Scrum is really useful for exploration and innovation work, things that may not even involve programming.
In general I think sticking to Scrum for Software Engineering is overkill, or maybe the 2 week sprints are too short.
I've had much happier engineers and product owners when working in Kanban, a steady stream of work with as few meetings as you can manage is much better for SE work, it is harder to get it up and running though, and can take some time to bed in.
Im not a 3d artist, but I still find Ian Hubert's blender tutorials[1] very cool to watch.
He comes off as an artist who immensely enjoys their craft. I have also really enjoyed his Dynamo Dream series [2] which are a labor of love for him. He's only released like 3 episodes over several years, but hey labor of love.
Ian was also chosen as the director of Tears of Steel (2012) which is one of the Blender Open Movies [3] the foundation produces. You might not recognize that film, but many of you have heard of at least one Blender Open Movie, Big Buck Bunny! A big nod (IMO) from the Blender foundation that he represents the spirit of the project and community, as well as has the skills to oversee a project meant to demonstrate Blender's capabilities.
These Open Movies are projects that HN can likely appreciate, as they are created to showcase and help push capabilities of the open source Blender software, are licensed under Creative Commons, and their assets are provided to the community for free.
New title: 16yo watched ALL the Ian Hubert tutorials
But who can blame them? Ian's tutorials are some of the most entertaining videos out there, especially his lazy tutorial series: https://www.youtube.com/watch?v=JjnyapZ_P-g
UK also has "free schools" which are similar to state schools but unaffiliated with education trusts, normally setup by parents, locals, the community.
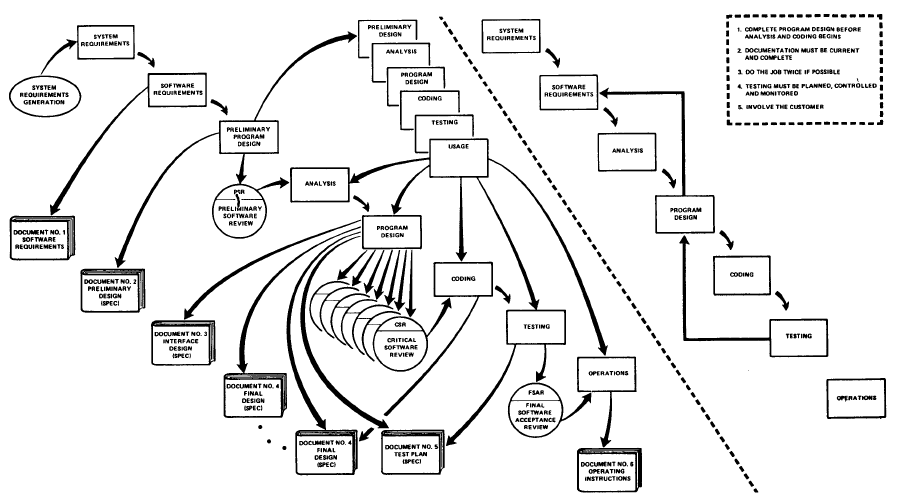
Winston Royce actually did have an iterative process as part of Waterfall, it was in his final model, and the diagram was on the next page of the document that most people fail to recognise.
My recollection from the paper is that he presented what’s typically discussed as waterfall at the start of the paper, and from there developed the iterative process.
Neither process was explicitly called “waterwall” - and the former is what I was taught at software engineering school.
Royce's model wasn't Waterfall. Waterfall is the model he started with, knocked, and then improved on. Idiots in DoD (and from there industry) mistook his first figure as the target, and not the thing to avoid. They codified it in a standard and it has been the cause of much government and government contractor waste ever since.
Microservices are more an organisational thing than a recommended pattern, when a project grows and wants to hire more staff to increase its bandwidth then microservices are a great way to support that, the additional benefit is that they work great in a CI/CD setup so you can release seamlessly.
GraphQL from what I can tell supports web developers rewriting their APIs when they need to instead of waiting on back-end teams to support them.
Most of my projects have just a single team in charge of a single code base, so there seems to be no need for microservices at all, and yet some people keep bringing up that we should really look into microservices.
My impression is that GraphQL is great if you're building an api that's going to be used by lots of different teams with different needs and the api developer doesn't know what they are. Again, with a single team doing everything, there's no need for it at all. But we're using it anyway.
Also, they keep talking about a Single SPA Application, and I can't tell if that's just a redundant way to say SPA, or if it's really something new, or if they're just messing with me.
> My impression is that GraphQL is great if you're building an api that's going to be used by lots of different teams with different needs and the api developer doesn't know what they are.
This has been my experience as well. It provides flexibility to the consumers of the API to structure things how they want and fetch only what they need. E.g. if you add a new field, there isn't any impact on existing users to make any changes since they are not specifying it in their current request anyway. To certain extent, that also helps with things being somewhat future proof because even if you knew what the users want today, you can't predict what they will want tomorrow.
Having done a bunch of REST and GraphQL APIs, the only thing I would say for GraphQL is to avoid re-inventing the wheel and use a stable third-party library to do as much heavy lifting as possible so that you can focus on the logic side of things.
{kind=link}