We had an "open-ended" project in an undergraduate Computer Security course to discover a 0-day in Firefox. The professor (a researcher, not lecturer, by trade) didn't really have a curriculum, and said this artifact accounted for 70-80% of our grade.
Trying to compile Firefox was already a challenge. That, and each compile took an hour. IIRC, Firefox is built on some esoteric architecture / design pattern that's definitely beyond the scope of design patterns undergraduate students are familiar with.
By the end of the term, no one discovered a 0-day, unsurprising considering half the class didn't even try. There were 90 students in the class, and I ended up being the only person to produce a JS payload that would crash Firefox in one of the newer HTML5 libraries. It's neither a zero-day or exciting or profitable vulnerability though.
Realizing everyone in the class would fail, the professor changed the grade of this project to only account for 30% of the grade. I spent most of my time on this project while disregarding the rest of the busy work for the class. In the end, I got a C grade while my peers who didn't even attempt to tackle this project received higher grades.
He is neither a researcher nor teacher - typical academic parasite.
Makes a bet on trendy advanced task and, if it works, lets you be a coauthor. If it does not - no big deal some naive student spent 1/2 year on something virtually impossible w/o deep industry experience.
> I am generally suspicious of anyone who voluntary pursues academia
That's very unfair imo.
The majority of people I know in academia don't fit this profile at all.
There is obviously disappointing stuff happening, but people generally still are working/teaching in good faith.
>but people generally still are working/teaching in good faith.
It depends on university. On mine, most professors just see it as a job, something that one must endure until it's over. And when you bring to attention that what they're lecturing is incorrect or not proven they don't really care, again not all, but most, at least on my university. Just today I reminded the professor that there is a difference between a theory and hypothesis, their response was that they don't know if the theories they're teaching were tested or proven, but they are teaching this because that's what's written in the book...
That made me really sad, it's already hard to stay motivated to not leave the university because you need a certificate of a higher education to be taken seriously, but such behaviour from professors makes it even harder.
I've already expressed my worries to those in control of courses and they say that they understand but can't do much to change things because the curriculum that we have was accepted by the government.
Here in Slovenia people that work in the universities are paid by the government regardless of how happy or unhappy the students are, which is probably the reason for the situation in which we are...
As a fellow Slovenian, former student and now someone who's spent years professionally in academia, let me try to show your experience from a different perspective. I don't know anything about your professor except the anecdote you shared, so I'm not defending them. I'm just trying to shine a different light "on the situation in which we are" that you as a student perhaps didn't (yet) have a chance to see. I'm also writing this because I feel like your view is pretty common among our students.
How our universities work is that as a researcher a part of your duty to the university is teaching students. Unfortunately, fields of research and study subjects in most cases aren't aligned. Nobody will be researching basic subjects that must be taught to the students, and on the other hand a very specialized field of research might not be taught to anything but a small post-graduate course. This means that often professors will end up teaching an undergraduate course that has next to nothing to do with their field of study. In the end, someone must be teaching those introductory courses and for some subjects being taught the university might not have any professional researchers at all.
Professors are researchers first and teachers second. This is most likely the reason why it appears that teaching is "something that one must endure until it's over". Your professor might be a brilliant world-class researcher in their field and they pursue it with passion, but they might be teaching e.g. linear algebra to undergraduates twice a week based on "what's written in the book" to keep their job. As it turns out, teaching and research are quite different skills and they often don't coincide. When they do, you get some really amazing professors and I'm sure you have some on your course as well.
It's not a perfect system, but I've spent enough time in foreign universities where research staff was on-the-hook all the time and liable to get fired if students weren't happy with them. It's such a constantly stressful environment that I was amazed that people managed to do any kind of research at all. In the end, it's a trade-off. You can't have a university without either top-end research or teaching and we might have chosen a slightly different trade-off between these two than the countries you seem to look up to.
Anyway, I hope I've given you a new way to look at things and I hope you will stay at your university for more than just to get the "take me seriously" papers.
> people still can be harmful even being in good faith
That's a general truth.
You make it sound like people choose academia to somehow cheat the system and profit from free student's work or whatever.
Make a real case for you thesis then.
People choose academia to be within (zero-sum) system and project the same expectations to students, while real life success is about being out of any system.
Hence the harm.
People don't 'choose academia to be within a zero-sum system and project the same expectations to students'. My partner and most of my friends are or have been in academia and the one common thing is a real passion for their subject of choice and industry doesn't offer the same flexibility to focus on it.
Being suspicious of those who voluntarily become academics is odd.
Real life results of academia are largely propaganda (tuition billions well spent).
They are not even good in figuring out why/how things work and replicating success (additionally proven by Soviets).
Your language of choice - Clojure according to your HN bio - works on a product where important parts (e.g. Generics and the Java collection framework) were done by academia. One of the most popular compilers (LLVM) was done in academia (and still is in parts!). Most of the optimizations compilers use were done by academia.
Your work stands on the work of countless academic researchers and you run around "What did academia EVER do for us?" - the Monty Python sketch about Romans comes to mind.
This is especially laughable, since I have seen how that works on practice: take something everyone already does, write 1000 of PhDs on that, add to academic history book, now wikipedia and voila.
If any of IT projects came from academia to the market, it's only because certain people were picked up by businesses that were onto something already.
I don't mean this in a derogatory way but from your bio it sounds like you work in full-stack web development - maybe with some data processing. Sure, this stuff doesn't really come from academia. But there are other bits of tech where academia does play a large part and your viewpoint is just not correct. One example that contradicts your second paragraph away is I spent several years at a consultancy that helped academics commericalise their own research - mostly medical tech but some computer vision stuff too. There's loads of great work businesses coming out of academia - you might just not be in a position to see it.
Coincidentally, before current full stack freelancing stuff, I've spent around two years in augmented reality, often having to dig through tons of published research, only to realize pretentious lab methods do not work outside. We ended up adopting some methods from hacky teens on DIY forums, but never that..
Don't be salty, man, no offence, academics need love too. I'm not even by far academic, academical, but, let's keep it cool, man. No offence or intent to be hostile.
That makes no sense as a class design - are there so many zero days in firefox that are so easy to find that you can expect undergrads to casually find enough that you can base 70% of the class grade on it?
I'm gonna go out on a limb and say that a research professor at presumably a large research university doesn't give two shits about being the next jaime escalante. The reality is probably that they're more focused on research, and don't care much about actually teaching. You see quite a bit of that.
Any change to the grading scheme of a class should be Max(old grade, new grade). One of my profs once offered a re-test opportunity such that you would have had an incentive to do worse on the exam for certain original scores. Drove me up the wall.
I also think that just keeping the new grade is a valid retake scheme. Although it's less forgiving for the students, it encourages them to make absolutely certain that they know the content for the retake. Anything with a square root curve where you have to pinpoint your retake score perfectly to maximize the final grade is unfair and encourages the wrong thing.
Yep, that's also fine by me. Although ideally (and especially if it's required to do a retake!) this would be set out ahead of time. Many profs don't seem to understand the kind of time and grade tradeoffs students need to make. Once had a prof come in to a class with a bunch of seniors with many other high priority classes that wouldn't release the grade weighting at all. They didn't understand that people need to know that kind of thing to know whether they need to do really well on something or if it's the kind of thing that can be dropped or half assed when push comes to shove.
> Realizing everyone in the class would fail, the professor changed the grade of this project to only account for 30% of the grade.
> I ... disregarding the rest of the busy work for the class.
It sounds like OP could not find a zero day (old_grade=0) and did not do any other homework (new_grade=0), therefore should have received max(0, 0), but received a C.
I'm curious what year this was. When I was in college (~2005) we had an entire class based around contributing to Mozilla (both Gecko and other parts - https://wiki.cdot.senecacollege.ca/wiki/DPS909). The very first assignment in that course was compiling Firefox. Which, especially on Windows, was a herculean task at the time. I believe this sort of experience helped to spawn https://wiki.mozilla.org/MozillaBuild and other developer experience projects.
Things are much better these days, but there is still much inherent complexity in a project like Firefox.
> Trying to compile Firefox was already a challenge. That, and each compile took an hour.
At first glance, this sounds terrible. But when compared to software projects of comparable size, Firefox is hardly unique. Compare to compiling Chromium for example, or even the Linux kernel.
Those are all very different levels of difficulty IMO:
Linux is almost trivially easy, only slightly harder than the usual configure && make and has very few dependencies.
Firefox is pretty painful but it's doable with a decent amount of care and bandwidth.
Chromium is a fairly typical google project where the recommended first step to building it is to become a google employee but some alternative workarounds are also available if that's not practical.
Nah building is fine, just follow the steps from Debian/Ubuntu/whateverdistro . But trying to contribute is fun. By the time you've danced all the hoops to allow you to contribute, some Google employee has already refactored the code around the bug. Then you have to be fast enough to get your updated patch applied before someone else has reorganized the code again...
At some point I started wondering if indeed I'd get the fix in faster by starting to practice whiteboard interviews.
> ...some Google employee has already refactored the code around the bug. Then you have to be fast enough to get your updated patch applied before someone else has reorganized the code again...
For what it's worth, this is how it work's if you're a Google employee too.
It's uses gn, a build system developed for Chromium. That said, on an Ubuntu system the steps to build Chromium are fairly well-documented and straightforward, as long as you have an appropriately beefy system (unfortunately it's a long wait and a fair amount of RAM is required, and Googlers tend to use a distributed build system).
gn is of course a meta-build system, the initials stand for "generate ninja". ninja does the actual build execution. The Firefox build system has a similar homegrown frontend called mozbuild, which generates Makefiles for the actual build.
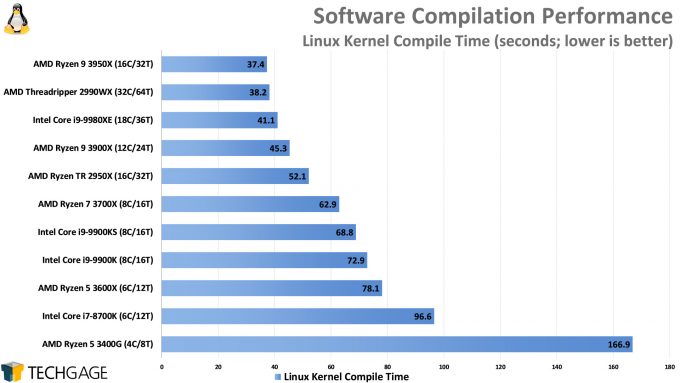
I think at scale (according to Wikipedia the 5.6 release has ~33M lines of code) the Linux kernel might be one of the easiest (and quickest) projects to compile[1].
I haven't compiled my own kernel in at least 15 year but I remember it was quite easy (is make menuconfig still the way to go?). I did have much more free time though.
I had to compile linux once and I found the process to be trivial. My distro had a guide for how to do it and then how load the kernel in to grub and it was basically just copy/paste
The syllabus where a grade is broken down by percentages is (at US institutions) considered to be like a contract. If the course originally had it at "70-80%", then it cannot be changed mid-semester without being acceptable to you. It's fairly incredible for this to happen (at a US institution).
They'd have ignored you. I went through something similar myself. The barrier to exit for students is so high that colleges have little incentive to care about pleasing them.
I just wanted to say that, despite a few mishaps, firefox is what _everybody_ on hn should be using. I can give my browser-time credentials, but really. Firefox is amazing. Care for the open web, fear ie6, and at the same time enjoy firefox!
> Care for the open web, fear ie6, and at the same time enjoy firefox!
And remember: Chrome is the new IE.
(Since a number of people have misunderstood this quote in the past I'll explain it up front: 1. IE was in some ways technically superior to competition until they became dominant. 2. At the same time devs stopped caring about other browsers, and then 3. Microsoft lost interest in it. We are repeating this it seems, currently at step 2 for a few years already, waiting for Chrome to completely outcompete other browsers and for Google to abondon it like so many other of their projects :-)
For people who don't care about privacy, what would be the motivation for making the switch?
Chrome is good enough. The interface is still streamlined.
Microsoft didn't just lose interest in IE, but it became bloated with the toolbar. The UI wasn't well proportioned in general.
Web development wise, it was a struggle to be compatible with IE. Chrome may be setting the web standard for better or worst, but atleast developers are more comfortable developing and testing Chrome. The sentiment is that writing code to work I.E. would be exceptional, whereas now writing code for non-Chrome browsers would be the exceptional case. In fact, developers sometimes only test Chrome. Some popular E2E JavaScript testing frameworks only work with Chrome.
Also, I don’t know if there are examples of Chrome implementing non-standard behavior that rivals IE having an event bubbling system that was inverted from every other browser.
As a developer you get a lot for free by developing in Firefox, most importantly if it works in Firefox the it will likely work in all other browsers as well. This is, in my experience as developer and code reviewer not the case for code written and tested exclusively on Chrome.
>The sentiment is that writing code to work I.E. would be exceptional, whereas now writing code for non-Chrome browsers would be the exceptional case. In fact, developers sometimes only test Chrome. Some popular E2E JavaScript testing frameworks only work with Chrome.
This was once the case with IE, as well. Testing code in non-IE browsers used to be the exceptional case, and a lot of developers only ever tested in IE. There are countless enterprise applications that only work in IE even now, which is most likely the main reason that Microsoft is still keeping IE alive.
I wish I could recommend Firefox but I can't because it cripples performance of the things I'm working on, namely streaming and rendering large 3D data.
I'm using Firefox privately at home but for work, including work@home, I'm using almost exclusively Chrome. Chrome is just so much faster and the developer tools so much more polished than Firefox. DataView is 40 times slower in Firefox, and I'm using it quite extensively to read binary files. There is a Uint8Array hack/workaround that lets you write your own DataView that is 4 times faster in Firefox, but 10x slower in Chrome, so it's not an alternative I'm going to use.
A rather basic jsperf is here: https://jsperf.com/dataview-float-int
The results are that the u8 hack is equally slow in firefox and chrome (~90ops/sec), the DataView version is 10x faster in chrome(945ops/sec) but almost 4x slower in firefox(25ops/sec).
I was thinking about Firefox development quality while trying to figure out why the f does Firefox CPU usage fluctuate between 1 and 5% with one background tab open and only one plugin installed (containers). The same URL when opened in safari goes to 0.1% or 0.0. I tried to look up dom timeout config settings and tried to set aggressive timeouts, but in the end I gave up.
There must be something fundamentally wrong if apps can't stfu and be at 0% while in background with simplest use case. I am going back to close app's when I am done using it.
Besides the devtools profiler, which may not capture everything there's a whole-application profiler for firefox, that might provide some insight: https://profiler.firefox.com/
But try the devtools one first, it's easier to use.
the f does Firefox ... same URL when opened in safari
It would be interesting to compare the safari budget/manpower. Even given that, I would imagine safari only has to support one-ish OS, and probably has help from the OS group.
The WebKit team is smaller than the corresponding team at Mozilla, even if you look at the subset of of identical roles across both organizations (and e.g. ignore those working on the Firefox network stack).
That said, it's worthwhile remembering that WebKit does very much maintain all the abstractions to be cross-platform (and Apple do still maintain a Windows port), even if it does try and leverage plenty of OS libraries in a way neither Firefox nor Chrome do.
I'm unaware of any special treatment (but that doesn't mean there is none!), beyond Apple caring about battery life in general on their OS and I would strongly expect that the browser forms part typical-use testing of the OS and as such influences what parts get targeted for performance work.
Certainly Apple's WebKit port uses Core Animation heavily, which is definitely heavily tied to the compositor in the window server.
Safari definitely uses private APIs (or at least did at one point) to manipulate out-of-process layers more directly than the public CA API lets you do.
Hey, I've been trying to remember something about the way CA and the windowserver interact for a few weeks but I can't find anything about it. I remember somewhere there was a setting for maybe the backing layer of how a window was set up? And there were a few hidden ones? i remember that one of these settings was how minimized windows were implemented because the layer was set up to copy some other layer, and then shrunken, so that way you get minimized windows changing when the window changes for free.
In my experience (which includes using both Firefox and Chrome on a Linux VDI which is particularly CPU-constrained), I've noticed that Firefox's event loop handling seems pretty poor, and seems to redraw/paint even a blank page (and has a full core of CPU usage for doing nothing), whereas Chrome is fully-idle and has no CPU usage in the same scenario. Minimising Firefox is the only way I've found to stop it updating the VDI's content and using CPU.
Things (on the same constrained resources VDI) get even worse with actual "complicated" content: viewing the same page which contains an animated GIF, Firefox seems to prioritise playing back the content, even at the expense of noticing/obeying user-interface interaction like closing tabs and opening menus: i.e. gifs will keep playing (very slowly), but it won't notice UI clicks on its interface for many seconds seconds.
In the same scenario, Chrome responds to UI events much more quickly (very nearly instantly).
It's possible this is due to hardware acceleration or something, but as both are running in the same VDI that barely seems to have OpenGL 2.0 support (I can't run modern OpenGL apps), that seems unlikely to me...
In addition to what others have suggested you might want to check how many things you have registered under about:serviceworkers (type that in as the URL), there might be something in there running far more than is reasonable.
I’ve gotten in the habit of killing Firefox before going to bed, the processes seem to run away and peg the CPU periodically throughout the night. It seems to be generally Facebook, but other JS heavy sites have similar issues.
Google Calendar has had some serious issues with doi g something weird in the background.
At some point Google search results page also would spinn up one core on my machine one or twice a minute if left unattended but last I saw that was years ago. (FWIW I don't use Google search much these days, so it might slip by without me noticing.)
This is beyond me as well but I chalk it up to our entire field being immature, which means there are endless possibilities and endless chaos.
IMO background activity should need an extra permission similar to notifications and geolocation.
But we need to sort out UX (and start punishing the companies that "misunderstand" GDPR to mean they just need to add another popup) as it is starting to get bad now.
BTW, this needs to be fixed across a number of situations. There's no reason why I would want to allow a build tool to access all my projects just because I want to allow it to access one project. (Github and Azure Devops, I'm looking at you)
Depends on how you look at it, I need to keep state of work things (emacs sessions etc). But compared to my fridge or pretty much any industrial country my computers electricity consumption is near negligible.
Chrome has the same issue. The thing is, Safari is deeply connected to OS X and its internals to save as much energy as possible. Apple can do this and tie the code to the specific hardware, kernel, and what else matters that Safari runs on as they control everything. Chrome and Firefox cannot.
I would not be surprised if someone tells me that parts of Safari hook into private APIs in the kernel, the graphics driver and the other parts of the graphic and input stack to achieve the (measurable!) performance advantage over other browsers. For me personally, this is uncompetitive behavior that should be punished, but oh well, anti-trust legislation isn't exactly something that got much use over the last decades :(
You think Apple should be punished for creating a vertically integrated stack?
Setting aside private APIs as I have no idea what Safari does or doesn't use (although vast portions of it are open source, enough that you can compile modern versions of WebKit and "upgrade" the ancient WebKit on PowerPC Macs), another browser could be just as closely integrated as Safari. Obviously, the cost/benefit ratio is awful for Mozilla and Google, so they won't, but why should Apple cripple their own software? Safari's development costs, as part of MacOS, are funded by profits from Mac sales. Safari is deeply integrated with MacOS which is in turn deeply integrated with the Mac.
In my opinion the whole point of the Mac is this vertical integration, and the main value-add of Apple's sphere. If you don't value that, there are cheaper options where cheaper and more flexible software is available.
To me, an anti-trust suit would make sense for Safari on iOS, where Apple has locked all competitors out (in practice). Saying Apple should be fined for Safari because it's more integrated and efficient and that's not fair to Chrome and Firefox seems a bit silly, especially given (desktop) Safari's relatively small usage numbers. All IMO of course.
> You think Apple should be punished for creating a vertically integrated stack?
No, only for not giving everyone a fair and equal level of access. I'm not against Apple deeply integrating Safari into the OS, but they should allow competition to enjoy the same level of performance that their own stuff does.
> I would not be surprised if someone tells me that parts of Safari hook into private APIs in the kernel, the graphics driver and the other parts of the graphic and input stack to achieve the (measurable!) performance advantage over other browsers. For me personally, this is uncompetitive behavior that should be punished, but oh well, anti-trust legislation isn't exactly something that got much use over the last decades :(
In the absence of any evidence of this — have you looked at the open source releases? — why is that more plausible than a team employed by a hardware vendor which cares deeply about user experience and battery life prioritizing use of the platform features and talking with other teams at the same company? Part of what makes things like Firefox' compositor work hard is that they support multiple other platforms so the Safari team can easily be ahead without anything underhanded simply by virtue of not needing to support 4 major platforms.
I appreciate the acknowledgement of needing to tolerate previously acceptable conditions while scanning and remediating those same conditions point forward.
I wish IT auditors understood this concept better.
Sorry for the following rant, but I really don't think of Firefox browser when I think of code quality. (Still don't even though it has improved a lot in some areas).
When it comes to browsers, I still feel the old Opera browser (presto), that had more features, was blazing fast and small in size (in memory) is a very good example of a finely engineered software. In the early versions they really cared about optimizing for performance, using less memory and less power (on mobile devices) - I am amazed that years after, modern browsers are bloatier now than ever and just don't seem to care as much about these aspect as much as Opera did.
Questions like how modular is Firefox, how easy is it to customize Firefox (add or remove feature from the code), how easy is it for someone to use the Gecko rendering engine in their own project etc. all kind of indicate the bloatier, messier nature of the code within Firefox (in my opinion).
It's like browser developers now a days only care about adding more features (read bloat) without considering any constraints ...
Presto wouldn't be so memory efficient on today's web; web applications typically ran into plenty of places where memory consumption was worse in Presto versus WebKit, for example. (A simple example here is that each DOM Node was larger in Presto than any other browser, if I'm not forgetting.)
But ultimately a lot of this comes down to different considerations: when the majority of your revenue comes from companies who care about running on limited devices, of _course_ the company invested more in running well on them. And I wouldn't hold up Presto as a great example of modularity or the ability to embed the rendering engine in other projects.
> Presto wouldn't be so memory efficient on today's web;
I disagree. (I continued to use the last version of Opera Presto for a few year even after it was abandoned, and it continued to outperform other browsers on both platforms - Windows and macOS, though the macOS version was a bit more buggy).
Let's not forget that Presto already supported a lot of HTML5 features(1) before it was abandoned. (Even today, it works surprisingly well on most websites, though it does show its age a bit). And while the last few versions did seem to be a bit more resource heavy, I attribute that to development suffering because of the upheaval in the company - morale was low as many developers were laid-off while the management was also negotiating a sell out with investors. This naturally stunted the development of the core browsers parts in the end.
(Also, it was a suite and had an integrated email client, IRC, Torrent download manager, RSS reader, apart from the browser, all of which was packaged in a smaller size than Firefox or any other browser of its time!)
> when the majority of your revenue comes from companies who care about running on limited devices, of _course_ the company invested more in running well on them.
True. But let's not forget that Opera browser earned its reputation for being blazing fast, its tiny size and its low memory consumption on the desktop platforms long before it became a popular browser on the mobile platform. If I remember right, the first few versions of the Opera browser (then a non-free product) was less than 3-4 MB(2)!
> And I wouldn't hold up Presto as a great example of modularity or the ability to embed the rendering engine in other projects.
I can't comment much about this - The source code of Opera Presto is out there on the net, and it is definitely much easier to understand than the Firefox codebase. I also remember that the popular Macromedia (now Adobe) Dreamweaver used the presto engine at one point.
It says a lot about Mozilla that despite being older than both Chromium / Blink and Webkit, the latter are more popular in many open source and commercial applications because of the ease of use in coding and integrating it in their applications. A good example of this is QT5 which offers the QTWebView and QtWebEngine module (3) that allows you to embed webkit or chromium in your application, out of the box. Whereas qtmozembed is a barely maintained unpopular option for this same use (probably only surviving because Jolla develops their mobile browser for Sailfish OS using it).
(And I suspect this was a deliberate decision made by Mozilla after Gecko / Firefox became a cash cow for them - they just didn't want the code to be modular and easy to understand as it would hinder the creation of competing browsers, which would otherwise potentially cannibalise their own product. Ofcourse, with GeckoView this slowly seems to be changing perhaps on the Android platform, but I cynically suspect this has more to do with the fact that Firefox Mobile is not very popular on the mobile platform, and Mozilla now is looking to encourage developers to create even alternate browsers using their technology hoping it'll provide a filip for their own Firefox Mobile browser. That's certainly going to be interesting to see ... Another intresting tidbit I recall reading somewhere is that Mozilla also makes some developers sign non-disclosure agreements (4) which seems very odd and out of place to me, for an open source project.)
> But let's not forget that Opera browser earned its reputation for being blazing fast, its tiny size and its low memory consumption on the desktop platforms long before it became a popular browser on the mobile platform.
Just about all of the major browsers earned their reputation for being blazing fast, tiny, and using little memory. And those attributes are well-deserved at their launches. Then real-world pressures kick in -- it turns out that although people love small and fast, that doesn't do them much good without support for X (or being able to handle condition Y), and there are many, many values of X (and Y). Small and fast plus X would still be nearly as small and fast, but small and fast plus all X is decidedly not. Meanwhile, the other engines are evolving too, and everyone more or less converges on roughly the same performance characteristics. We [I work for Mozilla] end up mainly competing on different metrics, assuming we all keep up with "good enough" speed and size.
> It says a lot about Firefox that despite being older than both Chromium / Blink and Webkit, the latter are more popular in many open source and commercial applications because of the ease of use in coding and integrating it in their applications.
Indeed it does. Firefox abandoned embeddability long ago, and only recently decided to try again with GeckoView. And yes, it was a deliberate decision, but not for the profit motivations you're suggesting. It was based on maintainability and developer velocity, when we realized we were not going to out-compete Google with engineer headcount. We had to simplify and reduce our nonessential complexity overhead.
> Mozilla also made some developers sign non-disclosure agreements
Why throw so much shade? I'm not sure exactly what you're referring to, but Mozilla does indeed sign NDAs for stuff that people will only make available under NDA, and there is some insider knowledge that can only be released under NDA or not at all. That was far more common with FirefoxOS, because let's just say that the mobile industry isn't quite as open as desktop. (Massive understatement!) But generally speaking, we have very little to gain from keeping any technical or architectural stuff private, and quite a bit to lose. We're still a community-based project, and get very substantial contributions from non-employees, admittedly much less than in that past as a percentage (for a long time, we hired up many of the better contributors, which cut both ways.) The vast majority of our discussions happen in open forums (Matrix instead of IRC now, but still mailing lists + newsgroups + various other things). The only private technical stuff I ever deal with is security-related, and even there we're very good about opening up bugs after they've shipped.
> And yes, it was a deliberate decision, but not for the profit motivations you're suggesting. It was based on maintainability and developer velocity, when we realized we were not going to out-compete Google with engineer headcount. We had to simplify and reduce our nonessential complexity overhead.
How naive to think that copying your competitor makes you gain many users!
P.S: I hope you didn't feel attacked because of my harsh opinions in my prevoius reply to you. My ire is directed at the Mozilla foundation, and not at contributor employees like you who help to build a useful software.
> Just about all of the major browsers earned their reputation for being blazing fast, tiny, and using little memory.
Not like Opera though who made performance and small size (and power optimizations) as their core philosophy.
(This was the browser whose popularity even frightened Microsoft, whose infamous Internet Explorer had I think nearly 80% market share at the time. So much that they deliberately ensured that their website broke on Opera. And it forced them to reluctantly focus on the Trident engine that powered IE again - till then, they had been ignoring IE because Microsoft was rightly genuinely frightened of competing on and with the web).
Starting with the mindset of making a fast, small and efficient engine that could run on constrained systems was the reason Presto outshined other engines. Later this extended to optimising their code for lower power consumption too.
That's the main difference with Gecko, Chromium / Blink and Webkit (to a lesser extent) who did focus on optimising for speed but were a bit more lax on the memory and power aspect and only started addressing it after users started complaining (and ofcourse, only after they made mobile platform a priority). I still remember how we users grumbled when Opera installers crossed the 10 MB size :) ... but Opera still managed to keep us hooked by introducing a plethora of features while still trying their best to maintain an efficient code base and deliver it in a smaller package. Compared to it, equivalent versions of Firefox and other browsers at that time (and even today) seem very bloated in comparison because it's not a priority to them.
> Then real-world pressures kick in -- it turns out that although people love small and fast, that doesn't do them much good without support for X (or being able to handle condition Y), and there are many, many values of X (and Y).
Sure, but this doesn't apply to Opera. Opera kept their high standard and core philosophy intact till the last version before management failed them. It maintained feature parity with competing browsers till the end, before it was sold off and dumped for Blink to cut costs.
Opera didn't fail because it couldn't keep up with web standards or in introducing new features, but because of poor business management.
If Opera's founder is to be believed, they just couldn't allocate enough resources for keeping track of, and patching broken popular sites that don't follow web standards. (This is the reason he gave for abandoning Presto, and selling his company, and then choosing Blink for his new Vivaldi browser).
Opera the business failed, but their product was top notch and better than their competitors till the end. If I remember right, I stuck with it till 2017-18 before I moved on to Firefox and later to Ice Cat, Pale Moon and Safari.
> We [I work for Mozilla] end up mainly competing on different metrics, assuming we all keep up with "good enough" speed and size.
Yeah, that's spot on - that's what I've always felt about Firefox, that Mozilla's philosophy is to be "good enough", and that's why to us consumers the product (Firefox) feels "average". There is nothing much to feel excited about in terms of performance or features. That's the area (performance and features) that Opera excelled in.
> And yes, it was a deliberate decision, but not for the profit motivations you're suggesting.
I am sorry but I don't believe this - it was very much for profit too. I do believe it was to ensure the project isn't forked easily to build a competing product. Just look at Goanna / Pale Moon struggling to maintain quality and feature parity now. (Ofcourse they are also struggling because of the design decisions they made).
Chromeless Firefox was a very interesting project. Killed before it could become popular. Vivaldi browser is based on a similar idea and its enjoying some success.
My point is that it is a smart decision from a purely business perspective - look at all the relatively successful fork of the Chromium browser. And browsers based on webkit. There are many people who don't like the current direction of Mozilla and / or Firefox and they would gladly jump on to decent a fork if it were easy to do so.
> It was based on maintainability and developer velocity, when we realized we were not going to out-compete Google with engineer headcount. We had to simplify and reduce our nonessential complexity overhead.
That's MBA manager speak - lots of buzzwords that don't really convey anything meaningful. ;)
My perspective is that as an open source project, Mozilla shouldn't sacrifice product quality for short-term gains. They should fix bugs rather than focusing on new features or products even if they lose ground to other browsers. Their focus should be on quality rather than trying to compete with a corporate product and keep pushing release after release just for the sake of competing and "staying relevant".
> Why throw so much shade? ... we have very little to gain from keeping any technical or architectural stuff private, and quite a bit to lose.
As for the snark against Mozilla - your perception is right. I do have a certain level of antagonism against the foundation. It stems from the following reasons:
(1) They are a million+ dollar foundation and still produce an "average" product. Comparing them to other open source projects with much, much smaller budgets that produce high quality softwares really irks me.
(2) Some of their recent management decision range between foolish to greedy. E.g. Forcing Pocket on unsuspecting users (I strongly suspect some members where bribed to push this integration). E.g. Including closed source DRM in the browser (if users want to download a plug-in to watch DRM protected media, then they should have a choice to do so. Google and Cisco, if I remember right, now have a monopoly on this because of Mozilla).
About the NDA part: some community members have the possibility to sign an NDA and get access to some Mozilla Corp information before it is public. This is absolutely not required to contribute to the code base.
About DRM: Mozilla fought against it, and caved when it became clear they could not win. But Firefox users still have to opt-in to install the binary blob (eg. Widewine), it's not bundled in the browser.
> About DRM: Mozilla fought against it, and caved when it became clear they could not win.
While I do believe there was genuine opposition to this move within the community, I think the real decision makers had already made up their minds and just made a show of "discussing" it. I feel they did it under pressure, and perhaps were even induced with promises of more revenue, from Google.
And where was the question of really caving? All they had to do was ask Google (or any other company) to develop a browser plugin for Firefox and let the user decide if they wanted it (when a user encountered it on a site, produce a pop-up alerting the user to the plug-in required). And maybe then we would have some real competition in this space too as a new plug-in war would have developed ...
> But Firefox users still have to opt-in to install the binary blob (eg. Widewine), it's not bundled in the browser.
I think since EME free versions were released, at some point a policy decision was taken to make it "opt out" in the usual general releases, as a technical person would rather opt for the EME Free version or go through the options and disable it if they so desired, where as a non-technical user might get confused about EME or DRM or plug-ins ...
I fear that the Google DRM binary blob has actually made it much easier for them to uniquely fingerprint every Firefox user with EME / Widevine despite all the ad-blockers and anti-fingerprint extensions or techniques being used. In other words, I fear that Firefox (knowingly or unwittingly) has aided Google in killing privacy on the web.
> While I do believe there was genuine opposition to this move within the community, I think the real decision makers had already made up their minds and just made a show of "discussing" it. I feel they did it under pressure, and perhaps were even induced with promises of more revenue, from Google.
The problem with beliefs is that there is no option to disprove them. Mozilla said they fought against it, the people who were there say they did fight against it, you don't believe it and think it's some kind of "show" put up.
> All they had to do was ask Google (or any other company) to develop a browser plugin for Firefox and let the user decide if they wanted it (when a user encountered it on a site, produce a pop-up alerting the user to the plug-in required).
And what incentive would companies have had to do that? Firefox simply doesn't have the market share to force anyone to develop for them. Even worse, Google has every incentive to not do it and instead pop up a banner "hey, looks like your browser doesn't support YT, use Chrome". People who argue that Mozilla was wrong to accept the DRM blob never have a good answer for this and usually then end in "people would have seen that Mozilla is right and boycotted YT" or "who cares if Mozilla has only 1% market share, it's far more important to never make any compromise".
> Firefox simply doesn't have the market share to force anyone to develop for them. Even worse, Google has every incentive to not do it and instead pop up a banner "hey, looks like your browser doesn't support YT, use Chrome". People who argue that Mozilla was wrong to accept the DRM blob never have a good answer for this and usually then end in "people would have seen that Mozilla is right and boycotted YT" or "who cares if Mozilla has only 1% market share, it's far more important to never make any compromise".
It wasn’t just Google: Microsoft and Apple also sold both DRM systems and content, and all three loved the idea of getting rid of Adobe. I never could get anyone to offer a credible theory for how Mozilla could fight those odds.
> And what incentive would companies have had to do that? Firefox simply doesn't have the market share to force anyone to develop for them.
- Firefox has enough of a marketshare that nobody ignores them.
- If Google wouldn't, someone else would have.
- The content providers (Netflix, Prime, Hulu etc.) would have forced them to do so.
I don't buy these arguments. And the fact that Mozilla makes it opt-in by default shows that the Mozilla board is now more concerned about revenue from Google and squeezing it as much money from their product than actually improving it. I wish the Firefox developers had more voice.
> Just look at Goanna / Pale Moon struggling to maintain quality and feature parity now. (Ofcourse they are also struggling because of the design decisions they made
What design choices? If they would ride on Firefox release cycle, Pale Moon would lose its advantages.
True. I meant that some of the struggles that they are facing in keeping parity with current Gecko development is because of the goals they have. I use Pale Moon sometime but it's performance on mac leaves a lot to be desired. I also worry about security issues on it ...
> I disagree. (I continued to use the last version of Opera Presto for a few year even after it was abandoned, and it continued to outperform other browsers on both platforms - Windows and macOS, though the macOS version was a bit more buggy).
Loading my profile on Twitter leads Presto to use more memory than Firefox. (Though really that's a terrible benchmark, probably want to disable in-memory caching.)
> Let's not forget that Presto already supported a lot of HTML5 features(1) before it was abandoned. (Even today, it works surprisingly well on most websites, though it does show its age a bit). And while the last few versions did seem to be a bit more resource heavy, I attribute that to development suffering because of the upheaval in the company - morale was low as many developers were laid-off while the management was also negotiating a sell out with investors. This naturally stunted the development of the core browsers parts in the end.
In all due respect, you sound like you have no idea what you're talking about, neither with when there were lay-offs or with how morale was internally. Morale only really collapsed after the move to WebKit, nor had there been lay offs for several years prior.
The increases in memory consumption were primarily down to changing trade-offs with performance v. memory consumption, and certainly a fair number of these were configurable at compile-time (heck, Futhark stayed around for a while after Carakan was shipping on desktop precisely because it's memory consumption was lower).
> I can't comment much about this - The source code of Opera Presto is out there on the net, and it is definitely much easier to understand than the Firefox codebase. I also remember that the popular Macromedia (now Adobe) Dreamweaver used the presto engine at one point.
The graph of module dependencies was… quite something. There was a _lot_ of mutual dependencies between modules, so in many ways it really wasn't modular.
As for embeddability, I'll point out that typically there were multiple implementations of platform layer stuff across the company (heck, Core maintained an almost entirely separate implementation to Desktop for all the platform layer stuff, despite the test browser running _on the same platforms as Desktop_). You had to write a lot of code to get the browser running on a new platform.
As for all your comments about Gecko's embeddability, I'm not even going to give them a response; they've largely been covered already.
> Loading my profile on Twitter leads Presto to use more memory than Firefox. (Though really that's a terrible benchmark, probably want to disable in-memory caching.)
That's not surprising as current Firefox has indeed made improvements. Your argument is disingenuous if you aren't comparing Opera presto with the equivalent version of Firefox of the same period. Firefox than couldn't even manage 10-20 tabs, without high RAM consumption, whereas Opera Presto could easily handle around 100+.
> Morale only really collapsed after the move to WebKit, nor had there been lay offs for several years prior.
I didn't claim the layoffs started years before they were sold. Opera was a solid company for some time. But many employees were laid off prior to Opera being sold to their current owners, mostly the marketing and support staffs and some developers. Morale was indeed low in the company. And rumours were already swirling around in Opera forums and popular Opera fan blogs that Presto would be dumped. (And it was dumped ultimately for Blink, a fork of webkit, created in partnership with Google).
Your point about some memory issues with engines, compared to the previous versions, are correct. Despite those issues, Opera Presto was still better than Gecko during the same period.
My point is to compare Apple to Apple - highlighting the weak point of a browser engine, whose development has since been abandoned, by comparing it to Gecko's current modern avatar doesn't make sense, when my argument is that Presto was a better engineered product than other browser engines of its times. Ofcourse I agree that Firefox has come a long way and is far better now. (That's why I shifted to it after Opera died).
> The graph of module dependencies was ... so in many ways it really wasn't modular.
Perhaps so. It is still easier to understand than Firefox's mish-mash of a codebase, because it is smaller and better coded.
> The source code of Opera Presto is out there on the net
I don't suppose it's been open-sourced, has it? It would be great to have an alternative browser engine out there, instead of just three (or two and a half, depending on how you count Blink and Webkit).
No, it was leaked illegally. Opera filed a lot of DMCA complaints with many online Git repository services to get the code removed from them. But you can still find it if you Google hard. I also recall reading that some Russian developers were working on the leaked code and had also released a "newer" version with some patches (Opera presto was really popular in Russia) but I couldn't find it.
There is another little known open source browser project independent of Gecko, webkit and Blink currently being developed but I just can't remember its name, even though I tried compiling it on my system ... damn ... I'll post an update when its name comes to mind.
Opera felt small and fast because it did less and ran websites doing less. If you look at an old site in a modern browser, it's much faster; if you even could run a modern site in an old browser, you'd see just how many optimizations you're taking for granted — not to mention things like high-quality text rendering which fully supports Unicode and complex scripts.
The machines you were likely running Opera on were a lot less powerful though. Doing a bit less on a Pentium IV might be more impressive than rendering a modern website on an i5.
True, but again it was doing much less: we take things like high resolution, full color depth with color management, high-quality text rendering, anti-aliasing & subpixel rendering, etc. for granted.
Back then, good scrolling performance meant moving one page of thumbnails at a time, not continuously scrolling many times more thumbnails of significantly greater resolution.
The better lesson I’d draw from this is that it’s healthy to be skeptical when people say we “need” a huge pile of JavaScript for everything. If you let a modern browser run without layers of heavy code it’s usually easy to get the response times faster than the thresholds where users perceive it as instantaneous.
> Opera felt small and fast because it did less and ran websites doing less.
Let us assume that is true (even though it isn't) - what's Firefox and other browsers excuse for running slower than Opera on these same sites, during the same period?
Opera presto supported a lot of the features of HTML5(1). So it didn't necessarily "do less" than the others.
And second, if you really want to compare Opera presto with other browsers, you should do it with the versions of the competing browsers that were available then. (I still remember how people complained about Firefox consuming a a lot of RAM when you opened more than 10 tabs, where as Opera could easily handle 100+ tabs(2) without any complaints.)
Even otherwise, if you test it out yourself today by downloading an Opera presto version (version 12.15 / 12.16) you will find how usable it still is on 70-80% of the websites today, even after not being developed for years now).
Nobody is arguing that Opera wasn’t fast, only that there’s been more than a decade of massive improvements which is not reflected in your comments. I used, and paid for, Opera but its golden age is past.
> ... only that there’s been more than a decade of massive improvements which is not reflected in your comments ...
Oh ok. I see the confusion - I was speaking specifically about Opera (Presto engine) versions. Not the current Opera Chromium clone. And the point I was trying to make is that it was a much, much better product than its competitors. And if it had survived, with the original team still working on it, it still would be better than Firefox / Gecko and Chrome / Blink of today.
I was also talking about Presto. It was good at the time in some areas but that’s like the guys who say their classic car is unmatched ignoring that everything on the lot is safer, lower maintenance, and less polluting.
People switched because Presto wasn’t perfect (I had plenty of big reports) and it was falling behind with each release as Mozilla and Google really hit their strides.
> I was also talking about Presto. It was good at the time in some areas but that’s like the guys who say their classic car is unmatched ...
I was talking about Presto in comparison with browser engines of its period. As for people switching to others because "Presto wasn't perfect" - obviously, even an Opera fan like me did too, because the project was abandoned and started showing its age! My point was that it was a much better engineered project than its competitor of the same period and if its development had continued with the same philosophy, it would still be one.
When I say Opera Presto was better, I do mean better than Gecko, Trident, Webkit of that period, not better than the current modern versions of these browser engine.
I second your opinion. I used to give Firefox a tremendous amount of leeway because its support for extensions and customization set it head and shoulders above competing browsers. Now that they've thrown away that advantage I find myself using alternatives more and more.
> Our next major challenge: We are dealing with 21 million lines of code.
I think I just fail to understand the true complexity of a browser, but how is Firefox 21 million lines of code? How can a browser be 21 million lines of code? That just seems so large for what a browser does.
A browser lays out text and graphics (for any script in any locale), does GPU accelerated 3D rendering, handles network communication, plays video, plays audio, provides accessibility, parses a bunch of languages, compiles a couple of languages to machine code run in a security sandbox (and has a separate optimizing compiler), provides database storage, implements a plugin system, provides support for 25 years of legacy standards. And a bunch of more things.
It also reimplements all of those things itself from scratch because their priority is on cross-platform parity, not efficiency.
Every time I see someone working on a FF bug I’m cc’d on, I marvel at how many files they have to touch to get anything done. One key binding missing, because they’re not using the system text field? Hundreds of lines of diffs, spread across a dozen source files.
I think you’re underestimating what browsers do. They have an incredibly performant and highly-tuned VM, an extremely flexible and powerful layout engine, a comprehensive set of media players, and that’s not even talking about networking, security, and UI.
This seems to scream "separate me!". Why is it acceptable to put all this responsibility into one giant ugly ball? We desperately need separate layout engines, parsers, renderers, etc. Assemble-your-own-browser.
Because the entire advantage of the web from the perspective of the end user (as opposed to desktop applications) is that you can expect it to work the same everywhere. If everything were separated, it wouldn't make a difference, because Chrome and MobileSafari will continue shipping one integrated stack, even if they're forced to open up APIs for modularity.
What tangible advantage would this have? Having competing browsers seems possible, but since end-users wouldn't be choosing individual browser components anyway, it wouldn't actually improve anything.
It sounds like a good idea to be implemented by a technical user, and a solution looking for a problem to every other kind of user. I thought dependency hell was bad but this sounds like a further circle of such hell. I like that I can tell a user to just update their browser and OS and be confident that most users will handle the operation thereof. I know how to tell a non-technical user how to update their web browser in words they can understand. I’m going to have to write a new script for how to explain the scope of the limitations of using a web browser as a compiled application versus the proposed modular architecture just so they can tell me they don’t want or need that.
Choice matters. Sometimes you have to make a choice on behalf of your users. I think that’s what the industry as a whole has done here. Nothing is preventing people from rolling their own modular web browser. Maybe things like Beaker Browser and TOR Browser are versions of that same idea but approached from a specific use case.
Thanks for this comment. I think your idea is good but not for the same reasons that a web browser suite is a good idea for most non-technical users.
It doesn't seem that crazy to me. Calling them web browsers is kind of anachronistic at this point. Just the JS engine itself seems like it would be massively complex. It's a VM with a JIT compiler which I can only imagine is quite cumbersome to implement securely
It does effectively. With Gmail at least, there's an option to register Chrome as the mailto handler. Anytime you click on a mailto link anywhere on your computer, it will open Chrome to the compose window in Gmail. And Gmail works offline, so it's not really any different from having a traditional email client built into your browser.
This is something I really deplore about the state of modern software development. Taken collectively, it's mind-boggling the amount of waste there is in terms of memory and CPU (i.e. energy) usage by running a huge portion of consumer software in the browser. We could achieve the same result so much cheaper, with better performance and UX, by putting a serious effort into a set of standards for handling code from an arbitrary source securely.
HTML+ECMAScript keeps the developer at quite a distance from the hardware, and it imposes all kinds of limitations which don't have to exist.
The web is good enough for pure content delivery, but for more advanced interactive applications, the limitations are a huge waste. For instance, I have a computer at home with a 12-core, 24-thread processor, but web applications are basically single-threaded with some very limited support for web workers. I'm also limited to basically one language, which is garbage collected, so performance and memory usage are significantly worse than they could be. And as far as graphics, you're limited to WebGL which is ages behind the state of the art in terms of graphics APIs.
Basically there is a whole universe of tools out there for software development, but if you want to target web you're limited to a handful of poorly performing, hacky options.
For my work, we use several web applications to collaborate. As someone who works on highly optimized user-facing software, it's frustrating to understand how poor these web applications perform given the potential of modern hardware.
The reason we use them is because you can send anyone a link, and they're into the software in one click. There's no reason we couldn't have the same experience for native software, where when you click the link your computer downloads a native binary and runs it in a sandboxed environment against a standardized system API. It would take a lot of careful work and planning, but there's no technical reason it couldn't exist, and it would be so much better for developers and users.
But if it were to run on every platform and processor the binary would have to be written to some VM, which would slow it down a bit. That’s webassembly, which is coming up.
Also, there would have to be some GUI framework that works well across all devices, phone to desktop. That alone would be massive undertaking.
I agree there is no technical reason, but once you consider all limitations and let some time pass in the end you might up with something similar to what we have now. For example you might standardize on a current graphics API, but in a few years: guess what, you have an outdated API like webGL now.
> But if it were to run on every platform and processor the binary would have to be written to some VM
Not necessarily. You could have different binaries for different architectures. All you need is a consistent system interface with a well-specified ABI, and the client would just have to request the binary for their architecture.
> That’s webassembly, which is coming up.
Web assembly still has the limitations of running inside the browser. It's still single-threaded, and also the file size is pretty large compared to a binary.
> Also, there would have to be some GUI framework that works well across all devices, phone to desktop.
If you had a consistent system interface, you'd only have to do it once.
> For example you might standardize on a current graphics API
I mean Vulkan is basically this. And graphics API's are converging not diverging: modern graphics API's are all structured in a very similar way, since they're all just wrappers around the low level functionality of the GPU at this point.
I'm not saying it would be easy, but the reasons we don't have it have more to do with the fact that it would be difficult to get buy-in from OS vendors than it has to do with the technical problems involved. From a technical perspective, we could easily do way better than modern web.
JS is generally very fast because these monolithic VMs have had so much money poured into them that their optimisation process is unparalleled. V8 can sometimes get performance on par with C. "Overhead" is arguable, JS may be garbage in a lot of ways but modern JS is quite efficient.
sometimes is the key word there. It's amazing what kind of performance can be reached with JS given the monumental amount of effort which has gone into optimizing it, but there are structural reasons JS hsa a performance ceiling. JIT compilation can't change the fact that it's a highly dynamic, weakly typed language which is garbage collected. You might be able to find examples where a JIT compiled block of JS code performs comparably to a similar block of C code, but there are design patterns available in languages like C/C++ and Rust which aren't even expressible in JS which allow an extremely high level of optimization using careful memory management techniques.
Also web is basically a single-threaded runtime environment. For the foreseeable future, increased parallelism is the main way we can expect to get increased computing performance, and it's basically not available on the web.
The biggest thing you would probably be sacrificing is development time for every engineer involved. The html/css/js stacks have had unimaginable amounts of manpower invested, more so than any UI stack in history. This has made them much easier to learn and manipulate. Throwing away all of that would be a very hard sell.
I agree there would be an adoption problem for something new. But if there were a viable alternative, and people managed to build killer apps on it might be possible to draw adoption over time as people got to experience the superior performance.
This LOC count is going to be a huge problem in the future, and you'll see it as the bug count climbs. It'll be hard for people to understand how the system works and hard for them to ramp up. You'll see the slow decline if there's ever a point in which their funding is reduced and employees have to be laid off.
{kind=link}
Trying to compile Firefox was already a challenge. That, and each compile took an hour. IIRC, Firefox is built on some esoteric architecture / design pattern that's definitely beyond the scope of design patterns undergraduate students are familiar with.
By the end of the term, no one discovered a 0-day, unsurprising considering half the class didn't even try. There were 90 students in the class, and I ended up being the only person to produce a JS payload that would crash Firefox in one of the newer HTML5 libraries. It's neither a zero-day or exciting or profitable vulnerability though.
Realizing everyone in the class would fail, the professor changed the grade of this project to only account for 30% of the grade. I spent most of my time on this project while disregarding the rest of the busy work for the class. In the end, I got a C grade while my peers who didn't even attempt to tackle this project received higher grades.