>sharing your code is even pain with colleagues even if they are using the same operating system, mainly because the Python requirement file doesn't pin dependencies,
wat? Pretty sure you can use == in requirements.txt
Also, its very possible, and quite easy to just include the code for the library in your package, which effectively "locks in" the version. We did this all the time when building AWS lambda deployments.
This comment section itself clearly shows how crazy dependency and environment management is in Python. In this thread alone, we've received instructions to...
- poetry
- "Just pin the dependencies and use Docker"
- pip freeze
- Vendoring in dependency code
- pipreqs
- virtualenv
This is simply a mess and it's handled much better in other languages. I manage a small agency team and there are some weeks where I feel like we need a full-time devops person to just help resolve environment issues with Python projects around the team.
Keep in mind that Python is 31 year old (it's even older than Java) it was created around the same time as world wide web. So it started when no one even knew they would need dependency management and evolved over time from people posting packages on their home pages, to a central website to what we now call PyPI. Similarly the tooling and way of packaging the code evolved.
What you described are multiple tools that also target different areas:
> - poetry
from what you listed this seems like the only tool that actually takes care of dependency management
> - "Just pin the dependencies and use Docker"
this is standard fallback for all languages when people are lazy and don't want to figure out how to handle the dependencies
> - pip freeze
all this does it just lists currently installed packages in a form that can be automatically read by pip
> - Vendoring in dependency code
this again is just a way that applies to all languages, and it is still necessary even if there's a robust dependency management as there are some cases where bundling everything together is preferred
> - pipreqs
this is just a tool that scans your code and tells you what dependencies you are using. You are really lost if you need a tool to tell you what packages is your application is using, but I suppose it can be useful for one offs if you inherit some python code that wasn't using any dependence management.
> - virtualenv
this is just a method to have dependencies installed locally in project directory instead per system. This was created especially for development (although it can be used for deployment as well) as people started working on multiple services with different dependencies. It's now included in python so it's more like a feature of the language.
Being 31 years old doesn't preclude having a decent, official and reproducible way of installing packages in 2022. That's just a bad excuse to justify subpar package managers and terrible governance around this problem.
Package management is pretty much a solved problem, no matter how old is your language. It smells to an outsider like me like a lot of bike-shedding and not enough pragmatism is going on in Python land over this issue. Has a new BDFL stepped up after Guido left?
But Python has a decent and a reproducible way of installing packages. The problem python has is that things evolved over time, so you can find on the net plenty of outdated information. There is also a lot of blogs and articles with bad practices, most written by people that got something working.
I think also a lot of issues with packaging is ironically because of PyPA that supposed to work on a standard, but in reality instead of embracing and promoting something that works they just pushes half-assed solutions because author is one of the members. Kind of like they were pushing failed Pipenv "for humans". Seems like Poetry is generally popular and devs are happy with it, so of course PyPA started pushing their own Hatch project, because python packaging was finally getting too straight forward.
I think Python would benefit as a whole if PyPA was just dissolved.
Poetry has been the one I've settled on as well. It "Just Works™" for everything I've used it for thus far, and it's even been easy to convert older methods I've tried to the Poetry way of doing things.
I do see that in their repo[1] they use a non standard way to build the package. They use Bazel, but that's Google for you. They never do things everyone else is doing. I'm not sure why this is Python problem rather than package problem.
They have tons of open issues around building: [2]
Yup. Java is 27 years and has a splendid package management system (Maven Central) which is so well designed that you can use it from two different tools that are extremely different (Maven and Gradle).
This really isn't a good argument though: it's an extra, extremely specific use case for assignment that looks visually very similar.
And worse, effects code maintainability - if you need that assignment higher up, you're now editing the if statement, adding an assignment, plus whatever your interstitial code is.
Python doesn't have block scoping so the argument for it is weak.
It's not for extremely specific use-case, unless you consider using variables as a condition of an if statement or loop extremely specific.
> And worse, effects code maintainability - if you need that assignment higher up, you're now editing the if statement, adding an assignment, plus whatever your interstitial code is.
How is that different than variables declared without the walrus operator? If you declare a variable with the walrus operator and decide to move its declaration you can still continue to reference that variable in the same spot, just like any other variable. Do you have an example you can share to demonstrate this? I'm not sure I understand what you mean.
> Python doesn't have block scoping so the argument for it is weak.
The walrus operator another way to define variables, not change how they behave. It's just another addition to the "pythonic" way of coding. It's helped me to write more concise and even clearer code. I suggest reading the Effective Python link I provided for some examples of how you can benefit from it.
# some other code
if determined_value := some_function_call():
do_action(determined_value)
and then I change it to this:
# some other code
determined_value = some_function_call()
logger.info("Determined value was %s", determined_value)
validate(determined_value)
if determined_value:
do_action(determined_value)
and determined_value is a reasonably expensive operation (at the very least I would never want to redundantly do it twice) - then in this case my diff for this looks like:
--- <unnamed>
+++ <unnamed>
@@ -1,5 +1,8 @@
-
# some other code
-if determined_value := some_function_call():
+determined_value = some_function_call()
+logger.info("Determined value was %s", determined_value)
+validate(determined_value)
+
+if determined_value:
do_action(determined_value)
whereas if I wrote it without walrus originally:
--- <unnamed>
+++ <unnamed>
@@ -1,5 +1,8 @@
# some other code
determined_value = some_function_call()
+logger.info("Determined value was %s", determined_value)
+validate(determined_value)
+
if determined_value:
do_action(determined_value)
then the diff is easier to read, and the intent is clearer because diff can simply infer that what's happening is the semantic addition of two lines.
Code is read more then it's written, and changed more then originally created, and making the change case clearer makes sense.
Your issue is with the readability of the diff? That is so trivial. You're trying to find anything to complain about at this point. How about just look at the code? You should be doing that anyway.
Diffs are the predominant way people relate to code changes via PRs. It is standard practice to restructure patch sets to produce a set of easy to read to changes which explain what is happening - what "was" and what "will be".
An example where I have wanted this many times before it existed is in something like:
while (n := s.read(buffer)) != 0:
#do something with first n bytes of buffer
Without the walrus operator you either have to duplicate the read operation before the loop and at the end of the loop, or use while True with a break if n is zero. Both of which are ugly IMO.
I used to think this and rage at the current state of Python dependency management. Then I just buckled down and learned the various tools. It's honestly fine.
> all this does it just lists currently installed packages in a form that can be automatically read by pip
Are you referring to version specifiers[1] being optional or is there something more to versions that I don't understand? PEP 440 is a wall of text, maybe I should get around to reading it sometime.
This whole chain started with someone pointing out the author doesn't seem to realize you can pin versions[1]. I'm just confused how people seemed to end up questioning what pip freeze does.
I tried to say that from mentioned tools only poetry can be called as a dependency management.
The other tools are used for different purposes, but perhaps could be used as a piece of package management in some way. The mentioned docker and vendoring is irrelevant to Python and it even applies to Go.
Sometimes I feel people are using Python very differently than me. I just use pip freeze and virtualenv (these are Python basics, not some exotic tools) and I feel it works great.
Granted, you don't get a nice executable, but it's still miles ahead of C++ (people literally put their code into header files so you don't have to link to a library), and even modern languages like rust (stuff is always broken, or I have some incompatible version, even when it builds it doesn't work)
By the way if you're a Python user, Nim is worth checking out. It's compiled, fast and very low fuss kind of language that looks a lot like Python.
> and even modern languages like rust (stuff is always broken, or I have some incompatible version, even when it builds it doesn't work)
Been working on and off with Rust for the last 3 years, never happened to me once -- with the exception of the Tokio async runtime that has breaking changes between versions. Everything else always worked on the first try (checked with tests, too).
Comparing Python with C++ doesn't make do argument any favours, and neither does stretching a single Rust accident to mean the ecosystem is bad.
This is consistent with my experience. Semantic versioning is very very widely used in the Rust ecosystem, so you're not looking at breaking changes unless you select a different major version (or different minor version, for 0.x crates) - which you have to do manually, cargo will only automatically update dependencies to versions which semver specifies should be compatible.
For crates that don't follow semver (which I'm fairly certain I've encountered zero times) you can pin a specific exact version.
When I was a Python dev, I never saw that happen in ten years or so of work. Pip freeze and virtualenv just worked for me.
I will say, though, that this only accounts for times where you’re not upgrading dependencies. Where I’ve always run into issues in Python was when I decided to upgrade a dependency and eventually trigger some impossible mess.
Piptools [1] resolves this by having a requirements.in file where you specify your top level dependencies, doing the lookup and merging of dependency versions and then generating a requirements.txt lock file. Honestly it’s the easiest and least complex of Python’s dependency tools that just gets out of your way instead of mandating a totally separate workflow a la Poetry.
It's really not. I've had a much, much worse experience with Python than Elixir / Go / Node for various reasons: lots of different tools rather than one blessed solution, people pinning specific versions in requirements (2.1.2) rather than ranges (~> 2.1), dependency resolution never finishing, pip-tools being broken 4 times by new pip releases throughout a project (I kept track)...
In Elixir I can do `mix hex.outdated` in any project, no matter who wrote it, and it'll tell me very quickly what's safe to update and link to a diff of all the code changes. It's night and day.
Thankfully, it's getting gradually better with poetry, but it's still quite clunky compared to what you get elsewhere. I noticed lately for instance that the silent flag is broken, and there's apparently no way to prevent it from spamming 10k lines of progress bars in the CI logs. There's an issue on Github, lost in a sea of 916 other open issues...
As soon as you take 2 dependencies in any language, there's a chance you will not be able to upgrade both of them to latest versions because somewhere in the two dependency subgraphs there is a conflict. There's no magic to avoid this, though tooling can help find potentially working versions (at least by declaration). It's often the case that you don't encounter conflicts in Python or other languages, but I don't imagine that Go is immune.
I've used npm but an not familiar with these kinds of details of it. There would seem to be some potential putfalls, such as two libraries accessing a single system resource (a config file, a system socket, etc.). I will take a look into this though. Thanks.
npm works around some problems like this with a concept of "peer dependencies" which are dependencies that can only be depended on once. The typical dependency, though, is scoped to the package that requires it.
Rust can include different versions of the same library (crate) in a single project just fine. As long as those are private dependencies, no conflicts would happen. A conflict would happen only if two libraries pass around values of a shared type, but each wanted a different version of the crate that defines the type.
I have rarely encountered issues in rust. Most rust crates stick to semver so you know when there will be a breaking change. My rust experience with Cargo can only be described as problem free(though I only develop for x86 linux).
As for pip freeze and virtualenv things start to fall apart especially quickly when you require various C/C++ dependencies (which in various parts of the ecosystem is a lot) as well as different python versions (if you are supporting any kind of legacy software). This is also assuming other people working on the same project have the same python yadda yadda the list goes on, its not great.
> pip freeze and virtualenv things start to fall apart especially quickly when you require various C/C++ dependencies
Yes 100 times. That can be incredibly frustrating. During the last year I've used a large (and rapidly evolving) C++ project (with many foss C/C++ dependencies) with Python bindings. We've collectively wasted sooo many hours on dependency issues in the team.
Long compilation times contribute considerably to slow down the feedback loop when debugging the issues.
Wat? What dependencies? I have right now 100 separate Python projects which each have their own venv, their own isolated dependencies, and their own isolated copy of Python itself and my code dir doesn’t even crack top 10 hard drive space.
No, saying "one common library is big" isn't a good way to show that "Python dependencies are big", which is what the initial claim was. Most libraries are tiny, and there's a very big one because it does many things. If Tensorflow were in JS it wouldn't be any smaller.
Yup. PyEnv for installing various versions. /path/to/pyenv/version/bin/python -m venv venv. Activate the venv (I made "av" and "dv" aliases in my .zshrc). Done, proceed as usual.
You can get that by bundling up your venv. When you install a package is a venv it installs it into that venv rather than the system. As far as the venv is concerned it is the system Python. Unfortunately passing around a venv can be problematic, say between Mac and Linux or between different architectures when binaries are involved.
Sounds like someone has never been asked to clone and run software targeting Python 3.x when their system-installed Python is 3.y and the two are incompatible.
Sounds like someone is making assumptions on the way I work :) As a matter of fact I have and the solution is pyenv. Node has a similar utility called n.
Now try installing tensorflow. Treat yourself to ice cream if you get it to install without having to reinstall Linux and without borking the active project you're on.
And unless things have gotten a lot better in the 2 years since I last did `pip install numpy` on ARM, prepare for a very long wait because you'll be building it from source.
The major issues you'll see involve library version mismatches. It's a very good idea to use venv with these tools since there are often mismatches between projects.
Tensorflow sometimes is pinned to Nvidia drivers, and protobuf. And I think it has to be system level unless you reaaaaally want to fiddle with the internals.
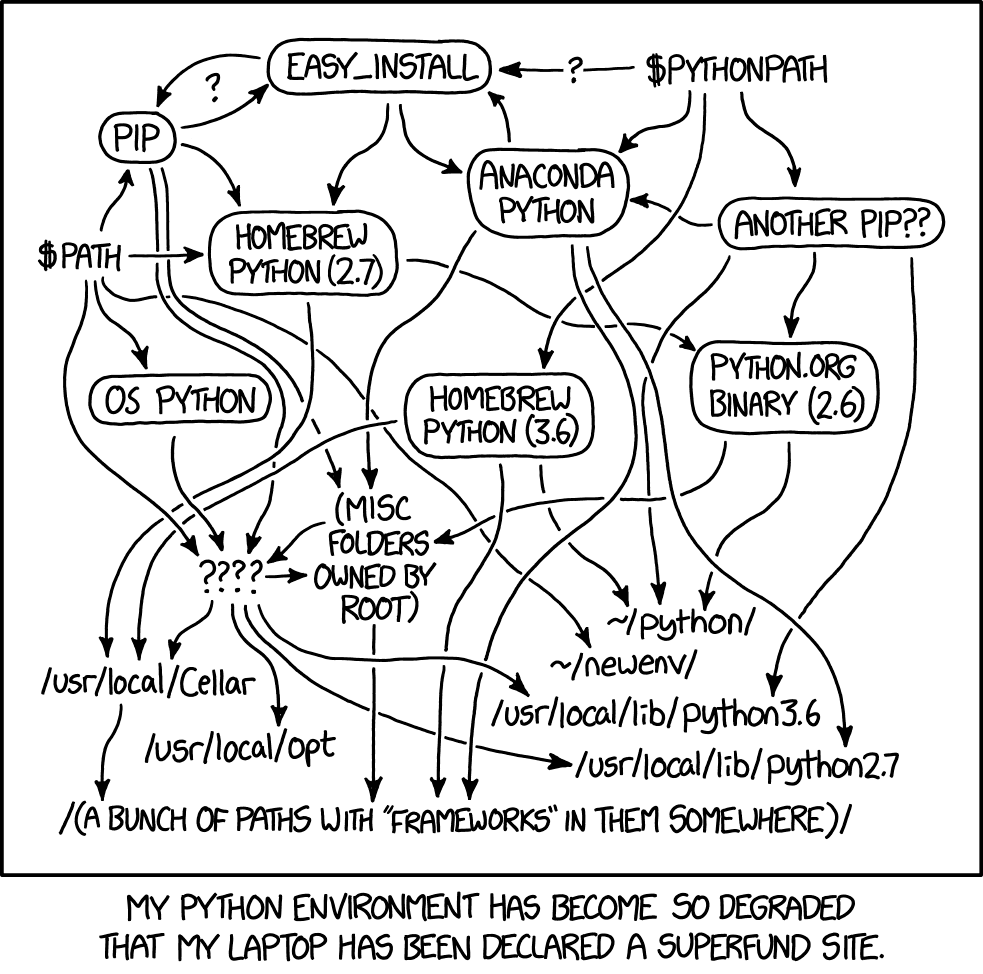
The core problem with Python dependencies is denial. There are tons of people who make excuses for a system that is so bad Randall Munroe declared his dependencies a “superfund site” years ago. In a good ecosystem, that comic would have prompted change. Instead, it just prompted a lot of “works for me comments”. Monads are just monoids in the category of endofunctors, and C just requires you to free memory at the right time. Python dependencies just work as long as you do a thing I’ve never seen my colleagues do at any job I’ve worked at.
That's half of why from 2017 to 2021 I had a yearly "uninstall Anaconda and start fresh" routine. The other half is because I'd eventually corrupt my environments and have no choice but to start over.
Are you using conda-forge? Solving from over 6TBs of packages can take quite a while. Conda-forge builds everything. This isn't a criticism, but because of that the number of packages is massive.
"You can't use the big channel with all the packages because it has all the packages" isn't an exoneration, it's an indictment.
To answer your question: yes, we were using conda-forge, and then when it stopped building we moved to a mix of conda and a critical subchannel, and then a major GIS library broke on conda and stayed that way for months so we threw in the towel and just used pip + a few touch-up scripts. Now that everyone else has followed suit, pip is the place where things "just work" so now we just use pip, no touchups required.
Is it a mess? Yes. But, is the problem to be solved perhaps much simpler "in other languages"? Do you interface with C++ libraries, system-managed dependencies, and perhaps your GPU in these other languages? Or are all your dependencies purely coded in these other languages, making everything simpler?
Of course the answer to these questions could be anything but to me it feels like attacks on Python's package management are usually cheap shots on a much much more complicated problem domain than the "complainers" are typically aware of.
Or the "complainers" work with Rust and Elixir and giggle at Python's last-century dependency-management woes, while they run a command or two and can upgrade and/or pin their dependencies and put that in version control and have builds identical [to those on their dev machines] in their CI/CD environment.
¯\_(ツ)_/¯
Your comment hints that you are feeling personally attacked when Python is criticized. Friendly unsolicited advice: don't do that, it's not healthy for you.
Python is a relic. Its popularity and integration with super-strong C/C++ libraries has been carrying it for at least the last 5 years, if not 10. There's no mystery: it's a network effect. Quality is irrelevant when something is popular.
And yes I used Python. Hated it every time. I guess I have to thank Python for learning bash scripting well. I still ended up wasting less time.
It's a bit ironic to pick someone's up on "taking things personally upon criticism", then proceeding to display a deep, manichean, unfounded hatered for a language that, despite its numerous flaws, remains a popular and useful tool.
Hanging people upon dawn was popular as well; people even got their kids for the event and it was happening regularly. Popularity says nothing about quality or even viability.
Use Python if it's useful for you, obviously. To me though the writing is on the wall -- it's on its loooong and painful (due to people being in denial) way out.
EDIT: I don't "hate"; it was a figure of speech. Our work has no place for such emotions. I simply get "sick of" (read: become weary of) something being preached as good when it clearly is not, at least in purely technical terms. And the "hate" is not at all unfounded. Choosing to ignore what doesn't conform to your view is not an argument.
> Your comment hints that you are feeling personally attacked when Python is criticized.
I am not feeling personally attacked (I am not married to Python), I am mostly just tired of reading the same unproductive type of complaints over and over again. This attitude is not unique to Python's situation, but actually is typical to our industry. It makes me want to find a different job, on some days.
The community is trying to improve the situation but there is no way to erase Python's history. So it's always going to continue to look messy if you keep looking back. The complaint is unproductive, or in other words, not constructive.
I can agree with your comment. What's missing is the possibility to, you know, just jump ship.
You might not be married to Python but it sure looks that way for many others. I switched main languages no less than 4 times in my career and each time it was an objective improvement.
The thing that kind of makes me look down on other programmers is them refusing to move on.
For nuance and to address your point, I have worked with PHP for about six years, .NET for five, C++ for two, and Python for seven.
I still dabble in all of them. Who knows when I will move on to the next. Rust looks nice. I tried go.
But they do not yet provide any of the tools/libraries I need for my work. That's how I've always selected my programming language.
So I would first need to invent the universe before I can create valuable things. Instead I will just wait until their ecosystems mature a little more.
I will end the discussion here though. Thanks for the response!
Yes. In elixir, you can install GPU stuff (Nx) with very few problems. Some people have built some really cool tools like burrito, which cross-compile and bundles up the VMs to other architectures. Even before that it's been pretty common to cross-compile from x86 to an arm raspberry pi image in the form of Nerves.
As a rule elixir devs don't do system level dependencies, probably because of lessons learned from the hell scape that is python (and Ruby)
Yesterday I onboarded a coworker onto the elixir project, he instinctively put it into a docker container. I laughed and just told him to run it bare (he runs macos, I run Linux). There were 0 problems out of the box except I forgot the npm incantations to load up the frontend libraries.
2) not that I can find for that specific task but the typical strategy is to download (or compile) a binary, drop it into a {project-dependency}[0]-local "private assets" directory, and call out the binary. This is for example how I embed zig pl into elixir (see "zigler") without system-level dependencies. Setting this up is about 40 lines of code.
3) wx is preferred in the ecosystem over qt, but this (and openssl) are the two biggies in terms of "needs system deps", though it's possible to run without wx.
For native graphics, elixir is treading towards glfw, which doesn't have widgets, but from what I hear there are very few if any gotchas in terms of using it.
I bring up cross-compilation, because burrito allows you to cross-compile natively implemented code, e.g. bcrypt that's in a library. So libraries that need c-FFI typically don't ship binaries, they compile at build time. Burrito binds "the correct" architecture into the c-flags and enables you to cross compile c-FFI stuff, so you don't have a system level dependency.
[0] not that this has happened, but two dependencies in the same project could download different versions of the same binary and not collide with each other.
Its not a mess, people just make it a mess because of the lack of understanding around it, and getting lazy with using a combination of pip install, apt install, and whatever else. Also, the problem is compounded by people using Mac to develop, which have a different way of handling system wide python installs from brew, and then trying to port that to Linux.
Even using conda to manage reqs is an absolute nightmare. Did a subreq get updated? Did the author of the library pin that subreq? No? Have fun hunting down which library needs to be downgraded manually
I used a couple of tricks to solve this. First, make cond env export a build step and environment.yml an artifact so you've got a nice summary of what got installed. Second, nightly builds so you aren't surprised by random package upgrade errors the next time you commit code to your project.
This has indeed been eye opening. We got bit by a dependency problem in which TensorFlow started pulling in an incompatible version of protobuf. After reading these comments, I don't think that pip freeze is quite what we want, but poetry sounds promising. We have a relatively small set of core dependencies, and a bunch of transitive dependencies that just need to work, and which we sometimes need to update for security fixes.
Why do you think that `pip freeze` wouldn't be what you want? (I once had the exact same issue with TF and protobuf and specifying the exact protobuf version I wanted solved it.)
When I tried learning Python, this mess is what turned me off so badly. Python is the first language I ever came across where I felt like Docker was necessary just to keep the mess in a sandbox.
Coming to that from hearing stories that there was supposed to be one way to do everything disenchanted me quickly.
Every article I found suggested different versions of Python, like Anaconda. They all suggested different virtual environments too. Rarely was an explanation given. At the time, the mix of Python 2 vs Python 3 was a mess.
The code itself was okay, but everything around it was a train wreck compared to every other language I’d been using (Go, Java, Ruby, Elixir, even Perl).
I attempted to get into it based on good things I’d heard online, but in the end it just wasn’t my cup of tea.
> This is simply a mess and it's handled much better in other languages.
I don't agree.
The problem is simply that Python encompasses a MUCH larger space with "package management" than most languages. It also has been around long enough to generate fairly deep dependency chains.
As a counterexample, try using rust-analyzer or rust-skia on a Beaglebone Black. Good luck. Whereas, my Python stuff runs flawlessly.
What many newer languages do is precompile the happy paths(x86, x86-64, and arm64) and then hang you out to dry if that's not what you are on.
I agree that it is handled better in many other languages. However, Go has some weird thing with imports going on. When I tried to learn it I just could not import a function from another file. Some env variable making the program not find the path. Many stackoverflow/reddit threads condecendenly pointed to some setup guide in official docs which did not fix or explain the situation.
After an few hours or so of not making much progress in AOC day 1 I just gave up and never continued learning Go.
It's not crazy at all. You use requirements.txt to keep a track of the dependencies needed for development, and you put the dependencies needed to build and install a package into setup.py where the packaging script can get it.
These are two different things, because they do two different jobs.
Granted, I'm more of a hobbiest than a dev, but I think this is part of the problem that virtualenvs are supposed to help solve. One project (virtualenv) can have numpy==3.2, and another can have numpy==3.1. Maybe I'm naive, but it seems like having a one project with multiple versions of numpy being imported/called at various times would be asking for trouble.
The thing you can’t do is solve for this situation.
A depends on B, C
B depends on D==1.24
C depends on D==2.02
There should in an super ideal world be no problem with this. You would just have a “linker” that inserts itself in the module loader that presents different module objects when deps ask for “D” but it hasn’t happened yet.
Someone else already responded. It's a one-line command.
I never could get poetry to work right; it's configs are sort of messy. pip freeze > requirements is built in. The only thing it doesn't pin is the python version itself.
As explained elsewhere in this thread, the one line command only generates a lock file. This doesn't manage the dependencies so if you want to upgrade cool-lib and recalculate all the transient dependencies so they fit with the rest of your libraries, you cannot afaik.
This is not actually true. :-) Pip will install transitive deps from a requirements file unless you add the “no deps” flag. Pip freeze doesn’t pin anything. It just dumps stuff into a text file. If it’s a complete list, it has the side effect of pinning, but that’s not guaranteed by pip freeze in any way.
Poetry requires pip in the way that `go mod` requires `go get`, i.e. Poetry allows one to operate at a higher level of abstraction, where it's harder to make mistakes and generally easier to manage your dependency tree.
Sure, this is true for every abstraction: some are more air-tight or leaky than others, but IME Poetry and go mod are fairly solid.
I haven’t had to use pip in a long time. Just like I haven’t had to use `go get` in a while.
I mean it’s not the most rock solid abstraction, but introducing sane package management in an OSS environment with a decade plus of history is very hard. Against that background, they are doing pretty well, IMO.
Kind of. It's intended to be a system package/tool. In that regard you can use, wait for it, yet another python tool - pipx. So instead of installing poetry to a venv or whatever using pip, you can use `pipx run poetry`. Now you have to install pipx...
I'm a huge, long time, python fan. I don't tend to have a lot of problems with dependencies, but it clearly is something that certain situations have problems with.
As I understand the post, the author is saying "It sure is nice to be able to just hand off a go executable and be done with it." And I think we can agree that the Python runtime situation is far from this.
I largely control my work environment, so this isn't a huge issue for me. But I'm right at this very moment converting a "python" to "python3" in a wrapper script because the underlying code got converted to py3 and can't "import configparser". (Actually, I'm removing "python" entirely and adding a shebamg).
I've been looking at writing a small tool in Python and then porting it to Go (I don't know go, so seems like a reasonable way to approach it), because the main target of the app is my developers, who probably don't have the right Python environment set up, and I just want them to be able to use it, not give them a chore.
Also, its very possible, and quite easy to just include the code for the library in your package
This only works if installing on exactly the same os and architecture. It can also make the installer for your quick little command line tool hundreds of megabytes.
That being said packing up the python interpreter and all dependencies is the approach I ended up using when shipping non-trivial python applications in the past.
Yep, I have no idea how they do not even understand the basics of python dependency management. pip freeze > requirements.txt will do it all for you. No wonder they found rust to hard.
You can do you want you suggest, but it's an operational pain in the ass. You need to maintain two files, the actual requirements.txt and the `pip freeze` one that locks the environment. And you better never `pip install` anything by hand or you'll capture random packages in your frozen file, or else always take care to create your frozen file in a fresh virtualenv. And if you don't want to install your dev packages into the production environment, then you need to maintain two requirements.txt and two of those frozen files.
The author mentions Poetry which does solve these issues with a nice interface.
`pip freeze > requirements.txt` will generate a lock file. You want a requirements listing as well as a lock file (like rust, poetry, golang, npm, ruby).
There's lots of cases where you wouldn't want to pin your requirements.txt, the main one being if you're authoring a package. You need to leave the versions unpinned, preferably just bound to a major version, allowing some variability for the users of your package in case there's a shared dependency. I have a feeling that's what the author is describing here, because Poetry solves this dilemma by introducing a poetry.lock file which pins the dev versions of all the dependencies, but publishes a package with unpinned deps.
This is wrong and OMG all other 15 answers to this comment even more wrong.
Pinning a dependency in requirements.txt does not pin its transitive dependencies.
This does NOT mean you should pip freeze everything into requirements.txt, because then how do you distinguish top level dependencies from transitive?
The correct answer is to use lock file. No third party tools needed (1). In Python they named it constraints and requires an extra flag to use. pip freeze > constraints.txt. Then next time pip install -r requirements.txt -c constraints.txt.
Oh, and always always always use a venv for each project. Globally installed packages is a recipe for disaster.
(1) Poetry and Pipenv are still nice additions, with nicer project declarations in pyproject.toml and to save you from remembering pip flags or forgetting activation of venvs. But they are not strictly necessary and it’s honestly just 2 commands extra without them.
The issue is transitive dependencies. A dependency you pin isn't guaranteed to pin its own dependencies. A bug somewhere in a grandchild dependency can manifest for you even if you have a version pinned but the dependency did not.
It's not automatically a problem but it certainly can become one.
Python has several. It’s overall a good thing. It’s the reason you can package both one-file scripts and huge C++ / Fortran packages, which is the reason it has become a huge language in HPC / ML / AI / astronomy / data science / …
I agree that it makes life more confusing for newbies, though.
something like poetry's approach is the right one here; you need a list of core dependencies (not derived ones), you need a solver for when anything changes to find a new set of viable versions, and you need a lock file of some sort to uniquely & reproducible construct an environment.
You can, but one of those packages that you depend on will have a loose version spec for one of its dependencies, making your `pip install -r requirements.txt` non-deterministic.
Poetry and Pipenv solve this, though, by pinning all dependencies in a lock file.
While the documentation of many open source Go libraries is definitely lacking, I find that the combination of types and links to readable source in the generated docs more than make up for it. While the documentation for Python libraries is often better, it is generally much harder to answer questions not answered by the docs yourself.
I agree with this. I also derive quite a lot of value from having a consistent way of reading and navigating documentation for every library too. I can have an applet in my browser's toolbar and hit it when I'm looking at the Git repo and it'll almost always take me to the right place to ser the docs.
i dragged my feet on go for a long time. i also thought that skipping go and moving to rust was the play. a few years later, i still write python often, but i don’t build systems with it. python i now use like bash, to glue things together and automate random things. it’s a fantastic language and i will never drop it.
the verbosity of go is the biggest hurdle for a pythonista. the thought of giving up context managers, decorators, iterators, comprehensions, exceptions, coroutines, it’s unthinkable. in comparison go is ugly. your aesthetic mind screams in protest.
write go full time. dive in. as months pass, not only will those aesthetic objections fade, your mental model from python cleanly transforms to go. go is what mypy tried to be. the cost was aesthetic changes. the benefit is worth it.
the zen of python says if it’s easy to explain it might be a good idea. this is go, and it is.
i rebuilt a reasonably sized project from python[1] to go[2] over the last few years. i also have a system that i maintain both python[3] and go[4] implementations for, sharing a test suite in python. squint at the implementations. consciously ignore aesthetic objections. they are basically the same, not very different from a python codebase with and without type annotations.
go, like python, is fantastic. use both in whatever amount works for you. don’t read about them, build with them. you won’t regret it.
Obviously the closest thing in the general sense to Python is Ruby. But I think a case can be made that in practice, the closest thing to Python on the static language side is Go. The list of superficial differences is a mile long, I don't deny, nor will I exhaust my audience's patience with actually writing them out. But the interface orientation of Go captures the essence of how you design in Python surprisingly well. Of all the static languages, Go has the closest thing to duck typing, in particular the ability to declare a "duck type" for an existing third-party thing that you don't want to or can't change, and integrate it into your code as a compile-time checked member of that "duck type".
I've rebuilt multiple projects written in python/php/perl originally in go instead and it's just great how much more performant these comparatively are... Just way lower resource usage and the programs work faster now. It's worth it to consider the switch.
One of the things that go is really good for is the amount you can get done without having to deviate that far from the standard library. A lot of churn in updating code can be alleviated if you try to select small, well-written, well-maintained libraries in ANY language but in go this just feels way easier, I find myself thinking how to solve it using stdlib instead of trying to find out what package would suit my needs and boom everything is there already don't need to mess around too hard looking on whose shoulders to stand on only to have them walk away and do something else with their time down the line. The worst ecosystem for that is easily nodejs, blows my mind what front-end dev often looks like these days... like it being normal for a project's node_modules to hit like 500mb is just incredible to me. I'm extremely allergic to that mentality. Someone hit me up like hey I have a linux problem when i run webpack it crashes my whole system... like yo how does some corky javascript thing to minify stuff cause semaphore exhaustion to a point where your entire system goes down when you run it on a sufficiently large project, that's just horrifyingly bad. Found out if he was to continue using that tool that he had to install some graceful filesystem package for it to work. I think I managed to convince him to switch to esbuild, written of course in go. [1]
i agree, performance and stdlib are very nice benefits.
i enjoy refactoring with type safety and using gopls and ide completion instead of external docs. i used to constantly read boto3 docs in a browser, now i use gopls in my ide.
frontend dev can be sane[1] too! my default setup is a go lambda with an spa frontend inlined into an html file.
I like TypeScript + deno [1] a lot these days for similar reasons... It's got the same thing going for it, a solid standard library on top of something like JS but sucks less.
Do Go programmers also not like capitalization? Just a tease, I noticed the readme and your comment don't have any Capitalized Letters. Well, the readme has a few but you know what I mean.
Breaking basic language norms in this way is the equivalent of CONSTANTLY RAISING YOUR VOICE. It's distracting and attention-getting. Which may be your goal, but if your goal is to be easily understood and sympathetic to your reader, it's counterproductive.
I hated the "damnable use requirement" (the error you get on unused imports) for years, but I've been keeping a count of how many bugs they've caught (I was surprised the first time this happened) and I'm up to 3-4 now. What people who code in Go seriously do is just hook `goimports` up to their editor, and then never think about this again.
Every time someone mentions this fact I think about Zig having recently added this "feature" and my blood boils.
Unused imports or variables being errors is the most idiotic and overrated paper cut ever implemented in compilers. In no universe it is a good idea.
I posit there are actually no or very few bugs it catches, and in exchange it ruins people's iterative development, flow and hyperfocus states when experimenting, because poor compiler can't deal with an unused import, fix it now or else. Now we need an IDE setup to deal with this? And why the hell isn't this a feature that can be turned off?
If only I could throw the person that invented this crap into the flaming sun.
It has caught some bugs for me, and I essentially never think about it anymore, because `goimports` just handles this. It is substantially easier for me to deal with imports in a Go program than in a Python program, and if I look back at my old code, I wince at all the pointless crap at the top of my programs.
How is this better than downgrading the error into a warning? You'd be able to build but would still know something was wrong-ish. Certainly a warning would be sufficient to chase down any bugs, and is very freeing compared to an error.
Knowingly shipping code that generates warnings during build is anti-social. It usually isn't that much work to fix a warning as you are writing the code and you encounter the warning the first time. It becomes much more expensive to fix warnings later because you do not have the mental context you had when you wrote the code.
But some people behave like that. They think it is someone else's job to chase down bugs in their code after they have knowingly submitted code with defects rather than deal with it immediately.
Classifying something as an error rather than a warning makes zero difference to programmers who take care not to knowingly ship defects. It only makes a difference to people who were going to ignore it and let someone else take up their slack. And to be frank: why on earth would you want to accomodate them?
Turned around, what's the benefit of allowing someone to build something that may potentially break, when the alternative is an easy to fix error instead?
Sometimes you want to comment out something and rerun, and having to do the same with dependencies is annoying. Maybe have a dev vs prod compilation split, with the first allowing unused imports.
I think it's important to know what problem the no-unused-imports error is solving. See Rob Pike's talk from 2012, and in particular, the section of dependencies in C++: https://talks.golang.org/2012/splash.article#TOC_5.
Basically, the point of no-unused-imports is to reduce compilation time at scale. In the C++ ecosystem, there are lots of redundant and unused #includes. This means that a lot of the bytes sent to the C++ compiler are just thrown away. If you can guarantee that the compiler will never need to look at a source file it does not need to, you can cut down on the compilation time. For small projects, this doesn't matter much. For large projects, it does. Go was designed for large projects.
goimports seems an endless source of absolutely bizarre bugs unless your packages' terminal path element exactly matches the package name (even sometimes if it does e.g. https://github.com/golang/go/issues/29041).
These do get addressed over time but also seems to break in a new way at least a couple times a year.
I only use python casually, but it seems to me that python library authors are always refactoring and breaking interfaces.
Recently, there was a bug in a second order dependency, and the version that fixed this bug was after a version that moved a function into a submodule.
So I had to make a local patch to my dependency that changed all of the imports.
Was the new interface more consistent? Yes, but could they have left a shim for backwards compatibility, or just lived with the old slightly less consistent interface? Seems to me like they could.
I think that depends on library. The ones I use seem to use appear to not do that. In fact I think I actually have seen that more in Go. What goes for Go though is that you won't compile your code until you fix it. In Python you could use mypy, but unfortunately is optional and will work only if you and library author uses annotations.
I don't think Python packaging is as bad as people make out (if packages only stick to the basic features of Python!) A far bigger issue I see is despite Python supposedly being 'cross-platform': the language introduces so many small, backwards-compatibility breaking changes that you really need to use the most up to date interpreter you can.
For instance: there is now a really cool operator that lets you do expressions where you assign a value and evaluate the result in one line. So you can write the C equivalent of something like while(buf = recv(...)) ... and it will work. Well, any program that uses this new feature won't run on anything but the most bleeding edge Python versions. Despite a program only needing a small fix to remove such expressions. It wouldn't run at all.
I think the Python interpreter needs to be 'smarter' and add the capability to automatically install parallel Python versions if it detects a package using a more recent interpreter. Would honestly solve so many issues.
While I do see the value in something like that, I can’t help but feel like that would just bake in more complexity. The python ecosystem is fragmented with micro fixes and half-solutions without anything truly addressing the major confusing aspects.
There's what people think and then there is observed reality. Observed reality informs us that this is a big problem with Python, so we'll just have to accept that. What people could do isn't the issue - what people do is. Also, you don't fix a problem by adding complexity and unpredictability. Again, as reality informs us, this hasn't worked for Python. It is still a mess.
Python 3.8 and its walrus operator is 2.5 years old, it's not bleeding edge, at least not anymore. That being said, I'm worried about the language in that complexity increases through the introduction of new language features without much benefit at all.
The complaint about aws-sdk-go (presumably v1) is legitimate, it seems to me that code was generated and therefore the repo can be less than ideal w/ Go. I suspect that is improved/ing in v2.
using goimports as your formatter solves the complaint about unused imports
There was a significant portion of time where python 2.x and earlier releases of Go overlapped, and finding UTF-8 safe python libraries was non-trivial. Go makes utf-8 the default. As I understand it many companies still have python2 w/o a EoL plan.
One thing I really miss about working with python is list/dict comprehensions and lambdas
It's still valid for v2. While it's a bit easier to use in almost all respects, the documentation is still kind of crazy because it's mostly autogenerated.
In Go, the first thing you run into when making an API call is figuring out how to handle the errors, and the aws-sdk-go docs still don't give you much help there --you have to still dive into the official REST docs, or worse, the Java docs via google, and sort of guess how each exception/error code gets mapped into what Go error.
Jumping into the library code works for most Go libraries, but with the autogenerated REST bindings that is the AWS SDK, it usually isn't much more illuminating.
Organizing a golang-based project is also something that, while documented, is not front of mind for most new golang users, nor does the "beginning go" posts out there do a good job of how to lay out a project for success.
There's one thing I think that people getting started with this language should know and that's in the pursuit of getting the stuff you mentioned right, is making sure the reference material (blog post, book, whatever it is) you're reading is something written within the past two or three years. The official site really has enough that you need to know in order to have good knowledge coverage, but the module system beyond version 1.16 especially is something you need to get right and which a ton of old information is out of date on:
Is Python significantly better in this regard? I don't think so, especially with the differentiation between modules which are directories with an __init__.py and modules which are files you import directly but if not in the same directory also still need an __init__.py which has tripped up probably 80% of the people I try to teach Python to.
In Go you can at least get pretty far with a totally flat namespace and there's nothing wrong with that, up to at least 50kloc or so. That's less true in any language where files become a unit of modularization.
> modules which are files you import directly but if not in the same directory also still need an __init__.py which has tripped up probably 80% of the people I try to teach Python to.
Not necessary anymore since Python 3.3 (released in 2012).
Beginners trying this are still liable to make import cycles, which... sort of work? Depending on what you do with them? I feel like Go and Java have much better (and different) answers here; I wonder what a Python equivalent of the Java style would look like.
I've been reimplementing a tool that was done in nodejs before and ported it to golang.
I have to say that a lot of programming paradigms are different in golang, a few parts are annoying, and some parts are "getting there" with generics.
The most annoying part if you do a lot of parsing is the golang mandated rule of what is public and what is private in a package. If you want to parse lots of JSON into a struct, mess is on you, always have to implement a custom marshal/unmarshal for it.
If you always have to implement a custom JSON marshalling method, and abuse annotations for mapping upper/lowercase properties...why was the uppercase rule mandated in the first place?
I wish golang had gone for an export keyword instead. Structs would have been so much cleaner.
The second issue I have with golang is that struct properties (as all data types) aren't nullable except via pointers, which makes consuming JSON APIs a fustercluck to deal with some times. I wish there was a nullable string data type instead of having to use dozens of helper functions.
The last issue is lack of functional ideas (as of now) but they are coming. lo is a lodash inspired library that makes a lot of things easier. [1] I hope that a lot of these helpers will at some point be part of the core libraries, so that datatypes can be easily mapped, casted and filtered.
Personally I find struct field tags a nice way to encode the json fields. They also allow you to use upper case names for all struct members. I’ve never had an issue with the way json is done in golang, and I’m kind of confused by this rebuke. What’s wrong with using string pointers? What helper methods are necessary to write? This kind of feels the same as reading a rant against strict types.
I tried porting a Python utility I wrote to Go specifically because I did not want people to have to install any 3rd party libraries (in this case just one). If anything I had a much deeper appreciation as to how much Python does for you and just lets you work. I would still like to port someday. For now I can containerize my app but that would still require people to install docker and learn how to use docker.
The easiest way to do this is to use shiv[0] if you don't mind asking people to have Python itself installed; if you want a truly "one file bundle" you should use PyInstaller[1] (which bundles a Python interpreter)
You don't need docker to bundle an app with custom libraries. You can use AppImage which is pretty much just an ordinary app install rolled into a single file.
It requires a linux subsystem, true, but not a fully fledged VM. The subsystem still shares the file system with the primary OS, for a start. And while I haven't tried it, the instructions for installing AppImage on WSL (for example) don't look trivial.
MS call it a "lightweight utility virtual machine", and "not a traditional VM experience", whatever that means.
Docker also works on MacOS, with a basic linux distro running under hypervisor that again, I'm not sure qualifies as a 'fully fledged VM' (at least in terms of user access to it).
WSL, starting with v2, is a fully fledged virtual machine, and comes with its own built in Linux kernel. The 'lightweight' part is because resource allocation is bit more dynamic than your usual VirtalBox VM. Other than that, there is no difference.
I was kinda hoping an article with a headline like that would present some code and tooling and explain it in terms of how a Python programmer sees the world.
Tooling aside, Python is a more powerful language, so I’m wondering whether he started generating code to work around stuff like try/except and defaultdict and itertools and decorators.
I don't understand how the author struggled to find a good DynamoDB library. The official AWS SDK has a very useable DynamoDB client and provides utility classes for marshaling and unmarshaling Go types: https://docs.aws.amazon.com/sdk-for-go/api/service/dynamodb/...
> I hate how it forces to you create a module everytime.
This affected me recently, so I have sympathy for the author. Trying to upgrade an older project I had to the module system meant trying to find out how to import modules which don't have reachable URLs and were only on the GOPATH. At I hate how it forces to you create a module everytime. some point programming in Go stopped being for fun.
Having done both Python and Go for quite some time now, yes, Python modules are a mess, but it wasn’t so long ago that the same could be said for Go (glide-> dep -> go mod anyone else?) Go mod is finally maturing, but there are still some painful edges as well.
This roughly matches my experience, though he doesn't really discuss the language differences in this article. Here's a similar kind of article I wrote a few years ago, "Learning Go by porting a medium-sized web backend from Python": https://benhoyt.com/writings/learning-go/ -- mine focuses more on language and standard library differences.
A bit of both is my answer. For some usage cases eg cloud functions go does seem superior. Yet the convenience of hacking stuff together with python has its appeals too
I realize that Go's original release is later than Python's, but they still feel roughly the same vintage to me. Usually, these articles have a "old to newer" feel, but these two ecosystems feel just different to me. Which is not bad.
What would be fascinating is to see some HN links to articles where the journeyman programmer went backwards in time, e.g. "Learning Fortran as a Python developer" or something like that.
So the biggest complaints, from what I read here, is "it does not allow me to write bad code or make mistakes, I want something I can hack together without having to worry about conciseness", and based on groupthink "HN was negative about it". Languages like Rust and Go were designed to keep this sort of thinking away.
> The libraries for Go aren't as good as for Python– certainly, the documentation is lacking
Huh, Go has some of the best autodoc features of any language. Also the library assertion is insane to me. I switch back and forth from Go to Python all day and generally Go has more stable better maintained libs
Sadly I agree with the author on the general feel of Go libraries. I can feel the language design itself and non-written philosophical identity of Go strongly affects what APIs people write in it. Most often, they suck. They feel monolithic, unforgiving, and impossible to extend. I don't belive we can only blame the lack of generics for that, it runs deeper.
On documentation, I've never seen a language community that comes with so little examples most of the time. Take any random Python library RTD, it's full of it. You can skim through said examples to understand the overall features and capabilities before you dive into the API reference. No such luck in Go: here is the bare-bones godoc, good luck!
The bare bones godoc is generally fine because the language is so easy. Python needs the examples because most of the libraries have no types so you would have no idea whats happening without examples
> The bare bones godoc is generally fine because the language is so easy.
No, it's not.
> Python needs the examples because most of the libraries have no types so you would have no idea whats happening without examples
That’s not the main reason examples and narrative explanations in documentation are useful, but if the false belief that it is has helpe to fuel the Python documentation culture, I’m not going to complain too much.
Autodoc is great when you want to know "how do I use this function" but I find that projects that rely on it inevitable fail to answer "why do I use this function" which is usually the harder question.
TL;DR: Python is hard because of library dependencies, go is better about that because of compiling to an executable, but is pickier about code quality ("I just want to try something"), and has more issues with library quality.
I've encountered input libraries in go tha for some reason just grab all the signals and whatnot, so you can't ctrl+c, sighup, sigterm, use ctrl+z to return to the shell… the only option is to do a kill -9 from a different shell.
On the subject: What is a good, idiomatic, Go project to study? Something big enough to be a good example of code organization, yet small enough not to become a new hobby.
Go's stdlib is often given as an example for this, and I personally found it to be useful learning material. I wouldn't advise trying to study it all (it's quite big): just study some pieces of it.
> I had heard of Go for many years, but never stuck with it; it gets constant negative press on Hacker News/Reddit
I think on Hacker News it's really fashionable to criticize Go, and this has led to a culture where Go gets significantly more negativity than it deserves.
As technologists, one of our most important jobs is to see through such fashions and judge languages/tools/technologies based on their actual merit.
While gauging sentiment about things on a forum like Hacker News is generally really helpful, it should not be the main basis of our decisions.
I own a T-shirt which says "Haters gonna make some good points". People do indeed only complain about the things which are used and not the things they don't care about because nobody uses them. But, we should not think this means the complaints just signify success.
People are complaining because they care, but also because it's not good, or it's not as good as it should be.
As an engineer who uses Go and appreciates it as a replacement for most purposes where you might use C or C++, the complaints just seem bizarre.
You've got people who argue against explicit error checking and people who don't understand the important role of nil pointers and people who don't see the massive net win of garbage collection in concurrent programs, and so on.
Endlessly.
It feels like a waste of time defending the language when the people criticizing it seem to hold such a vastly different point of view. It's like trying to convince people that Natural Born Killers is a good movie or that Primus makes good music. There's an unbridgeable chasm between you and the people you're trying to convince.
I think there’s a lot of disagreements about what people think is desirable in a language in the first place and then start complaining without understanding the design concepts that shaped its creation nor even agree the problems are even problems to begin with. Many even seem to think that bad ergonomics are to be accepted and want to create a higher barrier for programming productivity (there are some merits to this attitude honestly but that’s not the point I’m interested in).
I think it’s more akin to trying to talk to people about Quentin Tarantino movies. Lots of people enjoy them, many critics like his stuff, and then there’s a relatively small group of people that disparage everything he does because he isn’t ascribed to any artistic school of filmmaking and under a lot of such critical analysis his films are pop fodder. It’s not like he ever makes his movies to please critics is the thing, he’s basically a super fan that just winged it all. Many fairly sane and measured, learned critics “get” Tarantino and appreciate him for what he tries to do and all is fine there. But it won’t matter what Tarantino does going forward with the other crowd - it’s because they have diametrically opposed ideas of wtf movies even are supposed to be.
Languages generally aren't stuck in time. If we actually want languages to evolve and in ways that are actually valuable to real people (not a small subset of those developers writing it), then these pieces should be an invaluable resource to help steer the language in the direction that will most reward adoption, longevity, etc.
Go has always been a Java, C#, Python, and Ruby killer. It has not and never will be a C or C++ killer. C is the language of libraries and embedded, neither of which Go is good for. C++ is the language of large systems that need extreme control over resource allocation. Go is not good for this either.
I agree with you that Go does not replace C or C++, but I strongly disagree that Go is an obvious replacement for most uses of Python, C#, Java or Ruby, all of which are, frankly, _much_ higher level languages than Go.
Go gets used for two main reasons that I've been able to observe:
1) a desire for a very specific type of concurrency
2) a desire for a fast compiled language with a minimalistic feature set that scales well to large teams.
Switching to Go from one of those languages is very much giving up a kitchen sink for a purpose-built tool. It may be the right decision under lots of different circumstances, but it doesn't directly compete with any of the languages you've mentioned because of how minimalistic it tries to be.
Overall, in fact, I think Go does something far more interesting: it's legitimately an attempt to carve out a whole separate niche for software development. Whether it's ultimately been successful there is for a different comment thread, though. :)
Go has always been a high level language, and is even more so now with generics. I would even argue that Go, correctly done, is halfway between the Java tier and the Lisp tier. Due to Go's quick and easy parsability, generation, and compilation. It is very easy to write tools for Go. Code generation and struct tags are even part of the standard, but very people use them beyond the basic serialization libraries. It's not quite lisp, but it is very close in many ways.
Very few people rewrite projects. Most change happens by new projects adopting one language over another. The fact that I hear of Python rewrites to Go is honestly amazing.
It is too easy for people to forget that C was not always the language of "libraries and embedded", and that writing large systems programs in C, of the sort that nobody would realistically consider writing that way in 2022, was a norm. Displacing C doesn't just mean rewriting existing C dependencies, but also changing the balance of decisions about which new programs to write in C. Go has had a tremendous amount of impact there. Without Go, Docker would almost certainly be a large ball of C code.
Is Go really killing C# though? I've rewritten Go components in C# (the initial version only had basic functionality requirements, but as they expanded, Go made less and less sense given the rest of our codebase), but can't readily imagine wanting to rewrite C# in Go. Maybe once they add proper exceptions...
My current project was switched from C# to Go almost 2 years ago. It was a management decision, and while the team all generally has found something or another to like about Go, we all miss C#.
That implies that if a better alternative to VS came along, C# developers wouldn't choose it! I certainly would, for one, and I'm a long-term VS user, well aware of its failings (but also yet to come across another IDE that's noticeably superior. And coding with a text editor and command line compiler is something I spent 10+ years doing when it was all that was available, and nothing I have any great hankering to go back to - even if it's something I still resort to as an emergency measure, e.g. when on some remote system with text-only access etc.)
The only IDE better than Visual Studio is probably one of the Smalltalk IDEs, but the languages are too niche these days. It's a shame none of the large companies wants to back them.
Some of the HN audience had already been reading PG’s essays for years, and our expectations of new languages were shaped by http://www.paulgraham.com/avg.html.
Go is a vastly preferable language to Python or Ruby for most things. The "negative press" is quite overstated, it does get plenty of favorable advocacy as well.
I don't understand the criticism on "shared environments" which the author latter voids himself, but what I do know is that Go makes a fairly good choice for extending Python, but isn't really in the same ballpark as Python.
Some thoughts:
- Go singlecore is actually slower than Python (nb Stackless[0] [still stands], but not only that: graalpython/loom is even faster, much faster)
- Prototyping is always slower in most AoT-compiled languages, obviously. I'd be more convinced to try Go if it had something like Cling[1].
- CSP is (in my opinion) less palatable than Actors and makes Go feel somewhat... dated? Matter of taste?
- Go doesn't use libc which can be awkward at times.
{kind=link}
wat? Pretty sure you can use == in requirements.txt
Also, its very possible, and quite easy to just include the code for the library in your package, which effectively "locks in" the version. We did this all the time when building AWS lambda deployments.