Beyond the validity of the statistical methods used.. can someone clarify what is the actual hypothesis we are debating about competence? And what does each article propose?
My understanding is that the hypothesis is "Those who are incompetent overestimate themselves, and experts underestimate themselves".
DK says: True
DK is Autocorrelation says: ???
"I cant let go..." says: True?
HN says: also True?
Is there really any debate here? The "DK is Autocorrelation" article seems to be the only odd one out, and it's not clear if it even makes a proposal either way about the DK hypothesis. It talks about the Nuhfer study, but that seems Apples vs Oranges since it buckets by education level. Then it also points out that random noise would also yield the DK effect. But that also does not address the DK hypothesis, and it would indeed be very surprising if people's self evaluation was random!
So should my takeaway here just be that the DK hypothesis is True and that this is all arguing over details?
DK is Autocorrelation says: The DK article is based on a false premise, we got to disregard it
"I cant let go..." says: Actually, given that we assume people are somewhat capable of self-assessment, which is reasonable, "DK is Autocorrelation" is the one based on a false premise, and we should disregard that one instead, and not DK.
> My understanding is that the hypothesis is "Those who are incompetent overestimate themselves, and experts underestimate themselves".
The DK hypothesis is "double burden of the incompetent": "Because incompetent people are incompetent, they fail to comprehend their incompetence and therefore overestimate their abilities more than expertes underestimate theirs"
Arguably the hypothesis that matches the data from the DK paper best is: "Everyone thinks they're average regardless of skill level"
> The DK hypothesis is "double burden of the incompetent"
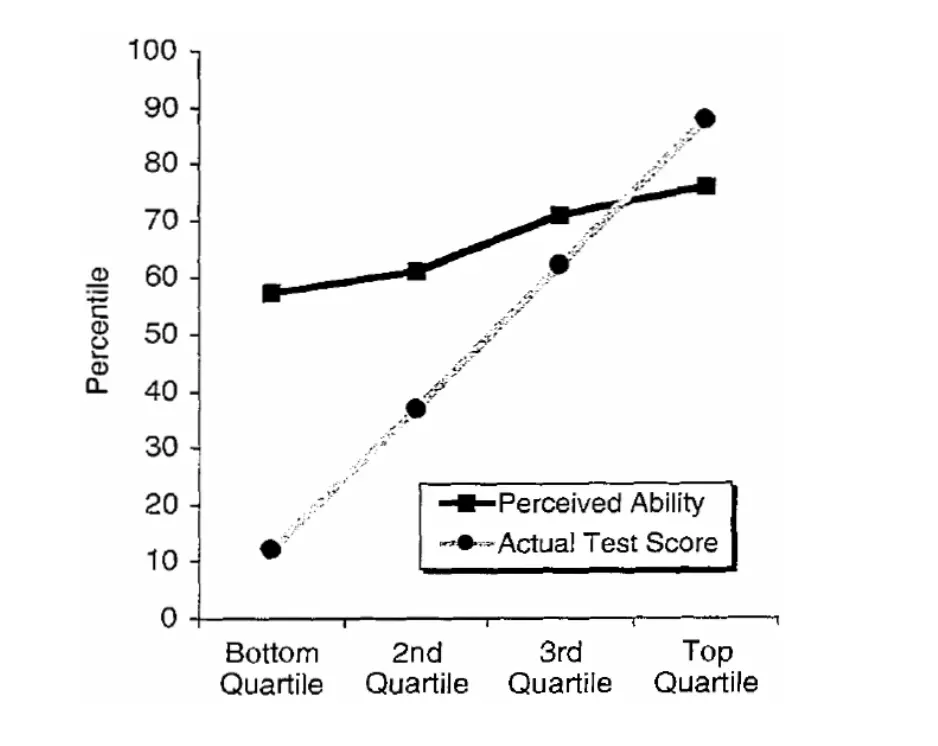
The actual DK result (which is much criticized, but that's a different issue) was actually a pretty much linear relationship between actual relative performance and self-estimated relative performance, crossing over at about the 70th percentile.
(Because there is more space below 70 than above, that also means that the very bottom performers overestimated their relative performance more than top performers underestimated, not because of any “double burden” (overstimation didn't rise faster as one moved below the crossover), but just because there was more space below the crossover point.
> Arguably the hypothesis that matches the data from the DK paper best is: "Everyone thinks they're average regardless of skill level"
If there was a perceptual nudge toward average relative performance, you'd expect a crossover at the median with a slope below 1, the nudge is toward a particular point above average.
Sure, there's in aggregate a slight positive slope to self-assessment when plotted against performance. But all of these have in common that the range of self-assessments is small across the full range of performances and they're all centered somewhere around 60.
> The actual DK result
The "incompetent self-assessment because incompetent" claim is literally everywhere in the paper. It's in the title, the abstract, the introduction and every section thereafter until the end.
>Arguably the hypothesis that matches the data from the DK paper best is: "Everyone thinks they're average regardless of skill level"
No, if you look at the graph[0] everyone thinks they are above average (over 50). The worst think they are a little above average and everyone else thinks they are better and better but increasing by less than the real difference.
At any rate, the issue seems to be with how people imagine everyone performs - they seem to think there are a lot of people who are really bad for a start, and seemingly a bit more people who are really good than there are (at least if we assume the results are accurate).
What I don't like about statistics, or rather the use if them, is the tendency to focus exclusively on them instead of treating them as the tool they are. Statistical analysis is not the subject of the DK effect or paper, it is a tool D & K used in analyzing the effect, nothing else. D&K did put more expertise, research and knowledge into their research than simple statistics.
I hate it when people are "solely2 using statistics, and other first-principle thinking approaches, to understand well researched and documented topics. And I hate it if people use solely statistics to criticize research without considering the other aspects of it. Does it mean the DK effect can be discarded or not? I don't know, I think some disagreement over the statistical methods is not enough to come to any conclusion.
Attacking the Dunning-Kruger study only on statistical grounds looks like aprime example of the DK effect in itself...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
My understanding is that the hypothesis is "Those who are incompetent overestimate themselves, and experts underestimate themselves".
DK says: True
DK is Autocorrelation says: ???
"I cant let go..." says: True?
HN says: also True?
Is there really any debate here? The "DK is Autocorrelation" article seems to be the only odd one out, and it's not clear if it even makes a proposal either way about the DK hypothesis. It talks about the Nuhfer study, but that seems Apples vs Oranges since it buckets by education level. Then it also points out that random noise would also yield the DK effect. But that also does not address the DK hypothesis, and it would indeed be very surprising if people's self evaluation was random!
So should my takeaway here just be that the DK hypothesis is True and that this is all arguing over details?