Do I understand it correctly, that an LLMs are neural networks which only ever output a single "token", which is a short string of a few chars? And then the whole input plus that output is fed back into the NN to produce the next token?
So if you ask ChatGPT "Describe Berlin", what happens is that the NN is called 6 times with these inputs:
Input: Describe Berlin.
Outpu: Berlin
Input: Describe Berlin. Berlin
Outpu: is
Input: Describe Berlin. Berlin is
Outpu: a
Input: Describe Berlin. Berlin is a
Outpu: nice
Input: Describe Berlin. Berlin is a nice
Outpu: city
Input: Describe Berlin. Berlin is a nice city
Outpu: .
One addition is that they don't return just one token, but the probabilities for each token.
You could then greedily take the most probable single token, or select a bit more randomly (that's where temperature comes in) in a few different ways. You can do better still by exploring a few of the possible top options to select a high probability chain of tokens. That's because the most probable next token may not be the start of the most probable sequence of tokens. That's called beam search.
Other than that, things like gpt can't go back and edit what they've outputted, so it's much more like listening to someone talk from the top of their head and writing down everything they say. They can say something wrong, followed by correcting themselves. The fact that the output becomes the input makes it much more obvious why "lets think through step by step" helps them reason, they can do simpler things then see the simpler steps they've already done to answer the more complex parts.
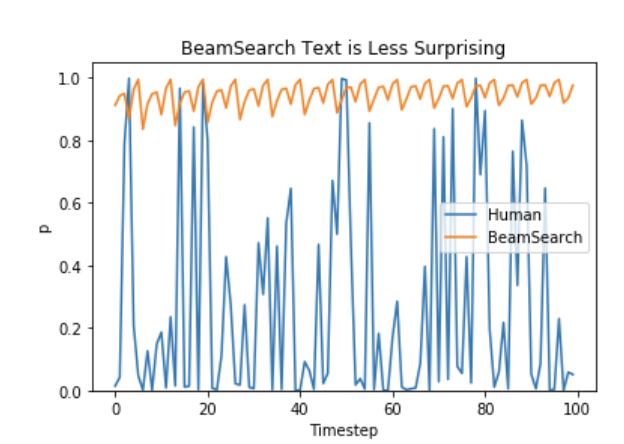
The probabilities are fun (and ability to manipulate/mask/logit bias them), but small nit pick: Beam search isn't popular because it results in less human like text and takes more processing time, as a concept it sounds great in theory, but it's generally worked worse in practise compared to the next token with temperature, and results in text that is not human like, the gap is larger with larger models too, it doesn't get better:
The way most GPT models are set up, they don't edit, but there was a lot of work (made redundant by OpenAI) on using gap filling tasks (masking) to iteratively improve or construct or otherwise edit and formulate logic using the encoder-decoder models of yesteryear - in many ways, I think it would have been more exciting if that approach powered the likes of 'think step-by-step' results.
Oh interesting thank you, I thought they were using it.
There's nice stuff you can do with the probabilities, a shame it's more restricted with the chat models. I hope they add some lightweight thing you could pass with your request to constrain the response.
That's how autoregressive LLMs work. GPTs are autoregressive, but it's not the only way an LLM can work. You can also have other types of LLM, like diffusion based, other types should also be possible.
At the moment, image models are mostly diffusion models while LLMs are mostly autoregressive.
With a few other examples. Google has for example created both an autoregressive image model, Parti, and a diffusion model, Imagen.
Could you or someone else kindly explain how it works for diffusion based LLMs, based on the style of GP? What happens for instance, if I give as input the prompt 'Describe Berlin' or maybe the more fitting 'Berlin city on a sunny day'?
Many diffusion based approaches have been tried for language. I like a diffusion style that goes a bit like this:
* empty string
* Berlin
* Berlin city
* Berlin is a city
* Berlin is a city in Germany
* Berlin is the capital of Germany
* Berlin is the capital of Germany, located in the North East.
* Berlin is the capital. It is located in the North East of Germany.
* Berlin is the populous capital city of Germany. It is in the North East of Germany, by the river Spree.
* Berlin is the capital city of Germany with 3.6 million inhabitants. It is located in the North East of Germany. It's centred on the river Spree.
...
At every step, the diffusion slightly rephrases to add more information content and detail to that of the previous level, by inserting, replacing and deleting tokens.
It is usually more costly to sample from these diffusion style models (which is not the case for diffusion for images, as unlike text, images tend to have a fixed size). But, one might imagine this approach to scale up to generate texts of arbitrary lengths. Just keep on adding more and more detail on your text, and you'll end up with a book or a coherent novel.
I haven't studied diffusion methods in great detail, but my simplistic ELI5 understanding goes something like: during training you gradually add noise to an image, step by step, and then the model learns how to remove the noise at each step. Adding noise to an image is, of course, very easy to do.
But for this approach adding "noise" would be much less straightforward, wouldn't it? You'd have to have some way to work out how to take "Berlin is the capital city of Germany with ..." down to an empty string in a way that marginally removes detail. For some passages this could be rather difficult to do. I feel like gathering training data would be a huge trial here.
Yes, the noising-denoising steps in this approach are summarizing-extending. The idea is that (unlike images) any piece of text lies somewhere on the length scale, like a fractal. You could take the whole text and treat it as a large scale object, or take shorter sentences and treat them on the short scale. What you are right in, is that you need a dataset of things being described twice. Like abstracts and papers, or messages and tldr's.
Another approach I've seen suggested is to start with what's essentially a randomly initialized embedding vector and have a way to turn any embedding vector into text, then what you'd do is diffuse the embedding vector for a number of steps before turning it into text at the end. This is kinda similar to what stable diffusion does with images, but is a bit more tricky to get to work well with text than pixels.
> but is a bit more tricky to get to work well with text than pixels
Interesting. Can't you just start with 4K of randomly assigned tokens and tweak it until it's right (including the tokens for EOF), like they do for images where they start with noise and move towards an image?
This is not my corner of DL research, but my understanding is that pixel noise is far more acceptable in a e.g. 1084 x 1084 canvas than it is when dealing with a sentence of 36 words.
I think you'd start out with gibberish and at each step the output would become more refined, so first you'd maybe see scrambled words emblematic of Berlin, which would then eventually synthesize into a sentence. I think you'd have a fixed length of text, with maybe some way for the model to mark some of it as truncated.
Basically, yes! There are some technical quibbles (tokens don't line up to words, there's recent research on how to make LLMs stateful so they don't need to pass back the entire conversation for every token but can simply initialise to a remembered state), but this is basically correct as to what LLMs are mechanically doing.
The really exciting stuff is how they're doing that! Research into that question is generally called interpretability, and it's probably what I'm most interested in at the moment.
> recent research on how to make LLMs stateful so they don't need to pass back the entire conversation for every token but can simply initialise to a remembered state
I’m very curious about the insights that will give us in to LLMs. My initial instinct is that it won’t work unless you have essentially the entire state remembered since each “point” in the LLM can lead anywhere. I’m imagining an experiment where the task is “Get a person who’s never been to this city before from point X to point Y without describing the destination and while providing as little information as possible”. Giving them the full map with directions is the equivalent to giving the LLM the full previous conversation.
Intuitively there is low-hanging fruit (just provide the directions of single optimized route), but it feels like it gets chaotic quite quickly after that. How many steps could you leave out of turn-by-turn directions before the person is hopelessly lost?
This is based on my current understanding of LLMs so YMMV, but I’m definitely curious about ways we can start from a remembered state.
It's already being implemented into the OpenAI API to reduce per-token API costs. It's not as complicated as I think you're envisioning, you just take the current state in memory of the model at a given token, and then put it in storage when you want to suspend or share the conversation. When you want to continue from that point in the conversation, you just load the state into memory and after inputting your next prompt it works normally. Think of it more like Quick Resume from the Xbox technology stack or the way save states work in gaming emulators.
Those are solid analogies, thank you. I can see how that would work and also a little disappointed because it doesn’t need to give us any additional insight in to LLMs themselves.
We don't now for sure, which is why it's so interesting to research! There are some tantalising hints though, for example the OthelloGPT results (here: https://thegradient.pub/othello/) which show that LLMs can form internal world models and then use them in inference to make decisions. Another interesting result is this one (https://www.nature.com/articles/s42003-022-03036-1), which shows that neuronal activations in some parts of the human brain linearly map to neuronal activations in deep learning models when they are both doing the same task; this doesn't tell us anything about how either is doing what they are doing, but it does suggest that the human brain and LLMs may be doing a similar thing to achieve the same end result. We definitely need a lot more research before we can say anything definitive about this question, but there are a bunch of useful research directions that AI and neuroscience researchers are pursuing.
> neuronal activations in some parts of the human brain linearly map to...
Holy.shi..
As I have been observing the ways AI struggles and the ways it produces output, I’ve had this growing suspicion that LLMs have been somehow showing us things about the human brain, but it wasn’t until this moment that I had any validation of the theory.
If you think about the attention mechanism in LLMs, it may not work the same way as the brain, but there should be some functionality of the brain that also deals with attention. And if you think about that, you might also think that attention has some role in consciousness: you need to pay attention to things to be aware of them, and you need awareness of the self for consciousness, etc...
With LLAMA at least, not just past tokens, but also past states for each layer and each token. So LLama has information not just on the word "Berlin", but also on why it outputted "Berlin".
Yes. "What is the most probable next word given the text so far" is the standard 'language modeling' task from classical NLP where it was done before using Markov chains and n-grams. RNNs then transformers and huge amounts of training data made them output what we see now, versus coherent but otherwise not very impressive text 10 years ago. The large contexts of current models made it possible to generate valid code where you need to remember to close a bracket opened 200 tokens before.
Yes, in the same sense a modern digital camera is a glorified photodiode. In both cases, light comes in, voltage comes out, and we can use it to count how much light came in.
The tokenization algorithms I encountered all had around 50000 tokens, which fits nicely into (and makes good use of) a 16-bit number. Is this just a coincidence or does it have advantages for the token to be a 16-bit representable number?
Are you sure this is ChatGPT? If so, which version? I was under the impression that it's much better. Even the tiny 2.8B parameter LLM (fine tuned RedPajama-INCITE-Chat-3B) in my offline LLM app seems to do better (pardon the shameless plug!).
> Human: Describe Berlin
> Bot: Berlin is a city in Germany. It has been the capital of Germany since 1871 and it's also known as "the city that never sleeps".
Yes. The actual output is all the tokens and a probability for each. You can pick the highest or take one randomly using those probabilities. Depends how creative or deterministic you want it to be.
Exactly. A temperature of 0 means you always pick the highest probability token (i.e. the "max" function), while a temperature of 1 means you randomly pick a token according to their given probability. Values in between are also possible.
However, it's important to note that the numbers which the models returns for the next tokens can only be interpreted as probabilities for foundation models. For fine-tuned models (instruction SL, RLHF) the numbers represent how good the model judges the next token to be. This also leads to a phenomenon called mode collapse.
{kind=link}
So if you ask ChatGPT "Describe Berlin", what happens is that the NN is called 6 times with these inputs:
ChatGPT's answer: Is that how LLMs work?