The only thing FreeCAD has going for it is that it's free, everything else about it is far behind the serious commercial tools.
> Ideally I'd like to see some sort of editing graph where you can see intermediate steps and pick visually parts to operate on for the next step - all underpinned by a concise textual representation that can be versioned.
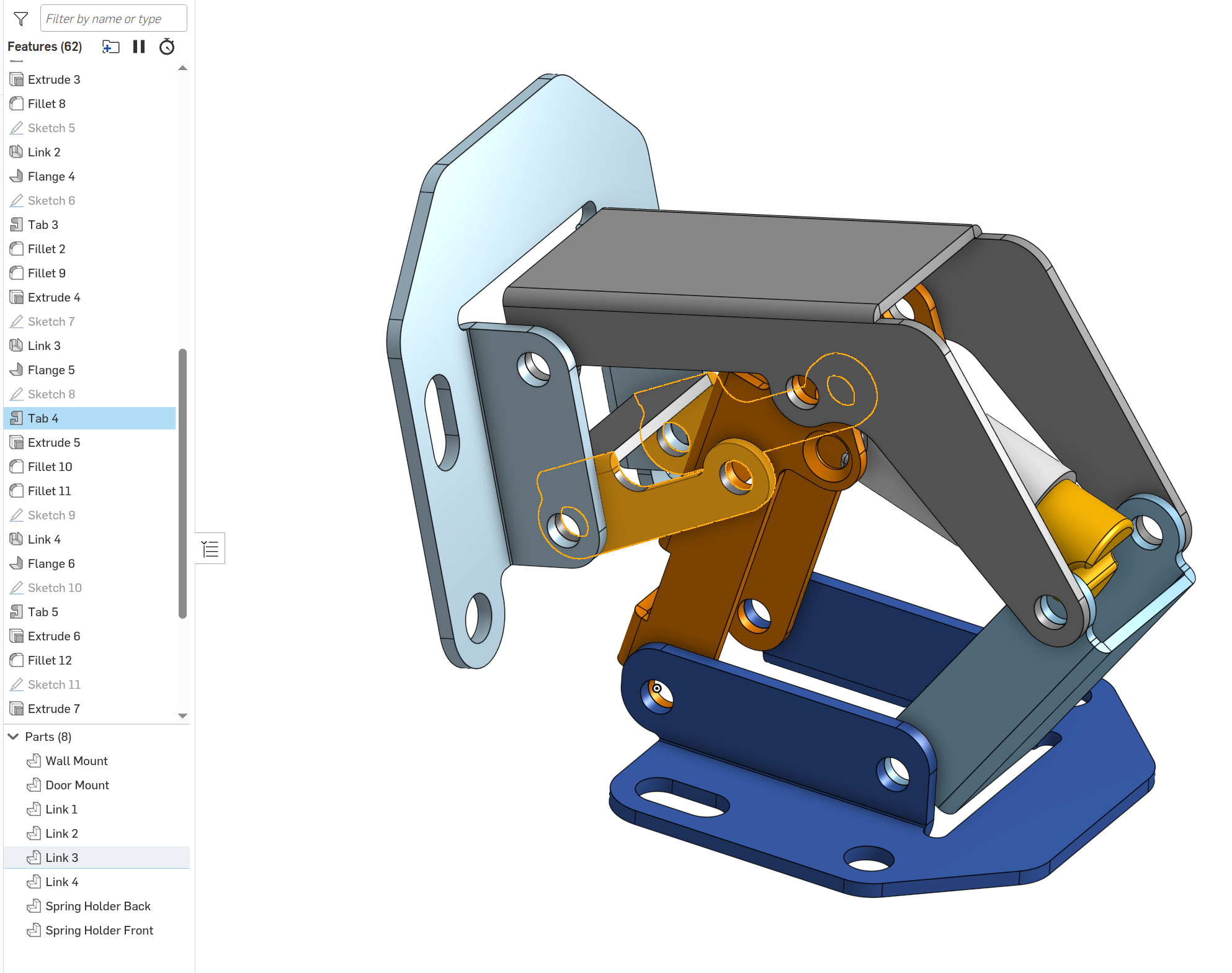
This is exactly how most[1] commercial 3D CAD packages have worked for at least the last 30 years, they've done it longer than Git or SVN have existed. Specifically everything is represented as a list of operations (sketches, extrusions, chamfers, etc.) and you can freely go back and edit any step, or you can click on any part of a model and see exactly what step was used to generate it.
Some CAD packages will let you see a textual representation, but it's only really useful for scripting when they do. The versioning tools that are built in to any CAD package are far better than trying to work with text.
[1]: Excluding the more obscure CAD packages like Creo that do things differently to fit in to a specific niche.
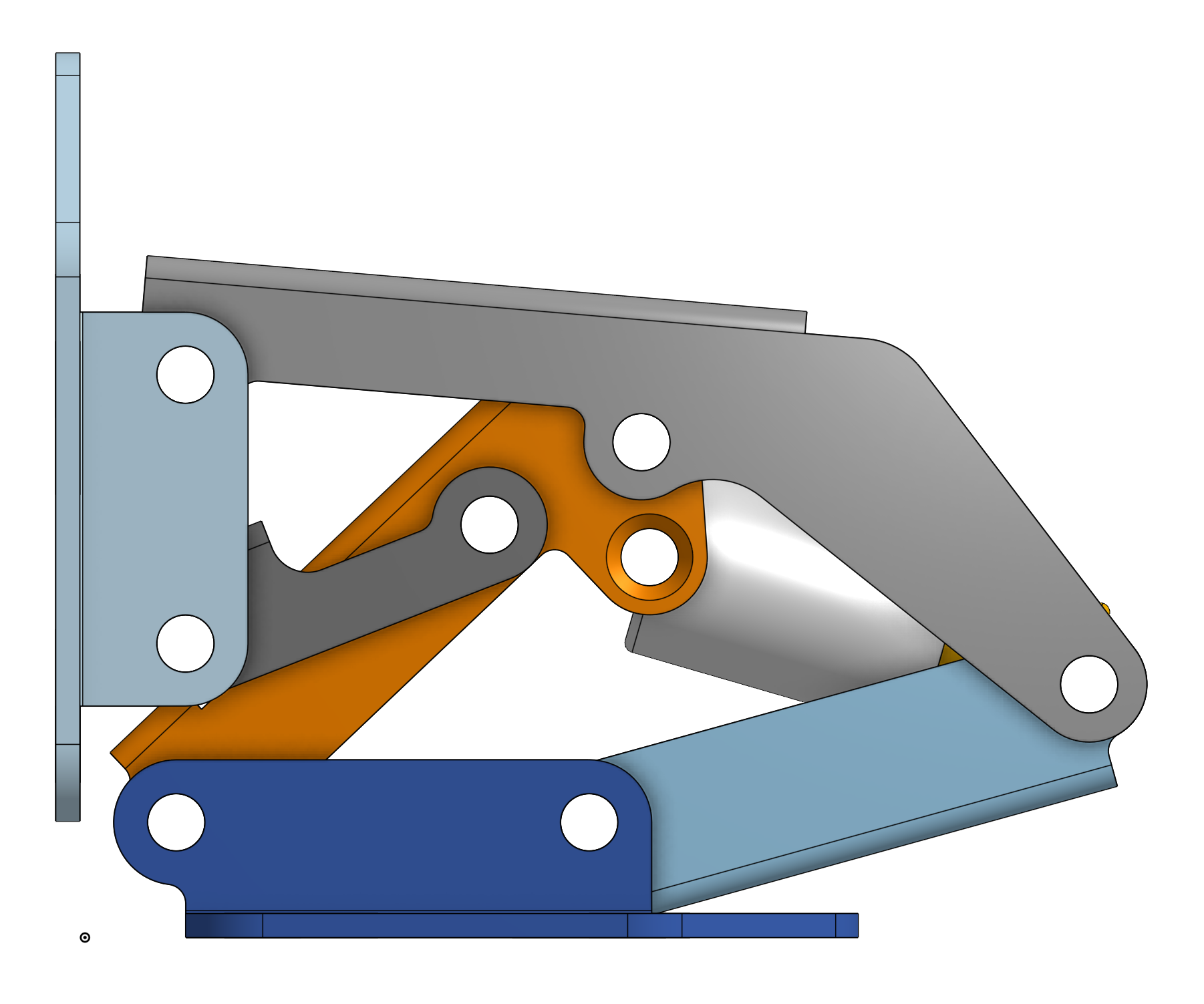
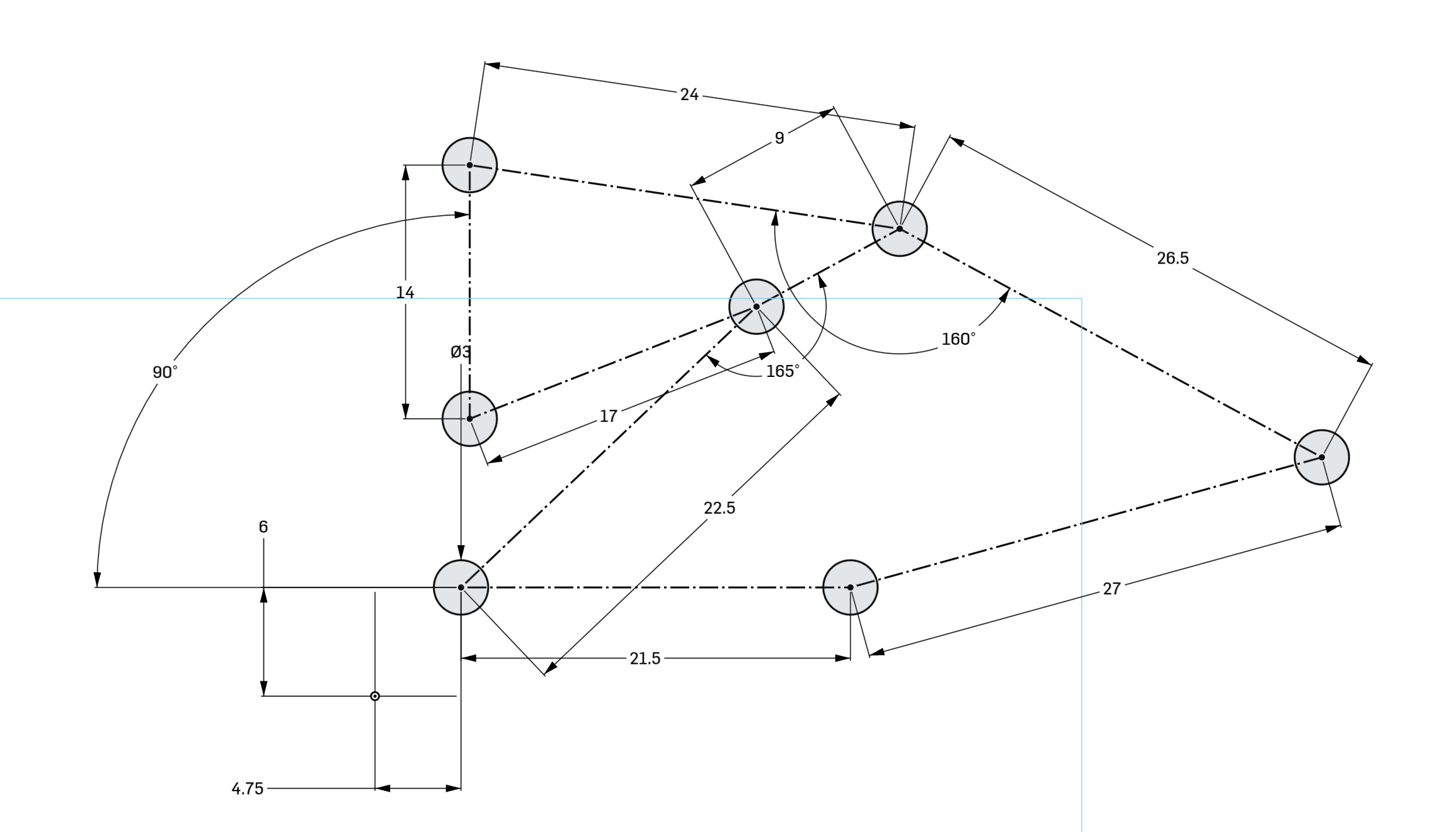
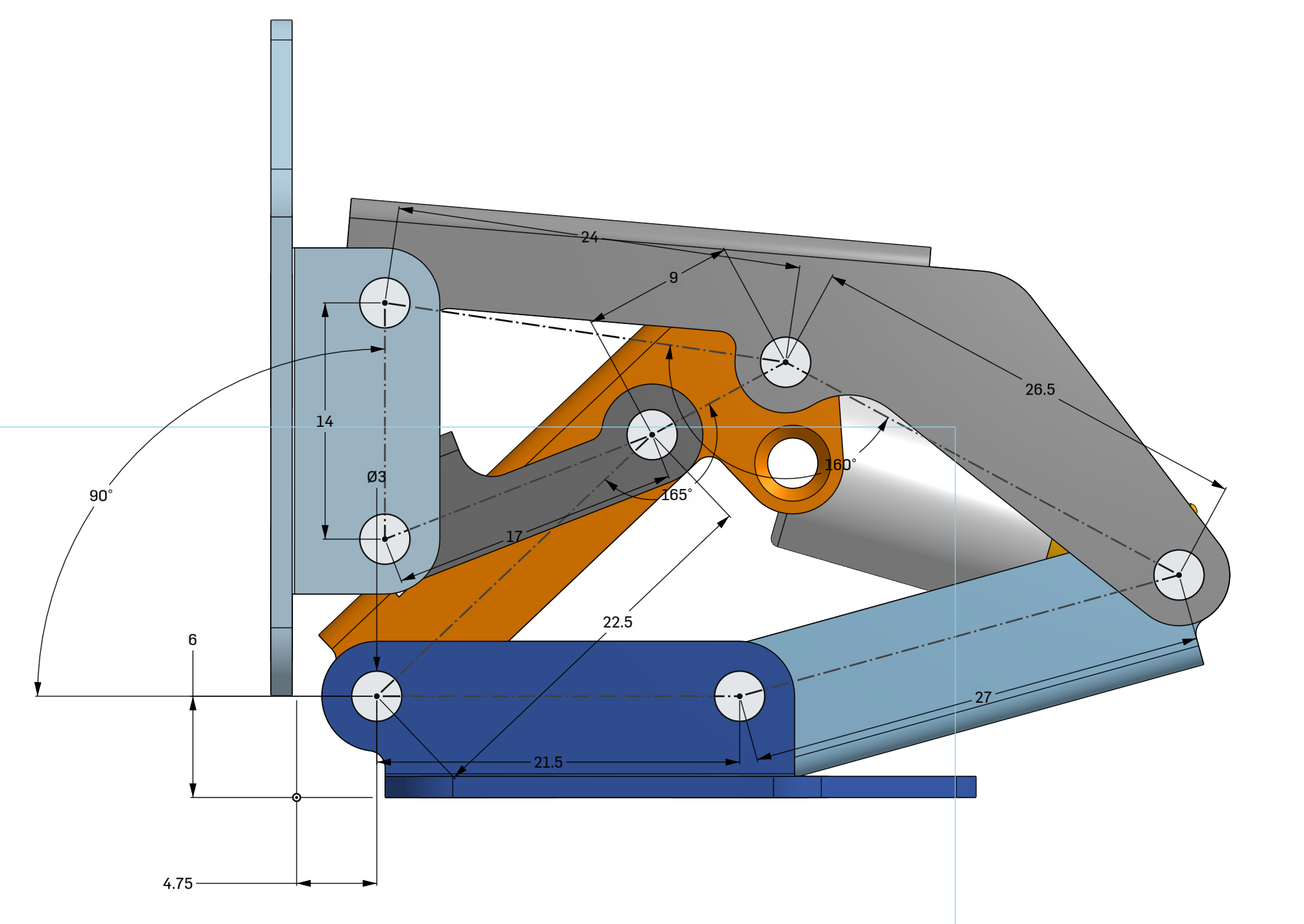
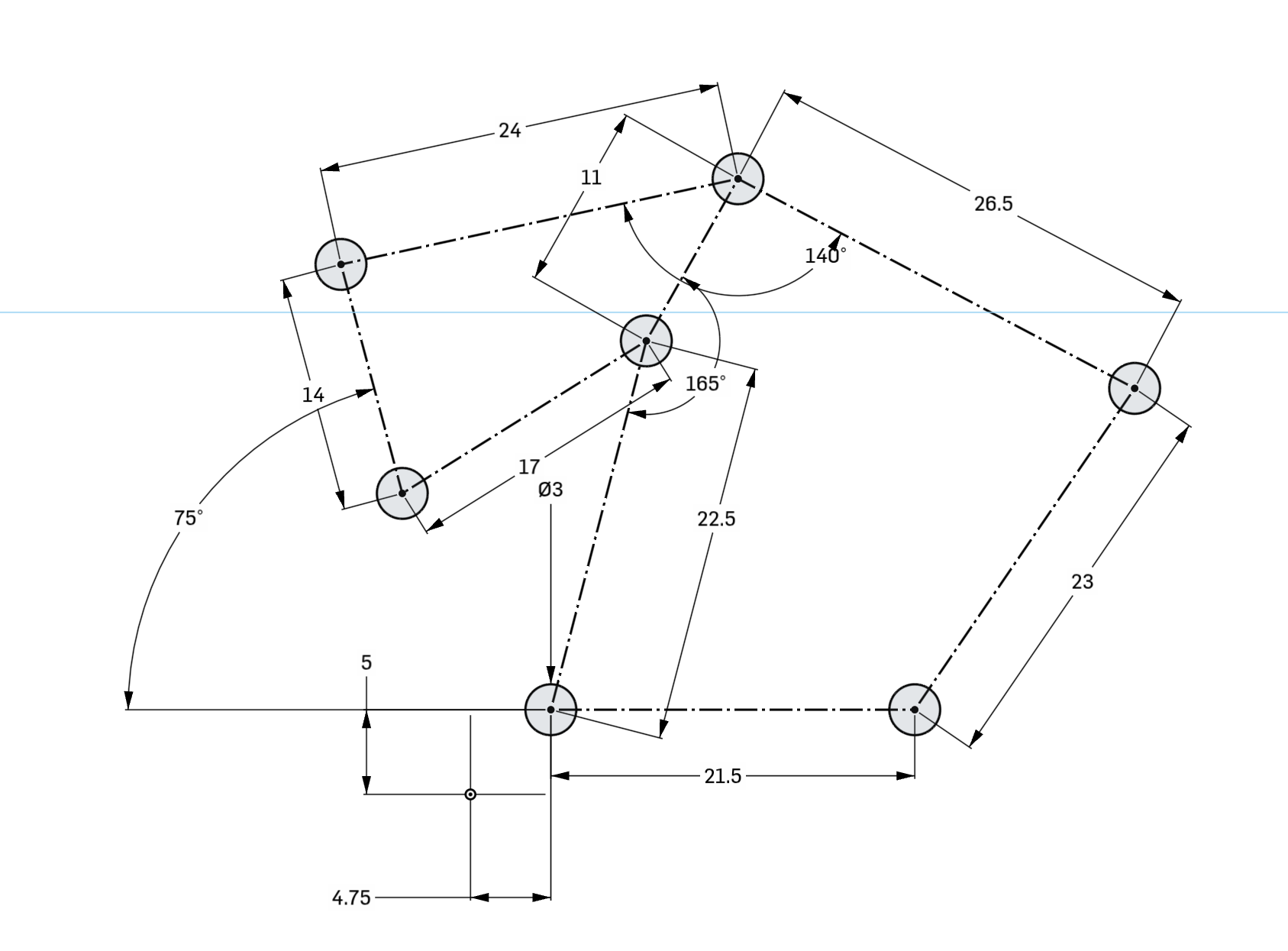
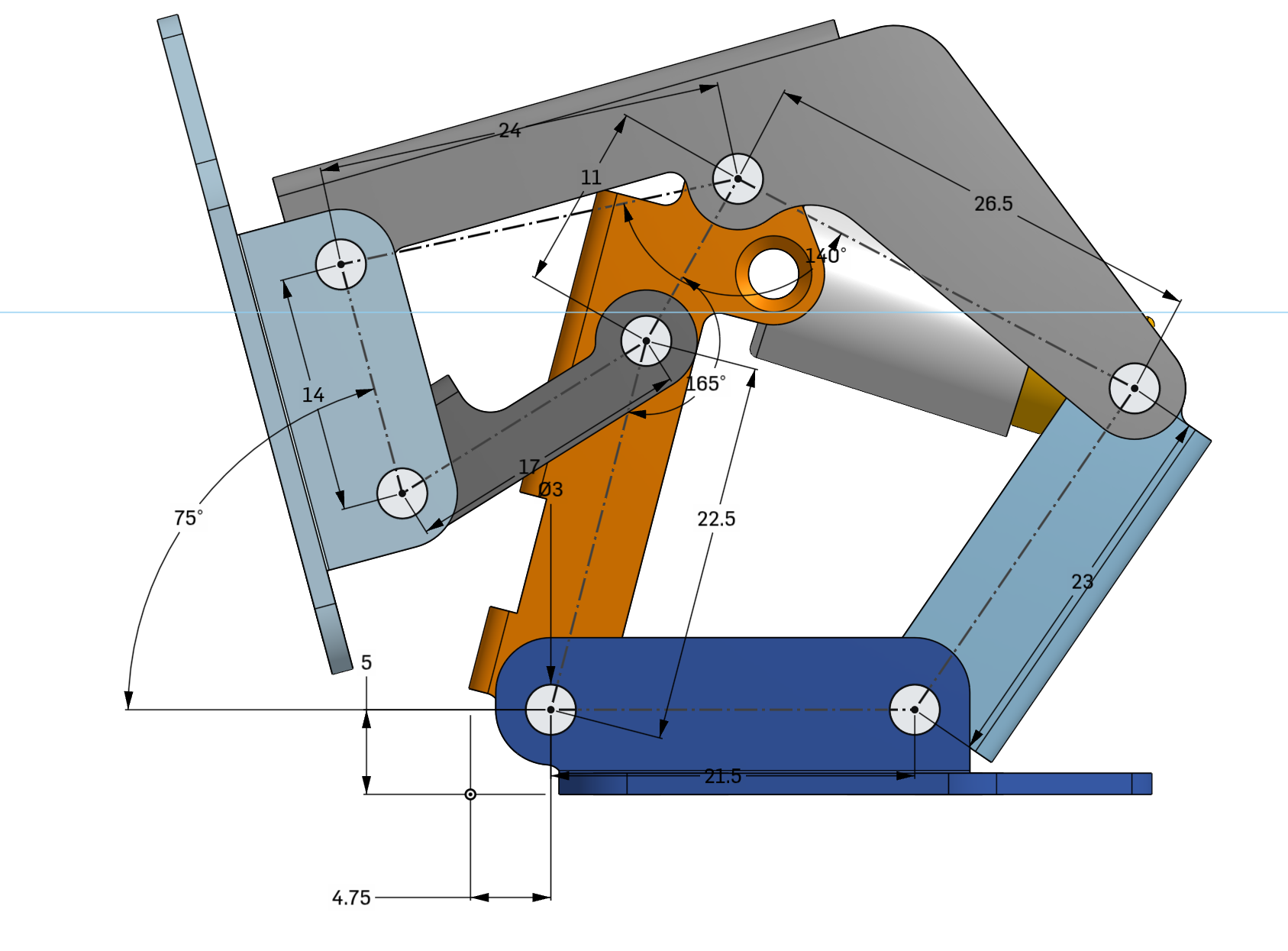
Just like that the entire model has changed based on the initial sketch. I didn't have to go edit any other features here.
As a bonus here's the assembly being moved by dragging the mouse after those changes, showing that this might not be the most well-designed hinge after those changes: https://files.catbox.moe/eztkja.mp4
Also here's the timeline I mentioned, you can see how I've clicked on a feature and it shows me exactly what it did, this also works when clicking on part of the model: https://files.catbox.moe/f0bb2k.png
Well, like I said: From open tools I had available b123d was the one that relatively quickly (within a weekend from picking up the tool) allowed me to mock up something to the point where I became confident enough to keep going.
I tried to do that with FreeCAD without too much success. I assume someone proficient with it could probably crank out the whole thing within an afternoon, but not me.
I'm sure professional tools are many times more productive, but you need to spend thousands of dollars and presumably months if not years of training to become proficient in them.
And admittedly that's more of a weird hangup of mine but to me it also sort-of misses the point to use a proprietary tool for building an open source project. No one without the tool could open the source files and make modifications.
At a high level I think a lot of it is simply hubris from software engineers who see the basics of electrical engineering or 3D CAD and think that the basics are all there is to the field. It's the same as when people see a hello world or fizzbuzz program and think that's representative of software engineering before proposing no-code solutions.
Anecdotally as someone who studied mechatronics: Software engineers are far worse than any other engineering field in assuming that everything is trivial compared to SE.
100% is always just an arbitrary value chosen by the device or battery manufacturer, there's no 100% level inherent to a battery. Unfortunately there's very few manufacturers that will tell you their estimated number of cycles and none (as far as I know) that will give you the number of cycles as a function of charge percentage.
Yes, but no. There is an absolute number that the circuitry tracks internally. The hardware does several kinds of measurements to count every joule entering or leaving the battery. The system knows exactly how much energy is in the cells.
The arbitrary value is what voltage you stop charging at. You set your maximum cell voltage and stop charging once you reach that voltage AND input current is below a threshold. Once charging is complete, you store the current energy value as the latest full capacity. That value then becomes the 100% mark.
Remember that batteries lose capacity over time. You must continually scale your state of charge percentage to the actual state of the battery.
The final charge voltage is a tradeoff between safety, longevity, and usable capacity. Higher voltages squeeze a few more joules into the cell at the cost of much faster degradation and increased risk of catastrophic failure.
A cycle count figure on lithium cells is pretty much worthless. It depends quite a lot on exactly how you cycle the battery. A 100 to 0% cycle is much, much more damaging that a 100-50% cycle. Higher currents and temperatures degrade the cell faster. Most cell manufacturers I've seen do give cycle counts under specific test conditions, but that's hardly applicable to real use cases.
It's not arbitrary. Lithium batteries charging uses voltage termination, and the usual cutoff for 100% on lithium-cobalt batteries (so not LiFePO which is not yet widely used on phones) is 4.2 volts. It's the same for all batteries I've ever used or heard about. You can charge it to higher voltages, but basically nobody sane does that as it quickly becomes dangerous, and 4.2 is pretty much the standard voltage.
Pouch batteries straight from distributors might all recommend 4.2V, but what's actually used in phones varies a lot. The Samsung Galaxy S21 for example charges all the way to 4.4V. I don't have a huge sample size to work with, but I have seen a number of recent Samsung batteries degrade alarmingly fast, likely because of this.
According to [1], the S24 has gone all the way up to 4.45V.
I was surprised to read the label on a GoPro battery and see it rated to 4.4v or thereabouts.
I used to build quadcopters around 2015, and some of the battery mfgs released "LiHV" batteries, which were supposed to be safe up to 4.35v, however if you actually charged them that high, they would puff up like balloons after only a couple flights. Maybe with the cumulative advancements in the last 10 years, they've been able to push up the max voltage more safely.
> So, essentially, no company out there supports all these stores, and you just train users to bypass these warnings.
This just sounds like a problem with your company. The barrier for getting certs from a public CA is lower than ever now that Let's Encrypt and others exist. If you really must have a non-public CA then your company needs an IT team that can properly manage that.
> This just sounds like a problem with your company.
I have seen that pattern in enough companies to be convinced this is widespread.
> The barrier for getting certs from a public CA is lower than ever now that Let's Encrypt and others exist
I don't think you understood what I'm talking about. Public certificates are cute for your public website, but any sizeable company is _also_ hundreds of internal websites and services, especially for the non IT departments. Think legal, compliance, accounting, HR, etc.
Most companies use a private CA for these, and that makes sense:
- You want subsigning CAs for your VPN, contractor services, websites, teams, etc.
- You want private DNS to private IPs (lots of ISPs won't even serve your private IPs through their DNS caches)
- etc
> If you really must have a non-public CA then your company needs an IT team that can properly manage that.
On the contrary, managing private CAs is what most companies do _well_. What they don't (and honestly nobody can) do well is distribute CA certs to user devices. This is often not done right on work devices, but BYOD made it even worst. No company can distribute its CA certs on the hundreds of different stores that one could think of, so after 2 years, some benign change of default corporate browser for users ends up with them learning to auto bypass certificate warnings.
Nothing stops you getting a cert while pointing your DNS records to internal addresses. The DNS-01 challenge exists to serve exactly that kind of configuration.
> lots of ISPs won't even serve your private IPs through their DNS caches
I have never seen this, could you give an example? However, if this is an issue then there's nothing stopping you from just using your public DNS for DNS-01 challenges and using your internal DNS for everything else.
It is also impossible for your ISP to do this if you're using DoH or DoT, which you really should be, especially if you already know that your ISP is messing with DNS traffic.
> You want subsigning CAs for your VPN, contractor services, websites, teams, etc.
You can't do this, but you can have your own ACME server that forwards requests to a public CA if you really need to let different teams manage their own certs. A better option is probably to use one of the paid CloudFlare tiers where you can create scoped API keys that provide DNS editing access scoped to a subdomain, or you could of course host your own DNS server or find a different DNS provider that offers this service.
We have a team who uses a ".dev" domain for local development (with a publicly issued SSL cert), with an A record of 127.0.0.1.
We had someone new join the team and couldn't get the dev environment working. Turns out his ISP's DNS wouldn't resolve to an internal IP. Simple fix was updating his system DNS away from his ISP. We only saw this happen to one person, so wouldn't say it's common but it happens.
That's protection against DNS Rebinding attacks -- you don't want external domains to be able to make same origin requests to internal domains, and while it suffices to only block changing resolution, that's harder than blocking internal IPs altogether.
They've clearly read this to write this article. I don't understand why they don't at the very least reference it, even if they don't provide a direct link.
Edit: See other comments. Some CVE board members have posted this on their social media accounts however there's still nothing on any official CVE channels. It's a little concerning that this was upvoted to the top of the front page before those comments had been posted given that this is a newly registered domain running on Google sites for something that it says has been in the works for a year.
Original comment:
Why is this being upvoted? There's no reference to it on the CVE website and the domain was only registered after the letter leaked despite the website claiming this was in the works for a year.
Additionally the WHOIS claims that the registrant is "CVE Foundation" which can not be found using the IRS search tool for tax-exempt organisations (note that MITRE does show up here): https://apps.irs.gov/app/eos/
Seconding this. A program like CVE still has to be built on (to some extent, and at least in the initial stages) traditional, non-cryptographic trust.
Who runs this thing? Who's funding it? Who's reviewing, testing, and approving the reports? Assigning them IDs?
I'm hoping for the best, and I'm willing to give the benefit of the doubt because of the frankly crap timing around this whole mess, but on its face, in its current state, I wouldn't trust this org at all.
Extremely. We are all extremely happy to see it. No data Sharimg with the Whitehouse, keep the tsunami at bay.
Not, "All your updates are belong to us."
And...
A personal thanks to every security researcher who has contributed. In.The last year. I see a CVE, and specifically look for the out-or-band update and patch everything that powers up.
One breach on an old ladies laptop, who had the sence to bring it right to me. Keep those covers on the cameras folks.
Can you expand on your thoughts here? What is the root issue with unsigned integers? Is your complaint primarily based on the implications/consequences of overflow or underflow? I’m genuinely curious as I very often prefer u32 for most numeric computations (although in a more ‘mathematics’ domain signed ints will often be the correct choice).
Unsigned integers are appealing because they make a range of invalid values impossible to represent. That's good! Indices can't be negative so simply do not allow negative values.
The issues are numerous, and benefits are marginal. First and foremost it is extremely common to do offset math on indices whereby negative values are perfectly valid. Given two indices idxA and idxB if you have unsigned indices then one of (idxB - idxA) or (idxA - idxB) will underflow and cause catastrophe. (Unless they're the same, of course).
The benefits are marginal because even though unsigned cannot represent a value below the valid range it can represent a value above container.size() so you still need to bounds check the upper range. If you can't go branchless then who cares about eliminating one branch that can always be treated as cold.
On a modern 64-bit machine doing math on smaller integers isn't any faster and may in fact be slower!
Now it can be valuable to store smaller integers. Especially for things like index lists. But in this case you're probably not doing any math so the overflow/underflow issue is somewhat moot.
Anyhow. Use unsigned when doing bitmasking or bitmanipulation. Otherwise default to signed integer. And default to i64/int64_t. You can use smaller integer types and even unsigned. Just use i64 by default and only use something else if you have a particular reason.
I'm kinda rambling and those thoughts are scattered. Hope it was helpful.
That doesn't compare to RDP where remote windows act just like local windows in that you can resize them and drag them between monitors, they're not constrained to just being on a virtual desktop.
RemoteApp is basically RDP for one single desktop app running on the remote server but launched and run to appear like a local app. It's improved a lot over the past decade+
There's an extra interesting feature there where the remoteapp windows are aware of each other. It's a niche use case, but the remote side counts as one session, so apps can interact and automation/accessibility mostly works as expected. Although the local system still sees the remote apps as opaque rectangle rather than widgets.
> The completion seems good to me. In fact suggesting "speed" as a parameter seems unexpectedly good rather than nonsensical.
I can't see any way the "speed" could ever be the next item in the series "velocity, acceleration, jerk, snap", could you explain how it could be? It's an extremely common sequence so it should be something a LLM can get right easily. Even the auto complete in a Google search gives the correct answer.
> Foes anyone really expect better than what your images show which in my opinion is pretty damn good. Do you really expect to write a program just mindlessly hitting tab all day long?
The other examples (and most of my other tests) show variables and types being invented that don't exist anywhere in the code base, how is that good? In both of these cases the LLM is strictly worse than my regular auto-complete that gives the correct result. I fail to see how a downgrade from that can be considered good.
You cant see any connection between speed and velocity or acceleration? Speed and velocity are literally synonyms at least in the common use and certainly as close to velocity as acceleration.
But hey noone is forcing you to use this tool right so just turn it off I guess.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
> Ideally I'd like to see some sort of editing graph where you can see intermediate steps and pick visually parts to operate on for the next step - all underpinned by a concise textual representation that can be versioned.
This is exactly how most[1] commercial 3D CAD packages have worked for at least the last 30 years, they've done it longer than Git or SVN have existed. Specifically everything is represented as a list of operations (sketches, extrusions, chamfers, etc.) and you can freely go back and edit any step, or you can click on any part of a model and see exactly what step was used to generate it.
Some CAD packages will let you see a textual representation, but it's only really useful for scripting when they do. The versioning tools that are built in to any CAD package are far better than trying to work with text.
[1]: Excluding the more obscure CAD packages like Creo that do things differently to fit in to a specific niche.
reply