Amateur mistake, compared to my professional mistakes.
I once wrote a bot that sent email within the company (100K+ employees). I kick-started the bot on a server remotely and only then discovered it's an endless loop. It required server admin rights to stop it, which I did not have.
I couldn't immediately reach server admins so had to physically drive there. An hour or so later somebody helped me kill the process.
The emails already sent could not be cleared out server-side, which meant that recipients had freezing email clients for over a week, unable to handle the volume, a typical 300K new emails per recipient. They had to Ctrl+A and Delete 100 emails, do this for the next 100, and so on, whilst not deleting real and useful emails.
I pretty much destroyed email for those people.
I don't just destroy things at scale though, also at home. Around the time we had our first home broadband internet connection, I set up a web server and just kept my PC running. Unknown to me, the web server software included an email server with open relay enabled by default.
About 3 days later, my dad complained about the internet connection not working. The IPS detected the issue (millions of emails sent out via my home server) and gave us a red card, fully shutting us down, permanently.
> I kick-started the bot on a server remotely and only then discovered it's an endless loop. It required server admin rights to stop it, which I did not have.
That sinking feeling when you realize you've started something bad and can't stop it always gives me a visceral feeling like the world is doing a dolly zoom* around me.
I have had two really fun bulk email screwups:
The first one started when we hit the the send button for a mass email campaign driving traffic to our newly launched website redesign. We immediately realized that the email marketing software had put a unique query parameter in every link that was resulting in all requests to our cache going to origin, which instantly smoked the little vm hosting the site, sending thousands of clicks to the now famous 503 Guru Meditation page. With the infrastructure folks offline in another timezone, it was the perfect environment to learn Varnish Configuration Language on the fly with the whole marketing team hanging over me with looks of horror on their faces!
The second one involved coming to work, sitting down with my coffee and noticing that our email sending process had crashed overnight. Given the rate they could be sent sequentially I realized we'd have a big backlog of tasks, so I wrote a quick shell script to split the tasks into separate lists and parallelize them across the number of cpus on our (big, colocated, dedicated, hosting many important apps and websites) server. As soon as I ran it I sent it to the background and opened up `top`, only to see thousands and thousands of forks of my process filling the list. By the time I realized that I'd flipped the numbers and split 4 email tasks into each of 50,000 processes instead of 50,000 tasks into 4 processes, the server locked up and my SSH session disconnected. Cue several panicked minutes of our apps being offline while I scrambled for the restart button in the remote management console. Somehow there were no lasting effects, and every service started up on its own when the box came back online, even though it hadn't been restarted in several years.
On a serious note, the trend where development and admins now operate in a single blur, I find concerning. It may now be quite common for a front-end developer to also do all kinds of potentially disastrous admin/infra changes.
I think this is in particularly true with all the cloud stuff. 20 years ago, adding new servers to our DC would be a 6 month process. Now I can accidentally spin up 500 in 1 second.
> On a serious note, the trend where development and admins now operate in a single blur,
It is I know enough about admin stuff to know that I don't know much of the endless amount of small but "for production" very important things which you can get away without on a local dev setup and which don't tell you they are wrong. So it will just not work grate and you have no idea why and might even think it's a problem of your software instead of your setup.
Doing admin properly is as big of a job as any programming task and it's a very different field of expertise.
And docker doesn't fix it, at all. It at best improves the illusion of you doing admin stuff correctly.
>That sinking feeling when you realize you've started something bad and can't stop it always gives me a visceral feeling like the world is doing a dolly zoom* around me.
The largest unit of time known to mankind, the "Ohnosecond".
Thanks for sharing this. I hope that the person who made the mistake (or better yet, their manager) sees these types of stories and realizes how common this sort of thing is, even for good engineers.
I wouldn't go so far as to say that it's never an engineer's fault, but this sort of thing usually relates more to faulty processes than people.
I'm reminded of the engineer at AWS who was writing a bash script about 5 years ago and unwittingly took down a good chunk of AWS's main east coast region, causing outages for tens of thousands of websites. I remember admiring that their response wasn't to fire the engineer, but rather to say that any system that large that allows a single non-malicious engineer to take it down must need some beefing up to make that sort of mistake impossible.
Thank you for the appreciation, it was in part my goal to normalize mistakes and to treat them in a light manner.
I in particular object to kicking a man when already down, which is a common behavior these days.
I think spreading awareness of the error, pointing out the stupidity of it, or taking entertainment value from it is really cruel. I'm sure the person involved is aware they screwed up and is embarrassed, so all these piled up messages only hurt.
And I still think it was incredibly harmless. Any individual would get at most one useless email, which contained nothing inappropriate.
As said, this intern must professionalize in their errors, as this is not a pro level screwup.
To avoid accidentally deleting useful emails while “Ctrl-A-ing”, could they have run a search by sender or some other criteria first? Then only delete the search results.
In the email client? Probably yes, if they know how. This was a very long time ago, early 2000s, and the email client was the dreaded Lotus Notes software.
I had to use that client recently. I can't believe it doesn't even have a proper email search function. Best you can get is ctrl-f on the open page or sorting all your email alphabetically.
Aww I’m feeling bad for the poor engineer who is saying “crap” a thousand times now, or is blissfully unaware that their day is about to get much worse.
Once during a system upgrade we ran some scripts and they triggered emails to about 8,000 people before we realized it (would’ve been 150k people otherwise). The next day was all about clean up, sending an apology email etc.
My mother had visited the next day and asked why I wasn’t hanging out and my son (6 at the time) said, totally unphased, “oh he can’t come now because he’s saying sorry to 8,000 people”
Hope you get through it! These mistakes happen. Oh, and your test passed. :-)
That engineer should absolutely point out that despite the mistake, he just created the most engaging newsletter email ever in defiance of modern marketing practices. The real cosmic brain strategy is to run with this somehow and turn it into something like those guerrilla marketing campaigns.
happened to me as well, we send out newsletter to a b2b ecom site with all links to staging, behind htacess of course: so no tracking pixels, no images etc.
some complaints, lots of „hey you did something wrong - even more of „i can’t open it please send again“ — and it was the best week in terms of sales ever.
Similar story... about 10 years ago, I had written a really simple script to email all our customers. It worked great for a long time, but then suddenly we went over 1000 customers.
My script was supposed to try to grab batches of 1000 customers and keep looping until it ran out of customers (signaled by having retrieved less than 1000 customers in my last request for the next batch of 1000 customers).
My script was missing the offset part of the query, so after we hit 1000 users, it just kept looping, sending the same email over and over to our first 1000 users.
I felt so bad that day. From then on, sending out emails was this whole huge process that involved queuing them all and then having like 6 people review to make sure we didn't mess it up.
oh man I just wrote a piece of code that lets me write any markdown, push a button and it just sends it out to our ~1-2000 users.
An hour later I just commented it all out, and wrote a note to myself: "if you need this, uncomment and push back to stage". Just having that code even sitting around makes me nervous
We introduced an allowlist on all our testing and staging environments to ensure that only certain recipients can get email. We also make sure that no email address in these databases would work, unless we really want to send to it.
I sympathize because when I was a junior engineer once I accidentally emptied the test email spool sending the entire company including upper management all sorts of fake test emails accumulated in the past years about hires and fires and whatnot. What is more, a coworker convinced an HR person to play a prank and call me to HR office next day for giggles. Needless to say it was stressful and infuriating at the same time.
Now I know better and if somehow they are reading here, I would advise the person to just chill and don't take any shit than necessary. If you were not one of the few people with root access but somehow still had the capabilities for mass emailing in prod, that is not your problem, it is an organizational problem. For an operation at the size of HBO, anything prod has to be behind sufficient failsafes and a peer reviewed process (except maybe for a very rare "break glass" emergency).
Hope there will be a good, rational postmortem that can cool headedly identify the root causes and create action items for the actual stakeholders. If your shop is worth its salt, there wouldn't be performance evaluation consequences for you. If there is, no worries either, it is time to look for a better place.
> What is more, a coworker convinced an HR person to play a prank and call me to HR office next day for giggles.
That's the type of thing HR people should be putting a stop to, not literally being a party to. I don't have any illusions about HR being there for the employee rather than the employer, but I can't imagine working for a place where HR is abusing their authority to add stress and shame solely for their own amusement.
> Aww I’m feeling bad for the poor engineer who is saying “crap” a thousand times now, or is blissfully unaware that their day is about to get much worse.
I hope not. It sounds like the test database was not being anonymized but sometimes things like this can be as simple as not selecting a debug build in Visual Studio, either of which is an organizational issue and not an individual one so he shouldn't be punished.
This is especially true if you have corporate buzzwords like "taking ownership and responsibility". No one will take responsibility if there are punishments for owning up to and admitting mistakes. Odds are they feel pretty bad about it already.
While we're sharing personal anecdotes. Parents get very upset when they incorrectly receive truancy reports because you forgot to check the IsDeceased flag...
I hope not. It sounds like the test database was not being anonymized
Taking a copy of a production database and using it for tests is a bad idea, even if you believe you're expunging any private user data.
Development, staging, and test environments just shouldn't ever have access to production data. If you're at a company that's ISO27001 certified for data security it even goes as far as most employees not having any access to data. I've never seen any production data for the app I work on.
I agree about the part of not accessing information from production.
But I am wondering how could we debug or test something which happens only on production? I ask this because there are some bugs that can appear at the intersection of code and data.
So far my strategy is to do the following:
1. Only one person can access production DB. This person will do a backup copy and encrypt it to an internal storage.
2. Another one will get the backup and run an anonomizer script on data. The anonimzer is still up to debate what it should do after the obvious cleaning of personal data from user accounts. One important (and hard step) is regenerating the uuids but keeping foreign keys integrity.
At the end this person will create a new DB internally with the anonimizer data.
3. Someome reviews the new DB and marks it as ready to be used
Then a dev can ask access to this fresh copy.
In some teams I played with making this process full automated until review. But then if there are bugs suddenly we have a live internal DB with customer data which is not wanted.
As an alternative but only for small projects I wrote once a script which analysis the DB data and tries to create fro, scratch a similar data structure but with fake data.
> But I am wondering how could we debug or test something which happens only on production? I ask this because there are some bugs that can appear at the intersection of code and data.
I've found that your strategy depends greatly on the kind of bug and what kind of service:
* If you're implementing a DNS server, you can copy live queries and compare good-to-bad. Then you can notify when something bad crops up. But odds are you aren't implementing a DNS server.
* If you're working on something whose behavior potentially changes under load, you need to find a way to replicate load. Some companies have entire production environments where release candidates are sent without being less secure. Cloudflare has some of these - I implemented one of the early versions.
* If you're dealing with weird logic tied to edge cases in the database, you need to work to identify those. Having live data often makes it only marginally easier.
There are products out there that will synthesize large amounts of production-like data based on the patterns in your database. I've used tonic.ai, and I know there are others. As you say, this is a touchy process with nasty error cases. Having someone else implementing it might be desirable.
Use a copy of production (perhaps anonymized) for debugging, and delete the copy afterwards.
This way of debugging assumes a lot of things;
- You're assuming that your anonymization script works. What if some data isn't removed?
- What if the system you're using for debugging sends an email or connects to a webhook or attaches to a remote volume or pushes to a cloud service etc etc? Did your anonymization step really work?
- What if someone has connected the system you're debugging on to a production service by mistake? That would mean you're not even using the anonymized database. You're really on production..
- What if you forget to delete the database afterwards? Or forget to purge a cache? Or you fail to delete a container? Or you do delete the container, but not the container volumes? That production data is still there. Oops.
It's much simpler to just not use production data for debugging. It makes debugging harder, which is annoying, but you can't go wrong and accidentally leak your user's data. I'd prefer to just spend more time on debugging than have my users data be put at risk.
> I've never seen any production data for the app I work on.
The rest I agree with you, at least in a perfect world, but not allowed to look at production data? In the jobs I've had recently I wouldn't even be able to hypothesize what the problem is without looking at production data and production logs. Some of the issues wouldn't even have been reported if I wasn't checking the logs.
How do you bridge the gap from problem to replication and/or something actionable? Do you have someone knowledgeable enough in a role where they can feed you this information?
I guess the poster meant production customer data. Production logs and metrics should be easy to access, but customer data should be highly privileges and definitely not present in logs. At my old employer viewing production customer database required a customer support escalation.
The rest I agree with you, at least in a perfect world, but not allowed to look at production data?
For some context, the app is all about visualising corporate and legal structures at global law firms, so it's all very private and very secure. Never having access to production data to replicate issues certainly makes debugging a bit harder, but it's never been so complex that we've not been about to figure out what's happened. I've learned a lot about understanding how an application works, how data flows through it, and intuitively zeroing in on a likely problem area while I've worked on it.
I'm also in a similar situation, but in my case, i cannot even get access to the application logs unless i explicitly ask for them (typically as a part of solving a certain problem, given a time of occurrence), same for APM data.
While there's certainly something good to be said about the data security in such instances, it makes catching errors and fixing them absolute hell, especially if the clients are unaware that there are the occasional exceptions appearing into the logs, or they send the wrong logs (in the case of old fashioned file based logging with unclear logging strategies).
Daily ETL with data anonymization/pseudonymization from the prod and into the test environments would be really good to have, yet i haven't really seen any companies adopt that. The closest i've seen were situations where, the production data would be manually exported, scripts run against it and then given to the developers quarterly at best.
That concludes my tiny rant that's vaguely related to the topic (DB data vs log data), though that could also encourage discussion about which data is available to other developers and how they approach it (e.g. trying to never log things like monetary amounts or even person data in logs to make them harmless and the tradeoffs of that, like them becoming more useless). Heck, maybe someone out there has automated the things i mentioned above.
Honestly I'd rather them not send an apology email... because then I'd have two useless emails. And in the grand scheme of things, it's literally just one more email I receive during the day.
I for one am happy to know that they're running integration tests at all, so I don't think they have anything to apologize for. It was just an email -- I get many uninvited emails per day. This uninvited email happened to be from an engineer rather than a marketer.
Good point, but considering a lot of people are probably calling/emailing HBO without any sort of response, asking what the email is about.. it might be more fair to say that the stranger called back, you didn't pick up, and now you're calling back to clear the air.
I can't get HBO max here (UK) and I got the email. I don't recall signing up for anything.
If I get a moment I might GDPR the info out of them but honestly loads of spammers have my email it's nbd.
e: Going by past emails someone decided to change their account's email to mine (which HBO was fine with, no confirmation required, hope the user can still use their account).. Don't you just love end users.
It depends what the email was about. If its content reads like "test email" or some nonsense like that, nevermind. But if it looks like a legit email that would have significant consequences for the recipient, were it legit, it should definitely be clarified what's up. Also, a well-crafted email will hopefully prevent people invoking the GDPR on the sender.
I disagree, it's definitely useful. It's useless only if it feels/is dishonest. One way to avoid sounding dishonest is letting the dev team write the small apology piece.
Once during a system upgrade we ran some scripts and they triggered emails to about 8,000 people before we realized it (would’ve been 150k people otherwise). The next day was all about clean up, sending an apology email etc.
On the bright side, if you can accidentally send an automated email to that many people, then sending another email to them to apologise is unlikely to be a manual effort either.
When you've interrupted the process partway through as they did, figuring out which part of the list you need to apologize to may well be significantly more effort.
This is why at my startup we have a “sent_emails” table with the to and from addresses, email type and a template id (if applicable.) Saved a lot of headaches
The bigger and more concerning issue would be recipients complaining about the incoming email and marking it as spam, which could damage the reputation of HBO Max's domain and potentially send future legitimate messages to spam. (provided the integration tests don't use a non-primary domain for sending)
I learned this the hard way in my last role, I worked for a small company that wanted to do custom email marketing. I was pretty gung-ho about it, I thought I'd just set up a script to loop through contacts and use mailgun to send the email from a custom domain. As we used the tool we saw a steady drop-off in click-throughs to the site, the majority of our messages were getting caught up in spam filters.
Turns out there's a whole science to email marketing, how emails should be structured and formatted etc. A lot of times the criteria for spam is how often the domain was flagged for spam in the past, the length of the email, the contents etc.
I had a experience like this, once. Luckily it was less visible, but I felt like a fool all the same.
I came out as trans and changed my name last year, and with the name change I set up a new email alias for work. Then I set up automation to send out a gentle reminder email about the change for people who emailed my old alias. It worked fantastically for a few months… right up until the point that (due to a series of individually innocent events) the automation ended up running across the entirety of my 7 years worth of inbox. Everyone who had mailed me over the 7 years prior to the name change started getting the reminder email. One reminder for each email they had sent me. The worst part is that due to a bug in the email automation stuff, emails sent by the automation weren’t preserved in my sent box. So I don’t even know how many people I spammed. If I had to guess, I sent dozens of emails to the CEO and other execs, hundreds to my director, and thousands to people who worked closely with me over the years.
I've been laughing at myself for like two years now about how awkwardly I came out, and only now do i realize how fortunate i am that i didn't try to automate it. Thank you very much
You joke, but there is a profound truth to this. Don’t reinvent the wheel. To be fair, it’s not like I wrote any real code for my auto-responder. I used a slightly janky mail tool that could, if held just right, be used to set up an auto-responder. I should have looked for something a bit more bulletproof and focused, but I wanted to play with this specific tool and see what I could make it do.
Mostly, I’m kicking myself for not thinking to put safeguards in. Dependencies can fail in unexpected ways, and I should have set up my auto-responder to be a bit more defensive.
I did similar in Mac Mail a few years ago: it caused an out-of-office reply to be sent to every email I’d ever sent going back years. I was surprised Mail allowed for this scenario. Needless to say, my holiday got off to a stressful start!
You're getting downvoted to hell, but I'm going to respond anyway. The parent poster here is fully transitioning their gender. They're not cross-dressing at night, they're not "closeted trans"--they're changing their identity for their whole life, in all contexts--personal, professional, etc. Furthermore, they don't want to be known by their old identity anymore--in the parlance, that's called a deadname. So they're informing people of that happening, of who they're identifying as from now on.
It’s often considered professional courtesy to let people know when a property that matters to 99% of humanity (name and gender) changes permanently. Everyone takes a different approach. There are upsides and downsides to the “email autoresponder” method, but it’s certainly an acceptable option in local instances of context.
There are certain predictable exceptions, like when the physical changes reach a threshold of severe mismatch versus your old name and they get uncomfortable and figure it out (or ask :)
An HR person was poking around the admin panels of a payroll system and accidentally clicked a notify on SSN change box. An email was sent with the before and after social security number went out to 20,000 people.
I had a bug in our invoice sending script. Someone had been getting thousands of copies of their invoice. They called and politely asked if we could stop sending them that mail :D
Badge of honor to be honest. Even if HBO Max fired me I would forever be stoked to be "that guy/gal" who sent out an integ test message to the entire userbase.
Without knowing any details, that you're framing it this way (their fault for being junior and "excitable") and that you don't mention any failed safeguards and process failures (implying that their mistake was an easy one to make) doesn't let you (and that org) appear in a great light. This sort of thing is a huge org smell for me; people will always make mistakes, how you deal with that fact tells a lot about the quality of leadership.
And what exactly is the "excitable" bit supposed to tell us?
It's probably supposed to tell you this is a humorous anecdote about a mistake someone made and not a thinkpiece about all of the valuable lessons this company learned.
I still might sometimes put a funny/lighthearted twist on debugging logs that nobody outside the company would see, but I never put in swear words, condescending things, or anything else I wouldn't be okay with if it was accidentally logged in production.
I fortunately did not have to make that experience myself, but I've seen too many supposedly "internal only" messages turn uninternal.
I setup an apache webserver one time with a single index.html with the word "FOO" in it.
It was a placeholder until the software dev team responsible for the server could deploy software onto it (they asked it be setup with something in the index.html so they could confirm it was running, they didn't care what)
The networking team in advance of that wired it up to some load balancers.
They took an IP which had formerly been a decommissioned cluster of webservers serving the main website for the entire company (an internet retailer named after a river in some other country, you've probably never heard of them).
The DNS loadbalancers found the old IP (it had never been deleted from their configs which was the root cause) was now live and it was REALLY fast, so they shunted most of the traffic over to it.
Created a sev1 outage for "users reporting 'foo' on the website"
> Let's say 99 of your 100 machines are taking 750 msec to handle a request (and actually do work), but this single "bad boy" [machine] is taking merely 15 msec to grab it and kill it. Is it any surprise that it's going to wind up getting the majority of incoming requests? Every time the load balancers check their list of servers, they'll see this one machine with nothing on the queue and a wonderfully low load value.
> It's like this machine has some future alien technology which lets it run 50 times faster than its buddies... but of course, it doesn't. It's just punting on all of the work.
I learned that lesson the hard way when I was a teenager.
I'd semi-automated the generation of emails to parents about how their kids were doing at summer camp. It was basically just a script that asked various questions and pulled various data about the camper from the database, then used that to generate a letter that could be used as a starting point and edited to be more personal (or, if in a rush, just sent as-is).
Long story short, due to user error, a value of 0 was set for a camper's behavior/politeness/helpfulness rating, which resulted in a joke sentence that I'd written as an Easter egg getting slipped into that particular report. Cue egg on my face when a parent calls in, baffled about the otherwise normal report containing a casual aside about how terrible their nice little girl was.
After that experience, I always assume that every string in the code will inevitably be seen by a real user/customer.
The first production outage of my sysadmin career was when I crashed a university email system at a summer camp (I was a kid attending, probably very early 1990s?) by circumventing the block on emailing the entire university, using the Mac keyboard shortcut Cmd-A to select all in the recipient field in the cc:Mail UI. I apologized for childishly causing harm with something I thought would be funny, and so they decided not to kick me out.
Totally agree. I loved how it just showed the difference between a cop going through the motions, and these 2 guys show up months later and solve the thing in the span of 5 mins. "Real police"
Not directly related, but it still enrages me to this day that HBO allowed the two idiots who shall not be named to butcher Game of Thrones. It went from one of the biggest things in popular culture to basically nothing over the span of a few weeks.
This, a thousand times. I have a standard bit of lorem-ipsum-style content for this situation (whose origin I have forgotten and cannot credit, lo siento):
This is a test.
This is only a test.
Had this been a real emergency, we would have fled
and you would not have been informed.
This is a great point, but it's a good idea to be cautious about anything you write in a work context - like in IMs, commit messages or emails. I've been working by the principle that I won't write out things that I would be uncomfortable being confronted with out of context - say if a newspaper got hold of some leaks, or some court case caused a company to have to turn over emails etc. This doesn't mean I don't swear or joke ever, but it means that I don't send stupid one-off throway dumb things. So "The fucking $foo-service is down again, I've no idea what caused it" is fine, but "Well $foo-service is down, hope our idiot customers don't figure it out before we fix it lol" is obviously a no-no (not least because that's not actually how I joke or talk anyway).
> I still might sometimes put a funny/lighthearted twist on debugging logs that nobody outside the company would see, but I never put in swear words, condescending things, or anything else I wouldn't be okay with if it was accidentally logged in production.
A previous company I worked in once managed to send the following in patch notes:
"So sit back, smoke a spliff and stop worrying you nappy wearing fucktards"
Yep, a colleague of mine was running a quick test (this is a long time ago though) to see if some new feature, which sent email, was working and, because it was not supposed to actually sent email anywhere else than to him, he quickly put something with 'fucker' in it, pressed test and... yep all customers received that. Luckily we were in NL with only NL people receiving it and they mostly just found it funny. My colleague nearly got a coronary of course and never did that again.
Not using swear words was a big change I had to make when going from working alone as a freelancer to working with other engineers and testers. Where I work we delegated some frontend stuff to a team last year who would test with things like “God damned” and when I saw that I realized how much I’d matured as my first thought was, “unprofessional.”
One team I worked on put a profanity filter in the source code checkin filter so that we could put curse words in whatever code we were writing and make sure it didn't get merged until that code was refactored.
I used to write silly or rude things when testing, however I once found out a client of ours was getting tagged onto all of my emails via bcc, From then on I always use "This is a test, Please disregard"
I worked with a guy that was convinced at the last second to change his test email from a swear word to just "test". When he accidentally sent that to the customer base the CEO tore him a new one; it could have been so much worse.
I learned my lesson from him and now I keep these things very clean, just in case.
I set up the production servers for Pokemon GO using my personal email address as the owner. When we hit 120 million users and all the servers melted, guess which address every single one of those people was told to email about the problem?
It took a script running for five days to delete everything.
Can I just say I would love a detailed break down of the glorious mess behind the Pokemon GO launch. As a person who both wanted to play from the very start and couldn't even log in and a DevOps person who empathized heavily, I'd love to hear all about the firefighting behind the scenes during those first few hours to weeks.
I’d love to write one. I need to take a look at my NDA again just to make sure I don’t infringe on anything.
I can say one thing: the problems were heavily exacerbated by a few botters trying to scrape the entire planets worth of data every minute so they could charge money for realtime maps of everything. Every time we’d shut them out, they would find another way around the limits. Not fun when we were already so overloaded with real users.
if you can't find anything about Pokemon Go, might be worth looking for Ingress instead - I believe that Pokemon Go was sort of based on that mobile game
Oh man. I'm assuming you used your Gmail or Microsoft account where they can handle that amount of influx. Imagine if that happened on a late 90s ISP-run email account running on a single server. Ouch.
A while ago I worked on an SMS gateway and somebody had entered their own phone number in some sort of test. Somebody tested it, and there was a bug which triggered 100s of messages to be sent to their phone.
This was over a decade ago, when the messages were stored on the SIM and there was a limit as to how many they could hold (something like 20). So you just fill up the limit and that's it right? Nope, the carrier helpfully buffers messages that can't be received, and they will be sent/received when there is space on the device. I can't remember how they resolved it in the end, I guess just waiting for the messages to expire (72 hours).
I once tried to apply a hotfix in prod by opening the PHP file through ftp and modify it inline and just save. What I was fixing was the email sending logic. Since it was a long time since I had written any PHP, I forgot to add a $ before my i-variable in the loop. It still ran, though, just getting stuck with index=0 and sending email after email. Luckily my user was the first one in the db so no one else was affected.
But since PHP running on a managed host isn't something one can easily "shut off" it ran until it timed out, sending thousands of email to my gmail. While Google could handle it, it ended up locking my account for a few days with an error every time I tried opening the inbox.
Luckily my domain / provider didn't get blocked or spam-listed in the future.
Just curious, how is something like this typically handled/addressed internally? Is it one of those live and learn type situations or was there any consequence other than your email getting flooded?
My first IT job was in a large call center. I was sweeping up in a data center and there was a keyboard cable stretched across a walkway. The keyboard wasn't movable (I don't remember why) so I unplugged it from the PC, swept around it, and plugged it back in. About 2 minutes later half a dozen people run into the room. Apparently the SUN workstation I had unplugged the keyboard from was a critical component of the call manager and there was a bug that forced a reboot when the keyboard was plugged in while the system was running.
I had hung up on ~36,000 people. Lesson learned and I only had to keep the data center clean for another year.
It sounds like the real lesson that needed to be learned was taught to whoever decided that a system without any fault-tolerance that reboots whenever a keyboard is plugged in was fit for production.
My work is doing planned DR testing right now. One key system had some problems failing over - so they delayed failing back, then they decided to change when they were going to fail back.
Each time they changed their plans, there were war rooms discussing the "impact" of them changing plans. In each meeting, I'm scratching my head: this the closest thing to an actual disaster and we are all in a tizzy.
They had an outage which caused them to optimize the time to recover. However, this article didn't make any mention of regular testing of the new failover. If I'm reading it right, they designed their backup to not report on its health at all, and they instead have to just hope it works when they need it.
Was this not the completely wrong lesson to learn?
>Since our capacity injection is swift, we don't have to cautiously move the traffic by proxying to allow scaling policies to react. We can simply switch the DNS and open the floodgates, thus shaving even more precious minutes during an outage.
>We added filters in the shadow cluster to prevent the dark instances from reporting metrics. Otherwise, they will pollute the metric space and confuse the normal operating behavior.
>We also stopped the instances in the shadow clusters from registering themselves UP in discovery by modifying our discovery client. These instances will continue to remain in the dark (pun fully intended) until we trigger a failover.
Reminds me, my friend recently had a "scoping" meeting. It was planned for 2 hours. Lasted 9. Obviously they needed a scoping meeting to scope their scoping meeting.
I wonder if it was one of the earlier PS/2 keyboards. As I recall some of those weren’t plug and play, so it would have been less of a bug and more just that the hardware wasn’t designed to be hot swapped.
Due to its how its implemented on the motherboard, standard PS/2 isn't hot swappable. Any support for hot swapping is the exception, rather than the norm.
I always thought it was a bit ironic that VGA and RS-232 cables (with D-sub connectors) could be mechanically attached with screws, even though they were hot swappable. Yet PS/2, which used screwless mini-DIN connectors, wasn't hot swappable.
I'm hilariously reminded of the episode of Rick and Morty where Morty flips the wrong light-switch, killing a room full of cryogencially frozen people.
I did almost the same action and unplugged and replugged a Sun keyboard while rearranging cables. But in my case the machine just suspended to the boot mode. 10 minutes later my team lead came and found me, figured out the situation and typed 'go'.
The server restarted and just continued happily doing its job.
I have also seen instances of similar things, but usually there is a large sign saying "do not unplug/turn off" and they try to make it as unobtrusive as possible.
The problem here is that it is you were the newbie. It should have been done by a higher up who could then properly chastise whoever was responsible of that mess.
Fundamentally, a large "do not unplug" sign is just like any other failsafe system. Nuclear missile silos, probably the most "do not touch this switch" systems in existence, are only slightly more refined, and have red covers over all the important switches instead.
The alternative is to epoxy the keyboard in. But then when you legitimately need to unplug it, you need to find a hammer.
As an aside, that XKCD strip feels heavily inspired by an episode of the IT Crowd [1]
I heard how a company in the long past got a phone call from an elder customer: I've got such a strange letter from you. Reception asks what it says. Says the customer: I don't know yet, they're still busy putting it in the hallway. Huh?
It turns out an error was made in a mass mailing, and every letter was sent with the first address on the list. The list was roughly sorted by birth date, so the eldest customer got all of them. Postal office workers drove with a van to the customer, and duly delivered bags and bags of mail to the same address.
Same thing happened somewhere I worked, except all mail was being sent to the company HQ. It was loaded on lorries but someone at the sorting centre had the foresight to phone up and ask "is this correct"?
My email sending bug: I work at a large email sending company. You’ve heard of us. One of my first days on the job (years ago now), my task was to set a cron to send out emails to folks to say “hey you’re almost out of credits you should upgrade your plan.” Well there was a bug caused by a couple different problems in the system. And it turns out that the utility got stuck on a tight loop on one poor individual’s inbox. this poor yahoo recipient received over 400,000 emails from me in a matter of seconds. Yeah, i felt pretty bad there.
>the second you really can only apologize by doing it again.
Do you though? Is there value in sending yet another email? Is there harm in not sending another email? For those of use "tuned in", we just grab the popcorn, and show sympathy for the poor chap that is having a bad day. The rest of the world probably ignores. Maybe some people report it as spam?
I once sent spam out to persons unknown. It was probably sent to about 4000 people - but no one could actually be sure.
So to fix it, I sent an "I'm sorry email" to the following: my boss, his boss, and 50 key customers, all on BCC so they didn't know who I was "apologizing to" and left it at that.
Depending on the type of accidental email it may have tracking links and the software may let you redirect those links to a “we screwed up” page.
Sending an apology email really should be reserved for situations where the mistake included erroneous information - a “Dewey defeats Truman” type of email, or with wrong dates, etc.
I was building a system to call patients and remind them of doctors appointments. This was hooked to a T1 I think, with dozens of phone lines. Naturally, we tested this with our own phone numbers. One evening I get a call reminding me of a fake appointment, and while I listen to the reminder and enjoy knowing I built this... I get a call waiting notification (and you know the rest)
... (but I'll say the rest anyway). The system was using dozens of phone lines to call me and leaving multiple voice messages simultaneously. I considered myself reminded.
I did that to myself via gmail. Gmail has some kind of weird quota. It got to the point where it would only let like 100 emails per hour through. So that 5 minutes of email blast turned into one big blast, and then 100 emails per hour, for like 14 days straight. Thanks filters at least to send them to the trash..
Depending on the time period, it's pretty easy to clean out nice well patterned spam like that these days. In the days of yester-year, it could be a largely manual process.
In AOL one prank was to flood someone with emails because it was difficult to remove them, IIRC and needed to be done almost one by one.
> In AOL one prank was to flood someone with emails because it was difficult to remove them, IIRC and needed to be done almost one by one.
An email service one of my friends used around 2005/6 (I can't remember if it was Lycos or the school internal system) had a similar issue - you could only remove a page (10-15 IIRC) of emails at a time. Once he mentioned this, one of my other friends took this as a cue to blast him with 32k (pretty sure it was 32768) emails. I don't think he ever got them all deleted.
After launching a web app we noticed severe performance issues and had to roll back to a previous version. To identify the performance problems introduced in the new version, I wrote a script mimicking a thousands of typical user interactions. This also included sending email. In the moment, we forgot to properly configure the dev environment and the emails went out.. but it did not stop there.
This is a good decade ago and some clients still preferred to get faxes instead of emails. We used a service which automatically converted emails to fax messages. We tried to intervene but were not able to stop thousands of fax messages and basically DDOS'd many fax machines and then had to call the affected clients..
The bigger problem I see is that they’re clearly using production data on test systems (or using the production system for testing), including PII. This is a pretty big no-no and violates many security standards. I don’t blame the tester per se, but I do blame HBO for not having a process in place that prevents this kind of thing from happening.
Except they also sent emails to people who are not subscribers such as myself and there was no unsubscribe link in the email. There was also no header, footer or any branding at all in the email. The only content in the email was the single line of text that read:
"template is used by integration tests only."
None of that sounds like a mail list management system to me. Also nowhere does the OP appear to "shame" anyone. In fact the OP very clearly states they don't blame any person but that they felt fault lies in lack of process to prevent such incidents.
That sounds exactly like what you would send to a mail list management system. Since you’ve likely never used them, think of it like a black box you feed a template that has a bunch of vars you can reference like
The whole point of a template is so you send to an entire distribution list with a single API call and the mail system handles rendering templates to per user emails, setting up the unsubscribe link, tracking pixels, etc.
> Except they also sent emails to people who are not subscribers
That has exactly zero relation ship to your name being in their mail distribution system.
> That has exactly zero relation ship to your name being in their mail distribution system.
Seems it has some relation after all: If your name isn't in the system, you wouldn't receive the result of the template being applied: Somewhere a bit higher in the code than your example, up among the headers, there's a bit like "to:{emailaddress}".
I mean, what is sending mail to non-subscribers related to, if not the contact data of those non-subscribers being in the sender's mail distribution system?
No, you’re getting confused. An email list management system has far different data than the system that dispatched the fucked up template to it. Additionally, whether or not someone is an active subscriber no impact on them being in the mail system in general.
The whole point is that the piece that screwed up and pushed this template would have no PII access itself.
Beyond it being PII, it’s just how you sanely design these types of mass email/sms/push notification distribution system.
This incident doesn't necessarily indicate that they were using prod data in a test system.
I can plausibly imagine that there's some separate system that takes an identifier for some list of customers, and some template, and blasts out emails. Such a system could exist to help manage compliance issues with e.g. unsubscribe requests.
If so, and with a few "shortcuts" taken in making test environments for integration testing, I could envision a scenario where this incident happens that don't involve the test having direct access to real user data.
HBO Max sounds like a big company (I've heard of HBO, and "Max" sounds big to me). But it is possible they are using something like Mailchimp for their mailing list and don't do it in house. I'm just guessing here - a quick look at the headers would reveal this.
And with a confusing and horrendous UI such as Mailchimp's, it's quite easy to send a test email to the "live list". VERY easy indeed.
We've done it twice now. Once to about 10,000 emails and another to almost the entire list of 800,000. Luckily the template we were testing was 95% complete and not many people noticed. It just looked like the email got truncated with gibberish at the end.
In some systems the cost of writing and maintaining stubbed or alternate versions of things you don’t want hit by tests in prod can be pretty overbearing. Good SLOs can serve the same purpose as well for that sort of flow
+1. The first thought I had when I saw that email was that I felt bad for the tester/dev; it's not really their fault, but they're certainly going to get at least some backlash for this. Really, it's a director/VP level issue that this kind of mistake was even possible with my email address.
It was IMO still an ill-considered tweet even if made in a jokey way. While no one was really hurt by this--OMG I got an extra email!? :-)--something more along the lines of Oops, sorry for sending out that test email by mistake. We'll be putting processes in place so it doesn't happen again.
We all make mistakes but rarely at this scale. I hope whoever accidentally sent out the integration email to everyone doesn't get in trouble. I would hate for my dumb mistakes to be put on blast by hundreds of thousands or millions of people.
I often see "this person should be fired" etc in response to legitimate mistakes.. but that's massively undervaluing the mistake.
There's a pretty good chance the person who made such a mistake is less likely to repeat it or other mistakes than someone who hasn't yet had the experience. So at best you're just sending a more valuable employee to one of your competitors.
There's some gray area when it comes to making a poor judgement call to skip a well defined procedure or be lazy.. and some cases this doesn't apply to like intentional malice or a continued series of similar obviously avoidable mistakes.
On a related note im often frustrated when people play a blame game (even if one might be somewhat called for, in a way) instead of considering "human factors" and how to systematically avoid people being able to make such mistakes. Or refuse to accept a human factors style explanation and just say the person "should have known better" etc. The best high profile example was that hawaii missile alert that was supposed to be a test having an incredibly poor UI. But there are countless examples everywhere all the time. I often try to think about this a lot in my work.
“Recently, I was asked if I was going to fire an employee who made a mistake that cost the company $600,000. No, I replied, I just spent $600,000 training him. Why would I want somebody to hire his experience?”
If someone can make these kinds of mistakes, IMHO it is usually not their fault and instead is the fault of the systems that failed to prevent it from happening.
It is still their fault -- they did something they shouldn't have done. But the mistake exposes a bigger problem in the underlying infra, which is a good thing.
I think it's harmful to ascribe fault as a binary thing.
Assuming, of course, that this wasn't some deliberate act (because that would be weird):
The person who ultimately pressed the button which caused the code to run that sent this email only shares some portion of the fault. Maybe that person even wrote and deployed the code.
There's many other deficient processes that led to this even being possible - why did test code run in a place that had access to production credentials? what caused the code to run in the first place - was it accidentally triggered by some other bug, or deliberately run by somebody who didn't realize they were in production? If so, why are their systems built in a way that it's hard to realize when you're in production? Why is the system architected in such a way that large quantities of email can be sent inadvertently without some sort of approval? You could always delay large batches and send an alert so a human on-call could be in the loop to detect and delay such emails.
I've definitely seen issues where the engineers at the keyboards that day weren't at all at fault, and were just doing exactly what was asked of them, but systemic issues caused something like this. You can blame poor tech hygiene by the whole team, and lack of foresight by the manager, but most of that would be 20/20 hindsight.
This is why blameless postmortems are a good thing, because humans are simply awful with hindsight bias.
Best thing to do is just figure out how not to do it in the future.
On the list of screw-ups I've seen, this is pretty benign. I'm sure not long after this happened, they either realized their mistake or a flaw on the system they were working with. No reprimand needed, maybe some joking criticism to ease the stress I'm sure they're feeling knowing some asshat manager might actually think this is terrible and do something stupid like fire them.
The worst side effect of this to HBO is probably the cost of some unnecessary customers calling customer service confused.
The other side effect is a non-trivial number of people probably reported email from HBO Max as SPAM to Gmail etc. Speaking of which--I got this and, while I subscribed to HBO on Comcast for a while, I've never been an HBO Max customer.
Some successes are obvious luck (e.g. winning the lottery). Some failures are the obvious result of bad choices or are so egregious they don't warrant generosity (e.g. cheating on a spouse).
Anyone can make a mistake. I think it speaks to their professionalism that they test with straightforward content in the email instead of having "underpants gnome alert" or a bunch of swear words in there.
We just got a peek inside HBO's technological kitchen. Seems all right.
> We just got a peek inside HBO's technological kitchen. Seems all right.
My PS4 HBOmax app won't run, won't uninstall, and won't update. The only way out I can see is reinstalling the system software. It's possible it's a PS4 issue, but none of my other software has this problem. If the PS4 was the only way I could consume my subscription, I'd unsubscribe.
So, I'm not really impressed with their technological kitchen.
I was developing an e-letter integration. Basically I had to push a specifically formatted text file to an FTP server, from where the Post office's systems would grab it, print it and mail the physical letter.
There was a specific "this is a test" bit that had to be set so that the actual letter wouldn't get sent.
So... I kinda forgot that bit at one point and received a hefty pile of letters addressed to me to the office.
IMO the most important lesson to learn from such incidents is that you should never put shitty content in „emails that never get sent“, because eventually they might get sent out anyway. That way you’re fuck-up is just a minor annoyance — to laugh about and tell the tales how everyone also fucked-up that one time — rather than an actual shit-storm.
This one is pretty tame. I feel like we have all been tempted to write ridiculous test data -- "Dear Valued Customer, we regret to inform you that the HBO Max Defraculator has been compromised and your credit card details have been sold to a self-aware purchasing bot. We are sorry and wish you the best." Sending that to your customers is a minor disaster. Sending "This template is to be used by integration tests only." will be ignored by everyone who isn't a software engineer.
I did something very similar in my current job during my first few weeks. We had an "engineering test" script that monkeypatched the definition of "all users" (so that it returned the emails of the engineering team rather than the several hundred thousand people) before calling "send to everyone". This is obviously bad because someone might come along and change the internals of the "send to everyone" method and that person happened to be fresh-faced me. I had been tasked with making "send to everyone" a little more judicious (e.g. excluding people who hadn't opened an email in 90 days or had reported emails as spam), so I replaced the call to "all users" with some other method that calculated the recipients. And then, because I didn't totally understand how the script worked (and it seemed to be listing out some internal emails as recipients), I ran a final "engineering test" in production to see how it would look with real email content. Whoops x a few hundred thousand. I did get some pretty great responses to my apology email though.
Right? And apparently there's a tracking pixel. On the other hand, if it was intentional its hard to believe there wouldn't have been a scaling issue in production.
I wouldn't read anything into the presence of tracking pixels. They plausibly would route all outbound mail through some system which instruments it with click tracking and tracking pixels, and probably also handles rate limiting, bounced delivery, unsubscribe, etc.
At least, I'd consider doing something like that if my systems sent a lot of email and had to deal with a myriad of tracking and compliance needs.
Plus if you're going to send an "accidental" email that gets everybody talking, you would absolutely want to use something a little less dry and clinical, because that'd get a lot more coverage outside of the usual tech circles.
>We mistakenly sent out an empty test email to a portion of our HBO Max mailing list this evening. We apologize for the inconvenience, and as the jokes pile in, yes, it was the intern. No, really. And we’re helping them through it.
On 30th May I received an sms from my post office at 2AM. It says that the package with some tracking number couldn't be immediatelly delivered and there will be a followup sms when I will be able to claim that package at the local post office.
I asked at the post office about it and they said: "oh, many people ask about it. We received that sms too. That is to be ignored."
I wonder why they couldn't send followup sms and save people trip/call to local post office.
I’m assuming folks that responded to your call are not the same folks who can send the follow up SMS. Happens all too frequently when e.g. developers are detached from production and oncallers are dying under the pager load.
Well, those employees should pass that info UP the chain and let them know that this mistake causes inconvenience and confusion and they should clean up the mess.
Ofcourse that lady is not the one sending sms...
I wonder if they are testing new functionality - I'v read that we will be able to have our own pickup station right at my house, for some subscription price or something like that. So packages/postage will come delivered directly to my door behind a closed box (given it is being delivered by national post office).
And this is why you should be careful with "funny" test messages/placeholder names/dummy products etc. This could be a lot more trouble if it weren't obviously a technical thing, although a clear sentence along the lines of "if you are a customer and received this email, sorry, please ignore it" would maybe be a slight improvement.
Their tweet solely blames an intern but doesn't try to explain why an intern was running tests on production data in the first place. You kind of expect big players to have proper data protection in place, but then you hear stories about interns having access to production data with passwords in plaintext.
I've worked for a few big players. Expect that none of your data is protected unless the government will fine & punish them/individuals if they don't. Though even then, the company just forces employees to take some token training first, so later when they're compromised they can just blame some poor random employee that had no authority to change things.
Did you know only a handful of US states have laws about how you can use or handle social security numbers? If the business isn't in one of those states, expect the intern to have a big list of SSNs on their laptop. Even when there is a regulation, sometimes it's intentionally violated on a regular basis, either as part of a cost/benefit analysis, or some loophole that means nobody will personally be held responsible.
This happened to me once at an old job. I discovered a race condition between the process that sanitized data out of the staging environment as it was (continuously) refreshed in from a production fork, and the process that sent notification e-mails during mass events.
Our customers were all rather large corporate types, so a great many "Was this sent to my stores?" type messages from VPs and C-staff ensued.
I luckily wasn't involved in the communications fallout from this, but it did initiate a sweeping change inside of engineering to go proactively find and correct for these sorts of issues. We had the same pattern in use throughout our platform, and really all that stood in the way of this race condition being triggered had been QA not testing at the exact same time a critical part of that refresh process was running.
This is a perfect mistake. Embarrassing but mostly harmless. Probably not too expensive (depends on ESP cost). Great teachable moment. I wish I could get my engineers to make more mistakes like this. :)
you should file a personal data request if you live in CA or EU!
"""
If you are a California resident, California Civil Code Section 1798.83 permits you to request information about our practices related to the disclosure of your personal information by certain members of the WarnerMedia family of companies to certain third parties for their direct marketing purposes. You may be able to opt out of our sharing of your personal information with unaffiliated third parties for the third parties’ direct marketing purposes in certain circumstances. Please send your request (along with your full name, email address, postal address, and the subject line labeled “Your California Privacy Rights”) by email at WMPrivacy@warnermediagroup.com.
patio11 shared on Twitter how he pushed a faulty code to prod *just before changing apartments* so that it started sending email, sms and calling hundreds of people every 5 min for 13 hours:
This is a great reminder to make sure your tests are phrased in such a way that if a layperson comes across it, they can ignore it, sort of in the same way we came across "This is a test of the Emergency Broadcast System."[1] And not "Big Brother Is Watching."[2]
I once accidentally ran a load test against our password API in production and reset the password for about 100k users to random characters. Hang in their bud. Happens to us all.
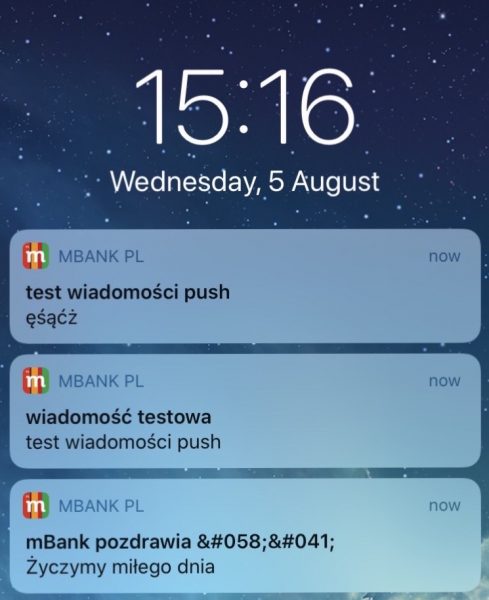
In the last August Polish internet bank mBank had two "issues": they sent out of sudden 3 notifications onto mobile devices, one even literally saying "push notification test" and the other included some of Polish diacritics [1]. Site went offline soon after these were delivered. Then few days later, database was damaged in a way some clients could see account balance and personal data of other people - that was fixed relatively fast but permanently disabled the feature of accessing recipients list in shared accounts. No idea if that was fixed - my family moved accounts elsewhere.
My colleague did it once. He accidentally used an incorrect API key and sent a garbage push notification like "ohai" (don't recall exactly). We were a pizza delivery startup.
Few hours later, we sent another notification as an apology.
"Oh Hi. Use this coupon code for 20% discount: OHAI20"
A few decades ago, I was rewriting the standard sendmail.cf that we used in the company where I worked as a sysad. I think we had about one hundred or so Sun 3/60s and 3/80s that were using it.
Well, in one of my test emails, I triggered an email loop. Suddenly, all the clients were furiously mailing the mail host and queuing up additional copies as fast as they could.
To make matters worse, my test mail was unprofessional in terms of the language I used.
Fortunately, it was a Sunday afternoon when it happened, and the mail stayed local. But it was scary and a real pain in the neck to halt and clean up.
In a future post, I’ll share how a fellow sysad and I shorted out the RG-8 coax backbone while trying to add a vampire tap. That was another kind of all night deal.
As is usually the case with such things, this wasn't really the intern's fault. The question I'd be asking is: why wasn't there proper access control in place to stop this? The system actually sending the emails should not have allowed "testuser" to send to a production list. So, second question: when this was proposed during some planning meeting (and it almost certainly was), why was it shot down? That's the process problem right there.
Years ago I worked at a company that send out a test email to all our users with some light profanity in it. We got a little (unexpectedly) good press about it and it ended up being no harm, no foul.
Hopefully everyone at HBO is as nice about today's mistake!
A long time ago I worked at a company that prided itself on unrestricted source code access to promote cross-group cooperation. The check-in procedure relied on an understanding of the code review and ownership policy but wasn't enforced programmatically.
One day I came back from lunch to see that someone had marked an entire Perforce depot for delete. I've never scrambled so fast to try to identify this unknown user. I figured it had to be an intern and ran across the floor looking for him, only to find a poor confused intern surrounded by out of breath developers imploring him to not hit submit. Every 30s someone else ran up to try to get him to not delete the entire depot.
It was the intern's first week on the job and he thought he was just deleting some local files. The event definitely inspired some access lock-downs and automated check-in procedures going forward.
---
I laughed when I saw the email but was also a little pissed because I am a former, not current customer. I hope HBO Max doesn't send out an apology email. That's the equivalent of unsubscribing from an email list only to get an email confirming the unsubscription that I also have to delete.
Oof. I think there are two types of engineers in the world. Those that have done something like this, and those that will someday do something like this.
I develop on an application which does, next to other things, send out push notifications to apps via Firebase on a schedule. I was implementing a limiter for these notifications (so you can only send ~4 in a 24h window) and tested them on a local instance by generating a lot of messages. As I wanted to create a few quickly, I didn't change the date from the default, now.
The actual limit was configurable, so I went and changed the config and realized I used the wrong file all along. So I switched the file, without realizing that the other file also had the actual live credentials configured (it was used for testing while developing this feature not long ago). I only realized the mistake when I had a lot of log messages along the lines of "sending push notification" at startup.
Luckily for me, we had thought of rotating the secret, so no notification got through. But I had a fun five minutes while searching my phone in panic to find out how bad it really was.
Hope the poor guy working at HBO reads these stories later to brighten his day a bit :)
At my company I had a co-worker named Swaroop. Who decided to use swaroop@ourcompany.com for some test email address in some e2e tests. Fast forward a day, we get an email from the CEO containing a forward from a very concerned Board Member (also named swaroop and the owner of swaroop@ourcompany.com email address) asking if we had been hacked.
Meh, it happens. Sending out test emails is about the best-case on the spectrum. I've been involved in cleaning up incidents where someone accidentally sent out discounts worth 7 figures that were meant to be for a test but it was misconfigured. That was not a good day for a bunch of people.
Since we're sharing email sending mistakes: We wanted to start sending users occasional summary emails about activity on the platform that they might be interested in. We wrote the email generation logic first, and then the plan was to start adding different activity events and dogfooding the emails internally to see how they looked in practice. This would be fine because while we developed only internal users would have activity data, so only we'd get emailed. But there was a bug in the "is this email empty" logic so we once sent every user an email with the subject of something like "Check out your recent activity on X" with a few headings and absolutely no activity content. Oops.
The email is innocuous. I opened the headers to see what was going on and why it got past spam blockers. My next thought was how much more valuable this mistake is than most their advertising budget to get attention.
Reality is this will lose them paying subscribers, so without a doubt this is an expensive mistake regardless of who’s to blame. Large subscription businesses are very careful about when to email the segment of their subscriber base that is paying but inactive. This email just reminded a bunch of people they are paying for something but not using it, and therefore should cancel (granted, it’s unclear who it went out to).
It could cause some ESP/deliverabilty problems too.
On the bright side, this can serve as a reminder to us all to make sure this doesn’t happen at our companies.
Everyone I've asked that is paying has said they got it but paid it no mind since it had no information that seemed relevant to them or they were a developer that thought it was funny.
I'm actually hard pressed to even imagine the person that is cancelling their HBO max account because this single email was just too much for them.
I don't imagine many people will cancel HBO Max because this email was just too much, but rather because this email reminded them that they have HBO Max, and might spur them to think "I never use that so I should cancel it"
When I was working at Kiwi.com as a senior product designer one of the guys on the development team did something very similar.
We were testing a new push notification refactoring and managed to send a push notification "Test test" to our whole Android user base (couple of hundred thousands of users). Interestingly enough, it was a great reactivation campaign. We bumped bookings by a noticeable margin, and since we redesigned our "rate us" flow couple of weeks before, we had a huge influx of 5* ratings as well.
This was one of the worst day of my "engineer" life. I was very young and inexperienced at that time.
We were running a Ruby-On-Rails app with push notifications.
We had an "on creating" life-cycle hook on a model recording an event, so that every time a new model was saved, a job sending a push notification (android or iPhone) to the appropriate user would the triggered. This would notify the users that the "event" was done.
The implementation was wrong. Instead of an "on creating" hook, the push notification logic was added in an "on saving" hook.
As the model was supposed to only ever be saved once (on creation), this worked for a while, and no-one ever realized. You now guess what's going to happen.
Then after some time, came the day when we needed to do some data migration. Easy right? The data-migration included updating some data in the the above model in question (all rows must be updated). We run a ruby script to update the model.
Everything was working in staging environment. So we release in production. The moment we release, we sent hundreds of push notifications to each of all our clients (including to our own phone, as we were using the service). Basically everyone was receiving as many push notifications as the number of "events" they completed until now.
Immediately, all the phones in the office (CEO's phone, sales rep, etc.) started to ring with complaints from customers asking what was going on.
The CEO was as angry as you can imagine. But no time to be angry, as everyone needed to apologize and explain the situation to all our customers.
Basically the whole team was at fault for letting the problem slip through the code review.
From then on, we improved code review process, and decided to include push-notifications in staging environment too.
This right here shows the danger of relying on ActiveRecord callbacks, instead of explicitly calling the notification/etc code from the caller which did the creation – potentially very impactful things can happen in a non-obvious way
Aside: I'm a big fan of HBO's content but their app is really poor quality. Playback frequently is unable to start or halts midstream. I've noticed this on distinct devices (android, AppleTV). DRM run amok? I don't know but you would think making playback work consistently would be near the top of their list.
It's gotten slightly better over the last year or so. But it still happens way more often than it should.
Are you protected by GDPR ? If so yes, if not it's just business as usual. Gather as much data and keep them just in case you need them in an hypothetical future for an hypothetical use case
I was at a company that did something like this. However, the fallout was the sending IPs and domains got put on so many email blacklists, spent months on improving emails to no avail. Our sending success rate to Gmail never recovered even after talking to an engineer who said we were on like 4 blacklists. I hope HBO's servers or ESP fare better.
For about 24 hours last summer, Citizen app on Android would play the audio from a "Who's that Pokemon? Rick Roll" video when there was an alert. They quietly fixed it. I can only imagine that it went to prod because it was a goofy test alert sound that accidentally got promoted out of a QA environment?
Worst mistake I made like this: B2B service, we billed customers, and then added white label service where we wouldn't bill our customer's end customers (they shouldn't even know we are the underlying provider). Guess who forgot to update that code and ended up sending billing emails to everyone.
Are we talking about heart surgery here? No, we're just talking about an insignificant test email. Nobody was hurt, and it reactions were actually fun to read.
So, whoever unintentionally did that: this is okay. And if your manager says it's not, this is not okay.
It's not going to help if this ran on production. But I can't recommend mailtrap.io enough for catching all emails sent from staging/development. Nice for testing as well since you have an inbox you can view all emails from.
I was wanting to start a pool to see how how the Test Email # got. Test #1 seems successful. I wonder what Test Email #2 will be. I know a lot can be learned in a single test, but surely, there's more to test yet.
This is me every time I compose an email on Mailchimp. I am always petrified that I'll send to the entire mailing list rather than send out a test email.
I wish these mass-emailer companies ask you to solve a captcha, puzzle, or a simple math question before you send out a mass mailer.
This reminds me of when I took over a project after a developer that left they company.
They had just added SMS notifications to production but to my horror left some test code that would text you "Hey motherf**r" every time you would change your phone number.
To this day I still wonder how many people got that text.
Pretty sure this will happen to every web dev at some point in their career. It's why I strictly enforce professional test messages and test users, nothing worse that doing a product demo with users named Donald Trump and Osama Bin Laden.
Hope the guy didn't get fired, things like this happen because of multiple failures in dev ops, not just 1 guy pressing the wrong button.
{kind=link}
{kind=link}
{kind=link}
I once wrote a bot that sent email within the company (100K+ employees). I kick-started the bot on a server remotely and only then discovered it's an endless loop. It required server admin rights to stop it, which I did not have.
I couldn't immediately reach server admins so had to physically drive there. An hour or so later somebody helped me kill the process.
The emails already sent could not be cleared out server-side, which meant that recipients had freezing email clients for over a week, unable to handle the volume, a typical 300K new emails per recipient. They had to Ctrl+A and Delete 100 emails, do this for the next 100, and so on, whilst not deleting real and useful emails.
I pretty much destroyed email for those people.
I don't just destroy things at scale though, also at home. Around the time we had our first home broadband internet connection, I set up a web server and just kept my PC running. Unknown to me, the web server software included an email server with open relay enabled by default.
About 3 days later, my dad complained about the internet connection not working. The IPS detected the issue (millions of emails sent out via my home server) and gave us a red card, fully shutting us down, permanently.