While the M1 is super impressive, I'm kind of wondering how scalable the performance increases they made here are.
They moved high bandwidth RAM to be shared between the CPU & GPU, but they[1] can't just keep expanding the SoC[2] with ever larger amounts of RAM. At some point they will need external RAM in addition to the on chip RAM. Perhaps they will ship 32GB of onboard memory with external RAM being used as swap? This takes a bit away from the super-efficient design they have currently.
Likewise, putting increasingly larger GPUs onto the SoC is going to be a big challenge for higher performance/ Pro setups.
I think Apple really hit the sweet spot with the M1. I suspect the higher end chips will be faster than their Intel/ AMD counterparts, but they won't blow them out of the water the way the current MacBook Air/ MBP/ mini blow away the ~$700-2,000 PC market.
[1] I updated the text here because I'd originally commented here about the price of RAM which is largely irrelevant to the actual limitations.
[2] As has been pointed out below, the memory is not on the die with the CPU, but is in the same package. Leaving the text above intact.
To your main points, they have yet to fully utilize advanced packaging (TSMC 3D for example) to get much more RAM in the SOC. They could also go off package at the expense of power, a good tradeoff for a desktop system. The die size is also small compared to competitive processors (120 mm^2) so they can certainly add more cores. I think with a larger cost budget they'll make the high end sing.
I don't mean to pick on you as you're not alone in what is a very natural skepticism. However, it is somewhat amusing to watch the comments about the M1 over time. When Apple announced the M1 based products many critics were crying impossible, faked, rigged benchmarks, etc... Now that the products have proven to have performance at least as good as claimed, lots of people are suggesting this is some kind of low end fluke result and the higher end systems won't be so great. Just wait. I think we are seeing a tipping point event where RISC (fueled by great engineering) is finally fulfilling its promise from many years ago.
> To your main points, they have yet to fully utilize advanced packaging (TSMC 3D for example) to get much more RAM in the SOC.
The big problem is as you get larger and larger amounts of RAM, the demand drops precariously. The number of people who need 16GB of RAM? Very large. The number who need 32GB is at least an order of magnitude smaller. The number who need 64GB another order of magnitude smaller. The number who need 256GB of RAM or more is likely in the low thousands or even hundreds.
Making a custom package for those kind of numbers becomes prohibitively expensive.
> I don't mean to pick on you as you're not alone in what is a very natural skepticism. However, it is somewhat amusing to watch the comments about the M1 over time. When Apple announced the M1 based products many critics were crying impossible, faked, rigged benchmarks, etc
I've figured from the start that Apple wouldn't make this transition unless there were a significant win here. In my above comment, I think I made it quite clear that I expect Apple's upcoming CPUs to outperform Intel.
I'm just not as certain the delta between Apple's top end CPUs and Intel/ AMD will be as great as the delta between the M1 and the Intel CPU it replaced. So for example, the M series chip might be 20-30% faster than the Intel in the 16" MacBook Pro, not double the performance as it was in the MacBook Air.
> The number of people who need 16GB of RAM? Very large. The number who need 32GB is at least an order of magnitude smaller. The number who need 64GB another order of magnitude smaller. The number who need 256GB of RAM or more is likely in the low thousands or even hundreds.
"need" can be a combination of objective and subjective takes, but I would posit that the amount who would at least purport to need 256GB+ is radically, radically higher than the low thousands.
In a laptop, low thousands might be about right. And for RAM, need captures it pretty well. Either you will once in your life need to do something that uses 256GB ram, in which case you need it, or you don't.
As for need, as alluded to in my previous reply generally I agree in an objective sense (although uses 256GB does not necessarily mean it needs it either). On the subjective side, I have long-observed that people will blindly assert that more memory is better even when they don't profile their peak physical usage and may easily never make use of the amount they have outside of disk caching. Even if folks don't need incredible amounts of memory, that doesn't necessarily stopping them from wanting it even if it provides little to no benefit.
Yes, I expect an ARM MacBook Pro not to be that massively faster in the peak pearformance, but it should run considerably cooler. This means sustained peak performance and overall less fan noise. If I have anything to critisize about the MB Pro, it is that there is just too much fan noise with even not so big loads and the machine just getting very hot. Adding more battery lifetime would also be a welcome improvement.
(Though, 8 high performance cores would also deliver a quite impressive speed)
I've had problems with MB Pros getting too hot for at least a decade. My 2008 model was actually too hot to use on my lap. Sun-burn level of hot if I wore shorts, or even something like pajama pants.
This is kind of what I expect of the 16" MBP and the higher end 13" MBP, cooler running with low/ no fan noise, tremendous battery life, 20-50% better performance than the M1, drop 8GB RAM and offer 32GB, better video performance (support dual 5k displays).
It's possible they will launch the iMac with the same chip as the MBP 16 as well.
Fair enough. I may have projected a number of other comments onto yours a bit. Sorry about that. If the delta is similar it would certainly be crazy fast.
As far as the packaging, I agree with your general assertion. However, they ship about 20 million computers and about 240 million iOS devices per year, all of which require custom SOC packages. Needless to say, they are a very large customer with their packaging suppliers. I could be wrong, but I think the leverage they get will keep the costs in line even for a smaller slice of their premium priced products.
Apple has always billed their big selling point in terms of performance per watt. That narrative might change.
I suspect even if the 16" Pro has more modest performance gains than the Air, it will still have massively better battery life. The iMac and Apple's bigger devices have a lot of thermal and power headroom to make up for the shortcomings of Intels CPUs.
It seems like Apple walked away from a bad PowerPC situation into Intel's arms only until they could do something like this... Especially after the past few years where Intel can't execute on the fab process and forced Apple to switch vendors when Intel couldn't execute on 5g.
> To your main points, they have yet to fully utilize advanced packaging (TSMC 3D for example) to get much more RAM in the SOC.
The M1 is using off the shelf LPDDR4 modules on the package but not on the die. 3D stacking is possible for denser DRAM modules but wouldn't make much sense compared to just adding 2 more DRAM modules and spending the physical space on it - there's more than enough room especially in devices like the Mac Mini. A boring ol' daisy chain setup would work perfectly fine here.
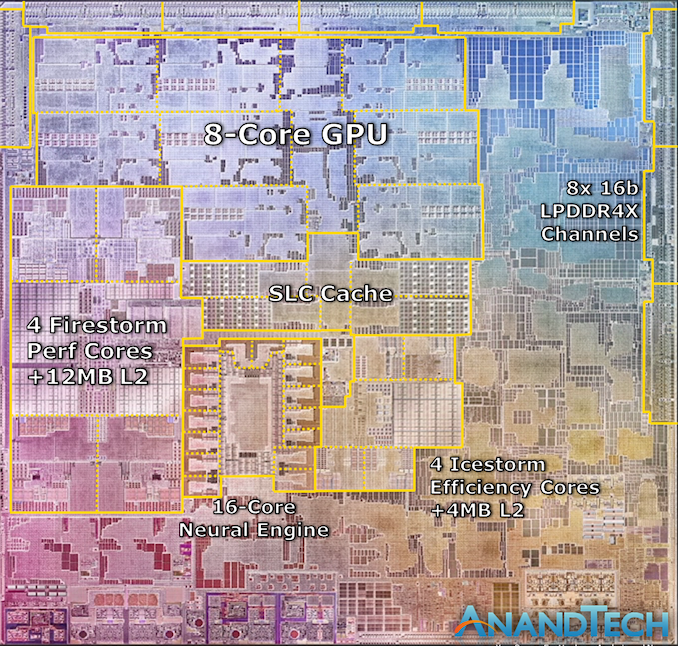
Interesting, where do you find the size of these dies? I was really curious about how large the Firestorm cores are compared to say Zen3 or Intel cores.
How many cores do you think Apple can realistically add? Can they get up to something like threadpiper. or are we talking more about something along the lines of a 12 core upper limit?
The Zen 3 is interesting. It has a separate IO chip coupled with one or two 8 core processors. The 8 core version has a total die area of about 80 + 125 = 205 sq mm. The 16 core is 285 sq mm.
Intel chips are all over the place depending on core design and number of cores. As an example from the reference above, a 6 core i7-8700K is about 154 sq mm. The i9-9900K is 180 sq mm and the 10 core is 206 sq mm.
How many cores can they add? From the die photograph of the M1, a very rough estimate of area dedicated to the 8 cores and associated cache is maybe 40 percent or 48 sq mm. Compared to the 205 sq mm for the 10 core i9, they could add about 16 more cores. Seems unlikely of course because of all the other things you have to do to support that. It is reasonable though to imagine a 180 to 200 sq mm Mx chip with maybe 16 CPU cores and perhaps a few more GPU cores. Fun.
The fundamental limit to die size is what's known as the reticle size. That's the maximum size of the stepped design that is repeated over the wafer. This is a limitation of the lithography equipment. That limit is around 850 sq mm, but no one builds a high volume chip anywhere close to that big because the yield and therefore the cost would be atrocious. Instead, several repeats of the design are included in the reticle and then that is stepped over the entire wafer.
More interesting is comparing core size, I think. Just spitballing in MS Paint, if we chop off the FP the Zen 3 core plus 1MB L2 is probably ~ 3 sq mm. The M1 seems to be about 2 Firestorm complexes high and 4 wide, so a complex would be 15 sq mm, or ~ 3.75 sq mm for a core plus 3MB L2.
> but at $200/ 8GB, getting up to 32GB or 64GB is going to be a challenge and quite expensive
It's worth noting that Apple's price for the upgrade doesn't necessarily tell us much about the actual cost to them. They've famously charged exorbitant amounts for RAM for a long time, including charging that same rate, $400/16GB, to bump up the RAM on the current (Intel) 16" Macbook Pro:
I updated my comment hopefully made it more clear. The issue is less about the $$ amount, and more about the practicality of including ever larger amounts of RAM on the SoC.
There's no DRAM on the SoC die. The DRAM is separate dies that are packaged close to the SoC die, but they don't have to be that close. A typical graphics card has an array of 8+ DRAM packages surrounding the GPU, with a faster bus speed than Apple's using.
To scale up DRAM capacity and performance, Apple will have to increase the number of DRAM controllers on the SoC and maybe increase the drive strength so that they can push the signals a few cm over PCB instead of less than 1cm over the current SoC package substrate. Neither of those is a particularly difficult scaling problem.
I think you might be underestimating the importance of RAM proximity to the CPU.
The speed of electricity over copper is listed as being 299,792,458 meters per second. A meter is 39.3701 inches, so that would be 11,802,859,050 (11.8 billion) inches per second.
Now imagine a CPU trying to send a round trip electrical signal 4 billion times per second over the the RAM, over the distance of two inches (a 4 inch round trip). That's literally 16 billion inches of distance that you are asking the electrical signal to cover in the space of a second, but we know that the electricity can only physically cover 11.8 billion inches in that second, so we would essentially have a bottleneck due to the physical restrictions of the speed of light.
Now imagine if you could cut that distance down from inches to cm or even millimeters... This is the benefit of having everything together on an integrated chip.
Speed of light delay due to trace length really is not that important to DRAM. Adding ~6cm to the round-trip path would add about 0.3ns to DRAM latency, which is already over 30ns. So we're looking at less than 1% difference between on-package vs on the motherboard. This is a much less important concern than signal integrity and drive strength necessary to maintain bandwidth when moving DRAM further from the CPU.
Your argument would be much closer to relevant if we were discussing SRAM caches.
> Moving high bandwidth RAM to be shared between the CPU & GPU
There's a really weird amount of focus on this. Unified memory has been a thing for almost half a decade now. It become a thing as soon as AMD stuck the CPU & GPU behind the same IOMMU ( https://en.wikipedia.org/wiki/Heterogeneous_System_Architect... )
Now you may ask, but why hasn't anyone leverage this before? And the answer is they have, but it's usually not worth doing because usually the integrated GPU isn't worth using for anything. As in, the market for HPC software that doesn't benefit from a discreet GPU is vanishingly small. So nobody really cares about it. But there are applications of this. Things like Intel's QuickSync should be internally leveraging this on the relevant CPUs, for example. So those sorts of frameworks (like MLKit) will just be a bit faster and cheaper to spin up.
The rise in consumer software that does "HPC-like" workloads (eg, facial recognition, voice recognition, etc..) make this more interesting, but there's nothing new here, either. It's certainly not playing any meaningful role in the M1's current performance. The bigger question here would be to what extent does Apple push this. Like is Apple going to try and push integrated GPUs for the iMac Pro? What about the Mac Pro?
Well, the article is basically just wrong on that, kinda. It is a single memory controller, which means the CPU & GPU are fighting for bandwidth. It's not an exclusive lock, no, but you will see a very sharp decline in memcpy performance if you're also hammering the GPU with blit commands.
Which is the same as basically all integrated GPUs on all modern (or even kinda modern) CPUs. You don't usually have such heavy CPU memory bandwidth and GPU memory bandwidth workloads simultaneously, so it's mostly fine in practice, but there is technically resource contention there.
Is this from real world observation, or just looking at the diagrams or what? Because by all accounts, these chips don’t seem to encounter any issues with the ui or encoding movies or whatever. Which would strongly imply that memory contention between the gpu and cpu is not a significant issue.
If you have actual data that backs up your position, I would love to see it.
As I said, in most scenarios this doesn't matter, so I'm not sure why you're pointing at an average scenario as some sort of counter-argument?
There's a single memory controller on the M1. The CPU, GPU, neural net engine, etc... all share that single controller (hence how "unified memory" is achieved). Given the theoretical maximum throughput of the M1's memory controller is 68GB/s, and that the CPU can hit around 68GB/s in a memcpy, I'm not sure what you're expecting? If you hammer the GPU at the same time, it must by design share that single 68GB/s pipe to the memory. There's not a secondary dedicated pipe for it to use. So the bandwidth must necessarily be split in a multi-use scenario, there's no other option here.
Think of it like a network switch. You can put 5 computers behind a gigabit switch and 99% of the time nobody will ever have an issue. At any given point you can speedtest on one of them and see a full 1gbit/s on it. But if you speedtest on all of them simultaneously you of course won't see each one getting 1gbit/s since there's only a single 1gbit/s connection upstream. Same thing here, just with a 68GB/s 8x16-bit channel LPDDR4X memory controller.
The only way you can get full-throughput CPU & GPU memory performance is if you physically dedicated memory modules to the CPU & GPU independently (such as with a typical desktop PC using discrete graphics). Otherwise they must compete for the shared resource by definition of being shared.
The point I was originally responding to was, "Unified memory is not a good thing, makes the CPU and GPU fight for access." There is no evidence here that this is a significant issue for the M1.
So even if the memory bandwidth is split, the argument that this is a problem is not in evidence.
Considering how much emphasis Apple put on it, I don't think it is weird at all. Apple made big claims about their CPU and attributed a significant chunk of that performance gain to their unified memory.
Their claims about the CPU have proved largely accurate. Why would they fabricate the reasons behind that performance? It's not like they are throwing off competitors here.
It seems that some analysis overestimates UMA. It won't accelarate simple CPU performance and won't reduce RAM usage unless its data is also used on GPU.
Possibly is they also call stacked RAM as "UMA" rather than shared RAM between CPU and GPU?
What I find odd is how someone rushes out to "debunk" nearly everything Apple has said that they did to optimize the M1. It's clear the M1 is fast, so clearly some of the things they did to optimize it worked. Why Apple would lie about what those optimizations are is a head scratcher.
It strikes me as odd that so many people claim there is zero benefit. I'm left wondering if people think Apple is lying about all of the actual reasons the CPU is fast and have presented this as a smokescreen. Makes zero sense to me.
> Why Apple would lie about what those optimizations are is a head scratcher.
Indeed it is. But marketing isn't really known for being technically accurate, why would Apple's be any exception?
> It strikes me as odd that so many people claim there is zero benefit.
That's not the claim at all. The claim is that unified memory isn't new, and there's a decent chance you already had it. For example, every Macbook Air of the last few years has been unified memory. The M1's unified memory is therefore a continuation of the existing norms & not something different. The M1's IPC is something different. The M1's cache latency is something different. The M1's 8-wide decoder is something different. There's a lot about the M1 that's different. Unified memory just isn't one of them, and unified memory still just doesn't improve CPU performance. All those CPU benchmarks that M1 is tearing up? It'd put up identical scores without unified memory, since none of those benchmarks involve copying/moving data between the CPU and a non-CPU coprocessor like the GPU or neural processor.
> But marketing isn't really known for being technically accurate, why would Apple's be any exception?
The comments and emphasis about the benefits on unified memory come right out of Johny Srouji's mouth. Granted, everything Apple execs say is vetted by marketing and legal, but I can't see Srouji emphasizing a made-up marketing point as a weird red herring either.
As I mentioned above, someone on HN has "debunked" every single optimization Apple says they've done. But the numbers don't lie. Somewhere along the way, some of the "debunking" is full of shit. I'm guessing most of it is.
The simplest explanation is that Apple is being forthright here and people don't understand what they've done or how those optimizations work.
The whole focus on this makes no sense to me as well. UMA has been standard architecture for mobile SoCs since the dawn of time(aside from a few oddballs). Ditto tiling GPUs and the few other things I've seen called out.
Heck the XBox 360 used UMA[1] and the PS3 didn't[2]. It really didn't play into the systems performance directly(other than you might do some crazy tricks like store audio data in VRAM and stream it back). With UMA you can get into cases where heavy CPU reads can impact other parts of the system because the memory controller is shared.
I've seen a few very rare edge cases where you can do cool tricks with UMA on mobile (which as you say have been UMA for years). For example on Android for VR you can have the sensor data stored in a chunk of memory that can also be read by the GPU, so your last-second time warp can have that smidge less latency by sampling the latest sensor data as hot off the sensor as it gets, without even bouncing off of the CPU. ( https://developer.android.com/ndk/reference/group/sensor#ase... )
But the best VR experiences are still done on non-UMA desktop PCs with discrete graphics so... At some point the slight efficiency wins of UMA are trumped by just the raw horsepower you get from multiple big dies.
Its just LPDDR4. HBM is a different thing. You can tell because HBM has 1024-bits bus per chip, but LPDDR4 is just 128-bits per chip.
There's almost nothing special about the RAM, aside from it being locked to the chip and unable to be upgraded. It seems like the clockrate to the LPDDR4 is a bit higher than average, but its nothing extravagant.
> How do they manage even larger amounts of RAM? Perhaps they will have external RAM in addition to the on chip RAM, with perhaps 32GB of onboard memory and the external RAM being used as swap? This takes a bit away from the super-efficient design they have currently.
They COULD just support a DIMM stick like everyone else. But Apple doesn't want to do that strategy and prefers packaging the RAM and CPU together for higher prices.
This isn't a 1024-bit bus (that requires 1024 wires, usually an interposer). This is just your standard 128-bit LPDDR4, maybe at a slightly higher clockrate than others for a slight advantage in memory.
------
In case of HBM2, you can't upgrade RAM beyond one-stack per 1024-bit bus. A GPU goes 4x wide with 4x 1024-bit busses to 4x different HBM2 stacks for a massive 4096-pin layout (!!!), that's 4096 wires connecting a GPU to individual HBM2 chips.
Hypothetically, a future GPU might go 6-stacks or 8-stacks (8192-wires), but obviously running all those wires gets more-and-more complex the bigger you go. So in practice, GPUs seem to be ~4-stacks, and then you just buy a new GPU and run the entire GPU in parallel when you need more RAM.
> > Moving high bandwidth RAM to be shared between the CPU & GPU
That's not the advantage. When the L3 cache is connected between CPU and GPU, you gain a bandwidth edge in heterogenous systems. AMD / Intel have been connecting L3 caches to their iGPU solutions for over a decade now.
CPU - to DDR4 - to GPU is very slow compared to CPU - to L3 cache - to GPU. Keeping the iGPU and CPU memory-cohesive is a nifty trick, but is kind of standard at this point.
On a related topic, will Apple need to go up to LPDDR5 to get to 32GB of RAM? I read a comment a day or so ago that said that LPDDR4 is limited to 16GB. I'm wondering if Apple can release a 32GB machine within the next 6 months.
I'm not an expert here, just going by the articles I've read on this topic recently. That said...
> Its just LPDDR4. HBM is a different thing.
Hmm, Apple refers to it as High Bandwidth Memory. The Register[1] refers to it as "High Bandwidth Memory" and also:
"This uses 4266 MT/s LPDDR4X SDRAM (synchronous DRAM) and is mounted with the SoC using a system-in-package (SiP) design."
Which implies to me that some kinds of LPDDR is indeed HBM and that what's on the M1 isn't something which can be replaced by drop in RAM.
> That's not the advantage.
Hmm, again quoting The Reg here because I think it's a fairly independent source on Apple hardware.
"In other words, this memory is shared between the three different compute engines and their cores. The three don't have their own individual memory resources, which would need data moved into them."
Maybe I didn't express this clearly enough above.
> AMD / Intel have been connecting L3 caches to their iGPU solutions for over a decade now.
My point above wasn't that Apple invented this idea. It was that the idea doesn't scale well. Who invented it doesn't really matter.
You're right. The Register article says that. The Register article says that because they're parroting Apple's marketing. I don't fault The Register for copying Apple. I fault Apple for being misleading with their arguments. LPDDR4x is NOT HBM2. HBM2 is a completely different technology.
"High Bandwidth Memory", or HBM2 (since we're on version 2 of that tech now), HBM2 is on the order of 1024-bit lanes per chip-stack. It is extremely misleading for Apple to issue a press-release claiming they have "high bandwidth memory".
HBM2 is the stuff of supercomputers: the Fujitsu A64FX. Ampere A100 GPUs. Etc. etc. That's not the stuff you'd see in a phone or laptop.
> "In other words, this memory is shared between the three different compute engines and their cores. The three don't have their own individual memory resources, which would need data moved into them."
It would be colossally stupid for the iGPU, CPU, and Neural Engine to communicate over RAM. I don't even need to look at the design: they almost certainly share Last-Level Cache. LLC communications are faster than RAM communications.
From the perspective of the iGPU / CPU / Neural Engine, its all the same (because the "cache" pretends to be RAM anyway). But in actuality, the bandwidth and latency characteristics of that communication are almost certainly optimized to be cache-to-cache transfers, without ever leaving the chip.
While I can certainly understand a certain amount of frustration at Apple for using phrasing that has been used as an official marketing term, I also have to say that I don't think too highly of whoever came up with the idea that "HBM" should be an exclusive marketing term in the first place, when it's a very straightforward description of memory that includes, but is not limited to, memory within that specific label.
Based on what Apple's doing, it seems perfectly legitimate and reasonable to refer to the memory in the M1 Macs as "high-bandwidth memory", even if its lanes are not 1024 bits wide.
When Supercomputers and GPUs are pushing 1000GB/s with "high bandwidth memory", its utterly ridiculous to call a 70GB/s solution 'high bandwidth' (128-bits x 4266 MT/s).
There's an entire performance tier between normal desktops and supercomputers: the GDDR6 / GDDR6x tier of graphics RAM, pushing 512GB/s (Radeon 6xxx series) and 800GB/s (NVidia RTX 3080).
To call 128-bit x 4266MT/s "high bandwidth" is a complete misnomer, no matter how you look at it. Any quad-channel (Threadripper: ~100GB/s) or hex-channel (Xeon ~150GB/s) already crushes it, let alone truly high-bandwidth solutions. And nobody in their right mind calls Threadripper or Xeon "high bandwidth", we call them like they are: quad-channel or hex-channel.
> "High Bandwidth Memory", or HBM2 (since we're on version 2 of that tech now), HBM2 is on the order of 1024-bit lanes per chip-stack. It is extremely misleading for Apple to issue a press-release claiming they have "high bandwidth memory".
Considering how few people know what HBM2 is, the idea that Apple is trying to make any claims that their solution uses HBM2 seems weird.
Apple absolutely knows what HBM2 is. They've literally got products with HBM2 in it.
Note: LPDDR4x RAM is typically called "Low Power" RAM, in fact, that's exactly what LPDDR4x is for. Its designed to be a low-power consumption ram for extended battery life.
It takes a special level of marketing (ie: misleading / misdirection) to buy two chips of "low power" RAM, and try to sell it as "high bandwidth RAM".
> "This uses 4266 MT/s LPDDR4X SDRAM (synchronous DRAM) and is mounted with the SoC using a system-in-package (SiP) design."
> Which implies to me that some kinds of LPDDR is indeed HBM and that what's on the M1 isn't something which can be replaced by drop in RAM.
Sibling comment already outlined that HBM is unique & different from LPDDR. Using LPDDR means it's definitely not HBM.
But you can definitely hit LPDDR4 at 4266 MT/s speeds with drop-in RAM. That's DDR5, which in the "initial" spec goes all the way to 6400 MT/s. More relevantly, DDR5-4800 (so 4800 MT/s) modules are among the first to actually be manufactured: https://www.anandtech.com/show/16142/ddr5-is-coming-first-64...
It is just LPDDR4X, it is normal ram. Claims of something special about the ram are marketing untruths, other than it being high end laptop ram, like you would get on a high end x86 laptop too.
That it is packaged right next to the cpu may reduce latency by half a nanosecond out of ~60.
Where it might help more is by reducing the power needed to run the ram. Putting it on package keeps the trace lengths to a minimum and might reduce the power the memory controller needs to talk to it.
Another discussion thread has noted that LPDDR4x can be 16x bits or 32x bits.
DDR4 is always 64-bits. Two channel DDR4 is 128-bits. So right there, 2-channel x 64bits DDR4 is the same bus-width as the 8-channel x 16bits LPDDR4x.
With that being said, 8-channel LPDDR4x is more than most I've heard of. But its not really that much more than DDR4 configurations.
128-bit (2-channel) DDR4 at 3200 MT/s is 51 GB/s bandwidth.
4266 MT/s x 128-bits (8-channel) LPDDR4x is 68GB/s. An advantage, but nothing insurmountable.
--------
A Threadripper can easily run 4-channel 3200 MT/s (100GB/s). Xeons are 6-channel. GPUs are 500GB/s to 800GB/s tier. Supercomputer-GPUs (A100) and Supercomputer-CPUs (A64Fx) are 1000+GB/s.
----
HBM2 has a MINIMUM speed of 250GB/s (single stack, 1024-bits), and often is run in x4 configurations for 1000GB/s. That's what "high bandwidth" means today. Not this ~68GB/s tier Apple is bragging about, but instead HBM is about breaking the PB/s barrier in bandwidth.
--------
But yes, I'll agree that Apple's 68GB/s configuration is an incremental (but not substantial) upgrade over the typical 40GB/s to 50GB/s DDR4 stuff being used today.
I think I've read that there are now Ryzen laptops shipping with LPDDR4x as well. It's awesome that Apple is using ram with this much bandwidth, but it's not exclusive.
I completely forgot that 11th gen Intels actually supported LPDDR4 / LPDDR4x.
Its kind of ridiculous: LPDDR4 has been used in phones for years, but it took until this year before Intel / AMD added support for it. Ah well. This one is definitely on Intel / AMD's fault for being slow on the uptake.
DDR4 had largely the same power-draw of LPDDR3 (but was missing sleep-mode). So I think CPU makers got a bit lazy and felt like DDR4 was sufficient for the job. But LPDDR4x is leapfrogging ahead... the phone market is really seeing more innovation than the laptop / desktop market in some respects.
I'm doing this from memory btw, so I might have gotten something wrong. But my understanding of LPDDR4x is 32-bits per channel, 4x channels per chip (typical: different LPDDR4x chips can have different configurations).
Automotive grade, but allegedly still LPDDR4. Looks like they're x16 and x32, as you said.
--------
Hmmm, I know that the M1 is specified as 128-bits on Anandtech's site. If its 4-dies per chip, then 32-bits per die, 4-total dies of LPDDR4? I know Anandtech is claiming a 128-bit bus, so I'm reverse-engineering things from that tidbit of knowledge.
-----
Either way, these 128-bit or 64-bit numbers are all very much smaller than 1024-bit per stack HBM2 (high-bandwidth memory). Much, much, much much smaller. Its clear that the M1 isn't using HBM at all, but some kind of LPDDR4x configuration.
This chip claims to be LPDDR4x, but it is a 556-pin package. This is in contrast to your earlier data-sheet, which only has 200-pins. Maybe LPDDR4x doesn't have any standardized pinouts?
This isn't exactly where I normally work, so I'm not entirely sure what is going on.
You can clearly see the two LPDDR4x chips packaged with the Apple M1. There's no question that the M1 package contains two DRAM chips. The only question is the configuration of the "insides" of these DRAM chips.
------
Anandtech's interviews give us a preview: 128-bit wide bus (8 x 16-bit it seems), two chips, LPDDR4x protocol. The details beyond that are pure speculation on my part.
> They moved high bandwidth RAM to be shared between the CPU & GPU, but they[1] can't just keep expanding the SoC with ever larger amounts of RAM Perhaps they will have external RAM in addition to the on chip RAM, with perhaps 32GB of onboard memory and the external RAM being used as swap? This takes a bit away from the super-efficient design they have currently.
The RAM isn't on the SOC, it's soldered on the package, which is a very different proposition. Possibly so they don't have to bother routing on the board (meaning they can shrink the board further), and can cool the RAM at the same time as the SoC (without the need for a wider cooler base).
The PS5 also has unified memory and uses faster RAM, the RAM chips are soldered on the board around the SoC.
>I'm kind of wondering how scalable the performance increases they made here are
It's a good question and really only time will tell, but this same comment was made about these chips in the iPhone: "impressive yes, but would they be able to scale up to power a laptop?" A lot of people said no back then, and yet here we are.
Apple's not stupid and they're not going to slap Intel in the face like this if they're not 100% sure they won't need them again in the future. I'd be willing to bet they already know the answer to these questions (and likely even have 32/64GB M1s running in their labs). There's just no way they'd go into something like this blindly.
I thought I was pretty clear that I fully expect Apple will be able to migrate their entire line.
My only question is whether they will blow the doors off Intel/ AMD the way they did with the M1. With the MacBook Air (and largely with the base MacBook Pro), Apple was able to more than double the processor speed even while increasing processor speed. I'm not convinced we'll see that kind of explosive speed improvements with the 16" MacBook Pro. Battery life will almost certainly trash the current MBP. I'm just not confident we'll see the base 16" MacBook doubling its CPU performance.
FWIW, I don't see anything Apple has done as a slap in the face. They've been pretty reasonable about not mentioning Intel in their performance numbers. Instead all metrics are based on the performance of previous generation MacBook Air.
I would be stunned if Apple outsourced any part of their CPU/ GPU design. About the closest I could see to that would be offering discrete graphics on some of their top end models.
The HBM confusion comes from Apple Marketing, they have since corrected the phase.
It uses LPDDR4x, fairly standard across the industry.
The LPDDR4 spec allows up to 8 Channel per package ( Although I have not yet seen any manufactures announced such a SKUs ), meaning Apple could scale to 32 GB, or with LPDDR5 using the same setup gives them 64GB while increasing the bandwidth by ~30%+.
From a portable perspective I think 64GB is good enough. Not to mention larger size of RAM being unsuitable for product with battery.
I have no idea how their Desktop part will play out, especially when Memory bandwidth is required for their universal memory.
This is something I have been trying to understand. What is the practical limit today? How many cores, and how much more memory can Apple add before they run out of Silicon? From what I understand there are a number of practical limits to how big they can make the silicon die, because the equipment on the factories are not really made for arbitrary large chips, and anyway the defect rate will quickly rise if you make too large chips.
Like can we expect say something like a 32 core M3 chip with 64 GB RAM, or will that be too much for this design?
> with perhaps 32GB of onboard memory and the external RAM being used as swap?
I wouldn't be surprised if Apple was working on some ways to optimize swap so that SSDs can fill the roll of "external ram." At this point, PCI Express has the theoretical bandwidth to compete with DDR5, but it can't handle anywhere near the number to transactions. But I bet with some clever OS-level tricks, they could give performance that's good enough for most background applications.
Apple's still working with the same NAND flash memory as everyone else, so there's little opportunity for them to do anything particularly clever at the low level.
But even looking at commodity hardware, high-end SSDs are already capable of handling a comparable number 4kB random reads per second to the number of context switches/page faults a CPU core can handle in the same second. The huge latency disparity is the problem: the SSD would prefer you request 4kB pages dozens at a time, but a software thread can only fault on one page access at a time. Using a larger page size than 4kB will get you much better throughput out of a SSD. On the OS side, swapping out a large number of pages when the active application changes can make good use of SSD bandwidth, but when a single application starts spilling into swap space, you're still fundamentally screwed on the performance front.
{kind=link}
{kind=link}
They moved high bandwidth RAM to be shared between the CPU & GPU, but they[1] can't just keep expanding the SoC[2] with ever larger amounts of RAM. At some point they will need external RAM in addition to the on chip RAM. Perhaps they will ship 32GB of onboard memory with external RAM being used as swap? This takes a bit away from the super-efficient design they have currently.
Likewise, putting increasingly larger GPUs onto the SoC is going to be a big challenge for higher performance/ Pro setups.
I think Apple really hit the sweet spot with the M1. I suspect the higher end chips will be faster than their Intel/ AMD counterparts, but they won't blow them out of the water the way the current MacBook Air/ MBP/ mini blow away the ~$700-2,000 PC market.
[1] I updated the text here because I'd originally commented here about the price of RAM which is largely irrelevant to the actual limitations.
[2] As has been pointed out below, the memory is not on the die with the CPU, but is in the same package. Leaving the text above intact.