Seeing how much people recommend other solutions, I've actually moved from Travis to Jenkins, and never looked back.
Yes, Jenkins has its issues (crappy UX, poor/awkward docs), but where it shines is the fact it's self-hosted, so I can SSH onto the instance to debug a failing build or replay it with a modified Jenkinsfile on the fly.
I'm quite proud of the current setup we have; We're hosting our app with Google's Container Engine (Kubernetes), so what we're doing is on every build Jenkins creates a slave agent within the same cluster (just different node pool) as the production, so the environment in which test containers are ran is identical to production, and what's more it actually talks to the same Kubernetes master, which means I can, for example, test our Nginx Reverse proxy with real backend endpoints and real certificates (that are mounted through glusterfs).
The problem with travis and the like is most do not support arbitrary builds.
Drone for example is trying to sell itself as a "jenkins replacement" but has no concept of a build triggering arbitrarily, or that isn't intrinsically linked to a git repo. It's nonsense.
Once you set up a bunch of tooling jobs on Jenkins it's very nice to be able to use it as some form of control center for a bunch of different operations. Calling it a build server is underselling it.
The lack of arbitrary jobs in Gitlab is one of my huge pet peeves regarding it. I've used Gitlab-ee for a year now and really enjoy it for CI/CD stuff. But sometimes I want to throw up a quick shell job that is something super simple, like backing up a database, cleaning up docker images, things like that. I'm used to storing these in Jenkins/Bamboo so that they aren't left hidden on a server in a cron job.
I can do this by setting a manual build that I just run occasionally, but what if I forget to run it for months? In Jenkins I could say "run this job for no reason whatsoever other than the fact that 30 days has gone since it last ran."
This IMO is a huge use case for Ops. At this point I'll likely need to run Gitlab and Jenkins which I really don't want to have to do.
Periodic jobs is great for overnight regression testing, things of that nature and the few examples I gave above. That'll be a great (re)addition. But still, the ability to create random jobs like in Jenkins without having to create a repo, etc would be a huge plus along with easing ops teams into performing server maintenance via CI.
If you use one 'catchall' repo for your random jobs you would only have to modify a file instead of creating a repo when adding a new job. Do you think this is acceptable considering the added convenience of having the job under version control?
So perhaps something like an infrastructure/tasks repo, then make various "environments" for assigning different env variables (like server IPs, etc). I'll fiddle around with this and see if its viable. I just really don't want to have to create a project/repo for every single little tiny task/report I want automatically done.
I like to run various reports, for example run a report monthly and diff my AWS/GCE firewall rules to show if anything that shouldn't have changed has changed then email if the there is a diff. Same with instance lists, load balancers, things of that nature. Then all of the server stuff, hourly snapshots using aws-cli or gcloud, yaddayadda.
Once the periodical thing is back in I can give that a shot. I've only used the travis style builds for about a year so I'm not very advanced with them. I think when I can do a when: monthly that will help greatly.
Re: ChatOps I've upvoted the ticket. I'd LOVE it if there was a slack: step that Gitlab could use that went beyond the checkboxes under integrations> - for instance I'd like the ability to echo whatever under a Slack step to a channel, for instance. I can do this buy making my own step, running a slack container and doing webhooks but that's clunkier than I'd like, especially when the GItlab server already has my slack tokens/etc. Right now I need to run a container that pulls that info to webhook to slack.
slack:
if: successful
channel: deploys
echo: "$buildtag has been deployed, you can access this build at $server1 and $server2"
curl: #posttodatadog "$buildtag released on $date"
I think one thing GitlabCI lost in taking inspiration from Concourse (amongst other tools!) was the centrality of resources. It wasn't obvious at first why this is so important, I and most others fixated on the other visible differences (containers for everything, declarative config, pipeline view etc).
There are a lot of features that don't need to be added to the core because they can be resources instead.
For git-triggered builds, I use the git resource. Periodic, I use the time resource or a cron resource. S3 triggered, I use the S3 resource. Triggered on release of new software to PivNet, I use pivnet-resource. Triggered on a new docker image, I use docker image resource. And so on.
Any resource that has a 'get' operation can trigger a build. 3rd parties can add triggers without needing to avoid interference with other resources, because every operation is isolated.
Disclosure: I work for Pivotal, which sponsors Concourse.
well I know you have great idea's but sadly a lot of the focus of gitlab at the moment is either monetizing with EE (which I can understand, I need to develop for my income aswell..) and the other with adding features to CE (which of course leads to the first).
Sadly this does not fix bugs. And the issue tracker of gitlab-ce grows and grows and the CI is not really stable.
The new permission model was great, but break stuff.
Unfortunatly at the moment me and my team is discussing to use gitlab + jenkins instead of gitlab + gitlab for vcs/ci.
just because webhooks + jenkins is way more stable than the gitlab way (and actually webhooks are push based, while gitlab ci polls.)
This is sad since gitlab ci was quick and easy, while even the new dsl for jenkins is way harder to get right. but we actually can't retry half of our builds.
Another way would be using the shell executor where we actually loose some functionality. (we use the docker executor).
I know your vision (and I think some ideas are great), but sadly I think too much centralization is harmful after going with gitlab since v8, somethings does not need to be reinvented by gitlab (they might just need a improvement).
We spend a lot of development time fixing bugs. Over the last year GitLab has gotten a lot more stable. Of course it is not perfect and the rapid addition of new features creates new bugs.
The issue tracker is growing because we also keep feature proposals there.
GitLab CI doesn't poll the repository. The GitLab Runner does poll GitLab for new jobs. We're currently working on making sure that GitLab can deal with those requests more efficiently. Polling makes setting up Runners a lot easier for our users.
Not being able to retry half of your builds sounds very bad. Please contact support@ our domain and add a link to this comment to receive help with that.
It was a big thing to add CI to GitLab and we had a lot of concerns about it before we did so. But after doing it the improvements in the interface, CD functionality, Pages, review apps, auto deploy, and many other things convinced us that this is the right path.
Thank you for your thoughts regarding your use of GitLab CI. As UX Designer at the gitlab CI team I can say that in the upcoming release there will be a focus on making the system more robust and fixing bugs. Stability and dependability are certainly a priority and are increasingly so. It's about finding the right balance between focussing our scope and broadening it.
My last note is on your mention of the growing issue tracker. The issue tracker is not only about defining bugs and problems, but also about idea exploration. To my knowledge the more GitLab will be known, the more it will grow. It is everyones best interest to let it flourish, but in an organised way. We are hard at work in that area as well! For example, we have dedicated Issue Triage Specialists which keep track and answer a lot of the newly created ones.
> or that isn't intrinsically linked to a git repo
This is required because the configuration is versioned in the git repository.
> has no concept of a build triggering arbitrarily
This is not entirely correct anymore. Drone can trigger builds and deployments using the API or the command line utility, and there is a PR to add to the user interface [1]. The caveat is you need to trigger from an existing build or commit, because Drone needs a commit sha to fetch the configuration from the repository.
There are individuals using Drone + cron to execute scheduled tasks such as security scans and nightly integration tests.
IMO moving from Travis to Jenkins seems like a very disruptive change.
As for me, I had used Travis just a bit, and same for Jenkins, and didn't like any of those options very much.
So when my team needed to setup a CI solution, we ended up using GitLab CI, and it brings the best of both worlds:
- Free service version if you use the GitLab.com deployment (granted, gitlab.com is a bit slow because it's the new thing and everybody is using it now), like travis.
- Open source so that you can host it yourself in the future if you need to, like Jenkins.
- Easy to use and configure, like Travis.
- Free service for private repos in GitLab.com (neither Travis nor any Jenkins-service provider offer this, AFAIK).
Honestly my experience is that SaaS / hosted CI is just generally annoying due to constant stability and performance (both transient and in general, eg. caching in Travis) issues.
Self-hosted CI on the other hand requires a lot of resources, especially when you're not only testing Linux or BSD, but proprietary OSes (OSX, Windows, although the latter at least has the Edge images that work everywhere).
Ultimately I feel like the use of CI in many open source projects isn't very high due to constant annoyances and difficulty debugging the CI environment.
> Ultimately I feel like the use of CI in many open source projects isn't very high due to constant annoyances and difficulty debugging the CI environment.
My perspective may be driven by the communities I'm involved in, but this seems wrong to me. From my experience I would say most open source projects use CI, particularly because so many of the bigger platforms (Travis, Circle, CodeShip) make it free for open source.
It is an extremely valuable resource when you consider the infrastructure and integration you get with absolutely no effort. Installing more obscure libraries or cutting edge releases can be a pain, but it is minuscule compared to the time it would take to provision, secure, and manage a group of containers for an open source project.
This doesn't solve issues in runner-to-base comms. I had tried this kind of setup relatively recently, and almost every 10-15th build had failed for me because GitLab wasn't healthy (502 from Docker registry or problems up/downloading artifacts between stages, etc.)
Fully self-hosted looks like the only sane way. Harder to set up, but at least one can check the whole chain that way.
Sorry about GitLab.com having performance problems. Self hosted is indeed the only way to work around it in the short term. I hope you can set it up quickly. Please use the Omnibus packages that should install in a few minutes https://about.gitlab.com/installation/
Do you really find Travis easy to use and configure?
I've used TeamCity a lot and find the functionality to be decent to good but the UI horrible. Perhaps a bit biased because I had access to the server and agents in that case. A lot of debugging/discoverability issues are easier with full access of course.
I've then used Travis a bit for small GitHub projects (and contributing to other people's projects) and it has a nice UI for simple stuff. However, it gives the impression that they are struggling to stay alive - many features are in beta or feel like they are; a lot is under-documented or planned soon (for multiple years). I know I can dig into their various projects' source code to find out how things work, but I always feel incredibly unproductive figuring something out in Travis. I worry for them. Great to hear you have a good experience with GitLab!
I'll definitely check it out - but the problem with many of these tools is a lack of "proper" Docker support, along with the ability to self host and debug. Thanks for the heads up!
GitLab CI has proper Docker support. You can set a default docker image for each runner `--docker-image ruby:2.1` or set one for the project in the .gitlab-ci.yml file. For more information see https://docs.gitlab.com/ce/ci/docker/using_docker_images.htm...
Also notable is services like docker-in-docker (and privileged docker containers) are allowed, which is a huge win over services like Atlassian's Pipelines.
Without dind, it's really hard/annoying to us CI/CD to build docker images. But with Gitlab, they also provide a place to store docker images (the "registry") right next to your code, for free!
At work, we're investigating moving to Gitlab for everything except issues (which we'd need to keep on JIRA for now since we're so embedded with it). It looks like Gitlab does have some integration with JIRA, but it's project-level, and it would be nice if it could be group-level since we have many small repos. :)
(I don't have an affiliation with Gitlab, I'm just super happy with the service.)
Thanks for the comment! Group-level integration with JIRA is a nice idea. I've created an issue for this [1]. If you would like to give us more details on how we could achieve this, or give us some insights of your use cases, please comment in this issue!
Thanks for your kind words for GitLab! Our JIRA support is pretty extensive https://docs.gitlab.com/ee/project_services/jira.html but extending it further is a priority. Felipe Artur is working on this full time. Consider creating an issue for group level integration, it sounds interesting.
Full disclosure, I am a Codeship employee that helps onboard new customers for our Docker support.
That said, our (Codeship) Docker support is the most "Docker native" on the market, in my opinion. We build your containers, by default, using a Compose-based syntax and all commands are natively executed by your containers. There's no interacting with a Docker host or running explicit Docker commands at all.
We don't offer self-hosting but we do have a local CLI that lets you run and debug your process locally with parity to your remote builds.
...sort of. I eventually rage-quit Circle and set up a Jenkins cluster because of all of the heisenbugs we found on Circle. Builds would fail 5-10% of the time for totally unreproducible reasons (for example, pip install into a venv would fail with a permission error), and you can't SSH into a build that's already failed. We very rarely had problems with Jenkins builds, and when we did, we could go look at the environment it had run in and diagnose what went wrong. I love Jenkins and would absolutely choose it over a hosted solution.
(We also went from paying $1k/mo to $0/mo, which is a very nice side effect)
Agree completely. I think new users are perhaps turned off by Jenkins due to its (deserved) reputation for ugly UI. But its very dependable, stable and reliable solution. And there are plugins for doing every conceivable thing. We have a job manager to store the config in CI, and its such a breeze to work with.
I had much the same experience. Their lack of (proper) caching support meant our already-slow build took 2.5 times as long as it should, not to mention over burdening the maven repos.
By lack of proper caching - I mean reusing a volume (or similar). They do have an approach where they bundle up some files and throw them on S3, but that can actually take more time than re-downloading them. Not much of a cache - which is important for both Docker and large Java builds.
Supposedly the v2 should fix that, but I've been waiting forever to get my beta invite.
Swapping to Jenkins allowed me to choose faster hardware, and optimize our build a bit better. Trying to get Blue Ocean to work right, but to be honest it's a supreme PITA - there seem to be bugs/undocumented workarounds in the github authorization side. Once that's up though, it _ought_ to work better.
Jenkins' usability issues are most of what's allowed these other products to become popular. Hopefully they'll focus on that a lot more, but past performance would suggest they won't. If I wasn't so lazy, I would pitch in myself :)
It's really well implemented too, it grabs authorised public keys from the github repo directly, so if you can push to the repo for the project, you can just ssh straight into the build machine. Magic.
We run Drone and are very happy with it. Really easy to install and get working, similar but better usage than Travis, open source, Docker powered. I really hope it catches on more strongly because it's fantastic.
I wasn't at first either, but benefits outweigh the risks (which are all security related).
It's something I'm willing to re-think if it turns out to be problematic on any level. But so far after half a year in production, we've seen no problems.
Juenkins' Kubernetes plugin allows to mount secrets like with usual pods so we deploy test secrets just like we normally do production ones.
As for glusterfs, our Nginx reverse proxy also has a cron job that runs letsencrypt automatic renewal once a week so it needs to be able to write those new certificates. Because we need to be able to run several reverse proxies, all with write persmissions (we run one at a time, but on deployment, there are two running to avoid downtime) we chose gluster, as gce-pd doesn't support multiple writers.
I am the community leader for Jenkins Blue Ocean and Product Manager for the project at CloudBees. It's really great to see Jenkins users getting excited about Blue Ocean!
Please let us know if there are any missing features that are blocking your team from adopting Blue Ocean. We know there are some gaps between Jenkins Classic and Blue Ocean and while we have some good ideas, we are relying on your feedback to help us prioritise what to work on next.
If you've got any questions feel free to drop a comment here and Ill do my best to answer them or join our Gitter community [1]
Some pieces of feedback on Blue Ocean, which we've used on and off but haven't been able to switch to:
- The console interface needs work. The "click on text to link to it" thing is making it very hard to select stuff. Line numbers on the left are useless for a log, timestamps would be much more useful. (Also please add ANSI color support!)
- Artifacts view is awkwardly empty. Instead of the artifact name being a link, there's a separate download button.
- I have a GH project linked to my various build-master jobs. Why is the "commit" column empty?
- Build -> Changes -> The commit column shows the commit; with Github integration it could use a link to the actual commit on GH itself.
- "Duration: A few seconds" is not helpful for builds <1 min long. If your build takes 4 seconds average and one build takes 33 seconds, that should be immediately visible.
- I can't immediately see which builds were recently triggered and when from the main view. Regression from the legacy main view.
- Bug: "Display the log in a new window" -> the log is being sent as text/html instead of text/plain
> I have a GH project linked to my various build-master jobs. Why is the "commit" column empty?
I think there was a regression introduced sometime before beta 12 that meant that commit messages were not displayed on the Activity, Branches and Activity tab. Do you find it is empty with all runs or just the first run of a newly detected branch?
You're welcome and thanks so much for this feedback. There's a lot here for us to cover - would you mind if we could have a short chat over email or even a Google Hangout? My email is jdumay@cloudbees.com
Particularly for search, I'd recommend signing up to our JIRA and watching both of those issues. You will be able to get a notification for any proposed designs (we'd love to have a discussion with you on the final solution) and when the feature ships in a beta release.
Nice to see someone working on Jenkins UI, looks good!
About the search: there are many JS libraries which allow pagination, sorting and searching tables, so it might be fastest (and most user-friendly) to just use one of those. Well, as long as we-re talking about 100s of jobs and not 1000s... :) For instance, I had great fun dealing with DataTables [0] lately (needs jQuery). The advantage of this approach is that it takes half an hour tops to implement.
We have blue ocean installed on our Jenkins instances and I periodically check when it is suitable for our use.
Currently our promotions to environments etc. use `input` step on the pipeline. This is, for now, the main thing that blocks us from using blue ocean.
I asked the exact same question on last week's Jenkins Online Meetup and got this answer: it's Jenkins pipeline under the hood, so the stages are only restartable if you're running Cloudbees' Jenkins Enterprise.
Esoteric use case from someone in AI: Jenkins is the only CI we've been able to use even as an open source project due to needing gpus. CI and things like special hardware is a "semi-common" edge case and a big reason to have something self hosted.
Referencing other comments here: We've also found periodic builds and arbitrary jobs to be a must as well.
A lot of providers out there support most of the basic stuff out of the box, and I understand why they won't go after an edge case like that. It's great to see improvements in the UX on the horizon, that has been our biggest pain point.
If anyone's curious, our CI setup involves a multi OS cluster: Mac,windows,linux for power,linux x86 (with cross building for android) with 1 linux master running a gpu for gpu tests.
Yup, we switched to Jenkins a while back for a similar reason. We're changing a bunch of our tooling for a new project because we can, but we didn't even consider switching out Jenkins. It's ugly but it works and it isn't worth figuring out anything else. The promise of Blue Ocean and the new declarative pipelines helps a lot although we probably won't bother trying it out until it's out of beta.
IBM engineers ensured that Concourse can run on linux/ppc64le. There are also Mac workers and, I believe (based on looking across the office to a Windows-facing team) Windows as well.
The only reason it's possible is because Concourse uses the Garden API for container management; in turn Garden can create real or I-can't-believe-it's-not-real containers for the target platform if there's a backend for it.
In GitLab CI you can use any machine for a build as long a you can install GitLab Runner on it. We kept the design of that simple with few dependencies and it is written in Go.
So, you're saying that you can use tags [0] to specify that a runner has some special hardware like GPUs. Then in the project set a job to only run on a runner with those tags [1].
We just don't use gitlab heavily enough yet :). We are mainly a JVM shop so the bias jenkins has for things like maven and what not out of the box is pretty appealing. I've been watching your integration play :). Maybe 1 day.
You cannot provision jenkins
unattended without 3rd party hacks and undocumented features. Until this is fixed I recommend avoiding it, as you'll get pet servers. This is totally retrograde to the devops mindset. Now why should I not use that mindset if that proves to be productive at other parts of work?
There are also puppet modules, Chef cookbooks, and etc that a lot of people use. Some of those are maintained by people who are also in the Jenkins community, so I don't consider them "3rd party hacks" if you are referring to those.
And this is one of the major shortfalls of the Jenkins mindset. Everything is a plugin and an afterthought from the main design of the system. Something as crucial as configuring the system should be a top design priority, not shoved into a plugin 5 years after the launch of the project.
So, great, there is a plugin to deal with configuration. How do I bootstrap my infrastructure? If it's a plugin, it sounds like I need to install that in an already running Jenkins setup, no? Currently, both this and the bypassing setup wizard seem like hacks to me.
Configuration of a critical piece of your infrastructure should never be a hack.
Totally, I just was considering the fork point from Hudson back about 5 years ago. As an independent project they've had 5 years to think about design and it seems like no one really has cared.
I still think core functionality shouldn't be put into plugins in any software system. You should have sane functionality and defaults right out of the gate. Plugins or modifications are for extending the base use case. Configuring your software to me is a base use case.
Jenkins is incredibly popular and has a huge community. Dropping backwards compatibility would be very harmful.
What they did instead was to move most of the core functionality in plugins maintained by the core contributors, so they're plugins all but in name. I.e. they can be installed separately, uninstalled, etc., but about 100 plugins are supposed to be used together and you see them frequently in examples, docs, etc.
Plenty of systems can and do evolve their community forward with it. The sentiment of backwards compatibility at all costs is the same that leads you down the road of having to support IE 7. No one is saying play fast and loose with core functionality, but do it responsibly and with community input.
That "about 100 plugins are supposed to be used together" is indicative of bad design to me.
They really should be taking a look at modern systems like Concourse CI to see what they can do to improve.
FWIW, if you fight through the "undocumented features," Jenkins actually ends up being one of the best tools out there to manage via Ansible or whatnot. The Groovy/Java API for Jenkins is incredibly powerful, and by adding Groovy scripts to the /var/lib/jenkins/init.groovy.d/ directory, you can configure just about anything.
TBH there's not much I can say on this as its not my particular area of focus (I'm the "bring CD to everyone" kinda guy) but I and other community members do recognise it is a problem that we want to solve. With Pipeline there is a trend to moving job configuration to source control and I think that direction will make things more Ops friendly as time goes by.
Not only job configuration. But the entire configuration of your jenkins setup.
For example this issue was a blocking factor for automatically provisioning a new jenkins.
https://issues.jenkins-ci.org/browse/JENKINS-34035
I wouldn't call it just a trend, it's part and parcel with the DevOps philosophy. Infrastructure as code, in source control. It's more of a conclusion, the trend is adoption.
I'm not sure I get the "provision Jenkins part". Slaves "self install" once you have a working SSH connection and the master is just a bunch of XML files.
Have you tried setting up the jenkins docker image?
I'd expect an experience where it works out of the box, or works out of the box after setting up some environment variables.
Actual experience:
you need to manually click a wizard, and set up an admin password, or google and find a hidden github issue of an ansible playbook with a workaround how to make jenkins startable for the first time unattended.
Just a bunch of xmls? Which ones? With what content? Have you tried ansible for example? I'd like to declaratively define my initial setup:
- jenkins admin password, users, passwords, roles, ssh keys
- slaves
- jenkins plugins can be listed and are installed
- git repository lists which contain the Jenkinsfiles
Good luck doing this non-iteractively with those bunch of XML files... (the jenkins cli randomly does not support parts of these steps)
I'd guess the OP means restoring configs and the fact that Jenkins setups tend to turn into snowflake servers. Here are some issues:
- State is stored on the filesystem across a bunch of XML files, rather than in a DB.
- Configuration of Jenkins itself happens primarily from the UI rather than in config files. This makes it very difficult to provision automatically.
- No HA story. Or there is a workaround and it relies on NFS. Which is basically the same as no HA story. For a piece of critical infrastructure this is very bad.
- Startup time is horrendous. If you build an AMI and put it in an autoscaling group to attempt to get some vague approximation of HA, boot times often tend to be so long that you need to increase your warmup health check a ton so the autoscaling group doesn't kill the server in an infinite loop.
Sure, you can ssh into your server and apt-get install it, but really you should be writing automation and not doing setups by hand.
So while it's nice to see some effort focused on the UI, since Jenkins relies on it almost exclusively, there are a lot of other fundamental problems.
I always try to use anything other than Jenkins unless forced to.
I agree Jenkins isn't the easiest to automate but surely the fact that it's all XML files makes it easier than a database -- using config management you can install Jenkins and template out the necessary configuration file(s). I much prefer systems that use files instead of the db for configuration...
Configs should be in config files, state in a database. They are coupled in Jenkins and both are on the filesystem, mainly in XML files that are undocumented. Sorry if I wasn't clear about that.
Wow, this looks amazing. I really want to try this out.
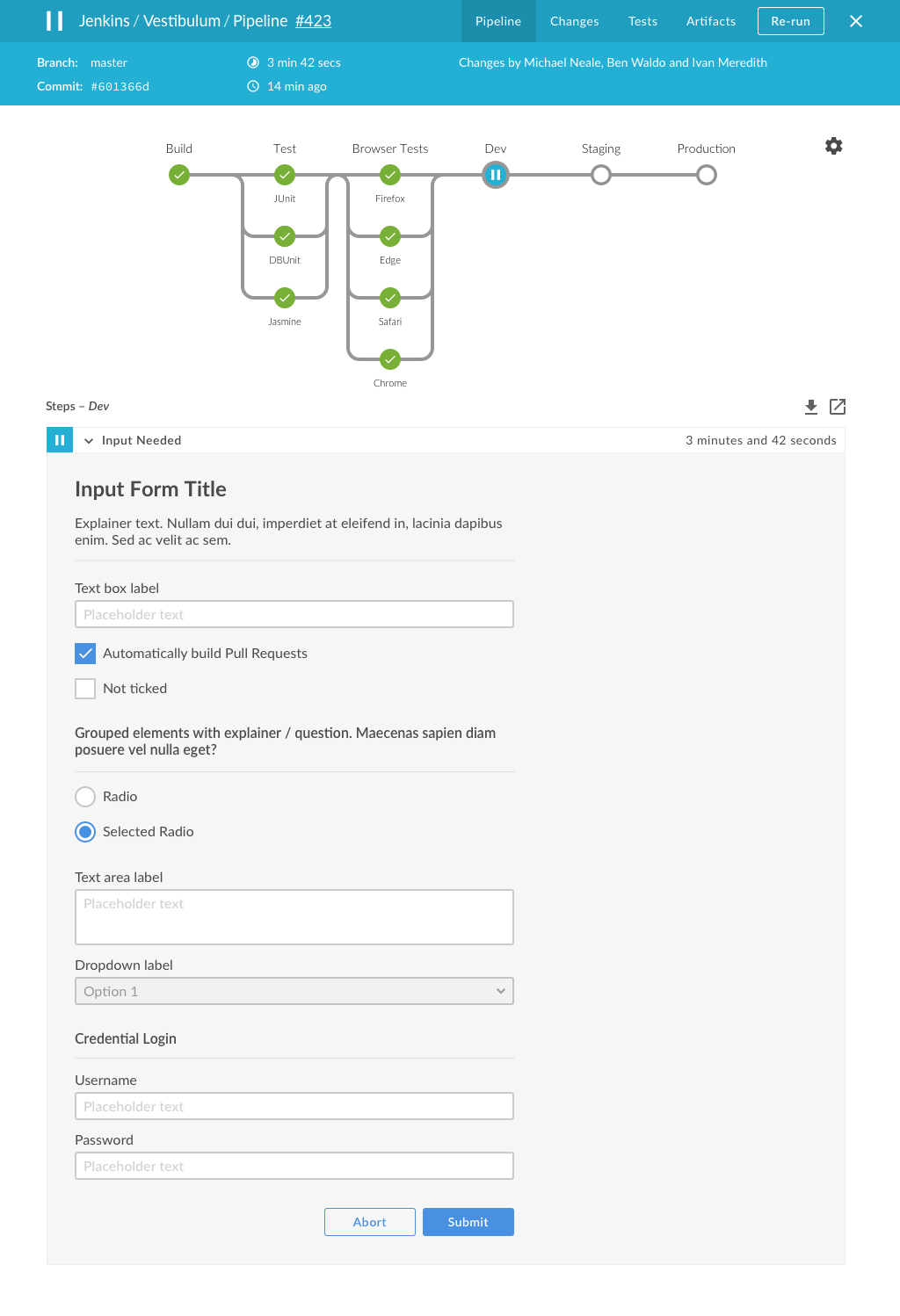
On my current contract, we've been moving away from Jenkins and towards Gitlab CI. I still work on an opensource project that uses Jenkins to build. The screenshots show a really good pipeline layout. It seems like it's similar in power to Gitlab CI, but also looks like it has way better visual representations and UI.
I'm glad the Jenkins team is still moving forward and developing plugins/tools like this.
I think the consensus is that Jenkins offers more power and flexibility at the cost being more complicated to set up. GitLab CI is easier to get up and running with and superbly integrated with GitLab (as one would hope).
We also want to offer all the power and flexibility of Jenkins but we still have some work ahead of us. The idea is to add those features to GitLab itself and not to plugins. Plugins tend to cause brittleness https://news.ycombinator.com/item?id=13218391 We want to make sure that you can upgrade GitLab without having to worry about things breaking.
For the current GitLab release (8.15, December 22) we planned the following CI improvements (not all will be ready, some will slip to Jan 22):
Does these pipelines thing imply moving away from Sidekiq? At work that's our biggest issue with Gitlab. Sidekiq dies all the time and Gitlab has to be restarted for merge requests to work again.
These pipelines do not imply moving away from Sidekiq. Have you tried using the Omnibus package? It contains logic to make sure restarting Sidekiq is automatic. How much memory does GitLab have and how many users?
The Bitnami package indeed doesn't include any of this. I strongly recommend switching to Omnibus.
From https://about.gitlab.com/installation/
"One-click installers are frequently out of date and might not contain our Omnibus packages. An example of this are the Bitnami packages in the past couldn't be updated and are now much harder to update than the Omnibus packages. We advise to not use one-click installers but instead start an vanilla Ubuntu instance and use the recommended Omnibus package installation. This is almost as quick as a one-click install and you're sure of the latest version and easy upgrades."
I dunno, I found the opposite. Jenkins is an easy stand-alone package that I can just install & immediately navigate to the UI. GitLab-CI requires you to install & configure & link "runners" in a manner that I found less intuitive.
We're always interested in making that experience better. The reason that it is more complex than Jenkins in the first place is that we think the builds should happen on another instance than the one GitLab is running on. I've seen running the builds on the Jenkins machine lead to many problems. Hence the need for our process that we try to make easier than setting up Jenkina build slaves while still being secure when working on the public internet.
Interesting, thanks for the insight. Those are certainly valid reasons for things being the way they are, but I have to wonder how many GitLab installs are like mine: a single "git/build" server on a private network serving a small group of users. I'd wager the number of installs that fall into that category is fairly substantial, and in that situation the runner configuration feels pretty over-engineered.
I just want to mention that I loved the idea of BlueOcean at the begining. It looks sleak an works well with pipeline. However, for us it's unusable in production setting.
I know that it's still in beta, but as one example it doesn't support parameters. When user starts a job through BlueOcean it will fail.(Officialy they don't plan to implement it any time soon as I found out) That means It stays disabled in our jenkins. PS: For now its just a presentation tool for management :)
Well, that's Jenkins in a nutshell. You usually need to extend Jenkins with lots of plugins because they provide functionality that should have been in core in the first place. Then you realize that those plugins are not properly sandboxed and often do not work well together (especially with multi-configuration builds), not to speak of how updating Jenkins becomes a nightmare with plugins breaking left and right because of some internal API changes which are not yet properly handled by some plugin.
In fairness, Jenkins did not have the benefit of hindsight. Plugins were the this-is-how-you-support-extension architectural style of the period (see also Wordpress, Eclipse).
I've been working on a Concourse tutorial video series. One of the points I've made is that plugins are unsafe to compose. They need to know too much about each other to prevent interference.
Concourse instead composes on resources, which all have an identical interface (check, get, put). You can pretty much use any resource with any other resource if they achieve your purpose.
We're still calling Concourse "CI/CD", but folk are now jokingly referring to "Continuous Everything" at Pivotal. Because it really is becoming the first tool for everything. We're running large automatic tooling with small teams, because it's easy to extend and relatively easy to rearrange.
Disclosure: I work for Pivotal, which sponsors Concourse development.
Actually, we're working on parameters and input right now! It's likely that both parameterised job and Pipeline input will land in a beta release mid-Jan.
The ansi output color plugin doesn't work with output. Nor the build timestamp plugin. The PR interface only works with Github, should also work with bitbucket pull requests.
And the most annoying, when blue ocean is tailing a job thats running, it uses 100% cpu on safari.
Those are the biggest issues I find with it as of today, otherwise its great for a manager mode until then.
We used Jenkinsfiles and pipelines recently. And also introduce Blue Ocean on our jenkins server.
It come with a few glitches: Some plugins are not compatible with Blue Ocean, causing a white-page-of-death. However I found there where already issues created for them, i just turned off the plugin.
But the biggest downer, is that blue ocean is just a small UI on viewing pipelines. Its not a replacement for jenkins. And you still need the normal jenkins UI. Which doesn't handle pipelines well.
The blank screen issue is extremely important to us to fix and we hope to have a change that fixes it shortly. It's a consequence of the new REST API depending on all the plugins installed on your system and exposing its data for JS plugins. If one plugin misbehaves then it 500s the REST response. We've got an approach to isolating per plugin failures so that you can load the page even if one plugin fails.
I have been using Blue Ocean as the radiator view for our Jenkins projects for a long while now and it does look really nice and sleek. That said, currently that's pretty much the extend it can be used for. I'd say it has about ~5% feature parity with the "old" UI currently, which means that there's not much to do than just look at the pretty progress bars. Can't wait for this to progress though, the old UI of Jenkins is archaic at best.
Thanks for the complement. It's hard building a new UX for a tool like Jenkins. It can be difficult to pick the next thing to work on because one feature could be the killer feature for one developer but not the other. Is there anything in particular that blocks you from using it day to day?
Thanks for replying! (First, our Blue Ocean plugin is at 12b currently, so some of these might be already there).
I agree with the difficulty with picking the next UX piece to build and as such I guess most of my "wants" are mostly for me. I spend most of the time in Jenkins fiddling around in the settings, plugins and credentials and such I'd love to see "/credentials", "/configure", "/configureSecurity", "/pluginManager" and maybe "/log" and "/load-statistics" under the Administration tab.
These would alone lower the need for the old UX for myself close to nil, as the pipelines are mostly automatically managed by our (Jenkinsfile based) integrations. I do see how the administration part will be really painful, as all the conventions used by plugins would be have to be "ported" somehow first I assume?
Administration tasks are not really in our scope yet (at least not for 1.0 as it's a huge job to boil the ocean, so to speak) and our focus is on making the best developer experience for CD Pipelines.
There's a lot of job level configuration that's moving into the Jenkinsfile with Declarative Pipeline [1], such as triggers, and you can expect that process to continue.
You're right on the plugin conventions having to be entirely ported. There's a whole new UI stack that those plugins have to adopt and we have to think carefully about how we design those extension points rather than blindly pulling them into the UI.
This news is from September, I gave my first impressions on Hacker News then, here's my blog post including an interview from the team behind Blue Ocean.
Restrictive licensing and then there's the fact it is a huge memory hog. I have Blue Ocean running on a home lab with 16GB RAM and Jenkins + SSH slave drains almost all the resources.
Also - GitLab Travis / CircleCI etc being quite trendy/new remember that if you need to extend Jenkins you're dealing with a legacy product.
Last week I was setting up a large java app (bamboo) and I started it up. Where did I instinctively go to check that it was running? Ask systemd? No. Check the log file? Nope. I went into htop to check that the CPU was now pegged... :)
We currently have a Jenkins setup and recently looked into both Concourse CI and GoCD as candidates for a change.
We decided not go with Concourse, because it has a complex setup with bosh. Not much other use cases are really covered in the docs other than a simple one machine setup so you are left to figure things out on your own (don't really have the time to go into all that, jenkins + ec2 plugin is very simple and just works). Also the minimal GUI, very CLI-centric. this is more of a particular thing, since I don't think that our current team will be comfortable with that UX and we have to weight this in.
We did like the docker-centric approach and specially the postgres backend that makes for a much more flexible maintenance story.
We decided not to go with GoCD simply because it feels very similar to jenkins in several aspects, but all concepts and workflow are different so we would have to relearn all that we do in jenkins in the GoCD way. Also redo all ops involved in backup, update etc. I just didn't find the killer feature to justify going through it. The postgres backend would maybe have caught my attention if it wasn't offered as an add-on for the expensive paid version.
In the end just decided to leverage more of Jenkins 2.x pipelines with shared libs instead of having independently configured jobs that are bothersome to maintain. Will probably make some changes to our agents to leverage more of docker instead of messing with AMIs.
Another major factor is the size of community, which alleviates a lot of worries.
As for Blue Ocean, I hope it evolves in the right direction, but right now it simply does not solve any problems for us. As said somewhere else, you can't build a pipeline with parameters. This is really a show stopper, parameterized builds are central to a lot jenkins use cases. Another problem is a single view for all jobs but no filter? The favorite jobs feature does not substitute either search or the view and folder way.
Are there any other missing gaps you think are important? I'm keen to get them solved :)
EDIT: I missed the comment regarding search and that is something we are working on. I hope to have a design up for it on https://issues.jenkins-ci.org/browse/JENKINS-38982 in early January and we believe it should be quick for us to ship.
A note on concourse deployment: their docs recommend bosh deployments, but they also provide standalone binaries [0] and the deployment workflow in this case is extremely simple. Run "concourse web" for the UI, "concourse worker" for a worker, and all the basic connectivity stuff is handled via command line parameters.
That being said, depending on your company habits, the fact that concourse is very opinionated on how to run the jobs (every is built around docker) and how configuration is done (yaml files, no UI) can be either a blessing or a showstopper.
> the deployment workflow in this case is extremely simple. Run "concourse web" for the UI, "concourse worker" for a worker
By which you mean, of course, "write systemd units or whatever for the web and worker jobs", because you don't want to be starting your CI system by hand. That's not rocket science, but it's not quite out of the box.
That said, the emphasis on BOSH must really be hurting Concourse adoption. Nobody outside the Cloud Foundry bubble (which includes Pivotal) has any interest in using BOSH at all, and honestly, quite rightly so. It's cool there's a BOSH option for fans, but the primary deployment option has to be something accessible by the general public.
> That said, the emphasis on BOSH must really be hurting Concourse adoption.
It did, I think. My gut feel from watching the Slack chat is that lots of people are deploying using the prebuilt docker containers. There are even projects that set up k8s clusters for you.
Whoa... GoCD is a major superset of what Jenkins (or anyone else) provides! Pipelines are first-class constructs - beyond the visual representation and the Value Stream Map. There is full end-to-end audit-ability and traceability, you don't have to resort to any hacks to mix 'n match components.
Do contact the community on the GoCD mailing list to understand what it takes to migrate from Jenkins to GoCD.
Meanwhile, please also check https://build.go.cd/ (user -> view, password -> password) to understand some of what's possible.
Possibly, however large enterprises might lock CI/CD down and manage it centrally. In those cases they're likely running Jenkins and Blue Ocean looks a breath of fresh air for the folk in those sorts of situations.
Moving to either of Concourse or GoCD takes some rethinking about how to use project automation. I've been watching and participating in this process at Pivotal. Once people "get" Concourse, they use it for everything, but for orgs with heavy investment in Jenkins customisation a hard cutover might not make sense.
Really depends. When I tried it, GoCD sucked a bit for shell-script/makefile based build processes, but worked really well for Java/C#. Also IMO, Jenkins has a less-steep learning curve and is far easier to set up and for devs to modify themselves. But everybody loves shiny things.
I'm building my entire operating system using GoCD. Once you start to mature in your development practices, you start to realise the need for first class pipelines and more.
I think in the what is AI argument what has actually happened is that there have been two conversations about AI over the years - what AI is and what AI can do by virtue of being AI.
In that conversation the assumption has been that AI would be in some ways self-aware and intelligent like 'Data in Star Trek'
and by virtue of being self aware and intelligent it would be able to learn things from its users, it would be able to make aesthetic judgements about music and art, it would be able to create interesting art of its own and so forth.
As it turns many of the things that AI will be able to do for us has been done by programs that are 'just math', the question is if in the future more or even all of AI's perceived benefits for humanity can be accomplished by just more and more complex 'math'.
In the end perhaps the essence of what AI is will only be beneficial to AI itself.
This is nice! I've been looking for a way to schedule deployments of multiple code bases at the same time, with automatic rollback support. Does this support that?
This looks great. Not because of the aesthetics, but because it finally acknowledges that Groovy is absolutely useless for Pipeline. I want to try out this new workflow.
This actually looks interesting. You can maybe containerize it to increase adoption/reduce setup time.
I agree with both the unfriendly and over-engineered part ;). But right now there is no other tool that provides a task runner PLUS all the plugins of Jenkins that provide so many features out of the box.
This look nice, is there a hosted version of BlueOcean?
I've been looking into (preferably hosted) pipeline-based CD options because simple CIs like Travis and CircleCi are not really meant true CD. What does everybody recommend?
Jenkins isn't really CD either. I'd suggest looking at GoCD or spinnaker, though you'd have to host both yourself.
You can get away with using any of the CI tools to just run through pipelines (heck, you can do this with fancy bash scripts if you're a real masochist ;), so I guess you could use any of jenkins, CircleCI or Travis to run a pipeline. I guess it'll depend on how much you really don't want to manage a CD server yourself.
I'm a Concourse nut, which was partly inspired by GoCD.
I'm not sure Jenkins is really making pipelines first class in the same way GoCD or Concourse do. In particular, there will be a painful period where some plugins work well and some don't, because plugins are difficult to cleanly compose.
Disclosure: I work for Pivotal, which sponsors Concourse development.
{kind=link}
Yes, Jenkins has its issues (crappy UX, poor/awkward docs), but where it shines is the fact it's self-hosted, so I can SSH onto the instance to debug a failing build or replay it with a modified Jenkinsfile on the fly.
I'm quite proud of the current setup we have; We're hosting our app with Google's Container Engine (Kubernetes), so what we're doing is on every build Jenkins creates a slave agent within the same cluster (just different node pool) as the production, so the environment in which test containers are ran is identical to production, and what's more it actually talks to the same Kubernetes master, which means I can, for example, test our Nginx Reverse proxy with real backend endpoints and real certificates (that are mounted through glusterfs).