bigger background objects or skymaps) have a higher chance of being hit.
There are also OctTrees where you can have rays bounce inside of a 8GB chunk (all of which is loaded in GPU RAM only), and only reorganize the rays when they leave a chunk.
So even Pixar-esque scenes can be rendered quickly in 8Gb chunks. In theory of course, I read a paper on it but I'm not sure if this technique is commercial yet.
But basically, raytrace until a ray leaves your chunk. If it does, collate it for another pass to the chunk it's going to. On the scale of millions of rays (like in Pixar movies), enough are grouped up that it improves rendering while effectively minimizing GPU VRAM usage.
Between caching common objects and this octtree / blocks technique, I think Raytracing can move to pure GPU. Whenever Pixar feels like spending a $Billion on the programmers of course.
Not a C coder but isn't there a way to embed platform specific optimizations into your C project and make it conditional, so that during build time you get the best implementation?
Yes, but then you have to write (and debug and maintain) each part 3 times.
There are also various libraries that create cross platform abstractions of the underlying SIMD libraries. Highway, from Google, and xSIMD are two popular such libraries for C++. SIMDe is a nice library that also works with C.
> Yes, but then you have to write (and debug and maintain) each part 3 times.
could you not use a test suite structure (not saying it would be simple) that would run the suite across 3 different virtualized chip implementations? (The virtualization itself might introduce issues, of course)
FFmpeg is the most successful of such projects and it uses handwritten assembly. Ignore the seductive whispers of people trying to sell you unreliable abstractions. It's like this for good reasons.
Or you just say that my code is only fast on hardware that supports nativ AVX512 (or whatever). In many cases where speed really matters that is a reasonable tradeoff to make.
You can always do that using build flags, but it doesn't make it portable, you as a programmer still have to manually port the optimized code to all the other platforms.
Yeah, you can do that, but that still means you write platform-specific code. What you typically do is that you write a cross-platform scalar implementation in standard C, and then for each target you care about, you write a platform-specific vectorized implementation. Then, through some combination of compile-time feature detection, build flags, and runtime feature detection, you select which implementation to use.
(The runtime part comes in because you may want a single amd64 version of your program which uses AVX-512 if that's available but falls back to AVX-256 and/or SSE if it's not available)
For any code that's meant to last a bit more than a year, I would say that should also include runtime benchmarking. CPUs change, compilers change. The hand-written assembly might be faster today, but might be sub-optimal in the future.
The assumption that vectorized code is faster than scalar code is a pretty universally safe assumption (assuming the algorithm lends itself to vectorization of course). I'm not talking about runtime selection of hand-written asm compared to compiler-generated code, but rather runtime selection of vector vs scalar.
To clarify, it's 94x the performance of the naive C implementation in just one type of filter. On the same filter, the table posted to twitter shows SSSE3 at 40x and AVX2 at 67x. So maybe just a case where most users were using AVX/SSE and there was no reason to optimize the C.
But this is just one feature of FFmpeg. Usually the heaviest CPU user is encode and decode, which is not affected by this improvement.
It's interesting and good work, but the "94x" statement is misleading.
According to someone in the dupe thread, the C implementation is not just naive with no use of vector intrinsics, it also uses a more expensive filter algorithm than the assembly versions, and it was compiled with optimizations disabled in the benchmark showing a 94x improvement:
Talk about stacking the deck to make a point. Finely tuned assembly may well beat properly optimized C by a hair, but there's no way you're getting a two orders of magnitude difference unless your C implementation is extremely far from properly optimized.
If and only if someone has spent the time to write optimizations for your specific platform.
GCC for AVR is absolutely abysmal. It has essentially no optimizations and almost always emits assembly that is tens of times slower than handwritten assembly.
For just a taste of the insanity, how would you walk through a byte array in assembly? You'd load a pointer to a register, load the value at that pointer, then increment the pointer. AVR devices can load and post-increment as a single instruction. This is not even remotely what GCC does. GCC will load your pointer into a register, then for each iteration it adds the index to the pointer, loads the value with the most expensive instruction possible, then subtracts the index from the pointer.
In assembly, the correct AVR method takes two cycles per iteration. The GCC method takes seven or eight.
For every iteration in every loop. If you use an int instead of a byte for your index, you've added two to four more cycles to each loop. (For 8 bit architectures obviously)
I've just spent the last three weeks carefully optimizing assembly for a ~40x overall improvement. I have a *lot* to say about GCC right now.
You've mis-understood. The 8tap filter is part of the HEVC encode loop and is used for sub pixel motion estimation. This is likely an improvement in encoding performance, but it's only in one specific coding tool.
FFMPEG uses hand written assembly across their code base, and while 94x may not be representative everywhere, it's generally true that they regularly outperform the compiler with assembly:
^ this, took my biggest step entry into programming via learning how to get my videos on an iPod Video in 2004, that eventually required compiling ffmpeg and keeping up with it.
I'll bet money, sight unseen, that poster above is right its used for HEVC. I'll bet even more money its not some massive out of nowhere win, hand-writing assembly for popular codecs was de rigeur for ffmpeg. Thrust of the article, or at least the headline, is clickbait-y.
> GPU cores aren't any good at largely serial things like video decoding
I'm surprised to hear this, considering GPUs are often used for video encoding and decoding. For Nvidia cards, this is called NVDEC, and AMD/Intel both have corresponding features for their video cards.
NVENC/NVDEC and similar technologies use what is effectively an ASIC that happens to be integrated on the GPU. It doesn't use the general purpose GPU cores. This is the reason why the limitations on e.g. which codecs it supports are so strictly tied to the hardware generation; it's just fixed function hardware.
There's no reason you can't bundle the same kind of ASIC on a CPU too, and indeed Intel does do that with QuickSync. For video game capture/screen recording though (which is a big part of what people tend to do with NVEnc) it might be a bit more convenient for the chip to be on the GPU? I don't know, not a GPU expert.
> For video game capture/screen recording though (which is a big part of what people tend to do with NVEnc) it might be a bit more convenient for the chip to be on the GPU?
Yeah there's usually a fast path which copies the framebuffer directly to the encoder internally, so the huge uncompressed frames never have to be transferred over the PCI Express bus.
That doesn't use the GPU cores. They just happen to package dedicated video hardware alongside it, but it's more similar to a CPU with a specialized DSP attached.
Any kind of decompression isn't fully parallelizable. If you've found any opportunities, that means the compression wasn't as efficient as it theoretically could be. Most codecs are merciful and eg restart the entropy coder across frames, which is why the multithreaded decoding in ffmpeg is able to work.
(But it comes with a lossless video codec called ffv1 that doesn't allow this.)
Yeah, I wrote my CS dissertation on this. It started as me writing a GPGPU video codec (for a simplified h264), and turned into me writing an explanation of why this wouldn't work. I did get somewhere with a hybrid approach (use the GPU for a first pass without intra-frame knowledge, followed by a CPU SIMD pass to refine), but it wasn't much better than a pure CPU SIMD implementation and used a lot more power.
x264 actually gets a little use out of GPGPU - it has a "lookahead" pass which does a rough estimate of encoding over the whole video, to see how complex each scene is and how likely parts of the picture are to be reused later. That can be done in CUDA, but IIRC it has to run like 100 frames ahead before the speed increase wins over the CPU<>GPU communication overhead.
NVENC is trash, fast trash, but trash none the less. Encode the same source file with FFMPEG at the same bitrate using NVENC and the CPU and the loss of quality with NVENC is readily visible. NVDEC is fine, but if you're encoding with the CPU, you'll lose performance moving the frames over to the CPU. Sure you can offload it all with NVDEC+NVENC, but only if your only criteria is speed, rather than quality or file size.
The GPU is a lot slower than the CPU - per core/thread. Otherwise you would need to select different core/thread counts on both sides, or set something like a power limit in watts. When it comes to watts the process node (nanometers) will largely determine the outcome.
This is a slightly misleading comparison, because they're comparing naive scalar C code to hand-vectorized assembly, skipping over hand-vectorized C with vendor intrinsics. Assembly of course always wins if enough effort is put into tuning it, but intrinsics can usually get extremely close with much less effort.
For reasons unknown to me the FFmpeg team has a weird vendetta against intrinsics, they require all platform-specific code to be written in assembly even if C with intrinsics would perform exactly the same. It goes without saying that assembly will be faster if you arbitrarily forbid using the fastest C constructs.
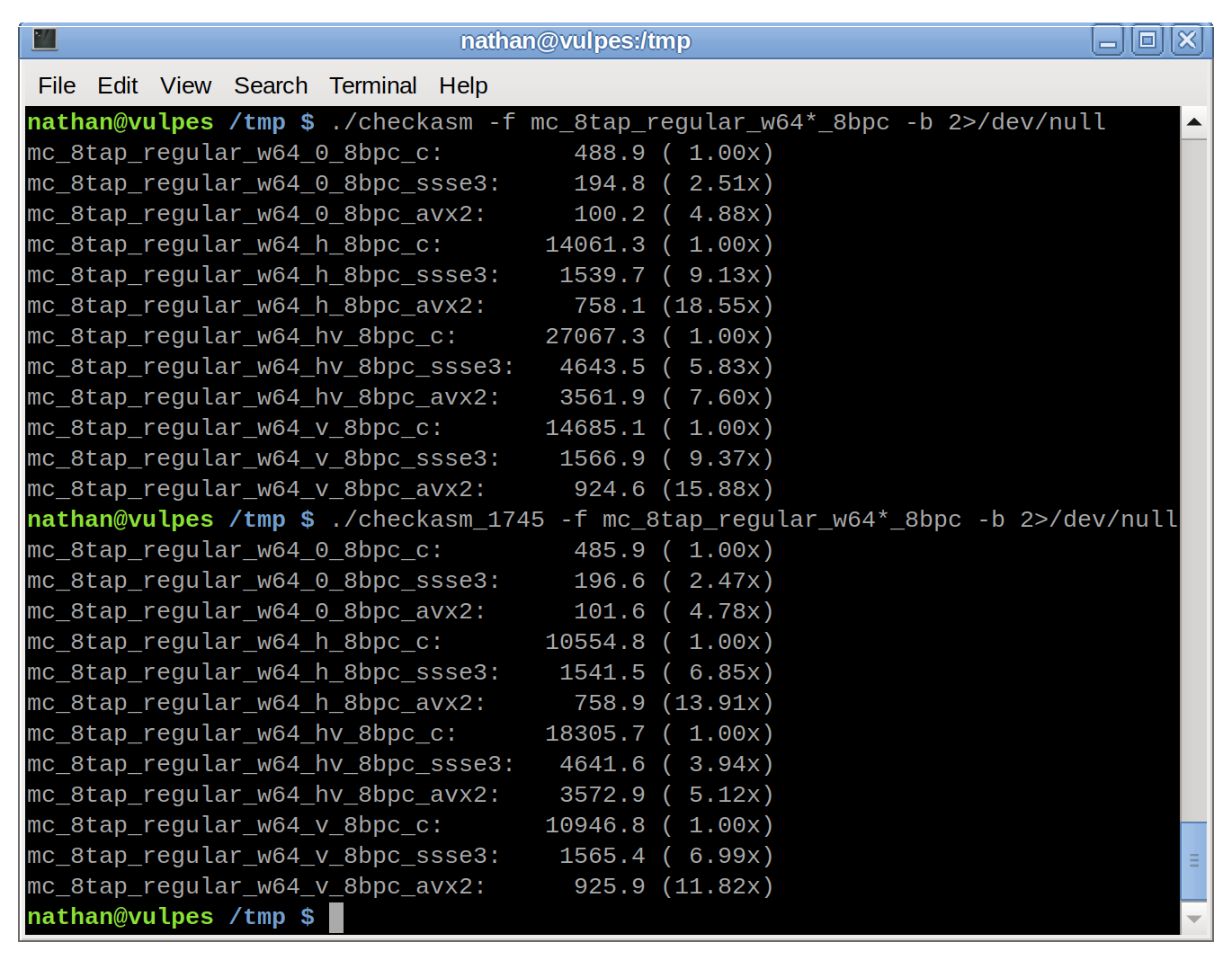
It is actually quite a bit more misleading. I was not able to reproduce these numbers on Zen2 hardware, see https://people.videolan.org/~unlord/dav1d_6tap.png. I spoke with the slide author and he confirmed he was using an -O0 debug build of the checkasm binary.
What's more, the C code is running an 8-tap filter where the SIMD for that function (in all of SSSE3, AVX2 and AVX512) is implemented as 6-tap. Last week I posted MR !1745 (https://code.videolan.org/videolan/dav1d/-/merge_requests/17...) which adds 6-tap to the C code and brings improved performance to all platforms dav1d supports.
This, of course, also closes the gap in these numbers but is a more accurate representation of the speed-up from hand-written assembly.
The thing I found interesting in the AVX512 gains over AVX2. That's a pretty nice gain from the wider instruction set which has often been ignored in the video community.
The important thing to understand about why AVX512 is a big deal is not the width. AVX512 adds new instructions and new instruction encodings. They doubled the number of registers (16->32), and added mask registers that allow you to remove special cases at the end of loops when the array is not a multiple of the vector width. And there is piles for new permutation operations and integer operations that allow it to be useful in more cases.
The part Intel struggles with is that in many places if they had the 256-bit max width but all the new operations then they could build a machine that is faster than the 512-bit version. (assuming the same code was written for both vector widths) The reason is the ALUs could be faster and you could have more of them.
For most operations, on most CPUs, you can get the same results with twice as many AVX2 instructions. And that's excluding the CPUs with no AVX512 at all.
But the number of situations where AVX512 has a significant advantage is growing, so interest will grow alongside it.
> FFmpeg team has a weird vendetta against intrinsics
To be fair, ffmpeg is really old software. Wikipedia says they released their initial version in the end of 2000. The software landscape was very different.
Back then, there were multiple competing CPU architectures. In modern world we only have two mainstream ones, AMD64 and ARM64, two legacy ones in the process of being phased out, x86 and 32-bit ARM, and very few people care about any other CPUs.
Another thing, C compilers of 2000 weren’t good in terms of performance of the generated code. Clang only arrived in 2007. In 2000, neither GCC nor VC++ had particularly good optimizers or code generators.
Back in 2000, it was reasonable to use assembly for performance-critical code like that. It just they never questioned that decision later, despite they should have done that many years ago.
FFmpeg developers aren't stupid and aren't doing things because of historical accident. If you don't mind writing platform specific code, it simply works better this way.
The other reason to do it is that, since x86 intrinsics are named in Hungarian notation, they're so hard to read that the asm is actually more maintainable.
The code is correct, and on some processors runs slightly faster than the original. Clang is the only compiler which does anything like that. And the example is irrelevant to ffmpeg because it operates on FP64 numbers, video codecs mostly do integer math.
> they're so hard to read that the asm is actually more maintainable
That’s subjective, I’m using SIMD intrinsics for years and I find them way better than assembly.
Another thing, you can treat C as a high-level language as opposed to portable assembler. If you define structures, functions and classes in C++ which use these SIMD vectors, readability of intrinsics becomes way better than assembly. Here’s a good example of a library designed that way: https://github.com/microsoft/DirectXMath
The intrinsics aren't portable across architectures, so using them vs inline asm (or linking with a .s/.asm file) is more about convenience/ease of use than portability (although they might be slightly more portable across different OSes for the _same_ architecture, e.g. macOS/linux for aarch64).
In some ways, I prefer the "go big or go home" of asm either inline, or in a .s/.asm file, although both inline and .s/.asm have portability issues (e.g. inline asm syntax across C/C++ compilers or the flavor of the .s/.asm files depending on your assembler).
Intrinsics do have certain advantages besides convenience, since the compiler can reason about them in ways that it can't with an opaque blob of asssembly. For example if you set the compiler to tune for a specific CPU architecture then it can re-order intrinsics according to the instruction costs of that specific hardware, whereas with assembly you would have to manually write a separate implementation for each architecture (and AFAICT FFmpeg doesn't go that far).
Those kind of optimizations aren't needed on big desktop CPUs these days, they don't need special scheduling or anything.
And yes, when it's important it does do that. They aren't stupid. (An example is that unaligned SSE loads are very slow on some CPUs but faster on others.)
> but intrinsics can usually get extremely close with much less effort
Why 'much less effort' though? Intrinsics are on the same abstraction level as an equivalent sequence of assembly instructions aren't they? And they only target one specific ISA anyway and are not portable between CPU architectures, so the difference between coding in intrinsics and assembly doesn't seem all that big. Also I wonder if MSVC and GCC/Clang intrinsics are fully compatible to each other, compiler compatibility might be another reason to use assembly.
Instrinsics more or less map to specific assembly instructions, but the instruction scheduling and register allocation is still handled by the compiler, which you have to do by hand in raw assembly. Possibly multiple times, since the optimal instruction scheduling is hardware specific. Intrinsics can also be automatically inlined, constant folded, etc, which you don't get with assembly.
Also Intel and ARM themselves specify the C intrinsics for their architectures so they're the same across MSVC, GCC and Clang, it's not like the wild west of other compiler extensions.
Clang doesn't guarantee that; it runs everything through its optimizer, which means you can use an intrinsic and not get the instruction it's named after.
The other big general issue is memory aliasing. If you're working on 8-bit data then C says that means it aliases everything and it's going to deoptimize your other memory accesses. Conversely if you're freely switching types like SIMD tends to do, that's against the aliasing rules.
Hmm right, makes sense. I do wonder though if actually making use of the high level convenience then can harm performance again, e.g. let's say I'm building intrinsic parameters with regular C scalar expressions, or use if-else control flow between intrinsics. Convenient to do, but can't be great for performance versus fully simdified code.
Intrinsics are compatible across compilers and OSs within the same architecture, and are also mostly compatible between 32 and 64 bit variants of the same architecture. With asm, you have to handle the 3 different calling conventions between x86, x86-64, and win64, and also write two completely separate implementations for arm32 and arm64, instead of just one x86 intrinsic and one NEON intrinsic version. Sure ffmpeg tries to automatically handle the different x86 calling conventions with standard macros, but there's still some %if WIN64 scattered around, and 32-bit x86's register constraints means larger functions are littered with %if ARCH_X86_64.
Which brings us to the most "more effort" of assembly - no variables or inline functions, only registers and macros. Which is okay for self-contained functions a hundred lines or so, but less so with heavily templated multi-thousand line files of deeply intertwined macros nested 4 levels deep. Being able to write an inlined function that has no side effects felt a thousand lines away reduces mental effort by a lot, as does not having to redo register allocation across a thousand lines because you now need another temporary register for a short section of code, or even think about it much in the first place to still get near-optimal performance on modern CPUs.
> This is a slightly misleading comparison, because they're comparing naive scalar C code to hand-vectorized assembly, skipping over hand-vectorized C with vendor intrinsics. Assembly of course always wins if enough effort is put into tuning it, but intrinsics can usually get extremely close with much less effort.
It's a perfectly valid comparision between straightforward C and the best hand optimization you can get.
> For reasons unknown to me the FFmpeg team has a weird vendetta against intrinsics, they require all platform-specific code to be written in assembly even if C with intrinsics would perform exactly the same.
Wanting to standardize on a single language for low level code is absolutely reasonable. This way contributors only need to know standard C as well as assembly instead of standar C, assembly and also intel intrisics which are a fusion of the two but also not the same as either and have their own gotchas.
I mean currently, contributors who want to work on vectorized algorithms need to know C, amd64 assembly with SSE/AVX instructions, aarch64 assembly with NEON instructions and aarch64 assembly with SVE instructions (and presumably soon, or maybe already, risc-v assembly with the vector extension). I wouldn't say it's simpler than needing to know C, C with SSE/AVX instricsics, C with NEON intrinsics, C with SVE intrinsics and C with risc-v vector intrinsics.
You don't need to submit all of those, but generally these vectorized DSP functions are parts of decoding straight out of the spec, so there isn't a new way to do it.
Sometimes there is of course. In that case you can get someone else to help, or one platform just runs ahead of the others.
Right, but you see my point, don't you? For every set of intrinsics you'd need to know as a contributor if the vectorized code was in C, there is an assembly language and a set of intrinsics you need to know as a contributor today. Moving to C wouldn't increase the set of things a contributor needs to know.
For the curious, this is fresh from VDD24[1]. The 94x is mildly contested since IIRC how you write the C code really matters (e.g. scalar vs autovectorized). But even with vectorized C code the speed up was something like >10x, which is still great but not as fun to say.
One clarification: this is an optimization in dav1d, not FFmpeg. FFmpeg uses dav1d, so it can take advantage of this, but so can other non-FFmpeg programs that use dav1d. If you do any video handling consider adding dav1d to your arsenal!
There’s currently a call for RISC-V (64-bit) optimizations in dav1d. If you want to dip your toes in RISC-V optimizations and assembly this is a great opportunity. We need more!
They introduced efficiency cores, and those don't have AVX-512. Lots of software breaks if it suddenly gets moved to a core which supports different instructions, so OSes wouldn't be able to move processes between E-cores and P-cores if P-cores supported AVX-512 while E-cores didn't.
As long as the vast majority of processes don't use AVX-512, you could probably catch sigill or whatever in kernel and transparently move to a P-core, marking the task to avoid rescheduling on an E-core it again in near future. Probably not very efficient, but tasks which use AVX are usually something you want to run on a P-core anyway.
That's actually an interesting idea, and yeah that should work.
You'd still have the problem that software will use the CPUID instruction to do runtime-detection of AVX-512 support. You'd need some mechanism to make CPUID report to lack AVX-512 support if the OS doesn't support catching SIGILL in the way you describe, and make CPUID report to support AVX-512 (even when run on an E-core) if the OS supports catching SIGILL and moving to a P-core. That sounds doable, but I have no idea how easy it is. You'd need to be able to configure AVX-512 reporting differently for virtual machine guests than for the host, and you'd need the host to be able to reconfigure AVX-512 support at runtime to support e.g kexec. There are probably tonnes of other considerations as well which I'm not thinking about.
Given the relatively limited benefit from going 512-bit wide compared to 256-bit, I guess I understand the decision, but you're right that it's not as black and white as I made it out to be.
> As long as the vast majority of processes don't use AVX-512
One very common function used by nearly every process is memcpy, and it's often optimized to use the largest vector size available, so it wouldn't surprise me if the vast majority of processes does use AVX-512.
Depends. If they can essentially "just" add a bit of microcode to emulate AVX-512 with a 256-bit wide vector pipeline then it shouldn't be worse. I don't know if that's feasible though or if there are other costs (would you need physical 512-bit wide registers for example?).
You can double-pump a lot of the instructions, but emulating some of the rest would lead to severe slowdowns in code that should instead be using an AVX2 implementation.
It's better not to fake it that hard. If those cores don't have it, don't pretend to have it.
The reason is that those CPUs have two types of cores, performance and efficiency, and only the former supports AVX512. Early on you could actually get access to AVX512 if you disabled the efficiency cores, but they put a stop to that in later silicon revisions, IIRC with the justification that AVX512 didn't go through proper validation on those chips since it wasn't supposed to be used.
Probably reduce wasted silicon because very few consumers will see a significant benefit in everyday computing tasks. Also supposedly they had issues combining it with e-cores. Intel is struggling to get their margins back up. The 11th gen had AVX512 but the people who cared seem to be PS3 emulator users.
A 94x performance boost will not come from just writing some assembly instructions. It will come from changing terrible memory access patterns to be optimal, not allocating memory in a hot loop and using SIMD instructions. At 94x there could be some algorithmic changes too, like not doing redundant calculations on pixels that can have their order reversed and applied to other pixels.
There was probably just one single bottleneck that got fixed by the ASM code. Often in my experience, not enough work is done to identify what the bottleneck is before trying to solve performance.
It's not like every line of C takes N amount of time and every line of ASM takes a fraction of N. Most lines of C compile to the optimal ASM right off the bat. If this was one of those case like 90% of cases are, where you just need to identify the bottleneck, you can normally fix it and stay in C (not ASM), although I used to enjoy doing some inline ASM in my C code to milk out every last bit of performance in critical loops.
The title gives the impression that handwritten assembly code is the cause of this performance improvement, when in fact it was use of AVX-512 SIMD instructions that really made the difference.
I've got to wonder how gcc's AVX-512 vectorization would compare ?
Is this a case where x64 beats out Apple Silicon, (at least for AMDs Zen4 and Zen 5 and Intel servers)? What size are the SVE registers on M3/M4 [1]? Sorry for sounding inflammatory, I'm genuinely interested in the performance on Apple Silicon. I expect ffmpeg devs at least have NEON implementations, if not SVE for the newer Mx chips.
This is interesting. I thought one should generally avoid the vectorized AVX-512 because most processors with it get thermally throttled. I'll definitely take a closer look now.
By the way, whenever I've written platform-specific code we've just #ifdef'd it and compiled it one way or the other. How does ffmpeg and other binary-distributed software do it? You can't late compile on the platform so presumably they select implementations at runtime? Install-time configuration seems too risky (people move hard drives and so on).
> I thought one should generally avoid the vectorized AVX-512 because most processors with it get thermally throttled.
AFAIK, that's only the case for Intel processors; on AMD processors, you can use AVX-512 without fear.
> How does ffmpeg and other binary-distributed software do it? You can't late compile on the platform so presumably they select implementations at runtime?
Yes, that's what they do, either manually, automatically with compiler help (ifunc or similar), or with a full copy of the whole library which is loaded from an alternative directory whenever the necessary hardware features are present (for instance, when AVX-512 and a number of other features is available, the x86-64-v4 subdirectory will be used; run "/lib64/ld-linux-x86-64.so.2 --help" to see which ones would be used on your system).
I used to work on video encoding/decoding. Good times! I thoroughly enjoyed running the profiler and squeezing out a few percent here and there. It always amazed me what features CPUs have once you have an understanding of their low level architectures. They are true marvels.
I often think that our “portable assembler” isn’t really what it says on the tin any more, and that this is an opportunity for a new programming paradigm to be developed where it once stood.
{kind=link}
And the annoying part is that there are good reasons to write hand-written assembly in some particular cases. Video decoders contain a lot of assembly for a reason: you often have extremely tight loops where 1) every instruction matters, 2) the assembly is relatively straightforward, and 3) you want dependable performance which doesn't change across compilers/compiler versions/compiler settings. But those reasons don't let you make ridiculous claims like "94x improvement from hand-written assembly compared to C".