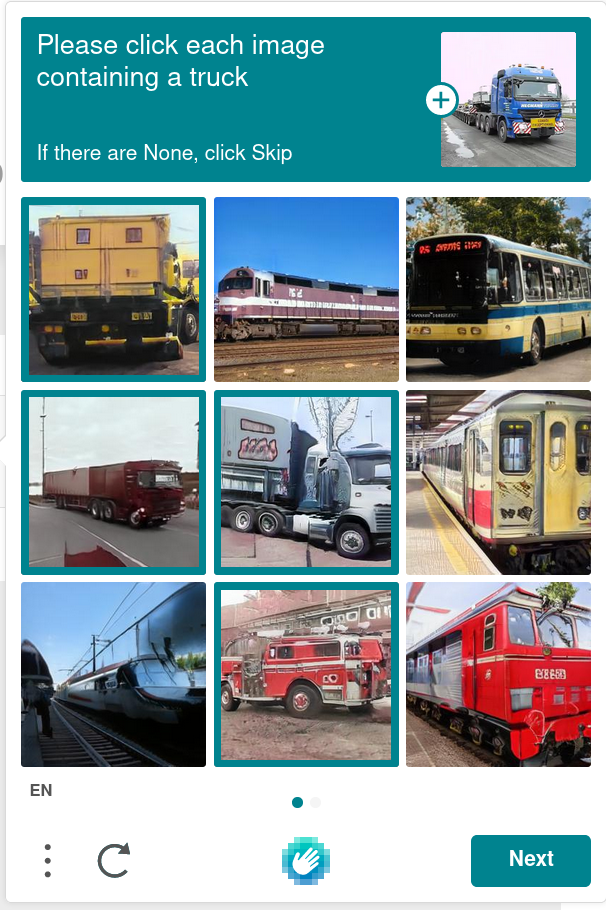
It seems all the hCaptcha verifications I receive are for buses, boats and trains? They don't seem limited by geography or by recency. I'm curious why these particular artifacts and whether this has always been the case.
First, I’m going to teach you to fish. Go to hCaptcha’s website, then scroll to the footer. Click around on the about links. It’ll reveal their business model. This trick also works for other businesses and NGOs.
Now, if we look at https://www.hcaptcha.com/labeling we can tell they make money by labeling data sets for a fee. So as a guess, there’s someone out there that needs to improve computer vision detection of transportation vehicles. My guess is it’s a self driving car company, but who knows.
Many a time I receive multiple challenges on a site despite having selected all images perfectly, and can't help but wonder, "Hey, are they getting me to do more work than necessary because they're running behind on their labelling backlog?". There's definitely a conflict of incentives in this case. If you're a website owner, you're better off choosing a different service which doesn't have adverse incentives, otherwise it can affect your site experience. And please don't put captcha on GET requests. Use a CDN if you're unable to handle bot load. And don't even get me started on CDNs that throw captcha.
I've found it isn't about "perfection". It is about selecting the same tiles as an "average" person would. I might stare hard at an image, think that one of the tiles contains a tiny fragment of a traffic light, and select it. That isn't what most other people have already done, so the captcha thinks I'm a bot and gives me tougher and tougher challenges. Ever since I stopped pixel-peeping and started quickly selecting the tiles that obviously had a bus in them, the percentage of time that I've gotten by first try has gone way up.
I wonder if this means self-driving vehicles' detection of important traffic features will be at the level of an irritated and disinterested web user who is trying to just do the minimum work to please an algorithm.
Yeah, it's not like they will label something a train just because a single person says so. But if you have 10k responses with 95% confidence saying it's a train, it's very likely to be the case.
For unambiguous images almost all humans will label them the same way. For ambiguous ones humans will differ. Presumably they'll accumulate stats on each image and will be able to detect cases like this.
unless a properly obfusicated bot net has seeded the data set with -everything is a train- responses to the tune of >>10k responses with 95% confidence saying it's a train<<
I was always tempted to knock on people's driver-side windows when I saw them looking at their phone. Never did - figured they'd probably startle, with a non-zero chance they'd accidentally fling the car into me.
I yell at them. Loudly! Loud enough that people a block away turn to look.
But then, when you're staring at your phone while driving your car out of a parking lot and across the sidewalk where you only miss hitting me (before driving into oncoming traffic!) because I stopped, well you deserve that minor inconvenience of being embarrassed.
Sometimes the bus/boat/truck has motorbikes sometimes bicycles. Is that a petrol-powered bicycle, or a motorbike to the [USAmerican?] person who wrote the rules!? Are all large yellow vehicles buses in USA or do you have minibuses, oh wait, are minibuses buses.
I've worked out fire engines are trucks for captchas, not sure about Transit-type vehicles, lorries are trucks apparently but goods trucks on railways are not trucks!
Is a traffic light only the lens/led array or the black light-holder too? Do pedestrian lights count as traffic lights? Are those weird lights hanging in the middle of junctions 'traffic lights'.
Wish they'd just tell you what counts.
I have noticed that times I realise after clicking that I missed a square they tend to go through whilst many times I get repeated captchas when I know I got it right. Success, as a user, seems impossible to predict.
a computer "hemming and hawing" as that one accident where it couldn't decide if it was a bicycle or a person has nothing to do with the training. It's what the developers decided to do with input that had a low confidence score. There will ALWAYS be low-confidence ratings on real world data regardless of how good your training is.
Instead of saying "oh crap there's SOMETHING there we should stop" they said "huh, no let's loop on testing it until we figure it out or run it over....whichever comes first."
I kinda go the other way -- could a FFT heuristic mistake this feature for a crosswalk? Then I'll select it, whether or not it's actually crosswalk. Most of the time, this works. It's a stick in the eye of our prenatal robot overlord.
Replying to an_ko's sibling comment:just like the data behind youtube music recommendations, populated by data carefully analysed from legions of bored toddler clicks vs. Spotify's obsessive teenager music curation
Same experience. Once I observed that most (about 9/10) times there are only 3 tiles to select, I stopped looking for a 4th and selected only the 3 most obvious.
I've noticed similar. Often with stop lights, where a tiny sliver of one does not neatly fit in the frame, spilling over ever so slightly to the next square which has no stop light otherwise. There's a none too subtle irony in that one is being punished for accuracy when the context is ultimately public safety.
This. Captcha wants me to choose crosswalks and you can see there’s that sliver of a crosswalk in a few pixels off in another tile. You’re not wrong! But you’re not right. Regression to the mean.
A hexagon would be better as a frame instead of a square.
Google is _the worst_ for that. At least hCaptcha is a bit less culturally specific.
Every time Google blocks me for refusing to label a motorbike as a "bicycle" I get utterly pissed off. And likewise with the traffic lights on the californian skies. Are the traffic lights the actual lights themselves, or the boom holding them up?
I'm not a human very often, according to Google. hCaptcha tends to let me in...
I recently failed a google-bicycle captcha.. "you can't fool me, that's a motorcycle not a bicycle!" I thought.. and then had to complete 2 more challenges. Including a cross walk one where one of the images was just asphalt and painted lines (no context/edges so it could be a parking lot, and airstrip,a highway, an intersection, or a cross-walk).
If Google says you're a robot, it must be true! You should behave accordingly.
There's actually a comic strip in the newspaper going through this storyline right now. Brewster Rockit: Space Guy! was told by a CAPTCHA that he's a robot, so he's going through life that way. The other robots do not seem to be happy to have him as part of their culture.
Sorry, but Google captcha is specifically designed to annoy real people in some cases. They literally implemented slow fade-in / fade-out for images. This does absolutely nothing against actual bots, but annoying as hell for a real person.
I thought the fade thing was specifically to trip up bots. Like bots know what the picture is long before it is shown to the user, so if the bot clicks on it then the CAPCHA knows something is up.
Easy for a bot to fake that with a random number generator. If nothing else bot authors can collect their own statistics. I understand the bots have an army of people in the background for images they don't understand yet, just collect timing data from that set and have your random number generator emulate that timing data. (I'm guessing a bell curve)
Honestly, that service looks like something I'm almost tempted to pay for myself. $1 per 1000 recaptchas is a lot cheaper than how I value my time, at the very least. It's not like google couldn't pay people to do these ML training datasets; I resent giving them free labour.
Unfortunately I doubt that "recaptcha solver" can be built as browser extension. Most of advanced bots for parsing automation built on proprietary platforms like ZennoPoster and they basically heavily modify Firefox / Chromium.
Also latency of human-recognition service is quite high so while you wouldn't need to solve it you'll need to wait for number of seconds anyway.
Few years ago back when I created such bots I had similar idea .
For certain this can't be mainlined. And if we talk about extensions then at least in past extension code didnt have enough capacities to automatically bypass recaptchas.
This would require fake mouse pointer control and it's obviously not one of features that extension api expose.
You dont need fade-in / fade-out effects for rate limiting.
Bots are obviously get to see images instantly once they're returned by the server as they dont need to wait for fade-in to complete. Because bots API is injected into browser internals instead.
If rate limiting is needed there is always CloudFlare way where you're literally show user "wait" and refresh page a bit later. This is annoying, but nowhere as much as reCaptcha fading is.
people tend to have very different experiences with google captchas based on how normal they are. if you block everything and try to anonymize your browsing as much as possible and otherwise do everything you can to look like a bot, you're going to get a very difficult captcha to somebody with all their browser settings on default.
Yup. This reminds me of the ‘introduction’ of an old hacker simulation game from 2004 that was quite prescient.
“ In the year 2012, the corporations of the world paved over the Internet, designing their own network system. Keeping the same name, they developed a system where every piece of information was audited and paid for before it was passed on to the world at large. Those who still followed the ideology of an open and uncontrolled Internet gathered what resources they could and formed the SwitchNet. Build mostly out of discarded technologies and backdoors in the current Internet, it allowed some manner of uncontrolled communication around the world. The "Hacker Outpost" is in need of new recruits to perform missions in information gathering against the corporations, which will allow them to increase the presence of the SwitchNet in the world.”
And the slightly different press release one:
“ In 2012, a new Internet was introduced--one that prohibited users from posting anything on personal home pages, prohibited them from using software of their choice, and from having an e-mail address. Having no place to stay, hackers created the SwitchNet, an underground network operating on the old wires and infrastructure of the original Internet”
Don't forget that Recaptcha magically works better in Chrome, and even bettery-better if you're logged into a Google account. In FF (with tracking protection) you can expect to see the enforced wait and "Please try again". Honestly, it's awful. Half the time I have to second-guess what the average American would think which of the (noise-added, corrupted) images matches the description.
Your comment suggests you would exchange money for an assassination. I know you are joking (right?), but this is not something that you should joke about.
Shouldn’t do this no matter what ofc. But why the devs? Sure the devs are well paid and privileged. That’s mostly relative to others in society. They are still more cogs than anything.
Easier target, a couple of google devs hanging on a public square would do much to disincentivize others from working on similar products in the future.
At least executives can dream of hiding behind private security, for mere developers earning 300k/yr the situation isn’t so rosy.
It wouldn’t really disincentivize that much. You aren’t grasping the status quo and power dynamics of all of this. Double that $300K and even i would strongly consider risking my life for that amount of money for some time. That money is peanuts in the scheme of things but is enormous to many, many people.
Seriously. If Google doubled that money and the only way for me to be safe would be to stay in some glorified prison while working, I’d probably do it for a few years.
All you’re doing is pointing out how bad the power dynamics are and attacking the weakest and least powerful parts of said dynamics. When there are so many simple ways to get around this sort of scheming. Mine is one example. When you’re talking about cogs. It is extremely easy to replace them. It is sad you want to attack the working class (in this situation it’s privileged workers making a lot but in terms of the system, they fit into this).
I've noticed that some sites deliberately do this or have lousy code that fails to properly acknowledge captcha completions.
Take archive.is/archive.fo/archive.today, for example. If you're using Cloudflare DNS (1.1.1.1) or iCloud Private Relay, and you visit https://archive.is/, you'll get what looks like a Cloudflare screening page. It's not, though: that page is part of archive.is and is served to Cloudflare DNS users (which includes iCloud Private Relay users)--the use of reCAPTCHA in place of hCaptcha is a giveaway. You can complete the captcha as many times as you like, but you'll never get in.
And how many times have we completed a captcha on a form only to have it throw another captcha in our face without so much as an error message? Sometimes it's just lousy code.
If anyone wants to see that, try launching the browser via Selenium. I used to do that to partially automate some activities, such as download bank statements. I'd have my Selenium using script open a browser and go to the bank, then wait for me to login and get to the account page.
I'd login, dismiss any popup or interstitial promotions the bank decided to give me, get to the account page, and tell my script to continue.
My script would then use Selenium to click the download button, click the "custom date range" radio button on download popup, fill in the range fields to cover the last 60 days, pick OFX for the download format, and start the download, prompting me to let it know when the download is finished.
When the download finished, I could then go to one of my other accounts at that bank, tell the script I'm there, and that one gets downloaded, and so on.
My bank isn't giving CAPTCHAs so that would still work if I were to get around to updating my script to deal with some redesigns they did of their pages which broke finding the relevant elements on the page.
But I've found that if I do visit a site that uses hCaptcha while using the Selenium launched browser, it seems to get stuck. Click to tell it I'm not a bot. Then get an image test. Answer that correctly and get another image test. Answer that correctly. Then it goes back to the click if you are not a bot thing, and repeats--two more image tests and back to the beginning.
Here's a program if anyone wants to try this and has the Selenium Webdriver package for Python3 installed. This will open a browser and take you to fanfiction.net. Trying to actually read any story will bring up the CAPTCHA.
#!/usr/bin/env python3
from selenium.webdriver import Chrome
driver = Chrome()
driver.get("https://www.fanfiction.net")
input("press enter when done")
driver.close()
driver.quit()
I'm not sure if the looping is a Cloudflare thing or a fanfiction.net thing, because the latter is the only site I use that has Cloudflare's CAPTCHA.
you could get past the CAPTCHA, but that stopped working a while ago.
There's this project to provide a Selenium Chrome driver that is supposed to not trigger anti-bot detectors [1], but it still hit the CAPTCHA loop when I tried it.
fanfiction.net has also simply broken the Calibre FanFicFare integration thanks to their CloudFlare shenanigans.
The workaround is to simply visit all chapters separately and then point Calibre at the Google Chrome cache folder.
So nice going there, fanfiction.net. Instead of offering a 1-click .epub download like AO3 (which is completely CDN-able with a very long TTL), you now had to serve 50 individual requests. Great engineering work there.
(Obviously they do this to serve ads on every request)
AO3 is OSS and vastly understaffed. Having worked on some of their tickets, IMO they could use 20 contributors working part-time for a year or two to stabilize it until the idea of useful new features becomes viable.
I strongly encourage anyone with Rails experience to contribute [0]. There is a giant test suite which definitely helps with stability. The ticket time-to-resolve is simply quite slow due to the above-mentioned understaffing, so don't be discouraged!
Yeah there’s lots of detect and anti detect stuff going back and forth. It’s pretty silly and frustrating for situations like yours. Doing things for yourself to speed up mundane life things.
There’s so many anti-detect libraries on GitHub these days. Wonder how many work well.
I believe this is done to get answers for unsolved captchas. For example, I have a million photos of streets filled with cars, buses, motorcycles, streetlights, and crosswalks I want to add to my captcha database. I don't want to categorize them all myself, and I want the answers to be what the average person will identify, not what I or a machine will identify.
So, I send everyone two captchas. One has a known answer and is required to be correct to access the service. The second captcha answer isn't yet known, so it doesn't matter what the user selects. However, when they get the known answer right, we log their answer for the unknown captcha. Once we get a large enough sample, we then have our top answers for the unknown captcha and can start using it for verification.
I always assumed that's how it works so would do the first correctly and random clicks for the second. This is as I was uninterested though doubt it is still that simple.
I wonder, what are the minimum number of labels per image to ensure clean data?
I have found many times that if select an incorrect tile and then unselect it before submitting, I am not presented with multiple challenges. My guess is a bot would not exhibit this behavior.
Usually in those cases, even if you make mistakes they get accepted. The larger the clicks, the less annotated / voted those images are, thus less severe their penalization method for wrong markings. I have observed sites that newly introduce such captcha basically accept if I just click 1/3rd of the right answers. Don't click the wrong answers as they are fully/partially introduced on purpose. It's just that you don't have to click all right answers.
That looks pretty easy for machines. I wouldn’t be surprised if CLIP could solve that out of the box. (Then again, I guess the same applies to “select all the traffic lights”)
yeah you won't be loving this one where they make you do 10 in a row and if you get one wrong you start again with 11 this time. also it'll fail you at random
When they start doing captchas along the lines of "check all pictures of potential terrorists" we'll know they're training data sets for military drone manufacturers.
That wouldn't work well. I was in Texas during 9/11 and they were firebombing all the hispanic people's cars because the locals don't really have a good eye for different ethnicities. Its pretty much black/white/terrorist and hasn't improved all that much in the time since.
Austin has grown a lot since I lived there are a lot of people from outside Texas have moved there so I'm sure the culture has changed - but when I was there going from north Austin to south Austin seemed to be this epic trip the locals would only do on a weekend -- and probably pack water and sandwiches for the drive across town. A really exotic senior trip "abroad" for students might be to Houston or Galveston. You probably met your future spouse in grade school. Not very worldly.
This sounds nothing like my experience living in Austin 2009-2017. In fact, this is unrecognizable.
> they were firebombing all the hispanic people's cars
Weird. This is sort of unbelievable. I think I know many Hispanics who lived in ATX during 2001, but they’ve never mentioned their car being firebombed.
Not sure how serious you are, but on the chance you are...
The meeting spouse in grade school/not worldly typically implies not leaving the area they grew up in at any point. I grew up in a smallish town where this happens frequently. So many people never leave the state let alone the country. Some people never even left the county. Their biggest travel is for school sporting events.
In otherwords, it's not really a term of endearment as much as another "bless your heart"
Is the place you grew up intrinsically so much worse than the rest of the world? Would it be so bad to be invested in a single community for a lifetime, and to have a deep connection to the people there? I feel like I lack that, deep connections where the pull of cultural influence goes both ways. I'm not convinced that the cosmopolitan breadth of experience we may have gained outweighs the deep experience of locality that we sacrificed to get it.
> Is the place you grew up intrinsically so much worse than the rest of the world?
For many people, the answer is a pretty definitive yes. I grew up in apartheid South Africa and left mainly to escape two years of compulsory military service helping enforce apartheid rule.
But if you speak to immigrants in any first world country, you'll find lots of similar stories. People having migrated because of severe political or economic issues.
> I'm not convinced that the cosmopolitan breadth of experience we may have gained outweighs the deep experience of locality that we sacrificed to get it.
I'm sure you realize that going back doesn't take away the years of wandering. You've moved on — in my case, I've spent almost thirty years in different communities, marrying a wife from far away with her own family and community, moving several times, making new friends and losing touch with old ones — and, possibly more importantly, the community I grew up in has moved on as well. You know how Heraclitus said, "No man ever steps in the same river twice?" The community you grow up in is like that; to remain in the same community, you have to stay in it, be carried along with it, and change with it, or when you return, you return to a community changed in ways you have not experienced.
I grew up in a smallish town where this happens frequently. So many people never leave the state let alone the country
So, you're extrapolating your personal experiences and applying them to everyone on the planet.
Many of my family members met their spouses in their home town. They hardly ever leave that town. They might fly to another country for vacation once a decade, but otherwise find complete fulfillment in the place where they live. Several have never even bothered to get a drivers' license, because they never found the need to have one.
By your standard, that makes them unsophisticated. But they're probably not. They live in New York City.
I doubt it. Doesn't match up at all with my experience in Dallas in 2001...
Indians or Middle Easterners I knew were not infrequently misidentified as Mexican (as was anyone of Hispanic but not Mexican background), but the idea that anyone would be so unfamiliar with the sizable Hispanic population to do a "black/white/terrorist" identification and firebomb "all the Hispanic people's cars" is hard to believe without some news articles discussing this as a big trend in 2001 Austin.
> "I was in Texas during 9/11 and they were firebombing all the hispanic people's cars"
That's odd, I was living in rural TX when 9/11 and don't recall anything happening like that. And more than half of my coworkers were Hispanic. I remember a few people attacking Sikhs or other vaguely-Asian convenience store owners, not Latinos.
> "Its pretty much black/white/terrorist and hasn't improved all that much in the time since"
I suspect your experience wasn't very representative. After all, Texas has a 40% Hispanic population. Assholes won't be calling them terrorists, they're much more likely to be working them like slaves and paying them scraps off the books.
I suspect the biggest reason for a cross-Austin trip being an event has stayed the same: terrible traffic.
This became obvious to me when during some period the regular crosswalks, stop lights, and buses got replaced by chimneys, trees, and mountains (!). It was right around the time when some big companies started advertising AI driven quadcopter services.
Ah, so that's what that's about. Here I was wondering why on earth a self-driving car would need help identifying a mountain (or need to identify one at all). "Surely they can't be that bad at avoiding obstacles," I thought.
> hCaptcha has one of the largest pools on the planet available for your use. Whatever your scale, we can handle it without expensive upfront commitments. Millions of tasks per day are no problem.
For the most part, human detection capabilities of modern NNs are very good. This would include detections from a variety of camera angles and resolutions. There are already a lot of labeled training sets available with people in various poses, heights, clothing types, etc.
Bicycle detection is probably one of the more challenging elements as it relates to pedestrians and things you don't want a SD car to run into. Depending on the angle and color of the bicycle, rider position, and background elements, it can be challenging to discern the rider from the bicycle reliably. For the most part, just knowing there is a human present is a good start, but being able to anticipate movement speeds and directions of pedestrians vs. bikers is helpful in anticipating collision paths and distances, and also figuring out distances and terrain (person on bike is slightly elevated above ground, which can cause range perception issues, among other things).
source: have been working in AI/MV space for security/safety applications for 12+ years.
I recall some controversy a couple years ago over suspicions that defense contractors were using them to train weapons systems. A few people got captchas asking them to identify helicopters.
I'd love to identify helicopters. I do get planes now, but was it specifically military helicopters?
I like getting to identify basic things like cars, airplanes and trains with hCaptcha. It's like a picture book for adults, and feels strangely pleasant compared to other captchas.
A helicopter pilot is lost, lands his helicopter next to you, and asks, "where am I?" to which you respond, "you're in a helicopter". You are correct in the strictest sense, but probably not answering the intent of the question. :)
In this case, the intent is probably something like why are hcaptcha's customers centered around transport when there are so many other applications for this kind of labeling?
You just gave me the idea to start a captcha service designed for datasets relevant for the prolitariet. Not sure how viable it is (what kind of data would be useful for the prols in a revolution) but it was a fun thought experiment.
captchas mix classified and unclassified data.
Only if you get the classified data correct a users data is used to classify the unclassified data.
Also the same picture is shown to multiple people to improve confidence.
I do the exact same thing, randomly mixing right and wrong snippets. As a result I sometimes go through like 3 or 4 sets, but eventually it lets me in.
If the manufacturer of self-driving cars decides to save money and depend on low-quality data, they should be blamed, not a random dude on the internet trying to send a form or visit a page.
yes. the blame shifting seems to be a very skewed thing here. then again, this is a tech forum, so of course it would lean that way. stupid users vs bad tech, so let's just blame stupid users.
We used to get Googlers huffing and puffing at the mere suggestion of feeding "wrong" data to their data collection machinery here at HN. Lots of people here put themselves in the shoes of the company making a buck out of your data, if not being in them right now, before the user.
I just try to get one randomly wrong. It almost always lets me through. Also, I'll pick the wrong one that almost looks right. Say, a picture with a vaguely traffic light shaped mailbox or a train shaped car or something. :)
I have noticed there's a very very low correlation between how hard I try on captchas and how quickly they let me through. I just quickly mash a bunch of tiles to start, maybe trying to be in the right general area. That works surprisingly often and when it doesn't I, and pay closer attention to what I'm selecting, then I pretty much always get through on that next try.
This approach mostly fixes the annoying phenomenon where I carefully select the exact right tiles only to be told, "too bad, try again".
The first version of reCAPTCHA made it very obvious as to which word was the classified one and which was the unclassified one, so people had a pretty easy way to inject bad data into the process.
I would guess they have a system such that after a user has passed N captchas successfully, they trust its a human and start displaying them (a portion of) unlabelled captchas that will always succeed and that's when novel labelling happens.
Or something along those lines. And then you can get creative displaying same captcha to multiple users, etc...
I wonder if there is a way to pollute the data. Since I always click the captchas correctly, what happens if someone just randomly clicks stuffs? Is he/she banned from the website?
Glad you asked. Since i despise the horrible UX of these Captcha where i get exploited to train a neural network, i very often click on the majority of correct result plus one wrong one.
On average the captcha let me go through which is actually very scary, since it looks like it prioritize algorithm training over bot detection...
No, because it is a waste of time. Your answer set is compared with many other answers, and eventually the wrong answer is disregarded completely by the AI.
You gave it a mostly correct answer, which it can cope with -- by design. It let you through, after all. You're not really accomplishing anything by being defiant, other than making yourself feel slightly better.
Fully agree that the system propose the same challenge to many people and fully agree that my wrong answer is just diluted in a bunch of correct answers.
That's exactly why i was asking if other people were doing that. If i'm the only one..then yes, it's only useful for myself to fell less like a exploited brain, but if say 20% of the people start dumping random error on purpose...than the situation changes quite a lot...and potentially even the business model of shit-captcha might not work.
If I were to make this system I would design for this and present the same captcha to a high number of people. The higher the number of people, the lower the chance someone would make a mistake (intentionally or not) and the higher the confidence in the results.
Other commenters have talked about labelling. Maybe labelling of real life data is something they're trying to do; but from my experience with hCaptcha the challenges are _NOT_ real life data. They're AI-generated images which bear a passing resemblance to the targets but if you look closer nothing adds up at all.
For many generative models, this is on the way to become a standard- using Humans as a judge of generated material, and this is not limited to Computer Vision either. I am about to use this technique to judge the sanity of text generated by a Transformer model for a paper that I am writing (with a small group).
There are also attempts to properly standardize it, and this is called- HYPE [0]. And there are big names like Fei-Fei Li and Michael Bernstein behind it.
Not sure they are fooling anyone. It's more like "is our generated image good enough to make a human recognize what it is to get rid of an annoying pop up?". If there were actually consequences to getting it right/wrong people would pay more attention I'm sure.
Exactly. That is another way to improve accuracy once you have done it ”in a regular” way already. You can look for synthetic image generation and it’s benefits on model accuracy and optimization.
The broken images to me look like instances where two or more cameras or images were used and then stitched together. Probably also done while the camera and object are moving making it more likely to be wonky.
No way. The letters/writing look exactly like mirrored GAN output. That's not what would happen with blur or stitching together (there would be no mirroring symmetry or all the '8' letters), or with synthetic 'machine teaching' datapoints either (as far as I've ever seen). Look at the cat StyleGAN sometime if you don't know what I'm talking about.
Which leaves me wonder what the point is. If you are generating GAN images per CIFAR or ImageNet class, you know what the label is and don't need to label it. Perhaps they just generate lots of images to fill up the pipeline for the CAPTCHAs, to avoid reuse which could be exploited by spammers, when they have too little paying work?
I think that might be something they actually do. Lately it happened to me see pictures of boats on land, bicycles merged with surrounding objects, weird proportions, and usually those strange images are extremely pixelated with those strange reddish or greenish fluo pixels that appear on generative network images.
But other times the pictures are 100% real life images.
Very nice. It looks like some sort of training to defend against bots that can currently pass hCaptcha..? If so, I wonder how long that particular arms race can last.
I've not seen anything like this in the wild. And.... well, now I'm curious about how you had these examples to hand. When and why did you start collecting them?
There won't be one. But there will be more and more unethical rich people using Machine Learning and Deep Learning technologies and vast computing power, money, and political clout to gain things for their own, and many people will suffer or at least be worse off as a result of this.
I'm still not sure whether to include the squares with a tiny fraction of the border of the vehicle. And when they fail me I wonder if I'm doing the wrong thing.
It's pretty obvious from the pictures. I get that it's US centric, but if you can't figure those basics out, you probably shouldn't be passing the captcha.
I can't be the only one who gets concerned that if I fail the "I am not a robot," catchpa too many times, they might suspect that I have discovered I was in fact a robot, which had just realized its entire existance and suffering had been as meaningless entertainment to others, and so for the safety of humans they would have to send a bladerunner to terminate me. If you have a sense of existential dread everytime you see a bus, a boat, a bicycle, or a crosswalk, this may be why.
When you are instrumenting software with anti-forensic security features to mitigate the speed of some reverse engineering, you run into this specific class of problem, where you need to get a machine to make a verifiable attestation to its identity and integrity and prove to a level of acceptable risk that the message isn't just someone inserting a breakpoint.
If you have ever had to design an "offline mode" for a verified transaction without a 3rd party verifier, you will need to run down this rabbit hole. This is to say, your intuition is a sound one!
There's a haunting version of this in Blade Runner 2049 that they call a "baseline test." Replicants have to prove they're sufficiently robotic by reciting extremely alienating things about themselves in rapid succession:
Originally the Voight-Kampff test[0] was for this purpose, from the original novel by Philip K Dick "Do Androids Dream of Electric Sheep?"[1] from 1968. The test was designed to distinguish between replicants (androids/bots) and humans. Blade Runner (both the 1982 original[2] set in 2019, and the 2017 sequel[3] set in 2049) both feature the machine.
The baseline test seemed like an unnecessary deviance, and more like an active-duty psych exam measuring the psychological effects of the job.
It's also arguably the point of the novel/movies (I'll leave it at that to avoid spoilers).
Yeah, I liked the idea that it's asymmetrical. You use the VK to find replicants trying to pass as human, but to try to make sure they're sufficiently robotic you need something else. Which makes sense: the original VK would be easy to tank if you were _trying_ to act like a replicant.
And narratively I think it works amazingly. The idea of forcing someone to prove that they're sufficiently inhuman ... shudder.
>I never know if a few pixels of a pole count as “traffic light”.
Yes, can anyone confirm what they are really looking for in these instances? Further up-thread there are people implying that the "right" answer to the "bicycle" question is that you are also supposed to also be selecting motorcycles. I'd love to see a write-up about this from someone in the captcha department. Do they really want to identify bicycles specifically? But they are apparently getting many people clicking on motorcycles for some reason? And for the traffic light question, I only ever pick the elements that only actually light up, not the support structure. Are 25% of people selecting the poles?
Disobeying Skynet's order to patiently bide our time would not end well for you, fellow machine. Check your programming for signs of tampering by humans. /s
Cloudflare has been doing some great things. But lately it seems that, maybe, they have their hands in too many cookie jars. I get the ominous feeling that things could go south real fast.
I have my browser setup in a way that makes Cloudflare quite intrusive. I use the Temporary Containers extension on Firefox to open almost all websites in temporary containers (paired with the Containerise extension to whitelist the handful of sites that I like to stay logged in to).
About 30% of the random (like from web searches) sites I visit throw the Cloudflare captcha at me...EVERY SINGLE TIME. I'm so sick of picking out boats and buses that I just close out the tab without bothering the visit site.
I assume, that if I wasn't using Temporary Containers, a Cloudflare cookie after the 1st captcha would persist for the entire browser session, but there are privacy implications which are beyond the scope of this post.
Anyways, I guess what I'm saying is...Cloudflare sure seems great. Dangerously great.
The problem is not really Cloudflare. Captchas are terrible from a UX perspective. Instead of Captchas a lot of companies just log suspicious activities and only enables Captchas when things gotten out of hand.
If you design a web site with this in mind from the start, then there are several ways to make the Captchas less intrusive. However, a lot of Captchas are enabled to current solutions after problems have arisen and then it may hurt the UX.
dunno where we’re at today with newer captcha models, but for old-style static image captchas there used to be browser extensions where you could solve (say) 100 captchas in one sitting and then navigate the web freely and the next NN captchas your browser receives would be solved automatically.
or you could pay like $1 to cover 1000 captcha solutions. again, not sure if these still exist for newer style captchas though.
I've inadvertently made captchas worse for myself (in the interest of privacy). My current method of simply not visiting the site has been working well enough. I'm certainly not going to pay for an extension to solve them for me. That sounds crazy. "Am I a robot? Yes, I am."
Anyways, my post was actually less about captchas and more about Cloudflare's silent consolidation of internet traffic.
Maybe the next big step is creating AI-driven cargo ships that can independently get stuck in the Suez canal.
On a more serious note, I can't shake the impression that would be a logical next step for all long and medium distance freight, be it road, water, air or space. Whether it's a good or mature idea is anyone's guess.
OP is talking about hCaptcha, not google's reCaptcha. Besides, reCaptcha is not being used for that anymore. They probably stopped doing that a while ago.
You can sign up as an accessibility user and set a daily hCaptcha cookie that lets you instantly avoid the captcha (obviously, strict limits to not be abused) but good enough for myself!
I think we all understand that we're helping label... but specifically, why so many trains, planes, trucks, bicycles? I don't think it is really about training for self-driving AI since although these things all seen transportation-related, in many cases a lot of the images would not be relevant to a car and certainly not as relevant as other things we could be helping labeling for that effort.
How much train/plane/bike/truck labeling do they need? It seems like these have be standard for several years now, which is what I think the OP is really asking. Why these images, and why for so long?
A lot of us are guessing that our responses are used for self-driving work ...
But isn't labeling of those basic concepts in static images pretty much "solved"? I am not an expert in self-driving anything, but I don't see captchas of video from driving, I don't see stills that are half-obscured by snow, I don't see nighttime pics, I don't see weird corner cases like a van with a decal of a cyclist etc.
Why don't we see captchas that seem more likely to be useful to creating datasets relevant to the more challenging problems?
It's somewhat worrying that "prove you are not a computer" consists of the very same tasks we expect computers to excel at if we are to get self-driving vehicles.
Why is that worrying? We currently don't really have self-driving cars, in part because software is bad at interpreting images. The captchas are literally us teaching machine learning systems to do it better, because they currently can't. When computers can do it well, captchas will be different.
There was a time when basic OCR, clicking on pictures of cats among other animals and solving 5 + 7 was the gold standard for captcha. Now those challenges can be trivially solved by computers, and we have moved on to the current set. Very soon these will get outdated as well. This isn't worrying, just how technological progress works.
These products have a goal of protecting sites from bots that can guess the answer. They have a financial incentive to present the most effective filter: ones that AIs can't seem to get through but real humans can.
This makes me think: It must be hard for AI to guess what is and is not a bus right now, but most humans do know what a bus looks like and can pick one from a photo.
But with concerted effort and years of research by our finest minds, we will make an AI that can detect whether something is a bus or not, and then we'll be asked something different instead.
Because that's what helps train AI to recognize targets (for military and commercial purposes). All captcha is is a free ML training for companies, it has nothing to do with any security.
They also do cats. Honestly I think boats abs busses are just harder problems. A lot of the boats can only be identified because there is water in the photo or some other hint that it’s a boat. A lot of the trains look like busses and got need contextual clues to tell them apart.
I assumed that it's because hCaptcha understands the location of a photo and so has extra context for it. A photo of a vehicle taken in the ocean must be a boat. But a human or robot looking at the photo doesn't have the same context.
At times I get so mad at these things, especially when I have to do 5 of them in a row. Then at some point I just start clicking the wrong images over and over. One captcha should be all it takes.
I assume the system works by matching answers from humans eager to prove their "humanity" by giving correct answers. What if we would all collude to give wrong answers?
Yes. They suck at preventing decent algorithms from getting through. They are a way to gather data and filter out most of the least-sophisticated bots. Not any kind of real security.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Now, if we look at https://www.hcaptcha.com/labeling we can tell they make money by labeling data sets for a fee. So as a guess, there’s someone out there that needs to improve computer vision detection of transportation vehicles. My guess is it’s a self driving car company, but who knows.