To my understanding, removing downvoting removes a vector of abuse. ie: "downvote brigades" on Reddit
While Twitter doesn't have downvoting, it is still dealing with "report brigades" - various interest groups will organize via Telegram (or similar) to mass-report tweets they don't like.
I wonder if you could strike a balance by incorporating downvotes as a visual metric, but not using it to rank content, thus allowing the expression of dislike while removing the abuse vector.
> Here's what I don't get. Almost everyone I talk to hates Teams. But they use it anyways. Nothing is stopping them from using Zoom or Google Meet, or some other alternative.
Maybe in startups and small companies without a dedicated IT team, but an enterprise IT group will absolutely stop you. And Teams is very easy for them to administrate if they are already deploying MS products.
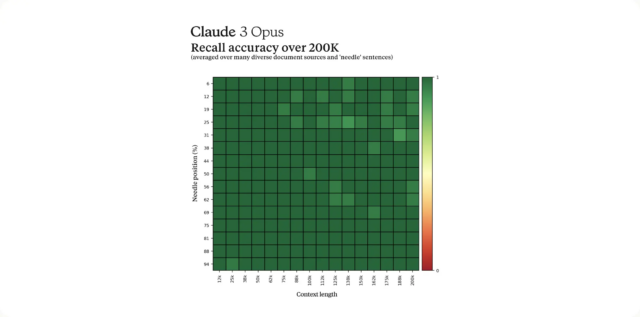
Just to add some clarification - the newer GPT4 models from OpenAI have 128k context windows[1]. I regularly load in the entirety of my React/Django project, via Aider.
Be aware the haystack test is not good at all (in its current form). It's a single piece of information inserted in the same text each time, a very poor measurement of how well the LLM can retrieve info.
Even in the most restrictive définition of recall as in "retrieve a short contiguous piece of information inside an unrelated context", it's not that good. It's always the exact same needle inserted in the exact same context. Not the slightest variation apart from the location of the needle.
Then if you want to test for recall of sparse information or multi-hop information, it's useless.
For my education, how do you use the 200k contenxt the normal chats like Poe, or chatgpt don't accept longer than 4k maximum. Do you use them in specific Playgrounds or other places?
Nice work! I watched the demo and can see how it will generate fixes for you, which you then copy and paste into the editor. Perhaps you could consider automating this process like Aider[1] does, whereby you force the LLM to generate a git diff for the fix and automatically commit it.
Haha thanks! Yeah, I think that's definitely a logical next step. We do something similar for the larger bug resolution platform we've been working on, so it shouldn't be too hard to port over!
Still learning about the landscape so can't give informed opinions. LMQL is a new one for me, will check it out.
What we're mostly going for is composability vs abstraction. What's the smallest nugget of lift we can do for you, to make it feel natural to implement what you want? In this case it's treating the calls as functions and leaning on native python features like functions, docstrings, and types, so you can still use the python language like closures to do the weird things you need.
This is all handwavy, put on my wizard language design hat, so take it with a grain of salt. We're just trying things out.
I'd like to see an injectable mitm like proxy that can rewrite payloads. Many of these frameworks are useful, but when they go off the rails, they hard to modify and introspect.
It would be nice if LLMs had a way to speak an annotated format, like XML that was able to encode higher level information in a coherent manner over "well formed" addhoc text.
LLM libraries are in a crazy state right now. It is like JS frameworks 2015, a new one that demos well every other day.
one idea we're cooking is to offer a proxy with a hosted reformatting model on-board, to rewrite payloads on their way back in the case of type parse failure. fructose, the clientside sdk, would be optional
> Setting up a new Macbook will be tough and cumbersome. Every time I get a new Macbook, I go over the same steps on how to set it up for my working experience.
Huh? My last several hardware upgrades I just plugged in my Time Machine drive and everything is migrated within 1-2 hours.
These days, besides the dotfiles and few minimal settings that I remember, I just let it go as I go along. In about a month or so, it all gets to where I want.
This is what I tend towards too. It helps that my setup isn’t too deeply customized (for example I think the only UserDefaults change I make is to add a Quit menu item to the Finder’s app menu), so even defaults are reasonably usable.
Even with that, there’s more than enough tools out there to automate setup.
For example, I use https://www.chezmoi.io/ which creates a standard home directory set up (prompt etc), decrypts SSH keys and other private stuff, and installs a bunch of tooling through brew/apt.
Different people lose energy from different tasks. I.e. it may not tax your mind to have clutter around, but it can be a distraction for someone else. For some people (like me), clutter is fine but starting on a task takes a lot of energy. The important thing is knowing and accommodating for yourself to get the best results.
My work MacBooks have the migration assistant disabled by MDM, it's a pain in the ass to swap, I can live with them for 3-4 years though so not a big problem, just annoying.
For my personal Macs the migration assistant is fantastic, never had a hiccup and when I boot the new machine after migration is almost exactly like the old one, except for having to re-authorise some music software.
First I’ve heard anyone say this. FWIW, I experienced no issues, and I’ve been using migration assistant since my first (well, second, I suppose) Mac (I recently found an old config file dated 2007!).
I had problems with Homebrew and some apps installed through it (crashing). I couldn't compile one DLL. I had to reinstall Command line tools. Deleted one electron app - couldn't be bother.
I also noticed two binaries (one was Python) running in x86 mode via Rosetta. It was slow. Another reinstall. You can check Kind in Activity Monitor (apple/intel)
I read dozens of them and I found the presentation to be a fun approach. The creativity is welcome IMHO. It was immediately clear to me that these were comments scraped from various sources on the internet. Who they're replying to doesn't matter much. If you've worked with JIRA extensively, you've already heard many of these criticisms.
> I barely have any cognitive or physical energy to do any mentally taxing work even if that means learning something new and exciting
When I was in this situation, I found learning or doing side-project work in the morning, before leaving for work, to be a substantially better approach. I'd get up at 5AM and work until 7AM. It made me excited to go to bed and felt like I was giving the best hours of my day to myself.
+1 for this. I think of it as momentum. Whatever I start my day with sets the tone for my day as a whole. Changing my personal growth time to the morning is probably the best change I ever made for myself.
I've been independently employed the for 13 years as a software consultant. Most of my work has been building web-based business software for small/medium sized businesses. This involves both designing and implementing solutions for non-technical clients. It's a lot of greenfield design and development, which feels a lot like working in an early stage startup.
I have at times taken 6mo - 24mo contracts as just a software engineer when the pay and environment were good enough. This work is far less interesting, because someone else is typically designing what is to be built.
The term “greenfield” comes from physical development- a you are taking a “green field” and turning it into a factory or housing or similar. It’s contrasted to “brownfield” which means developing in or over an already built up area.
In software development “greenfield” generally refers to new systems development whereas “brownfield” refers to the maintenance, extension, or enhancement of existing systems and solutions.
Sibling comments both answered the greenfield thing as I would have :)
As for first business, I built a very small network over 7 years working in house at an advertising agency (which did a lot of digital work) and some startups. While I was just an IC developer, because I could communicate with non-technical people well, I became the first point of contact for a lot of decision makers over time.
If you want to do solo technical consulting start making friends with non-technical people who are in leadership roles. It takes time but it does snowball.
This really speaks to me and is exactly what stopped me from my multiple attempts to get into native Mac/iOS development - the IDE. Your assertion of form over function has helped me articulate what I hated about xCode - so thank you for sharing.
I've been in the JetBrains ecosystem for over a decade now and while there are faults, I've never felt that JetBrains wasn't designing their IDEs to work how I wanted them to work.
{kind=link}
{kind=link}
While Twitter doesn't have downvoting, it is still dealing with "report brigades" - various interest groups will organize via Telegram (or similar) to mass-report tweets they don't like.
I wonder if you could strike a balance by incorporating downvotes as a visual metric, but not using it to rank content, thus allowing the expression of dislike while removing the abuse vector.
reply