An idea from the 'Crossing the Chasm' book is to find a niche where whatever characteristics of the product you're working on can win. You are not going to win going head to head with the entrenched competitors.
That's the wrong framing for Hurd. Hurd isn't a "product" that's trying to "win" by beating competitors.
It's a project that's being built by and for people that care about it.
You might as well ask "How can my local pick-up basketball team find a niche to make money, like NBA players do? Can we all wear more colorful jerseys so TV stations cover us?" No, that's silly, the point of the pick-up basketball team isn't to make money, it isn't to beat a competitor, like the NBA, for sports coverage, it's to hang out with friends and have fun.
That's what many free software projects are like. And if enough people come to hang out and have fun, it might organically become bigger and better, but if you start making it the point of it, it ruins it. If you tell the pick-up basketball people "No, you can't join, you're not photogenic enough", you won't have friends soon. If you start telling hurd developers "We need to take on MS, stop working on that thing you care about, no one else cares about it", the project will die.
I mean, if the goal is "install a niche kernel for the sake of it", sure that's... a reason, but all the modern non-mainstream kernels (aka not Darwin or NT) at least have a purpose as to why you'd pick them.
* Linux is the de facto kernel used on most servers, has great support and is the third pick after the mainstream kernels for a good reason. It's also usually someone's first introduction to Unix-based systems these days, so there's loads and loads of documentation available (even if the quality of that documentation runs the gamut from "acceptable" to "who wrote this").
* BSDs are rock solid and a great pick if you're targeting reliability. Knowledge on a BSD changes little with the years and that's a big bonus.
* Plan9 is interesting because it provides a unique approach to system design by taking the "everything is a file" approach to its logical limit. That doesn't make the system itself the most useful in the world but it is an excellent system to study and borrow good ideas from.
The main reasons I can see to use Hurd are... ideological opposition to Linux and being a microkernel. While the latter has interesting implications, the usual GNU problem of "we don't try to support any hardware unless it ideologically conforms" really gets in the way of wanting to use it and that's definitely a broader GNU problem but it's a much larger for problem for something as crucial as a kernel.
Also not helping things is that to my understanding, Hurd kind of has a start-stop nature to its development - that is, the project is on life support unless someone starts dissing it, so it picks up back for a few months to show how it's totally alive. Very much more of a spite driven project these days than a legitimate option.
You bring up Plan9 here as though it isn't in the same boat as Hurd. Hurd also has quirky file system stuff [1] and many other interesting and relatively novel features, but you seem to treat this totally differently from Plan9 with no real reason other than you haven't bothered dto learn about the features of Hurd.
Software development definitely needs more ideology, principles, and ethics. When talented hackers get behind a project united on these matters great and interesting features occur spontaneously
When I say ideology, I'm referring moreso to both dogma and bruised egos, both of which the GNU project is rife with.
A lot of Hurds continued development is just predicated on "we don't want to admit Linux became a success" rather than any serious principles or ethics. Again, just look at the whole start-stop nature of its development.
I don't disagree that a lot of tech professionals could spare at least some basic regards for the ethics surrounding the software they create, but you're not gonna find that at the GNU project.
> When I say ideology, I'm referring moreso to both dogma and bruised egos, both of which the GNU project is rife with.
Then just say I don't like that Hurd is part of the GNU Project because I dont like what the latter does. In my opinion, it is very hard to deny that GNU Project / FSF take principles and ethics of software development very seriously. Some people even call them dogmatic for it.
> And if enough people come to hang out and have fun
Is Hurd there? I mean, you obviously don't frame 'success' with an open source system in financial terms, but I would argue that developing a critical development mass is pretty important. Without that, the project will wither and die.
Open source is sort of an "attention economy", so the currency isn't dollars, but developer interest.
Fooling around with something for the joy of learning is a motivator, but I don't know that it's enough to sustain a project, long term.
And Hurd very much is a 'product' in the economic sense, whether it's open source, not for profit, or whatever.
I wrote a little kernel for fun in high school. I wish I still had the time to pick it back up again, or contribute to something like GNU/Hurd. Stuff like this is exactly the reason I became fascinated with programming.
If "fun" and "idological reasons" are the reason there is a community around the project, then that is in fact the answer to the question, if a little vague.
For people still not understanding, it would be nice to have an explanation of what people find fun about it, especially as a user and not a developer, and what ideological reason exactly are driving it.
I'm glad someone gets it. I've been using Linux as my daily driver for about a decade at this point. I can understand the desire to hack on that for fun, because doing so would actually bring about a tangible improvement to my life.
I find the desire to work on a 30 year old operating system that still lacks USB support much more confusing.
Again, no one is saying that everyone should care about Hurd. This just feels like an entire subthread about a strawman. I think your stance is entirely reasonable, and one I resonate with, but it felt like you expected Hurd enthusiasts to convince you that you should care. Which feels like missing the point, to me, at least.
As far as my understanding goes, there are 2 main reasons:
1. The very specific nature of the OS, which aims to be (in theory) very modular
2. You need to partake on a very clear idea of what software freedom means, in every sense of the word
I don't use Hurd, but I do get it. I feel it's quite simple.
Just because it isn't there yet doesn't mean one wouldn't want to hack on it from time to time
Hurd is over 30 years old. It didn't get support for SATA drives until 2013. It still does not support USB devices, at all. Working on such an OS doesn't seem like it would be a good use of my time, especially when that time could be spent working on Linux, or a BSD.
> why we should care about it when more popular operating systems fit our needs better
Linux started this way. If Linux reaches a point where it doesn't fill the needs of its users/developers better, they will pivot to another alternative, and Hurd is one of those future alternatives. See it as future insurance.
I don’t know enough about Hurd to say, but as an example MINUX found its niche as the control software for Intel’s management system. As a result MINUX is/was more widely deployed than Linux for a few years. Still might be.
I would argue that MINIX being used by one company for one application that isn't visible to users and doesn't (as far as I know) contribute any code back to the wider MINIX community (which is a thing) means it really isn't in the same conversation with Linux and *BSD. YMMV.
I mean, any unique features HURD has, Linux can easily copy, like with FUSE.
The safety benefits are kind of dubious, in that we're not in the 90s anymore, restarting Windows 3 times a day. Modern kernels are very stable as it is, so more stability is barely noticeable.
Yep, it found a "niche": people could actually hack on it and get it to do stuff, rather than waiting around for the other thing, which wasn't even really a thing yet anyway.
Linux has a large, large established user base at this point. If you want to attract people to a different platform, you need a compelling reason.
For people just looking to look/experiment/learn/play, 'something new' that's more easily understood because it's small might be enough, but that's unlikely to be a large user base.
I think you missed the point of that comment completely.
Which market segment does linux not totally dominate nowadays? Phones, big servers, embedded devices, HPC... Maybe you could argue desktops? Maybe? Still a very signficant player there however you dice it.
Going back to Linus' original email announcement then apply your framework and you don't predict linux competing anywhere let alone dominating everywhere. How could anyone? Smash Sun, IBM, HP all of them. No chance. None.
The future, it's really hard to predict except in hindsight.
The fact that Linux dominates does not entail that other architectural approaches may be more suitable for the task. Variety is the spice of life and the “Linux monoculture” might not be such a great thing. BeOS/Haiku, Plan9/Inferno, OS400, and Fuchisa are all fascinating lineages that excel in their chosen domains.
Going off base, as this is about Hurd vs GNU/Linux.
On the IoT space it seems like not everyone is keen in having to deal with GPL and Linux, hence the myriad of FOSS MIT/Apache licensed OSSes that now exist.
To be completely honest, there are people against the GPL just about everywhere.
For the same reasons, there are also people just about anywhere that do find value in the GPL.
The license is there for a reason, and its working.
Linux is amazing what you can do with it. You can implement things in a day that you simply couldn't afford otherwise. And it's probably a 100-1000 times less reliable than systems architected around actual RTOS's.
Once upon a time the Hurd was the future. But that time is long in the past and nowadays the Hurd is a relic and I don't see any chance of a revival. Something entirely new probably stands a better chance at arousing some interest than the Hurd.
Yes we have seen it with projects such as serenityOS, redox but if you look closely at those projects most of them stand upright with just 1 or 2 developers. If for some reason they get burned out or some life changes force them to limit their time and attention to these projects they can fall behind very very quickly.
Unless one is already depending on it on a daily basis, nobody wants to take over someone else's project.
> If for some reason they get burned out or some life changes force them to limit their time and attention to these projects they can fall behind very very quickly.
These projects are all one bus away from becoming the next TempleOS.
Kind of weird to see linux called out as too big, and then the ack that writing a ton of device drivers is hard and will take time. Isn't that a large part of the source tree? Realizing I haven't even tried compiling a kernel in a long long time. Feels oddly sad to say.
I'm writing a hobby kernel/operating system and one of the things that surprised me was how simple ext2 is. It really isn't much different from fat32 in many ways, just a bit more flexible and designed in a more future-proof way.
Obviously ext2 is a very outdated filesystem by today's standards, but considering ext3 and ext4 are essentially just some extensions slapped onto ext2, I still didn't expect it.
Another thing I found really impressive was just how resilient e2fsck is. During early development of my ext2 code I frequently mangled the file system in a myriad of weird ways, but no matter how much I broke things, e2fsck was almost always able to restore the file system into a reasonable state.
(For the curious, there is some excellent documentation on the ext2 file system at https://www.nongnu.org/ext2-doc/ext2.html that I mostly used for my implementation of it. Sadly no such thing seems to really exist for ext3/ext4).
The difficulty in filesystems is generally getting to the point of high enough reliability that people trust then with their data. This is why development and adoption of new ones tends to be slow, not the quantity or complexity of implementation. So for a hobby it's quite accessible because that expectation of reliability isn't there.
I also thought that'd be a fun project. BTRFS seems to have the largest feature set although many features are experimental but maybe there would be a place for something smaller that scales well and maybe has some of the new features like deduplication
Simple filesystems - those oriented at speed, without integrity checking, compression, encryption and raid-like features. Which are extremely useful and desirable in a filesystem.
When people tried to do a full-featured filesystem, with a remarkable exception (ZFS) it's either a disappointing unfinished mess (btrfs) or a promising, but a long-term project taking years (bcachefs).
Making a filesystem with strong support of important features is an extremely demanding project.
Filesystems aren't complex to implement -- even complex filesystems.
What's harder is making them as robust as they need to be for practical daily use. Doing that is a matter of comprehensive testing, though. With filesystems, the hard part is QA, not implementation.
It's "perpetually half-finished". Convoluted admin cli tooling, bad track record with reliability and loss of data, lots of stories on the internet. It perhaps got better, but RAID5/RAID6 for metadata (standard use of disks) still not oficially recommended and thus standard RAID5/RAID6 is not reliable. Also, look at some FS benchmarks - BTRFS is still much slower than EXT/XFS, and slower than ZFS.
About the only class of scenarios to use BTRFS instead of ZFS is if you want the features, do not need RAID5/6, require support by Linux distributor/kernel developers or for some other (hard to think of) reason you can't use ZFS.
I do use BTRFS on a single disk where I don't touch it with cli tools, and there it's fine.
Yep, because everyone who is going to do something interesting or enjoyable starts with the question "should I use language X because it's cool?".
Look, I'm as into cool FS-hacks as anyone, but writing a new filesystem has 99+ problems and the language used is either the last of them, or it isn't even in the set.
Granted, you could (on Linux) write a little pseudo-filesystem (e.g. /proc or /sys) and not face any of the issues involved in extN or btrfs etc. I didn't get the sense that this was what the OP intended, but I could be wrong.
1) LoC doesn't indicate complexity. When you're looking at a code base and you see that it's 65000 lines, that by no means should be an indicator of whether or not a re-write is easily feasible -- especially with a filesystem.
2) Language shouldn't be a motivator for a re-write without considering why the language offers advantages, the end users don't care about which file extension is littered across the source tree.
Both of those tendencies (one to re-write everything in your favorite language, and two to come across with an idea that you understand how complex a mechanism is simply from LoC) indicate to me, anecdotally of course, a certain lack of experience; and I have a hard time imagining someone with those concerns tackling a re-write of a filesystem that gains 'the audience' any benefits.
If it's just for the sake of personal toys and fooling around with your own machine I feel as if those motivations are fine, but I have concerns if 'a new filesystem in Rust' comes from what I view as shaky initial motivations.
I frankly don't understand why he doesn't realize that the borrow checker is just the thing to prevent all the bugs you can have with a file system implementation.
Many of the worst bugs (data loss and corruption)? Probably.
Having something like the Rust borrow checker around to make sure you don't make dumb mistakes is handy, to be sure. But, let's not oversell it as some kind of panacea. I bet I could write a FS in Rust with all kinds of bugs, and the borrow checker wouldn't be able to stop me.
I don't have anything recent, but back in 2004, the majority of the Linux kernel code was in its drivers: https://dwheeler.com/essays/linux-kernel-cost.html I expect that most of the current Linux kernel code is also for handling hardware (that is, drivers + the code to handle various architectures).
> You think you want a stable kernel interface, but you really do not, and you don't even know it. What you want is a stable running driver, and you get that only if your driver is in the main kernel tree. You also get lots of other good benefits if your driver is in the main kernel tree, all of which has made Linux into such a strong, stable, and mature operating system which is the reason you are using it in the first place.
Just because the driver creator is a different human/org to the Kernel maintainers, doesn't mean their code needs to be separate if it makes more practical sense to bundle it all together.
Also the "proof of work" of being allowed to add your driver is probably that you are designing and producing actual hardware, so it is hard to troll.
It just produces Conway's law in the other direction (which is smart). Now anyone wanting to use Linux effectively needs to integrate with its development process, which is large part of why it is successful as a project. (However, GNU attempted similar with their lack of an extension interface for GCC and that arguably blew up in their face with LLVM, so it's far from a guaranteed success)
I think it's monorepo vs multi-repo, and since Linux maintainers update the drivers (I believe) when internal APIs change, and the internal APIs are not stable, monorepo seems more practical.
"how the source code is stored" is what leads to "wow, the linux kernel is really big". Nobody's measuring kernel size by the number of resident pages it takes up.
The author is the same (Linus), so it makes sense that he would design a source control system that supported the monorepo he created over the prior 15-ish years.
The machines are different. Multicore 64-bit chips are now standard for consumer PCs. RAM and persistent storage are faster and much more abundant. The architecture of the modern x86-64 is much more sophisticated than that of the 386 for which the earliest Linux was written. Vectorization, predictive branching, and asynchronous code are all front and center in the modern programmer's ecosystem.
In short, hardware is more capable, and so perhaps now we can afford to take more opportunities to trade a little bit of overhead for abstractions that are more modular and robust.
Being a microkernel doesn't automatically make you more robust. If you look at their docs, Hurd has only one feature that's different to Linux and that's a sort of souped up FUSE. But as they realized later, allowing arbitrary unprivileged programs to extend the filesystem like that doesn't mesh well with the UNIX security model. You can write a "translator" that redirects one part of the filesystem tree to another, so you get the same issues as with chroot or symlink attacks. Their proposed solution (never implemented?) is to stop programs paying attention to translators by default if they are running as a different user. There are other cases where translators can DoS apps or do other undesirable things.
The basic problem is that the kernel boundary is a trust boundary. You assume that anything in the kernel is legit and won't try to attack you, which simplifies things a lot. In the microkernel world the original idea was that all the servers would be just ordinary programs you could swap in and out at will. But then the threat model becomes muddied and unclear. Is it OK to run a server that's untrusted? If so, to what extent?
The Hurd seems under-designed as a consequence. To make that vision work you'd need to be willing to depart from UNIX way more, which really means being a research OS.
> Being a microkernel doesn't automatically make you more robust.
No, of course, it doesn't automatically do so. But it makes it a whole hell of a lot easier to write a reliable service, if you don't have to deal with all the crap that a monolithic kernel does. In a very real sense, lines of code are a liability: fewer LoC generally translates into fewer bugs in the software.
I think you'd find Plan 9 interesting. It deals with many of the issues you're talking about in a rather head on way. In fact, it takes things even further than Hurd might, and allows processes to migrate to different processors, which may be contained on completely different machines.
In a very real sense, the hardware has given a realization of microservice ideas, but at the hardware level. My WIFI card, the common and popular example, probably has more processing power than some of the early desktop computers back in the day. Certainly SSDs are getting much more complicated.
They aren't general purpose, but I presume microkernel "services" would also not be general purpose?
Often they are general-purpose. There's a blog from maybe 10 years ago of someone launching Linux on a hard drive (it refuses to fully boot because the hard drive doesn't have an MMU, but they get some familiar log output).
> In short, hardware is more capable, and so perhaps now we can afford to take more opportunities to trade a little bit of overhead for abstractions that are more modular and robust.
We could afford that before, it's just that Linus didn't see the value and put his foot down. Which is definitely a choice.
Do we have more hardware isolation? There was a pretty strong argument against microkernels - a driver running in userspace can still bork the whole machine if the hardware being controlled can write to memory at arbitrary addresses.
On the other hand, datacenters have become so large that a 1% performance improvement can amount to millions of dollars in hardware and energy savings, so the extra cost of a microkernel might not be very welcome outside consumer devices.
We did not yet have a big publicized hack of whole cloud infrastructure causing massive economic harm. When that happens (the buggy PC/Linux architecture running the world is ripe), more secure architectures will become commercially interesting despite the 1% performance penalty.
1. Read up on the seL4 microkernel. It pretty much destroyed the "microkernels are too slow" argument.
2. Modern day hardware is mostly just ringbuffers mapped to memory. There's a real convergence of hardware interfaces, virtio, and io_uring into all being this very similar looking thing. With IOMMUs, moving drivers to userspace is pretty attractive. There's not much of a difference between a cloud VM getting access to a VFIO device from the hypervisor and a userspace device driver getting access to hardware from the microkernel. And there's a lot of money in making cloud VM networking & storage faster.
The drivers are not used in that way in NetBSD, they are either compiled into the kernel or built as modules just like in Linux, the graphics drivers even use the source code from Linux.
Anywhere. There are lots of examples on the topic ; running NetBSD driver code inside NetBSD's user-land is the simplest use-case (https://www.netbsd.org/docs/rump/sptut.html), but that code is portable without modifications to just about any context possible.
Check out Antti Kantee's The Design and Implementation of the Anykernel and Rump Kernels if you want details on the architecture.
GNU Hurd for example. I haven't used it so I'm not sure of the exact status but it sounds like they are using it in some cases to make use of existing drivers in a microkernel style. There have been a few attempts to rumpify Linux but it doesn't seem like any of them succeeded and I'm not sure if anyone is still trying.
Yes, that is how it works in most sane operating systems, even more so nowadays where writing userspace drivers is preferable to dynamically loadable modules.
With a microkernel model, most of those drivers would run in user space, not kernel space. So it's possible for the device drivers to be large but the GNU HURD kernel itself to be much smaller than the Linux kernel.
Heh, not a particulary in-depth article in any way, to be honest.
"the GNU/Hurd is Unix(POSIX)-compatible, so most things work"... well that's to be said for MacOS, QNX, etc. In practice, where is the "65% of the Debian archive can be built for the Hurd" figure coming from? I'm sure it can be built in theory, how much does it require source modifications?
I love how much things have progressed. I remember I used to have to set up a clean build to run while I was at school so it could be done when I got back. Now it is done within seconds.
Ha. Yeah. Remember taking a whole day or more for a clean build of the 2.4 kernel on my childhood Pentium machine. Would go to school hoping I’d come back to a completed build but it would just keep going for another day.
At this point I don’t remember the last time I’ve compiled a kernel.
I used to compile kernels on a 2012 HP quad-CPU, 80 thread machine. It would finish in a minute and a half or so. I got a ryzen 5850 to replace it, it also takes a minute and a half or so - but uses 1/4th the power at the wall. 32 threads vs 80, 250W vs 1000+W
My memory was spending as much time learning on the different options as anything else. Though, I think most of my memory was all of the config for FreeBSD. Compiling Firefox was the beast that I remember. Only thing I still compile is Emacs, and that is silly fast on modern computers.
Really, the speed of compilation is such that I understand why so many source distribution methods are as popular as they are now. Feels funny to have come to that point so effectively.
The big break (for me) in configuring the options was the very welcome addition of "make menuconfig" to replace the original "make config". As the number of supported filesystems/drivers/options increased, it could take more than an hour to get through a "make config".
I haven't built my own kernel for more than 15 years, but I probably built more than a dozen before that, each of them re-compiled upon every new release (going back to 0.98).
I understand what you're saying, but both are true.
1. Linux is too big. Even if we exclude the drivers, which are a majority of the kernel codebase, linux is still a massive kernel. Most microkernels are small enough to fit in the L3 cache, some are small enough to fit in the L2 cache. Linux, even if we could exclude the drivers, doesn't even come close. This inability to fully cache the kernel ends up negating the primary benefit that monolithic kernels have, which is performance. Linux spends more time bouncing around the cache than a modern microkernel takes to do an extra syscall.
To add to this, unless you are compiling your kernel specifically for your machine, your kernel is going to be a bloated compromise of the set of drivers that your system is most likely to see. That means that you will have dozens, if not hundreds of drivers compiled into your kernel which will never need to be used.
It's also too big in the sense that there are now far too many lines of code to be able to effectively monitor for vulnerabilites. That codebase size won't change when having a microkernel with the same number of drivers, but what will change is the ability of a single vulnerability to compromise your whole system. You have effectively compartmentalized vulnerabilities to their own address space. So in that sense, big codebases are a huge problem for monolithic kernels, but only a small problem for microkernels.
2. It will take time to write a ton of device drivers, simply because most of them aren't written yet. To that extent, Linux most definitely has an incumbent advantage. But that isn't to say that microkernels also have an advantage here. Anyone who has written a driver knows how much the ability to iterate quickly is helpful. Drivers in userspace can be written directly on the system that they will run on, with no virtualization or kernel reboots necessary, and with incredibly fast start/restart/stop. Userspace drivers are dramatically simpler to write, simpler to build, simpler to monitor, simpler to test, and simpler to distribute.
With all that being said, I definitely don't think Hurd is the future. But what could change the world is already out there but not really ready to use at the moment. One possibility would be an open-sourcing of QNX which is an amazing and incredibly mature microkernel OS, possibly the most mature in the world. If there are any bored billionaires out there reading this, please buy QNX from Blackberry and do that. Another possibility would be to put a shit ton of effort behind the SeL4 userspace, which is just too damn hard to do anything practical with at the moment.
> To add to this, unless you are compiling your kernel specifically for your machine, your kernel is going to be a bloated compromise of the set of drivers that your system is most likely to see. That means that you will have dozens, if not hundreds of drivers compiled into your kernel which will never need to be used.
I imagine there's two pools of Linux users: those that compile their own kernel, probably with only the drivers they use; and those that use distribution kernels, which have a small set of compiled in drivers, and a huge initrd with all the drivers. Neither one of those groups ends up with all of the drivers loaded into memory: the compile their own have a small set, the distro kernel people end up with only the drivers they need loaded; both groups have a relatively small kernel footprint.
Going in that configuration screen, looking up all those modules to check whether you need them, and checking / unchecked them takes so much time I would imagine some people who compile their own kernel don't bother
No, and this is what saved a lot of people's arses many times over. A lot of the CVEs for the Linux kernel turn out to only be exploitable under very specific circumstances.
> Most microkernels are small enough to fit in the L3 cache, some are small enough to fit in the L2 cache. Linux, even if we could exclude the drivers, doesn't even come close. This inability to fully cache the kernel ends up negating the primary benefit that monolithic kernels have, which is performance. Linux spends more time bouncing around the cache than a modern microkernel takes to do an extra syscall.
This makes no sense. The comparison that matters isn't kernel vs microkernel, its kernel vs microkernel plus all the userland code needed to implement system services. If my program wants to read a file and write to the network, then the code to do that has to be brought to the CPU to run before my program can finish doing that, and it doesn't matter whether that is in the kernel or userland.
> This makes no sense. The comparison that matters isn't kernel vs microkernel, its kernel vs microkernel plus all the userland code needed to implement system services.
And also, what matters for performance is the size of the "hot" code. A lot of code, both on a monolithic kernel and on the userland code implementing system services for a microkernel, is going to be "cold" code which executes rarely. This includes initialization code, shutdown code, most of the error handling code, code to react to uncommon hardware events, and so on.
> If my program wants to read a file and write to the network, then the code to do that has to be brought to the CPU to run before my program can finish doing that, and it doesn't matter whether that is in the kernel or userland.
And given that the essential complexity is the same, it's very likely that the size of the relevant code is similar.
You're right...that is the part that doesn't matter. But the kernel still has to coordinate and schedule that. The kernel has an inherent overhead for execution and context switching, and will always have some amount of code that is hot.
The reason microkernels typically benchmark on syscall (typically IPC) latency is because that is the only truly apples to oranges part that you can't compare between the two. Monolithic kernels have a single context switch, microkernels have two. But microkernels, being micro, are a lot friendlier to caches (less to load and flush), and especially so with dedicated code caches (which do not need to flush on context switch).
> Most microkernels are small enough to fit in the L3 cache
Is that important, though? As soon as you start processing any meaningful amount of data, won't your OS be evicted from the cache anyway?
> unless you are compiling your kernel specifically for your machine, your kernel is going to be a bloated compromise of the set of drivers that your system is most likely to see. That means that you will have dozens, if not hundreds of drivers compiled into your kernel which will never need to be used.
I'm not sure this is true. Device drivers are typically compiled as modules, which are only loaded into the kernel if needed. Common wisdom among Linux power users for the last decade or so has been that compiling your own kernel for any tangible performance/memory improvement is basically futile.
Are there exceptions to this that you are aware of, and can elaborate on?
> Is that important, though? As soon as you start processing any meaningful amount of data, won't your OS be evicted from the cache anyway?
Writable caches yes. However many (most?) modern processors also contain a code-only cache which can be used for OS caching without any need to flush. The raspberry pi 4 can fit many modern microkernels in their tiny immutable cache, so it gains a massive caching benefit by being small.
> Are there exceptions to this that you are aware of, and can elaborate on?
You’re probably right, I was unaware of the extent of the kernel module usage. Regardless, the smallest common kernel in use that I know about is for alpine Linux and that is still at least 100MB, which is dramatically larger than the <1MB microkernels that are typically available.
Too big for what exactly? Because it's clearly not too big to run. It's been running very well for decades, and Hurd has not.
I've known for decades that on paper, microkernels and Hurd should be superior, and I've wondered for nearly as long why then they aren't taking off. If they're so good, they should at least be thriving in some niche where that performance matters, shouldn't they?
And now I hear that even after 3 whopping decades, it still doesn't run on real hardware! Entire operating systems have been born and died in that time.
What is the problem that's making Hurd still not work?
> 2. It will take time to write a ton of device drivers, simply because most of them aren't written yet. To that extent, Linux most definitely has an incumbent advantage.
But why is Linux the incumbent when Mach and Hurd were conceived 3 years earlier?
> But that isn't to say that microkernels also have an advantage here.
I would love to believe that, but then why has that advantage not paid off for 30 years?
> With all that being said, I definitely don't think Hurd is the future.
A
Why not? And is this why nobody has been writing those drivers?
I don't mean to be shitting on Hurd, but it's been really promising for so long, and not delivering, that it's starting to feel like fusion power: always in the future, nearly there, but never quite here.
> I've known for decades that on paper, microkernels and Hurd should be superior, and I've wondered for nearly as long why then they aren't taking off. If they're so good, they should at least be thriving in some niche where that performance matters, shouldn't they?
They (microkernels) thrive in Automobiles, Aircraft, Spacecraft, Security systems (such as hardware encryption devices), Defense Munitions, Embedded Devices, Maritime devices, radar systems, and many other areas. The common thread here is that they are not just resource constrained and performance sensitive, they are also typically very specialized and mostly write-from-scratch.
That last part is the key to understanding why general purpose operating systems mostly use legacy kernels that are decades old. We want to preserve as much as we can from what came before.
> But why is Linux the incumbent when Mach and Hurd were conceived 3 years earlier?
Because Linux worked earlier. Nobody in the GNU ecosystem knew how to develop a microkernel that worked, let alone drivers for a constantly changing target OS.
> I would love to believe that, but then why has that advantage not paid off for 30 years?
Again, they have. Almost all RTOSes are microkernels, and the most popular embedded OSes are microkernels. When you're writing something from scratch, it is always going to be easier with a microkernel. Don't mistake Hurd with the concept of a microkernel. Hurd sucks because it has always sucked. It's bloated, poorly documented, relies on a very janky GNU ecosystem that has already mostly adapted to Linux out of practicality concerns, and there is no ecosystem tooling around it.
But the advantages of microkernels in general are very real. The best one out there in terms of maturity is QNX, and while practically every modern car on the planet runs on it, it's licensing pretty much precludes it from being used as a general purpose OS.
Who's used QNX in automotive for anything other than infotainment? A lot of people seem to think it's being used for vehicle control systems, but I've never been presented with a credible evidence of widespread use in production vehicles.
It's probable that QNX would underpin any future Mitsubishi Electric autonomous driving system, and more certain that it would underpin sensor integration etc. in future Mitsubishi car models.
But it's not being used there in current mainstream production.
It's certainly difficult to pick through the Blackberry QNX hype to see where it's actually headed outside of infotainment, lot's of fuzzy weasal phrasing:
BMW, Ford, GM, Honda, Mercedes-Benz, Toyota, and Volkswagen are all users of QNX’s safety-certified versions, which I would assume means more than just infotainment.
So Linux is too big for embedded systems. I completely understand that. But I was hoping they'd also be viable for general purpose computers. That's certainly what Tannenbaum argued back in the day.
Or could they work if only people would stop focusing on Hurd? Is Hurd a dead end? Or is GNU the real problem and should we abandon that?
I think Hurd is fixable from a functionality standpoint, but I think it is a dead end from a sociocultural standpoint. It’s old, boring, and has never worked well in its entire history, why would anybody think they could be the one that makes the difference? Nobody cares about it anymore, it’s the kernel that almost tanked the GNU ecosystem before it was saved by Linux.
Out of all of the microkernels out there, the one I like the most is SEL4, but the security model is so different from most OS kernels that you essentially have to program for it from the ground up. And it seems like there isn’t any momentum there either. QNX is already very mature and performant though, and it has gotten a huge boost from IoT and electric car development, and IMO all it needs is an open source license and it will eventually creep its way into general purpose OS usage.
Yes, it's old. Yes, there's only little interest. Yes, there are _still_ many technical problems.
The interesting thing here is that technical problems can be solved, and will be solved given enough time. Heck, I've heard rumors that even Windows does not crash multiple times a day anymore.
Focussing and working on what is popular will most likely create a world that is less free every year. Some people rather work on something that seems right and promises a better, freer future. Even if it's not popular (right now), even if it has a high probability of failure.
The biggest success that GNU has had is that they made it incredibly unpopular to keep source code proprietary and closed. It is no longer necessary to limit yourself to just the GNU OS in order to enjoy limitless freedom of computing.
And popularity might be a double edged sword, but double edged swords are still useful if you're careful.
Although keeping software proprietary or writing proprietary software may have become somewhat unpopular in some niches (I'm not sure it's incredible unpopular seeing how many people and institutions still use and often advocate Apple, MicroSoft, use FaceBook, WhatsApp, whatsnot...), I'm not yet convinced that many people (say more than 1%) really believe that all software should be free and act on that?
Linux IPC syscall latencies benchmark in the 10s of microseconds typically. SeL4 has worst case execution guarantees that are better than that, even counting the fact that you have to do two syscalls for every one Linux syscall. We’re talking less than a thousand cycles total, which would be less than a single microsecond.
> Syscall latency also is not the end-all-be-all of performance.
That depends on what you're doing. If you're running some digital signage display or whatever, no one cares about a missing display frame or whatever. But if you're running a car's HUD or, worse, its steering system, you absolutely need the execution time guarantees or your code won't make it past certification.
I'm not saying it's not an important space, because it is. But the majority of use cases are not that latency-sensitive. And if you're not that latency-sensitive, it's not obvious that microkernels like SeL4 and QNX are faster than Linux, for the relevant definitions of faster.
And likely it's not even close when you take into consideration the capability gap between Linux and competitors, that is to say, the "fatness" comes from legitimately useful functionality, or compatibility, that any alternate kernel may need to implement to replace Linux for its own use cases, and not because something is wrong with Linux.
Could just as well be read as the position of the goalpost gets more precisely specified for each question. The original "performance" was quite ambiguous; this is just a final specification of what was meant by the word.
I do believe there are speculative execution mitigations, yes...and from what I remember there was a significant performance impact when they were implemented, and especially so on processors without dedicated code caches.
Syscall latency is definitely not the end-all-be-all of performance, but it is all there is to compare between a monolithic kernel and a microkernel. In both cases, driver code needs to run, and that driver code can be good or shitty just like everything else.
When it comes down to it, the syscall latency that is comparable is the context switch between privileged and unprivileged mode. The holy grail of microkernels isn't to be faster than macrokernels, it is to be just as fast, but a hell of a lot more modular, usable, and secure.
Fuschia is definitely interesting but I don’t really see a lot of non-Google work being done with it and while google is worth billions, it doesn’t seem like they’re investing billions into fuschia specifically. I’d say caution is warranted but it’s certainly a possibility if there were more non-google players in the ecosystem.
how different is the Hurd driver model from Linux's? is it a straightforward but tedious process to port drivers, or does it require major rethinking? I wonder if machine translation is possible, or even LLM-assisted automatic ports as a starting point. disastrous to think about, as careful as kernel code has to be, but maybe with enough static analysis and guardrails it's doable?
It is quite different, and porting drivers from Linux would be very hard to do en masse. However, other open source kernels have drivers that are much easier to port. NetBSD, for example, has a whole host of drivers that can and are used almost unchanged in other microkernels.
Okay, so there are a handful of massive $4k+ chips that can fit the Linux kernel in the L3 cache. Meanwhile, you could fit 5 copies of the SEL4 kernel in the L2 cache of a raspberry pi.
Which is fine for a program that does essentially nothing. But once a program wants to talk to the network or disk, or display something on the screen, it needs more system services that need to come from somewhere. Can you fit all of those in the caches too?
> To add to this, unless you are compiling your kernel specifically for your machine, your kernel is going to be a bloated compromise of the set of drivers that your system is most likely to see. That means that you will have dozens, if not hundreds of drivers compiled into your kernel which will never need to be used.
These days most Linux distros build pretty much any driver as a module that can be built as one. Boot-critical modules (like NVMe drivers) are included in the initramfs so they're available before the disk is mounted.
I agree that Linux is still larger than a microkernel, but very few users have a bloated kernel in RAM due to lack of customizations.
Which distribution kernel specifically? If you're running on a VM, you get a cloud kernel in many distros, which is very stripped down for example. On other systems - the modules part still applies - how much are you actually trying to save on the kernel RAM usage? I've got a very average kernel from a distro at 20MB and initramfs at 35MB. They could be twice the size and I would never notice. I appreciate they could be smaller, but we're running a minimum of 8GB these days.
The rest is in the modules and they're not loaded unless they're actually used. The parts baked into the kernel are mostly display, storage and various buses, which you would need to have immediately loaded in Hurd anyway to load the rest of services.
It would be great if they didn't of course. But historically, I've never had issues with kernel patches. In large enough deployments you get everything rolled ahead of the publication, or care enough to run grsec and custom profiles. In smaller ones, the kernel side is far down the list of things you care about.
So yeah, in the ideal world, let's have everything isolated. For now it would be great if they worked at all.
Also... There's a bit of practical limitation to how useful the isolation is. It's cool that the FS module runs in the userspace. But if it can create a suid-equivalent file and point an arbitrary config at it, you're not gaining much.
On the topic of the Linux kernel, why is it that modules and config options are so poorly documented, often not at all? I remember when I was compiling my own kernel, many options and modules I'd just have to guess based on my hardware. I understand Torvalds to be an incredibly demanding BDFL. I'd assume he'd insist on clear helper docs for any modules that wish to merge.
You can get 32MB L2 cache on an Intel i9 13000k and maximum size of a compiled Linux Kernel appears to be around 8MB.
I am not going to pretend I have any idea because I have just googled these numbers but it seems to me that an amount of cache could be reserved for the kernel without too much of a hit to applications on what are currently high end machines.
On modern computer systems still virtual paged? I don't think it really matters if the entire OS fits in the l3 cache because if it's paged as i believe it is then the most relevant pages will end up in cache.
So even if you have a really large monokernal the parts of it that actually get used will be in cache in the parts that aren't used and won't be in cache.
Has other people stated how Michael Colonel is still going to need a lot of user modules to do most of the work that's normally in the monolithic kernel, so it'll probably end up being about the same amount of code that needs to be in cash first, not in cash. The differences is really come down to just call boundaries as I understand it
I'm very open to that debate, but then show it. Exclude the drivers from the numbers. To do otherwise feels very dishonest.
Process isolation and selinux are things that exist. You even mention it. Turns out, having complete isolation between basically everything in your system is hard. I don't see how microkernels will make that difficulty disappear?
Seven million lines without drivers. Linux is huge. I'm sure you'll move the goalposts further though, so what should I do next? Delete most stuff in arch/ and samples/ ?
Numbers obtained by running cloc 1.96 on current kernel master.
This seems to just support my criticism, though? Even without the drivers, it is still a big number, but is literally less than half the lines of code shown before? Why inflate what you show just to get an absurd comparison?
I think many are misunderstanding my criticism here. I offer it more as a way to strengthen the message than I do to question it entirely.
To that end, the only "goal post shift" I would add is to ask how many of the 17 million lines of driver code have to be done for Hurd to support hardware that would make it more relevant for a ton of users?
Probably? If you really want an apples-to-apple comparison, delete everything but x86_64 support from both Linux and Hurd. Remove sample code.
linux/net isn't strictly "drivers", but implements the base of the networking stack. That's 900k lines. Is that networking base code included with the Hurd figures? If not, delete it (or include in your comparison Hurd's base networking code).
Beyond that, this is getting a bit ridiculous. Who cares about the LoC comparisons? They're very different kernels with very different levels of maturity and number of features. I'm not even convinced you can call one "better" or "worse" based on this metric at all.
> I'm very open to that debate, but then show it. Exclude the drivers from the numbers. To do otherwise feels very dishonest.
You can ask for numbers without casting aspersions like that.
This is HN. It is something like a casual conversation. You are free to ask for numbers, other people are free to provide or not provide them, and we should be able to have this conversation without leveling accusations of dishonesty (which the word “feels” does not really temper).
I didn't say they were being dishonest, I said it feels dishonest. Consider it a critique of the message with my reasoning given.
I was actually trying to find the numbers myself, and it was surprisingly more involved than I'd care for. I didn't want to give someone else more work, but happy to see the numbers expanded. I stand by my criticism, though. It feels off. If you want to say it is justified, spend more effort justifying it.
> I didn't say they were being dishonest, I said it feels dishonest.
The phrase “it feels” is not carte blanche to say what you want.
I could say, “Someone reading this post might think that you’re an axe murderer.” Certainly not me, I don’t think you’re an axe murderer. But someone reading this post might think so. What this does is introduce a new topic of conversation—that topic is you, and whether you’re an axe murderer. I’ve done it without saying anything untrue. It is literally true, that someone reading this post might think that you’re an axe murderer. That has much the same effect as an accusation, but I’ve given you no real way to respond.
When you write “it feels”, there is an implied subject, who is feeling those feelings. That subject is you.
This form of rhetoric for criticism is silly, though. For one, you are giving no charity to the side of my conversation. For two, you have to take it to the absurd caricature of claiming that others think someone is an axe murderer to try and make your point. Literally a type of rhetorical fallacy.
I flat out feel it is dishonest, in the vein that it is cherry picked data to further support a point that they agree with. Such that, using "this is a casual conversation" as a rubrik, I absolutely call BS from people when they say stuff like this to me.
If this was a "town square debate" where the conversation is partisan and folks are trying to score points, I'd agree with your assertion a bit more. But for casual conversation specifically, I ultimately reject this view.
Now, if the poster is specifically offended, I'm more than willing to apologize on that and to clarify my point. I had no ill things to say about the poster or the main topic. Heavily critical of cherry picked data, with a justification of why.
> For two, you have to take it to the absurd caricature of claiming that others think someone is an axe murderer to try and make your point. Literally a type of rhetorical fallacy.
No, actually quite the opposite: Reductio ad absurdum is a form of logical proof, not a fallacy.
But that is the entire point of the comparison. I get that you think an apples to apples comparison is the most honest way to portray this, but the whole point is to portray that this is an apples to oranges comparison. Linux has millions of lines of code running in ring 0, a micro kernel does not. They may end up having the same lines of code for comparable total system size, but that isn’t the point of the comparison.
Process isolation actually isn’t fundamentally hard…it’s just hard on a system that wasn’t designed for it. And SELinux doesn’t do what microkernels do. Even with a tightly locked down SELinux configuration, a driver vulnerability can lead to root access. SELinux can protect your userland the same way that microkernels do, but it can’t put your drivers in userland.
Fair. I'm not a fan of apples to oranges comparisons without leaning into more of it. Especially not when the obvious driver for difference between two things is that one is old and has a ton of the code you are currently behind on writing.
I do question if process isolation isn't fundamentally hard. Separate processes for separate things entirely is not fundamentally hard. That, I agree. But, so much of what we do is integrated together. Is why early attempts to make it so that some programs can't see my whole hard drive are bonkers annoying. I specifically want access to the picture I just saved in that editing program so that I can email it.
Fair, if amusing. Hurd "predates" Linux in name only. And, if anything, this would serve as a strong piece of evidence that microkernels have a hard time getting traction.
Which brings the debate back to the argument, doubtless made many many times over the years, that there is probably a reason that microkernels have a hard time getting traction.
I get that. But it is still an unfair dig when a large chunk of the code that is being pointed at is the code that they will have to write? (Granted, they can put an easier line in the sand on how far back they go on what they support hardware wise, but still...)
I agree it is defensible. But, it is code that has to run for me to use my computer. I'm not clear that I have reason to care about the kernel distinction, at this level. Would help the defense to lean in and show legit and not theoretical examples of it.
It's not about the code existing, it's about the code being an integral part of a monolithic architecture vs. "servers" facilitating a microkernel design like hurd/mach.
But that is silly? If I have to audit the code for my system running, I would have to audit the code for each of the "servers" as well? If not, why not?
To that end, how different is it, actually? And what are the other tradeoffs?
That's the big unknown question with microkernels. It was (in the 90s) a reasonable theory that a microkernel could be much more robust and secure and easy to develop than a monolithic kernel.
It would be more robust because individual services could crash and restart. That could really work for, say, WiFi drivers. It doesn't quite work for disk drivers or the file system, since how do you even restart something without a file system?
It would be more secure because drivers would live in isolated memory spaces. So a non-critical piece like a printer driver couldn't read memory from something more critical like a file system. Part of what changed since microkernels were originally proposed is that drivers are often split into low- and high-level parts. So a printer driver in Linux consists of a standard USB or network driver in the kernel, plus a user-level driver that can be worked on like a microservice. And the WiFi driver is a low-level driver plus wpa_supplicant running at user level. The USB and network drivers are shared with critical services, so you can't easily restart them anyway.
It would be easier to develop because you can restart just the piece you're working on without rebooting the whole kernel. That's a plausible argument, but somewhat undermined by HURD taking 30 years to develop. But there were many other reasons for that.
I guess the way to convince yourself one way or another is to try writing a driver for both.
Right, I remember parts of that history. Memory protection schemes in other operating systems didn't exactly stay static, though. And a ton of the optimizations that monolithic kernels (mostly looking at windows) did went away just with the lack of need for them. Heck, at the time, Mac wasn't even a preemptive multitasking operating system.
And "drivers" could just restart is laughable with a role play of it. Ok, your wifi driver restarted. What are the protocols to get everyone caught up between that driver and your application for what messages were lost and the messages that are now arriving? This is effectively no different from any distributed application where similar things are unsurprisingly hard to achieve well.
I'll state that I think this is a laudable goal. And I'm happy to see people working on it. Would be thrilled to be shown I'm wrong.
If your WiFi driver crashes and restarts, at the minimum, I think it could be treated as if you lost network connectivity for a short time. This is a situation that applications should be able to handle anyway, since it happens all the time on laptops.
There are plenty of applications out there that just don’t respond to configuration changes gracefully. For example, if you have a music program running, and then you plug a MIDI keyboard in, is the new MIDI keyboard recognized by your music program? Maybe so, and you can use it immediately. Maybe not, and you have to restart the application.
If your MIDI driver crashes, maybe the music program doesn’t handle it gracefully, and you have to quit and relaunch the program. But that is miles better than crashing the system and rebooting.
It really depends on what all is done "in the driver," though? Since, per the application, the data may have been passed off to the driver with a successful message pass. And if I have to have secrets in the driver for it to be able to connect to access points and such, it seems dubious how protected from all of my secrets the system can be between all parties.
MIDI is actually an easy example, all told. If I unplug and replug a keyboard in, I expect it to probably not handle any persistent state of the keyboard correctly. (For fun, it is common for the "at rest" value of peddles to be discovered at connect time. Good luck with that if the driver crashes.)
> Since, per the application, the data may have been passed off to the driver with a successful message pass.
The application already knows that the data is not guaranteed to be delivered, or even sent at all. That’s just the nature of network programming—it’s inherently unreliable.
> And if I have to have secrets in the driver for it to be able to connect to access points and such, it seems dubious how protected from all of my secrets the system can be between all parties.
To make an analogy—locking your front door doesn’t protect thieves from stealing your plastic flamingoes and garden gnomes, but it does make it harder to steal the $50,000 in cash you have hidden under the mattress.
The point of isolation is to reduce the effect of failures. If you have a buggy WiFi driver, in a monolithic kernel, that could be really bad—it could even be a remotely exploitable vulnerability in the kernel itself. In other words, you have no front door, and the thieves can steal the $50,000 hidden under your mattress. If your WiFi driver is unprivileged, then the thieves have only broken through your front gate, and they can only steal your garden gnomes and plastic flamingoes. They need to combine the vulnerability with a local privilege escalation vulnerability, or be happy with the value of plastic flamingoes.
> For fun, it is common for the "at rest" value of peddles to be discovered at connect time.
The keyboard itself does this, either when it’s turned on, or through the configuration menu (or not at all). It’s not something that has anything to do with drivers or connecting the keyboard.
Applications are usually written to know that anything sent over the network could be lost. You don't usually do the same for sending to the different devices. Are you expecting retry logic in all places sending to a device?
We /could/ turn all computation into remote procedure calls. There is plenty of precedence that that will not end well. You do it where you have to. Not everywhere.
And fair point on the device learning its "off" position at startup. Though, that really leans into another point I made in another branch. That level of "isolated and can restart" is already largely accomplished by having extra compute on the devices you are connecting to. I really can't see much benefit it doing everything in the RPC paradigm.
I get the promise. I'm not buying the evidence that you can solve this by making it transparent that all things are "servers" and some are remote.
> Applications are usually written to know that anything sent over the network could be lost.
Generally they are—when you make an HTTP request, the client waits until it receives an HTTP response before it reports success.
> We /could/ turn all computation into remote procedure calls. There is plenty of precedence that that will not end well. You do it where you have to. Not everywhere.
I think you may be having some kind of a different conversation here. I don’t understand your position, and I don’t think you understand mine.
Microkernels treating every system in the machine as a "service" is literally asking developers to treat everything as a distributed system. No? Was literally a selling point early on in the literature for them.
There are good arguments for this in some environments.
> Ok, your wifi driver restarted. What are the protocols to get everyone caught up between that driver and your application for what messages were lost and the messages that are now arriving?
Doesn't fully help? Could actually be more difficult if you let the driver do the TCP ack. And you are likely going to back yourself into a situation where you need TCP between the application and the driver... Remember, at that point, it is just a message pass, as well.
There is a good article somewhere about how you have to do end to end for any of this to really work.
If your network stack is running isolated to your wifi driver (with the interface being frames to send and receive), it's fine: the network stack just sees some dropped packets the same as if something else dropped them. If your network stack with your TCP state crashes, then it's a bit trickier: the connection will likely be dropped, which requires an application-level retry, which also will generally already exist to deal with more significant network issues. I don't think you've picked a great example for this kind of problem.
I would assume that the TCP state would be part of the "networking service" that is isolated from my application. As such, I'm assuming the more complicated situation there.
That said, I don't make too big of a defense of networking being a bad choice. At large, that is literally where you have to do distributed computing anyway; so, agreed a lot of it will be covered for a lot of applications. I was trying to stick to the examples others chose as I'm not really trying to "gotcha" to anyone. My main point was honestly more about how similar that is to how we are today. If you were in a microkernel, is it any easier? Because that is the original goal post here.
I do further question why you'd want to do that for every subsystem interaction, and if you really want to have to redo all kernel context swaps and local message passes if something went wrong locally.
It can be done though: see what Windows has managed to do with graphics drivers. I've experienced a full crash of the graphics driver and windows just restarted it and kept on trucking, the only casualty being the 3D application which presumably triggered the crash. It's not just a matter of sprinkling the microkernel architecture on your system, but something like that is a prerequisite.
The servers are run in isolated address spaces like processes, taking advantage of MMU protection for more of the low-level facilities.
Ask yourself why it's safer to use FUSE filesystems on Linux when mounting untrusted block devices/image files than the in-kernel filesystem drivers and maybe it'll become clear why this is advantageous.
Or if you're familiar with containers and why that's a good thing, you can think of it as containerizing the kernel's subsystems/drivers.
This... didn't answer my question? For many that are concerned with containers and such, they also have to audit the container process code. Such that, fine, try to use that to inflate the numbers on Linux.
Pointing at literally decades of device drivers as why the size of the code is bad, while acknowledging that it will take time to write device drivers so this will work on a respectable amount of hardware just feels weird.
That all said, please don't take this as a criticism of any of these ideas. I confess seeing Hurd in the headlines gave me a smile. Is nice to see people can still work on many ideas out there. I am only questioning the "size of code bad!" right next to "it will take us a long time to replicate a large portion of the code we just pointed at."
And given what the modern Linux kernel does, alongside the power of modern systems (even embedded ones), it's also difficult to argue that the Linux kernel is too large by any stretch of the imagination.
my entire kernel, including all drivers needed for my system except the nvidia blob is 11MB - 10876160 bytes. i don't optimize for size, necessarily, i'm sure i could get it down a lot more if i disabled most of the "default enabled" stuff in a modern kernel that assures it will boot on a majority of systems.
LoC is a metric for manageability of the code base and compile time, and you might need other metrics to judge those two factors.
For real world use wheen comparing OS you would generally go for other metrics like resource usage, multi threading bottlenecks, throughput of network packet and their processing, context switches(or equivalent) per second, and dozens of other things that would be paragraphs in length before you get to LoC.
Windows had the lead until about 15yrs ago when suddenly iPhone arrived and it propelled apple/Mac (and by association Linux) back into the game.
in recent years the rise in popularity of CLI, microservices (APIs for everything) and remote working/collaborating is indicative of a market shift, away from monolithic, centralized systems and providers (Cloud aside).
Security + Privacy are more so becoming inseparable, for users all around (private, business, orgs, gov).
I particularly like their concept of user-space servers and translators [1] [2]
[1] A translator is simply a normal program acting as an object server and participating in the Hurd's distributed virtual file system.
I look at Hurd and how it took this long for it to boot X, and I look at Redox and its booting and pretty active. Hurd died the day Linux went GPLv2. It's a shame too, I trust the Redox design in every other regard.
Someday it'll have the fault tolerance of OpenVMS, where it'll somehow keep running when the hardware dies.
The concept of microkernels is cool for security ... the only thing cooler in OSes is maybe unikernels :P
And certainly the time is ripe since we have such powerful and capable machines even in the pockets of our pants ... we can certainly waste a little bit of resources to work with more secure layers of abstraction ... yes?
But Hurd has taken so long, I feel like Google Fuschia might dive in and capture everyone's imagination with a more modern and practical implementation of the concept. To be clear ... neither Hurd nor Fuschia are really practical today ... I just feel like its more likely Google might throw a few hundred million at the project if it pans out in the few places its currently being field tested (like in Google Home devices).
The drivers aren't part of the microkernel and run with limited privilege. So, yeah, OK, if you wrote all those drivers you'd have a lot of code, but not all of it would have total control of the system. You can't really make a direct comparison.
Linux has a hell of a lot of system calls and weird bells and whistles in non-driver code, too.
I also recall it having some ridiculously low limit for partitions, like 1GB or something.
Apparently because it mmaps the entire disk, and under 32 bit CPUs there's not enough address space.
Which is a ridiculous technical limitation. You could have bigger disks than that by the mid 90s.
Come think of it, my Ryzen 9 3950X supports 43 bits of address space which works out to 8TB. So if that limit applies, even the 64 bit version would be limited on modern hardware.
48-bit virtual addresses are the most common in use today. All AMD, ARM64 processors, and most of Intel's. Only recent Intel chips support PML5 (5-level paging), giving them 57-bits of virtual address space. There are no 64-bit processors that can use a full 64-bits of virtual address space.
I’m surprised to see that Mach is still the microkernel for Hurd. When I last (very casually) followed Hurd development two decades ago, Mach was generally regarded as obsolete and there were hopes to base Hurd on a new microkernel like seL4.
HURD (the parts that aren't the rest of the GNU OS) is mainly a set of servers for Mach. These are closely coupled to how mach handles IPC, how it handles virtual memory, etc. Apparently, there were also shortcomings in L4 itself, or at least with respect to what HURD wants to do with its microkernel: https://www.gnu.org/software/hurd/history/port_to_another_mi...
> Apparently, there were also shortcomings in L4 itself, or at least with respect to what HURD wants to do with its microkernel
Yes, that was the issue as I recall. But seL4 is an excellent, secure high-performance microkernel. If something is painful to do in L4, it will likely not be faster or more secure running under any other microkernel, and so you should arguably question the wisdom of what you're trying to do.
Oh, interesting, people created a GNU clone of Mach, removing the licensing problem that all but killed the project early on its life.
For the ones not in the know, Mach is an OS designed after the idea of "the network is your environment, not the computer" where it should make little difference if the resources you are accessing is on your computer or not. And "resource" here is really generic, meaning things like files, login information, printers and other periferals, CPU, whatever.
For some reason (maybe related to costs and licensing), people never adopted the idea... and insisted on reimplementing it with unreliable hacks and lots and lots of problems on top of every other OS out there instead of just having it on the OS itself.
> an OS designed after the idea of "the network is your environment, not the computer" where it should make little difference if the resources you are accessing is on your computer or not. [..] For some reason (maybe related to costs and licensing), people never adopted the idea...
I personally think it's a pipe dream, and the way history worked out seems to confirm that.
Truly transparent networking never really worked out anywhere. The better RPC solutions in use, for example, make it very obvious that an RPC is an RPC, instead of looking like a local function call. In file transfer, it has been common to e.g. replace NFS with something HTTP based for quite some time. "Cloud" file systems seem to operate at a much higher layer, preferring external syncing and special high level APIs with only some actual OS support sprinkled in.
For Operating Systems, a lot of Mach breaks down when you want to do things fast and securely.
It's a testament to APIs better being shaped by locality. Roughly and informally spoken, the closer you are to the actual CPU, the more "lightweight" and "direct" your API can and should be. The further you move away, the more resilient you need to become, and the more control and insight you need to give the caller about the actual transport.
To pick two very real extremes as an example: When writing to a register on a local bus, you often just assume it will work. If it doesn't, a panic is sensible (sometimes even worse, like a lockup leading to a watchdog timeout). When trying to invoke a function on another server, obviously that's not acceptable. Then you want to be able to timeout, retry, inspect transport failures, fall back to other servers, configure endpoints, be picky and explicit about payload (and result), and so on and so forth.
The immense cruft necessary for the latter case becomes unnecessary and expensive the more local you are. It affects security, and can even pose chicken and egg problems.
> For the ones not in the know, Mach is an OS designed after the idea of "the network is your environment, not the computer" where it should make little difference if the resources you are accessing is on your computer or not. And "resource" here is really generic, meaning things like files, login information, printers and other periferals, CPU, whatever. For some reason (maybe related to costs and licensing), people never adopted the idea
To me, the reason is obvious: what happens when someone unplugs the network cable? This is #1 in the list of distributed computing fallacies (https://en.wikipedia.org/wiki/Fallacies_of_distributed_compu...): "the network is reliable". The other fallacies on that list might also be relevant.
> what happens when someone unplugs the network cable?
About the same thing that happens when you unplug your corporate Windows machine. You only have cached and local resources.
People insist on using all of that functionality. People also insist on implementing it by hacks everywhere with nothing talking with each other and each part failing for its own reasons.
> For some reason (maybe related to costs and licensing), people never adopted the idea
The network is relatively slow and unreliable. Whenever you access a network resource error handling, asynchronous operations and possible inconsistencies have to be the first things you deal with.
MacOS XNU is based on OSFMK which was also used by Tru64 and few others, and sometimes called "Mach 3.5" IIRC. One of the major differences was that it embedded the BSD server into kernel space.
Even rms gave up on Hurd and it stopped being a core priority of the GNU Project a long time ago. The current maintainers/developers are doing it as a solo hobby. Which is fine, but that's what you should keep in mind as far as support if you decide to use it.
Even in the noncommercial world, Hurd's gone precisely nowhere. RedoxOS is a toy and had a GUI within a year or so. Brutal got in within two. SerenityOS not only built a GUI but the beginnings of the first greenfield web browser to gain any semblance of modern standards support in the past several decades.
Honestly, what's Hurd doing wrong to flounder so hard?
Also, given its velocity, 'strike back' is totally the wrong phrase. 'Strike back' implies speed and/or alacrity, neither of which gnu/hurd possesses in any appreciable quantity.
Ah, sixels, I forgot about those. I was going to guess it implemented a modified display of a pixmap or something: https://en.wikipedia.org/wiki/X_PixMap
Also in that same screenshot, hurd used to drop you into a shell as the nobody user where you could run the login binary... Curious if that was changed as part of debian, or changed for some other reason.
Kinda wonder if the best approach for them at this point would be to target RISC-V and worry only really about running in a hypervisor, or very narrowly targeted open hardware, instead of futzing with implementing a pile of device drivers. Make it useful in that environment, and then go from there.
Hell, wouldn't it be cool if there was an official GNU GPL'd RISC-V board, running GNU Hurd?
I used to idle in the hurd irc channel and there was definitely someone working on smp support, but it was just one person's pet project apparently. They seemed to have things working in an experimental setting, but I don't think anything landed upstream.
It was clear there's a severe lack of manpower on the project. I think it'd have to be rewritten in rust or something hip to get new blood today.
It's very cool, but the MIT license on that means it will never fit the niche (mainly ideological) that the Hurd was aiming at.
I actually think GPL is key in long-term adoption and is part of at least the early part of Linux's success. To prevent fragmentation. To coax commercial entities to contribute. And to generally encourage community development, rather than forks (since forks require distributing source anyways).
But others disagree, and these days Apache/MIT type licenses proliferate.
I'm not convinced that the license is the biggest motivator today for vendors getting code to upstream Linux. Look at LLVM - Sony has spent significant effort landing support for PlayStation targets there, the license doesn't require it, but it means they aren't chasing such a moving goalpost with some internal tree.
When they don't get the code upstream, it's usually because they know the code doesn't pass the stringent requirements for upstreaming and don't want to get embarrassed during review.
What you do get in that case is code dumps from those companies so someone interested at the very least does not have to reverse engineer the driver to rewrite it and get it accepted upstream.
Weird that a lack of systemd was called out as a problem. Your pid1 can be any of a myriad of tools, systemd is just the (current) dominator. Only a few years ago I was working on RHEL machines without any systemd to speak of.
Agree, systemd is not the last word in init systems.
There are use-cases where linux/whatever is used to run a single system across a cluster of hosts. For this, you need a scheduler to dispatch across a set of machines.
There is room to debate whether init should happen at the system level (driven by OS tooling), or at the application level (not driven by OS tooling).
Systemd is bound by single-host assumptions. Hence, systemd is either inadequate (OS tooling) or else too complicated (application driven).
If you wanted to do something in the spirit of systemd (OS tooling), but which was suitable for clusters, the scheduling function would live as a consensus across a grid of hosts. Hosts would have a simple init that joined that consensus at boot and which acted as an agent for the init consensus.
This would scale down to all the use-cases systemd currently covers - you could have a consensus of one.
{kind=link}
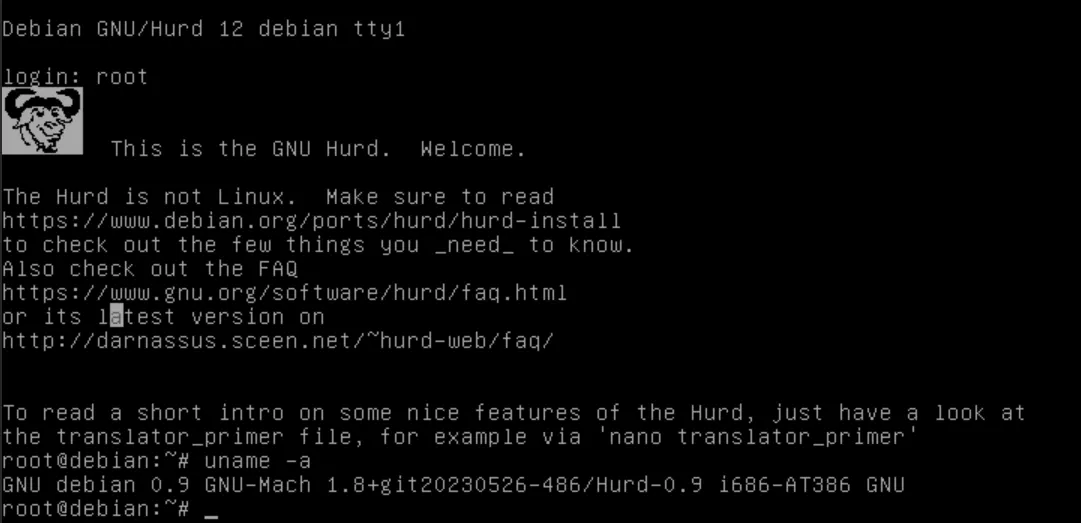{kind=link}
What does that look like for Hurd?