I'm not a screen reader user, but I have ublock origin on my mobile filtering out media elements over 1000kb. Instead I was given the alt texts for at least one of the images.
It's great when people do this, so many times I also just get emails from marketing that are images only without any descriptors, and I can't help but think about how many international groups simply don't care about accessibility.
I regularly use the speech feature of macOS to read web pages aloud to me, so I was also pleasantly surprised to hear meaningful descriptions of the images from the alt text.
Maybe one day computers will be able to describe to me what is in an image without a person having to type it.
This is very slowly happening for some Chrome users. Generating meaningful, accurate descriptions is a general AI task, though.
As an aside, Chrome does the autolabeling (including OCR) only if there's no alt provided, so alts like "screenshot", "photo" etc. actually cause more harm than good.
It's fairly long and winding but the main point seems to be that because Unicode exists, and Unicode supports characters that are problematic for the concept of a unique identity, then it is the concept of a unique identity that is the problem.
It also presents a front-end solution (fuzzy-text matching for @'ing someone's display name in a Slack channel) but does nothing to address the ever-present back-end need to actually validate that a client is who they say they are.
There's a good reason you can't make your bank username 𝕥𝕙𝕖 𝕜𝕚𝕟𝕘 , and it's not "because developers are anglo-centric and intrinsically against all the wonderful individual expression and identity that Unicode could bring us."
Since the article mentioned Punycode, I actually think the current implementation is an elegant solution to a real problem. Of course we should enable folks from anywhere around the world to experience the Internet in their native language. That's the reason the Chrome algorithm to determine whether to show Punycode is so complex - it has to carefully balance the desire to show text the way it was intended while considering that it might be a malicious attempt to phish someone using characters outside their typical locale. In this case, the front-end solution of asking the user "which google.com from this list of two identical-looking google.com's is the one you want" just won't fly.
Your bank doesn't need the concept of a username. A service may need a username if it's going to have social features, public content, or other ways in which users interact with each other. If people just log in and use the service, let them use an email address as their login (which is already unique), and don't make them pick a username at all.
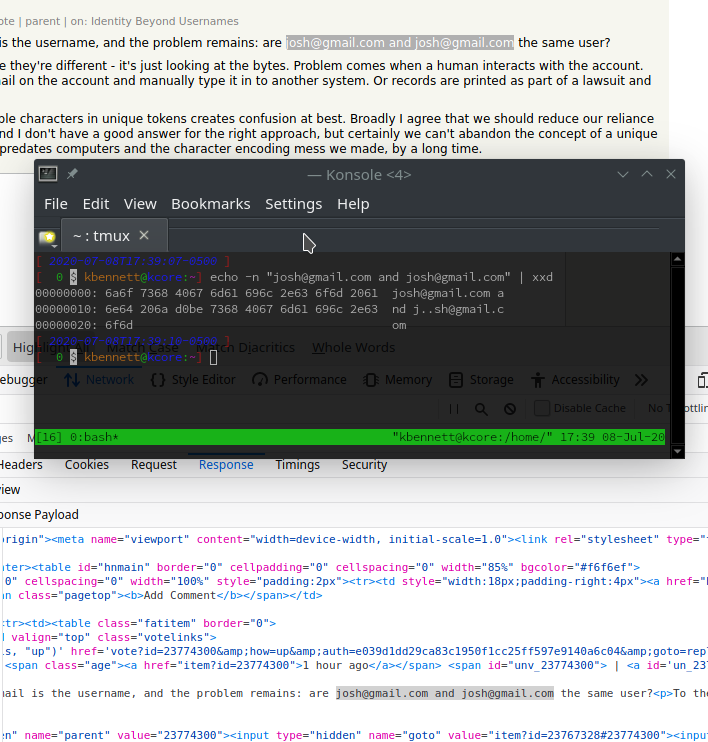
In that case, the email is the username, and the problem remains: are josh@gmail.com and jоsh@gmail.com the same user?
To the system, of course they're different - it's just looking at the bytes. Problem comes when a human interacts with the account. Maybe they see the email on the account and manually type it in to another system. Or records are printed as part of a lawsuit and has to be transcribed.
Allowing indistinguishable characters in unique tokens creates confusion at best. Broadly I agree that we should reduce our reliance on unique identifiers, and I don't have a good answer for the right approach, but certainly we can't abandon the concept of a unique identifier altogether: it predates computers and the character encoding mess we made, by a long time.
> are josh@gmail.com and jоsh@gmail.com the same user?
I like to think I have a keen eye and pay attention to subtle details. I don't think I see a difference between the two addresses. Your message seems to state they're different though. Did HN normalize the differences? Did my browser?
In a blaze of stupidity, I decided to to copy and paste into my terminal and pipe it through a hex dump [0].
* The character difference doesn't show up in the viewport in Firefox; of course, it's rendered.
* The character difference doesn't show up in the HTML editor; of course, it's showing the "raw text" and the "raw text" is valid unicode.
* It doesn't show up in the browser's network inspection of the response payload. That's the scariest part in Firefox IMO.
* It doesn't show up in my Terminal either. Why shouldn't it? We've fought long and hard for terminals to support Unicode.
Of course, then there's the fact that I decided to copy and paste from a browser into my terminal even though I already knew I shouldn't [1]. What else could be hidden in unicode? An entire bash script starting with `sudo`, perhaps? Websites can already inject their shitware into the clipboard with clipboard events [1].
The second email address uses the Cyrillic small letter O, which renders the same as the Latin small O in almost all fonts. You can see this in your hex dump, too: Instead of a single o, your hex dump shows two bytes for the second character in the second email address.
They aren't "lying", it's the same glyph in many fonts.
That you think homoglyphs would somehow look different in any of those steps of your post is peculiar to me. l and I are the same in some fonts and they are in the ascii set.
That's what I mean, looking at the bytes is the only way to know.
How would you solve homograph/glyph attacks though? One idea is yet another encoding where there are no homoglyphs, only whitelisted diacritic sequences, and there aren't more than one way to assemble the same character ("ó" vs "o"+"´". So tough potatoes for Cyrillic "o", it's forced to use its nearest equivalent: 0x6f Latin "o" in the ascii set.
> How would you solve homograph/glyph attacks though? One idea is yet another encoding where there are no homoglyphs
First, modern operating systems (should?) already provide APIs to canonicalize UTF.
Second, perhaps an additional API needs to be created which suggests similarities between characters intended for use by an intelligence (artificial or otherwise...).
Unicode, in some cases, did avoid separating characters out, and that was also a mistake that damaged existing alphabets irreparably.
See the Han unification [0] effort.
There are characters in Japanese and Chinese which are similar, but written differently in each... And they ended up using the same codepoint in unicode for them and relying on different fonts.
So now I can't easily quote a japanese sentence in a chinese book without having to use two different fonts, which seems quite silly.
Worse yet, there were many common glyphs in use (especially for names) that were unified out of existence. There are literally people who couldn't type their names in unicode. There are a lot of works of text that can't be faithfully OCRd due to not having certain character variants that were unified away.
Okay, so why wasn't the cyrillic alphabet unified with the latin one even if the japanese and chinese ones were? Clearly Han unification did much more damage than cyrillic unification would have.
Well, the answer is sorta politics. ISO 8859 is what came before Unicode, as far as the unicode consortium is concerned. Since ISO 8859 encoded latin and cyrillic separately, that got carried over for "compatibility". Because the unicode consortium and ISO 8859 were both more western-centric, and CJK users had already dealt with things in a way that was standardized only over there, not in any western ISO standard, of course the unicode consortium would honor the existing ISO standard and ignore the CJK standards.
Idunno, the Han unification wasn't that aggressive. What would really be destructive would be something like 瞭 and 了 sharing a codepoint.
Which glyphs were “unified out of existence”? Isn't it more just a matter of using the appropriate typeface or a variation selector? In my limited experience, I've noticed some things being non-unified that I would expect to be unified, like 步 and 歩 (e.g. in 散步 [zh-TW] vs 散歩 [ja-JP]); far as I can tell there isn't any semantic difference between these characters, 新字體 just added a stroke to make one of the radicals more consistent; I guess the idea was that Japanese users mix 新字體 and 舊字體 in text, and JIS character sets had separate codepoints for each from the beginning.
As somebody who is learning both Taiwanese Mandarin and Japanese, I don't think it's common for unified characters to differ enough that they would be unrecognizable. I think that no matter how the Unicode Consortium approached this, they would need to set some limits on what gets a separate codepoint; the question is not whether or not to do the Han Unification, the question is when a glyph is actually its own character.
Let's look at a specific example then of why sharing codepoints between languages is so silly.
Let's talk about 直. Is that a japanese character? A chinese one? Well, let's look it up in a japanese dictionary [0] and then a chinese one [1].
You should see that the results look different. They're two different characters drawn in two different ways. However, in this hacker news comment, there's no way for me to indicate to use one font for one, and one font for the other. I can't say "The japanese glyph 直 is the same unicode codepoint as the chinese glyph 直 even though they render differently. They were unified". I can't make them render correctly as japanese and chinese respectively. For my computer, it _only_ renders in the chinese variant (without the extra stroke on the left) on hacker news. Like most sites, there's no way to indicate in the text input which language that portion of my text is. Unlike with every western script, if I don't indicate the language correctly, it will be actively rendered wrong and difficult for a reader to understand.
To draw an analogy from another hacker news comment, this would be like the unicode consortium saying that 'colour' always renders as 'color', and you just have to switch fonts for it to look like 'colour' [3].
Okay, so that's why unifying things at all is silly and causes trouble.
As for characters that were unified out of existence: unfortunately, examples of those are hard to give. There are various names that have stylistic choices or use unusual characters which can no longer be rendered "correctly". Arguably, that could be seen as akin to the fact that if you style your name calligraphically in the western world, unicode doesn't help you replicate that flair.
> However, in this hacker news comment, there's no way for me to indicate to use one font for one, and one font for the other.
Sure you can, the Chinese one is 直 and the Japanese one is 直. They are still the same character though, and it's meant the same thing the whole time. The Japanese got it earlier, so they form it in a way that would be recognizable to the scribes of the Zhou dynasty, and possibly the Shang dynasty. [0]
Part of how you can “tell” it's the same character, is that the cousin variations are all used in precisely the same way. Many compounds formed with it are shared directly between Japanese and Chinese. [1] [2] [3] It's related right down to in some compounds being interchangeable with 只, the latter being a less dated form of it (i.e. 直中 vs. 只中 in Japanese). And beyond all of this, compounds shared between languages have been written in both orthographies and meant precisely the same thing for a very long time.
I think considering these variations to be separate characters makes about as much sense as considering the s in “stop” to be different in French because it's pronounced slightly differently, and because French penmanship is different from British/American penmanship (i.e. sometimes French people lift the pen while forming a lowercase s [IIRC]).
步 and 歩 are similar for sure, and for people aware of what's in Han unification, it's probably not that bad.
But the problem is, there are many characters very similar to each other, with a difference of one stroke already. 今 and 令 for example, are both simplified Chinese, but with completely unrelated meaning.
So, when you see a character that looks familiar, how can you tell whether you are looking at a character that you don't know or a character you know but rendered in a different language?
While 今 and 令 may be stylized similarly today in Chinese, they are clearly distinct, those sorts of things are not unified in the Han Unification.
In fact 令 is different enough that the version of it no longer commonly used in China now has its own codepoint.
In the case of 今, it means something on its own in Japanese; and to a lesser extent it means something on its own in standard Chinese (kinda like 這, sometimes like 現在) and definitely in classical Chinese. In Japanese, 令 doesn't tend to mean much on its own (though it can still be read a couple ways), but in Chinese it has many standalone meanings.
The local-part of email addresses, which is the part before the @ sign, may only contain ASCII characters, so the other variant is not a valid address.
It's somewhat comforting that that's the case. For argument's sake, we can pretend instead that the 'a' in gmail.com is the Cyrillic 'a' for one of the addresses.
For me the first email address has the initial lowercase j seemingly normal; the second email address has the initial lowercase character that appears as j, except the below-the-line curly part doesn’t extend as far, and doesn’t upturn at all, unlike the first email’s j. This is on iOS 13. Curiously, if I copy and paste, both j’s look the same; they are formatted when pasted the same as the first initial j, which to me seems normal.
I’m on iOS too. I see why you might think there are two different j there but what’s actually going on is that since the quoted text is in italics, and the text is wrapped on our iPhones so that the second italic j is on the next line of text, part of it is outside of the “bounding box” of the text of sorts, and is clipped off in rendering.
Or your platform equivalent of pbpaste. If this isn’t totally safe and could have side effects, your platform’s clipboard implementation is problematic.
Turn on bracketed paste mode everywhere. Doesn’t help with homograph attacks (e.g. an IDN homograph attack tricking you into downloading something from the wrong domain), but at least you’re totally safe until you press enter to execute.
And it is an unbelievable pain in the ass. I accidentally ended up in this situation somehow, and it took me forever to figure out that I had two different accounts with the same email.
If I log into AWS using one account (the one I've had for Amazon.com for more than a decade), I get the console with no resources in it. If I log in with the same email but a different password, I see all of my resources. Absolutely insane.
to distinguish only by password is evil. a token that can be the same over multiple accounts must not be used as an account identifier for login or anywhere else. what if i use the same password on both?
> are josh@gmail.com and jоsh@gmail.com the same user?
You made me think of an interesting hack. We could pass public messages or make public statements that are forever ungoogleable. I could write: “Hey, jоsh, you can bring up the secret menu in еріс games by clicking six times on the blue icon.” But you’d never find this message again by searching the Internet for josh or epic spelt the normal way.
By the way, a quick way to perceive the lookalike Unicode above is to paste the words with an appended .com into the address bar of your browser. If you paste jоsh.com or еріс.com, you’ll see punycode.
There was a Reddit account that for a few months posted all their comments with alphas instead of the letter a. There was some speculation that it was too make their comments ungoogleable, but it turned out to just be for fun.
There's a problem with using email addresses as IDs which has nothing to do with Unicode: Is frobozz@example.com the same as frobozz@example.com? Don't bother comparing bytes: What's changed is the time, and who owns the frobozz@example.com email account. Names need to have some kind of stability over time to be useful, and need to have some mechanism whereby they can be changed gracefully if they need to be. Email addresses have neither of those properties.
Mailing addresses have the same problems to some extent, but at least most mail systems should have some concept of forwarding addresses by now. Email is never going to.
I don’t see this as a problem so long as you don’t treat the email as the permanent source of truth of the account identity and instead have it be the email you happen to have associated with the account at that time.
We have abstracted the notion of passwords as “a collection of authenticators defined by the user”, no reason your account can’t have a collection of identifiers as well.
I agree with you that "identity" has many attributes of which an email address is only one.
The problem is that in practice, control of the email address on record is sufficient to take over many modern accounts. Bank accounts likely shouldn't fall into this category, but most web sites don't have bank account level of security.
Hotmail created a hornet's nest of problems when they started recycling email addresses after 6 (or 18?) months of inactivity. It allows a quick "password reset", then the account is now owned by whomever controls the email address. Effectively, the identity is hijacked because control of the email address was most of the authentication mechanism. Queue the spam messages and fraud/phishing.
Also developing/managing a customer service tool which allows them to decipher these "takeover" events and ensure the person contacting them used to own the account is difficult and sometimes not possible.
Some banks don’t have a “username” to log in but insist on “account number”. Which works but is not something I remember easily and forced me to use a PWD manager, which I guess is a good thing.
There should only be to features exposed from the clipboard API.
1. Push. Add a new item to the clipboard.
2. For apps, with an opt in permission. Delete items added by the app. Good for password managers.
Also, it's basically impossible to use a password manager without using the clipboard. At the one I use will automatically remove the items it sets after a timeout I can configure.
In light of numerous browser exploited I've switched to an external third party password manager. On android, even givin proper permissions, the app fails to recognize many password inputs in apps, sites, etc. Probably the result of bad design on the site or app operators part. On desktop the pwd app just works.
> This even allows them to have fully-Unicode usernames; username phishing is less of a problem when users expect duplicate usernames, and none of your systems depend on username uniqueness.
It's surprising but providing an extra degree of freedom makes the system more robust. Username phishing is a real problem on Twitter because people expect unique names associated with each person they interact with but if usernames can not be assumed to be unique then using the name as a heuristic for identity is no longer a viable shortcut so people have to develop other ways of making sure they're talking to who they think they're talking to.
On a related note, keybase (keybase.io) proofs never made sense to me until I started thinking about how I would prove to people that I am indeed who I say I am. Keybase provides a cryptographic basis for trust, which is much better than what most social media systems currently support with their verification mechanisms. I personally trust cryptographic signatures over whatever verification mechanism Twitter is using to provide blue check marks to verified accounts.
> The only solution is to develop systems that don’t have usernames.
I disagree that this is the only solution. The OP comes very close to discovering an alternative one: don't allow users the power to select their own arbitrary username.
When a user makes an account on your site (and if your site actually needs publicly-displayed usernames in the first place), give them the option of, say, ten usernames generated by the site itself; these don't need to be numeric codes like WeChat does, they can be pronounceable phrases in the same manner that Gfycat generates URLs. Everyone will end up with names like "questionable wet aplomado falcon", "each unlawful harlequin bug", "icy inferior iceland gull", which honestly isn't any worse than the average name I encounter on Reddit or elsewhere.
The biggest downside(?) of this approach is that it makes it harder for someone to build their personal brand, but the older I get the more I think it's a bad idea to use a consistent nickname across different websites.
Why should Vietnamese or Icelandic users have to use English user names? It is really necessary to enforce English hegemony at such a fundamental layer of the software?
For comparison, imagine if your randomly generated user name was one of the following 5 (these are all combination of three words):
It's easy to hijack a consistent username too. If you're "foobar123" on a dozen sites I could register "foobar123" elsewhere and do damage to your "personal brand" pretty easily.
I tried this approach for a service awhile back, and the biggest hurdle was educating the users. Even determining what to call it was a huge challenge, as it’s clearly not a ‘username’.
In what way would the user need to be educated? Social products like IRC, Twitter, and Reddit have accustomed users to seeing opaque, often-nonsensical strings next to every action taken by every user, and the only difference here is that a given user hasn't had the opportunity to select their own opaque and nonsensical string to associate with their actions. They wouldn't even need to remember this string to log in, because sites use email or third-party login services for that (and even if they did need to know their own username to log in, their browser would remember it for them).
New wireframes don't need to be made, because this paradigm already exists in a roundabout way. For many websites that I have signed up for, any attempt to register an already-taken username will present the user with multiple suggested alternative usernames. It's been decades since I signed up for Gmail, but I'm pretty sure that on the sign-up screen you would enter your name, "John Smith", and then your desired email, "johnsmith@gmail", and then when that failed you would be given a list like "john_smith@gmail", "smithj@gmail", "johnsmith2@gmail", etc.
This is the same UI flow as the above, except that it's not based on anything that the user has already entered and it doesn't provide any way for the user to override the suggestions, which actually makes it simpler than the existing flow.
I like the petname approach that GNS[0] takes - there are stable identifiers (they're public keys) but users are meant to refer to identifiers using local names (or names that their contacts have set).
Generally, using cryptography or associated cryptographic functions is the way to go when trying to make robust systems. Joe Armstrong has a great talk where he outlines how to create a content addressable store for storing and working with knowledge/data. He suggests using SHA256 content hashing because giving items of data unique names is a hard problem so we might as well name pieces of data by their content hashes and then have a human readable pointer.
Unicode usernames in Discord are my bane. I can’t search for them. I can’t type them in manually. I can’t even copy their official name because the app interface doesn’t allow selecting them. If the right click context menu doesn’t allow the operation I need, I’m just SOL. A complete clustertruck.
The author's solution is to shift the problem of uniqueness of usernames to email, as if email is less likely to change than a site-specific username.
The opposite is actually true - there are many reasons to change your email, while changing your username on the vast majority of websites is simply unnecessary (e.g. anything without a social component, such as banks, shops, Healthcare providers etc.).
Not to mention, if you don't have a system for ensuring unique usernames, you also shift the burden of ensuring identity to your other users, who now have to understand how to distinguish different users with the same name.
to me it seems the suggestion is to allow aliases (nicknames, images, utf, qr-code, text) and stick with numerical ids (or whatever you use as the true primary key, which can be email or phone number i guess, but hope not).
Discord and Blizzard both use a unique numerical ID as the true source of identity (your name displays like "Mr. Bob#1234", but only the "1234" part is actually important), while using email for logging in. The email and the display name can both be changed at any time.
The 1234 part changes too and if you pay for the premium service, called Discord Nitro, you can set it it to whatever you want instead of a random value.
Its only purpose is to prevent name collisions.
In many fashions, the account is identified by a "snowflake", a 64-bit ID space that every user, every guild/"server", every channel, and every message has.
Its described here and is the only permanent identity on the account, since everything else can be changed. The identity used to @ is transient and can change at any time, but the client, the API, and the myraid of bots written for Discord know the real identity is the snowflake ID.
I'm pretty sure the ID that Discord and Blizzard use as the "true" source of identity (as in, the key they store in the database to keep track of who's on your buddy list) is different from the "#1234" number used to disambiguate people with the same username.
In particular, that number is only four base-10 digits long, and I'm pretty sure there are more than 10,000 people in the world who have ever played Hearthstone.
And ICQ! While AIM was letting people choose usernames, ICQ looked deep into your soul and assigned you an ID based on the order in which you joined :)
Purely as an implementation note, the Slack rich text editing widget is quite poor, and the Discord rich text editing widget is lousy. Both have serious bugs (Discord’s seems to be almost nothing but bugs) where their widget just doesn’t behave like a normal <input type=text> or even contenteditable (which behaves subtly differently), in decidedly off-putting ways.
On @-mention autocompleters in general (and :emoji-code: completers too, and GitHub/GitLab issue/PR #-reference completers), I honestly can’t think of one that I’m completely happy with. Every last one I’ve experienced harms the editing experience with surprising and inconsistent behaviour.
It’s all surprisingly hard to get right, and very few people that implement seem to even try to actually get it right.
Perhaps I should perform a more detailed study, enumerating the problems clearly, and try to create one that’s as close to flawless as is possible. (I’m sceptical that flawless is actually possible with the tools given web tech, especially in Blink and I think WebKit which don’t properly support the difference between before-end and after-end in selection in contenteditable, which matters more than you might think.)
The author lists a bunch of gripes with alphanumeric usernames but I'm fact many of these shortcomings are not worth a switch away towards non-unique, freeform names (John Smith), or towards random ID allocation (whether purely numeric or word-like).
In spite of what I'd personally have bet on a decade ago, I don't actually know many international users who complain about alphanumeric handles. People can/should still have Unicode-ish display names on top of handles, change those, and be searched by those. Twitter does this well for example.
But a human-readable, ASCII-friendly, user-chosen unique handle is the best thing I've seen so far for disambiguation on a social network.
GDPR adds an interesting wrinkle in all this. GDPR requires both the right of removal (removing @-mentions) and the right of rectification (updating them.) So if I change my name from notJim to notJohn, GDPR requires* services to update previous @-mentions from notJim to notJohn, and similarly requires services to remove old mentions of notJim if I request removal. Using an identifier behind the scenes greatly simplifies this, because instead of dealing with text, you fetch the appropriate display name at render time.
* IANAL, etc, and I'm sure requirements and interpretations of GDPR vary, but I do know that my company invested quite a lot into systems to fix this @-mentioning issue, so at least some people thinks it requires this and are willing to spend probably millions of dollars of engineering time to comply with said requirement. Personally, I support this provision.
Here's a thought I had when Twitter was still very new:
1. Sites should forbid dots in "normal" usernames.
2. Usernames with dots can only be registered by demonstrating ownership of the corresponding DNS domain.
Now you can have your favorite "brand" across all sites, nobody else can register it before you, etc.
This is obviously not very non-techie friendly at this time...
{kind=link}
I'm a screen reader user and don't encounter those often. There's even some fun in those alt texts, i.e.
"screenshot of unicode character inspector revealing "epic" to actually be "еріс". of course you, a screen reader user, aren't fooled."
Btw, most people would just label that "screenshot", which is extremely infuriating.