Maybe it's sarcasm, but the author seems to downplay these images. Are we really that jaded? This seems like criticizing a dog that learned to speak only basic english...the fact that any of this is even possible is stunning.
Could not agree more. We keep moving the goalposts for what constitutes intelligence, perhaps that is a net good, but I can't help feeling that we are taking incredible progress for granted. Both DALL-E and large language models (GPT-3, PaLM) demonstrate abilities that the majority of people doubted would ever be possible by a computer 20 years ago.
Imagine telling someone in 2002 that they can write a description of a dog on their computer, send it over the internet and a server on the other side will return a novel, generated, near-perfect picture of that dog! Oh - sorry, one caveat, the legs might be a little long!
True if you would have asked a nerd. If you had asked a person on the street, they would have answered, “Why, of course. Can’t computers do more complicated stuff already today?”
This isn’t true, the quality of images generated by DALL-E are really good, but they are an incremental improvement and based on a long chain of prior work. See e.g. https://github.com/CompVis/latent-diffusion
Also Make-A-Scene, which in some ways is noticeably better than DALL-E 2 (faces, editing & control of layout through semantic segmentation conditioning): https://arxiv.org/abs/2203.13131#facebook
Just about all the AI achievements are really impressive in the talking dog quality as you say.
The thing is that current has been producing more and more things that stay at the talking dog level (as well as other definitely useful things, yes). So the impressiveness and the limits are both worth mentioning.
I don’t think people are jaded. I just think it’s going to take a while for these types of generated images to pass the Turing test, and that’s why it doesn’t feel that impressive yet. It’s very clear they’re made by an AI. Which isn’t bad. It’s just obvious in a way that isn’t fooling anyone. There’s a very specific way that AI generates things like hands, other limbs, eyes, facial features etc. Whoever figures out how to fix that, and then fix the “fractal” like style that’s a hallmark of AI generated images will win the AI race. Maybe it’ll be openai. Maybe it’ll be someone else.
The images already look better than what like 99.9% of humans would be able to produce and it produces them orders of magnitudes faster than what any human could ever hope to produce, even when equipped with Photoshop, 3d software and Google image search.
The only real problem with them is that they are conceptually simple. It's always just a subject in the center, a setting and some modifiers. It's doesn't produce complex Renaissance paintings with dozens of characters or a graphic novel telling a story. But that seems more an issue of the short text descriptions it gets, than a fundamental limit in the AI.
As for the AI-typical image artifacts, I don't see that as an issue. Think of it like upscaling an image. If you upscale it too much, you'll see the pixels. In this case you see the AI struggling to produce the necessary level of detail. Scale the image down a bit an all the artifacts go away. It's really no different then taking a real painting done by a human and getting close enough to see the brush strokes. The illusion will fall apart just the same.
Given this is a LessWrong article, my default assumption would be "author is being matter-of-fact while talking about a subject they're ridiculously excited / concerned about".
I wonder how many elements are copied verbatim from the input images. Obviously, it's all synthesized from existing images, but some of these have regions that are particularly suspect to me:
DALL-E definitely does not encode the mechanics of cloth and yet there are regions of perfectly consistent geometry and lighting in the clothing wrinkles.
I have a strong suspicion once these models start getting into mainstream hands it's not going to be uncommon for people to find the input photos that were copied. What do we do when a popular image from DALL-E turns out to be an artist's existing creative work with a style transfer applied?
The AI maximalists simply refuse to entertain this possibility.
The most interesting thing about DALL-E is its understanding of the prompt, objects, concepts and scenes. Which has improved significantly but is still very far from perfect.
The rest is a rorschach test that abstracts the flaws away.
I'd be almost as impressed with it if it spewed out stick figures.
In fact I wish it had an unstylized mode, so one can more clearly see and think about the way it composites things.
Quite, focusing on the artistic merit or quality of the visual elements is missing the point. These are collages. What's interesting is the comprehension and interpretation of the prompts, the way the meaning of the visual elements is understood, and that they are composed in semantically appropriate ways.
Having said that the way the visual elements are integrated together without painfully obvious seams or blurring is impressive.
Many of the images, which are not as cherry picked as the ones promoted when DALL-E 2 was announced, exhibit obvious seams when looking closely. Sometimes it works out and sometimes it doesn't. A lot of the ones that work out actually seem OKish because the obvious flaws could be considered forms of "artistic expression". In art there are no mistakes, only happy accidents.
You're discounting the possibility that this is _all_ that intelligence is: understanding and composition. Arguably, DALL-E has already surpassed the average person's ability to create images. Sure, there are many creatives that could be a better job. The average person can't create anything that comes close though.
I'm really confused about why you think this would even be a valid criticism. If I asked you to draw clothing, do you calculate cloth dynamics? No. You would immediately look for either a real life or image example, then you would draw using that as inspiration.
Even if DALL-E was copying certain segments of an identically in order to compose new images, it is a huge advance. On top of that, much work has been done on GANs and other generative algorithms to investigate how similar output images are to training images.
I think the words examples provide insight into how the image generation works at several levels. You can clearly see [1] how the glyphs are created by approximately merging several letters in one place to create a new symbol, while maintaining the overall structure of words and paragraphs within a well-composed layout in the page.
I would say that the merit of the technique is not in generating new images, but in correctly associating the images and the concepts they represent, at the right level (art styles at the low-level pixel representation, and objects as recognizable high-level features).
I agree that it will be common to recognize where some reused elements come from, in special for small concept domains or art styles; this image generation is largely making clever collages. However, at a sufficiently fine-grained level, it is not unlike how most human artists create art.
Not in a relevant sense. When you see cloth, they don't look right or wrong based on whether you ran a detailed mental simulation, but based on how the patterns conform to the object. Plausibility is much more important than precision. There is not much reason to expect DALL-E 2 should not to be able to encode that same rule of thumb.
Doesn't this fall into the same category as DALL-E begin able to create reflections in water and smooth surfaces to the elements it adds to images? (Look specifically at the Flamingo examples on their website) I'm sure it doesn't encode the mechanics of reflections either, but considering all the other stuff it can do, I'm wouldn't be surprised if it could learn how those work.
But I'm also really interested in the possibility of finding obvious traces of specific input images on the output. The fact that "The Emperor of the Galaxy, byzantine mosaic" generates something strongly resembling Jesus may be a sign of this. Maybe someone with more AI knowledge is able to explain how possible/likely that is.
Starting a very long debate about whether human just another DALL-E or fighting on whether model just copy and change old art by some calculations... finally it just no one care, how can you catch so many people?
Amazing stuff. It’s unfortunate that you have to be a famous blogger to get access to this. It’s been said enough at this point but it really goes against the spirit of OpenAI and what they ostensibly stand for.
And that it’s crippled to be prevent expressions of concepts of violence, politics, or sexuality. Making it the worlds most advanced clip art generator instead of a revolutionarily powerful tool for artistic expression.
And before anyone even says it… obviously they have to try and prevent child porn. That’s settled US Law with regards to artistic depictions of underage sex. However everything else they are preventing (and would ban you for if they caught you deliberately found a way to trick it into producing) is protected artistic expression under freedom of speech, first amendment stuff.
While some jurisdictions, notably Japan and the US Federal level, are not legally concerned with depictions of underage sex that does not have anything to do with an incident of actual underage sex, other jurisdictions such as the majority of US States at the state level have laws that treat any visual depictions of underage sex as equivalent be they photographs of a real event or artistic depictions of completely imaginary stuff.
So while it’s a fair position to take that banning it is absurd… as a Corporation in US legal jurisdictions such as I believe California, Washington and Delaware, they will have to comply with state law regarding such matters in three separate jurisdictions, easiest way being to completely prevent the objectionable content entirely.
Certainly, I was more talking about the law itself. It seems to me that if there was a flood of fake child porn, the demand for real child porn would plummet.
The reason is that there will be more children abused. People who watch things will have a tendency to do that thing. Analogy: we had "fight club" fights outside bars 20 years ago.
I think it makes perfect sense to ban child porn, and strongly support it.
"People who watch things will have a tendency to do that thing."
Given the fact that millions upon millions of children play incredibly violent video games without feeling the urge to go on killing sprees, I'd say what you're saying is completely specious, but I can understand that critical thinking can be difficult.
In those video games people are in general playing as heroes. If million of kids where playing games where the "protagonist" was a school shooter then yes I believe we would see an increase in school shootings.
The revolutionary powerful tool for radically upsetting artistic expression will not come from a billion-dollar corporate-funded research consortium and frankly a lot of artists would have a worldview crisis if it did. ;-)
It’s probably not the same kind of worldview crisis but the fact that by massively commodifying unique (and that’s the key word since unique work costs more) business friendly corporate clip art and stock photo type content without needing anyone with artistic talent or skill, it’s going to suck away a lot of the money that would otherwise have gone to artists who otherwise don’t have a great career track as far as “average income” is concerned. Struggling artist is a meme for a reason, and when it’s as easy as “push button… receive art” it’s hard to imagine that not making it even more of a struggle. Which does feel like a somewhat incipient worldview crisis in a more career viability sort of way.
Probably not enough RAM. The page isn't doing anything crazy, but includes a dozen or so example <video>'s, which in turn can send Linux into an out-of-memory situation that freezes the system (technically it's still working just really slow). Ran into that issue a lot when browsing around with 8GB RAM, upgrading that helped. Installing earlyoom[1] is another workaround.
Thanks, earlyoom looks interesting. But as I know where my memory usage goes (Firefox, mostly) I think I'll just write a script to kill Firefox if I run out. Much better than waiting for the scheduler to kill KDE out from under me!
> That’s settled US Law with regards to artistic depictions of underage sex.
I'm not clear what you mean by this. The laws regarding CSAM vary a lot across the USA because of the different states and then federal law on top. After a federal Supreme Court ruling that virtual images didn't meet the definition of CSAM a lot of jurisdictions modified their statutes to make constructed images also illegal (e.g. cartoons like "lolicon" come under this). It really comes down to where in the USA you live, and remembering that for most Internet crimes the state can charge you and also the federal government can also charge you. I wouldn't screw with these laws either. If I remember correctly there is one US state that has a mandatory minimum of 100 years in prison for a single image.
You’re right about the Supreme Court verdict and the subsequent state law changes, which is why I called it “settled”. It’s settled in the “normal conditions” sense. There’s basically no where you could operate the servers or send it to a user where it wouldn’t probably be a violation. If you operate in the USA then your subject to that hodgepodge of state laws, which mean you just have to avoid it because it’s too big if a risk.
A true artist can express themselves without violence, politics, or sexuality. Art is about using the tools available to you and creating art. michelangelo didn’t have cad or 3d modeling programs, but he created great sculptures using the tools available to him.
It’s all well and good to mention great artists and such. But it’s a bad comparison, this is about a tool that is conceptually limited, it’s something art has never had before. We didn’t have paint brushes that wouldn’t let you use them to paint a nude portrait or spray cans that refused to let you use them do create graffiti.
This artistic tool is built to prevent you trying to create content containing certain concepts which is a fundamental new factor in how artistic tools shape the art that is created with them.
And in case my viewpoint isn’t clear, I don’t think it’s a good thing, and that we should not allow it to become normal. I don’t object to its existence, because I understand corporate politics and how it leads to this. But this sort of crippled tool has all the concerning potentials of “newspeak” in Orwell’s 1984, except to art not to language.
Blame that to the harsh criticism these models get on reception. If you say "picture of a doctor" and the output does not cover all races and genders with equal probability, then it's biased. If you say "John wants to become a *" and it fills in stereotypical male dominated jobs, then it's biased.
> But it’s a bad comparison, this is about a tool that is conceptually limited, it’s something art has never had before. We didn’t have paint brushes that wouldn’t let you use them to paint a nude portrait or spray cans that refused to let you use them do create graffiti.
But is the comparison to 'art' apt?
The platonic ideal is that this will work like the holodeck from the Enterprise, but the skill is all in the machine, there is no effort or skill for the consumer aside from the decision what she wants to see.
I can enter "monkey on a bicycle" in the Google image search and Google shows me pictures of monkeys on bikes. Dalle works exactly the same. Is Googles image search for that reason like a paint brush? Should it make illegal content available? I don't think so, it is a content service. A future Dalle-22 may be virtually indistinguishable from Youtube or Pornhub and A) it should be able decide what it wants to be and B) be bound by the same laws like youtube or pornhub.
The skill is in providing the inputs that produce output pleasing to the audience. To use another Star Trek analogy, “Tea” isn’t the same as “Tea, Earl Grey, Hot” by using more specific inputs you “cook” with the replicator.
This is the way it’s an artistic tool. You can say “monkey on a bicycle” and sure you get it randomly generating stuff, but if I ask for “capuchin monkey riding a red schwin bicycle with whitewall tires and a basket on the front handlebars” I’ve used the tool to craft a specific image I’ve constructed in my imagination, it becomes a tool to take what I have imagined and realise it, it’s an artistic tool just like the photoshop contextual fill tool is an art tool, just way more advanced.
As for future iterations… I don’t see any reason to assume that “Dall-E 22” or even “Dall-E 44” will somehow gain sentience and have tastes or be capable of deciding what content it want to produce for us. The “Tastes” of this model are determined by its training data, as is what it is capable of generating, you mentioned PornHub and that’s a great example, no matter how good the model gets at generating photorealistic things from descriptions, if they don’t include anything in the training data that’s labeled as “dildo” then the mode will have no way of knowing what to generate and will just produce randomised nonsense… so again you would be forced to use it as an artistic tool, to describe the scene constructively like they do with their dead horse example, “horse sleeping in a lake of red liquid” produced an image that looked like a dead horse in a lake of blood. If you have to do this then you are “painting” a scene by writing an elaborate description of everything in it and are using the model as an artistic tool in order to produce the visual image you want.
Agreed. The same thing happened with GPT-3. The waitlists for OpenAI products are always obscene. The TechnoSiliconValleyTwitterPersonality elites always seem to get next day access. But normal people who aren’t chronically online seemingly never get access. Not very Open of them.
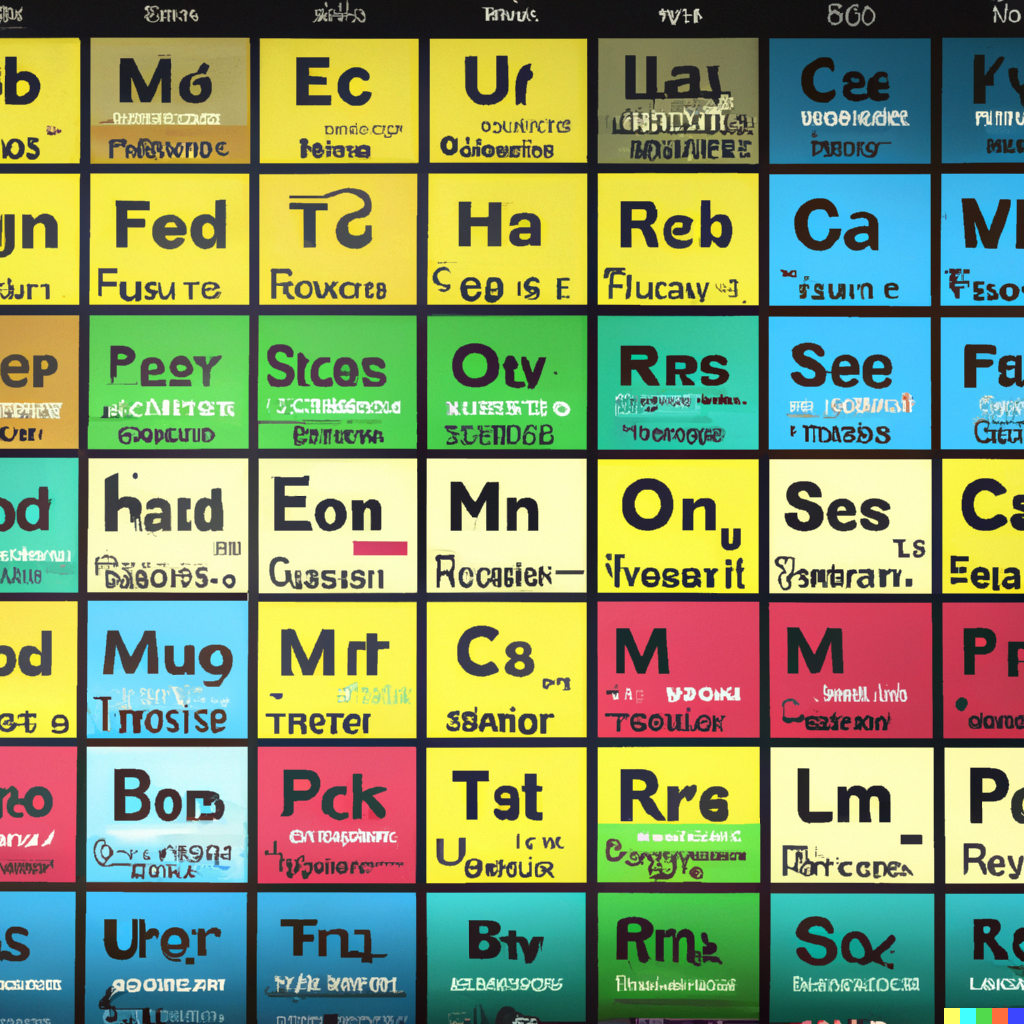
The text this generates reminds me of the kind of text you'd see in a dream. The images look real enough, and the text looks like words; but totally unreadable. Kind of an uncomfortable feeling.
It's fascinating that the system is able to generate such precise imagery, yet can't handle words at all -- it can only barely reproduce words you explicitly tell it to. But sometimes it'll adds words when you're really not expecting it, and like you said, it's uncomfortable. Like the worst uncanny valley I've ever experienced. It was so unsettling to see the "four seasons" and "periodic table" that I couldn't stop nervously laughing.
I think the words examples provide insight into how the image generation works at several levels.
You can clearly see [1] how the glyphs are created by approximately merging several letters in one place to create a new symbol, while maintaining the overall structure of words and paragraphs within a well-composed layout in the page. The periodic table [2] seems to be doing the same, where the layout is the structure of colored boxes and two sizes of letters within them.
Image composition seems to be doing something similar, learning to associate concepts with their visual representations at the right level, and merging already-seen examples in the right proportions to create a novel image. Cats and vampires are represented by their distinctive features, arms and legs are correctly positioned as parts of the body according to the action they perform, and instructions of style (either by artists like "Pieter Brueghel", art styles like "digital" or "mosaic", or even camera settings like ISO exposure [3]) are translated into lower level pixel representations of color, shapes and shadowing.
My hypothesis is that if you included examples where the letters are taught one by one, like in kindergarten primers, it may be able to learn those concepts as well and generate better painted text (although I'm not sure it could make the jump to "understanding" the relation between their role as input instructions and as output image text).
I have. You can read things while dreaming. Individual words are fine. But, just like dreams themselves, if you read more than a sentence or two, your mind will be unable to really keep a plot. And if you look away and read again, the text will have changed.
It's interesting because for me it's the opposite. I feel DALL-E 2 is the clear evidence that we're headed for the next AI-Winter soon.
Don't get me wrong, DALL-E is remarkable. But it's remarkable in almost the exact same way ELIZA was remarkable in 1966, and Markov Chain generative models were in the 1990s. All of these, given the context computational powers at the time, were both miracles and parlor tricks at the same time.
The trouble is that these demos are impressive, but not much has changed in how the world works. I work in AI/ML and every places I've seen the practical applications of these techniques has ranged the equivalent to adding sprinkles on a cake, to completely useless engineering nightmares that would ultimately create more value with their removal.
Yea, a 3.5 billion parameter model is neat, but we know that in 1970 when we couldn't imagine training such a thing. The problem is that we've made essentially no progresses other than showing when you pour incredible human and physical resources into a pot the result looks cool.
But when you do the accounting, and ask yourself "what has really changed with all these fantastic innovations in machine learning" the answer is surprisingly little.
Dall-E 2 is the type of cool that will be figure 12-3 in a undergrad textbook in 20 years. Students will go "oh that's cool" and turn the page.
I think the failures of people spouting hype and failing to deliver in ML has absolutely nothing to do with the real and immense progress which is happening in the field concurrently. I don't understand how one can look at GPT-3, DALL-E2, alpha go, alpha fold, etc and think hmmm... this is evidence of an AI winter. A balanced reading of the season imo suggests that we are in the brightest AI summer and there is no sign of even autumn coming. At least on the research side of things.
The difference between the two views could be summarized in a textbook intro from twenty years ago: here is a list of problems that are not (now) AI. Back then it would have included chess, checkers and other games that were researched for their potential to lead to AI. In the end they all fell to specific methods that did not provide general progress. While the current progress on image related problems is great, if it does not lead to general advances then an AI winter will follow.
I disagree. If we find a particular architecture is good for Chess, and another for image generation, then so be it. We would still have solved important problems. We are seeing both general and specific approaches improving rapidly. I don't think the AI winter was defined by a failure to reach AGI, but rather that they reached a Plateau and produced nothing of great commercial or even intellectual value for some years, while other computer science fields thrived. I would say the situation is the exact opposite right now.
> Back then it would have included chess, checkers and other games that were researched for their potential to lead to AI.
20 years ago (2002) Deep Blue had beating reigning world chess champion Kasparaov was old news.
Unsolved problems were things like unconstrained speech-to-text, image understanding, open question answering on text etc. Playing video games wasn't a problem that was even being considered.
I was working in an adjacent field at the time, and at that point it was unclear if any of these would ever be solved.
> In the end they all fell to specific methods that did not provide general progress.
In the end they all fell to deep neural networks, with basically all progress being made since the 2014 ImageNet revolution where it was proven possible to train deep networks on GPUs.
Now, all these things are possible with the same NN architecture (Transformers), and in a few cases these are done in the same NN (eg DALL-E 2 both understands images and text. It's possible to extract parts of the trained NN and get human-level performance on both image and text understanding tasks).
> While the current progress on image related problems is great, if it does not lead to general advances then an AI winter will follow.
"current progress on image related problems is great" - it's much more broad than that.
"if it does not lead to general advances" - it has.
A very telling example, since we now have methods like Player of Games which apply a single general method to solve chess, checkers, ALE, DMLab-30, poker, Scotland Yard... And the diffusion models behind DALL-E apply to generative modeling of pretty much everything, whether audio or text or image or multimodal.
I think you are totally, totally wrong. This is a turning point. Artificial Imagination is just going to revolutionize all content generation, arts and designing. It will expand to video/VR generation and the input prompts probably will came from realtime neurofeedback. And not to mention what fantastic tool will become to explore the humanity collective unconscious and our fundamental nature. In some way is reifying our hive mind.
These models look backwards. They mine the past of what human imagination created and produce passable composites that lack individual expression. The more they’re used, the more obvious the technique becomes and soon we’ll be tired of it.
Did you see the results? And the ones from other models like Midjourney? Many of these images are not just "passable composites" but can easily trick you as creations by human artists of high caliber. And this is only the beginning. Human artists also mine the past of the collective eons of human imagination, unconsciously. We are in many ways products of the past influencing us from the time we are born. GPT-3, DALLE-2 and the likes are not only a marvelous and almost magical novel technique, but they also have very deep philosophical implications about what we are and what is the thing we call "culture" and "language".
The stuff I see in contemporary art museums is only occasionally clearly better than what DALL-E produces. I don't think anyone would bat an eye if you put a selected collection of its images in a museum.
My guess is that human creativity is mostly just technical skill + taste + random noise. DALL-E has the first one, and we could probably approximate the last one, so the middle is the only one that needs work. It feels like that's a similar issue to how GPT often ends up trailing off. Maybe some kind of improved attention would work? Or an improved version of the sampling trick?
As far as something to play with to get interesting ideas, and to take a first few cuts at implementing them, DALL-E is great. Then let's bring the human's technical skill and ability at curation into the mix.
This was obviously the case for previous models. DALL-E 2 seems different - I’ve seen a few outputs that seem like genuinely novel creative artistic works.
When I say genuinely novel I mean genuinely novel. A trained artist can take a prompt from a person and integrate all they know from art and make something that fundamentally advances both. DALL-E appears capable of this form of creativity.
ELIZA and markov chain generators were curiosities without practical application.
DALL-E 2 is useful now. It's easy to imagine it replacing 99designs, Getty Images, and most of the digital art services on fiverr. I can't imagine what is going to happen in the world of print-on-demand tshirts.
Magazines and newspapers are regularly paying thousands of dollars for a single abstract illustration for an article. DALL-E 2 is going to replace a huge proportion of that. Not only the cost saving, but you can get an image minutes before you go to press.
Then it will be rejected by the person using DALL-E, or someone else in the publishing chain? Maybe an automated reverse image search AI?
I don't think anyone (yet) imagines all the humans at the NYT will be replaced by GPTX+DALL-E. We still have editors even though humans author the articles.
Does that exist? Can you determine how mcuch of a DALL-E picture is identical to copyrighted material? And what's the threshold anyway for copyright to apply? I'm not sure that's a process with set rules yet.
If you look closely at most of the images, they don't look quite right. There are usually artefacts, or slight misunderstandings of the brief etc. Its about 80% of the way there, but I think that last 20% is going to be a lot more difficult.
I'm sure there are some cool applications for this - maybe if you need a quick and cheap image for your newsletter, personal website or an experimental game for example.
For a serious commercial application I would think it would be easier and safer to pay someone.
> I'm sure there are some cool applications for this - maybe if you need a quick and cheap image for your newsletter, personal website or an experimental game for example.
I think this understates the market. For every New York Times article, there are millions of newsletters, analyst reports, tshirts, websites, logos, etc. Many of them are abstract eye candy and don't need photorealism.
Actually, even the high-budget articles often have pretty abstract art. I read this Wired article yesterday, and all the illustrations could easily have been generated:
Agree that we haven't really progressed past curve fitting. I'm hopeful that we'll see a resurgence in symbolic AI, rather than watching the whole domain freeze up for a few decades.
Has symbolic AI ever produced anything that really demonstrates that it's the right approach? As far as I know DNNs are still way better at symbolic problems than symbolic AI.
And calling it "curve fitting" is just disingenuous. There's quite a lot of evidence that "curve fitting" will scale for at least a few more orders of magnitude. Who knows, maybe the human brain is just "curve fitting".
> Has symbolic AI ever produced anything that really demonstrates that it's the right approach?
No it hasn't. And the problems are clear - it's impossible to express anything in the rigid hierarchies that symbolic AI requires.
Representing "Britain" in geographic, language, political and economic hierarchies does not allow a model to do any reasoning about what "British sense of humour" means.
"Softer" structures that represent concepts as a "blob" in a multi-dimensional space is clearly a better approach (aka embeddings, and the even better representations that more complex models use are even better).
Representing "Britian" as blob in a multidimensional space that is adjacent to concepts like "satire" and "surreal" as well as people like "John Cleese" lets a model reason about what "British sense of humour" means without being specifically trained.
As GPT-J[1] says when prompted with "A good example of the British sense of humour":
A good example of the British sense of humour is found in George Orwell’s novel, The Lion and the Unicorn. It’s a satire on socialism that is much more sophisticated than anything in contemporary Leftist intellectual thought. It was written during the war, in 1944. The story opens with a visit to a pub in a fictional village in England. The pub is named the Unicorn, but Orwell (or George, as he calls himself) has decided to call it the Lion. He explains:
“The Lion is a pub, just like any other pub, where people drink in the evenings, and talk about their daily business and their hobbies and where they exchange ideas, views, points of view. But the difference is that nobody in the Lion ever argues about anything. They just sit there, saying nothing, drinking nothing, not even beer. People can come to the Lion and buy beer, and leave the Lion and not buy beer. Beer is freely on sale in the Lion, but nobody ever buys it.
(One should note that George Orwell's "The Lion and the Unicorn" is nothing to do with a pub where no one buys beer. BUT the joke is kind of exactly like a British sense of humour).
The first back-prop paper originates in 1970. Hindsight is 20/20, but back then it was not so clear what will follow, just like we couldn't have hoped to see such a model even a few years ago.
About usefulness - the CLIP part of the model is a ready made zero shot image classifier. It reduces the amount of work needed for simple image classification tasks to just naming the classes. The generative part is good enough for illustrations. It will make an average web designer have the powers of a graphical artist.
Unfortunately the models are restricted and expensive today. I hope to see a real open AI initiative to train such models and share the weights, but can't hope that from OpenAI.
> I work in AI/ML and every places I've seen the practical applications of these techniques has ranged the equivalent to adding sprinkles on a cake, to completely useless engineering nightmares that would ultimately create more value with their removal.
That "count the objects" app that can tell you how many items you have in a photo seems like a very practical application that wasn't possible with traditional CV before ML.
"count the objects" is an interesting example to choose, it brings to mind the 1962 analog computer called "numa-rete" , composed of a grid of photocell nuerons (physical circuits) that works in parallel to instantaneously count the objects sitting on its surface.
Not far off from image recognition, save for the background segmentation ;)
If that worked well you could skip annual inventory, on which many companies spend huge amounts on. If you could just have a robot with video driving through the aisles of a supermarket to detect the number of items, misplaced items or expired items, that would be a huge value add and lead to less waste. But I doubt we're there yet.
"Attention is all you need" was published only 5 years ago in 2017. BERT in 2018, GPT-3 in 2020. Now DALL-E, PaLM, LaMDA, etc. The pace of AI progress is frighteningly fast. I really thin it's plausible that by 2030, AI is writing and debugging most code, and engineers basically become spec writers who manipulate prompts, generate code, and verify. Essentially, project managers whose "team" is a bunch of LLMs.
It really doesn't seem we've hit diminishing returns on LLM model size yet, and that's not accounting for the multi-input types where video, text, audio, and more are being fused together.
90% of work used to be farming. Today 10% of people are farmers. The next big thing was factory work. At first looms meant more textiles, not less workers. But eventually we hit the transition point where there's actually less factory workers. Now we've moved on to "knowledge work". Sure the effects of automation make more complex knowledge products and jobs for now, but once the automation becomes advanced enough, jobs in the field go down not up. So what comes after knowledge work?
We can't have it both ways. We can't pretend like automation will never kill our jobs while simultaneously pursuing the dream of permeant vacation through automation. The very goal of automation contradicts the idea that we would and should always have jobs.
If we produce enough of everything with less labor, each individual will work fewer hours to get all of their needs met. And that would be a good thing.
But we are very very far from that point. We have needs, like extending our life, that current technology cannot meet, and if we had excess time, most of us would trade it in exchange for more technological progress toward that goal. Fundamentally that is what's behind the increase in healthcare spending, and the growth in people employed in healthcare.
>If we produce enough of everything with less labor, each individual will work fewer hours to get all of their needs met.
No they won't. If people work fewer hours, they'll simply be paid less, barring legal limitations like a minimum wage. Meanwhile, costs will remain the same.
People are paid in goods/services, fundamentally. As production per hour of labor increases, so does wages, since there are fewer hours chasing more goods.
Yeah plus these haven’t been trained on multiple epochs and DeepMind just released Chinchilla which implies we don’t need to scale up as much as we have been wrt parameters. Also last month Microsoft published a paper demonstrating deep transformers. We may get to expert level performance on these without any major breakthroughs imo.
You'd still need to translate business requirements into exact requirements. For me, that's 90%+ of programming, and basically the job of a programmer. Technical details can already be abstracted away with libraries.
My productivity has definitely been increased by Copilot and there's potential for more increases, but I don't see where that would replace the programmer.
I am stunned by these results and I find it absolutely amazing, but somehow this also makes me kind of sad. So many things we consider worth learning are loosing their value with these advances. It really makes me think if I should stop trying to improve my skills, because in maybe 20 years there is not much left what can not be done better by a machine. :/
DALL-E has been trained in the styles of creative humans. It can mashup the content that it has been fed but I haven't seen it create a new style of artwork like impressionism or pop art that it hadn't already seen as examples. It also has no understanding of what is generated. We are impressed as human observers because it appears to understand the task we presented.
Zero. But I did read the research paper, web site and viewed the web site mentioned in this hacker news post along with the samples. I've worked with lots of machine learning models and tools and understand the underlying design of the system. You can't ask Dall-E to create a pop art picture of Corgis if you didn't train it on images of Corgis and pop art. I'm not downplaying the achievement of the system that creates an incredible connection between the input images and the text descriptions. But.. at the end of the day. It is not creative in the same way humans are creative.
That’s just begging the question. We don’t know if DALL-E is creative in ways isomorphic to humans. It might be. How would one go about structuring a hypothesis? Have you read the original DALL-E paper?
I think it’s vitally important to distinguish between skills you do for fun and skills that earn you a living.
For job skills to earn a living, you should definitely be paying attention and adjusting in order to future proof. Learn skills that will not become obsolete.
For skills for fun, don’t bemoan the fact that an AI can do it better. There is still inherent value in you learning and enjoying how to paint. Not everyone needs to be the best in the world. It would be silly to say “I love baking cakes for my family, but there’s no point because of British Baking Show.”
Compared to people who lived before the widespread adoption of calculators, you should probably limit how much time you spend getting good at calculations on paper and in your head, yes.
The point in life has never been to be "The best" (if it is, you've always almost certainly been bound to fail); it's to enjoy life while doing your best, enjoying the experience of life wisely. It actually makes me hopeful people will be driven to finally realize this when we're close to obsolescence in terms of abilities, and then we maybe can progress as a civilization toward a better society (using the newfound abilities).
I don't know--I'm super optimistic! Not only is it incredible in a way I haven't found technology incredible for a long time, but it has the potential to disrupt and simplify the hugely labor- and talent- intensive creative process.
Today, if you need a logo made or some clipart for your web page, to do it the correct, legal way, you have to either get lucky with some stock artwork or scout around for an artist, evaluate portfolios, select a few and buy some samples, decide on one and iterate back and forth until you have something you like. Then you have to have legal agreements in place, make sure rights and copyright and royalties and all that shit is decided, be careful about how you use that art (do I have the rights to put it on a billboard too?)
Imagine a far future where any creative work can just be freely generated with a text description, and the output is unencumbered by IP rights. Type something in and get an infinite scroll of outputs, select one, and you're done.
Extend it to all sorts of media: Music! "Two minute upbeat song about lawn care, jazz style." Out pops an infinite scroll of jingles. "Lullaby for 2 year olds about dogs." "20 minute opera in German, about cycling, in the style of Mozart." Movies! "Three part superhero series where the main character walks backwards." "Romantic comedy but with talking turtles." "Sci fi movie about underwater colonies with a shark villain."
This could be the future if intellectual property lawyers don't fuck it up with artificial scarcity and "digital rights" like they fucked up the copying of bits across the Internet.
The output of an ML model isn't clearly unencumbered by IP rights. There's already prompts to DALL-E that clearly output a copy of a Wikipedia image it's memorized, and the publicly available smaller models have lots of prompts that output images covered in literal Shutterstock watermarks.
This isn't real AI and it didn't come up with these images by imagining them. It's a blob of every image on Google Image Search stuck together in a way that's managed to differentiate between them (in the calculus sense).
AI is some weird infinite mirror to existence. I think we will give birth to general artificial intelligence at some point but I’m thinking it might be stranger than we can possibly comprehend.
The image to the prompt "A dog looking curiously in the mirror, in digital style" shows a cat looking into a mirror and seeing a dog as itself! Although very creative and "objectively funny" (may cat is like a dog!!!), I think the AI understood "A dog looking curiously (is) in the mirror".
These poems are absolutely hilarious also, it's photo-realistic, but the messages make no sense, though the fonts look so perfect! That's where you know it's clearly AI generated ^^ For now.... Sometime soon it looks like realistic pictures of protests are going to be so easy to generate with arbitrary text
Your comment is going to be misinterpreted without the context :
DALL-E 2 failed all the "X looking curiously in the mirror, but the reflection is Y" tests - showing X as the reflection instead, Dave Orr had to do some "hinting/editing" to achieve this :
> Here's one where I edited out the cat in the mirror and changed the prompt to be about a dog, and it did something sensible.
The cards that aren't cards in "dogs playing poker" look like the wrappers booster packs for CCGs come in.
The inability to spell words is because they're using BPE instead of actual text inputs, so it doesn't actually know that words are made out of letters.
I dunno, the networks are sophisticated enough to make anatomically correct things, seems like it would make sense for real english words to crop up as well unless OpenAI deliberately nerfed that.
Can anybody explain "Gollum writes his autobiography"[1]? The images themselves look extremely well "rendered", good lighting and all and they capture the description quite well. But the "Gollum" in the images doesn't look like any common version of Gollum I could find. Google Image Search and most other places are completely flooded with the movie version of Gollum, which looks very different. There are animated versions that look a little closer, but nothing I could find looks like the images produced by the AI.
I'd love to search through the training data to figure out what is going on here, but apparently that isn't public available either.
They did some filtering to make it difficult to generate certain things like people, celebrities, nsfw, etc. This has unpredictable consequences on downstream tasks, particularly if the filtering is aggressive and removes false positives.
Yes, here is a possible explanation: it face swaps.
Some observations:
Note that the writing utensil is always in the right hand. It is more evident after the first image that it is neither a pen or a feather or anything like that but a whispy blurry line that goes nowhere.
The book pages are always blank.
All the creatures are green and in the same pose.
The arms are wrong and often disconnected from the hands.
I believe the way to look at DaLL-E 2 output is to break the prompt and the resulting image into distinct concepts/layers.
Each layer is cribbed from some pre-existing image. Hands from here, arms from there, head from Yoda, swap the face. Blur everything together with a style transfer.
Finally will a next generation Spielberg be able to create a complete film using these tools sometime in the near future..
FUTURE AI: generate the film "E.T. as a comedy with a female protagonist, and the alien should look like a yoda, set in the 1960s" -or maybe we upload a film script and the AI will generate the movie in "Spielberg style, or Scorsese Style etc"...
finally the porn implications are worrying.. how will we ever control this?
I (and many others) have kind of soured on that one after the authors' actions.
First off, he fine-tuned the model on text from an online writing/fan fiction site without permission at all. That would in itself be dodgy enough, but if you know anything about these sites, you know there's a lot of pretty dubious sexual stuff there. And it's not as if he didn't know, because he used only a subset of the stories, he must have picked them himself.
But then, when the AI started generating stuff that would be illegal if it had pictures and OpenAI caught wind of it, he blamed his users, threw them to the wolves to stay in good standing with openAI. He would even ban people for what the model did, i.e. even if their prompt had nothing sexual in it, you could get banned for the smut-finetuned AI taking the story in that direction on its own.
Anything based on OpenAI is going to run into situations like these, they are terrified of bad PR.
My theory is that the model would not generate new faces, but rather "copy-paste" faces it has seen in training. Therefore, if someone generates "famous person doing bad thing" and publish the results there's a non-insignificant chance of a lawsuit. And even if the person is not famous, putting someone's picture on an image could very well be a privacy violation in many jurisdictions.
I assume the risk of giving the possibility of generating "person of group X doing something bad" ?
Or more prosaically, we're MUCH better at noticing something wrong in humans (especially faces !) than in, say, puppies, so that would make DALL-E 2 look bad to an uninformed observer.
You can easily pass the 'look good to an uniformed observer' test with human faces. Remember, faces were something GANs were doing near-flawlessly back as far as ProGAN all the way back in the dark ages of late 2017. (Then StyleGAN did non-photograph faces, like anime - see my ThisWaifuDoesNotExist for a demo of that.) Doing them as part of a larger composition, where the face is a small part of the images and may vary much more than in closeup centered portraits, is harder, but take a look at how Facebook's DALL-E rival Make-A-Scene does it: https://arxiv.org/abs/2203.13131#facebook They specially target faces as part of the training process, with face-specific detectors/losses, and so the faces come out great.
Since you know that training for photo-realistic faces is going to take extra effort, and that you're not going to allow them - you could just spare that effort ! (Or maybe leave it for later, if the network is flexible enough ?)
less exciting: they put their brands in the blacklist
they wouldn't want Dall-E's name plastered next to some harmful/offensive content. or generate uncontrolled PR from stupid meme articles. wouldn't be a bad idea to chuck all the companies names/brands in there. wouldn't be surprised if "OpenAI" and "GPT-3" are banned too.
based on the comments, the policy violations cover a lot of territory - covid, explosive, nuclear war.
one commenter said that "glass of guidelines" violates the policy, which is a nonsensical statement. suggesting either "guidelines" is a banned word. Or, maybe they have a content policy classifier, in which case a bunch of random stuff will probably trigger it.
_for sure_ they're not worried the "AI might visualize itself", that's not really a thing
No, almost certainly not - it's very heavily censored. So far I haven't seen anyone successfully generate anything you could call erotica. (One interesting consequence: the anime is not very good and it can be a struggle to generate anime at all https://www.reddit.com/r/AnimeResearch/comments/txvu3a/anime... )
If you mean just could such a model architecture be trained to generate furry erotica? Yes. Erotica, and furry art in general, in Tensorfork's experience, tends to be somewhat harder than regular images because of the more chaotic placement of everything such as limbs, but not that much harder. You might need half again as much compute to get equivalent quality results, perhaps, but probably not, like, 10 times as much.
If this is the same old CLIP model, I tried making anime with CLIP+GANs (usual prompt "chitanda from the anime hyouka") and it got the hair color right but nothing else - seemed to have first page of Google Image Search level knowledge.
There have to be a lot of limits once you get far enough out of its training data. Even if you could guide it by image prompts, it has to know what that image is meant to represent.
Also what most people mean by "anime style" isn't anime style, of course - they actually want one of Avatar-type cartoons, advertising key visuals, game characters, or pixiv/DeviantArt fanart. None of that is drawn the same way as TV anime.
They trained a new noise-aware one on the same dataset, I believe. The CLIP is frozen though in the second stage where they train on a cleaner dataset for the image generation via diffusion conditioned on a CLIP image embed.
They get the image embed from another model that can predict image embeds from text embeds to encourage generalizing when sampling.
It does suffer from some of the same issues with binding attributes and counting stuff, as far as I can tell. But that's not necessarily related to its ability to compose concepts.
I'm curious, how expensive is it to train these models? I wonder if it would be possible to crowdfund the training, especially if targeted at a group that is (at least stereotyped) as spendthrift as furries.
AFAIK the costs have not been published, but assuming you'd have access to the data (which is tricky, and getting an different, equivalent dataset may involve lots of time/effort/legal issues/cleanup work), my estimate is that the compute for this would cost in the ballpark of $1m-$10m.
But if you don't want a universal model but just a specific niche (e.g. furries) then you should be able to train a much smaller model on much less data and get something interesting much cheaper.
Could DALL-E 2 be used to make a series of images of the same character doing different things? Like, if you wanted to make a childrens book about Bobby the 7-eyed giraffosaur's trip to the store, it would be weird if the character looked different on each page.
Woah, plenty of fresh NFT material :) Go mint and sale, big business ahead ! Will sale like "some original DALL-E images, be the first to own this unique AI art"
You can effectively use it to make it sound like every other side is unbelievable, or just to tire people into giving up, or get past spam filters by generating better than ever nonsense.
And the in-group will take it as a point of pride to believe lies from their own group anyway.
I think the bigger danger is the speed that people will be able to fabricate 'evidence' to support a false narrative faster than photographs of an event can come in.
The first images of a news story available could be fabrications.
What if news organizations were able to put pictures of Saddam's WMDs (that remember, never existed) on frontpage stories while the executive was trying to manufacture consent for entering a war?
I feel like the human brain is going to have a hard time being skeptical of fake news when fabricated fantasies can be rendered realistically.
> What if news organizations were able to put pictures of Saddam's WMDs (that remember, never existed) on frontpage stories while the executive was trying to manufacture consent for entering a war?
Then the outcome would be... exactly the outcome we had anyway, which was the OP's point. You can already lie with images with Photoshop. It's a little more work, but you can probably still hide it far better than you can pass off a DALL-E generated image as real.
Lying with images isn't the problem. Telling a consistent lie, getting all the details right even when new evidence comes in, that's a problem, and this sort of AI doesn't help with that at all.
OpenAI is so hilarious to me. It's like if MADD pivoted to being a business that hacks people's car breathalyzers for them or something. Like just admit you aren't primarily about "Trust and Safety" and "AI alignment". You charge people for a language model that loves to say the N-word! lol
{kind=link}
{kind=link}
{kind=link}
{kind=link}