This article describes positional encodings based on several sine waves with different frequencies, but I've also seen positional "embeddings" used, where the position (the position is an integer value) is used to select an differentiable embedding from an embedding table. Thus, the model learns its own positional encoding. Does anyone know how these compare?
I've also wondered why we add the positional encoding to the value, rather than concatenating them?
Also, the terms encoding, embedding, projection, and others are all starting to sound the same to me. I'm not sure exactly what the difference is. Linear projections start to look like embeddings start to look like encodings start to look like projections, etc. I guess that's just the nature of linear algebra? It's all the same? The data is the computation, and the computation is the data. Numbers in, numbers out, and if the wrong numbers come out then God help you.
I digress. Is there a distinction between encoding, embedding, and projection I should be aware of?
I recently read in "The Little Learner" book that finding the right parameters is learning. That's the point. Everything we do in deep learning is focused on choosing the right sequence of numbers and we call those numbers parameters. Every parameter has a specific role in our model. Parameters are our choice, those are the nobs that we (as a personified machine learning algorithm) get to adjust. Ever since then the word "parameters" has been much more meaningful to me. I'm hoping for similar clarity with these other words.
This is a great set of comments/questions! To try and answer this a bit briefly:
The input string is tokenized into a sequence of token indices (integers) as the first step of processing the input. For example, "Hello World" is tokenized to:
[15496, 2159]
The first step in a transformer network is to embed the tokens. Each token index is mapped to a (learned or fixed) embedding (a vector of floats) via the embeddings table. The Embeddings module from PyTorch is commonly used. After mapping, the matrix of embeddings will look something like:
where the number of columns is the model dimension.
A single transformer block takes a matrix of embeddings and transforms them to a matrix of identical dimensions. An important property of the block is that if you reorder the rows of the matrix (which can be done by reordering the input tokens), the output will be reordered but otherwise identical too. (The formal name for this is permutation equivariance).
In problems related to language it seems inappropriate to have the order of tokens not matter, so to solve for this we need to adjust the embeddings of the tokens initially based on their position.
There are a few common ways you might see this done, but they broadly work by assigning fixed or learned embeddings to each position in the input token sequence. These embeddings can be added to our matrix above so that the first row gets the embedding for the first position added to it, the second row gets the embedding for the second position, and so on. Now if the tokens are reordered, the combined embedding matrix will not be the same. Alternatively, these embeddings can be concatenated horizontally to our matrix: this guarantees the positional information is kept entirely separate from the linguistic (at the cost of having a larger model dimension).
I put together this repository at the end of last year to better help visualize the internals of a transformer block when applied to a toy problem: https://github.com/rstebbing/workshop/tree/main/experiments/.... It is not super long, and the point is to try and better distinguish between the quantities you referred to by seeing them (which is possible when embeddings are in a low dimension).
> Alternatively, these embeddings can be concatenated horizontally to our matrix: this guarantees the positional information is kept entirely separate from the linguistic (at the cost of having a larger model dimension).
Yes, the entire description is helpful, but I especially appreciate this validation that concatenating the position encoding is a valid option.
I've been thinking a lot about aggregation functions, usually summation since it's the most basic aggregation function. After adding the token embedding and the positional encoding together, it seems information has been lost, because the resulting sum cannot be separated back into the original values. And yet, that seems to be what they do in most transformers, so it must be worth the trade-off.
It reminds me of being a kid, when you first realize that zipping a file produces a smaller file and you think "well, what if I zip the zip file?" At first you wonder if you can eventually compress everything down to a single byte. I wonder the same with aggregation / summation, "if I can add the position to the embedding, and things still work, can I just keep adding things together until I have a single number?" Obviously there are some limits, but I'm not sure where those are. Maybe nobody knows? I'm hoping to study linear algebra more and perhaps I will find some answers there?
One thing to bear in mind is that these embedding vectors are high dimensional, so that it is entirely possible that the token embedding and position embedding are near-orthogonal to one another. As a result, information isn't necessarily lost.
The information might be formally lost for the given token, but remember that transformers train on huge amounts of data.
The (absolute) positional encoding is an arbitrary but fixed bias (push into some direction). The word "cat" at position 2 is pushed into the 2-direction. This "cat" might be different from a "cat at position 3, such that the model can learn about this distinction.
Nevertheless, the model could also still learn to keep "cats" at all positions together, for instance such "cats" are more similar to "cats" than to "dogs" at any position.
More importantly, for some words, the model might learn that a word at the beginning of the sequence should have an entirely different meaning than the same word at the end of the sequence.
In other words, since the embeddings are a free parameter to be learned (usually both as embeddings, and weight-tied in the head), there isn't any loss in flexbility. Rather, the model can learn how much mixing is required or whether the information added by the positional embedding should be seperable (for instance by making embeddings linearly independent otherwise)
If you concat, you carry along an otherwise useless and static dimension, and mixing it into the embeddings would be the very first thing the model learns in layer 1.
> The input string is tokenized into a sequence of token indices (integers)
How is this tokenization done? Sometimes a single word can be two tokens. My understanding is that the token indices are also learned, but by whom? The same transformer? Another neural network?
The tokenization is done by the tokenizer which can be thought of as just a function that maps strings to integers before the neural network. Tokenizers can be hand-specified or learned, but in either case this is typically done separately from training the model. It is also less frequently necessary unless you are dealing with an entirely new input type/language.
> I recently read in "The Little Learner" book that finding the right parameters is learning. That's the point. Everything we do in deep learning is focused on choosing the right sequence of numbers and we call those numbers parameters. Every parameter has a specific role in our model. Parameters are our choice, those are the nobs that we (as a personified machine learning algorithm) get to adjust.
Be careful not to mistake parameters for hyperparameters.
- Parameters are the result of the training phase, as you mentioned. They start with random values and are discovered by the training algorithm;
- Hyperparameters, on the other hand, are the knobs you tweak to make the training process arrive at the "right" parameters. You can think of them as meta-parameters;
Also, it is important to think on the ML architecture - transformers, neural networks, random forests and so on - as the parameters change completely depending on which one you're using.
Yes, hyper-parameters are parameters about the parameters. Parameters we get to choose which control the parameters that the learning algorithm chooses.
The other set of data the book called "arguments", which is the term they use to describe the data you are training on. That seems like an unnecessarily confusing term, and I haven't heard it anywhere else.
I didn't learn anything truly new in all this, but it helped me sort my own thoughts to realize there is data, parameters, and hyperparameters. Data comes from the world and we cannot change it. Parameters are chosen by us indirectly through the learning algorithm, they are the most important outcome of successful learning. Hyperparameters are chosen by us directly and control the model and learning algorithm, and the resulting parameters.
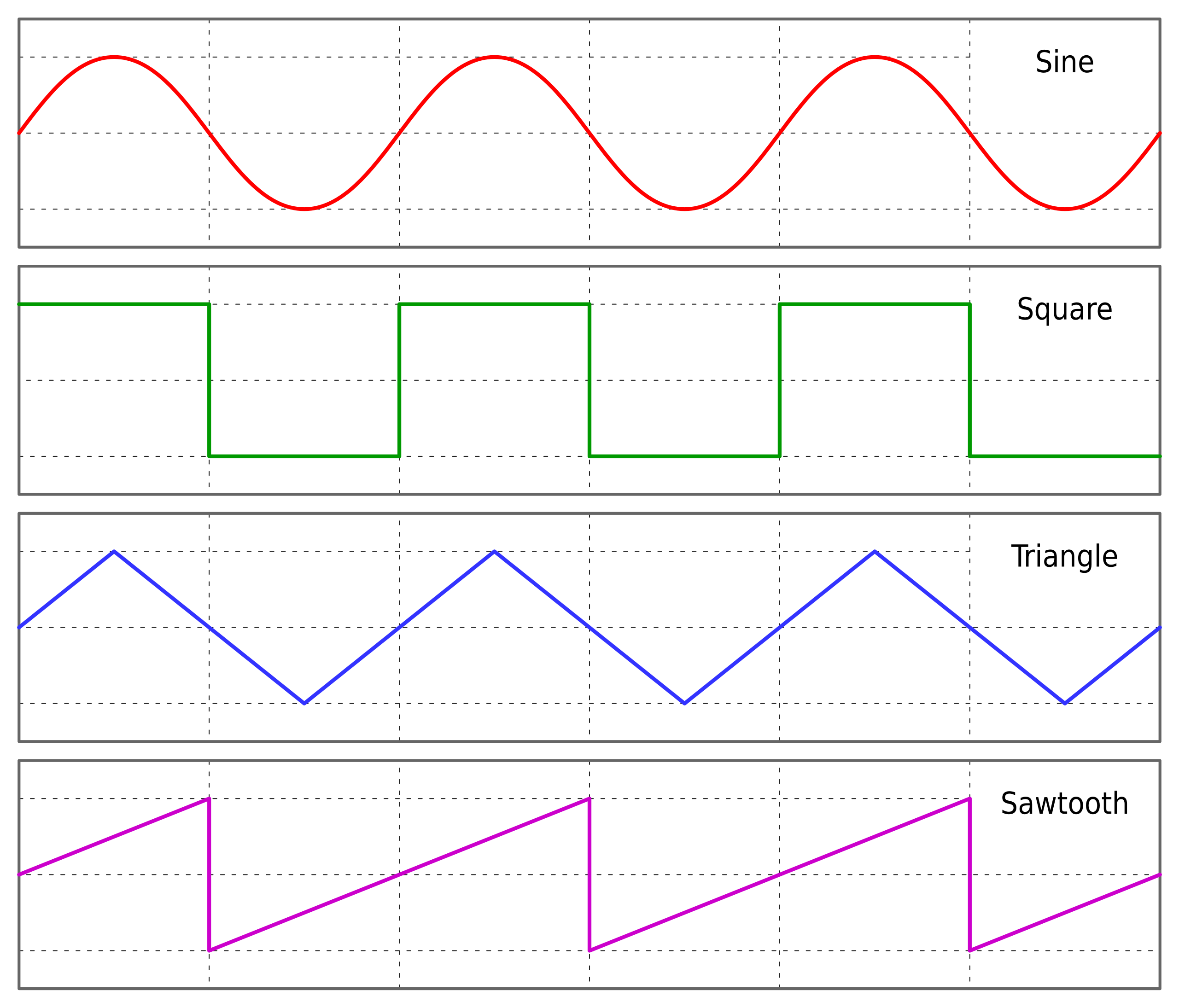
What I don't understand about positional encoding is why use sine waves at all? Sine waves have a weird property of "accelerating" and "decelerating," such that the distance between two points that are linearly the same distance apart in a sentence would result in two very different positional encodings relative to one another, just arbitrarily dependent on where they were in the curve. I'm sure this is somewhat counteracted by the fact that you have lots of these sine waves offset and at different frequencies, but it still seems like an unnecessary feature.
Wouldn't the positional encoding be better served by encoding to positions on a triangle waveform like this:
Could still do all of the same tricks of overlaying waves of different frequencies, but let the words be much more linearly related to one another. I suspect the function to plot to a wave like this is something like a modulus operation, where you adjust the modulus to produce different frequencies. And a normal modulus would get you something like the "sawtooth" graph, but if you did it so that you could determine if you were in an even or an odd period of the modulus, then you 1 - v the even ones and you'd get something like a triangle wave.
You might be misunderstanding the use of sin-cos in early positional embeddings. The waves are shifted such that each position gets a unique positional encoding. These encodings are not relative in distance to other positions, they are at best ordinal. They are meant to provide the same flexibility for the model as absolute positional encoding that are learned (so, position=2 always gets the same encoding) - which is what they achieve.
The matter of learning about distances between positions is left up to the later stages of the model.
This differs from the much more modern approach of relative positional embeddings, for instance Alibi or Rotary Embeddings.
These I think fit your intuition much better, as they seek to encode relative distances between tokens correctly.
I'm sure there's an even better positional encoding that can get around the ugly feature that both triangle and sine waves have of having distinct points where they "change direction." I suspect there's a way around this by sampling values from a 2 dimensional space while moving in a circle, something like that.
> such that the distance between two points that are linearly the same distance apart in a sentence would result in two very different positional encodings relative to one another, just arbitrarily dependent on where they were in the curve. I'm sure this is somewhat counteracted by the fact that you have lots of these sine waves offset and at different frequencies,
Relative distances in a sentence are actually maintained well by the sine encoding - better than they would by a triangle wave.
Think of encoding position as two waves, sin & cos. The pair as a vector has constant magnitude (Pythagoras). The size is independent of position. Two positions encoded as two sin & cos vectors have a difference vector which is also constant magnitude, so relative position's size is independent of absolute position too.
Position is encoded in the rotation of that pair around a circle. When embedded into high-dimensional model space by a linear map, that pair becomes an ellipse in some 2d plane whose orientation depends on the map. Other features, ie the token values, translate the centre of that ellipse but not its orientation. So the model is able to control how much weight to give position independent of position but dependent on token by translating the embedding vector to move the centre of the position encoding ellipse close to the origin in model space (by a translation determined by token), then giving greater or lesser weight to the subspace which spans that ellipse, ie the subspace of the orientation of the 2d plane. At the same time the model is able to map the ellipse to a circle in a standard orientation, and then particular patterns of relative positions of tokens within a sentence are rotationally invariant in that subspace of the mapped model space, as well as slight variations in the positions mapping to nearby points in the mapped model space. As with token-dependent model space translation, token- or position-dependent model-space rotation allows relative position patterns to be treated approximately independent of absolute position.
Add more sine waves to the mix and you get higher-dimension ellipsoids and subspaces, but the same principles apply. More tokens combine information though, so eg producing values that depend on patterns of relative positions of more than two tokens.
Crucially, all the maps just mention are affine maps, linear maps using a matrix plus bias. So the methods of linear algebra learned at high school (ie matrix and vector operations) apply, and maps easily combine multiple operations into one by matrix multiplication, just like in computer graphics. However, token-dependent and position-dependent (absolute or relative) selection of which maps, or actually weighted combinations of selections, is not linear. That's where the neural network non-linearities come in, and therefore multiple model layers because maps have to be selected then applied in the next layer.
Triangle waves don't have the same mapped constant vector magnitude and rotational invariance properties as combinations of sine waves. The model network could learn to accommodate the shapes of triangle wave induced subspaces, but it would place greater load on the model network due to being a less natural fit to combinations of affine maps. The greater load would probably result in more position-dependent artifacts and lower quality for a given model size. Similar to the difference between convolutional networks for image recognition versus old-school networks not using convolution.
An early explainer of transformers, which is a quicker read, that I found very useful when they were still new to me, is The Illustrated Transformer[1], by Jay Alammar.
A more recent academic but high-level explanation of transformers, very good for detail on the different flow flavors (e.g. encoder-decoder vs decoder only), is Formal Algorithms for Transformers[2], from DeepMind.
The Illustrated Transformer is fantastic, but I would suggest that those going into it really should read the previous articles in the series to get a foundation to understand it more, plus later articles that go into GPT and BERT, here's the list:
I remember looking into this article. It was really helpful for me to understand transformers. Although the OP's article is detailed, this one is concise. Here's the link: https://blue-season.github.io/transformer-in-5-minutes
I would also recommend Pascal Poupart's talk [1] on Attention and Transformers. Doesn't seem to be cited often, but its quite well done and seeing him work out some of the details using chalk and board is very reassuring.
A little understand would give you why certain prompts work or don’t work. A high level should do. It could help you make better prompts or trouble shoot, although you don’t need it for 80% of the cases
besides everything that was mentioned here, what made it finally click for me early in my journey was running through this excellent tutorial by Peter Bloem multiple times https://peterbloem.nl/blog/transformers highly recommend
so I’m on the same journey of trying to teach myself ML and I do find most of the resources go over things very quickly and leave a lot you to figure out yourself.
Having had a quick look at this one, it looks very beginner, friendly, and also very careful to explain things slowly, so I will definitely added to my reading list.
Ultimately because it’s such a hot topic the “market” is flooded with people that want to crank out content without understanding what they’re talking about.
Can somebody explain to me the sinus wave positional encoding thing? The naïve approach would be to just add number indices to the tokens, wouldn’t it?
- It should output a unique encoding for each time-step (word’s position in a sentence)
- Distance between any two time-steps should be consistent across sentences with different lengths.
- Our model should generalize to longer sentences without any efforts. Its values should be bounded.
- It must be deterministic.
Your example contradicts the 'values should be bounded' criterion as it generalizes to longer sentences.
I'm no expert, but I think it's so that the model can learn the relative position wrt other tokens.
They use indices for models like vision transformers with a fixed number of patches but for variable length context I think it's more beneficial to use encodings that can also capture the relative distance.
I was hoping it was an article on designing and building an electrical transformer complete with pictures of a home made, hand wound transformer. I was very disappointed.
This is cool, I highly recommend Jay Alammar’s Illustrated Transformer series to anyone wanting to get an understanding of the different types of transformers and how self-attention works.
The math behind self-attention is also cool and easy to extend to e.g. dual attention
Understanding how things work is useful and worthwhile on its own. Also while you probably can’t afford to train your own LLM you probably can afford to fine tune an existing one or to join one to another mode or lots of other things like that.
{kind=link}
I've also wondered why we add the positional encoding to the value, rather than concatenating them?
Also, the terms encoding, embedding, projection, and others are all starting to sound the same to me. I'm not sure exactly what the difference is. Linear projections start to look like embeddings start to look like encodings start to look like projections, etc. I guess that's just the nature of linear algebra? It's all the same? The data is the computation, and the computation is the data. Numbers in, numbers out, and if the wrong numbers come out then God help you.
I digress. Is there a distinction between encoding, embedding, and projection I should be aware of?
I recently read in "The Little Learner" book that finding the right parameters is learning. That's the point. Everything we do in deep learning is focused on choosing the right sequence of numbers and we call those numbers parameters. Every parameter has a specific role in our model. Parameters are our choice, those are the nobs that we (as a personified machine learning algorithm) get to adjust. Ever since then the word "parameters" has been much more meaningful to me. I'm hoping for similar clarity with these other words.