This is a great question, I also want a way to search the internet but exclude all major media domains as well as any company over a certain size. So I just want to search through old blogs, SO, non-corporate social media, weird forums, etc.
There are so many cool things I remember reading on the web like 10-20 years ago that still exist that are so buried now on Google they might as well not exist. Nowadays searching any topic seems to always lead you to CNN and Microsoft and Facebook and other huge corporations. Search results are just becoming more sanitized and beige and meaningless every day.
For years, my trick for finding interesting content was to go to, say, the 7th page of Google results, and start there. This doesn't work anymore -- it's SEO-optimised listicle blog posts all the way down.
My trick now is to use Twitter to discover interesting people, and follow them there. Granted, it's not a search engine, but it's at least given me the ability to discover weird things again.
One of the things I enjoy doing on Twitter is posting up something I'm working on, and then clicking through to all the profiles of the people who like, comment, or retweet my work. I stumble across an incredibly diverse range of people by doing this, many with conflicting opinions to my own, and many who belong to strange subcultures that I don't understand, but who were all drawn to my work for one reason or another.
I think there's definitely a danger of crafting a bubble for yourself if you choose to use it that way, but as a tool for discovering people making cool stuff who otherwise wouldn't cut through the noise on something like Google search, I haven't found anything better.
Many times I have thought about what could happen if Twitter asked you to recommend up to 3-5 people you value, and write a tweet-sized (or shorted) recommendation.
Over time you would get a 'pagerank for people' and could do awesome stuff with that, like 'You don't know XYZ, but 3 people you trust trust her, and this is what they tell about her:' ...
I was about to ask about dmoz.org. But apparently it's dead. We could probably do something with bookmark sharing à la Delicious. Good dead things for a better future.
Heh, I was trying to do research on coronaviruses (of which COVID-19 is one of many coronaviruses), but Google sanitized the result and only showed me "official" COVID-19 resources and buried the broader coronavirus resources.
Giving you the benefit of the doubt, and assuming this isn't just pedantry, especially since you're getting downvotes (because I assume everyone thinks this is just pedantic correction) I looked it up.
In the context of "trying to do research on coronaviruses" your comment appears to be not only correct but an important distinction, rather than the pedantry it appears to be.
From Wikipedia: "...more lethal varieties [of coronaviruses] can cause SARS, MERS, and COVID-19."
And...
"Severe acute respiratory syndrome coronavirus 2 [SARS-CoV-2] is the strain of coronavirus..."
Which can be further abbreviated as C19. I have seen this in personal chats and wonder how long it will be before it gets into newspaper headlines where space is at a premium in print editions.
I know you are relaying the public information accurately, but I wish authorities pushed better names. Like calling the virus "the virus that we know has a corona and causes these symptoms" and the disease "the disease caused by this virus that has a corona and that causes these symptoms" is circular. Also, it is not true that it is entirely a respiratory syndrome. There are serious non-respiratory symptoms, extent of which we are to discover. Finally, if it is a syndrome causing virus, by definition we wouldn't have the crisp boundaries of a disease around it, which indeed we don't.
If these were names for services and classes that came in a code review, how many would really approve?
[retracted] and I hope this is just a misunderstanding. As the director of the World Health Organization (WHO) said, 2019-nCoV is a novel (new) coronavirus.[0] The CDC defines coronavirus as a virus that was not previously known — check the FAQ, “what is a novel coronavirus?”[0.5]
They changed the name of this coronavirus to reflect the disease more accurately to COVID-19.[1]
The CDC has a list of other coronavirus’ that have existed.[2]
Edit: Since there seems to be a misunderstanding from everybody’s part on this as it’s referred to as both and often interchangeably in a mainstream setting, take a look at John Hopkins guide: https://www.hopkinsguides.com/hopkins/view/Johns_Hopkins_ABX...
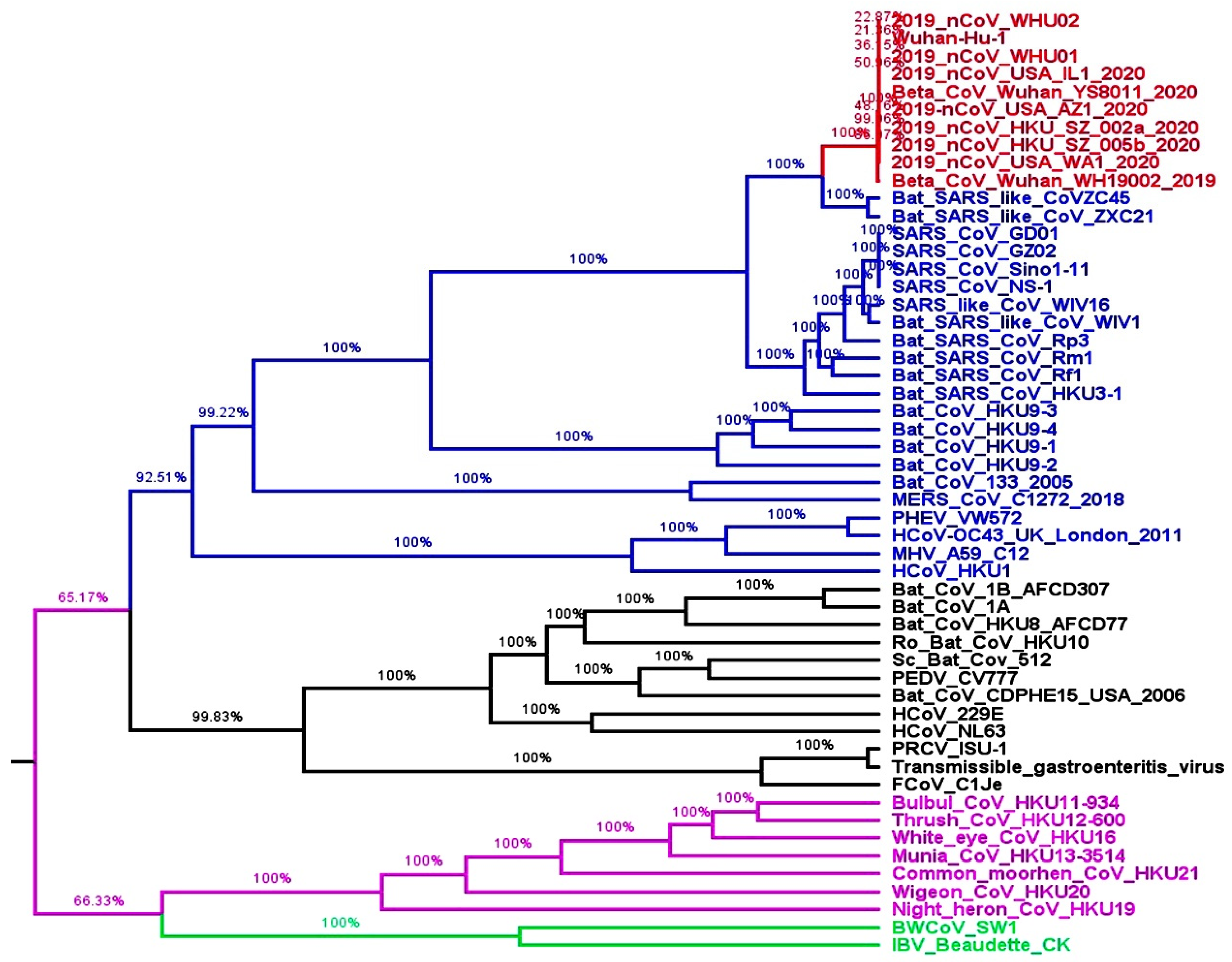
Excuse the incivility, but no. SARS-CoV-2 is not a strain or type of SARS-CoV. The viruses share ancestors, but SARS-CoV-2 did not come directly from SARS-CoV. SARS-CoV and SARS-CoV-2 are in the category of beta coronaviruses[0].
"The whole genome-based phylogenetic analysis presented that two Bat SARS-like CoVs (ZXC21 and ZC45) were the closest relatives of SARS-CoV-2."[1]
While we're on the topic of linguistic pedantary, strain isn't exclusive to direct mutations from a parent genome. Strains, like much of biological taxonomy, are a human abstraction to make communication of the idea of -- in this case -- "a virus sharing similar properties to coronaviruses that cause severe acute respiratory syndrome" -- albeit this is a very simplified definition for the sake of brevity.
SARS is caused by SARS-CoV-1 and COVID-19 is caused by SARS-CoV-2.
Rather, if we would like to be absolutely correct about these classifications, we would say SARS-CoV-1 and SARS-CoV-2 are both strains of SARSr-CoV (Severe accute respiratory syndrome related coronavirus), which in itself is a species, an abstract concept used to group related organisms into a convenient umbrella term.
There is no "eukaryote" organism the same way there is no "SARSr-CoV" organism. The added "r" was a recent addition when COVID-19 was discovered.
I will cede that I didn't specify this last point, and you were correct to point it out.
GP was pointing out that this was incorrect, and you just made that point by stating it yourself.
Assuming you are intending to engage in the conversation and not be a pedant, I might let you know that your replies are coming across quite coarsely. More specifically, as to prefaces on earlier comments, there is no need to excuse incivility, because there is no need for incivility here.
I found the exchange to be more than civil, with pleasantries not being taken in the literal sense.
At least this did not fall into the category of "Cold regurgitation of data" (quite popular it seems) and had a level of warmth that was an indication of passion, more than anger (from all parties).
If they added a temperature social cue to HN comments..... That would be funny.
"Is there a search engine which excludes the world's biggest websites?"
There was "rebranded" web search that someone created a number of years ago and posted on HN that aimed to exclude the top websites from results. I cannot remember the name he gave to the project.
One way to exclude the world's biggest websites when using Google is to restrict the search to TLDs other than .com, .net and .org. The root zone is full of silly new TLDs that no one uses for large websites. There are hundreds to choose from.
It is kind of funny that we talk about SARS-COV-2 as if it is the only coronavirus. Coronavirus, singular. If I’m not mistaken the common cold is in the corona virus family.
I have a theory that web crawling alone is not the best way forward to find the most relevant results because of the volume of content continually being created, much of which is niche and sometimes dynamic.
Instead I believe linking together vertical search sources that have targeted information based on search intent will provide better results.
I created Runnaroo [0] for that purpose. If you search a programing question, it will pull traditional organic results from Google, but it will also directly query Stack Overflow for a deeper search.
This is somewhat ironic because 20 years ago, hobbyists would frequently put their obscure personal pages on Geocities and other large corporation's web space.
Memory can be foggy but the most useful were hosted on university pages or random folders off a random domains or you get a subdomain. I picked the username 'search' which gave me search.batcave.net which worked great until one day they just took over the subdomain for a site wide search. They were confused when I complained.
Sure people hosted on geocities and tripod and they were the biggest and easiest to remember. But quality of a geocities page compared to a mit student page was much lower.
20 years ago, it was extremely common for your ISP to give you 5MB or whatever of space to use. users.ispname.com/~yourname or whatever. It was great, tbh, since anyone with cuteftp and notepad could publish to the world.
Hey! I actually liked this idea and I'm considering starting a learning project on it. I've seen a lot of interest and ideas in the comments, and decided to create a very short Google form to start gathering all the interested people so we can organise something interesing. Is anybody in? :)
If there was a way to simply exclude from searches: shopping, news, images, videos, and “listicles”, I think that would get us most of the way.
Especially shopping. The endless stores are the worst part of search results. If I search for anything that remotely looks like a product, the results are just choked with store after store trying to sell me the thing. Awful.
I tried it with "waders" which are either the things that you to put on your feet to go fishing or a category of birds (shorebirds or herons). The results after going for all the options were still exclusively stores wanting to sell me the former.
Garbage in, garbage out. I guess. Still I like the idea of something to side-step the SEO perhaps with more effort they can make it work but relying on Google or any major search engine for the base results is the wrong way to go.
I tested your search term and had similar experience. I have, however, had positive experience with other categories, such as philosophy. Searching Wittgenstein with the top million sites removed, I found some gems: a play, a disney character that was a supercomputer named after Wittgenstein on a direct to video movie which I learned was later partly inspiration for Wall-E, Wittgenstein-oriented societies, awards, and general philosophy references I had never heard of.
I've found that you get far better results for many queries on YouTube now since it's tougher to mass spam YouTube with low quality content (compared to churning out a $5 article).
There is Million Short which allows you to search without the top 100, 1k, 10k, 100k, or 1m sites. Personally what I'd like to see is a search engine that only indexes webpages without ads since that should eliminate lots of the SEOd garbage. It would also be nice to use the text to code ratio to derank JS heavy sites.
And they also, for the longest time, strongly turned me off paying for any news sites. The more they use scummy ads that turn people off, the more they need ad revenue.
I do a random city + documentary as the search term, it's taken me all over the world and seen some very strange things.
One of my favourites was Aarhus, which had a Danish language rapper proclaiming he was putting Aarhus on the global map (I have never heard of the city of Aarhus). https://youtu.be/WSZxuzgImLo They dis Copenhagen a lot too, lol. You get a more intimate YouTube experience with the low view videos
But I also seen amazing religious rituals. An excellent documentary on Karachi.
Because it's observable hq you can fork it and figure out your own algorithm for biasing the random.
Specifically this quote: "The way to win here is to build the search engine all the hackers use. A search engine whose users consisted of the top 10,000 hackers and no one else would be in a very powerful position despite its small size, just as Google was when it was that search engine."
There has been a lot of grumblings about the state of search these days. Maybe the time is nigh for a new search engine?
I feel that we should go down the adblock hosts list approach, where people download website lists from individuals they trust who have curated or scraped links of websites complete with keywords, and its up to the user to refresh their lists and then perform a search on their website.txt file
It will be limited, but still quite powerful, similar to the way that we can pick and choose different host file sources from the web.
Does anyone else remember StumbleUpon? It's not exactly the same as a search engine, but that worked really well for finding interesting content back in the day.
I've wondered if this can be built with a limited budget, in terms of cloud costs. At least it feels like you'd need a lot of hosts to satisfactorily index the web, and store the results so that you can return results instantaneously.
With limited budget and the right results, I think people would pay with “non-instant” results. Even 5-10 seconds might be perfectly fine, and that’s “easy” on a limited budget.
DEVONagent is a highly configurable search utility which can be used to combine and de-duplicate results from multiple search engines at once, exclude sites or keywords from a blacklist, follow deep links within search pages, and perform some filtering logic on the text of results.
Before I knew about DEVONagent I would often just search multiple engines and sources trying to find something particular (e.g. a particular PDF) or unique results.
Thank you for the link. This looks really cool. I used DEVONthink years ago. It seemed like a great piece of software but I didn't have a great use case for it. Looking forward to checking out DEVONagent.
All it does is add -site:pinterest.com to the search bar for image results (can be configured to also do it for Web results), but it gets the job done.
The "About" information is, counter-intuitively, under "Settings":
> In the early days of the web, pages were made primarily by hobbyists, academics, and computer savvy people about subjects they were interested in. Later on, the web became saturated with commercial pages that overcrowded everything else. All the personalized websites are hidden among a pile of commercial pages. [...] The Wiby search engine is building a web of pages as it was in the earlier days of the internet.
That makes me think: Is there a search engine which removes pages with any ads or affiliate links? That might be the easiest way to remove the commercial pages.
I was just thinking pages with external dependencies, in the spirit of the old web, but your idea sounds a lot more reasonable. Not sure if that exists, I'd be interested!
It is a carefully curated directory, which is problematic.
For example, I submitted Pizza Hut's archived original web page [1], but it wasn't added.
Even for a search engine exposing niches, updating a directory manually will likely be too slow, unless the directory is maintaining a single nich (e.g., unladen airspeed of every species of swallow), but then we end up with some insane number of search engines and how to select which one?
Especially if you’re focussing on evergreen information, there’s no reason why people can’t have their own personalized crawler and index— I’ve occasionally thought about rolling my own with a browser extension that lets me add seeds at the click of a button.
I've been working on something like this for my own use - I'm not a fan of browser-based history. My home-rolled solution is starting to be good enough where I can use it to easily find exactly what I'm looking for, assuming I've previously read it, by both searching the title and URL, as well as the content on that page (my major gripe with "History" in Chrome and Firefox is that it doesn't search the page content, and if it did, syncing it would have major privacy concerns).
The problem I'm running into is that I still have to use major search engines to find new content, way more than I'd like. I hope to make my local service available open source once I have 'federated' history search working, so that we can have a primitive search engine and share with people we trust. Also need to work out some security issues - it's scary having all the content you read and see on your home network, protected only by your hackily-patched-together security.
EDIT: Actually I'd like to elaborate a bit more in case anybody actually reads this and has any ideas. On the desktop side, it's pretty easy. Initially started out MITMing my own traffic with a self-signed cert added as a root cert to all my machines. This only works on my home network, so I did a VPN thing. This was way to clunky and the security concerns are innumerable. I ended up biting the bullet and writing a chrome extension which works wonderfully, except for some slight performance issues.
However, I wish to also archive my phone content - I read just as much on my phone as my computer. I can do it on Android with the MITM process, but the same issues as above still apply, and it doesn't work with iOS (at least I can't find a way).
I'm thinking of taking an open source project, like Firefox/Fennec and building it in to the app itself. In that case it may make sense to forgo the browser extension and just roll my own forked browser on every platform, even iOS. I don't know much about iOS dev though.
I tried this yesterday. It seems biased towards the interests of the curators, and, like Google in regards to "some ideal average consumer", is therefore useless if you fall outside a certain level of similarity to the target demo.
For example, I enjoy weightlifting and strength sports. I did a search for "muscle", and every result but one was using the word "muscle" as a figurative metaphor. Barely anything about actual muscles. Searching "funk" was just as bad. One page about Motown and a LOT of midis.
What if Google Advanced Search produced a visual network map which showed you the salient clusters of terms related to your search? You’d then be able to click on a cluster and the search results would change to adjust to what you’re really searching for.
Ex: The network map for “weightlifting” would include many clusters, but 2 big ones would be the hypertrophic cluster (surrounded by a bunch of related terms) and toning cluster (calisthenics would be under this cluster for example). Click on either and the results will change accordingly.
This would actually work even better for subjects you don’t know much about, because Google will teach you about the salient clusters in that field. The clusters could be enhanced with popular images associated with each term. Popular clusters would display as larger than others.
Here is an idea that I've always wanted to do, but will never have time for: A curated search engine.
Basically the idea is to have people band together and "recommend" links. You then do your normal spidering of the websites to create a search engine (or even just call through to a number of existing search engines). However, the ranking of the results is based on the weighting of the recommendations.
It's essentially a white list based on your own personal bubble. Of course this won't work in general because you will always get SEO creeps spamming recommendations. However, it gives you tools for working around those creeps. The average person probably won't be able to manage it, but power users probably will.
By not trying to solve the problem for everybody, it makes it easier to solve to problem for some people. Or at least that's my thesis :-) I might be wrong.
You can boot up your own custom search engine in a few minutes with YaCy (Ya See!) an open-source, P2P, Dockerized crawler and search engine built on top of Solr.
If you're generous; you can make your index available to other P2P instances.
I wanted to run an API search the other week and was blown away with how quickly I could prop-up my own custom search portal (I didn't want to pay for API access to other search engines, and YaCy comes with a JSON and Solr endpoints).
I ran it locally to test my crawl filters, then pushed a private instance out to Digital Ocean to turn up the heat with the crawling. The only issue I had was the crawler would hit the max memory threshold on long crawls and the container would restart, but that was fixed by scaling up the box.
I have my own yacy search engines running internally (non-peered) for similar reasons. One crawls some key code documentation sites that I need for work, and another crawls a whole bunch of music blogs.
While I typically still use RSS for reading music blogs, I find having the search engine is a great way to go back and find something or discover something new! Every time I find a new blog, I just add it as an index to yacy to crawl.
I think it'd be great to see people spinning up larger instances that are highly specialized. For example, maybe a search engine that is dedicated solely to sci-fi and only crawls high quality boards, personal sites and blogs, and skips all the spammy, seo-optimized sites.
I built a search engine for this and other, similar purposes. With Crawl Crawler you start out by searching the meta data of a Common Crawl ("CC") crawl. Then you define a sub section of that data collection by designing a query which search result includes your favorite sites. Then you enrich that sub section by linking those meta data documents (that come from CC's WAT repo) to full text extracts or HTML from CC's WET repo or the WWW. Then you set it to recurringly refresh that section. Voila! You have created a search index that includes your preferred sites. https://crawlcrawler.com
You should try million short. As the name suggests, it takes our the first 100 / 1k / or a million results so you're left with those that aren't all that popular. That seems to be what you're looking for.
https://millionshort.com/
My hobby project is https://random.surf (works better on desktop than mobile).
I share that same desire to visit the web less travelled. I want to discover interesting sites that deserve to be bookmarked because they will never show up in a search engine.
There used to be java applet embedded in altavista.com's website that could be run against search results. It would do semantic processing on the results and present a list of generated terms, each with a checkbox. Checking a box would pull any returns which contained the topic from the remaining search results.
This was fire. If a topic were being discussed on the web, you could find it with this tool. Unfortunately, it did not fit the vision of the parasitic overlords who bred us to produce and consume for their benefit.
I would pay real subscription money for a search engine that focused on knowledge-oriented results rather than retail and commercial results.
When I type “shoes”, it would give me: links for the functional and creative history of footwear, the taxonomy of shoes, methods of construction, current and historical footwear industry data, synonyms and antonyms, related terms and professions, the dictionary definition, and similar links related to secondary meanings (such as any protective covering at the base of an object, horseshoes etc). I’d also hope for a comedy link to a biography of Cordwainer Smith.
What I actually get, which I don’t want at all: pages and pages of shoe shopping.
The various means to exclude “top X sites” are the roughest possible heuristic in that direction, and throw out the baby with the bathwater (for example, a long-established manufacturer may well have an informational online exhibit)
Google has essentially failed me in its primary mission. Bing at least has the grace to admit they are here to “connect you to brands”. And sadly, right now, every other option is an also-ran.
In practice I use DDG, directed by !bangs towards known encyclopaedic or domain-specific sources. I am certain that I’m missing out.
What you describe sounds like a mix of personal knowledge base that seats on the top of existing search engines, public and maybe even private databases. Major difference is here:
* when you make a query to this knowledge base, it has a history of your prev searches / preferences (not google)
* it can propose variants of suggestions on what is your intent in this particular query - and make much more detailed queries (auto include/exclude keywords websites etc) to multiple sources (not only google, maybe anonymously)
* it can parse results from these sources and re-arrange them (use own rank system) according to the your preferences. In this system, you can explicitly say - I hate that, and I like that, and this will affect the behavior. Yes this is 'information bubble' but it is controlled by you and not by google!
* finally, this system may work in background and handle 'research' search queries. What I mean here: currently, Google is about instant search - it gives you results in milliseconds, and that's all. It cannot spend much computations for more precise, more intellectual check of content in links from the search results - it cannot do reasoning - and you have to do that by yourself: open links from 1-st page, and close most of them immediately b/c they are not relevant for you, go to 2-nd page and so on. It would be cool if most of this could be automated - with modern natural language processing approaches and old-school prolog-like reasoning this is real and not a fantastic from sci-fi.
My vision that this kind of search assistant cannot be SaaS / closed source. It is about the freedom - and thus this should be open source / self-hosted app that can be deployed on PC or on cloud VM - but hosting should be controlled by end-users, not companies.
I don't know if something like this ever exist. If not, maybe its time to create it.
I know you’re only half joking. In practice many, perhaps most of my DDG queries do end in !w - but there’s a wealth of information that is relevant, interesting, and useful, but wouldn’t be considered encyclopaedic, or that is merely summarised in Wikipedia; in addition, their references are included as supporting citations, very far from a comprehensive index of currently accessible information.
I've long wanted to build a search engine of only personal blogs. I am less familiar with the field of information retrieval so I haven't gotten started yet, but it's always been a dream of mine and if anyone is interested please contact me at threemillionthflower [at] the world's largest email provider.
Discovering unknown parts and blogs on the internet is one of the enduring goals of a newsletter that I run [1], which provides a single link to an interesting article every day, usually by lesser-known authors and blogs across the internet.
I have been finding recently that Google has been breaking their existing "sort", "time" filters. Try searching for something with site:reddit.com prefix for example and set the time filter to be lets say "Last year". Google still shows you results from 4-5 years ago.
I also discovered that recently. It's gone the way of the verbatim constraint.
Control is being forfeited to steer users back to more profitable content in order to capitalize on a captive market.
I wonder if being open about it would be so bad for business, instead of the attempt to manipulate users into enjoying the ratcheting-up of their impotence.
Now, Youtube truncates search results and loads the recommendation stream instead, long before hits are exhausted.
At least it's been a while since Silicon Valley was keeping the mythical personalized advertising spiel in active circulation.
I personally use Google Chrome with the duckduckgo search engine. Duckduckgo is not perfect, very in depth searches (such as gameboy advance memory layout only return junk, while google knows you are searching for a nich) but on your average search it is as good as google, somethimes better because it is more factual and will promote less webstores. When it does not give me what im looking for I can add !g anywhere in the question and the same search is done using google.
Then I use Violentmonkey an open source js/css injector to inject this user script: https://greasyfork.org/nl/scripts/1682-google-hit-hider-by-d... This will block specific domains for you in google, yahoo, duckduckgo etc. I use this to block domains like Quora, sourceforge, cnet and softonic.
The nice thing about this script is that you can permaban domain you know are junk and they will completely be removed or you can ban a domain like commercial websites. When you ban something it is not removed from google or duckduckgo but it only shows the title in light gray, Im currently experimenting with this on some mayor webstores so I can not really say if this may help you but It can be a good start.
(edit) I saw some people say why this was not possible before. Google allowed you to block domains and website a few years ago, but they removed this feature. Duckduckgo never allowed you to do that because that would mean that you will have a cookie that remembers your preferences and that is against there principles.
I knew about !bangs, but I didn't know you could put them anywhere in the query (e.g. "hello !g world" searches Google for "hello world"). This is going to save me a lot of time on mobile. Thanks!
When researching a topic I have had great success searching HN and reading through the comments. If I want to find alternative software tools for a tool I am using the comments on HN are best. Searching through subreddits also yields better results than Google.
It feels like there could be a (partial) meta solution here:
A search engine that returns results whose pages weigh in under a certain size.
From the comments it seems most of the "cruft" filling up Google results are newer web apps, generally JS-heavy and advertising-heavy, etc.
If you had a filter for pages with (e.g.) < ABC kb of JS, < XYZ external links (excluding img tags), I feel like there'd be a good chance that the "old" web and the "unknown" web would bubble to the top.
There are plenty of false positives (particularly for "small" forums build with modern JS apps, etc), but it could be one of many filtering tools to achieve better search results.
Google used to let you blacklist websites many moons ago, that would go a long way already.
Now there are a few extensions that do that, but obviously they only hide the results from each page, so sometimes you will see pages with 2 results, if any at all.
It would be nice if there were a way to make the exclusion list de the default for all your queries. For instance, I never want to see results from WikiHow again. Ever. Or the New York Times or any of the other paywalled sites...
unpinterested is an extension which simply adds -site:pinterest to image searches. I don't think it'd be hard to do something similar with a custom list.
There is a similar problem where Youtube's recommendations and auto-play are mostly big name brands, to the exclusion of individual reporters, commentators, and other content producers. Since recently, a "De-Mainstream Youtube" plugin[1] is available for Firefox and Chrome, fixing that to some extent.
I've expressed this wish on HN a few times in the past as well. One downside to it that I can think of (off the top of my head) is that there may be a lot of small, personal websites that are hosted on a free blogging platform which injects ads into every page. These websites may be very valuable (and not SEO garbage link farms) but would get blocked nevertheless.
I don't know about the current query size limit but I think it's pretty likely to get hit quickly as you correctly pointed out. But, it's useful to use the wildcard "-site" ex: "-site:bigwebsite.com" for excluding just the site, and not the very word being mentioned.
What are folks’ non-commoditized heuristics for finding new things online?
I was intrigued by how dorkweed’s approach has changed over time, as described in a reply to a sibling comment.
As general search results get watered down and rotten tomato inflation maybe trends towards reflecting company interests rather than my interest-level, maybe it’s worth re-evaluating the vetting avenues we take as users.
Here’s mine: for games and shows I’ve recently found myself using quantity of fan-videos on YouTube as a proxy for quality. So far it’s been a decent means to find cult followings for something I otherwise wouldn’t necessarily hear about.
Obviously this approach has its flaws - and is subject to financial perversions to an extent - but I figure if enough people genuinely want to pay tribute to a work, it might be worth checking out.
Personal trick: I follow reaction video blogs, and if they are reacting to something then it is usually worth watching. But reaction blogs are only for short videos and other short form content.
I find that the YouTube sidebar is useful for me to find interesting music. I have eclectic tastes, and Google seems to have figured that out. I don't mind.
I suspect that it would be possible to create a custom API query to Google that would have a "blacklist."
1. Looking for niche domain or institutional/social knowledge produced by experts or insiders for an informed audience that isn't necessarily available in a scientific journal.
Especially with respect to the social sciences and literary analysis, there's a wealth of intelligent commentators that don't surface well on Google without very specific search terms, and the willful subtraction of domains like quora, medium, and tumblr.
They're usually contained on poorly maintained WordPress sites that the author has long-since forgotten about, or as invalid, handcoded html docs hidden in the personal subdomains of university professors and students.
2. Finding online communities that aren't a part of Reddit or a similarly prominent platform
in the same vein, it would be awesome to search for a product to buy with the results being ecomm websites owned by people in my area. A way to "shop local" online.
Currently for three product tiers (furniture, home decor, and fashion/clothing) in 14 major US markets, where stores within ~100 miles or a ~2 hour drive are considered as part of the market.
Aside from the constraints we apply to market/geography and product type? If that's what you mean, then technically it's a matter of whether the store's ecom platform is compatible with our indexer, which supports ~20 different platforms (and hundreds of variations). Otherwise, we do some light curating for product quality to include, but not limited to, the accuracy of meta data (titling, description) and image quality.
I'm curious how English speakers (especially not in US?) finding national shopping websites because I live in Japan so never find foreign website written in Japanese
Hey! I actually liked this idea and I'm considering starting a learning project on it. I've seen a lot of interest and ideas in the comments, and decided to create a very short Google form to start gathering all the interested people so we can organise something interesing. Is anybody in? :)
I don't know that I'd want a search engine to specifically exclude or limit the results of specific sites of their choosing (even if top 500 as the example is fairly unbiased), but I think I'd really like the ability to say "move these specific domains a few pages back. Don't eliminate them outright, but I have felt dumber having read them previously."
I have used copernik in the past this was a collection of search engines, listing more than 140 search engines. It combined the search results and sorted them by the key word % matched. It also had a lot of tools inbuilt for validating he links, coping the selection/ sorting and sharing the results.
Simply amazing results.
Google search is so sad these days, all results are media conglomerates, it's completely counter to the core reason why the internet existed. I really hope by catering to these mega corps that they are completely undermining their brand and someone else comes along and pulls the rug out from underneath them.
If anyone noticed during the first couple days of covid, google search was free from large media results, the algorithm reverted back to how it was years ago and it was such a breath of fresh air. Of course they fixed the algo immediately, it went back to only showing curated media results..there was an anon google employee who posted why this occurred.
I think we are gonna see aversion from going public. Companies like Stripe and SpaceX are gonna stay private for a long time.
When SEC laws, shareholder interest, quarterly performance and stock volatility comes into play, corporations become this mindless soulless monster that will devour everything in its way and fuck consumers in every which way.
Democratization of funds from central authority to public creates disincentives and the shareholders don’t give a shit about many auxiliary things such as environmental concerns. Bottom line always matters.
It’s not just google but any public corporation. Can you imagine SpaceX being able to operate with the same passion with shareholder interests?
It is, potentially, the compensation plans. If you go to the proxy document and look at how comp plans are set, they usually hire a consultant, and "best practices" drivers are cash + big bonus based on typically some TSR (total shareholder return metric).
So for google, "don't be evil" is what's written down, but for the top execs "sell ads" is what gets they paid out before they retire. And those senior level "lifers" are what 40 now?
Don't really have proof to support these claims though.
The reason given: Legit covid information was not getting through during the fist few days of the crisis, basically made an emergency move to disable the whitelist/blacklist functionality of the algo which reverted to how it worked years ago.
A mainstream search engines kinda like a big marker equity ETF or index? There are a ton of benefits but as a negative they make price discovery difficult and give monetary allocation to companies that probably shouldn’t have it.
Just a thought experiment, curious what others think.
I mainly use google as a reddit search engine these days. "tiki cocktail pineapple juice reddit" gives me way more than google algorithm, and plus it's kind of like human powered SEO where genuinely useful links will likely have some discussion.
So I figured I’d try a few of these with “Seattle vegetable garden blog” as the keyword. Either there aren’t a lot of blogs on the topic or most search engines miss them because results are sparse and they really shouldn’t be.
A curated, searchable web directory might be a concept that could come to be these days. It would share some of its DNA with the old school web directory but also share some with a search engine.
I sometimes use "inurl:wordpress" when searching for travel info. This ensures more first-person blog accounts, rather than all the tripadvisor junk that's at the top.
Man you read my mind, just starting thinking about this. From a search censorship perspective, the BBS's we were building in 93 would be better than what we have now.
can google allow us to exclude certain sites? i was surprised to see w3school showing up above official documentations for pandas and numpy. this is simply ridiculous!!
It wouldn't be hard to remove such results using a browser extension,but you will be scrolling a lot. Maybe duckduckgo should support it,feature request?
Not sure it would yield any useful results, but have been thinking about a no-index search engine for a while to help find obscure or otherwise hidden information. If one exists or you build one let me know.
Showing all the lower ranked sites would be pretty cool. A lot of blogs would probably end up there, especially if they don't care about pagerank like me.
if google would switch to the google's engine code that was used right before they modified the "+" operator for google-plus, it would be a lot better.... ie: bring back the + operator please (the quotes dont work the same way)
Look, I know it's important history and all, but looking at it realistically, it's a tiny part of the information the average person needs. Them removing Reddit, EdX, Sci-hub or the Hong Kong Companies Registry from search results would have a much bigger impact.
I like this question. I’ve often wanted a search engine which gives you the choice to find sites that don’t contain a paywall, tracking or advertising.
> Ask HN: Is there a search engine which
excludes the world's biggest websites?
> Discovering unknown paths of the web
seems almost impossible with google et
al..
> Are there any earch engines which
exclude or at least penalize results from,
say, top 500 websites?
Let's back up a little and then try for an
answer:
Some points:
(1) For some qualitative exclamation,
there is a LOT of content on the
Internet.
(2) There are in principle and no doubt so
far significantly in practice a LOT of
searches people want to do. The search in
the OP is an example.
(3) Much like in an old library card
catalog subject index, the most popular
search engines are based heavily on key
words and then whatever else, e.g., page
rank, date, etc.
So: (1) -- (3) represent some challenges
so far not very well met: In particular,
we can't expect that the key words, etc.
of (3) will do very well on all or nearly
all the searches in (2) for much of the
content in (1).
And the search in the OP is an example of
a challenge so far not well met.
Moreover, the search in the OP is no doubt
just one of many searches with challenges
so far not well met.
Long ago, Dad had a friend who worked at
Battelle, and IIRC they did a review of
information retrieval that concluded
that keyword search covers only a
fraction, maybe ballpark only 1/3rd, of
the need for effective searching. And the
search in the OP is an example of what is
not covered because the library card
catalog did not index size of the book or
Web site! :-)!
Seeing this situation, my rough, ballpark
estimate has been that the currently
popular Internet search engines do well on
only about 1/3rd of the content on the
Internet, searches people want to do, and
results they want to find.
So, I decided to see what could be done
for the other 2/3rds.
I started with some not very well known or
appreciated advanced pure math; it looks
like useless, generalized abstract
nonsense, but if calm down, stare at it,
think about it, ..., can see a path for a
solution. Although I never thought about
the search in the OP until now, in
principle the solution should work also
for that search. Or, the math is a bit
abstract and general which can
translate in practice to doing well on
something as varied as the 2/3rds.
Then for the computing, I did some
original applied math research.
Using TeX, I wrote it all up with theorems
and proofs.
So, the project is to be a Web site.
While in my career
I've been programming for decades,
this was my first Web site. I selected
Windows and .NET, and typed in 100,000
lines of text with 24,000 statements in
Visual Basic .NET (apparently equivalent
in semantics to C# but with
syntactic sugar I prefer).
The software appears to run as intended
and well enough for significant
production.
I was slowed down by one interruption
after another, none related to the work.
But, roughly, ballpark, the Web site
should be good, or by a lot the best so
far, for the 2/3rds and in particular for
the search in the OP.
So, for
> Ask HN: Is there a search engine which
excludes the world's biggest websites?
there's one coded and running and on the
way to going live!
Can you talk at a high level about the problems of keyword search, or is that part of your secret sauce? Off the top of my head I can think of two, which are intent and encoding.
Before you can even do a keyword search, you obviously need an intent to do so. But that means keyword search is pretty useless when you don't know what you don't know.
Encoding that intent...maybe doesn't matter for common searches, but everyone has heard of the concept of "Google-Fu". English text is a pretty lossy medium compared to the thoughts in people's heads...Shannon calculated 2.62 bits per English letter, so the space of possibly-relevant sites for almost any keyword is absolutely enormous (e.g. there are about 330,000 7-letter english keyword searchs...distributed across how many trillions of pages, not even counting "deep web" dynamically generated ones?). So we punt on that and use the concept of relevance for sorting results, and in practice no one looks beyond the first 10. I don't know what an alternate encoding might look like though
> Before you can even do a keyword search, you obviously need an intent to do so. But that means keyword search is pretty useless when you don't know what you don't know.
Right: The way at times in the past I have put something like that is to say that, ballpark, to oversimplify some, keyword search requires the user to know what content they want, know that it exists, and have keywords/phrases that accurately characterize that content. For some searches, e.g., the famous movie line
that is fine; otherwise it asks too much of the user.
For "encoding", my work does not use keywords or any natural language for anything.
My work does get some new data for each search for each user. But privacy is relatively good because for the results I use only what the user gives for that search; in particular, two users giving the same inputs at essentially the same time will get the same results. Thus, search results are independent of the user's IP address or browser agent string. Moreover, the site makes no use of cookies.
The role of the advanced pure math is to say that the data I get and the processing I do with that data and what is in the database should yield good results for the 2/3rds. The role of my original applied math is to make the computations many times faster -- they would be too slow otherwise.
When keywords work well, and they work well enough to be revolutionary for the world, my work is, except for some small fraction of cases, not better. So, there is ballpark the 1/3rd where keywords work well. Then there is the ballpark, guesstimate, 2/3rds I'm going for.
My work is not as easy for the users as picking a great, very accurate, result from the top dozen presented by a keyword search engine, e.g., the movie line example, but is much easier to use than flipping through 50 pages of search results and is intended usually to give good results unreasonable to get from a keyword search, without "characterizing" keywords, that yields, say, millions of search results and would require a user to flip through dozens of pages of search results.
Ads are off on the right side and not embedded in the search results. The SEO (search engine optimization) people will have a tough time influencing the search results!
We will see how well users like it. If people like it, then it will be good to make progress on the huge, usually neglected, content of the 2/3rds.
I have a list of 100+ candidates but (i) I have not selected one yet, (ii) don't really need one before I register it, and (iii) don't want to start paying for it before I need it.
{kind=link}
There are so many cool things I remember reading on the web like 10-20 years ago that still exist that are so buried now on Google they might as well not exist. Nowadays searching any topic seems to always lead you to CNN and Microsoft and Facebook and other huge corporations. Search results are just becoming more sanitized and beige and meaningless every day.