I wish Apple and Oracle would have just sorted things out and made ZFS the main filesystem for the Mac. Way back in the day when they first designed Time Machine, it was supposed to just be a GUI for ZFS snapshots.
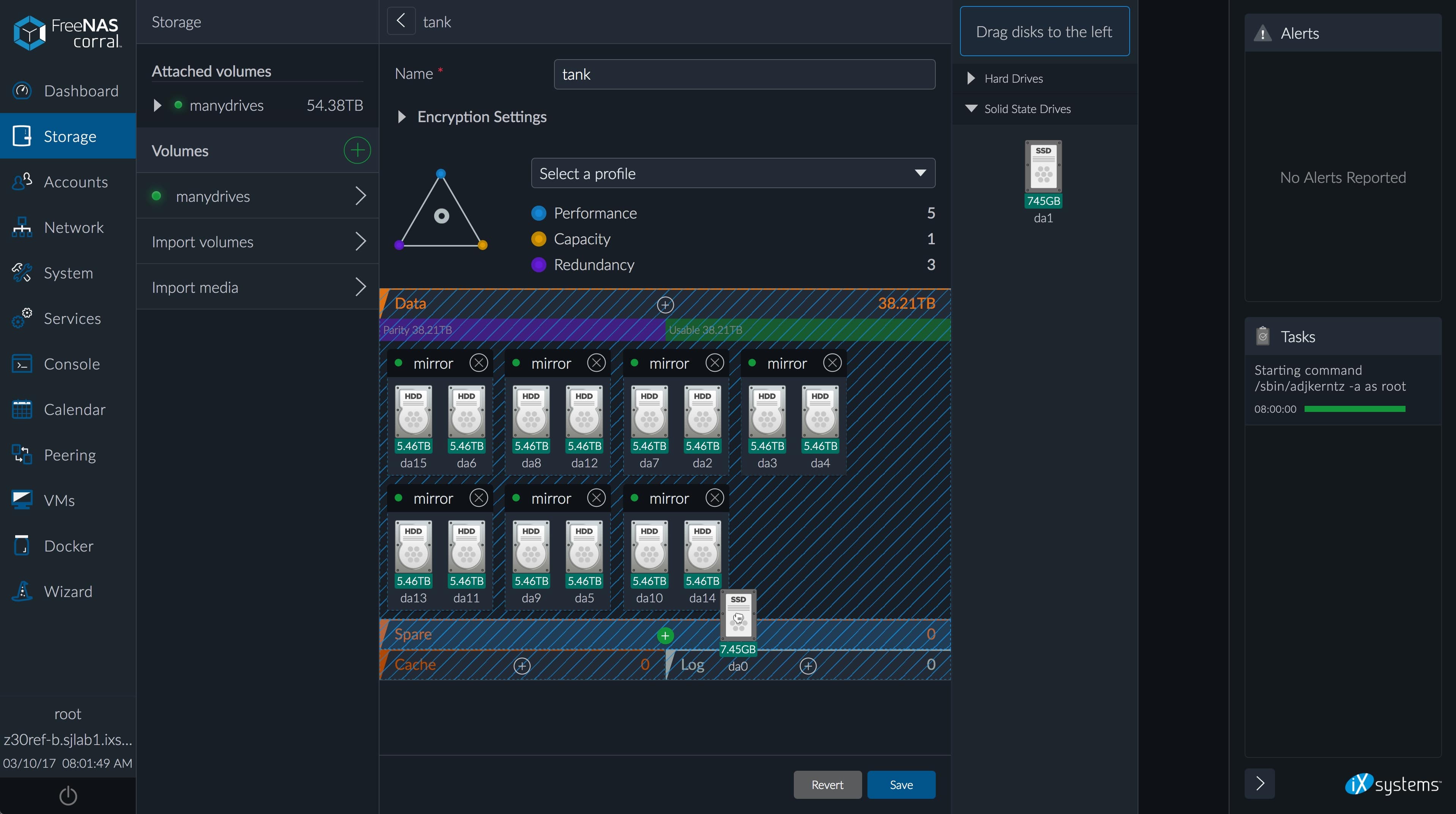
How cool would it be if we had a great GUI for ZFS (snapshots, volume management, etc.). I could buy a new external disk, add it to a pool, have seamless storage expansion.
httm has been at 9XX GitHub stars for what seemed like forever! Time to get over that 1k hump.
As a Rust project, it's something of a duty to hype and self-promote, and to troll C++, of course. So let it be known: If you're not using httm, you're not using modern ZFS. Or -- httm is the cppfront of ZFS utilities? Or -- httm is the 'auto' keyword for filesystems, but less confusing (to me)?
Yes, this will always depress me, and to me personally be one of the ultimate evils of the court invented idea of "software patents". I've used ZFS with Macs sicne 2011, but without Apple onboard it's never been as smooth as it should have been and has gotten more difficult in some respects. There was a small window where we might have had a really universal, really solid FS with great data guarantees and features. All sorts of things with OS could be so much better, trivial (and even automated) update rollbacks for example. Sigh :(. I hope zvols finally someday get some performance attention so that if nothing else running APFS (or any other OS of course) on top of one is a better experience.
> How cool would it be if we had a great GUI for ZFS (snapshots, volume management, etc.). I could buy a new external disk, add it to a pool, have seamless storage expansion.
Something like TVS-h474 seems quite nice for a wide range of uses.
I have TVS-h1288X and I am really happy with it, maybe it's a bit overkill for most.
That said, I could not use zfs send from my prev fbsd server, there are some compat checks in QNAP's version. Used nfs to migrate from my decade++ old pool.
Using Tailscale for access, they have QNAP builds on GH.
QNAP forked from OpenZFS a long time ago, before the ZoL project was renamed the canonical OpenZFS project IIRC, and has been reimplementing whatever they wanted for some time.
So it's not just a check for check's sake, I would suspect in practice their send/recv is just completely incompatible at this point.
Yeah I wonder if it was really caused by Jonathan Schwartz bragging to the media about it and pissing Steve Jobs off, as was rumoured at the time. Or if there was more behind it.
I would certainly not put it past Jobs. While he had some genius qualities, his personality was pretty deeply flawed. But on the other hand I wonder if his sense for business would not have prevailed.
If only Apple had absorbed sun instead of oracle, their legacy would have been better off. Of course it couldn't have been worse.
Which also made me wonder, of course Jobs and Ellison were big friends so perhaps Jobs just left it for him to take? Oracle always wanted to get their hands on java obviously.
Ps the whole ZFS on Mac adventure came a little after time machine was already in production.
ZFS is indeed an amazing desktop filesystem. I'm using it now on FreeBSD, I moved away from Mac because it became ever more closed down. I wanted more control, not less.
Apple buying Sun would have been a disaster. Oracle at least needed some (arguably most) of what Sun made - Apple did not and do not.
Apple would have killed Java in half a second. They don't need it, it was built to do the opposite of what they want their tech to do. Same for Solaris, burdensome duplicate. As for all the desktop-oriented FOSS projects (OpenOffice, VirtualBox etc), they would not have just been killed - Apple would have viciously bullied anyone to preclude them from forking them. The stuff they'd keep (MySql, probably), they would have made osx-only, and then strangled them quietly after they got out of the server game. They would have ripped anything technologically interesting from the hardware divisions and then shut them down - because they were no match, in terms of supply efficiency and value, for the Apple equivalents; and anyway they were never seriously interested in the server space.
Oracle did what Oracle does, and realistically the culture clash was never going to result in a smooth transition; but from a commercial perspective they kept around the best of what Sun was making (Java, servers) and largely let the community get on with the stuff they weren't interested in (if rebranded/forked). The only real crime they committed, IMHO, was trying too hard to make money from VirtualBox, effectively spooking the market; there is a different timeline where VBox ends up being what Docker became. But everything else was par for the course.
Not sure why you limit that to desktop. It's more important that server files can have an instant snapshot, compression and performant incremental backup to remote servers.
> How cool would it be if we had a great GUI for ZFS
Not in workstation OS, maybe not "great" but tools like FreeNAS had ZFS GUI sorted out[1] pretty decently and user-friendly for some time. I've seen storage laymen set these up, learn on the go and not screw up.
TrueNAS? You can manage the volumes with a web UI. It has a thing you can enable for SMB shares that let you see the previous versions of files on Windows. Or perhaps I don't understand what you're after.
yeah imagine a world where you could use time machine to backup 500gb parallels volumes where only the diff was stored between snapshots rather than needing to back up the whole 500gb volume every single time.
As a workaround, you can create a sparsevolume to store your parallels volume. Sparsevolumes are stores in bands, and only bands that change get backed up. It might be slightly more efficient.
Correct. I lied when I said you can't add single disks, I meant you shouldn't add single disks. It's not like e.g. Synology where you can add a single disk and it will expand your underlying RAID5/6 arrays
>How cool would it be if we had a great GUI for ZFS (snapshots, volume management, etc.)
I believe that was something built into the file manager in OpenSolaris, and then into illumos OS's. OpenIndiana has it in their file manager within their themed MATE desktop environment.
The big news here seems to be that iXsystems (the company behind FreeNAS/TrueNAS) is sponsoring this work now. This PR supersedes ones that was opened back in 2021
What worries me the most is them doubling down on it after it was shown to be a mess and totally insecure. I imagine to protect the corporate image. But such corporate interests don't belong in FreeBSD. Just admit you hired the wrong guy (or the right guy at the wrong time) and take the hit. Because it wasn't even the company's fault really.
The lack of serious review on the freebsd side was also a big one but I find the 'strings attached' the biggest issue myself because it made mitigation of serious issues such a problem.
The large amount of corporate kernel work in Linux is why I went for FreeBSD and to see whatever little go so wrong was worrying.
While I have some disagreements with iXsystems' pivot to ZFS-on-Linux offerings and the like, they're not the clowns that Netgate / pfSense are. 10cm to my right are TrueNAS and opnSense boxes - you won't catch me dead using pfSense in my network after the crap they've pulled.
> After the expansion completes, old blocks remain with their old data-to-parity ratio (e.g. 5-wide RAIDZ2, has 3 data to 2 parity), but distributed among the larger set of disks. New blocks will be written with the new data-to-parity
ratio (e.g. a 5-wide RAIDZ2 which has been expanded once to 6-wide, has 4 data to 2 parity).
Does anyone know why this is the case? When expanding an array which is getting full this will result in a far smaller capacity gain than desired.
Let's assume we are using 5x 10TB disks which are 90% full. Before the process, each disk will contain 5.4TB of data, 3.6TB of parity, and 1TB of free space. After the process and converting it to 6x 10TB, each disk will contain 4.5TB of data, 3TB of parity, and 2.5TB of free space. We can fill this free space with 1.66TB of data and 0.83TB of parity per disk - after which our entire array will contain 36.96TB of data.
If we made a new 6-wide Z2 array, it would be able to contain 40TB of data - so adding a disk this way made us lose over 3TB in capacity! Considering the process is already reading and rewriting basically the entire array, why not recalculate the parity as well?
> Does anyone know why this is the case?
> Considering the process is already reading and rewriting basically the entire array, why not recalculate the parity as well?
IANA expert but my guess is -- because, here, you don't have to modify block pointers, etc.
ZFS RAIDZ is not like traditional RAID, as it's not just a sequence of arbitrary bits, data plus parity. RAIDZ stripe width is variable/dynamic, written in blocks (imagine a 128K block, compressed to ~88K), and there is no way to quickly tell where the parity data is within a written block, where the end of any written block is, etc.
If you had to instead, modify the block pointers, I'd assume you have to also change each block in the live tree and all dependent (including snapshot) blocks at the same time? That sounds extraordinarily complicated (and this is the data integrity FS!), and much slower, than just blasting through the data, in order.
To do what you want, you can do what one could always do -- zfs send/recv between a filesystem between and old and new filesystem.
> To do what you want, you can do what one could always do -- zfs send/recv between a filesystem between and old and new filesystem.
Sure, but that involves having enough spare disks, enough places to put them, and enough places to connect them.
This way, while the initial expansion is not ideal, it works. If you really need the space gains from a wider distribution, you can do this expansion and then do the make a new copy, then replace old copy with a new copy dance... although that's counter productive if you have snapshots.
> Sure, but that involves having enough spare disks
So long as we are pointing out things: this presumes that the user doesn't have enough space to make the copies on their own disks? If one has a 3GB dataset and 9GB of free space, one can easily zfs send/recv that dataset and destroy the old copy.
> This way, while the initial expansion is not ideal, it works.
Yep.
> If you really need the space gains from a wider distribution, you can do this expansion and then do the make a new copy, then replace old copy with a new copy dance... although that's counter productive if you have snapshots.
That's why you do a zfs send/recv, instead of a copy. ZFS will copy your snapshots for you!
Again not an expert -- but if you look at the presentations re: this feature, I presume you wouldn't. Why? Because another feature, adopted concurrently, provides for time independent geometry? So, if you look at the pool after time X, you have the same block #, etc., but with a different geo.
The reason the parity ratio stays the same, is that all of the references to the data are by DVA (Data Virtual Address, effectively the LBA within the RAID-Z vdev).
So the data will occupy the same amount of space and parity as it did before.
All stripes in RAID-Z are dynamic, so if your stripe is 5 wide and your array is 6 wide, the 2nd stripe will start on the last disk and wrap around.
So if your 5x10 TB disks are 90% full, after the expansion they will contain the same 5.4 TB of data and 3.6 TB of parity, and the pool will now be 10 TB bigger.
New writes, will be 4+2 instead, but the old data won't change (they is how this feature is able to work without needing block-pointer rewrite).
The linked pull request says "After the expansion completes, old blocks remain with their old data-to-parity ratio (e.g. 5-wide RAIDZ2, has 3 data to 2 parity), but distributed among the larger set of disks". That'd mean that the disks do not contain the same data, but it is getting moved around?
Regardless, my entire point is that you still lose a significant amount of capacity due to the old data remaining as 3+2 rather than being rewritten to 4+2, which heavily disincentives the expansion of arrays reaching capacity - but that is the only time people would want to expand their array.
It just seems to me like they are spending a lot of effort on a feature which you frankly should not ever want to use.
I don't use raidz for my personal pools because it has the wrong set of tradeoffs for my usage, but if I did, I'd absolutely use this.
Yes, your data has the old data:parity ratio for older data, but you now have more total storage available, which is the entire goal. Sure, it'd be more space-efficient to go rewrite your data, piecemeal or entirely, afterward, but you now have more storage to work with, rather than having to remake the pool or replace every disk in the vdev with a larger one.
> So the data will occupy the same amount of space and parity as it did before.
So you lose data capacity compared to "dumb" RAID6 on mdadm.
If you expand RAID6 from 4+2 to 5+2, you go from using 33.3% data for parity to 28.5% on parity
If you expand RAIDZ from 4+2 to 5+2, your new data will use 28.5%, but your old (which is majority, because if it wasn't you wouldn't be expanding) would still use 33.3% on parity.
Could you force a complete rewrite if you wanted to? That would be handy. Without copying all the data elsewhere of course. I don't have another 90TB of spare disks :P
Edit: I suppose I could cover this with a shell script needing only the spare space of the largest file. Nice!
> Could you force a complete rewrite if you wanted to?
On btrfs that's a rebalance, and part of how one expands an array (btrfs add + btrs balance)
(Not sure if ZFS has a similar operation, but from my understanding resilvering would not be it)
Not that it matters much though as RAID5 and RAID6 aren't dependable upon, and the array failure modes are weird in practice, so in context of expanding storage it really only matters for RAID0 and RAID10.
The easiest approach is to make a new subvolume, and move one file at a time. (Normal mv is copy + remove which doesn't quite work here, so you'd probably want something using find -type f and xargs with mv).
> Considering the process is already reading and rewriting basically the entire array, why not recalculate the parity as well?
Because snapshots might refer to the old blocks. Sure you could recompute, but then any snapshots would mean those old blocks would have to stay around so now you've taken up ~twice the space.
AFAIK in ZFS snapshots are just a pointer to (an old) merkle tree[1], if you go about changing the blocks then you need to update that tree, but you can't due to copy-on-write (without paying for the copy, like I mentioned).
The key issue is that you basically have to rewrite all existing data to regain that lost 3TB. This takes a huge amount of time and the ZFS developers have decided not to automate this as part of this feature.
You can do this yourself though when convenient to get those lost TB back.
The RAID VDEV expansion feature actually was quite stale and wasn’t being worked on afaik until this sponsorship.
Was it confirmed anywhere that this space-inefficiency-until-rewrite issue was why it stagnated? I remember looking up the progress a few months ago and being perplexed by the radio silence, given there were celebrations that we were apparently on the home straight back in 2021
I imagine there would eventually be a way / option to automatically rewrite old blocks. Or at least I would hope so because usually when your adding new disks the array is going to be near full
Almost certainly not in any useful fashion that doesn't duplicate data versus old snapshots.
ZFS really deeply assumes you're not gonna be rewriting history for a bunch of features, and you'd have written a good chunk of a new filesystem to reimplement everything without those assumptions.
IIRC one of the developers was asked about this and said it would be about as much additional effort as the whole expansion feature so far. There is of course the user-level workaround of (roughly) `for file in *; do cp $file $file.new && mv $file.new $file && done`, but if I understand correctly you'd need to do this with no snapshots, otherwise the space from $file wouldn't be freed so you'd need an array that's at least half empty
You can do a zfs send/zfs recv to send a dataset (including all snapshots) to yourself which is effectively rewriting the whole dataset, including all of its history, by duplicating it.
Not hard, but it does require sufficient free space. Once it's done you can destroy the original dataset and reclaim the space.
"This feature allows disks to be added one at a time to a RAID-Z group, expanding its capacity incrementally. This feature is especially useful for small pools (typically with only one RAID-Z group), where there isn't sufficient hardware to add capacity by adding a whole new RAID-Z group (typically doubling the number of disks)."
I’m not an expert whatsoever but what I’ve been doing for my NAS is using mirrored VDEVs. Started with one and later on added a couple more drives for a second mirror.
Coincidentally one of the drives of my 1st mirror died few days ago after rebooting the host machine for updates and I replaced it today, it’s been resilvering for a while.
Mirrored vdevs resilver a lot faster than zX vdevs. Much less chance of the remaining drive dying during a resilver if it takes hours rather than days.
Is the amount of data read/written the same? I'm not clear why wall time is the relevant metric, unless that's the critical driver of failure likelihood. I would have guessed it's not time but bytes.
A mirror resilver is a relatively linear and sequential rewrite, so its very fast. Raidz resilvers require lots of random reads and writes across all the drives, and requires waiting for all drives to read data before it can be written to the replaced drive - "herding cats" sounds appropriate here.
That makes sense. Usually the received wisdom I hear is "RAIDZ is slower due to the parity calculations", which has always seemed dubious to me on modern CPUs, given we can do much more complex compression and encryption at way faster then disk speed (for HDDs, at least)
Usually what makes RAID-Z slower is not really the parity calculations, it's the fact that each RAID-Z vdev only has the read IOPS of the slowest disk in it.
So for example, a pool with 2 RAID-Z vdevs each containing 5 disks effectively has only 2x the IOPS of a single disk, while a pool with 5 mirror vdevs (i.e. RAID-10) has 10x the IOPS of a single disk.
It's not a big problem if you mostly do sequential I/O but it's a huge difference if/when you do small random reads (e.g. traversing a non-cached directory tree).
In the context of resilvers, currently RAID-Z pools can only be done by traversing the block tree which, due to fragmentation of CoW filesystems, usually leads to a lot of random reads/writes, while a RAID-10 pool can basically resilver a pool while doing almost fully sequential I/O which can be much, much faster.
Do random reads and writes out more stress on the drive mechanism? I’m wondering if this increase in resliver time adds risk of data loss, which is probably the more important factor than clock time. (But I’m open to learning if I am wrong)
I am backing up the whole NAS in case such a failure happens, and as was mentioned in other replies getting the replacement drive in the pool is way quicker on a mirrored vdev.
However RAIDZ2 can survive up to one of those stressed disks failing, while a 2-mirror has everything riding on that single survivor. It seems intuitive that mirrors would be safer, yeah, but if you run the binomial distribution numbers there are some realistic combinations of array size and individual drive failure probabilities where RAIDZ2 really does appear to be safer
Imagine a gambler telling you "you can either throw one k-faced die and you lose if it comes up on 1, or throw n k-faced dice and you lose if two come up on 1". Depending on k and n, the second really can be the better choice
Often people cite the faster rebuild of mirrors as a safety advantage, but the same amount of rebuild IO will occur regardless of how long it takes. Yes, there will be more non-rebuild IO in a larger time window, but unless that routine load was causing disks to fail weekly then I doubt it will change the numbers non-negligibly. It will of course affect array performance though, so mirrors for performance is a good argument
If we were to only compare survival after a fixed number of drives failed vs. storage efficiency, RAIDzN should always come out ahead in any configuration - with mirrors you can get unlucky drives choice fail, with RAIDzN any choice is a good choice. Only way to have RAIDz fail sooner than mirror is to have a comparatively less redundant setup (your choice of N and K).
Realistically though, RAIDz recovery is longer and more stressful, so more of your drives can fail in the critical period, and, assuming you have backups, your storage is there for for usability - mirroring gives you a performant usable system during a fast recovery for the price of a small chance of complete data loss (but you have backups?) vs RAIDz that gives you long recovery pains on a degraded system, but I expect a smaller chance of data loss on a lightly loaded system.
Well, from my probe of 500 servers I have at work I have seen RAID1 rebuild failing zero times and RAID6 failing once (but we did recover it).
Granted, that was a bit of uncommon case where:
* someone forgot to order spares after taking last one
* we still had our consumable buying pipeline going thru helpdesk
* helpdesk didn't had any importance communicated about it and because of some accounting bullshit the purchase got delayed long enough
* the drives in question were all from some segate's fuckup of a model with much higher failure rates.
One disk failed with some media errors, remaining 2 got kicked out of array for same reason during resilvering
We ddrescue'd the 2 on the pair of fresh ones and the bad blocks didn't land in the same place on both drives so it made full recovery. But we did learn many lessons from that..
However, RAID1, you stress the drive that has your only copy of the data. With 5/6 (RAIDz w/ 2 spares as well) you can have multiple copies of the data, so although you are overall increasing stress on your fleet, wouldn't it have a lower probability of data loss?
Drive stress (for me) is mostly a concern about data loss.
With RAID5 you'd have higher probability of data loss. Remember, you just loss the only redundancy you had, brining your redundancy to same level as RAID1 with failed drive.
... except now you have more drives that can fail.
With RAID6 yes, you can still fail one more time and still keep your data, which is why it is recommended.
Data safety wise I'd go RAID6 -> RAID1/10 (particularly linux implementation can do raid10 on odd number of drives which is nice) -> RAID5
Note that the listed probabilities of surviving N-disk failures are not correct, though after calculation, though the differences may not be that important.
Listed survival probability of N-disk failure in 8-drive/4-vdev mirror.
We just used RAID6... expanding by more drives is easy while keeping data waste low and the "we want to put bigger drives now" case isn't all that problematic considering that what you save you waste on low efficiency of RAID1 setup.
We did had a big case so we just ran 2xRAID6 setup and that one time where it was needed we just replaced to bigger drives one by one, while using the removed ones as spares for other machines. But that's benefit of scale bigger than "a NAS server".
Yeah mine is a home NAS, not a professional deployment. At first I was a bit disappointed at losing half the storage due to using mirrors but honestly it’s not a big deal considering the prices I managed to find on the drives. And I also wanted to expand at my own pace. The drive I recently used to replace the dead 4TB drive cost me 110€ and it’s a 10TB drive.
I got 2 so I’ll also replace the sibling of the dead 4TB one.
This has been floating around for 2 years at this point so might be a long while until it gets in. Interesting, QNAP somehow added this feature into the code that their QuTS Hero NASes uses. I'm not sure how solid or tested the QNAP code is but it's solid enough that they're shipping it in production.
I would expect any storage array to recommend a full backup any time you are messing with the physical disks. even "production ready" features one would not add, remove, or do anything with the array with out a full backup.
"Production" systems should not even be considered production unless you have a backup of them,
QNAP's source drops are also kind of wild, in that they branched a looooooooong time ago and have been implementing their own versions of features they wanted since, AFAICT.
I’m frustrated because this feature was mentioned by Schwartz when it was still in beta. I thought a new era of home computing was about to start. It didn’t, and instead we got The Cloud, which feels like decentralization but is in fact massive centralization (organizational, rather than geographical).
Some of us think people should be hosting stuff from home, accessible from their mobile devices. But the first and to me one of the biggest hurdles is managing storage. And that requires a storage appliance that is simpler than using a laptop, not requiring the skills of an IT professional.
Drobo tried to make a storage appliance, but once you got to the fine print it had the same set of problems that ZFS still does.
All professional storage solutions are built on an assumption of symmetry of hardware. I have n identical (except not the same batch?) drives which I will smear files out across.
Consumers will never have drive symmetry. That’s a huge expenditure that few can justify, or much afford. My Synology didn’t like most of my old drives so by the time I had a working array I’d spent practically a laptop on it. For a weirdly shaped computer I couldn’t actually use directly. I’m a developer, I can afford it. None of my friends can. Mom definitely can’t.
A consumer solution needs to assume drive asymmetry. That day it is first plugged in, it will contain a couple new drives, and every hard drive the consumer can scrounge up from junk drawers - save two: their current backup drive and an extra copy. Once the array (with one open slot) is built and verified, then one of the backups can go into the array for additional space and speed.
From then on, the owner will likely buy one or two new drives every year, at whatever price point they’re willing to pay, and swap out the smallest or slowest drive in the array. Meaning the array will always contain 2-3 different generation of hard drives. Never the same speed and never the same capacity. And they expect that if a rebuild fails, some of their data will still be retrievable. Without a professional data recovery company.
which rules out all RAID levels except 0, which is nuts. An algorithm that can handle this scenario is consistent hashing. Weighted consistent hashing can handle disparate resources, by assigning more buckets to faster or larger machines. And it can grow and shrink (in a drive array, the two are sequential or simultaneous).
Small and old businesses begin to resemble consumer purchasing patterns. They can’t afford a shiny new array all at once. It’s scrounging and piecemeal. So this isn’t strictly about chasing consumers.
I thought ZFS was on a similar path, but the delays in sprouting these features make me wonder.
Unraid "solves" that althought needs some user knowledge (IIRC parity drives must be the biggest one in array and for some reason that isn't automatic)
Ceph actually works quite well for that, althought obviously far more complex than anything for home use. You just tell it "x chunks with N parity" and it will spread it over available drives. Just need more drives than x + n and not too egregious size differences.
> Weighted consistent hashing can handle disparate resources, by assigning more buckets to faster or larger machines. And it can grow and shrink (in a drive array, the two are sequential or simultaneous).
It would need to be more complex than that. Putting chunks on say 2, 6, 8, 12, 22 TB (which might be what you'd get if you just buy "cheapest GB/$" for your NAS over last 10 years!) is more complex than that.
I can afford it, but have a hard time justifying the costs, not to mention scrapped (working) hardware and inconvenience (of swapping to a whole new array).
I started using snapraid [1] several years ago, after finding zfs couldn't expand. Often when I went to add space the "sweet spot" disk size (best $/TB) was 2-3x the size of the previous biggest disk I ran. This was very economical compared to replacing the whole array every couple years.
It works by having "data" and "parity" drives. Data drives are totally normal filesystems, and joined with unionfs. In fact you can mount them independently and access whatever files are on it. Parity drives are just a big file that snapraid updates nightly.
The big downside is it's not realtime redundant: you can lose a day's worth of data from a (data) drive failure. For my use case this is acceptable.
A huge upside is rebuilds are fairly painless. Rebuilding a parity drive has zero downtime, just degraded performance. Rebuilding a data drive leaves it offline, but the rest work fine (I think the individual files are actually accessible as they're restored though). In the worst case you can mount each data drive independently on any system and recover its contents.
I've been running the "same" array for a decade, but at this point every disk has been swapped out at least once (for a larger one), and it's been in at least two different host systems.
I like Snapraid, but there are a few downsides worth mentioning
* Rebuilds are semi-offline, as you said. Almost every other solution, even Unraid, will immediately emulate the data from a failed drive. On Snapraid you have to wait for each file to be restored, and depending on your union setup this may mean you have directories with half the files missing
* Whenever you modify or delete a file between syncs, your parity is now out of sync. This means some other files may fail to restore if you have a failure now. However using more than single parity will make this far less likely to happen. Another way to fix this completely the "snapraid-btrfs" tool, which runs Snapraid on snapshots of independent btrfs disks (somewhat like Synology?), meaning the old data is still available
* It saves almost no file metadata, not even owner and mode. Restored files just use the umask of the user running the restore command. A minor one, but surprisingly annoying
However one big advantage over Unraid it has is how transactional and rigorous it is. A power failure can cause Unraid parity to desync, with no clear way to know which disk is right. Snapraid OTOH is designed to survive interruptions gracefully, and checksums all files so should never accidentally restore corrupt data. And can detect silent drive failure ("bitrot") as a bonus
And for a typical home NAS storing movies and family photos (mostly append-only), those downsides are probably no big deal anyway
I gave snapraid a serious look a few months back and decided it might not be for me because the act of balancing writes out to the "array" member disks appeared to be manual.
I didn't want to point applications at 100 T of "free" space only for attires to start blocking after 8.
Sorry I said unionfs but it's actually handled by mergerfs [1], and it's all automatic. There are a whole boatload of policies [2] to control writes.
I use "existing path, least free space". Once a path is created, it keeps using it for new files in that path. If it runs out of space, it creates that same path on another drive. If the path exists on both drives for some reason, my rationale is this keeps most of the related files (same path) together on the same drive.
I see there's some newer "most shared path" options I don't remember that might even make more sense for me, so maybe that's something I'll change next time I need to touch it.
> If it runs out of space, it creates that same path on another drive.
That's not how it works.
The policy picks what branch to use and then once selected mergerfs will clone the relative path as needed. With "ep" policies it will never select a branch that doesn't have the full relative path. "msp" will always rerun the check one level up in the hierarchy if nothing is found at the current level.
> which rules out all RAID levels except 0, which is nuts.
RAID 1, you mean? Because that way you still have a complete copy of your data if one drive fails.
BTRFS is excellent for the use case of a wide variety of mismatched drives, because it supports adding and removing drives and rebalancing the array. But for the moment only the RAID 1 modes are really trustworthy. I have a NAS consisting of drives whose advertised capacities in GB are: 1000, 1000, 1920, 2000, 2048, 2050, 3840, 3840, 4000. But it started as a pile of infamously unreliable 3TB hard drives.
The BTRFS raid1 feature is very badly named, its best called two-copy. Skipping some details, two copies of data are written to the two drives with the most free space. So you can have multiple mismatched drives.
However you get no striping, and data is only read from one drive, so performance is limited to that of one drive for reads and writes. Plus with mismatched drives, smaller drives go unused unless you write enough data.
You're going to have to support that claim a bit better. The core idea of RAID 1 is mirroring data, which BTRFS RAID 1 mode definitely does. Striping is not an essential part of RAID 1 (hence RAID 10), and reading data from two disks in parallel is an optional performance optimization that is not performed by all RAID 1 implementations (but could be implemented for BTRFS RAID 1: https://stackoverflow.com/questions/55408256/btrfs-raid-1-wh... ).
> Plus with mismatched drives, smaller drives go unused unless you write enough data.
Yes, the allocation is suboptimal from a performance perspective, as I've already said. But it is simple and straightforward and reasonably good at avoiding putting you into a situation where manually issuing a rebalance command is necessary. If you do need better performance, there's a RAID 10 mode. But since my NAS is currently a motley pile of SSDs, I don't need to to anything extra to have decent performance.
RAID1 is about mirroring disks, BTRFS RAID1 mirrors block groups. Plus traditionally a RAID1 of 3 disks will mirror the same data on all disks, which is different to how the RAID1 mode on BTRFS acts. So the name leads to misunderstandings since it doesn't act like RAID1 at all.
It'd be way easier to talk about if it had a unique name, and you could say "It's like RAID1".
Despite all that I do like the mode, and use it in a few places.
BTRFS RAID 1 works just fine with heterogeneous disks with no extra configuration required; I would not have been able to provide examples from experience otherwise. When writing new data, it allocates two blocks on two separate devices, preferring to allocate space on whatever devices have the most free space. This may not be optimal from a performance perspective, but it does mean there's minimal wasted capacity in most configurations. (The RAID1c3 and RAID1c4 modes work the same, but with three or four copies of each block, all on separate devices.)
Were you assuming that BTRFS RAID 1 meant every block of data gets mirrored across every device? I've seen that assumption before, from people who don't realize there are two ways to generalize RAID1 to more than two devices.
Eh, it can kinda work. If you have 1, 2,3,4TB drives you can make RAID10 out of first GB, then stitch 2TB RAID0 from second and third and RAID1 it with 2TB out of 4th drive. then raid1 out of remaining GB on 3rd and 4th.
Until the BTRS filesystem gets to some indeterminate threshold of “almost full”, at which point you typically need to reformat and restore from backups…
I haven't been following BTRFS development closely for a few years, so I don't know how much more progress they've made on eliminating those corner cases. But I'm still careful about not letting the filesystem get close to full. Earlier this month, I noticed one of my machines was over 80% full, so I grabbed a few drives I had lying around that weren't in use at the time and added them to the array. The flexibility of BTRFS gives you a lot more options than eg. ZFS for getting out of a tight spot without the full wipe and restore hassle. But both can still leave you stuck, especially if you ignore the need for monitoring and preventive maintenance.
Disk full is not a “corner case”. It should be one of the first test cases a filesystem test suite should have, and that test should always pass in every configuration.
The fact that total data loss happened regularly on full volumes many years after a “stable” release means BTRFS is either fundamentally flawed in design or incompetently implemented. I have no idea how it was accepted into mainline Linux.
The fact that a certain large NAS vendor used BTRFS by default (without documentation at the time of purchase) has cost my org and others lots of downtime and money.
I didn't say it was. There are plenty of disk full scenarios that can be handled by BTRFS without trouble, especially when adding more disks (even temporarily) is an option. There are ways to get stuck with a full fs, but it's not a guarantee you'll end up in a "wipe and restore from backup" situation. (And to be fair, ZFS also gets very problematic when completely full; this is a general problem for CoW filesystems.)
Sooo basically if you were using XFS you wouldn't need to do anything at all till it got 99% full, and if you got it there you'd just get "disk is full" message instead of some catastrophe? I don't need that kind of stress in my life...
And with plain RAID6 I can still add hard drives if needed. Yeah the case of buying bigger drives is still a bit iffy but btrfs RAID1 gonna lose me more space than RAID6+LVM+xfs anyway...
> I’m a developer, I can afford it. None of my friends can. Mom definitely can’t.
The only thing that can work for your mom and your friend is, in my opinion, a pair of disks in mirror. When the space finished, buy another box with two other disk in mirror. Anything more than this is not only too complex for the average user but also too expensive.
I think I would advise against a direct mirroring -- instead, I'd do sync-every-24-hours or something similar.
Both schemes are vulnerable to the (admittedly rarer) errors where both drives fail simultaneously (e.g. mobo fried them) or are just ... destroyed by a fire or whatever.
A periodic sync (while harder to set up) will occasionally save you from the deleting the wrong files which mirroring doesn't.
Either way: Any truly important data (family photos/videos, etc.) needs to be saved periodically to remote storage. There's no getting around that if you really care about the data.
I completely agree. To build my array I had to buy several drives at the same time. To expand I had to buy a new drive, move the data onto the array, and then I’m left with the extra drive I had too buy to temporarily store the data because I can’t add it to the array.
I would love to have more options for expandable redundancy.
We may get a successor filesystem before that particular situation is sorted out..
By all accounts mainline is at best not interested, if not actively against ZFS on Linux. The last few kerfuffles around symbols used by the out-of-tree module laid out the position rather unambiguously.
It’s sad to see that free software under a license (and movement) that was born out of someone’s frustration with closed-source printer drivers (acting as DRM, albeit inadvertently) appears to include similar DRM whose sole purpose is to restrict usage of a (seemingly arbitrary) selection of symbols.
OpenZFS is a fork of the Sun/Oracle release of ZFS. The OpenZFS maintainers cannot change the license without consent of the copyright owners, and Oracle is unlikely to consent. Oracle could potentially change the terms in a future release of CDDL, and that might work, too.
Similarly, Linux probably has too many contributors, some of which are no longer living, to come to an agreement on a fixed license either.
Although, license changes do happen; OpenSSL did one recently, but I think there are fewer contributors.
Because it uses code released by Sun under the CDDL. Oracle has since closed sourced the whole thing again so they're not going to change the license of this old code, they don't even want it out there but they can't take it back.
https://lwn.net/Articles/939842/ was the most recent one (August 2023). The article focuses on the NVIDIA proprietary driver but the bulk of the comments are about the impact on ZFS.
ZFS is already a very awkward citizen on Linux (e.g. can't use the page cache so it has to duplicate all that in the ARC; won't be able to take advantage of multi-page folios because of the lowest-common-denominator SPL; ...) and it will get worse, not better.
bcachefs has had time to actually mature instead of being kneecapped early on by an angry Linus Torvalds when btrfs's on disk format changed and broke his Fedora install.
Has the whole license incompatibility thing actually been tested/litigated in court? I heard Canonical has (at least at some point) shipped prebuilt ZFS. I understand that in-tree inclusion brings its own set of problems, but I’m just asking about redistribution of binaries - the same binaries you are allowed to build locally.
It would be nice to have a precedent deciding on this bullshit argument once and for all so distros can freely ship prebuilt binary modules and bring Linux to the modern times when it comes to filesystems.
The whole situation is ridiculous. I'd understand if this was about money, but who exactly gets hurt by users getting a prebuilt module from somewhere, vs building exactly the same thing locally from freely-available source?
The only entity to start a litigation cycle is Oracle, and they've either been uninterested or know they can't win. Canonical is the only entity they have any chance of going after; Canonical's lawyers already decided there was no license conflict.
Linus Torvalds doesn't feel like being the guinea pig by risking ZFS in the mainline kernel. A totally reasonable position while the CDDL+GPL resolution is still ultimately unknown. (And honestly, with OpenZFS supporting a very wide range of Linux versions and FreeBSD at the same time, I have the feeling that mainline inclusion in Linux might not be the best outcome anyway.)
I wonder what Oracle would litigate over though? My understanding is that licenses are generally used by copyright holders to restrict what others can do with a work so the holder can profit off the work and/or keep a competitive advantage.
Here I do not see this argument applying since the source is freely available to use and extend; the license explicitly allows someone to compile it and use it. In this case providing prebuilt binaries is more akin to providing a "cache" for something you can (and are allowed to) build locally (using ZFS-DKMS for example) using source you are once again allowed to acquire and use.
What prejudice does it cause to Oracle that the “make” command is ran on Ubuntu’s build servers as opposed to users’ individual machines? Have similar cases been litigated before where the argument was about who runs the make command, with source that either party has otherwise a right to download & use?
Playing legal chicken with Oracle is a really dumb thing to do because catching their customers in obscure license violations and then suing the hell out of them is their entire business model. They specialise in this stuff.
Copying and distributing those binaries is covered by copyright. You have to follow the license if you want to do it. It doesn't matter that end users could legally get the same files in some other manner. Distribution itself is part of the legal framework.
It isn’t compatible because it adds additional restrictions regarding patented code. The CDDL was made to be used in mixed license distributions and only affects individual files, but the GPL taints anything linked (which is why LGPL exists). Since the terms of the CDDL can’t be respected in a GPL’d distribution, I can’t see a way for it to ever be included in the kernel repo.
I don’t think there’s any issue with canonical shipping a kmod, but similar to 3ᴿᴰ party binary drivers, it would need to be treated as a different “work”.
It's a little unfair to blame it on GPL. If ZFS was MIT/BSD/etc licensed, it could be brought into the Linux repository just fine. CDDL explicitly doesn't let that happen, by saying "Source Code form must be distributed only under the terms of this License". That only is harsh.
if the kernel was MIT/BSD/etc licensed ZFS would be allowed in the kernel just fine too. but only one of the licenses is infectious and requires things of the other sources.
it's definitely a GPL issue more than a CDDL issue
GPL predates CDDL; CDDL authors were well aware of GPL; CDDL authors chose to make the license different from existing commonly-used open source licenses. Ask why...
I'm aware of the surrounding arguments, I promise; my remark was that I doubted Linux would like to ship a large mass of code with any additional encumberments even if it didn't somehow fail the GPL compatible test. (I'm aware that this is an impossible condition barring court precedent that ignores the definition of the constraint.)
Can you elaborate on what kind of bugs? I've been following bcachefs casually because I am very excited for its eventual stabilization. But I am very conservative with my main storage array.
Not GP, but I tried it out a few weeks ago. I experienced it working for about 15-20 minutes, then it stopped doing any I/O to the disks until I rebooted. After it happened a few times in one evening, I switched to something else.
If you don’t need real-time redundancy, you maybe better served by something like SnapRAID. It’s more flexible, can mismatch disk sizes, performance requirements are much lower, etc.
Yeah, the non-parity RAID modes have been safe for a pretty long time, as long as you RTFM when something goes wrong instead of assuming the recovery procedures match what you'd expect coming from a background of traditional RAID or how ZFS does it. I've been using RAID-1 (with RAID1c3 for metadata since that feature became available) on a NAS for over a decade now without loss of data despite loss of more drives over the years than the array started out with.
this is a really neat addition to raid-z. i recall setting up my zfs pool in the early 2000s and grappling with disk counts because of how rigid expansion was. Good times. this would've made things so much simpler. small nitpick: in the "during expansion" bit, I thought he could have elaborated a touch on restoring the "health of the raidz vdev" part, didn't really follow his reasoning there. but overall, looking forward to this update. nice work.
I remember in the decade+ before zfs was introduced and in several of the years since then trying to figure out the optimal stripe size for RAID 10 volumes and the optimal stripe size and count for RAID 5 volumes with Solaris Disk Suite, VxVM, Linux md, etc. Fixing bad decisions has typically meant backup twice, test a restore, fixe the volume, and pray one of your backups is good. :)
ZFS has generally been easier to go from zero to working well once you accept that life doesn’t need to be so complicated as legacy md, lvm, and fs layers made it. It also has a pretty big footgun that causes me to carefully read the man page before using “zpool add” or “zpool attach”. Vdev removal is a big help for this.
oh, the memories of trying to optimize stripe sizes in the pre-zfs days! i can totally relate to the struggles with solaris disk suite and linux md. the pain of fixing poor decisions and the nail-biting backup processes are all too familiar. zfs really did simplify things in many ways. though i agree, it's always a good idea to tread carefully with commands like `zpool add` and `zpool attach`. glad vdev removal has made that process a bit smoother. it's pretty cool to see how storage management has evolved over the years. cheers for the trip down memory lane. :)
Lack of this feature has kept me on Synology and their SHR-system.
I can just slap in any drives of any size and it'll just adapt. As long as the new drives go in an empty slot or are bigger than the previous one, I get more space. Zero CLI commands needed.
Now get this feature in unraid or TrueNAS and I'm switching.
{kind=link}
How cool would it be if we had a great GUI for ZFS (snapshots, volume management, etc.). I could buy a new external disk, add it to a pool, have seamless storage expansion.
It would be great. Ah, what could have been.