> how many of the supported options boil down to Amazon S3?
That's a really good question. Diego's experiment used:
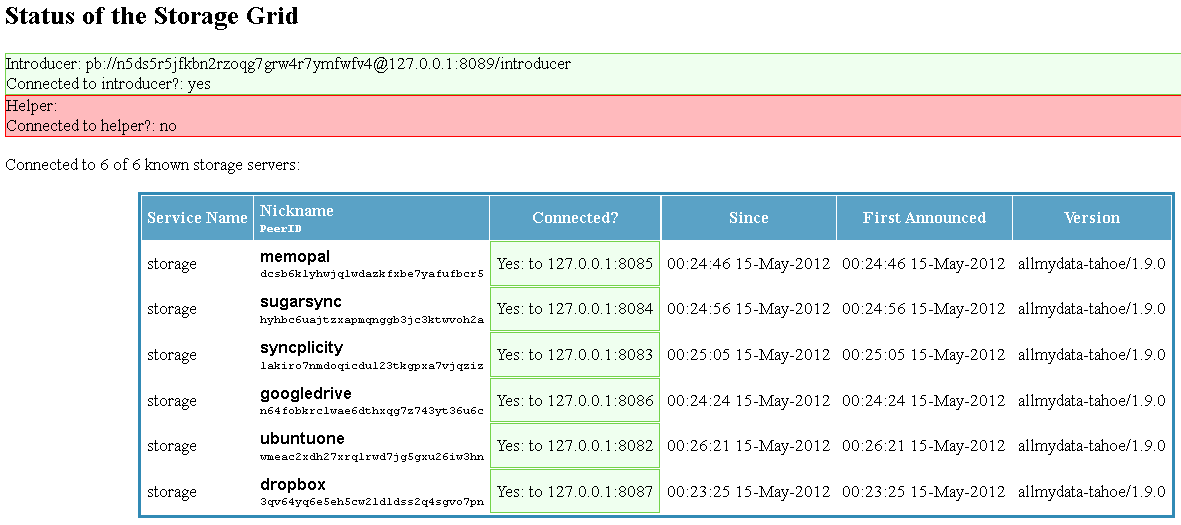
• memopal: I don't know if it uses S3
• SugarSync: I don't know if it uses S3
• syncplicity: I don't know if it uses S3
• googledrive: not using S3
• UbuntuOne: yes, it uses S3
• DropBox: yes, it uses S3
By the way, my startup, Least Authority Enterprises is working on a future product which also goes by the codename "Redundant Array of Independent Clouds". Our project is no relation to Diego Righi's experiment, except perhaps we inspired him by talking about it.
We've received a research grant from DARPA to implement it. The backends we're developing for are all guaranteed to be separate backends from each other -- none of them turn out to be front-ends for another one!
Amen!! Patrick "marlowe" McDonald has really given us a gift by publishing the Tahoe-LAFS Weekly News every week. We're coming up on the Tahoe-LAFS Weekly News one-year anniversary next week. ☺
One of the authors of RACS here. Indeed, the architecture of RACS is quite similar to Tahoe-LAFS, with a proxy server that sends shares of data to different cloud providers. With RACS, we focused on fault tolerance rather than malicious modification of data: Cloud providers have their own internal redundancy, so they (hopefully) protect their users from low-level hardware failures... but a company itself can fail, or even raise prices suddenly which can lead to an "economic failure", where the user's application becomes prohibitively expensive to run. So RACS is intended to protect against things like this. It can tolerate malicious modification of data shares on individual cloud providers, but that kind of security wasn't our focus, so it's interesting to see that Tahoe-LAFS takes that direction.
Hi -- I'm one of the authors of Tahoe-LAFS. I haven't read your RACS paper before, but it looks pretty good. I appreciate the emphasis on real-world economics and on the costs of vendor lock-in. I haven't yet completely digested your results numbers to see how they inform my business, but I definitely will.
It's too bad that you weren't aware of, or didn't cite, Tahoe-LAFS when you wrote that paper! Even though you used my zfec library, which I created (by copying Luigi Rizzo's feclib) for Tahoe-LAFS's use. Heh heh heh.
I tried to get Tahoe-LAFS's existence registered in the official academic research world by publishing this: http://scholar.google.com/scholar?cites=7212771373747133487&... but it didn't really work. Most of the subsequent research that probably should have cited Tahoe-LAFS still didn't.
Perhaps that 5-page paper was too telegraphic to communicate a lot of the important properties. For example, it does not spell out the fact that Tahoe-LAFS includes a kind of proof-of-storage/proof-of-retrievability protocol. Also, perhaps, I chose too obscure of a venue to publish it in. I'm not sure.
For your reading pleasure here is a big rant by me on my blog, whining that Tahoe-LAFS is deserving of more attention than HAIL (which you do cite):
"It is frustrating to me that the authors of HAIL are apparently unaware of Tahoe-LAFS, which elegantly solves most of the problems that they set out to solve, which is open source, and which was deployed to the public, storing millions of files, and summarized in a peer-reviewed workshop paper before the HAIL paper was published."
You know, I have to admit that the main reason academic researchers don't appreciate the sophisticated proof-of-work/proof-of-retrievability features in Tahoe-LAFS is that I didn't write it up. The 5-page paper that I linked to -- http://scholar.google.com/scholar?cites=7212771373747133487&... -- doesn't explicitly mention that it has proof-of-work/proof-of-retrievability properties at all, much less do the sort of thorough, precise specification and proof that, for example, the HAIL paper has.
Unfortunately our literature review didn't turn up Tahoe-LAFS when we wrote RACS, possibly because of differing terminology. It would have made a great addition to our related work section. I think the two systems are sufficiently different in design and aims, despite some similarities architecture.
Even before "cloud" or online storage was too hot or even showed up yet, I was thinking of doing this.
Time was Google providing "unlimited" gmail storage and fuse gmail-fs was just released. I looked for another fuse fs like a hotmail-fs but did not push hard on it. I could not find and let my idea die.
It was hard to do and time consuming, but marginal gain would be small. Also I'm a f lazy system administrator. I hate coding :)
I;m sure many of thought of this, nice to see someone do it.
My idea for backup would use something like DIBS ( http://www.mit.edu/~emin/source_code/dibs/) but instead of peers, use many free salami slice sizes of storage from cloud/hosting platforms.
Memopal does not use Amazon S3. Memopal is based on the
Memopal Global File System (MGFS), the archiving technology created and used by Memopal. MGFS is a distributed file system, designed to be highly reliable, scalable and at the lowest cost per Gb possible. read more http://www.memopal.com/en/technology.htm
my understanding is that tahoe-lafs is meant to be used as a live filesystem. how does the redundancy configuration affect latency? i would guess a cloned volume ("RAID 1") would be faster than a distributed volume (e.g. "RAID 5" or "RAID 6").
Tahoe-LAFS performance leaves a lot to be desired, for various reasons, but the erasure-coding levels (i.e. the degree of distribution of each file via "RAID"-like math) aren't necessarily the most important component. Brian Warner did some thorough benchmarks using dedicated servers on a LAN, and specifically look at how increasing the number of shares ("K") affected throughput:
The different colors of the samples there are for three different settings of how many shares the file was erasure-coded (RAIDed) into: 3, 30, or 60 shares. This type of file ("MDMF" type) seems to go about as fast at any of those three levels of distribution, but this older and more common type -- https://tahoe-lafs.org/trac/tahoe-lafs/attachment/wiki/Perfo... -- ("CHK" type, which is for immutable files) performs much worse for larger levels of distribution. There's probably just some dumb bug which causes this slowdown. This page has some ideas as to what's causing it: https://tahoe-lafs.org/trac/tahoe-lafs/wiki/Performance/Sep2...
the idea of using multiple independent free providers as a unified one it's something that could be very popular among some of my friends, if someone could slap a nice UI on it I believe there would be a good market for it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}