I get it's a joke, but it would be a better joke if it was actually valid C++ or close to something you would actually write.
contemporary C++ using STL looks like a classic case of the "If all you have is a hammer"-syndrome
I don't understand what it means. The STL is a very powerful tool to implement complex data processing and work on structure. Is this another case of someone using the containers without using the algorithm's functions?
Except that code isn't really that far from what you might type. I've spent a lot of time working with code that uses templates heavily (including "well designed" libraries like Boost) and it's just a god-awful mess. Make an error in instantiating a template class and you get an error message that refers to code deep in an STL header. Want to make your container class iterable? Get read to write dozens of lines of inscrutable boiler-plate code. Even something simple as iterating over a container is braindamaged. Before the auto keyword you had:
Then you need to use "itr." It's a pointer-like thing that isn't quite a pointer, and when you hold pointers in your container, which you often (usually) want to do you have to deal with a pointer-to-a-pointer which is almost never pleasant. And when you deal with keyed containers you have to remember the iterator actually points to a pair so you have to do .first and .second (why not .key and .value?)
The algorithms are a PITA without lambdas, and are not easily composable or extensible to express more complex iteration. None of them can work with multiple containers, which makes writing even something as simple as a "zip" function using the algorithms an exercise in futility.
But then you have to define the loop internal logic elsewhere because C++ has no lambda (yet, at least in most places where it's used in production). God help you if you have a lot of variables that need to be compared or referenced inside the loop.
First of all, like you've mentioned, his C++ example code is bogus.
Second of all he says "modern funkiness of dynamic languages" only to continue with lambda, map/reduce and type independence. The first two are unrelated to dynamic/static typing, the latter is incorrect or badly phrased. You don't get "type independence" in dynamic typed languages, the types are still there.
Thirdly, he greatly exagerates the complexity of templates (thousands of incorrect syntax options for smart pointers, all you have is a hammer, etc)
It's a classic case of fishing for arguments to support an idea.
I agree, the STL is a great resource and I miss it in other languages. However, the long type declarations clutter up code. Type inference would make STL code much, much, much, much, much easier to read. Mentioning a container's type once improves readability. It is nice to know that you're dealing with a vector<map<string, set<int> > > if someone has written some crazy code that uses one. Having to repeat the type over and over again, for example, needing to declare that your iterator variable is of type vector<map<string, set<int> > >::const_iterator, makes STL code unnecessarily painful to write and to read. The STL's consistency and feature set certainly makes other language's collection libraries look amateurish by comparison, but the lack of type inference in C++ makes the STL a mixed blessing.
Even though C is used for those large successful projects, even if it isn’t wrong for them, and even if the projects grew using C through a series of justified decisions, C can still be suboptimal for them.
There is no clear explanation of why he thinks C is suboptimal - his statement implies to me that there are other languages that are clearly better for writing things like OS kernels etc. and I'm not that has been demonstrated yet.
Considering only pure language design, I have to say that I'd prefer D to Go. A lot of people who talk about Go use some variation on the phrase "small sets of orthogonal features"—a phrase I feel applies to Go only by comparison with, say, C++—and D doesn't succeed in that regard, but I feel like D really fits a lot of the points on the wish-list much more closely (e.g. template metaprogramming, data structures, objects, &c. D's compile-time constructs are incredibly useful without the nastiness of the C preprocessor or C++'s templates.) One thing which draws me to D is the "you can, but you don't have to" attitude it takes towards certain features—for example, there is GC by default, but you can stop using it and do manual memory management if you feel like it's important.
The problem here, and the massive, massive thing keeping me from throwing my full recommendation behind it, is that D fails entirely on #7, because the community is small and so even installing libraries by hand can be tedious. I keep wanting to pull out D for personal projects, but then I come across some obscure, poorly-documented library with few/no alternatives, and after trying to build it for three hours, I give up and switch to something else. Recently, 'something else' has in fact been Go. I still feel like, in an ideal universe, I'd rather program in D than Go, but we do not live in an ideal universe, and of those two, Go is the practical choice. (And, despite my frustrations with Go, it is still better by leaps and bounds than Java and C++.)
Also, quick correction: any dynamic language worth its salt does the same short-circut evaluation with and and or, including Python, Ruby, Scheme, and Common Lisp, so they all have the property ascribed in this writeup to only JS and Perl. In Python, you can change whether instances of a class are 'true' or 'false' values by overloading the __nonzero__ method, which means e.g. empty user-defined data structures could be considered 'false' while non-empty ones could be 'true.' On the other hand, Ruby considers only false and nil to be false values, Scheme considers only #f to be a false value, and Common Lisp considers only nil to be a false value. Aside from individual quibbles about which values are true and false, all of these languages implement an or that returns the first true value it finds, and all of them implement an and that returns the first false value it finds.
EDIT: Lua also allows the short-circuit boolean operators to return values. The only widely-known dynamic language off the top of my head that doesn't do this is Smalltalk. This would be complicated to add to a type system, for relatively little gain, so as far as I know, no typed language allows it.
Especially with Andrei Alexandrescu on board, D is striving for some very interesting stuff with its template metaprogramming system. I think Alexandrescu said in an interview somewhere that the goal is to have a language where you don't ever need to reimplement an algorithm once you've gotten it right once in a library.
This gets particularly interesting with mathematical code. If you have a templatized math function like a linear interpolation function, you can swap in integers, reals or complex numbers without writing new code, and also matrices, vectors or quaternions from another library, provided that they have the algebraic properties the function expects. Go is nowhere near allowing this degree of write-the-algorithm-only-once, as it both lacks generic types and has numeric types as privileged constructs you can't substitute with user-defined ones.
Thanks for your kind words. In D's standard library we consistently attempt to define each and every algorithm in its most general form, with opportunistic specializations wherever available. As a trivial example, startsWith works on average faster on sequences with O(1) length because it can compare the lengths beforehand. D's generic amenities (static if and constrained generics in particular) make it very easy to write code with lots of such micro-specializations effortlessly. You just say "oh, do these guys support the length method? Then if lhs.length < rhs.length return false".
We've managed to reach a very high leverage in std.algorithm (http://d-programming-language.org/phobos/std_algorithm.html) because of that, and there's seldom a need to redo by hand one of its algorithms for efficiency or convenience reasons.
I was thinking along those lines as well, though the first language that came to my head was actually c# (my second thought was D). It may not be listed due to it's precarious position in the world, but it answers the majority of the points on his list, though still runs in a vm environment. Perhaps that's the distinction.
An aside - using implicit typing in c# you can have an object perform as a boolean in boolean expressions. You can also use implicit typing for more than just booleans as well.
Typed languages (like C# and Scala) can definitely use non-booleans in boolean expressions; the thing they're lacking here is that you can't return non-booleans from boolean expressions, e.g. you can't have a line like
config_file = get_config_file() or "~/.my_config"
(which is valid Python; if get_config_file() returns None or False or an empty string, then it sets config_file to a default value instead) because the typing problems get nasty. (You'd have to stipulate that 1. boolean expressions can return non-booleans and that 2. all the arguments to a boolean expression must be of the same type, and, if you want to include a not operator, 3. there are 'canonical' true and false values for every type, so you can evaluate expressions
String s1 = !"some_string";
String s2 = !"";
which is why the typing rules would get... uhh, complicated.)
Perhaps because I don't understand type theory, this doesn't seem especially hard to me. Every type should be a subtype of boolean, right? Otherwise you couldn't evaluate truth or falsity on something like a string in the first place.
Wouldn't the 'not' function signified by your operator just return a basic boolean (for any argument which was a subtype of boolean, which would be any argument...)?
[To be clear, "go read 'Book That Will School You' " is an acceptable answer to me, if it really will]
It is a great book, but a little dense. Its example language is a typed lambda calculus. This is both good and bad. The good: you can evaluate most expressions in your head or with a pencil. The bad: sometimes it is difficult to read without evaluating the expressions.
It is heavy on proofs and mathematics, but it does what it says: it introduces you to the basics of type theory as applied to programming languages.
I second the commenter who recommended Types and Programming Languages, but the short answer is, "Sure, if your language has subtyping, and you want to arrange the inheritance hierarchy in that way." It would solve it a little bit better because the type of
x || (y && z)
would default to being the 'most general' type of all its arguments, which could be Bool but might be more specific in certain circumstances. But this of course only works if your language has some kind of subtype relation, which is not necessarily true of every language—it is not, for example, true of Go, or most typed functional languages that I know of—and it still ends up having typing rules like
t1 : A t2 : B A <: C B <: C
------------------------------------
t1 || t2 : C
It also assumes that the Boolean class is implemented as a single class with no subtypes for True and False—i.e. not like Ruby's TrueClass and FalseClass; you'd have an instance variable or something which tells you whether an instance is True or False—because if you implemented it with singleton instances of a True class and a False class, then you'd bifurcate your whole object hierarchy, and it also assumes that there can be no type 'more general' than Booleans, because if there is something 'above' Boolean in the hierarchy, then you'd have to rewrite the rule as
t1 : A t2 : B A <: C B <: C C <: Bool
------------------------------------------------
t1 || t2 : C
Instead of using a Boolean, use a type that means what you actually want:
You want to short-circuit combine two (or more) values, returning the first one that is valid, without evaluating the later ones.
You need a type that represents a possibly-unavailable value. "Boolean" is not that type. "Maybe" is Haskell's type-safe "Nullable" type. It has two kinds of values: "Nothing" or "Just a", where "a" is a value of any type.
Some quick simplified definitions of Haskell terms:
"Control.Monad" is Haskell's generalization of "flow control"
"mplus" is Haskell's generalization of "or" (as it means in Perl/Python).
backticks are used to make a regular prefix function into an infix operator.
"undefined" is like Perl's "die" or Java's uncatchable Exception, used here to show where short-circuit happens.
ghci is a Haskell interpreter.
% ghci
> import Maybe
> import Control.Monad
> undefined `mplus` Just 1
*** Exception: Prelude.undefined
> Just 1 `mplus` undefined
Just 1
> Nothing `mplus` (Just 1) `mplus` undefined
Just 1
> Nothing `mplus` (Just 1) `mplus` (Just 2)
Just 2
It's practical. It binds very well to old C code; consequently, it avoids all the library-binding problems that plague D and (iirc) Go. It does well enough at backwards-compatibility that it even comes with a nice Lua binding:
Granted, Vala is what it is -- a language built for GLib -- but I think we've had enough languages try to take over the world. It's not unimpressive for a language just five years old and almost entirely community-developed to have a lot already being writen in it:
including Ubuntu's new user interface. Since it only really depends on GLib and gtk, it's cross-platform enough for most purposes, though the majority of projects written thusfar in Vala have only targeted X-based desktops.
Note that D can call C directly too; all you have to do is add the function's prototype to an extern(C) block in your D code. You can cheat on the prototype too, for example, using void* rather than spell out a struct pointer type, if you're in a rush.
There's also pragmas for adding the needed library to the compile command line.
It's actually pretty easy to use.
D's C++ binding support, on the other hand, leaves quite a bit to be desired... I always do extern C functions to bind them together.
This is a great article, although of course there are a few things to quibble about. One that stuck out to me was this: "One of the inventors is Ken Thompson of Unix and Plan9 fame, and he was indirectly involved with C as well."
I'd have to say that Ken Thompson was directly involved with C, not just indirectly!
Well, Ritchie is normally credited with the creation of C and Thompson with its predecessor B. You're probably right, with the two coworkers working closely together on Unix Thompson probably made a lot of direct contributions to early C. But it was Ritchie that took C as his project and shepherded it through its growth and standardization.
Certainly Dennis Ritchie is the primary author of C, but given the very close historical relationship between C and unix, we know that there was a tight synergistic evolution that shaped each in relation to the other. As an example, very early C didn't have structs, but Thompson clearly needed a bit more powerful abstractions for some of the work on converting unix into C from pdp assembler, so Ritchie added them.
I was really just quibbling over definitions and connotations, when I hear of an "indirect" involvement I think of something very different and much more remote than the deeply intertwined stories of unix and C and Thompson and Ritchie at Bell Labs in the 69-74 era.
Also, "of Unix and Plan9 fame"... I accept that his audience and HNers may feel just as home with Plan 9 as they are with UNIX, but the wording suggests that these two systems grant the same level of fame, which is a wild stretch!
C is a C-like language.
C++, being a superset of a language very similar to C, is a C-like language.
Objective-C, as a superset of C, is a C-like language.
But Java? and Javascript? They both have C-style syntax, but apart from that they are both very different from C (and from each other).
Please don't say `C-like' when mere `C-style syntax' is meant. (And please don't think that having similar syntax implies any other close similarity between languages.)
From a scope and features standpoint, C++ and Java are quite similar. I would guess that that's why Java made the cut. No idea where Javascript came from, though.
Go is NOT C-like. The same semantics could have been achieved by making minimal changes to the existing C syntax. For me, Go seems to be suffering from the NIH syndrome -- they made many syntax and cosmetic changes to C just for the sake of change itself. (Using {} for compound statements is not enough to qualify the language as 'c-like'.)
I have no doubts that Go authors think that their syntax is superior, but they'll have a hard time convincing me that
switch nr, er := f.Read(buf[:]); true {
is understandable (snippet taken from Go tutorial).
It is perfectly understandable from my perspective, but the caveat is that I'm used to Go's syntax and idioms and they are quite different from the usual. It has taken a while to unlearn the old way to be honest but I prefer it like this now.
"Since the switch value is just true, we could leave it off—as is also the situation in a for statement, a missing value means true. In fact, such a switch is a form of if-else chain. While we're here, it should be mentioned that in switch statements each case has an implicit break."
The basic outcome is that:
1. The assignment to er, nr is an initialization statement for the switch.
2. The true (default value if not specified) is used to configure the switch as an if-else chain which is required as the assignment above makes the purpose of the switch ambiguous (is the result of the assignment configuring the switch - how do you do that as multiple values are returned?).
You could rewrite it:
nr, er := f.Read(buf[:]);
switch true {
...
}
or even:
nr, er := f.Read(buf[:]);
switch {
...
}
But the switch initializer scopes it to the switch block cleanly.
This seems like a fairly poor article overall... His point about GTK is nonsensical - C is a very good language to use because it means that bindings can be made for pretty much any language any language - which is why you can use GTK in any language from C++, to Python, to C# and Java, PHP, Javascript and so on... And C is used on thousands of projects more than 10K LOC, so I don't see how it's 'not suitable'...
What part of it is painful? I've found gobject to be quite effective. It's not the most enjoyable to extend (there's marshalling and other boilerplate that's not difficult but not interesting either), but in the majority of cases when using GTK you're doing just that--using it, rather than extending it. Using C avoids the complex semantics of C++ templates/inheritance at the cost of losing type safety when things become void*, but if you a have a little discipline that tradeoff grants flexibility that's quite nice in my opinion.
The Go x64 compiler (6g) has gotten more attention than the x86 one (8g), and I think given that this days most systems are x64, this benchmarks page is more representative:
Quoting Google's Russel Cox in a mailing list discussion linked to above: "Go requires that int be at least 32 bits and that int64 and uint64 be supplied; practically that means we've given up on 8- and 16-bit CPUs."
Yeah, I was just thinking that C# sounds a lot like his ideal language. It kind of feels like he's one of those people who thinks that C# == java. It doesn't hit all his points, but it hits a few.
I crossed a point in my life, I'm not sure exactly when, where reading c-style code is just difficult for me. I see something like (from a Google sample):
Some questions and observations from the other side of the fence:
How do you differentiate your simplified function declaration to a function invocation?
The latter means you must refer to the receiver (the instance of Draft75Handler) as "this" or "self". In Go, you name it explicitly (in this case "f") which makes the code more readable IMO (although "f" is a strange choice in this case).
The variable names "writer" and "request" will become wearying as you use them in the function body - better to say the exact type once (http.ResponseWriter) and use shorthand thereafter (w).
(And, obviously, omitting the type information in the function arguments doesn't work in a statically typed language.)
What the Go folks are trying to do is get traction. Without traction the Go language won't be the "next big thing". So I expect we will see a lot of these "types" of articles coming out.
You make it sound like a conspiracy.
I get the impression that this is just a blogger writing an article about a language he likes and some he likes less.
I'm sure the Go team and Go enthusiasts would like to see Go be more widely known and used, but I get the impression that the Go team doesn't actually want it to be the "next big thing". If they did, they'd have made more popular design choices.
Given that the guy that wrote this article was clearly not very versed in Go and made some pretty basic mistakes, I'm not sure how you can say he is part of whatever "Go folks" conspiracy you are claiming.
I was disappointed not to see RAII on his list. I'd gladly leave C++ behind if I could keep my RAII and the well-designed STL (a great idea and implementation which is unfortunately uglified by C++-imposed verbosity.) Actually, I'd happily leave even the STL behind, but I always miss RAII.
Rust supports RAII, but it might be premature to include Rust in this kind of comparison.
I agree. For me RAII is almost like a Litmus test. I can comfortably write away in C# for a while but there's always a point in time where I want RAII something and realize that it's something extremely useful you give up when transitioning to a GC language.
The author did mention that GC has been around for C and C++ for ages yet people don't seem to use it. If manual memory allocation was such a big problem for C++ programmers people would have adopted a GC library long ago.
Which is not to say Go might not gain traction for other reasons but it's not really clear to me what problem it solves, even after reading the otherwise very entertaining and informative article.
I would posit that if you choose to use C it is because you want to micromanage performance (kernel, strict hardware constraints, etc) and therefore do not want GC, and if your environment is compatible with GC, you may as well go further to C# or Java or another high-level language that gives you even more goodies.
The D programming language has strong support for RAII, and of course has Andrei's range based algorithms library, which in my not-so-humble opinion is superior to the STL.
Python does foo if bar else baz, which is a little more verbose but still okay. JS and Perl, however, rock with their boolean operators AND and OR not just evaluating to true and false, but to the actual value that was considered true.
Python does that as well:
0 or False or 'Python rocks' or [] == 'Python rocks'
> Well, actually there are semicolons, but they are discouraged. It works like JavaScript, there is a simple rule that makes the parser insert a semicolon at certain line ends.
I find it ironic that this "feature" is #1 in the list.
I generally liked this review, but I really had a hard time choking down the sections on Concurrency (which was—charitably—poorly written and confusing) and OO (which classically mis-defines OO).
It makes me wonder, why is concurrency really that much of a black art in 2011? I still see people confuse parallelism and concurrency and just the other day an article got upvoted here describing why JavaScript programmers don't need to learn about concurrency; as if the continuation-passing callback style of JavaScript isn't a concurrency technique.
Some objections are questionable.
The writer regret ObjectiveC for the lack of a GC. Then blames Java for its size.
Then he exalts GO for the GC.
You can find disavantages in every programming language, but are the advantages which drive the choice.
You can also squeeze java a lot, running in less then 16MB.
So have I miss the point, or the writer is a GO-addicted?
{kind=link}
The problem is that when you notice something inaccurate in a document, you have the tendency to ignore the rest...
It is a superior alternative for classic application development, and some nice slim and full-featured GUI toolkits use its qualities well.
I would say C++ is the way to go for servers, not really GUI. As much as I love C++ I wouldn't recommend using it for writing a GUI.
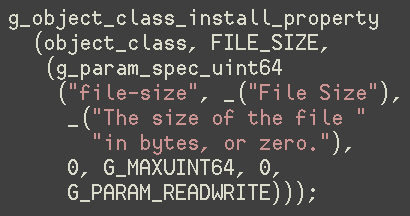
dynamic_cast<MyData>(funky_iterator<MyData &const>(foo::iterator_type<MyData>(obj))
I get it's a joke, but it would be a better joke if it was actually valid C++ or close to something you would actually write.
contemporary C++ using STL looks like a classic case of the "If all you have is a hammer"-syndrome
I don't understand what it means. The STL is a very powerful tool to implement complex data processing and work on structure. Is this another case of someone using the containers without using the algorithm's functions?