Author here, I actually think so. The rendering of the virtual DOM as well as hooks are fairly interesting mathematical constructs. A pattern I use a lot in web applications is the state reducer, which is really a fold over events and state. Seeing the functional nature of it (and reactive programming in general) can make for quite composable react code, while it is easy to make either a verbose mess of propdrilling or do a lot of tricky context mixing.
I'd love to see some examples of your diagrams. Are they all hand-written or do you use online tools for them? I do quite a bit of graph diagramming but not for detailed planning of implementation. Best example I've seen along those lines are the xState tools for state charts (https://stately.ai/viz).
This looks very mundane but I do think about it very mathematically as well: user interaction with a search engine. The "encode" arrow for example is very much about NLP and tokenizing, which is a functor from the "category" of natural language to the functor of "lucene tokens" which then has a functor to "lucene queries". This is of course the very mundane typing of functions as:
function parseQuery(query: NaturalLanguageString): LuceneQuery
nothing spectacular, but the abstract approach means I know I can cache/batch/precompute/distribute/pipeline/modularize it.
Similar mathematical concepts apply to all the other arrows, even if some are a bit wild (how does a search result influence a person's ideas?) But it means I can try to model the "wildness", and create say a probabilistic model to exercise and understand how my search engine actually performs (see for example click models and probabilistic graphical models)
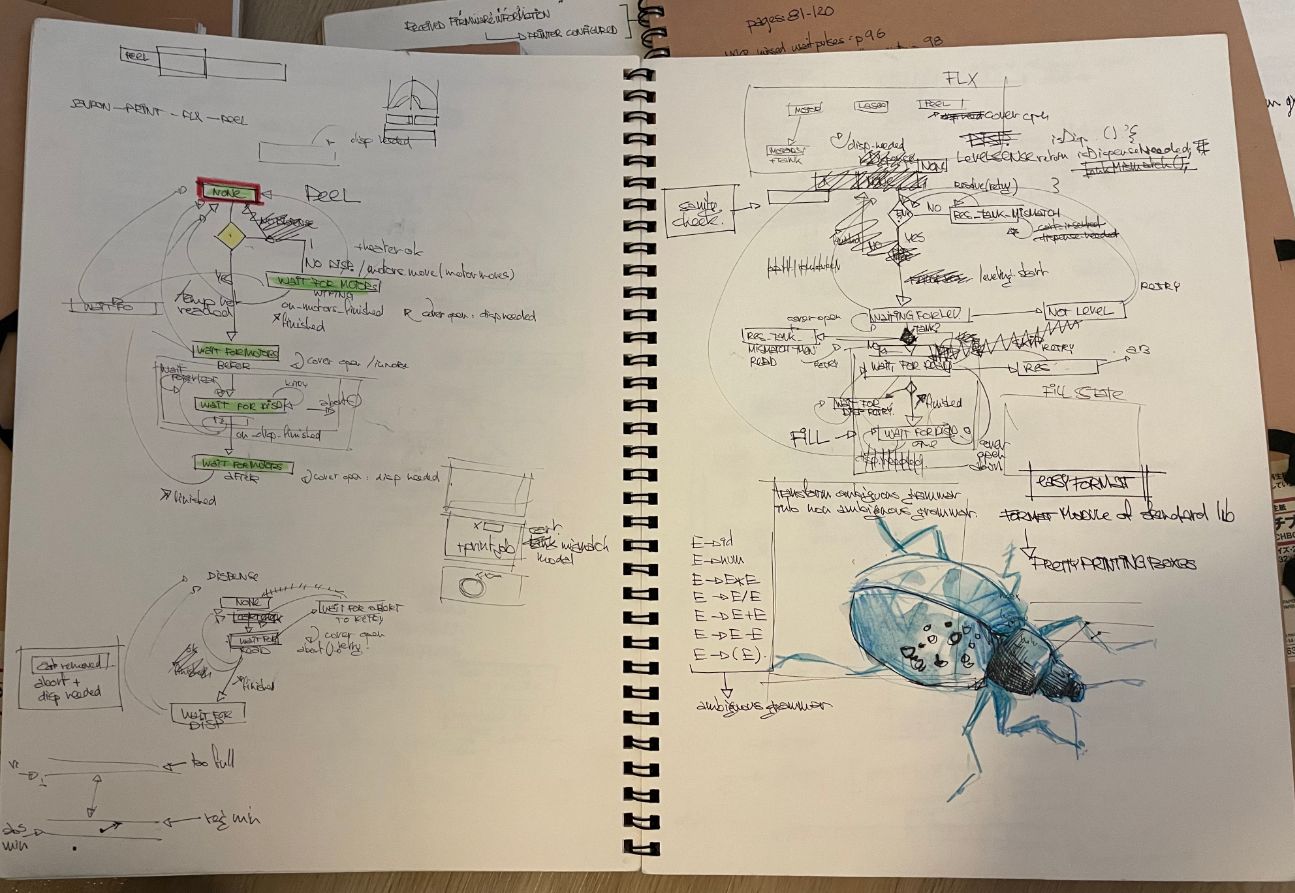
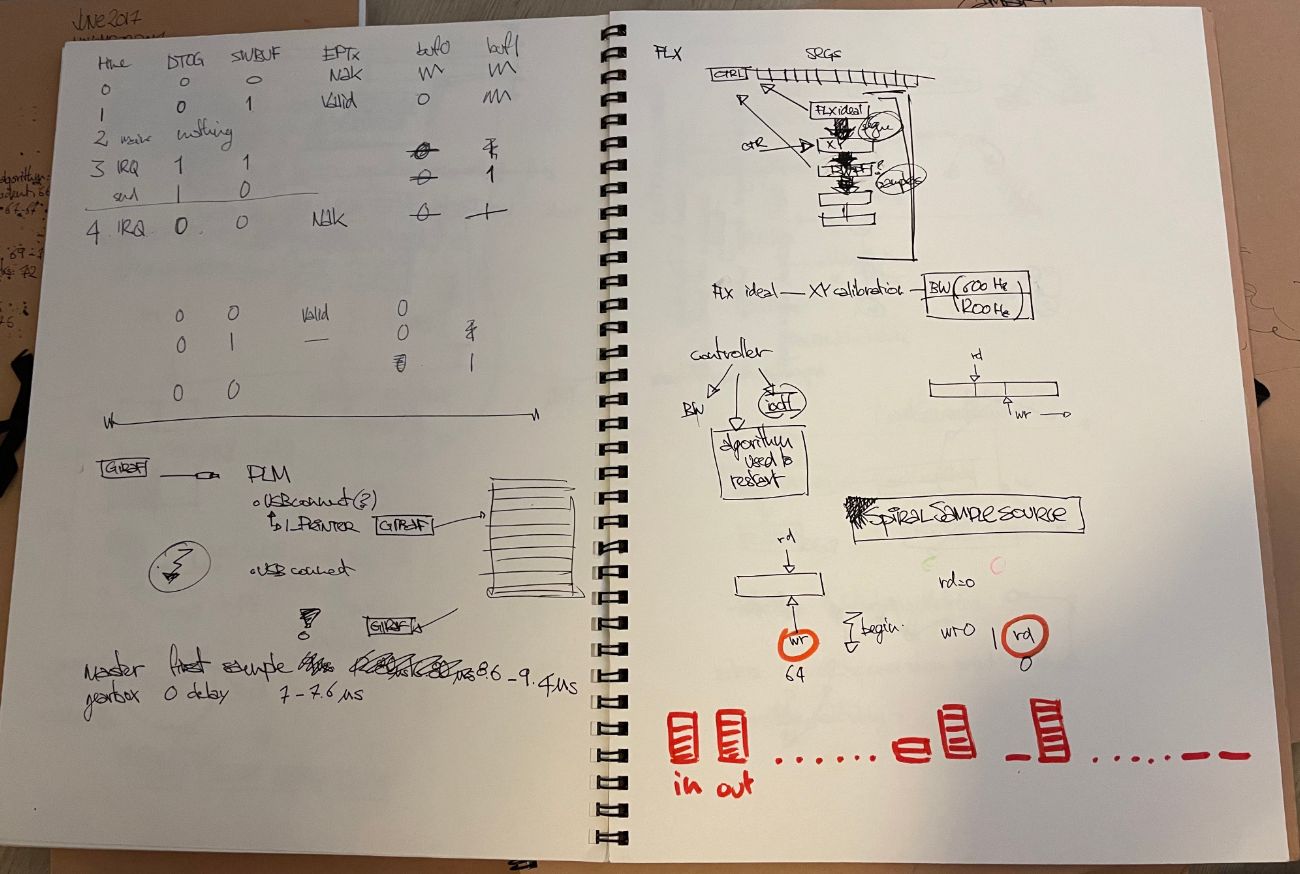
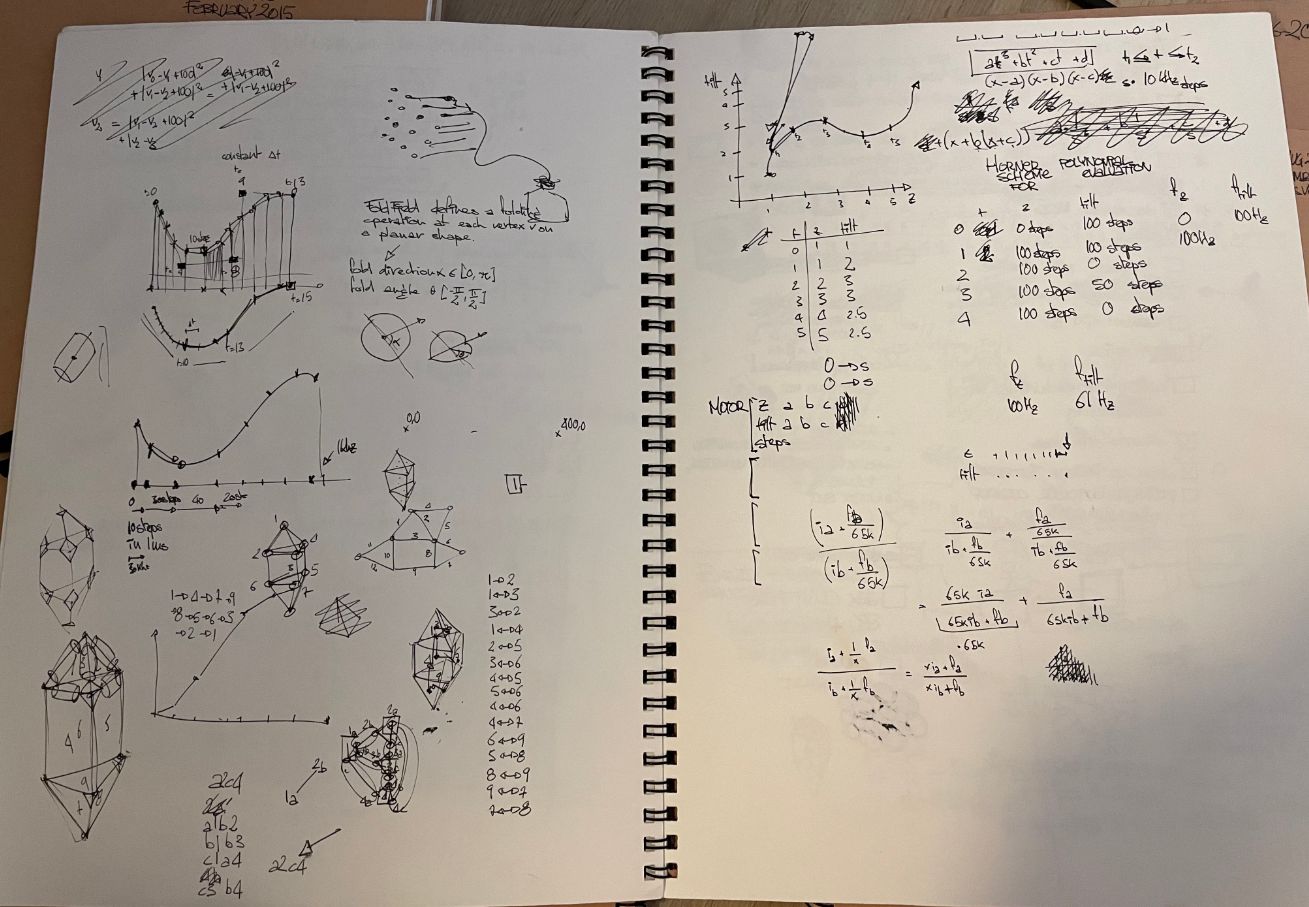
I love xstate! I do use plantuml a lot for sketching, but most is done on paper or whiteboards and is quite transient in nature. I must have hundreds if not thousands of sketchbooks pages that look like this:
I gave an Elm talk years ago at the shared office space I used to work at. A few devs there later told me the talk helped them better understand React.
Of course Elm is closely related to Haskell, which is a playground for category theory. I think learning the why behind it all can be useful in subtle ways.
Elm is a pure functional language where all data is immutable and functions are pure meaning they are guaranteed to have no side effects.
Having no side effects in JS is easy (just don't do it!) but immutability takes some effort.
React requires immutability so that if it sees the reference to an object again, it knows that it contains the same data. If it promised to work when mutating objects it would continuously need to deep search inside them to see what changed.
In JS, some array operations mutate the array, some copy it, you have to know specifically what operation you are using. In Elm, nothing mutates objects. All built in functions and functions you create will not do this.
In short - you can do (state, action) => state in any programming language, but mistakes caused by mutations are impossible in Elm by design.
{kind=link}
{kind=link}
{kind=link}
{kind=link}