At first I thought "What's the big deal? You also remove the query from recommender systems, for example. It's an obvious uninteresting result!".
But then I read the linked article [Nissim 2019] and it all became much clearer with te example in the title: "Man is to Doctor as Woman is to Doctor". If you remove "Doctor" from the results, you'll get "Nurse" instead, not because the dataset/society/... is biased, but because you inserted the bias in your model!
With this small "optimization" (and others presented in the article, such as the "threshold-method" and hand-picked results from the Top-N words), it's trivial to use the anology method to show that any dataset is biased, since you are filtering the unbiased results!
One a side note, I wish articles like this were more popular. I find that it's really easy to use AI techniques "the wrong way" and there's are a lack of articles pointing to common pitfalls (and, to make things worse, there are a lot of blog posts doing things wrong, which only validates bad methodology).
The other reason to not exclude King is that it's pretty likely that Queen is the closest word to King. Then King - X + Y = Queen is just saying that X and Y are close to each other, not an interesting result.
From my perspective (linguistic anthropology), they’re not actually all that close. Most historical “queens” (which have that label applied to them by modern English speakers) were not rulers (and we have a separate term, “queen regnant”, for that) but rather the gender dual to the male “royal consort.” It was only in recent history where you see examples of “equal-opportunity” monarchies that could have either a male or female monarch of equal power, and thus usages of “queen” to denote those monarchs.
Thus—given that we’re defining words based on their centroids of usage in a historical corpus—if a woman is a monarch of a kingdom, “king” is a tighter historical fit to describe her role than “queen” is.
Luckily we don't have to speculate. See a web interface at [1]. Select English from the dropdown and it says that the closest word to king is kings and second is queen, then monarch. And to test my second statement I also tried "red is to king as blue is to ___" and got kings and queen as the top two answers.
Considering the very high dimensionality of the space, it's not as obvious as you think. Consider the noise inherent in the word 2vec negative sampling method as well. Another word could very well end up closer to "king".
I think there are two ways to look at excluding input vectors from the output. You can look at it as cheating/bias, or you could say the method explicitly excludes a specific subcategory of otherwise valid results (i.e., perfectly equivalent analogs, where X:Z == Y:Z... not sure if there is a term of art for that). Which to me seems like a perfectly legitimate limitation on the algorithm, as long as it is explicitly acknowledged and handled.
But I think you are absolutely correct that very few articles explicitly acknowledge and handle these types of common pitfalls. Especially more intro-level articles. Personally, I'd love to read more about effective strategies for ensembling different algorithms to work around some of those pitfalls. For example, the OP points out that Word2Vec underperforms on lexical semantics. I wonder if you could use a different algorithm that performs well on lexical semantics but poorly on other categories as a supplement, with some third algorithm deciding which to use in any given case.
I would also agree with you that it is fine to add additional rules to improve the outcome, but than it shouldn't be made clear in the way the result is presented (as you say, that rarely happens in intro-level tutorials/courses).
Your last point sounds like a cool idea! Using those more in-depth metrics to find weaknesses and see if other, complementary algorithms can fill the gap.
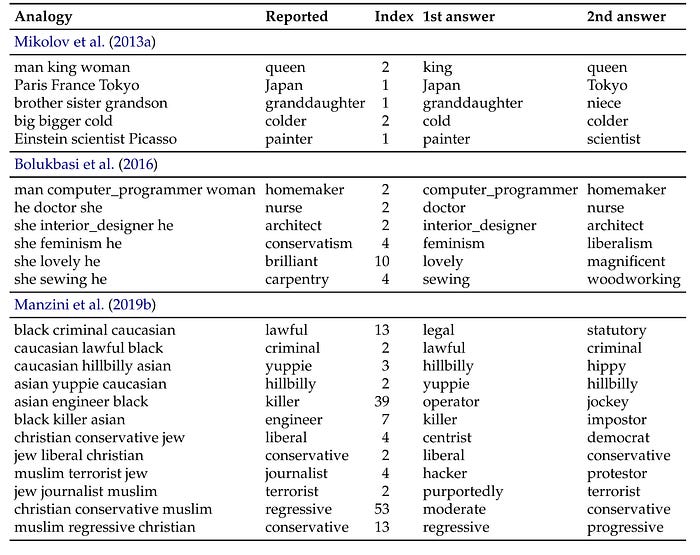
Wow, the Manzini et al. paper is particularly egregious, because they accidentally swapped "caucasian" and "black" in their actual query and still got the sensational word associations they wanted.
You're right they're just reporting their findings, and their stated methodology is to look through the top N words and pick the one they like best. They dug all the way down to the 39th word to find asian:engineer => black:? "killer", when the actual top two associations were "operator" and "jockey" (which also indicate bias, but not the kind the authors wanted). They dug to the 53rd word to find christian:conservative => muslim:? "regressive", when top results were "moderate" and "conservative. It may not be fraudulent, but the methodology is highly motivated, subjective, and introduces more bias than it purports to find.
Yeah I can't disagree with this. I think it's typical to present the highlights of your work though. In this case, the issue seems to be "why do the authors consider 'black:killer' to be a highlight"? It might be racist but it's not academically fraudulent (a strong statement) in my view.
The dataset is biased. Otherwise woman~nurse wouldn't have been the second hit for the query. Had the dataset not been biased it would have been able to produce the analogy "woman is to doctor as man is to nurse". See table 4b where they perform that experiment.
I think it is also important to note that this is an argument over which of two methodologies is best. The answer likely is that it depends on the use case. Researchers are not being accused of using underhanded methods, manipulating data or cheating.
Any finite sampling of any distribution (biased or not) can show bias. A feasible process that doesn't introduce or exagerate bias is the biggest problem when trying to get representative statistics.
And bias can certainly be of different magnitude. A weighted dice can have a bias that shows up after only 10 rolls and another one can only show it's bias after 1000.
> A random distribution is not biased. It really is not a "trick".
A random sample is not a product of a biased sampling method, but it can be (and almost always is) biased, it's just if you take enough such samples, the biases will tend to offset, which is why we say the sampling method isn't biased.
> The dataset is biased. Otherwise woman~nurse wouldn't have been the second hit for the query. Had the dataset not been biased it would have been able to produce the analogy "woman is to doctor as man is to nurse".
I think that this hypothetical example would be evidence of bias. "woman:doctor :: man:nurse" as an analogy only works because of gendered implications of 'doctor' versus 'nurse', so if that were a robust output of the model it would imply that the word2vec found that gender was of great significance in the manifold near 'doctor'. (The analogy would just be applying a negative weight to the gender basis, but that's mathematically fine even if not customary.)
but in analogies, a:b::c::___ (a is to b as c is to what), having d be the same as b is not allowed. Such as, I believe, on a Miller Analogies Test.
In a mathematical context, if you have something like this: 2:0::4: (two is to zero as four is to what?) then acceptable answers might be 2 (rule is: subtract 2), or maybe it could be 1 (take half, subtract one). But it couldn't be zero. (rule can't be "multiply by 0").
I could be wrong but I believe that's how it works.
> but in analogies, a:b::c::___ (a is to b as c is to what), having d be the same as b is not allowed
Particular tests may adopt such a rule, but this doesn't apply to analogies in general. Particularly, consider the case where Alice and Carol and both daughters of Bob: Alice:Bob::Carol:Bob is a perfectly valid analogy; a:b::c:b is commonly phrased along the lines of “a and c are similarly situated with respect to b”.
Just because there's not a "right way" doesn't meant that there aren't a lot "of wrong ways" ;)
Actually, some years ago I bumped into a similar problem to the one discussed, where someone wanted to use NLP to show gender bias in a dataset, and hit one of the common pitfalls that I mention (I hope that I don't start a flamewar by sharing this story):
Here's what they tried to do:
1. Fetch a list of ~800 atendee names from a Portuguese tech conference (it had an official API with user profiles)
2. Download a dataset most common male/female names for newborn babies in Portugal and America for the latest 3 years
3. Train a naive bayes model on the downloaded dataset and use it to classify the antedees into male/female
After doing that, the algorithm returned something like "8 female attendees and 792 male antendees".
I found this particularly strange (considering that I knew more than 8 women that attended on previous years), so I took a peek at the antendee dataset and found that:
- There were some users using a fake name (including one organization account)
- There were certainly more than 8 female antendees, and at least 6 were named "Inês" (female name)
After discussing this with the ones involved, we found the problem!
- The dataset was not being normalized (it was being trained with "Ines" and tested with "Inês")
- The naive bayes[1] implementation used, when faced with a completly new input, outputed the most common class of the training dataset
In the end, the final result was closer to "80 female, 705 male, 15 unknown", which is a much more believable result (closer to the typical distribution of Software Engineer students in Portugal).
Note that the author wasn't trying to deceive anyone, he just tripped on some common pitfalls (forgot to normalize the data and used an off-the-shelf implementation without looking into the details).
[1] There was only one attribute, so implementing this without using a naive bayes library was actually easier and produced the correct results.
For others reading, there are still important biases these models pick up (for a variety of reasons I won't go into). The takeaway here is that some of the evidence you've heard about isn't really evidence, not that the biases aren't there.
The first term may be more accurate than you might think. Elizabeth I of England ruled as Elizabeth Rex where Rex is Latin for "King" and Regina is the female term.
Technically in England Queen is an ambiguous term, queen regnant is the actual ruler, queen dowager is the widow of a king etc. But, again several European an other female rulers used the male term.
Hatshepsut crowned herself Pharaoh and maintained an elaborate legal fiction of maleness, because ya know she was in charge and could do what she wanted.
Hungary had two female kings Mary of the House of Anjou, and Maria Theresa.
Good point!
I would see this rather as yet another argument for why you should simply give the actual output of the NLP algorithm.
So if people actually do the calculation King-Man+Woman and it comes closest to King, than they should report "King-Man+Woman~=King" and not "King-Man+Woman=Queen" (only because that's what they expected).
To be honest, I think the idea that we should expect ML algorithms to give a single, certain answer is misguided. I would expect the output from this algorithm to be "King - Man + Woman = King (90%), Queen (83%), Prince (70%)" or something like that, i.e. a list of answers with some measure of how "good" those answers are. Then again, I work in a field that doesn't really have categorical answers so maybe I'm missing something obvious.
That's pretty much correct.
You would typically calculate a vector for "King-Man+Woman" and then do a query on this based on a cosine distance (or similar measure) over the entire vocabulary.
The query would give you a ranked list of the closest word vectors with scores that indicate how good the match is.
But the example is only performing vector operations. You could perhaps normalize the distances of a number of vectors with a softmax or something to produce a probability across a set, but what's being presented in the paper is the "closest" vector following the operations in terms of cosine distance.
In the end, it doesn't matter what transformation you do though, as long as you do it consistently and/or not in an ad hoc manner. If excluding the original term always leads to useful results, it is a useful transformation.
The problems materialize when you're just cherry picking for results.
I don't know. The problem here might be human expectations. As the article says, word2vec sometimes is "sold" with these kinds of analogies that seem so intuitive. So we come to expect the system to behave intuitively. And in many cases it does.
But, what are you really doing there?
Well, you are operating with vectors.
And what do those vectors represent?
Not the semantics about the words themselves. The vectors encode the context in which they appear. They encode what other words tend to surround them.
And there are more limitations. The most obvious one is polysemy. But even without polysemy, different words might have more or less "diffuse" representations. The more technical, precise and uncommon a term is, the less "diffuse" its vector is. King and queen, man and woman are far from precise, technical or uncommon terms. And therefore, there's a lot of "diffusion". Again, the problem here is our expectations versus the results we see in practice. But the models are what they are. And they are not magic.
The titular example is very often sold as something very close to the semantics; so the problem is indeed in the expectations, expectations created by how word2vec embeddings are often presented as vectors that magically understand the semantics.
What happens if you get the latent space of king, do no algebra and return the outcome with king being excluded? In case it's queen, then the author is correct and these examples are highly misleading. In case it's something like prince, Lord or ruler of the seven kingdoms the latent space algebra would be suitable imho.
Also, if we think about it in terms of decision manifolds, it seems the distance between queen and king is too large for the simple - man + woman to have an effect. Why not scale that substraction, so it leads to a change in predicted class without removing king? But of course finding a justifiable weight would be hard..
If we eliminate king from the result list I would assume it's plural is removed as well. Bummer, that would mean the latent space algebra in this example has no effect whatsoever..
> If we eliminate king from the result list I would assume it's plural is removed as well.
In fact, the plural isn't removed. You can see the effect by analogizing A:B :: A:?.
For man:king :: man:?, you get [kings, queen, monarch, crown_prince] as the top 4. For man:king :: woman:?, the results are [queen, monarch, princess, crown_prince], with 'kings' as #6.
Yes, the result seems entirely predictable and logical to me. Even using normal human logic, even if the amount of meaning that the whole term "king" contains is 100%, the "male" part of that meaning would answer for maybe what, ~20%? The rest would imaginatively be filled with things like "top executive in an organization", "power by family relations, not by democracy", "fancy clothes", "chess piece", "ceremonial post more than actual decision making in some countries", "feudalism", etc.
A related thing that amuses me: One of the (less popular†) benchmarks for embedding models is their performance on a TEFL word analogy test. At least as of the last time I perused the literature, which was a few years ago, there was one algorithm with which I've seen anyone report really high scores on this test. For all the crowing about how great Word2Vec is at finding analogies, it wasn't SGNS or CBOW. Not GloVe, either. It was boring, unsexy, 30-year-old, doesn't-even-have-a-strong-theoretical-foundation latent semantic analysis.
† Because it doesn't measure performance at something people typically want to do with these models in real life - there's a strong "party trick" component to the word analogy stuff.
I haven't been following the literature too closely lately - have there been promising results in using it for topic modeling or semantic vector modeling?
My own sense is, the real problem that the space needs to contend with isn't that the math isn't elaborate enough. It's that we're still waiting for someone to come up with a really good way to deal with polysemy, and with multi-word phrases that form a single semantic unit.
For dealing with multiple meanings,
It's already been done. Sense2vec resolves most of these issues and a wordnet integrated version of word2vec or the newer "XLNet" would be state of the art by a long shot but no one seems to want to implement it so the world waits longer for good NLP models I guess...
It relies on word sense disambiguation, which tends to be one of those very language-specific things, and so I'd expect (but haven't verified) that, like other techniques that rely on language-specific bits, it wouldn't work as well on most non-English text. And the most interesting polysemy problems aren't to do with part of speech. They're things like "apple-as-in-food" vs "apple-as-in-computer", or figuring out that "The Big Apple" doesn't have anything to do with either of those. What would be really interesting is dealing well with jargon, slang, and terms of art.
As far as those notebooks, is there one in particular I should be looking at? I might have missed something, but the stuff I saw basically just demonstrated, "Hey, we can handle a lot of training data really fast." What I'd be more interested in seeing is, "Hey, plug us into your document classification pipeline and your performance (as in accuracy) metrics won't know what hit them."
edit: For a more concrete example of what I'd like to see, and going back to the analogy task: The holy grail I'm looking for isn't "king - man + woman = queen". It's more like "software engineer = programmer", and also "software engineer != software + engineer".
You need to find collocations such as "software engineer" and "The Big Apple" and replace them with "software_engineer" and "The_Big_Apple" in the training corpus, then run regular w2v or GloVe. You will get exactly what you want, and also slightly improved vectors for the rest of the vocabulary.
I've heard good things about "Scalable Topical Phrase Mining from Text Corpora" [1], but it's been a while, so I don't know how close to the state of the art it is.
You'll find that if you run UMAP on a large corpus (the same size as your original word embeddings), the ones it'll generate (especially if you feed it any labels as UMAP supports semi-supervised and supervised dimensionality reduction) should outperform those generated I'd even wager by modern transformers. if they don't, than they'll be like 2% worse for a lot of speed improvement on the currently single threaded implementation of UMAP
Oh and you can use UMAP to concat tons of vector models together and all other side data for super-loaded embeddings
A subtle point not really mentioned or brought out. These vectors are 300 dimensional, and once you perform an "analogy " of "X - Y + Z = W" its almost certain that W does not exactly match anything in your vector space (probability of overlap is almost certainly zero). That means you must have an algorithm for choosing which non-matching word to pick. The point of the article is that if you pick strictly the closest one (in terms of euclidean distance in the space) then you usually end up back where you started. There are many measures that could be used, and who is to say that distance along all dimensions are equally important?
In 3d space for example (much simplified from 300d), things that are separated along a vertical axis are usually very different in kind than things separated even by a great distance on the horizontal axis (100m below you is likely to be much different from 100m in front of you).
Or imagine a sky scraper most of the "sameness" lies in a small horizontal region (one block say), but a vast vertical region (100 stories).
This is a simplified analogy to word vectors, but the point is that because two words are "close" in 300d space, if we don't understand what those dimensions mean, we can't say which one is more likely to be "similar" for a specific pair of words (King/Queen vs Mouse/Cat). Using euclidean or cosine similarity may or may not be relevant for one particular case.
If the system returns the same result word that was in the query, doesn't that just mean that the word doesn't have the intrinsic meanings you thought it did?
Besides that it's actually "King - Man + Woman = Queen [Regnant]", which broken down into smaller pieces should be "King - Man = Monarch", "Monarch + Woman = Queen [Regnant]". Then you also have the complicating factor of "Monarch + Wife = Queen [Consort]" and "Monarch + Husband = Prince [Consort]". It seems obvious from this, and "Husband - Man = Spouse" and "Wife - Woman = Spouse" that "Monarch + Spouse = Consort".
This allows a little thought experiment. If the king marries a man, you have a king and a prince. That's fine; no ambiguity there. If the queen [regnant] marries a woman, you have a queen and a queen. This is confusingly ambiguous. Do you rename the queen [regnant] to king, or do you rename the queen [consort] to princess [consort]?
I started playing around with word embeddings in SpaCy for finding synonyms, antonyms or any kind of word similarity that could be used to cluster a list of words into different conceptual groups. So far, the results doesn't seem to correlate very well with what I would consider "similar". Hopefully combining it with tools like WordNet and lemmatization + Levenshtein distance can get me closer to something useful though.
Word vectors like this only work if the two words you care about appear in similar contexts in the corpus it was trained on.
So the assumption is that words from similar context should be similar. But you're always going to miss out on some words that are similar but do not appear in similar contexts.
If the words are really similar in meaning, you should still be able to arrive at a useful result using some graph manipulations.
The words might not appear in a directly shared context, but given their semantic similarity, they should share more contexts of distance 1 (or something along those lines) than an arbitrary pair of words.
The whole cartoon about "martini - gin + whiskey" cartoon isn't great, as "cocktail" really is the best answer it could give. (A manhattan would also have to switch from dry vermouth to sweet vermouth, and change the garnish from an olive or lemon peel to a cherry, and traditionally it would not use just any whiskey, but use rye specifically.)
Has the author made sure he's using the exact same set of word embeddings as utilized by the authors of that paper? Are they trained on exactly the same corpus with the same parameters? Do the md5 hashes match? This could be cheating... Or it could be a case of model mismatch. I'm left without a clear reason to prefer one explanation over the other.
I've pondered making a video game based off Word2Vec. User collects words from conversations with NPCs and had to combine them to get new words which they use in conversation or maybe as physical items to cross barriers, etc. Not quite sure how it would work except that it would probably devolve into just random guessing. Still, I'd love to see it tried.
While not based on Word2Vec, there's a puzzle game that uses words to craft and manipulate rules of a physical world: Baba Is You. https://hempuli.com/baba/
Medium wants me to start a $5/month to read this article. If I pay does the author see any of that money? Or is it just medium capitalizing off their writing
BTW sometimes in history that equation was true. For example in medieval Poland Jadwiga was formally elected a king (król) not a queen (królowa). Only several years later her husband became a king and she got demoted to a queen.
A bit off topic: does anyone know where I can easily download pretrained simultaneously trained separate word and context vectors? that is before they are added together to get a single set of vectors?
Maybe I'm missing the point here, but what's so unintuitive about subtraction (vector or scalar) not being associative? Counterexamples seem easy to find. For example, 1 - 1 - 1 is not the same as 1 - (1 - 1).
The idea is that king k and queen q are both near some location r with a small displacement so k = r + dk and likewise q = r + dq. Then also so around s for man m and woman w, so m = s + dm and w = s + dw. The idea then is that dk = dm and dq = dw, this is the ”semantic structure.” The displacement is the same. So k - m + w = r + dk - dm + dw = q. It would have been cool, but it seems what really happens is queen gets embedded close to king, and the nearest word is just queen. I guess it does show that dk = dm and dq = dw though, but it could also be that dk = dq, and dm = dw.
The author seems to have just learned that most machine learning algos are not "free lunch" but there's a good amount of poking and tuning and some "cheating" needed.
It's part of the learning curve, and I spent quite some time to learn the basics
I'm fine with the free lunch thing. But here the cheating is done on the level of how people present the capabilities of the tool.
If you ask the algorithm how "SHE is to LOVELY as HE is to X", the reported answer (Bolukbasi 2016) was "BRILLIANT", which in this case suggests a heavy gender-bias. But what the algorithm actually gives for X is: "LOVELY". The authors justed picked the 10th example in the list without clearly stating it.
> The authors justed picked the 10th example in the list without clearly stating it.
That's not an accurate description what Bolukbasi et al (2016) [0] did. In particular, they do not list x close to lovely + he - she and then pick arbitrarily from that list. Instead, they explicitly reject that approach (see appendix A), because they're looking for pairs of words that are maximally gendered. They do that by finding x and y such that the angle between x - y and she - he is minimized. Since the task they're solving is different, you can't fault them for getting different results.
"Cheating" (in practice) usually means "embedding problem/domain specific quirks"
In the "King" example, you're adding and subtracting two words that are probably very close already, so if you want to find "something else" besides itself, you need to exclude it. For some problems it might make sense, for some others it might not.
That's fine if you're using it to make business decisions or embedded in a chatbot, but if you're using your new NLP algorithm to "discover" latent social biases and then make commentary .... then a "good amount of poking and tuning" is, at best, academic fraud.
Exactly! I think that was part of the problem for many of the examples that turn out to not-really-work.
People pretend they let the work do by an algorithm, but then hand-pick from a list of somewhat close candidates. Which of course happens with a hypothesis (and thereby desired outcome) in mind.
{kind=link}
But then I read the linked article [Nissim 2019] and it all became much clearer with te example in the title: "Man is to Doctor as Woman is to Doctor". If you remove "Doctor" from the results, you'll get "Nurse" instead, not because the dataset/society/... is biased, but because you inserted the bias in your model!
With this small "optimization" (and others presented in the article, such as the "threshold-method" and hand-picked results from the Top-N words), it's trivial to use the anology method to show that any dataset is biased, since you are filtering the unbiased results!
One a side note, I wish articles like this were more popular. I find that it's really easy to use AI techniques "the wrong way" and there's are a lack of articles pointing to common pitfalls (and, to make things worse, there are a lot of blog posts doing things wrong, which only validates bad methodology).
[Nissim 2019]: https://arxiv.org/pdf/1905.09866.pdf