My feeling is that the answer is "no", in the sense that these RNNs wouldn't be able to universally replace Transformers in LLMs, even though they might be good enough in some cases and beat them in others.
Here's why.
A user of an LLM might give the model some long text and then say "Translate this into German please". A Transformer can look back at its whole history. But what is an RNN to do? While the length of its context is unlimited, the amount of information the model retains about it is bounded by whatever is in its hidden state at any given time.
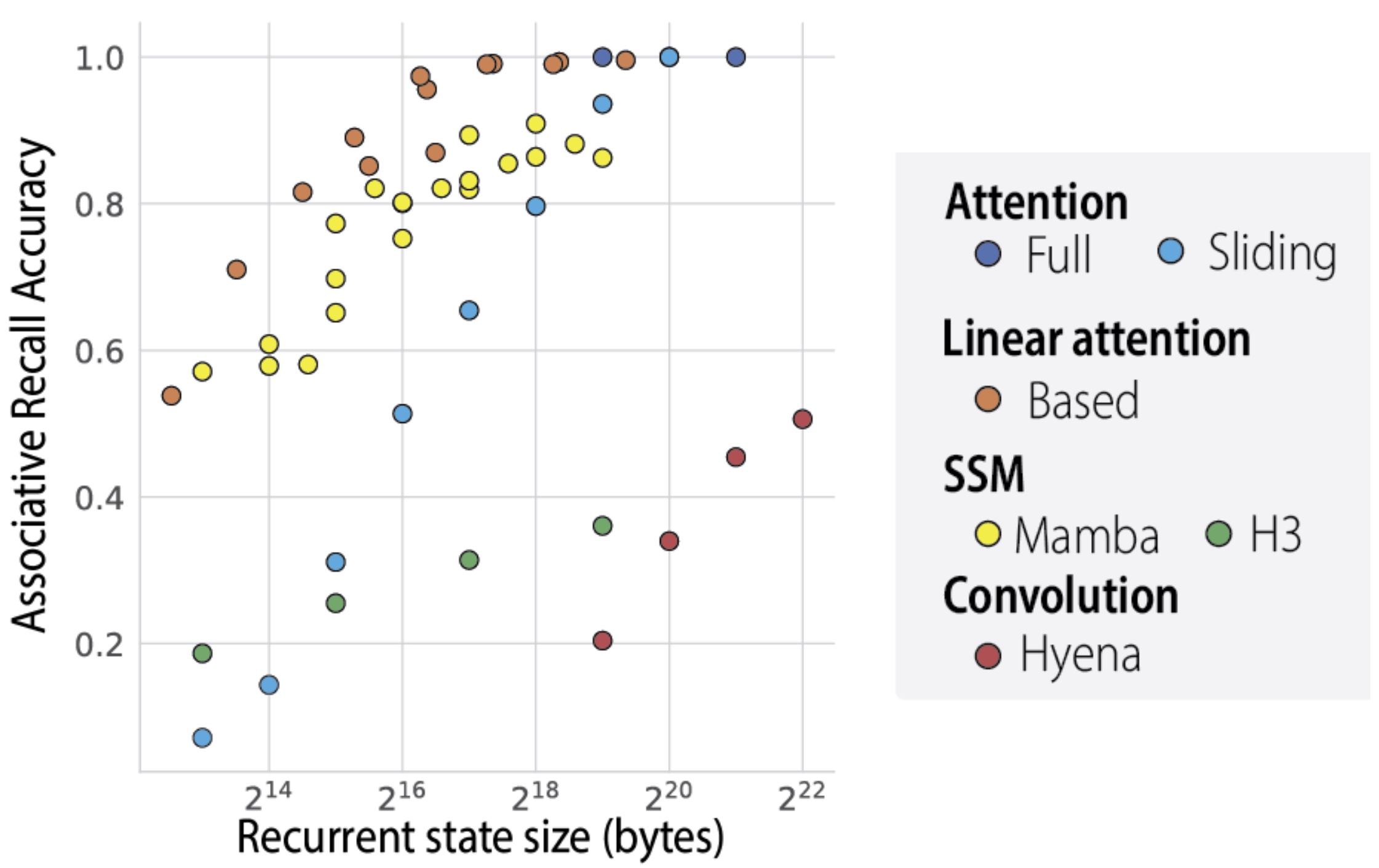
Transformers actually have an quantifiable state size (see https://hazyresearch.stanford.edu/static/posts/2024-06-22-ac...) although it's anywhere between 200k and 2M floats (for 360M and 1.33B respectively iinm). So a sufficiently sized RNN could have the same state capacity as a transformer.
> Transformers actually have an quantifiable state size
Are you griping about my writing O(X^2) above instead of precisely 2X^2, like this paper? The latter implies the former.
> So a sufficiently sized RNN could have the same state capacity as a transformer.
Does this contradict anything I've said? If you increase the size of the RNN, while keeping the Transformer fixed, you can match their recurrent state sizes (if you don't run out of RAM or funding)
> a Transformer layer can look back see O(X^2) numbers, while an RNN can only see O(X) numbers
The thing is RNN can look back infinitely if you don't exceed the state capacity. For transformers the state it is defined semi-implicitly (you can change the hidden dims but you cannot extend the look back; ignoring transformer-xl et al.) defined by the amount of tokens, for an RNN it's defined explicitly by the state size.
The big-O here is irrelevant for the architectures since it's all in the configuration & implementation of the model; i.e. there is no relevant asymptote to compare.
As an aside this was what was shown in the based paper, the fact that you can have a continuity of state (as with RNN) while have the same associative recall capability as a transformer (the main downfall of recurrent methods at that point).
> The big-O here is irrelevant for the architectures since it's all in the configuration & implementation of the model; i.e. there is no relevant asymptote to compare.
?!
NNs are like any other algorithm in this regard. Heck, look at the bottom of page 2 of the Were RNNs All We Needed paper. It has big-O notation there and elsewhere.
> I was responding to
>> a Transformer layer can look back see O(X^2) numbers, while an RNN can only see O(X) numbers
In the BASED paper, in Eq. 10, sizeof(s) = 2dN. But I defined d = N = X above. Ergo, sizeof(s) = 2X^2 = O(X^2).
For minGRU, sizeof(s) = d. Ergo, sizeof(s) = X = O(X).
That's just the state calculation which would be O(N) and O(1) respectively.
The based paper is saying if you made Transformers recurrent you would have a state size of 2Nd -> O(N), while based has a state size of d*d' -> O(1).
Transformers do have O(N^2) time & memory complexity, and Based/RNN/SSM {O(N) time, O(1) mem}, with respect to sequence length if that's what you mean. The point is it doesn't really give an indication of quality.
We can choose our constant arbitrarily so the big-O you've stated only indicates memory/time-complexity not 'look-back' ability relevant to any task. If you input the entire sequence N times into an RNN, you also have perfect recall with O(N^2) but it's not exactly an efficient use of our resources.
Ideally our state memory is maximally utilized, this is the case for RNNs in the limit (although likely oversubscribed) but is not the case for transformers. The holy grail is to have an input-dependent state-size, however that is quite difficult.
Simplistic thinking. An RNN hidden parameter space of high dimension provides plenty of room for linear projections of token histories. I think people just do not realize just how huge R^N can be.
> Simplistic thinking. An RNN hidden parameter space of high dimension provides plenty of room for linear projections of token histories. I think people just do not realize just how huge R^N can be.
16N bits as hard limit, but more realistically, about 2N bits or less of useful information probably.
You'd need to grow the network dimension in proportion to the maximum sequence length just to avoid the information theoretical limit.
That problem has plagued RNNs since the 90s: there's an information precision problem (how many bits do you need older states to carry), a decay problem (the oldest information is the weakest) and a mixing problem (it tends to mix/sum representations).
The counterargument here is that you can just scale the size of the hidden state sufficiently such that it can hold compressed representations of whatever-length sequence you like. Ultimately, what I care about is whether RNNs could compete with transformers if FLOPs are held constant—something TFA doesn't really investigate.
Well, that's what Transformer already does... One problem with the scaling you're describing is that there would be a massive amount of redundant information stored in hidden activations during training the RNN. The hidden state at each time step t in the sequence would need to contain all info that (i) could be useful for predicting the token at time t and (ii) that could be useful for predicting tokens at times >t. (i) is obvious and (ii) is since all information about the past is transferred to future predictions through the current hidden state. In principle, Transformers can avoid storing redundant info in multiple hidden states at the cost of having to maintain and access (via attention) a larger hidden state at test/eval time.
> there would be a massive amount of redundant information stored in hidden activations
Is there a way to prove this? One potential caveat that comes to mind for me is that perhaps the action of lerping between the old state and the new could be used by the model to perform semantically meaningful transformations on the old state. I guess in my mind it just doesn't seem obvious that the hidden state is necessarily a collection of "redundant information" — perhaps the information is culled/distilled the further along in the sequence you go? There will always be some redundancy, sure, but I don't think that such redundancy necessarily means we have to use superlinear methods like attention.
All information about the past which will be available for predicting future tokens must be stored in the present state. So, if some bits of info about some past tokens at times less than t_p will be used for predicting some future token at time t_f, those bits must be passed through all states at times from t_p to t_f. The bits are passed through the recurrence. Once information about past tokens is lost from the hidden state it is gone forever, so it must be stored and carried across many steps up until it finally becomes useful.
The information cost of making the RNN state way bigger is high when done naively, but maybe someone can figure out a clever way to avoid storing full hidden states in memory during training or big improvements in hardware could make memory use less of a bottleneck.
> The information cost of making the RNN state way bigger is high when done naively, but maybe someone can figure out a clever way to avoid storing full hidden states in memory during training or big improvements in hardware could make memory use less of a bottleneck.
Isn't this essentially what Mamba [1] does via its 'Hardware-aware Algorithm'?
>> A user of an LLM might give the model some long text and then say "Translate this into German please". A Transformer can look back at its whole history.
Which isn't necessary. If you say "translate the following to german." Instead, all it needs is to remember the task at hand and a much smaller amount of recent input. Well, and the ability to output in parallel with processing input.
It's necessary for arbitrary information processing if you can forget and have no way to "unforget".
A model can decide to forget something that turns out to be important for some future prediction. A human can go back and re-read/listen etc, A transformer is always re-reading but a RNN can't and is fucked.
If the networks are to ever be a path to a closer to general intelligence, they will anyway need to be able to ask for context to be repeated, or to have separate storage where they can "choose" to replay it themselves. So this problem likely has to be solved another way anyway, both for transformers and for RNNs.
For a transformer, context is already always being repeated every token. They can fetch information that became useful anytime they want. I don't see what problem there is to solve here.
That's just because we twisted it's arm. One could for example feed the reversed input after, ie abc|cba where | is a special token. That would allow it to react to any part of the message.
Having 2 passes can enable so much more than a single pass.
Another alternative could be to have a first pass make notes in a separate buffer while parsing the input. The bandwidth of the note taking and reading can be much much lower than that required for fetching the billions of parameters.
{kind=link}
Here's why.
A user of an LLM might give the model some long text and then say "Translate this into German please". A Transformer can look back at its whole history. But what is an RNN to do? While the length of its context is unlimited, the amount of information the model retains about it is bounded by whatever is in its hidden state at any given time.
Relevant: https://arxiv.org/abs/2402.01032