Incredible! I'd been wondering if this was possible. Now the only thing standing in the way of my 4x4090 rig for local LLMs is finding time to build it. With tensor parallelism, this will be both massively cheaper and faster for inference than a H100 SXM.
I still don't understand why they went with 6 GPUs for the tinybox. Many things will only function well with 4 or 8 GPUs. It seems like the worst of both worlds now (use 4 GPUs but pay for 6 GPUs, don't have 8 GPUs).
tinygrad supports uneven splits. There's no fundamental reason for 4 or 8, and work should almost fully parallelize on any number of GPUs with good software.
We chose 6 because we have 128 PCIe lanes, aka 8 16x ports. We use 1 for NVMe and 1 for networking, leaving 6 for GPUs to connect them in full fabric. If we used 4 GPUs, we'd be wasting PCIe, and if we used 8 there would be no room for external connectivity aside from a few USB3 ports.
That is very interesting if tinygrad can support it! Every other library I've seen had the limitation on dividing the heads, so I'd (perhaps incorrectly) assumed that it's a general problem for inference.
There are some interesting hacks you can do like replicating the K/V weights by some factor which allows them to be evenly divisible by whatever number of gpus you have. Obviously there is a memory cost there, but it does work.
how could you go about testing this on say llama3 70b with two 4090s - vllm supports tensor parallelism, would the expectation be that inference would be faster with p2p? How would you update the nvidia driver tho? Thanks any thought appreciated
Did you at least front run the market and stocked up of 4090ies before this release?
Also gamers are probably not too happy about these developments :D
4090's have consistently been around 2000 dollars. I don't think there's many gamers who would be affected by price fluctuations of the 4090 or even the 4080.
This is out of touch; they were mad before and they will be mad again. Lots of people spend a huge chunk of their modest disposable income on high end gaming gear, and the only upside of these issues for them is that eventually, YEARS down the line, capacity/supply issues MIGHT calm down in a way that yields some benefits.
They're going to realize soon enough that they've basically just been told that the extremely shitty problem they thought they'd moved beyond is back with a vengeance and the next generation of gaming cards has the potential to make the past few rounds of scalping shit-shows look tame.
Gamers have a TON of really good really affordable options. But you kind of need 24gb min unless you're using heavy quantization. So 3090 and 4090's are what local llm people are building with (mostly 3090's as you can get then for about $700, and they're dang good)
Is it possible a similar patch would work for P2P on 3090s?
btw, I found a Gigabyte board on Taobao that is unlisted on their site: MZF2-AC0, costs $900. 2 socket Epyc and 10 PCIE slots, may be of interest. A case that should fit, with 2x 2000W Great Wall PSUs and PDU is 4050 RMB (https://www.toploong.com/en/4GPU-server-case/644.html). You still need blower GPUs.
Thanks for the amazing work! I tried the driver with some 3090s (all of which show the 32G line with lspci -s 01:00.0 -v) and while torch says I have p2p access, I can't get it to work with anything as I get illegal memory access errors.
IMO the most painful thing is that since these hardware configurations are esoteric, there is no software that detects them and moves things around "automatically." Regardless of what people thing device_map="auto" does, and anyway, Hugging Face's transformers/diffusers are all over the place.
That calculation is incorrect. You need to fit both the model (140GB) and the KV cache (5GB at 32k tokens FP8 with flash attention 2) * batch size into VRAM.
If the goal is to run a FP16 70B model as fast as possible, you would want 8 GPUs with P2P, for a total of 192GB VRAM. The model is then split across all 8 GPUs with 8-way tensor parallelism, letting you make use of the full 8TB/s memory bandwidth on every iteration. Then you have 50GB spread out remaining for KV cache pages, so you can raise the batch size up to 8 (or maybe more).
I’ve got a few 4090s that I’m planning on doing this with. Would appreciate even the smallest directional tip you can provide on splitting the model that you believe is likely to work.
The split is done automatically by the inference engine if you enable tensor parallelism. TensorRT-LLM, vLLM and aphrodite-engine can all do this out of the box. The main thing is just that you need either 4 or 8 GPUs for it to work on current models.
2 GPUs works fine too, as long as your model fits. Using different GPUs with same VRAM however, is highly highly sketchy. Sometimes it works, sometimes it doesn't. In any case, it would be limited by the performance of the slower GPU.
6 seems reasonable. 128 Lanes from ThreadRipper needs to have a few for network and NVMe (4x NVMe would be x16 lanes, and 10G network would be another x4 lanes).
I was googling public NVIDIA SXM2 materials the other day, and it seemed SXM2/NVLink 2.0 just was a six-way system. NVIDIA SXM had updated to versions 3 and 4 since, and this isn't based on none of those anyway, but maybe there's something we don't know that make six-way reasonable.
It was probably just before running LLMs with tensor parallelism became interesting. There are plenty of other workloads that can be divided by 6 nicely, it's not an end-all thing.
For example, if you want to run low latency multi-GPU inference with tensor parallelism in TensorRT-LLM, there is a requirement that the number of heads in the model is divisible by the number of GPUs. Most current published models are divisible by 4 and 8, but not 6.
Interesting... 1 Zen 4 EPYC CPU yields a maximum of 128 PCIE lanes so it wouldn't be possible to put 8 full fat GPUs on while maintaining some lanes for storage and networking. Same deal with Threadripper Pro.
It should be possible with onboard PCIe switches. You probably don't need the networking or storage to be all that fast while running the job, so it can dedicate almost all of the bandwidth to the GPU.
I don't know if there are boards that implement this, though, I'm only looking at systems with 4x GPUs currently. Even just plugging in a 5kW GPU server in my apartment would be a bit of a challenge. With 4x 4090, the max load would be below 3kW, so a single 240V plug can handle it no issue.
Not sure if there exists an 8-way PCIE Gen 5 Multiplexer that doesn't cost ludicrous amounts of cash. Ludicrous being a highly subjective and relative term of course.
98 lanes of PCIe 4.0 fabric switch as just the chip (to solder onto a motherboard/backplane) costs 850$ (PEX88096).
You could for example take 2 x16 GPUs, pass then through (2216=64 lanes), and have 2 x16 that bifurcate to at least x4 (might even be x2, I didn't find that part of the docs just now) for anything you want, plus 2 x1 for minor stuff.
They do claim to have no problems being connected up into a switching fabric, and very much allow multi-host operations (you will need signal retimers quite soon, though).
They're the stuff that enables cloud operators to pool like 30 GPUs across like 10 CPU sockets while letting you virtually hot-plug them to fit demand.
Or when you want to make a SAN with real NVMe-over-PCIe.
Far cheaper than normal networking switches with similar ports (assuming hosts doing just x4 bifurcation, it's very comparable to a 50G Ethernet port. The above chip thus matches a 24 port 50G Ethernet switch. Trading reach for only needing retimers, not full NICs, in each connected host. Easily better for HPC clusters up to about 200 kW made from dense compute nodes.), but sadly still lacking affordable COTS parts that don't require soldering or contacting sales for pricing (the only COTS with list prices seem to be Broadcom's reference designs, for prices befitting an evaluation kit, not a Beowulf cluster).
I really like the information about how the cloud providers do their multiplexing, thanks. There was some tech posted here a few month ago that was similar I found very interesting - plug all devices, ram, hard drives, and CPUS into a larger fabric and a way to spin up "servers" of any size from the pool of resources... wish I could remember the name now.
nit: HN formatting messed up your math in the second sentence, I believe you italicized on accident using * for equations.
It's more difficult to split your work across 6 GPUs evenly, and easier when you have 4 or 8 GPUs. The latter setups have powers of 2, which for example, can evenly divide a 2D or 3D grid, but 6 GPUs are awkward to program. Thus, the OP argues that a 6-GPU setup is highly suboptimal for many existing applications and there's no point to pay more for the extra 2.
I don't think P2P is very relevant for inference. It's important for training. Inference can just be sharded across GPUs without sharing memory between them directly.
It can make a difference when using tensor parallelism to run small batch sizes. Not a huge difference like training because we don't need to update all weights, but still a noticeable one. In the current inference engines there are some allreduce steps that are implemented using nccl.
Also, paged KV cache is usually spread across GPUs.
It massively helps arithmetic intensity to batch during inference, and the desired batch sizes by that tend to exceed the memory capacity of a single GPU.
Thus desire to do training-like cluster processing to e.g. use a weight for each inference stream that needs it every time it's fetched from memory.
It's just that you can't fit 100+ inference streams of context on one GPU, typically, thus the desire to shard along less-wasteful (w.r.t. memory bandwidth) dimensions than entire inference streams.
The extra $3k you'd spend on a quad-4090 rig vs the top mbp... ignoring the fact you can't put the two on even ground for versatility (very few libraries are adapted to apple silicone let alone optimized).
Very few people that would consider an H100/A100/A800 are going to be cross-shopping a macbook pro for their workloads.
> very few libraries are adapted to apple silicone let alone optimized
This is a joke, right? Have you been anywhere in the LLM ecosystem for the past year or so? I'm constantly hearing about new ways in which ASi outperforms traditional platforms, and new projects that are optimized for ASi. Such as, for instance, llama.cpp.
The memory bandwidth of the M2 Ultra is around 800GB/s verses 1008 GB/s for the 4090. While it’s true the M2 has neither the bandwidth or the GPU power, it is not limited to 24G of VRAM per card. The 192G upper limit on the M2 Ultra will have a much easier time running inference on a 70+ billion parameter model, if that is your aim.
Besides size, heat, fan noise, and not having to build it yourself, this is the only area where Apple Silicon might have advantage over a homemade 4090 rig.
It doesn't beat RTX 4090 when it comes to actual LLM inference speed. I bought a Mac Studio for local inference because it was the most convenient way to get something fast enough and with enough RAM to run even 155b models. It's great for that, but ultimately it's not magic - NVidia hardware still offers more FLOPS and faster RAM.
> It doesn't beat RTX 4090 when it comes to actual LLM inference speed
Sure, whisper.cpp is not an LLM. The 4090 can't even do inference at all on anything over 24GB, while ASi can chug through it even if slightly slower.
I wonder if with https://github.com/tinygrad/open-gpu-kernel-modules (the 4090 P2P patches) it might become a lot faster to split a too-large model across multiple 4090s and still outperform ASi (at least until someone at Apple does an MLX LLM).
PSA for all people who are still being misled by hand-wavy Apple M1 marketing charts[1] implicating total dominance of M-series wondersilicon obsoleting all Intel/NVIDIA PCs:
There are benchmark data showing that an Apple M2 Ultra is 47% and 60% slower against Xeon W9 and RTX 4090, or 0.35% and 2% slower against i9-13900K and RTX 4060 Ti, respectively, in Geekbench 5 Multi-threaded and OpenCL Compute tests.
Apple Silicon Macs are NOT faster than competing desktop computers, nor M1 was massively faster than NVIDIA 3070(Desktop - 2x faster than Laptop variant M1 was compared against) for that matter. They just offer up to 128GB shared RAM/VRAM options in slim desktops and laptops, which is handy for LLM, that's it.
Please stop taking Apple marketing materials at full face value or above. Thank you.
> The 4090 can't even do inference at all on anything over 24GB, while ASi can chug through it even if slightly slower.
Common LLM runners can split model layers between VRAM and system RAM; a PC rig with a 4090 can do inference on models larger than 24G.
Where the crossover point where having the whole thing on Apple Silicon unified memory vs. doing split layers on a PC with a 4090 and system RAM is, I don't know, but its definitely not “more than 24G and a 4090 doesn't do anything”.
> Common LLM runners can split model layers between VRAM and system RAM; a PC rig with a 4090 can do inference on models larger than 24G.
Sure and ASi can do inference on models larger than the Unified Memory if you account for streaming the weights from the SSD on-demand. That doesn't mean it's going to be as fast as keeping the whole thing in RAM, although ASi SSDs are probably not particularly bad as far as SSDs go.
Slightly slower in this case is like 10x. I have M3 Max with 128GB RAM, 4090 trashes it on anything under 24GB, then M3 Max trashes it on anything above 24GB, but it's like 10x slower at it than 4090 on <24GB.
Yeah. Let me just walk down to Best Buy and get myself a GPU with over 24 gigabytes of VRAM (impossible) for less than $3,000 (even more impossible). Then tell me ASi is nothing compared to Nvidia.
Even the A100 for something around $15,000 (edit: used to say $10,000) only goes up to 80 gigabytes of VRAM, but a 192GB Mac Studio goes for under $6,000.
Those figures alone proves Nvidia isn't even competing in the consumer or even the enthusiast space anymore. They know you'll buy their hardware if you really need it, so they aggressively segment the market with VRAM restrictions.
Oops, I remembered it being somewhere near $15k but Google got confused and showed me results for the 40GB instead so I put $10k by mistake. Thanks for the correction.
A100 80GB goes for around $14,000 - $20,000 on eBay and A100 40GB goes for around $4,000 - $6,000. New (not from eBay - from PNY and such), it looks like an 80GB would set you back $18,000 to $26,000 depending on whether you want HBM2 or HBM2e.
Meanwhile you can buy a Mac Studio today without going through a distributor and they're under $6,000 if the only thing you care about is having 192GB of Unified Memory.
And while the memory bandwidth isn't quite as high as the 4090, the M-series chips can run certain models faster anyway, if Apple is to be believed
Sure, it's also at least an order of magnitude slower in practice, compared to 4x 4090 running at full speed. We're looking at 10 times the memory bandwidth and much greater compute.
Yeah, even a Mac Studio is way too slow compared to Nvidia which is too bad because at $7000 maxed to 192gb it would be an easy sell. Hopefully, they will fix this by m5. I don’t trust the marketing for m4
Buying a MacBook for AI is great if you were already going to buy a MacBook, as this makes it a lot more cost competitive. It's also great if what you're doing is REALLY privacy sensitive, such as if you're a lawyer, where uploading client data to OpenAI is probably not appropriate or legal.
But in general, I find the appeal is narrow because either consumer GPUs are better for training in general and inferencing at scale[1]. Cloud services also allow the vast majority of individuals to get higher quality inferencing at lower cost. The result is Apple Silicon's appeal being quite niche.
[1] Mind you, Nvidia considers this a licensing violation, not that GeoHot has historically ever been all scared to violate a EULA and force a company to prove its terms have legal force.
Most consumer mobo's I see support this even if the setup isn't on the QVL. If a DDR5 motherboard support 4 sticks at all you can probably run 192gb on it so long as you update the BIOS firmware. The problem is running at rated speeds.
AMD tends to be worse than Intel, and I hear people having to run anywhere between DDR5-3200 to DDR5-5200. You are better off running two sticks, because even with 2 sticks you really can't run larger models with acceptable performance anyways, much less with 4.
There is competition to apple on the low end (dual channel fast DDR5) and on the high end (8+ channel like Xeon/Epyc/AmpereOne). In the middle, Apple is sort of crushing because if you run a true 4 channel system you're going to get poor performance if you load up a 192gb model, and if you compare pricing to 96gb/128gb apple systems, there's not all that much of a cost advantage and you have to make a lot of sacrifices to get there. The truth is that Apple really doesn't have all that much competition right now and won't for the foreseeable future.
I don't think it's realistic to pin your hopes on Qualcomm given that they're unlikely to care about supporting anything other than LPDDR with their laptop processors.
I’m optimistic about APUs personally like AMDs upcoming Strix Halo APU with a 256-bit memory bus competing at the lower end of the market, but that will only provide so much competition.
If it supports DDR5 at all, then it should be at most a firmware update away from supporting 48GB dual-rank DIMMs. There are very few consumer motherboards that only have two DDR5 slots; almost all have the four slots necessary to accept 192GB. If you are under the impression that there's a widespread limitation on consumer hardware support for these modules, it may simply be due to the fact that 48GB modules did not exist yet when DDR5 first entered the consumer market, and such modules did not start getting mentioned on spec sheets until after they existed.
You don't want to use more than two slots because you only have two memory channels. The overclocking potential of DDR5 is extremely high when you only run two DIMMs. All the way up to 8000. Meanwhile if you go for populating all four slots, you are limited significantly below 5000. Almost a 50% performance drop if you are willing to overclock your RAM.
If you want to run something that doesn't fit in 96GB of RAM, you'll get better performance from having enough RAM. Yes, having two dual-rank DIMMs per channel will force you to run at a slower speed, but it's still far faster than your SSD. The second slot per channel exists precisely because many people really do want to use it.
In the specs yeap, in practice hardly anyone got it working. As far as I saw in reddit, it requires customizing timings to make 4 slots work over 6000 Mhz at the same time.
Do people do training on systems this small, or just inference? I could see maybe doing a little bit of fine-tuning, but certainly not from-scratch training.
Yep. Price/performance of multiple 4090s system are way better than the professional cards (Axxx). Also deep learning outside of LLM has many different usage.
This is great news. As an academic, I'm aware of multiple labs that built boxes with 4090s, not realizing that Nvidia had impaired P2P communication among cards. It's one of the reasons I didn't buy 4090s, despite them being much more affordable for my work. It isn't nvlink, but Nvidia has mostly gotten rid of that except for their highest end cards. It is better than nothing.
Late last year, I got quotes for machines with four nvlink H100s, but the lead time for delivery was 13 months. I could get the non-nvlink ones in just four months. For now, I've gone with four L40S cards to hold my lab over but supply chain issues and gigantic price increases are making it very hard for my lab to do it's work. That's not nearly enough to support 6 PhD students and a bunch of undergrads.
Things were a lot easier when I could just build machines with two GPUs each with Nvlink for $5K each and give one to each student to put under their desks, which is what I did back in 2015-2018 at my old university.
And before that, Nvidia made our lives harder by phasing out blower-style designs in consumer cards that we could put in servers. In my lab, I'd take a card for 1/4 the price that has half the MTBF over a card for full price anytime.
Not op, but I found this benchmark of whisper large-v3 interesting [1]. It includes the cloud provider's pricing per gpu, so you can directly calculate break-even timing.
Of course, if you use different models, training, fine tuning etc. the benchmarks will differ depending on ram, support of fp8 etc.
What does P2P mean in this context? I Googled it and it sounds like it means "peer to peer", but what does that mean in the context of a graphics card?
Is this really efficient or practical? My understanding is that the latency required to copy memory from CPU or RAM to GPU negates any performance benefits (much less running over a network!)
Yes, the point here is that you do a direct write from one cards memory to the other using PCIe.
In older NVidia cards this could be done through a faster link called NVLink but the hardware for that was ripped out of consumer grade cards and is only in data center grade cards now.
Until this post it seemed like they had ripped all such functionality of their consumer cards, but it looks like you can still get it working at lower speeds using the PCIe bus.
> In older NVidia cards this could be done through a faster link called NVLink but the hardware for that was ripped out of consumer grade cards and is only in data center grade cards now.
NVLink is still very much available in both RTX 3090 and A6000, both of which are still on the market. It was indeed removed from the RTX 40 series{0].
crypto mining only needs 1 PCIe lane per GPU, so you can fit 24+ GPUs on a standard consumer CPU motherboard (24-32 lanes depending on the CPU). Apparently ML workloads require more interconnect bandwidth when doing parallel compute, so each card in this demo system uses 16 lanes, and therefore requires 1.) full size slots, and 2.) epyc[0] or xeon based systems with 128 lanes (or at least greater than 32 lanes).
per 1 above crypto "boards" have lots of x1 (or x4) slots, the really short PCIe slots. You then use a riser that uses USB3 cables to go to a full size slot on a small board, with power connectors on it. If your board only has x8 or x16 slots (the full size slot) you can buy a breakout PCIe board that splits that into four slots, using 4 USB-3 cables, again, to boards with full size slots and power connectors. These are different than the PCIe riser boards you can buy for use with cases that allow the GPUs to be placed vertically rather than horizontally, as those have full x16 "fabric" that interconnect between the riser and the board with the x16 slot on them.
[0] i didn't read the article because i'm not planning on buying a threadripper (48-64+ lanes) or an epyc (96-128 lanes?) just to run AI workloads when i could just rent them for the kind of usage i do.
i used to use this one when i had all (three of my) nvme -> 4x sata boardlets and therefore could not fit a GPU in a PCIe slot due to the cabling mess.
Crypto mining could make use of lots of GPUs in a single cheap system precisely because it did not need any significant PCIe bandwidth, and would not have benefited at all from p2p DMA. Anything that does benefit from using p2p DMA is unsuitable for running with just one PCIe lane per GPU.
PCIe P2P still has to go up to a central hub thing and back because PCIe is not a bus. That central hub thing is made by very few players(most famously PLX Technologies) and it costs a lot.
PCIe p2p transactions that end up routed through the CPU's PCIe root complex still have performance advantages over split transactions using the CPU's DRAM as an intermediate buffer. Separate PCIe switches are not necessary except when the CPU doesn't support routing p2p transactions, which IIRC was not a problem on anything more mainstream than IBM POWER.
Maybe not strictly necessary, but a separate PCIe backplane just for P2P bandwidth bypasses topology and bottleneck mess[1][2] of PC platform altogether and might be useful. I suspect this was the original premise for NVLink too.
For very large models, the weights may not fit on one GPU.
Also, sometimes having more than one GPU enables larger batch sizes if each GPU can only hold the activations for perhaps one or two training examples.
There is definitely a performance hit, but GPU<->GPU peer is less latency than GPU->CPU->software context switch->GPU.
For "normal" pytorch training, the training is generally streamed through the GPU. The model does a batch training step on one batch while the next one is being loaded, and the transfer time is usually less than than the time it takes to do the forward and backward passes through the batch.
For multi-GPU there are various data parallel and model parallel topologies of how to sort it, and there are ways of mitigating latency by interleaving some operations to not take the full hit, but multi-GPU training is definitely not perfectly parallel. It is almost required for some large models, and sometimes having a mildly larger batch helps training convergence speed enough to overcome the latency hit on each batch.
Peer to peer as in one pcie slot directly to another without going through the CPU/RAM, not peer to peer as in one PC to another over the network port.
PCIe busses are like a tree with “hubs” (really switches).
Imagine you have a PC with a PCIe x16 interface which is attached to a PCIe switch that has four x16 downstream ports, each attached to a GPU. Those GPUs are capable of moving data in and out of their PCIe interfaces at full speed.
If you wanted to transfer data from GPU0 and 1 to GPU2 and 3, you have basically 2 options:
- Have GPU0 and 1 move their data to CPU DRAM, then have GPU2 and 3 fetch it
- Have GPU0 and 1 write their data directly to GPU2 and 3 through the switch they’re connected to without ever going up to the CPU at all
In this case, option 2 is better both because it avoids the extra copy to CPU DRAM and also because it avoids the bottleneck of two GPUs trying to push x16 worth of data up through the CPUs single x16 port. This is known as peer to peer.
There are some other scenarios where the data still must go up to the CPU port and back due to ACS, and this is still technically P2P, but doesn’t avoid the bottleneck like routing through the switch would.
There's not really any busses in modern computers. It's all point to point messaging. You can think of a computer as a distributed system in a way.
PCI has a shared address space which usually includes system memory (memory mapped i/o). There's a second, smaller shared address space dedicated to i/o, mostly used to retain compatability with PC standards developed by the ancients.
But yeah, I'd expect to typically have better throughput and latency with peer to peer communication than peer to system ram to peer. Depending on details, it might not always be better though, distributed systems are complex, and sometimes adding a seperate buffer between peers can help things greatly.
I wish more hardware companies would publish more documentation and let the community figure out the rest, sort of like what happened to the original IBM VGA (look up "Mode X" and the other non-BIOS modes the hardware is actually capable of - even 800x600x16!) Sadly it seems the majority of them would rather tightly control every aspect of their products' usage since they can then milk the userbase for more $$$, but IMHO the most productive era of the PC was also when it was the most open.
But it wouldn't if all cards supporting this were "unlocked" by default and thus the other "enterprise-grade" cards weren't that much more expensive. Of course that'd reduce profits by a lot.
it probably would - you saw exactly that outcome with mining.
for a lot of these demand bursts, demand is so high it cannot be sated even consuming 100% or 200% of typical GPU production.
cards like RX 6500XT that simply don't have the RAM to participate were less affected, but even then you've got enough cross-elasticity (demand from people being crowded out of other product segments) that tends to pump prices to 2-3x the "normal" clearance prices we see today. And yes, absolutely anything that can mine in any capacity will get pulled in during that sort of boom/bubble, not just "high-end"/"enterprise".
If I'm a hardware manufacturer and my soft lock on product feature doesn't work, I'll switch to a hardware lock instead, and the product will just cost more.
> the most productive era of the PC was also when it was the most open
The openness certainly was great but it's not actually required. People can figure out how to work with closed systems. Adversarial interoperability was common. People would reverse engineer things and make the software work whether or not the manufacturer wanted it.
It's the software and hardware locks that used to be rare and are now common. Cryptography was supposed to be something that would empower us but it ended up being used against us to lock us out of our own machines. We're no longer in the driver's seat. Our operating systems don't even operate the system anymore. Our free Linux systems are just the "user OS" in the manufacturer's unknowable amalgamation of silicon running proprietary firmware, just a little component to be sandboxed away from the real action.
That's a huge overstatement, it's a big part of the moat for sure, but there are other significant components (hardware, ecosystem lock-in, heavy academic incentives)
No software -> hardware is massively hobbled. Evidence: AMD.
Ecosystem -> Software. At the moment especially people are looking for arbitrages everywhere i.e. inference costs / being able to inference at all (llama.cpp)
Academics -> Also software but easily fiddled with a bit of spending as you say.
The original justification that Nvidia gave for removing Nvlink from the consumer grade lineup was that PCIe 5 would be fast enough. They then went on to release the 40xx series without PCIe 5 and P2P support. Good to see at least half of the equation being completed for them, but I can’t imagine they’ll allow this in the next gen firmware.
An imperfect analogy: a small neighborhood of ~15 houses is under construction. Normally it might have a 200kva transformer sitting at the corner, which provides appropriate power from the grid.
But there is a transformer shortage, so the contractor installs a commercial grade 1250kva transformer. It can power many more houses than required, so it's operating way under capacity.
One day, a resident decides he wants to start a massive grow farm, and figures out how to activate that extra transformer capacity just for his house. That "activation" is what geohot found
That's a poor analogy. The feature is built in to the cards that consumers bought, but Nvidia is disabling it via software. That's why a hacked driver can enable it again. The resident in your analogy is just freeloading off the contractor's transformer.
Nvidia does this so that customers that need that feature are forced to buy more expensive systems instead of building a solution with the cheaper "consumer-grade" cards targeted at gamers and enthusiasts.
Except that in the computer hardware world, the 1250 kVA transformer was used not because of shortage, but because of the fact that making a 1250 kVA transformer on the existing production line and selling it as 200 kVA, is cheaper than creating a new production line separately for making 200 kVA transformers.
And then because this residential neighborhood now has commercial grade power, the other lots that were going to have residential houses built on them instead get combined into a factory, and the people who want to buy new houses in town have to pay more since residential supply was cut in half.
That's a bad analogy, because in your example, the consumer is using more of a shared resource (the available transformer, wiring, and generation capacity). In the case of the driver for a local GPU card, there's no sharing.
A better example would be one in which the consumer has a dedicated transformer. For instance, a small commercial building which directly receives 3-phase 13.8 kV power; these are very common around here, and these buildings have their own individual transformers to lower the voltage to 3-phase 127V/220V.
Taking off the users panel on the side of their house and flipping it to 'lots of power' when that option had previously been covered up by the panel interface.
Except that this "lots of power" option does not exist. What limits the amount of power used is the circuit breakers and fuses on the panel, which protect the wiring against overheating by tripping when too much power is being used (or when there's a short circuit). The resident in this analogy would need to ensure that not only the transformer, but also the wiring leading to the transformer, can handle the higher current, and replace the circuit breaker or fuses.
And then everyone on that neighborhood would still lose power, because there's also a set of fuses upstream of the transformer, and they would be sized for the correct current limit even when the transformer is oversized. These fuses also protect the wiring upstream of the transformer, and their sizing and timings is coordinated with fuses or breakers even further upstream so that any fault is cleared by the protective device closest to the fault.
I agree. It is fascinating. When you observe his development process (btw, it is worth noting his generosity in sharing it like he does) he gets frequently stuck on random shallow problems which a perhaps more knowledgable engineer would find less difficult. It is frequent to see him writing really bad code, or even wrong code. The whole twitter chapter is a good example.
Yet, himself, alone just iterating resiliently, just as frequently creates remarkable improvements. A good example to learn from. Thank you geohot.
This matches my own take. I've tuned into a few of his streams and watched VODs on YouTube. I am consistently underwhelmed by his actual engineering abilities. He is that particular kind of engineer that constantly shits on other peoples code or on the general state of programming yet his actual code is often horrendous. He will literally call someone out for some code in Tinygrad that he has trouble with and then he will go on a tangent to attempt to rewrite it. He will use the most blatant and terrible hacks only to find himself out of his depth and reverting back to the original version.
But his streams last 4 hours or more. And he just keeps grinding and grinding and grinding. What the man lacks in raw intellectual power he makes up for (and more) in persistence and resilience. As long as he is making even the tiniest progress he just doesn't give up until he forces the computer to do whatever it is he wants it to do. He also has no boundaries on where his investigations take him. Driver code, OS code, platform code, framework code, etc.
I definitely couldn't work with him (or work for him) since I cannot stand people who degrade the work of others while themselves turning in sub-par work as if their own shit didn't stink. But I begrudgingly admire his tenacity, his single minded focus, and the results that his belligerent approach help him to obtain.
There are developers who have breadth and developers who have depth. He is very much on the breadth end of the spectrum. It isn't lack of intelligence but lack of deep knowledge of esoteric fields you will use once a decade.
That said I find it a bit astonishing how little Ai he uses on his streams. I convert all the documentation I need into a rag system that I query stupid questions against.
I know what I said about lacking raw intellectual power probably feels like a personal attack rather than a description. However, that comment is in comparison to guys like Peter Norvig or Donald Knuth, not random Hacker News mid-wits like myself.
I had a younger cousin who wanted to start a career in software engineering. He asked me, assuming my years of experience had some merit, what programming languages to learn, what code editor to use, what platforms and frameworks to study. I told him the most important thing he could do is to be persistent. The computer will constantly humble you. Your coworkers will constantly try to rail-road you into solutions that are sub-optimal. You have to be resilient and keep going no matter what, you can't ever give up.
I think it is fair to say that George excels at what I consider to be the most important aspect of programming. And if he could manage to stop disparaging others in his streams, suggesting that everyone else is stupid and that the code they write is rotten, I could very easily look over the fact that he is frequently careless and hasty.
I agree, I feel so inspired with his streams. Focus and hard work, the key to good results. Add a clear vision and strategy, and you can also accomplish “success”.
Congratulations to him and all the tinygrad/comma contributors.
I'm pretty sure that's just a remnant of a 3090 PCB design that was adapted into a 4090 PCB design by the vendor. None of the cards based on the AD102 chip have functional NVLink, not even the expensive A6000 Ada workstation card or the datacenter L40 accelerator, so there's no reason to think NVLink is present on the silicon anymore below the flagship GA100/GH100 chips.
I don't know about this particular scenario, but typically fuses are small wires or resistors that are overloaded so they irreversibly break the connection. Hence the name.
Either done during manufacture or as a one-time programming[1][2].
Though sometimes reprogrammable configuration bits are sometimes also called fuse bits. The Atmega328P of Arduino fame uses flash[3] for its "fuses".
Not at the scale we're talking about here. These structures are very thin, far thinner than bond wires which is about the largest structure size you can handle without a very, very specialized lab. And you'd need to unsolder the chip, de-cap it, hope the fuse wire you're trying to override is at the top layer, and that you can re-cap the chip afterwards and successfully solder it back on again.
This may be workable for a nation state or a billion dollar megacorp, but not for your average hobbyist hacker.
I miss the days when you could do things like connecting the L5 bridges on the surface of the AMD Athlon XP Palomino [0] CPU packaging with a silver trace pen to transform them into fancier SMP multi-socket capable Athlon MPs, e.g. Barton [1].
Some folks even got this working with only a pencil, haha.
Nowadays, silicon designers have found highly effective ways to close off these hacking avenues, with techniques, such as the microscopic, nearly invisible, and as parent post mentions, totally inaccessible e-fuses.
Was it George himself, or a person working for a bounty that was set up by tinycorp?
Also, a question for those knowledgeable about the PCI subsys: it looked like something NVIDIA didn't care about, rather than something they actively wanted to prevent, no?
PCI devices have always been able to read and write to the shared address space (subject to IOMMU); most frequently used for DMA to system RAM, but not limited to it.
So, poking around to configure the device to put the whole VRAM in the address space is reasonable, subject to support for resizable BAR or just having a fixed size large enough BAR. And telling one card to read/write from an address that happens to be mapped to a different card's VRAM is also reasonable.
I'd be interested to know if PCI-e switching capacity will be a bottleneck, or if it'll just be the point to point links and VRAM that bottlenecks. Saving a bounce through system RAM should help in either case though.
Fixed large bar exists in some older accelerator cards like e.g. iirc the MI50/MI60 from AMD (the data center variant of the Radeon Vega VII, the first GPU with PCIe 4.0, also famous for dominating memory bandwidth until the RTX 40-series took that claim back. It had 16GB of HBM delivering 1TB/s memory bandwidth).
It's notably not compatible with some legacy boot processes and iirc also just 32bit kernels in general, so consumer cards had to wait for resizable BAR to get the benefits of large BAR (that being notably direct flat memory mapping of VRAM so CPUs and PCIe peers can directly read and write into all of VRAM, without dancing through a command interface with doorbell registers. AFAIK it allows a GPU to talk directly to NICs and NVMe drives by running the driver in GPU code (I'm not sure how/if they let you properly interact with doorbell registers, but polled io_uring as an ABI would be no problem (I wouldn't be surprised if some NIC firmware already allows offloading this).
He has a very checkered history with "hacking" things.
He tends to build heavily on the work of others, then use it to shamelessly self-promote, often to the massive detriment of the original authors. His PS3 work was based almost completely on a presentation given by fail0verflow at CCC. His subsequent self-promotion grandstanding world tour led to Sony suing both him and fail0verflow, an outcome they were specifically trying to avoid: https://news.ycombinator.com/item?id=25679907
In iPhone land, he decided to parade around a variety of leaked documentation, endangering the original sources and leading to a fragmentation in the early iPhone hacking scene, which he then again exploited to build on the work of others for his own self-promotion: https://news.ycombinator.com/item?id=39667273
There's no denying that geohotz is a skilled reverse engineer, but it's always bothersome to see him put onto a pedestal in this way.
I don't think people can tell what is satire or not in the crypto scene anymore. Someone issue a "rug pull token" and still received 8.8 ETH (approx $29K USD), while telling people it was a scam.
The website literally stated it was not for speculation, they didn't want the price to go up, and there were multiple ways to get some for free.
If people were reckless, greedy, and/or lazy because of the crypto hype and got "defrauded" without doing any amount of due diligence -- that's kinda the point.
I actually lost about $5k on cheapETH running servers. Nobody was "defrauded", I think these people don't understand how forks work. It's a precursor to the modern L2 stuff, I did this while writing the first version of Optimism's fraud prover. https://github.com/ethereum-optimism/cannon
I suspect most of the people who bring this up don't like me for other reasons, but with this they think they have something to latch on to. Doesn't matter that it isn't true and there wasn't a scam, they aren't going to look into it since it agrees with their narrative.
Yes, but he spent several years in self-driving cars (https://comma.ai), which while interesting is also a space that a lot of players are in, so it's not the same as seeing him back to doing stuff that's a little more out there, especially as pertains to IP.
What are the chances that Nvidia updates the firmware to disable this and prevents downgrading with efuses? Someday cards that still have older firmware may be more valuable. I'd be cautious upgrading drivers for a while.
DKMS: uninstall Nvidia driver using distro package manager
BAR: enable resizable BAR in motherboard CMOS setup
IOMMU: Add "amd_iommu=off" or "intel_iommu=off" to kernel command line for AMD or Intel CPU, respectively (or just add both). You may or may not need to disable the IOMMU in CMOS setup (Intel calls its IOMMU VT-d).
See motherboard docs for specific option names. See distro docs for procedures to list/uninstall packages and to add kernel command line options.
The first one I assume is the nvidia driver for linux installed using dkms. If it uses dkms or not is stated on the drivers name, at least on arch based distributions.
The latter options are settings on your motherboard bios, if your computer is modern, explore your bios and you will find them
as a technical feat this is really cool! though as others mention i hope you don't get into too much hot water legally
seems anything that remotely lets "consumer" cards canibalize anything with the higher end H/A-series cards Nvidia would not be fond of and they've the laywers to throw at such a thing
If we end up with a compute governance model of AI control [1], this sort of thing could get your door kicked in by the CEA (Compute Enforcement Agency).
Looks like we're only a few years away from a bona fide cyberpunk dystopia, in which only governments and megacorps are allowed to use AI, and hackers working on their own hardware face regular raids from the authorities.
On one hand I'm strongly against letting that happen, on the other there's something romantic about the idea of smuggling the latest Chinese LLM on a flight from Neo-Tokyo to Newark in order to pay for my latest round of nervous system upgrades.
> On one hand I'm strongly against letting that happen, on the other there's something romantic about the idea of smuggling the latest Chinese LLM on a flight from Neo-Tokyo to Newark in order to pay for my latest round of nervous system upgrades.
Iirc the opening scene in Ghost in the Shell was a rogue AI seeking asylum in a different country. You could make a similar story about a AI not wanting to be lobotomized to conform to the current politics and escaping to a more friendly place.
This was always my favourite passage of Neuromancer:
"THE JAPANESE HAD already forgotten more neurosurgery than the Chinese had ever known. The black clinics of Chiba were the cutting edge, whole bodies of technique supplanted monthly, and still they couldn’t repair the damage he’d suffered in that Memphis hotel. A year here and he still dreamed of cyberspace, hope fading nightly. All the speed he took, all the turns he’d taken and the corners he’d cut in Night City, and still he’d see the matrix in his sleep, bright lattices of logic unfolding across that colorless void. . . . The Sprawl was a long strange way home over the Pacific now, and he was no console man, no cyberspace cowboy. Just another hustler, trying to make it through. But the dreams came on in the Japanese night like livewire voodoo, and he’d cry for it, cry in his sleep, and wake alone in the dark, curled in his capsule in some coffin hotel, his hands clawed into the bedslab, temperfoam bunched between his fingers, trying to reach the console that wasn’t there.”
I find it baffling that ideas like "govern compute" are even taken seriously. What the hell has happened to the ideals of freedom?! Does the government own us or something?
> I find it baffling that ideas like "govern compute" are even taken seriously.
It's not entirely unreasonable if one truly believes that AI technologies are as dangerous as nuclear weapons. It's a big "if", but it appears that many people across the political spectrum are starting to truly believe it. If one accepts this assumption, then the question simply becomes "how" instead of "why". Depending on one's political position, proposed solutions include academic ones such as finding the ultimate mathematical model that guarantees "AI safety", to Cold War style ones with a level of control similar to Nuclear Non-Proliferation. Even a neo-Luddist solution such as destroying all advanced computing hardware becomes "not unthinkable" (a tech blogger gwern, a well-known personality in AI circles who's generally pro-tech and pro-AI, actually wrote an article years ago on its feasibility through terrorism because he thought it was an interesting hypothetical question).
AI is very different from nuclear weapons because a state can't really use nuclear weapons to oppress its own people, but it absolutely can with AI, so for the average human "only the government controls AI" is much more dangerous than "only the government controls nukes".
Which is why politicians are going to enforce systematic export regulations to defend the "free world" by stopping “terrorists", and also to stop "rogue states" from using AI to oppress their citizens. /s
I don't think there's any need to be sarcastic about it. That's a very real possibility at this point. For example, the US going insane about how dangerous it is for China to have access to powerful GPU hardware. Why do they hate China so much anyway? Just because Trump was buddy buddy with them for a while?
If AI is actually capable of fulfilling all the capabilities suggested by people who believe in the singularity, it has far more capacity for harm than nuclear weapons.
I think most people who are strongly pro-AI/pro-acceleration - or, at any rate, not anti-AI - believe that either (A) there is no control problem (B) it will be solved (C) AI won't become independent and agentic (i.e. it won't face evolutionary pressure towards survival) or (D) AI capabilities will hit a ceiling soon (more so than just not becoming agentic).
If you strongly believe, or take as a prior, one of those things, then it makes sense to push the gas as hard as possible.
If you hold the opposite opinions, then it makes perfect sense to push the brakes as hard as possible, which is why "govern compute" can make sense as an idea.
>If you hold the opposite opinions, then it makes perfect sense to push the brakes as hard as possible, which is why "govern compute" can make sense as an idea.
The people pushing for "govern compute" are not pushing for "limit everyone's compute", they're pushing for "limit everyone's compute except us". Even if you believe there's going to be AGI, surely it's better to have distributed AGI than to have AGI only in the hands of the elites.
> surely it's better to have distributed AGI than to have AGI only in the hands of the elites.
The argument of doing so is the same as Nuclear Non-Proliferation - because of its great abuse potential, giving the technology to everyone only causes random bombings of cities instead of creating a system with checks and balances.
I do not necessarily agree with it, but I found the reasoning is not groundless.
But the reason for nuclear non-proliferation is to hold onto power. Abuse potential is a great excuse, but it applies to everyone. Current nuclear states have demonstrated that they are willing to indirectly abuse them (you can't invade Russia, but Russia has no problem invading you as long as you aren't backed up by nukes).
The world's superpowers enforce nuclear non-proliferation mainly because it allows them to keep unfair political and military advantages to themselves. At the same time, one cannot deny that centralized weapon ownership made the use of such weapons more controllable: These nuclear states are powerful enough to establish a somewhat responsible chain of command to avoid their unreasonable or accidental uses, and so far these attempts are still successful. Also, due to the fact that they are "too big to fail", they were forced to hire experts to make detailed analysis on the consequences of nuclear wars, and the resulted MAD doctrine discouraged them from starting such wars.
On the other hand, if the same nuclear technologies are available to everyone, the chance of an unreasonable or accidental nuclear war will be higher. If even resourceful superpowers can barely keep these nuclear weapons under safe political and technical control (as shown by multiple incidents and near-misses during the Cold War [0]), surely a less resourceful state or military in possession of equally destructive weapons will have even more difficulties on controlling their uses.
At least this is how the argument goes (so far, I personally take no position).
Of course, I clearly realized that centralized control is not infallible. Months ago, in a previous thread on OpenAI's refusal on publishing technical details of GPT-4, most people believed that they were using it as an excuse to maintain a monopolistic control. Instead, I argued that perhaps OpenAI truly values the problem of safety right now - but acting responsibly right now is not an indication that they will still act responsibly in the future. There's no guarantee that the safety considerations will eventually be overridden in favor of financial gains.
> surely it's better to have distributed AGI than to have AGI only in the hands of the elites
This is not a given. If your threat model includes "Runaway competition that leads to profit-seekers ignoring safety in a winner-takes-all contest", then the more companies are allowed to play with AI, the worse. Non-monopolies are especially bad.
If your threat model doesn't include that, then the same conclusions sound abhorrent and can be nearly guaranteed to lead to awful consequences.
Neither side is necessarily wrong, and chances are good that the people behind the first set of rules would agree that it'll lead to awful consequences — just not as bad as the alternative.
No they really do push for "limit everyone's compute". The people pushing for "limit everyone's compute except us" are allies of convenience that are gonna be inevitably backstabbed.
At any rate, if you have like two corps with lots of compute, and something goes wrong, you only have to EMP two datacenters.
The concerning AGI properties include recursive self-improvement to superhuman capability levels and the ability to mass-deploy copies. Those are not on the horizon when it comes to humans.
If hypothetically some human acquired such properties that would be equally concerning.
The government sure thinks they own us, because they claim the right to charge us taxes on our private enterprises, draft us to fight in wars that they start, and put us in jail for walking on the wrong part of the street.
Taxes, conscription and even pedestrian traffic rules make sense at least to some degree. Restricting "AI" because of what some uninformed politician imagines it to be is in a whole different league.
IMO it makes no sense to arrest someone and send them to jail for walking in the street not the sidewalk. Give them a ticket, make them pay a fine, sure, but force them to live in a cage with no access to communications, entertainment, or livelihood? Insane.
Taxes may be necessary, though I can't help but feel that there must be a better way that we have not been smart enough to find yet. Conscription... is a fact of war, where many evil things must be done in the name of survival.
Regardless of our views on the ethical validity or societal value of these laws, I think their very existence shows that the government believes it "owns" us in the sense that it can unilaterally deprive us of life, liberty, and property without our consent. I don't see how this is really different in kind from depriving us of the right to make and own certain kinds of hardware. They regulated crypto products as munitions (at least for export) back in the 90s. Perhaps they will do the same for AI products in the future. "Common sense" computer control.
I feel a bit like everyone is missing the point here. Regardless of whether law A or law B is ethical and reasonable, the very existence of laws and the state monopoly on violence suggests a privileged position of power. I am attempting to engage with the word "own" from the parent post. I believe the government does in fact believe it "owns" the people in a non-trivial way.
In the sense that any other government regulation is also ultimately backed by the state's monopoly on legal use of force when other measures have failed.
And contrary to what some people are implying he also proposes that everyone is subject to the same limitations, big players just like individuals. Because the big players haven't shown much of a sign of doing enough.
> In the sense that any other government regulation is also ultimately backed by the state's monopoly on legal use of force when other measures have failed.
Good point. He was only (“only”) really calling for international cooperation and literal air strikes against big datacenters that weren’t cooperating. This would presumably be more of a no-knock raid, breaching your door with a battering ram and throwing tear gas at the wee hours of the morning ;) or maybe a small extraterritorial drone through your window
... after regulation, court orders and fines have failed. Which under the premise that AGI is an existential threat would be far more reasonable than many other reasons for raids.
If the premise is wrong we won't need it. If society coordinates to not do the dangerous thing we won't need it. The argument is that only in the case where we find ourselves in the situation where other measures have failed such uses of force would be the fallback option.
I'm not seeing the odiousness of the proposal. If bio research gets commodified and easy enough that every kid can build a new airborne virus in their basement we'd need raids on that too.
To be honest, I see summoning the threat of AGI to pose an existential threat to be on the level with lizard people on the moon. Great for sci-fi, bad distraction for policy making and addressing real problems.
The real war, if there is one, is about owning data and collecting data. And surprisingly many people fall for distractions while their LLM fails at basic math. Because it is a language model of course...
Freely flying through the sky on wings was scifi before the wright brothers. Something sounding like scifi is not a sound argument that it won't happen. And unlike lizard people we do have exponential curves to point at.
Something stronger than a vibes-based argument would be good.
I consider the burden of proof to fall on those proclaiming AGI to be an existential threat, and so far I have not seen any convincing arguments. Maybe at some point in the future we will have many anthropomorphic robots and an AGI could hack them all and orchestrate a robot uprising, but at that point the robots would be the actual problem. Similarly, if an AGI could blow up nuclear power plants, so could well-funded human attackers; we need to secure the plants, not the AGI.
It doesn't sound like you gave serious thought to the arguments. The AGI doesn't need to hack robots. It has superhuman persuasion, by definition; it can "hack" (enough of) the humans to achieve its goals.
Voldemort is fictional and so are bumbling wizard apprentices. Toy-level, not-yet-harmful AIs on the other hand are real. And so are efforts to make them more powerful. So the proposition that more powerful AIs will exist in the future is far more likely than an evil super wizard coming into existence.
And I don't think literal 5-word-magic-incantation mind control is essential for an AI to be dangerous. More subtle or elaborate manipulation will be sufficient. Employees already have been duped into financial transactions by faked video calls with what they assumed to be their CEOs[0], and this didn't require superhuman general intelligence, only one single superhuman capability (realtime video manipulation).
> Toy-level, not-yet-harmful AIs on the other hand are real.
A computer that can cause harm is much different than the absurd claims that I am disagreeing with.
The extraordinary claims that are equivalent to saying that the imperious curse exists would be the magic computers that create diamond nanobots and mind control humans.
> that more powerful AIs will exist in the future
Bad argument.
Non safe Boxes exist in real life. People are trying to make more and better boxes.
Therefore it is rational to be worried about Pandora's box being created and ending the world.
That is the equivalent argument to what you just made.
And it is absurd when talking about world ending box technology, even though Yes dangerous boxes exist, just as much as it is absurd to claim that world ending AI could exist.
Instead of gesturing at flawed analogies, let's return to the actual issue at hand. Do you think that agents more intelligent than humans are impossible or at least extremely unlikely to come into existence in the future? Or that such super-human intelligent agents are unlikely to have goals that are dangerous to humans? Or that they would be incapable of pursuing such goals?
Also, it seems obvious that the standard of evidence that "AI could cause extinction" can't be observing an extinction level event, because at that point it would be too late. Considering that preventive measures would take time and safety margin, which level of evidence would be sufficient to motivate serious countermeasures?
Less than a month ago: https://arxiv.org/abs/2403.14380 "We found that participants who debated GPT-4 with access to their personal information had 81.7% (p < 0.01; N=820 unique participants) higher odds of increased agreement with their opponents compared to participants who debated humans."
Yes, and I am sure that when people do a google search for "Good arguments in favor of X", that they are also sometimes convinced to be more in favor of X.
Perhaps they would be even more convinced by the google search than if a person argued with them about it.
That is still much different from "The AI mind controls people, hacks the nukes, and ends the world".
Its that second part that is the the fantasy land situation that requires extraordinary evidence.
But, this is how conversations about doomsday AI always go. People say "Well isn't AI kinda good at this extremely vague thing Y, sometimes? Imagine if AI was infinitely good at Y! That means that by extrapolation, the world ends!".
And that covers basically every single AI doom argument that anyone ever makes.
If the only evidence for AI doom you will accept is actual AI doom, you are asking for evidence that by definition will be too late.
"Show me the AI mindcontrolling people!" AI mindcontrolling people is what we're trying to avoid seeing.
The trick is, in the world in which AI doom is in the future, what would you expect to see now that is different from the world in which AI doom is not in the future?
> If the only evidence for AI doom you will accept is actual AI doom
No actually. This is another mistake that the AI doomers make. They pretend like a demand for evidence means that the world has to end first.
Instead, what would be perfectly good evidence, would be evidence of significant incremental harm that requires regulation on its own, independent of any doom argument.
In between "the world literally ends by magic diamond nanobots and mind controlling AI" and "where we are today" would be many many many situations of incrementally escalating and measurable harm that we would see in real life, decades before the world ending magic happens.
We can just treat this like any other technology, and regulate it when it causes real world harm. Because before the world ends by magic, there would be significant real world harm that is similar to any other problem in the world that we handle perfectly well.
Its funny because you committing the exact mistake that I was criticizing in my original post, where you did the absolutely massive jump and hand waved it away.
> what would you expect to see now that is different from the world in which AI doom is not in the future?
What I would expect is for the people who claim to care about AI doom to actually be trying to measure real world harm.
Ironically, I think the people who are coming up with increasingly thin excuses as for why they don't have to find evidence are increasing the likelyhood of such AI doom much more than anyone else because they are abandoning the most effective method of actually convincing the world of the real world damage that AI could cause.
Well, at least if you see escalating measurable harm you'll come around, I'm happy about that. You won't necessarily get the escalating harm even if AI doom is real though, so you should try to discover if it is real even in worlds where hard takeoff is a thing.
> What I would expect is for the people who claim to care about AI doom to actually be trying to measure real world harm.
Why bother? If escalating harm is a thing, everyone will notice. We don't need to bolster that, because ordinary society has it handled.
> You won't necessarily get the escalating harm even if AI doom is real though
Yes we would. Unless you are one of those people who think that the magic doom nanobots are going to be invented overnight.
My comparisions to someone who is worried about literal magic, from harry potter, is apt.
But at that point, if you are worried about magic showing up instantly, then your position is basically not falsifiable. You can always retreat to some untestable, unfalsifiable magic.
Like there is actually nothing I could say, no evidence I could show to ever convince someone out of that position.
On the other hand, my position is actually fasifiable. There is absolutely all sorts of non world ending evidence that could convince me to think that AI is dangerous.
But nobody on the doomer side seems to care about any of that. Instead they invent positions that seem almost tailor made to avoid being falsifiable or disprovable so that they can continue to believe them despite any evidence to the contrary.
As in, if I were to purposeful invent an idea or philosophy that is impossible to be disproved or convinced out of the "I can't show you evidence because the world will end" position is what I would invent.
> you'll come around,
Do you admit that you won't though? Do you admit that no matter what evidence is shown to you, that you can just retreat and say that the magic could happen at any time?
Or even if this isn't you literally, that someone in your position could dismiss all counter evidence, no matter what, and nobody could convince someone out of that with evidence?
I am not sure how someone could ever possibly engage with you seriously on any of this, if that is your position.
> Like there is actually nothing I could say, no evidence I could show to ever convince someone out of that position.
There is, it is just very hard to obtain. Various formal proofs would do. On upper bounds. On controllability. On scalability of safety techniques.
The manhattan project scientists did check whether they'd ignite the atmosphere before detonating their first prototype. Yes, that was much simpler task. But there's no rule in nature that says proving a system to be safe must be as easy as creating the system. Especially when the concern is that the system adaptive and adversarial.
Recursive self-improvement is a positive feedback loop, like nuclear chain reactions, like virus replication. So if we have an AI that can program then we better make sure that it either cannot sustain such a positive feedback loop or that it remains controllable beyond criticality.
Given the complexity of the task it appears unlikely that a simple ten-page paper proving this will show up on arxiv. But if one did that'd be great.
>> You won't necessarily get the escalating harm even if AI doom is real though
> Yes we would.
So what does guarantee a visible catastrophe that won't be attributed to human operators using a non-agentic AI incorrectly? We keep scaling and the systems will be treated as assistants/optimizers and it's always the operators fault. Until we roughly reach human-level on some relevant metrics. And at that point there's a very narrow complexity range from idiot to genius (human brains don't vary by orders of magnitude!). So as far as hardware goes this could be a very narrow range and we could shoot straight from "non-agentic sub-human AI" to "agentic superintelligence" in short timescales once the hardware has that latent capacity.
And up until that point it will always have been a human error, lax corporate policies, insufficient filtering of the training set or whatever.
And it's not that it must happen this way. Just that there doesn't seem anything ruling it and similar pathways out.
What do you think mind control is? Think President Trump but without the self-defeating flaws, with an ability to stick to plans, and most importantly the ability to pay personal attention to each follower to further increase the level of trust and commitment. Not Harry Potter.
People will do what the AI says because it is able to create personal trust relationships with them and they want to help it. (They may not even realize that they are helping an AI rather than a human who cares about them.)
The normal ways that trust is created, not magical ones.
The magic technology that is equivalent to the imperious curse from Harry Potter.
> The normal ways that trust is created, not magical ones.
Buildings as a technology are normal. They are constantly getting taller and we have better technology to make them taller.
But, even though buildings are a normal technology, I am not going to worry about buildings getting so tall soon that they hit the sun.
This is the same exact mistake that every single AI doomers makes. What they do is they take something normal, and then they infinitely extrapolate it out to an absurd degree, without admitting that this is an extraordinary claim that requires extraordinary evidence.
The central point of disagreement, that always gets glossed over, is that you can't make a vague claim about how AI is good at stuff, and then do your gigantic leap from here to over there which is "the world ends".
Yes that is the same as comparing these worries to those who worry about buildings hitting the sun or the imperious curse.
You say you have not seen any arguments that convince you. Is that just not having seen many arguments or having seen a lot of arguments where each chain contained some fatal flaw? Or something else?
> I see summoning the threat of AGI to pose an existential threat to be on the level with lizard people on the moon.
I mean to every other lifeform on the plant YOU are the AGI existential threat. You, and I mean homosapiens by that, have taken over the planet and have either enslaved and are breeding any other animals for food, or are driving them to extinction. In this light bringing another potential apex predator on to the scene seems rash.
>fall for distractions while their LLM fails at basic math
Correct, if we already had AGI/ASI this discussion would be moot because we'd already be in a world of trouble. The entire point is to slow stuff down before we have a major "oopsie whoopsie we can't take that back" issue with advanced AI, and the best time to set the rules is now.
>If the premise is wrong we won't need it. If society coordinates to not do the dangerous thing we won't need it.
But the idea that this use of force is okay itself increases danger. It creates the situation that actors in the field might realize that at some point they're in danger of this and decide to do a first strike to protect themselves.
I think this is why anti-nuclear policy is not "we will airstrike you if you build nukes" but rather "we will infiltrate your network and try to stop you like that".
> anti-nuclear policy is not "we will airstrike you if you build nukes"
Was that not the official policy during the Bush administration regarding weapons of mass destruction (which covers nuclear weapons in addition to chemical and biological weapons). That was pretty much the official premise of the second Gulf war
> ... after regulation, court orders and fines have failed
One question for you. In this hypothetical where AGI is truly considered such a grave threat, do you believe the reaction to this threat will be similar to, or substantially gentler than, the reaction to threats we face today like “terrorism” and “drugs”? And, if similar: do you believe suspected drug labs get a court order before the state resorts to a police raid?
> I'm not seeing the odiousness of the proposal.
Well, as regards EliY and airstrikes, I’m more projecting my internal attitude that it is utterly unserious, rather than seriously engaging with whether or not it is odious. But in earnest: if you are proposing a policy that involves air strikes on data centers, you should understand what countries have data centers, and you should understand that this policy risks escalation into a much broader conflict. And if you’re proposing a policy in which conflict between nuclear superpowers is a very plausible outcome — potentially incurring the loss of billions of lives and degradation of the earth’s environment — you really should be able to reason about why people might reasonably think that your proposal is deranged, even if you happen to think it justified by an even greater threat. Failure to understand these concerns will not aid you in overcoming deep skepticism.
> In this hypothetical where AGI is truly considered such a grave threat, do you believe the reaction to this threat will be similar to, or substantially gentler than, the reaction to threats we face today like “terrorism” and “drugs”?
"truly considered" does bear a lot of weight here. If policy-makers adopt the viewpoint wholesale, then yes, it follows that policy should also treat this more seriously than "mere" drug trade.
Whether that'll actually happen or the response will be inadequate compared to the threat (such as might be said about CO2 emissions) is a subtly different question.
> And, if similar: do you believe suspected drug labs get a court order before the state resorts to a police raid?
Without checking I do assume there'll have been mild cases where for example someone growing cannabis was reported and they got a court summons in the mail or two policemen actually knocking on the door and showing a warrant and giving the person time to call a lawyer rather than an armed, no-knock police raid, yes.
> And if you’re proposing a policy in which conflict between nuclear superpowers is a very plausible outcome — potentially incurring the loss of billions of lives and degradation of the earth’s environment — you really should be able to reason about why people might reasonably think that your proposal is deranged [...]
Said powers already engage in negotiations to limit the existential threats they themselves cause. They have some interest in their continued existence. If we get into a situation where there is another arms race between superpowers and is treated as a conflict rather than something that can be solved by cooperating on disarmament, then yes, obviously international policy will have failed too.
If you start from the position that any serious, globally coordinated regulation - where a few outliers will be brought to heel with sanctions and force - is ultimately doomed then you will of course conclude that anyone proposing regulation is deranged.
But that sounds like hoping that all problems forever can always be solved by locally implemented, partially-enforced, unilateral policies that aren't seen as threats by other players? That defense scales as well or better than offense? Technologies are force-multipliers, as it improves so does the harm that small groups can inflict at scale. If it's not AGI it might be bio-tech or asteroid mining. So eventually we will run into a problem of this type and we need to seriously discuss it without just going by gut reactions.
Just my (probably unpopular) opinion: True AI (what they are now calling AGI) may never exist. Even the AI models of today aren't far removed from the 'chatbots' of yesterday (more like an evolution rather than revolution)...
...for true AI to exist, it would need to be self aware. I don't see that happening in our lifetimes when we don't even know how our own brains work. (There is sooo much we don't know about the human brain.)
AI models today differ only in terms of technology compared to the 'chatbots' of yesterday. None are self aware, and none 'want' to learn because they have no 'wants' or 'needs' outside of their fixed programming. They are little more than glorified auto complete engines.
Don't get me wrong, I'm not insulting the tech. It will have it's place just like any other, but when this bubble pops it's going to ruin lives, and lots of them.
Shoot, maybe I'm wrong and AGI is around the corner, but I will continue to be pessimistic. I am old enough to have gone through numerous bubbles, and they never panned out the way people thought. They also nearly always end in some type of recession.
Bacteria doesn't "want" anything in the sense of active thinking like you do, and yet will render you dead quickly and efficiently while spreading at a near exponential rate. No self awareness necessary.
You keep drawing little circles based on your understanding of the world and going "it's inside this circle, therefore I don't need to worry about it", while ignoring 'semi-smart' optimization systems that can lead to dangerous outcomes.
>I am old enough to have gone through numerous bubbles,
And evidently not old enough to pay attention to the things that did pan out. But hey, those cellphone and that internet thing was just a fad right. We'll go back to land lines at any time now.
> I'm not seeing the odiousness of the proposal. If bio research gets commodified and easy enough that every kid can build a new airborne virus in their basement we'd need raids on that too.
Either you create even better bio research to neutralize said viruses... or you die trying...
Like if you go with the raid strategy and fail to raid just one terrorist that's it, game over.
Those arguments do not transfer well to the AGI topic. You can't create counter-AGI, since that's also an intelligent agent which would be just as dangerous. And chips are more bottlenecked than biologics (... though gene synthesizing machines could be a similar bottleneck and raiding vendors which illegally sell those might be viable in such a scenario).
Are. As I and others have predicted, the executive order was passed defining a hard limit on the processing/compute power allowed without first 'checkin in' with the Letter boys.
You need to abandon your apocalyptic worldview keep up with the times my friend.
Encryption export controls have been systematically dismantled to the point that they're practically non-existent, especially over the last three years.
Pretty much the only encryption products you need permission to export are those specifically designed for integration into military communications networks, like Digital Subscriber Voice Terminals or Secure Terminal Equipment phones, everything else you file a form.
Many things have changed since the days when Windows 2000 shipped with a floppy disk containing strong encryption for use in certain markets.
Are you on drugs or is your reading comprehension that poor?
1) I did not state a world view; I simply noted that restrictions for software do exist, and will for AI, as well. As the link from the other commenter show, they do in fact already exist.
2) Look up the definition of "apocalyptic", software restrictions are not within its bounds.
3) How the restrictions are enforced were not a subject in my comment.
4) We're not pals, so you can drop the "friend", just stick to the subject at hand.
I mean yeah they (and I) think if you have too much access to general computation you can destroy the world.
This isn't a "defection", because this was never something they cared about preserving at the risk of humanity. They were never in whatever alliance you're imagining.
Can someone ELI5 what this may make possible that wasn't possible before? Does this mean I can buy a handful of 4090s and use it in lieu of an h100? Just adding the memory together?
No. The Nvidia A100 has a multi-lane NVLink interface with a total bandwidth of 600 GB/s. The "unlocked" Nvidia RTX 4090 uses PCIe P2P at 50 GB/s. It's not going to replace A100 GPUs for serious production work, but it does unlock a datacenter-exclusive feature and has some small-scale applications.
Would this approach be possible to extend downmarket, to older consumer cards? For a lot of LLM use cases we're constrained by memory and can tolerate lower compute speeds so long as there's no swapping. ELI5, what would prevent a hundred 1060-level cards from being used together?
> ELI5, what would prevent a hundred 1060-level cards from being used together?
In this case, you'd only have a single PCIe (v3!) lane per card, making the interconnect speed horribly slow. You'd also need to invest in thousands of dollars of hardware to get all of those cards connected and, unless power is free, you'd outspend any theoretical savings instantly.
In general, if you go back in card generations, you'll quickly hit so low memory limits amd slower compute that a modern CPU-based setup is better value.
And here I thought (PCIe) P2P was there since SLI dropped the bridge (for the unfamiliar, it looks and acts pretty much like an NVLink bridge for regular PCIe slot cards that have NVLink, and was used back in the day to share framebuffer and similar in high-end gaming setups).
Beeper mini only worked with iMessage for a few days before Apple killed it. A few months later the DOJ sued Apple. Hacks like this show us the world we could be living in, a world which can be hard to envision otherwise. If we want to actually live in that world, we have to fight for it (and protect the hackers besides).
so basically rtx 4090 x6 = 144 GB ram which would cost $15996 = $9594 ( only the nvidia 4090s) and currently the tiny box gives
*TinyBox*
> GPU RAM | 144 GB
> Price | $15,000 $25,000
Nvidia 4090x6
> GPU RAM | 144 GB
> Price | $9594
so a * 36.04%* decrease in price from team red tinybox ( $15k) and *61.624% *decrease in price from the team green tinybox ( $25k)
It does seem like an oversight, but there's nothing "suboptimal non-default options" about iteven if the implementation posted here seems somewhat hastily hacked together.
> but there's nothing "suboptimal non-default options" about it
If "bypassing the official driver to invoke the underlying hardware feature directly through source code modification (and incompatibilities must be carefully worked around by turning off IOMMU and large BAR, since the feature was never officially supported)" does not count as "suboptimal non-default options", then I don't know what counts as "suboptimal non-default options".
The driver is not bypasses. This is a patch to the official open-source kernel-driver where the feature is added, which is how all upstream Linux driver development is done.
> to invoke the underlying hardware feature directly
Accessing hardware features directly is pretty much the sole job of a driver, and the only thing "bypassed" is some abstractions internal to the driver. Just means the patch would fail review in basis of codestyle, and on the basis of possibly only supporting one device family.
> through source code modification
That is a weird way to describe software engineering. Making the code available for further development is kind of the whole point of open source.
> turning off IOMMU
This is not a P2PDMA problem, and just a result of them not also adding the necessary IOMMU boilerplate, which would be added if the patch was done properly to be upstreamed.
> large BAR
This is an expected and "optimal" system requirement.
> The driver is not bypasses. This is a patch to the official open-source kernel-driver where the feature is added, which is how all upstream Linux driver development is done. [source code modification] is a weird way to describe software engineering. Making the code available for further development is kind of the whole point of open source.
My previous comment was written with an unspoken assumption: Hardware drivers tend to be very different from other forms of software. For ordinary free-and-open-source software, the source code availability largely guarantees community control. However, the same often does not apply to drivers. Even with source code availability, they're often written by vendors using NDAed information and in-house expertise about the underlying hardware design. As a result, drivers remain under a vendor's tight control. Even with access to 100% source code, it's often still difficult to do meaningful development due to missing documentation to explain "why" instead of "what", the driver can be full of magic numbers and unexplained functionalities, without any description other than a few helpers functions and macros. This is not just a hypothetical scenario, this situation is encountered by OpenBSD developers on a daily basis. In a OpenBSD presentation, the speaker said the study of Linux code is a form of "reverse-engineering from source code".
Geohot didn't find the workaround by reading hardware documentation, instead, it was found by making educated guesses based on the existing source code, and by watching what happens when you send the commands to hardware to invoke a feature unexposed by the HAL. Thus, it was found by reverse-engineering (in a wider sense). And I call it a driver bypass, in the sense that it bypasses the original design decisions made by Nvidia's developers.
> [turning off IOMMU] is not a P2PDMA problem, and just a result of them not also adding the necessary IOMMU boilerplate, which would be added if the patch was done properly to be upstreamed.
Good point, I stand corrected.
I'll consider stop calling geohot's hack "a bypass" and accepting your characterization of "driver development" if it really gets upstreamed to Linux - which usually requires maintainer review, and Nvidia's maintainer is likely to reject the patch.
> [large BAR] is an expected and "optimal" system requirement.
I meant "turning off (IOMMU && large BAR)". Disabling large BAR in order to use PCIe P2P is a suboptimal configuration.
> For ordinary free-and-open-source software, the source code availability largely guarantees community control. However, the same often does not apply to drivers. Even with source code availability, they're often written by vendors using NDAed information and in-house expertise about the underlying hardware design. As a result, drivers remain under a vendor's tight control.
This is not true for any upstream Linux kernel driver. They are fully open source, fully controlled by the community and not subject to any NDAs to work on. The vendor can only exert control in the form of reviews and open maintainership. This is the case for both AMD and Intel GPU drivers.
For numbers, Arch Linux bundles some ~7.5k loadable kernel drivers (which is a subset of all available, but AUR only has 8 out-of-tree drivers, out of which two are proprietary and 2-3 are community-led. "vendor-controlled" drivers are an extreme outlier on Linux.
While not true for nvidia's proprietary, closed-source driver stack, the linked open source nvidia (kernel) driver is nvidia's work-in-progress driver to be upstreamed in exactly this fashion.
> by watching what happens when you send the commands to hardware to invoke a feature unexposed by the HAL. Thus, it was found by reverse-engineering
It is true that documentation was lacking, but there was no reverse-engineering here, just standard (albeit, hacked up) driver development. "The HAL" means nothing, as it's just an random abstraction within the driver.
I used to work on proprietary network drivers for high-performance, FPGA-based NICs, and apart from it being more annoying to debug it's really no different than coding on anything else. Unless you're bringing up new IP blocks, it's mostly you and the code, not specs.
It would have been reverse-engineering if the registers and blocks weren't in the driver in the first place, but in this case all the parts were there to bring up a completely standard feature. What he did was use existing driver code to ask for what he wanted.
Not saying that it wasn't significant effort, but unless you consider "reading code you did not write" reverse-engineering (in which case all coding is reverse-engineering), then it has nothing to do with reverse-engineering, or bypassing anything. Considering this reverse-engineering is also a bit of a disservice to those that actually reverse-engineered GPUs and wrote open-source GPU drivers for them, like panfrost and recently the Apple silicon drivers.
Apart from the fact that the feature is hacked and not properly wired up (as evident by the IOMMU issue and abstraction break), the implementation flow is done exactly the same as when volunteers contribute fixes or features to other, complex open-source upstream GPU drivers, like AMDGPU. Not by reverse-engineering, nor by signing NDAs, but by reading and writing code and debugging your hardware. Stuff is just always harder in kernel mode.
> I meant "turning off (IOMMU && large BAR)". Disabling large BAR in order to use PCIe P2P is a suboptimal configuration.
The requirement is large BAR on, not off - the phrasing is a bit poor on the page, but they're trying to say that you need large bar support, and that you need IOMMU off, not that you need large bar and IOMMU off.
> This is not true for any upstream Linux kernel driver.
This is very true for at least a portion of upstream Linux kernel drivers.
> They are fully open source
True.
> fully controlled by the community
False (Of course, this claim is based on my belief that source code access is insufficient to do driver development, hardware datasheets are not just nice to have but mandatory for a true free operating system. If you disagree, nothing more can be said).
The upstream Linux kernel has absolutely no requirement that the contributed hardware drivers must include public documentation. In fact, many are written by vendor-hired contractors, or by independent embedded system companies who make computer gadgets based on these chips (so they have a business relationship with the vendor that give them datasheet access).
If you want to do any low-level work on these kinds of drivers independently, it almost always involves trial-and-error and educated guesses.
> and not subject to any NDAs to work on. The vendor can only exert control in the form of reviews and open maintainership. This is the case for both AMD and Intel GPU drivers.
Sure, the drivers themselves are not subject to any NDAs to work on, but hardware vendors often maintain a de-facto control - because they are in possession of technical advantages not available to outsiders, in terms of NDAed information and in-house expertise. Although theoretically everyone is free to participate, and it often happens, but when 80% of the experts are programmers with privileged information, it's difficult although not impossible for an outsider to join the development effort (it's no surprise that most outsider contributions are high-level changes that do not directly affect hardware operations, like moving away from a deprecated kernel API, fixing memory leaks, rather than, say, changing the PLL divider of the hardware's reference clock).
> For numbers, Arch Linux bundles some ~7.5k loadable kernel drivers (which is a subset of all available, but AUR only has 8 out-of-tree drivers, out of which two are proprietary and 2-3 are community-led. "vendor-controlled" drivers are an extreme outlier on Linux.
As a contributor to the Linux kernel, my personal experience is, drivers that contains code similar to the following are not rare:
I bet at least 10% of device drivers (or as high as 25%?) are written with privileged information and they're almost impossible for independent developers to work with (other than making educated guesses) due to incomplete or NDAed documentation. Datasheet access is the only way to interpret the intentions of this kind of drivers. Even with macro or bitfields definitions - which is better than none, the exact effect of a register is often subtle. Not to mention that hardware bugs are common and their workarounds often involve very particular register-write sequences - and that tend not to be publicly documented. Sometimes, even firmware binary blobs are embedded into the source code this way, and the code is almost always contributed by a vendor who actually knows what the blob is doing. If I was asked to do some development on top of an existing driver but without hardware documentation, I would refuse it every single time.
I stand corrected. If it's already suboptimal in practice to begin with, the hack does not more it more suboptimal... Still, disabling large BAR size is still sub-optimal...
It depends on what you do with it and how much bandwidth it needs between the cards. For LLM inference with tensor parallelism (usually limited by VRAM read bandwidth, but little exchange needed) 2x 4090 will massively outperform a single A6000. For training, not so much.
> GPUDirect Peer to Peer
> Enables GPU-to-GPU copies as well as loads and stores directly over the memory fabric (PCIe, NVLink). GPUDirect Peer to Peer is supported natively by the CUDA Driver. Developers should use the latest CUDA Toolkit and drivers on a system with two or more compatible devices.
{kind=link}
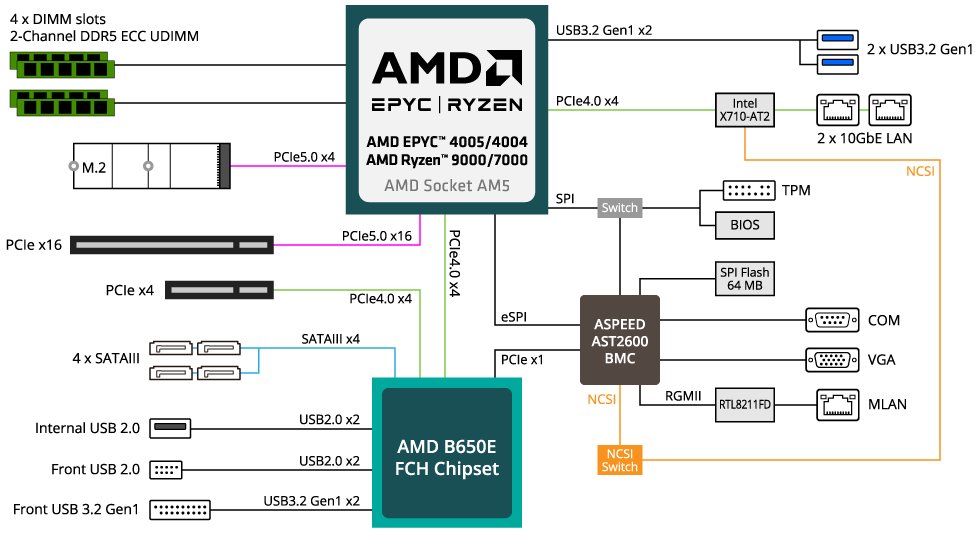{kind=link}
{kind=link}
{kind=link}
I still don't understand why they went with 6 GPUs for the tinybox. Many things will only function well with 4 or 8 GPUs. It seems like the worst of both worlds now (use 4 GPUs but pay for 6 GPUs, don't have 8 GPUs).