Hey there! This is Dan and Ustin (@uzarubin), and we want to share something cool we've been working on for the past year - an open-source
`tail -f` for your data, with a UI. We call it
"Streamdal" which is a word salad for streaming systems (because we love them) and DAL or data access layer (because we’re nerds).
Here's the repo: https://github.com/streamdal/streamdal
Here's the site: https://streamdal.com
And here's a live demo: https://demo.streamdal.com (github repo has an explanation of the demo)
— — —
THE PROBLEM
We built this because the current observability tooling is not able to provide real-time insight into the actual data that your software is reading or writing. Meaning that it takes longer to identify issues and longer to resolve them. That’s time, money, and customer satisfaction at stake.
Want to build something in-house? Prepare to deploy a team, spend months of development time, and tons of money bringing it to production. Then be ready to have engineers around to babysit your new monitoring tool instead of working on your product.
— — —
THE BASIC FLOW
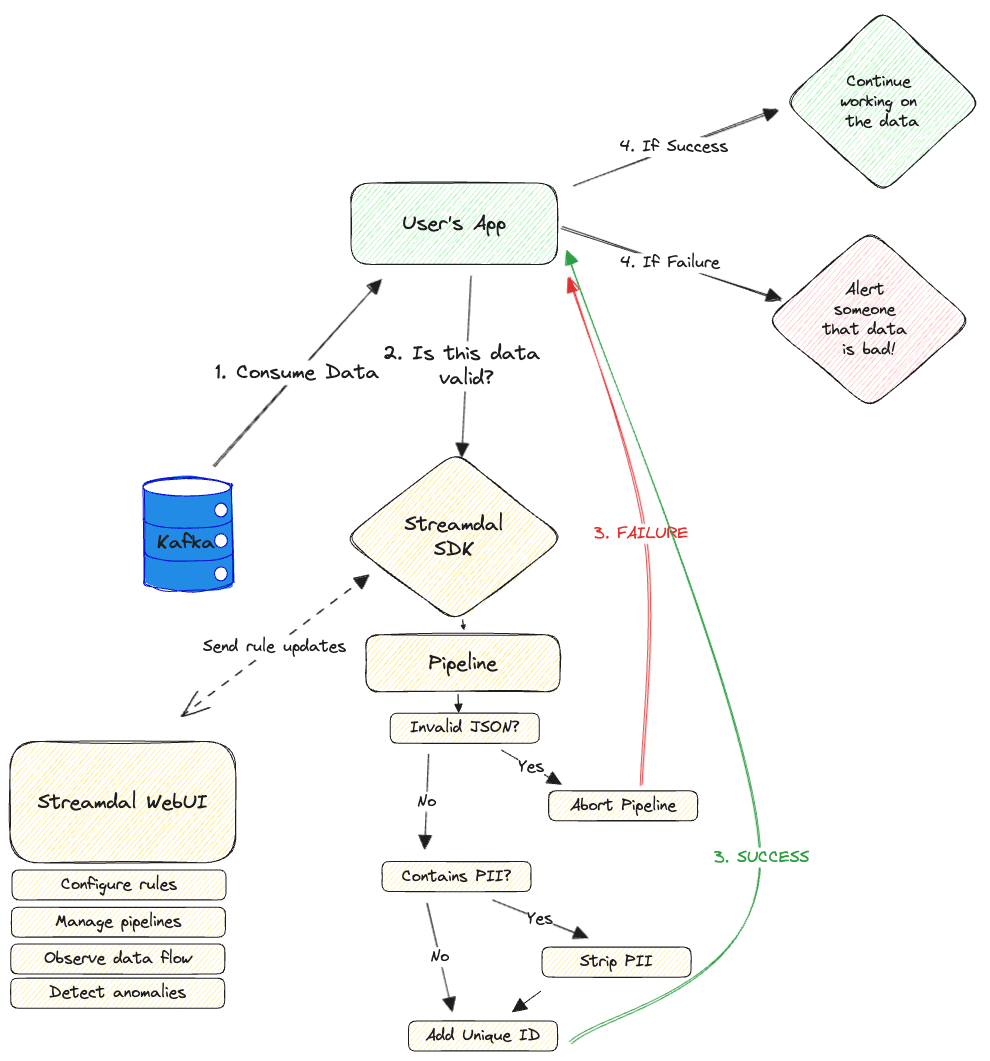
So, wtf is a “tail -f for your data”. What we mean is this:
1. We give you an SDK for your language, a server, and a UI.
2. You instrument your code with `StreamdalSDK.Process(yourData)` anytime you read or write data in your app.
3. You deploy your app/service.
4. Go to the provided UI (or run the CLI app) and be able to peek into what your app is reading or writing, like with `tail -f`.
And that's basically it. There's a bunch more functionality in the project but we find this to be the most immediately useful part. Every developer we've shown this to has said "I wish I had this at my gig at $company" - and we feel exactly the same. We are devs and this is what we’ve always wanted, hundreds of times - a way to just quickly look at the data our software is producing in real-time, without having to jump through any hoops.
If you want to learn more about the "why" and the origin of this project - you can read about it here: https://streamdal.com/manifesto
— — —
HOW DOES IT WORK?
The SDK establishes a long-running session with the server (using gRPC) and "listens" for commands that are forwarded to it all the way from the UI -> server -> SDK.
The commands are things like: "show me the data that you are currently consuming", "apply these rules to all data that you produce", "inspect the schema for all data", and so on.
The SDK interprets the command and either executes Wasm-based rules against the data it's processing or if it's a `tail` request - it'll send the data to the server, which will forward it to the UI for display.
The SDK IS part of the critical path but it does not have a dependency on the server. If the server is gone, you won't be able to use the UI or send commands to the SDKs, but that's about it - the SDKs will continue to work and attempt to reconnect to the server behind the scenes.
— — —
TECHNICAL BITS
The project consists of a lot of "buzzwordy" tech: we use gRPC, grpc-Web, protobuf, redis, Wasm, Deno, ReactFlow, and probably a few other things.
The server is written in Go, all of the Wasm is Rust and the UI is Typescript. There are SDKs for Go, Python, and Node. We chose these languages for the SDKs because we've been working in them daily for the past 10+ years.
The reasons for the tech choices are explained in detail here: https://docs.streamdal.com/en/resources-support/open-source/
— — —
LAST PART
OK, that's it. What do you think? Is it useful? Can we answer anything?
- If you like what you're seeing, give our repo a star: https://github.com/streamdal/streamdal
- And If you really like what you're seeing, come talk to us on our discord: https://discord.gg/streamdal
Talk soon!
- Daniel & Ustin
{kind=link}
I've noticed you've provided Go, Python, and Node SDKs. What's the general tech stack for these? I assume your usage of Protobufs is for a consistent schemas between languages?
I ask because I'm curious as to how much work it is to define new SDKs for other languages, as I'd love a Java implementation - Ideally the SDK should be a pretty thin wrapper, simply calling the gRPC service with some minimal error handling, is this the case?