Warning: these writings can change your view on the shell language. Now you probably think, as many of us did, that shell is a cute little hack, useful for one-off throwaway stuff, but not really fit for serious work. Afterwards, you will start to see the shell as a glorious, essential element of our civilization, worth of respect and deserving our careful attention. Pipes are an essential programming tool that must be supported by the core language and not by a library construct (as in python).
> Afterwards, you will start to see the shell as a glorious, essential element of our civilization, worth of respect and deserving our careful attention.
Nah.
There should be (probably is) a term for the phenomenon/trope where you can take something that was not carefully designed in the first place (like basically all of Unix) and then down the line you can hyper-analyze the hell out of certain bits of it and wax poetic about the few elegant bits that are inevitably there (even BASIC will work, yes) - while conveniently ignoring the whole is still a steaming pile. Lord knows that's what happened with "Unix" starting in the 90s, and Javascript in the 2000s.
> something that was not carefully designed in the first place (like basically all of Unix)
While I would generally agree that the Unix shell language (of which bash is a superset) and the bash language itself is not the most elegant and well designed things in the world - and that it should be used in a limited way and there are better options in most cases - I do have to say that to me at least it is significantly better than PowerShell which, while it clearly had a lot of design work put into it, seemed to have been designed by someone who has never used a shell or a terminal and maybe only had some limited interaction with a computer of any kind.
Unix: a shift from the pragmatic view that Unix is 80% nice and "worse is better" to a mystic longing for a time when everything was a file and you could compose things from well understood utilities which did one thing. (Which never existed, that dream was Plan9.)
Javascript: the idea that it's actually a nice language anyone should use except under duress.
I've written many, many shell scripts, back as a sysadmin, and because I wanted it to not be a cute little hack. I know all the tricks described on the blogpost and many more. I have an intimate understanding how the quoting works and how we can work around its limitations.
Let me tell you: shell is sort of a local optimum for one-off throwaway stuff, because it makes commonly needed thing accessible with so few keystrokes. But also, shell is a cute little hack. It's literally impossible to write robust programs in it.
It's literally impossible to write robust programs in it.
Right, that's the whole point of Oil! You can make those programs robust without rewriting them entirely. Run them with Oil, and then flip a few switches to enable stricter behavior.
But there are a dozen more. The key point is that bash's codebase has kind of "topped out" in the sense that it's hard to add anything without breaking something else. On the other hand, the Oil interpreter is reasonable, small, and you can add features to it, and fix things.
Anyone who knows about programming languages might be able to read the type definitions in osh/runtime.asdl (and frontend/syntax.asdl) and learn a lot about how shell works.
That misses the whole point - that there shouldn't be any difference.
Shells already behave like programming languages just bad ones.
The reason people use them over a "bona fide" programming language is their command line editing, easy process handling, first class support for job control, access to environment and pipes.
One could use a non-shell programming language, but then he'd have a much harder time with all the later - even though he'll have a much better time with abstraction, programming correctness, error handling, first class data structures, and so on.
So we're in an either (shell+easy command line use+process handling/job control/pipes etc) or (programming language+better syntax-cohesion-correctness-better error handling-libraries-first class data structures-and on on).
There are things in IT that can't be combined because one is a tradeoff to the other. This is not such a case - this is just a historical accident: crappy language features in shells and crappy job control features in programming languages.
But there's no reason one can't have all those latter things in a proper programming language.
>Let me tell you: shell is sort of a local optimum for one-off throwaway stuff, because it makes commonly needed thing accessible with so few keystrokes. But also, shell is a cute little hack. It's literally impossible to write robust programs in it.
But there's no essential reason why it has to be this way.
It's just that the first UNIX shell was a minimal and ad-hoc design, and the rest just accumulated BS craft in an unguided and even more ad-hoc way, without any vision or cohesion. Then POSIX came, and we got stuck with those (or hardly better versions, like zsh).
If by shell we define it as a programming language that has: first class support for job management, first class support for pipes, handy primitives for one-liners and file/text/job processing then there's absolutely no reason why such a language can't be much better than what we have.
For example, just off the top of my head:
- proper argument parsing (not just the BS hacks e.g. Bash allows)
- proper vectors and maps (not the primitive hacks bash allows - "shift" is so idiotic...)
- proper syntax (consider the BS [ vs [[ dichotomy in bash, or the millions of edge cases)
- proper exception/error handling (no just the primitive "traps" or checking $?)
- better expandability (e.g. consider the crappy kludge that autocomplete options are set)
- proper functions (not the arg1=$1 BS - shell could e.g. automatically assign to named arguments)
- namespacing
- packages, libraries. How many times people write and rewrite the same BS shell functions or primitives? "source" doesn't cut it.
> It's literally impossible to write robust programs in it.
It's hard, verbose, and littered with snafus, but it is also a solved problem.
POSIX and C shell are a source of quoting difficulties. The semantics of Plan9's rc and now fish are much more straightforward. I think that shells could be a robust technology if we were less fixated on faithfully capturing familiar idioms.
> It's literally impossible to write robust programs in it.
This is why I never write shell scripts more than about 4 lines long or with any control flow statements in it -- I use Python for that. The Python might be a bit longer, but at least I'll understand it when I come back to it 6 months later.
I would _like_ to use Python (2) for that, but it's EOL/effectively EOL, and Python 3 made the _wrong_ call with respect to Unicode support.
Source code is Unicode? Great.
Forcing _everything_ to have an Encoding when the surrounding world isn't an academically clean environment? Nope, this means Unicode Enforcement and Error Handling in what should be simple programs.
I don't mind have __optional__ libraries for handling Encoding conversions, corrections, and errors... but if I'm working with a legacy filesystem, human input, or anything else, the only basic language support I want or need is transparency of bits/bytes. Let a programmer decide if or where things are validated and what to do about handling invalid input at that moment; do not force the issue upon them.
(author here) Yes, that is exactly why I wanted to provide an upgrade path from Python 2 to Oil (reusing a portion of its CPython). But I mentioned in this post that I'm explicitly cutting it out for reasons of engineering effort.
But yeah I still think that idea has merit... Somewhere on my blog I made the observation that Python 3 and Perl 6 are both worse than their predecessors for the shell scripting domain. They're better languages in general, but worse for that domain -- which is still important and getting bigger along with the rest of computing, IMO.
I think Oil would be useful in any case, but both Python 3 and Perl 6 opened up that gap in the design space even wider. I mean the string is the CORE TYPE of such programs, so it's important that it be logically applicable to the problem.
Basically the same story, although I questioned their decision of not embedding the Python 2 interpreter instead. I think the only reason not to do that is "memes".
Please note that Perl 6 has been renamed to Raku (https://raku.org using the #rakulang tag on social media).
With regards to being better / worse in the shell scripting domain, I would say that currently performance wise, Perl is better for shell scripting. But development of shell script-wise, I think Raku has superior handling of command line parameters built in: https://docs.raku.org/language/create-cli
I agree; at Satellogic we had on-orbit error-handling problems due to Python 3's string encoding, where coercing binary data into a Unicode string caused an exception in our exception handler.
Python did eventually acquire a sensible (lossless, errorless) way to convert back and forth between binary and Unicode — UTF-8B, known as surrogateescape, described in PEP 383. Unfortunately, it isn't the default everywhere. PEP 540 makes it default in some cases.
This is the reason Oil is written in its own private fork of Python 2 instead of in Python 3.
Yes those kinds of errors are extremely common... In fact 2 days ago I was visiting a well-known company in SF, and someone mentioned the reason for an aborted Python 3 rollout:
a database contained utf-16 surrogate pairs mis-encoded in utf-8.
To me this is the same problem I had with HTML and DOM mentioned on the other thread (which I will reply to!).
The analogy is
HTML files : DOM :: string data :: Python strings.
I've long had a rant about "models/abstraction vs. reality", which is basically: Reality always wins :) The DOM is an overabstraction of HTML to the point of causing bugs and performance degradation; ditto for Python strings and "real world" textual data. I'd rather solve "honest problems" than self-inflicted problems caused by the wrong abstraction.
A lot of software is basically "undoing" problems caused by other software, not addressing something in the application domain. PEP 383 and 540 seem to be clear instances of that. (And note that I said Python is an amazing achievement in the appendix of this post, which is simultaneously true :) )
> at Satellogic we had on-orbit error-handling problems due to Python 3's string encoding, where coercing binary data into a Unicode string caused an exception in our exception handler.
Woah. If you're using a dynamic programming language for mission-critical software and your tests don't properly cover "coercing binary data into a Unicode string", then your problems run way deeper than Python 2 vs 3.
This isn't restricted to on-orbit software. Your GSE ("ground support equipment", for those not in the industry) also shouldn't have that kind of quality problems.
The problem, as I said, happened inside an exception handler; if we had written tests for that error case, they might have passed if it had thrown a UnicodeDecodeError instead of an IOError or whatever it actually was throwing.
In defense of Satellogic, it never would have gotten off the ground using traditional risk-minimizing aerospace engineering practices. And it's arguable whether the software in question was "mission-critical" — the mission did continue, after all. My efforts to raise the bar on software, process, and documentation quality were not appreciated.
> The problem, as I said, happened inside an exception handler;
Ah, I missed that bit. Still, that sounds to me like a problem with Python's attitude in particular, and with the attitude of many (not all) dynamic programming languages in general, and not so much with a problem of Python 2 vs 3.
> In defense of Satellogic, it never would have gotten off the ground using traditional risk-minimizing aerospace engineering practices.
Having worked for several years in the traditional space industry: Yes, I totally get what you're saying. In fact, the paperwork-heavy quality assurance we have to satisfy, which is more concerned with formalities than with actual hardware/software quality, probably would have missed that case as well.
> In fact, the paperwork-heavy quality assurance we have to satisfy, which is more concerned with formalities than with actual hardware/software quality, probably would have missed that case as well.
Do you have testing coverage metrics for exception handling? In my experience outside Satellogic, that's one of the places testing usually misses, especially in languages with Python's attitude, which I agree is not well suited to on-orbit code.
> Do you have testing coverage metrics for exception handling?
I have not personally come into contact with software PA/QA requirements, only with those for FPGA designs (VHDL in particular). In my largest project, I had to meet 100% statement coverage, with documented justifications for any uncovered lines. Typically, in such an environment, exceptions are a no-go for flight software.
Yeah, that makes a lot of sense to me. Clearly Python is not an option for such an environment; adding two small integers can raise MemoryError if it doesn't have space to allocate for the resulting integer object.
There are several notes on "failure-free programming" in Dercuano; maybe you'd be interested. Essentially I came to the conclusion that although purely local restrictions (like not allocating memory or raising exceptions) can be helpful, I don't know how to structure a program so that all of the desired safety properties can be checked locally, except for very simple programs. Let me know what you think if you do check it out; I'd be interested in your opinion.
All the standard libraries need to use it too. golang gets this part right.
In golang strings are immutable sequences of bytes (which can be concatenated) or have 'slices' taken from within them (I believe addressed to a rune; which IIRC is a complete UTF-8 sequence). Standard libraries typically operate with bytes[] for low level operations (file I/O) but strings and bytes can be coerced between each other with ease, and notably many objects (such as a File https://golang.org/pkg/os/#File.Write ) have methods for interacting with bytes[] and strings.
There's a core library specifically for low level Unicode operations and external libraries for more complex tasks.
Go gets this very wrong, because you can still index strings as arrays - and you get bytes back, which 99% of the time is not what you want. But which also happens to "just work" on common ASCII inputs, so you get code floating around that is broken without its authors' knowledge.
(This, coincidentally, was also the problem in Python 2, and why Python 3 breaking the world was necessary, if inconvenient for some.)
At this point, the only sensible design for strings is as fully encapsulated, opaque values that are emphatically not arrays of anything. If you want to index them, you should be specifically saying what you want - nth byte, nth codepoint, nth grapheme etc. If you want content as an array of bytes in a particular encoding, then you should ask for that specifically. Internally, yeah, it should use UTF-8, because it makes the most sense - but that's just an implementation detail.
So far, the only language I know that got this right is Swift.
Rust also gets this right: Every string and every string slice is guaranteed to be a valid UTF-8 sequence. If you slice a string at invalid UTF-8 boundaries, then – depending on the operation – the thread either panics, or None is returned.
I agree with your stated goals, but I'm less convinced Go gets this totally wrong. It has the nice property that a string is a string is a string -- a slice of bytes. The only exception is raw strings which as part of source code are defined to be UTF-8.
So, while there's a tradeoff in elegance I do think it's logically very simple. I do think the Rust approach for example is more "correct", but it's also tedious to work with and I think the ergonomics matter (can't speak for swift).
(not putting in a code block given the above and mobile...)
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
var x, y, z string;
x = "abc";
y = string([]byte{0x65, 0xCC, 0x81}) // 'e' + 0x0301 ( 0(011 00)(00 0001)) = "é";
z = "世界";
fmt.Printf("x = %s\n%d vs %d\n\ny = %s\n%d vs %d\n\nz = %s\n%d vs %d\n\n",
x, len(x), utf8.RuneCountInString(x),
y, len(y), utf8.RuneCountInString(y),
z, len(z), utf8.RuneCountInString(y));
for k, v := range y {
// iterates as runes, not string slices
//fmt.Printf("s %d\t%s\t%v\t%s\n", k, utf8.RuneCountInString(v), utf8.ValidString(v), v);
fmt.Printf("s>>r %d\t%d\t%v\t%c\n", k, utf8.RuneLen(v), utf8.ValidRune(v), v);
}
for k, v := range []byte(y) {
// iterates as byte units, not runes
fmt.Printf("[]b>>b %d\t%v\t%v\t%08X\n", k, utf8.FullRune([]byte{v}), utf8.RuneStart(v), v);
}
}
It seems like you want to do string-like standard library operations on byte arrays. Python 3 is clear here. You can do string stuff with strings only. If you want to do string stuff, you must decode the bytes.
The world is not only about English and ASCII.
People who want these shortcuts usually don't understand what problems Unicode and character encodings solve in general. And that's exactly what produces software that won't allow me to properly enter my Hungarian name as it is, with diacritics.
It's utterly inexcusable and lazy and stems from an annoying sense of Anglo superiority.
Not really, REPLs (all the way back to the first Lisp environments) are much more than most shells born on UNIX.
Even the best ones like Fishshell, are somehow pale to the scripting environment from Lisp Machines/Interlisp-D, Smalltalk transcript, XDE and Oberon UI scripting.
Function composition, interoperability with the OS APIs, inline display of graphics and data-structures, and just-in-time debugging.
We get there by not placing UNIX in a pedestal, being open minded and appreciate the dedication of several people that keep doing the thankless work to digitize the history of computing.
XDE was the developer environment for the Mesa programming language on Xerox Alto.
This feels great until your program reaches some complexity threshold and you start hitting core limitation of the shell execution model. Then you have to use high-numbered file descriptors, named temporary files, PIPESTATUS, etc... - and your neat programming model becomes ugly and full of hacks.
Sometimes shell is really the best even for complex stuff - for the example in initrd or during machine provisioning - but in most cases, having any sort of non-trivial flow control in shell is a bad idea.
> any sort of non-trivial flow control in shell is a bad idea.
It is often a bad idea in other programming languages also. Yet, some complex control flow constructs are straigthforward in shell but very difficult in other languages. How do you
ls *.jpg | grep 2019 | while read x ; do
echo convert ... $x album/$x
done | xargs -L 1 -P 32
Wow, there are 7 ways this can easily fail, and the script might not even notice.
How do you write in a normal language? With roughly 3 times the amount of keystrokes, but in a much more robust way. And if something fails, you will actually get a Python exception.
Yes exactly, see my sibling response. This is a perfect use case for the "xargs $0 dispatch" pattern I mentioned, and maybe I will use it in that blog post.
Your example does have some quoting problems which is understandable / common, but in Oil the obvious way should be the right way. That's not true in shell!
The only difficult part here is xargs parallel invocation. If you do this often, you may want to find/make the library for it. But even with just default python install, it is pretty straightforward:
files = [f for f in glob("*.jpg") if "2019" in f]
commands = ["convert ... {} album/{}".format(f) for f in files]
subprocess.run("xargs -L 1 -P 32".split(), input=os.fsencode("\n".join(commands)))
Note that this code, as well as original shell version, breaks if the filenames contains spaces or quotes; this is trivial to fix in python, but hard to fix in bash.
for f in ./*2019*.jpg ; do
convert "$f" album/"$f" # just don't use xargs
done
Note the prepended ./ which is necessary if you want to protect against filenames that look like command line switches (a file named "-rf" can be pretty dangerous)
If you wanted to use xargs and still make it perfectly safe with regards to spaces and quoting, you could use a GNU extension:
You can't write ASCII NUL characters from portable shell, that's why this task cannot be done correctly (for all possible filenames) from shell. You need to use tools like find(1)
So, no, it's not easy, at least not if you want to handle all cases without wreaking havoc.
Practically speaking, you can write NUL from shell because bash is everywhere, busybox ash emulates a lot of bash, etc.
However I won't claim it's pretty or easy for people to use, so the point of Oil is basically to clean up patterns like this, e.g. find -print0 | xargs -0 and more.
This post uses a related problem and solution as design motivation for Oil:
How to Quickly and Correctly Generate a Git Log in HTML
> Note that this code, as well as original shell version, breaks if the filenames contains spaces or quotes; this is trivial to fix in python, but hard to fix in bash.
Your code sort of cheats, since it is calling xargs to do the parallelism. Also, it is missing the imports. The equivalent pure python version will be probably still more complicated (regardless of it working for general filenames or not).
> Your code sort of cheats, since it is calling xargs to do the parallelism.
This is the whole point though -- you can still invoke external binaries in python!
For example, if you need to sort 100GB file, direct Python approach will likely OOM... while /usr/bin/sort will work just fine. I have seen people use this as an excuse ("I cannot use python's sort(), so I will just rewrite everything in shell") -- but for a complex script, it is almost always better to use Python as much as possible.
Thank you for the kind words! And I mentioned in a sibling comment, I regret not finishing that series...
My plan was to "finish" Oil and then publish them. So people would not only learn something but also have something to try.
I didn't realize it would take this long :) But we've made steady progress the whole time.
---
The other posts in this series are about xargs, the "$0 dispatch pattern", and the "run.sh" pattern.
They are very practical, though again more abstract than you might see in most shell scripts. I won't argue if someone says the syntax is ugly -- the point is as you say, that the structure of the programs valuable and not possible or not easy/idiomatic in other languages.
For example the way I run comparative benchmarks is to print a list of tasks to stdout, and then have a loop that consumes it (usually with xargs). You can control parallelism that way (with xargs -P), and you can filter the tasks, or you can even distribute them to other machines. I currently run benchmarks on two machines.
So yes hopefully I can make these patterns a little prettier in Oil because they are very worthwhile. For example "xargs" is really like "each" in JavaScript, but it can be serial or parallel.
If Oil reaches it goals, then one thing I'd like to do is run a lot of performance and correctness tools (dynamic and static analysis) on open source software, and report them on my site. I think there's a lot of room for this kind of knowledge to make open source better. There are knowledge bottlenecks where people don't understand how code works, so they write a lot of new code, which is better in some ways but worse in others.
Related to that is that I want to write a post about benchmarks/uftrace.sh and several other tools I used to speed up Oil:
But yes I will prioritize finishing the series since you reminded me of it :) I managed to get 7 posts this month but then I went back to coding. Thanks for the encouragement!
"So the biggest change is that Oil will be based on strings (and arrays of strings) like shell"
I would advise the author have a look at the internals of Tcl, not because you should copy all the sophisticated features immediately, but because it demonstrates a way to have both "everything is a string" and "advanced data structures" in a relatively principled manner. You don't have to start out with all the optimizations from day one but I always find it helpful to have a look down the road in cases like this, and make sure that if this sort of thing interests you that you don't accidentally make it impossible later.
(author here) Yeah I appreciate a lot of things about Tcl, which is basically Lisp + shell (I think Ousterhout even said that?) I read most of the thick book about it even though I don't regularly program in Tcl.
A bunch of people have brough up Tcl, and as noted here [1], Oil looks superficially like it because it has proc and set keywords.
The biggest difference is that Oil isn't homoiconic in the sense that Tcl is. I believe that implies a lot of dynamic parsing which I'm staying away from [2].
And of course Oil is a compatible Unix shell, which imposes a bunch of constraints. Namely the 'proc' is "isomorphic" to a process -- it takes argv and returns an exit code, and it can be transparently put in pipelines. I wrote 3 years ago about this powerful form of composition [3] and I wish I had finished that :-/
You can get Tcl-level homoiconicity with fexprs, Lisp-style macros, Smalltalk-like lightweight block syntax, or Algol-style call-by-name lazy evaluation rather than strings. Lisp moved from fexprs to macros in the 1970s for reasons that may not apply to Oil. You may also be interested in my comments in https://news.ycombinator.com/item?id=22150740 about typing; I regret having taken so long to respond to your thoughtful comments.
Thanks for pointing them out. And no problem, I realize I wrote a big mass of text :) I will try to respond without going a big tangent!
I also invite anyone interested in language design to come chat on Zulip [1] or send me mail. I had called for participation in the Oil language design [2]. I got a bit of feedback but am interested in more, especially from people who have used many languages.
I view shell as kind of the lowest common denominator "bridge" language. e.g. Python programmers use it, OCaml programmers, C/C++ programmers, etc. but a lot of them don't view it as a language! I view that as a big missed opportunities, for reasons I will hopefully explain in the upcoming blog posts -- e.g. the one about uftrace I mentioned in this thread. e.g. Shell Helps You Write Better Native Code
> But I realize that, in the best case, this will take decades. That's OK ...
Wow. I’ve never really thought about how much time and dedication is put into the languages and tools I’m surrounded by. Thank you for what you’re doing, Andy. You’re honestly an inspiration!
Yes, take a look at the appendix for my realization about Python from 1991. The comments about Clang and LLVM are also related -- with the Linux kernel and distros and distros in the early stages of migration 15-20 years later.
But to clarify, I don't want implementing Oil to take decades :) I was talking more about adoption. Mass adoption will take decades, just as bash actually wasn't that popular until 15 years ago, but it's also 30 years old. The adoption curve is very long just as it was for Linux, Python, sqlite, etc.
A major reason I write the blog is so that if I decide to stop working on Oil, future maintainers can pick up the knowledge. But I'm also saying it will be embarrassing if I quit before Oil replaces bash for my own use cases. Replacing bash for other people will take a lot longer.
I thought I was the last person who learned Python in 2003, but no, it turns out that several million people were still yet to hear of it :)
Not the author, but I've used a lot of Unix and Powershell.
Powershell is all objects which has some significant consequences. The first is that many operations will only be reasonably performant on tiny files. If you just want to grep a string from a medium sized file (Ex: 80 MB) and then sort it, the Powershell command is trivial, but can take minutes to run as every row becomes an object. To get around this, you have to generally write a fair amount of straight .NET code like C# which defeats the purpose of using Powershell in the first place. The second consequence is convenience. Because everything is an object, when you get files, you have so much metadata at your fingertips. This is definitely harder in shell and even a pain for me in Python.
Edit: on one of my older accounts I complained about the impossibility of parsing files with reasonable speed in Powershell despite me testing 5 different methods. Someone replied back with another few methods I've never seen before that were much faster, but still slow. If anyone can find that comment I'd be much obliged (hopefully the former poster remembers and can look back).
I really really want Powershell to be more performant with text work as I do a lot of that and everything else in Powershell is so darned convenient. As it stands, it is more of an IT Admin language and possibly DevOps more than anything.
[edit: I didn't mention `get-content -ReadCount 1000` but it might be good for streaming-reading a large file if you don't want it all at once. It outputs blocks of N lines at a time as a single string, which you have to split on newlines by yourself.]
There is a related issue in the PowerShell GitHub asking to standardise on a "just give me the data, no metadata" option which would be get-content returning plain strings: https://github.com/PowerShell/PowerShell/issues/7855
I spent 1/2 hour looking for that and failed on two different occasions, so thank you kind internet stranger and better PS user than I. I wish they covered this in "Powershell in Action" instead of just the cmdlets for IO.
I honestly can't believe that they don't have a cmdlet or cmdlet flag for get-content that does as you say and just returns plain text. I don't want metadata anyway when I'm not messing with files and directories.
Do you know of https://hn.algolia.com (change dropdown to search comments not stories). Way better than a Google search. Although it helps that I knew "if it was my comment about faster file reading, I know what was probably in it" to search for "powershell ${C:\" and there it was.
I didn't...I accidently log myself out of my account every now and then and have to make a new one. The only problem is I can't remember all of them :)
Since a few people have asked, I might write a FAQ about this, but the short answer is that I view PowerShell as one of the projects called "shell" that is least like a Unix shell.
Part of that is on purpose, because it's designed for Windows. And what works on Windows is very different than what works on Unix.
Windows is based around COM objects and binary formats like the registry, while Unix is based around text files. That makes the design of an appropriate shell extremely different.
I would say bash, zsh, and fish are pretty close (with the latter concentrating on interactivity), but PowerShell is way out there.
PowerShell also appears to be coupled to the .NET VM and is pretty inefficient. Some links and sharp comments here:
I think if you want a C# like programming language with shell-like syntax, that integrates with Windows, then PowerShell is for you. But most bash users don't want that! As mentioned, shell is used on tons of embedded systems now (usually busybox ash, which is growing towards bash.)
While I don't disagree with most of your points, NuShell's recent popularity seems to suggest that there is a demand for shells that operate on structured data – even in the Unix world. I dislike much of PowerShell's UX (syntax, tooling, etc.) but I love that aspect of it.
I see from the blog post that you've decided that Oil will operate on strings instead – I'm really looking forward to the blog posts explaining that, I'm sure it's not a decision you took lightly.
> "I gave up on PowerShell when I found out that the return value of a function is the console output."
The reason its return values are like that, is that the PowerShell developers copied the behaviour from Unix shells. Cat a file in bash, in a function, assign the result of the function call to a variable, the variable contains the "console output". (Although PowerShell has a pipeline output and separate "console" outputs as separate streams, so this reason for giving up makes no sense - the function could write verbose or informational console output and return something else through the pipeline, as the return value. (They aren't console outputs because PowerShell can be run with no console, e.g. remotely or as an automation engine)).
> It’s like they the cargo-culted a bunch of bad design decisions like the -eq operator without understanding that syntax isn’t why people use shell.
It's like they can now have a consistent operator style which doesn't clash with > and >> and < and | and &, and allows non-math operators like -contains and -match and -f string formatting. I've not seen anyone who wants -equ to be == explain what they'd do with -ieq and -ceq (case insensitive forced, and case sensitive) variants. A mess of inconsistent operators would be even worse, and `-` allows tab completion, which is a bonus.
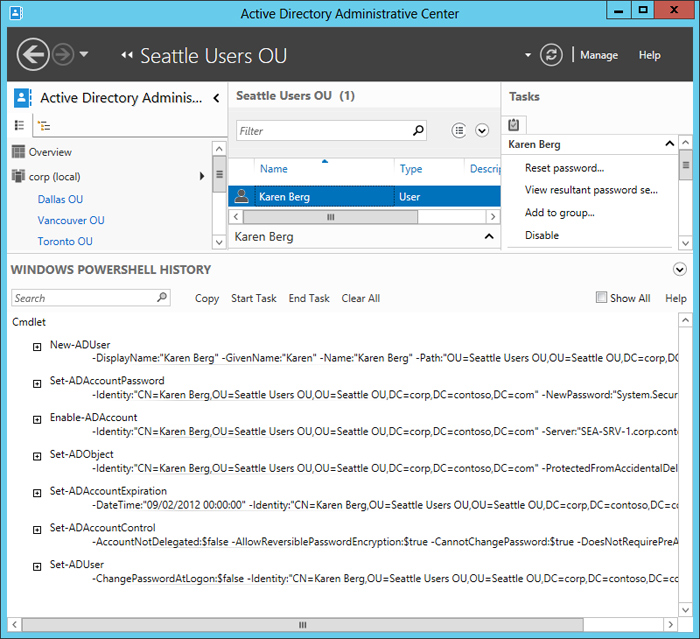
What none of the comments there address is PowerShell as an extension language - the Active Directory Administrative Center GUI is built on a PowerShell backend. When you are a point-and-clicky Windows Admin doing things in the GUI, you can show "Windows PowerShell History" pane and that shows you the PowerShell commands to run to do the same thing you just did, because that's what it did internally[1]. Any C# (or other .Net language) can load the PowerShell automation dll and run PowerShell commands through it. Any Enterprise C# developers could expose the behaviour of their tools to PowerShell scripting by making a simple C# class with a few attributes. The (perfectly valid) complaints about exit codes and piping binary data from .exe to .exe slightly miss the mountain for obsessing over the pebbles. What PowerShell is to a Windows ecosystem, is like Linux people missing what Remote Desktop is by saying "just use VNC", or what Active Directory is by saying "just use Kerberos and an LDAP directory". It's not just the top three bullet points of what it does, it's how it connects into Windows world.
[1] https://biztechmagazine.com/sites/default/files/tiny-uploads... - random google result, but imagine you're a 20 year Windows admin dragging yourself towards scripting, and on one side Linux users are mocking you, and on the other side Microsoft is giving you human-friendly tools you can click through and then copy the script code out for next time. Imagine you're a competent scripter and just don't know your way around which cmdlets do what, and what parameters they can take.
Mostly off topic, but I've never understood why shells are designed to have this weird dual use case of both being easy to type into a command prompt, and being easy to write 40+ line scripts in. Why does that need to have the exact same syntax? This is the root cause of why bash (and batch and etc etc etc) are so terrible to script in (and why powershell is so terrible to type into a terminal). This weird shit like [ being a command, and having to think long and hard about exactly when variables are replaced and when globs are executed and how errors happen.. It's just pretty pointless.
Like, if you write a script using Python or Ruby or Perl or whatever, there's easy ways to call into the shell. Often it's even built-in, like using backticks `echo like this`. These languages aren't designed for shell scripting but even they are often easier and cleaner than a bash script. It could be much better thoughk I bet.
I'd love to have a language that is easy and familiar to type into a terminal (and thus, sufficiently bash-like probably), while being significantly easier to write scripts in. You could require the script to have a bit more syntax, a bit more structure, but essentially have the same semantics as what you'd type on the command line, and you'd have the best of both worlds. If well designed, it'd still "feel" like the same thing (much like how all JS programmers immediately grokked Coffeescript when it came out, because it really was just JS); everything you'd learn on the command line, you'd be able to apply in a script and vice versa. The script would just require more structure and thus provide more comfort (good error messages, editor support, etc).
For example, globbing. The idea that the shell expands ".foo" into a list of files, before evaluating the command, is handy, but it's also an enormous footgun. What if on the terminal it would do that, but when scripting, you'd be required to write `glob(".foo")` or else it'd error out? THat would force you to clearly control when the expansion happens, it would let you assign it to a variable in a readable way etc. Imagine similar stuff for argument lists, escaping, variable substitution, etc - all the magic available on terminal, but contained in the script.
(author here) Your first and third paragraph seem to be in conflict? I have heard the feedback that an interactive shell and a programming language should be different, which I disagree with.
(For one, shell is already used as a programming language, so the ship has sailed. Also I use shell in the Lisp tradition: build your program up with a REPL.)
But yes Oil is designed to "give the best of both worlds" as you say in the third paragraph.
This recent post will probably give you the best idea of it:
echo $mystr # silently splits
echo "mystr" # no split
In Oil, it's:
echo $mystr # no split by default
echo @split(mystr) # opt in explicitly
This is enabled with options so existing shell scripts work. Also @split isn't really idiomatic since you would likely use arrays, but it could be useful for porting.
I've also thought of adding a more explicit alternative for glob, but I actually like the shorter syntax here:
echo *.py
echo @glob('*.py') # not implemented but is consistent
But I'm probably going to implement this safety feature
Still, echo is not good for these examples as for it the split doesn't matter and can't be detected, whereas for other commands (or even calls of functions) it indeed can matter.
This example, I think, illustrates the differences between quoted and unquoted use of $name (as present in the current shells) better (to those who aren't familiar with the nuances of shells):
> I've never understood why shells are designed to have this weird dual use case of both being easy to type into a command prompt, and being easy to write 40+ line scripts in.
It was probably less about that explicitly being considered the optimum design, and more about it being irresistible to save a lot of labor by getting 2 for the price of 1.
Is your complaint about PowerShell the verbosity? Because I love its approach to this: full verbosity is the default (great for scripts), then terminal usage is improved by aliases (ForEach-Object is just %), great autocomplete via psreadline, and automatic parameter shortening: -re and -fo are automatically understood as -Recurse and -Force. Honestly makes every other shell a pain to use now for me.
Also having everything be object based is just...I have no idea how I lived before.
Indeed, I do like scripting languages which are specific. Whatever the language, I do insist that people spell stuff out in a properly readable and standard fashion if writing a script. Aliases and shorthand are fine at a prompt but by damn if I ever see them in a Git commit...
For the record, most other shells seem to understand autocompletion of command parameters these days, so hitting <tab> after --re should complete --recurse.
Tangentially related and not aimed at parent post:
<rant>
My main complaint with Powershell is that it's a mess. I've had to write scripts in Powershell since version 1. We have to work with servers which are still running Windows 2008, and trying to get a Powershell script to run in the same way across 2008 - 2019 is next to impossible. People use Powershell because it's there and it's 'object-oriented' and the resulting maintenance is a terror because it started as a hack and actually fixing that will only make the compatibility story worse (some say this has already happened).
(That option to run it in a versioned compatibility mode? Doesn't seem to work properly in practice. I have a suspicion that the differences in this case were down to some quirk of the console/terminal behaviour on varying Windows versions rather than Powershell itself, but that doesn't cut a lot of ice when there is literally no way to fix such-and-such-a-system in a way which works across all relevant machines without, you know, replacing 10 megabytes of PS with something else entirely. Unix shells tend not to have this problem because the integration points tend to just be STDIN, STDOUT and STDERR, and the shell does very little to mangle them.)
If you write something for POSIX shell (no, not Bash) then it'll basically work on pretty much any Unix from the last few decades. No guarantees regarding the other things you invoke from it, but the shell itself is fairly minimal and consistent. If it's confining, use a more powerful language; you're probably outside its use case.
My other complaint is that I find the object-oriented nature of Powershell to be nothing but a bloody nuisance. I can see how it might be useful sometimes (when wandering around at the prompt it's OK for discoverability) but trying to debug any nontrivial script is a fucking nightmare. 80% of any script ends up just being sanity checks producing useful error messages, because the errors provided by PS itself are rarely useful and usually misleading.
(Actually that's inaccurate. It's more common that there are no sanity checks whatsoever, and the output of the script has no correlation with its purpose whatsoever because one function called early on yielded two values instead of one, so a variable was an array when the rest of the script assumed it was a scalar. The rest of the script then blithely continued on as if nothing was wrong, because some combination of properties on the result was missing/null (because it's an array, not a single object). The POSIX shell behaviour in such cases is usually to pass two paths instead of one to a command at some stage, which might cause an interesting error message, kill the script (`set -e` is your friend), or erase your hard disk (any of which may raise a ticket and maybe even get someone to fix the script).)
Object types are great with statically-typed compiled languages (because your compiler/IDE will usually yell at your mistakes) and they're fine with any project which has a proper build process (because your test suite should yell at your mistakes) but for standalone scripts they're a spectacular example of a foot-seeking tactical nuke launcher.
Net debugging time is less with a text-oriented shell because, when necessary, I can pipe STDIN or a text file to an individual command to see what it does, and what it prints to the terminal is exactly what it gave to my script.
Some or all of the above might be fixed by having someone's personal definition of 'competent programmers', but fewer ways for things to go wrong before the code is actually run would be a good start.
And no, 'Kubernetes' and 'Cloud' are not general solutions. Some of us still work with individual, separate machines in many legally distinct environments which do not permit the 'herd of cattle' and 'staged rollout' approach to server management.
</rant>
I agree that there's some tension between the design of a user interface and the design of a scripting language. But there are also some synergies. Two have been mentioned in the comments: you only have to implement one language interpreter instead of two, and you can build up a program interactively in the REPL before committing it to a file. But a third is that if a program can be invoked from a shell script, it can also be invoked interactively; you don't need to write a separate user interface for every program. And this, in many cases, results in programs being automatable with no extra effort.
I agree that the Bourne Shell in particular is a pretty suboptimal language, and I think we can probably do a lot better. Tcl, es, rc, and PowerShell are four attempts. But it's easy to do worse.
One way to reduce the tension is through interactions that go beyond just typing sequences of characters as if we were using an ASR-33. Filename tab-completion, for example, eliminates most of the uses of `ls` and `cd`, and current programmable completions for bash and zsh are pretty good at listing available completions for things that aren't even filenames. ^X * is a very handy way to do globbing, but you could usefully do it automatically, the way Slack's hated new WYSIWYG UI automatically applies pseudo-Markdown formatting to your messages as you type.
John Cowan suggests that tab-completion should invoke the command with -h or --help to offer candidate completions, and Javier Candeira pointed out that this could be made safe by doing the invocation inside a new container to prevent things like du -h from taking undesired actions.
> I agree that the Bourne Shell in particular is a pretty suboptimal language, and I think we can probably do a lot better. [...] But it's easy to do worse.
I found this startlingly true when having to write nontrivial scripts using the classic Windows cmd.exe language (what's its actual name? Batch?). Bourne Shell's feature set, archaic as it is, is so much more conceptually unified. Exactly as you say, it's sobering to keep in mind that things can be a LOT worse.
not only is this an extremely exciting project that I've been following for what feels like years, but there is such a tremendous richness of stuff only tangentially related to the project that the author has collected as well (one example: https://github.com/oilshell/oil/wiki/ExternalResources). this is clearly such a well-organized, thoughtful endeavor that i have absolute faith that great things will come of it. and he's an excellent writer to boot!
I’m looking forward to the post mentioned towards the end, detailing the cutting of features. I’ve been following the work on this for ages and was looking forward to types data as a way to guard against accidental mistakes, so I’m keen to read the author’s reasoning for switching to strings and arrays of strings. I’m sure there’s a non-trivial reason, his work has always felt careful, measured and well though out to me.
Thanks for the support! Since I may not get to those blog posts in a timely fashion, here's a little outline (and maybe this comment will form the seed of them).
-----
I should be more specific: I am ruling out reusing Python data structures, but I'm not ruling out typed data forever. I'm leaving space for types.
Though given all the work I see in the next year, I don't see a ton of work on them happening. If they happen, they won't not literally be Python types, because they don't seem like a great fit.
Background: A major motivation for using Python was that I wanted JSON in shell. JSON is a "versionless" textual interchange format that's ubiquitous on the web, and I see the web as an extension of Unix.
And there's an obvious correspondence between Python data structures and JSON: dicts, lists, string, float/int, bool.
But those structures are still a "model", and I've had many programming experiences that led me to believe that "bytes on disk/network -> data structure in memory -> bytes" is something of a fallacy.
Or at least it's a coarse, limited model, and not very shell-like. (For the purposes of a blog post I should find a name for that fallacy.)
Another way to say it would be: instead of "dict, list, string" as the model, I think a better model for a shell is "JSON, CSV/TSV, and HTML". In other words: (1) tree shaped data, (2) table shaped data, and (3) documents. [1]
In a more literal and concrete fashion -- NOT really high level abstractions for them. Maybe another slogan could be "Bijections that aren't really bijections".
However I'm not promising to get to this in the next year :)
----
But practically speaking, a lot of programming is spent shuffling between representations. And a lot of the times that's not only inefficient, but also incorrect. It relates strongly to this post:
How to Quickly and Correctly Generate a Git Log in HTML
If you want a buzzword I would say shell is a language where you deal with "concretions" -- that is, you deal with reality rather than abstractions. But a crucial point is that a language can still help you avoid mistakes when programming concretely -- in a large part with principled parsing and quoting/dequoting.
You're not going to "groveling through backslashes and braces one a time" as I call bash's style. The language can provide sharper tools than (JSON -> dict/list -> JSON) or (HTML -> DOM -> HTML).
----
A related thought is that I noticed that procs and funcs don't really compose (procs being shell-like functions, funcs are Python/JS-like functions).
As an analogy: If you've ever written a Python/C extension or a Node/C++ extension, you will also see that those models also compose pretty poorly. Despite the similar syntax, there's a surprising amount of friction semantically (types and GC being two main things).
So adding typed data and Python-like functions was almost tantamount to adding a "separate" language within shell itself. The language loses its coherence when the primitives don't compose. There can be too much shuffling.
-----
So that's a bunch of thoughts that may go into a blog post. Hopefully at least a few parts made sense :)
[1] This reminds me that there's a paper Unifying tables, objects, and documents that I think influenced C# ? I should go re-read it. An important point is that objects are a often a poor fit for representing tables and documents (e.g. ORM problem, awkward DOMs), and tables and documents are more prevalent in the wild!
You can deal with tables and documents "directly", rather than awkwardly manipulating object/tree representations of them. CSS selectors are a way of doing this, i.e. you're not "shuffling objects". A comparison I would draw is 2004-style DOM API vs. jQuery / HTML5 DOM.
I feel like this is hardest part. Bash is installed everywhere, and that ubiquity is one of its greatest assets. Oil can’t replicate that (at least not for a very long time).
And bash is also perfectly OK. It doesnt have all the bells and whistles of, say, zsh- but the things that it does do, it does better (especially autocomplete).
If you want to write scripts, bash is often a pretty good choice for anything involving simple manipulation of text files. If you want something more advanced then bash will let you edit, compile and run programs in the language of your choice.
That said- there may well be a killer usecase for Oil. If so- what is it?
This kind of reminds me of Ammonite: https://ammonite.io/#Ammonite-Shell which definitely for a different audience but kind of a blend of being a Scala repl and somewhat-usage shell with several common commands being implemented as JVM functions with sensible types.
{kind=link}
My mind was blown after reading two posts on Oil's author blog, a few years ago:
* Shell has a Forth-like Quality: https://www.oilshell.org/blog/2017/01/13.html
and
* Pipelines Support Vectorized, Point-Free, and Imperative Style: https://www.oilshell.org/blog/2017/01/15.html
Warning: these writings can change your view on the shell language. Now you probably think, as many of us did, that shell is a cute little hack, useful for one-off throwaway stuff, but not really fit for serious work. Afterwards, you will start to see the shell as a glorious, essential element of our civilization, worth of respect and deserving our careful attention. Pipes are an essential programming tool that must be supported by the core language and not by a library construct (as in python).