Before google analytics juggernauted the problem space, there were a bunch of log analysis tools which produced metrics similar to what the article describes, and more, locally and based on nothing but server logs.
Like the article, I recently realized that, while I did use it, I didn’t take advantage of google analytics at all so decided to nuke it from my sites. I had additionally been running webalizer for over a decade, but recently replaced it with goaccess (took about 10 minutes to set up) which is more actively maintained and have been quite happy with the basic metrics it produces. Sure it won’t stalk a user as they browse my site but I don’t care, just having an idea of how many hits I get, from which countries and which browsers is enough for my few personal and hobby sites.
I get a LOT of bot traffic with bogus user agents. Google Analytics does an okayish job dealing with it. Looking at web server logs and trying to reconstruct traffic patterns from just real users would be real chore.
I abandoned GA because they wouldn't do anything to fix the problem with referer spam. Unless they've finally fixed it, a lot of the stats they produce are from non-users.
I mean, that sounds like more of a feature than a bug. You shouldn't know exactly what people are doing on your site (too invasive), but this approach gives you a rough idea of which requests are being made.
I personally find it to still be too revealing in some cases, which is why tools like the nginx IPscrub module[0] should be the upstream default IMO.
> mean, that sounds like more of a feature than a bug. You shouldn't know exactly what people are doing on your site (too invasive), but this approach gives you a rough idea of which requests are being made
Why not? Why wouldn't you know what people are doing on your website, within limits? Which section is getting most visits, which is the slowest, how many elements people click on in your lists, etc etc can have immense value in deciding what to do with your site, what needs work, what doesn't work at all, etc.
I typically see software from the perspective of software freedom.
When a user downloads a web page from my server, I can temporarily record that an anonymous user made a request because I'm only logging what the software I'm running on my machine is doing. After that, the user should own that downloaded copy of the page and use it freely without surveillance from me or anyone else. The only restrictions in place are those set by the license (hopefully AGPLv3). Beyond those restrictions, the software doesn't belong to me anymore so I don't collect metrics.
It's true that I won't be able to get detailed metrics about what the user is doing, but it's also true that user's copy of my software will only be serving the user directly.
Web apps aren't different from other software; telemetry and user studies should be opt-in, transparent, and sent back only with informed consent. Only then can I consider running analytics.
I was deeply amused by the title. In my world using shell scripts to analyze access logs is the obvious solution and using google analytics is the exotic approach that you might come up with in very few special cases.
AWK & SED :) one of the better books I bought when studying. Often parsing a logs to find some things that other logging don't record/show for a manager. Often you hear the same phrase
'You can check logs like that, and you don't need a browser? How... magic....'
I just deployed Plausible.io[1] for my blog $6/mo on a droplet, it's self-hosted and 100% open source. It seems very privacy focused, and provides basically the same minimalist data described in this article.
I always find it weird though that privacy advocates still go for "I have this hidden treasure trove of analytics about my site that you cannot access"
Analytics should always be 100% anonymous and aggregated. And if you've met those two bars, making them open and public should be a non-issue. If you can't make your analytics public, that's called spying. There should be no issue making your analytics public. Mine are[2]
Analytics are business intelligence. Showing which of your content works well and which doesn’t.
The idea that there should be no issue sharing them is absurd. Yeah just publish the minutes from your marketing strategy meetings as well while you’re at it. Invite your competitors to go over your books with you and your accountant and then arrange meet and greets with your most profitable customers as dessert.
Sure, in the same way that code is intellectual property and should never be shared, and all ideas should all be patented in case they become worth something.
In all seriousness, I'm OK with that as long as people are honest about it. Just say "We track our users to collect business intelligence." and I'm happy.
We all would love to know what Google page ranking algorithm is. Disclosing any business information whether it is in the form of code, analytics, financial information, customer data, etc. sometimes makes sense but more than often, doesn't.
> Disclosing any business information whether it is in the form of code, analytics, financial information, customer data, etc. sometimes makes sense but more than often, doesn't.
While I agree with the spirit of your comment, this is a very sweeping generalization. Many kinds of financial information are being shared regularly with the public and for publicly traded companies they're required by law. Many companies build their infrastructure on open source software, with proprietary glue being a small percent.
Knowing what you can or even should share (for marketing purposes) is crucial. Especially knowing that keeping information asymmetry forever is impossible.
> Many companies build their infrastructure on open source software, with proprietary glue being a small percent.
This too is a sweeping generalization ;), a good one though. We're pretty fortunate to have a lot of our building blocks made using open source software. Boost libraries to openssl, most of the stack is open source including the programming language. Although, the proprietary glue is the important bit.
An architect's work is more than just bricks and mortar.
I am not disagreeing with you, but imagine if all business were completely open about all those things. Yeah, maybe your particular business would fail, but the net result would be the truly most effective business to succeed. Which would be an overall win for society. It would also mean that small players would have more of a chance, because they'd be able to build on big players failures/successes more easily. I suppose counter argument would be that it would inhibit people from taking risks, because the gains would be shared, while the failures would not.
Big businesses will just find ways to circumvent it like starting meeting with a copyrighted poem and arguing that minutes can’t be shared on copyright grounds (or similarly absurd loopholes) which smaller businesses wouldn’t think of doing. Thus big businesses end up getting a greater competitive edge.
Basically whatever process you put in place to level the playing field, big businesses will find a way to game it to their advantage because they have the resources to do so and the deep pockets that allow them to take risks.
I’d actually argue that this would have detrimental effects. What’s stopping a company from visiting your site, seeing what’s popular, and stealing it all for themselves?
What do you mean by stealing? Other companies could offer the same products you offer already. If they know what people want they will spend resources trying to optimise things based on data, instead of guessing. Some other company may find a better/more efficient way to offer the popular products, which is better for everyone.
It's a way to level the playing field. The idea is that, if everyone has access to all the data, then there's more opportunity to make all business more efficient, whereas if some businesses hold information about the market and costumers for themselves, then they get to be sloppier in their implementation because they are already so far in the game.
This is a good point and I agree for most businesses, you wouldn't want to publish your bi. But slimsag makes an interesting & valid point: that if you are confident enough in the privacy policy of your analytics, you should be able post it publicly without alteration.
Well even if you know that nobody can be identified from your data alone, if everyone releases data, it will become easier and easier to cross-reference and still identify people.
Instead of what solutions like Plausible are meant to do (only give a responsible well-defined party access to the data), now everyone can view your website users potentially PII.
Sure, someone could send out unique links to random `utm_campaign` IDs and see "did the person click it?" and I agree that's a bit nasty.
But even if you do convince someone to click _your_ link, what good does that do? We can see you yourself clicked that link from Germany on a mobile phone, and that's literally it. We can't get your IP address, or any PII - it's not stored.
You were able to verify what level of information my site is collecting *because* it is public. That is simply better than me spying and recording everything you do and you just having to "hope I never accidentally release it or sell it to someone" as is the case with modern tracking.
> Germany on a mobile phone, and that's literally it
Yes, and _that's it_! Just by getting someone to click on a site they find trustworthy, you are now able to extract country, device, browser, OS, time of access, and to some degree other pages visited on the website. This in itself may not be PII, but together with previously known data points may be enough to assemble PII.
Yeah, and I don't think that's a good idea that they do without any warning of the implications. If they make it easy to expose data publicly, there should at least be some measures to ensure anonymity like e.g. differential privacy based querying.
For a product that markets themselves as GDPR compliant and without cross-site tracking (which this technique enables to a certain degree), that's not really a great look.
> You were able to verify what level of information my site is collecting because it is public.
I mean kinda, but not really. I have no assurance the "all the data you are showing me" == "all the data you have about me". In the end I still have to trust you that you don't collect more data and that you won't sell that data to someone else.
-----
All in all, I really appreciate what you are trying to do here in terms of transparency, and I'd like to see that spread. However I think there is still a lot of room for tools to improve to provide a similar level of transparency while also insuring users privacy.
> Yes, and _that's it_! Just by getting someone to click on a site they find trustworthy, you are now able to extract country, device, browser, OS, time of access
So you'd be using this as an overly complex IP geolocation lookup and UA header parser? All of this information is either already known to you when you trick someone to click on that link (because they are on your website so you get the same data) or can instead be obtained by tricking them into clicking on a link to your website instead of that one (if it's an email for example).
> The target may feel much safer clicking a link to knowntrustedsite.abc than yourunknownphisysite.xyz
Big doubt honestly, at least for the vast majority of people. Just set up some blog with some contest that interests them (can be copied from other blogs) and they're not gonna suspect a thing. People might notice if you pretend to be their bank but are actually a phishing site, but they don't notice if you pretend to be a blog and are actually a blog that harvests their data just like any other website.
I literally did the same thing last night! A DO droplet hosting a statically-generated site composed of html generated from some markdown and sandwiched between some html headers, then served up by the Rocket[1] framework.
It's my first website, and I think the total size of the backend is something like 40 LoC. I've never had any kind of analytics (or needed them), but I thought it would be neat to see what was going on. It took me all of 20 minutes to sign up, add the single Plausible <script></script> line to my index files and headers, and there it was. As someone with literally no other web experience, I can't imagine it having been easier. The cost of my website is now a whole $12/mo instead of $6, and I agree that it feels kinda nice to support a service that seems to place value on privacy and openness.
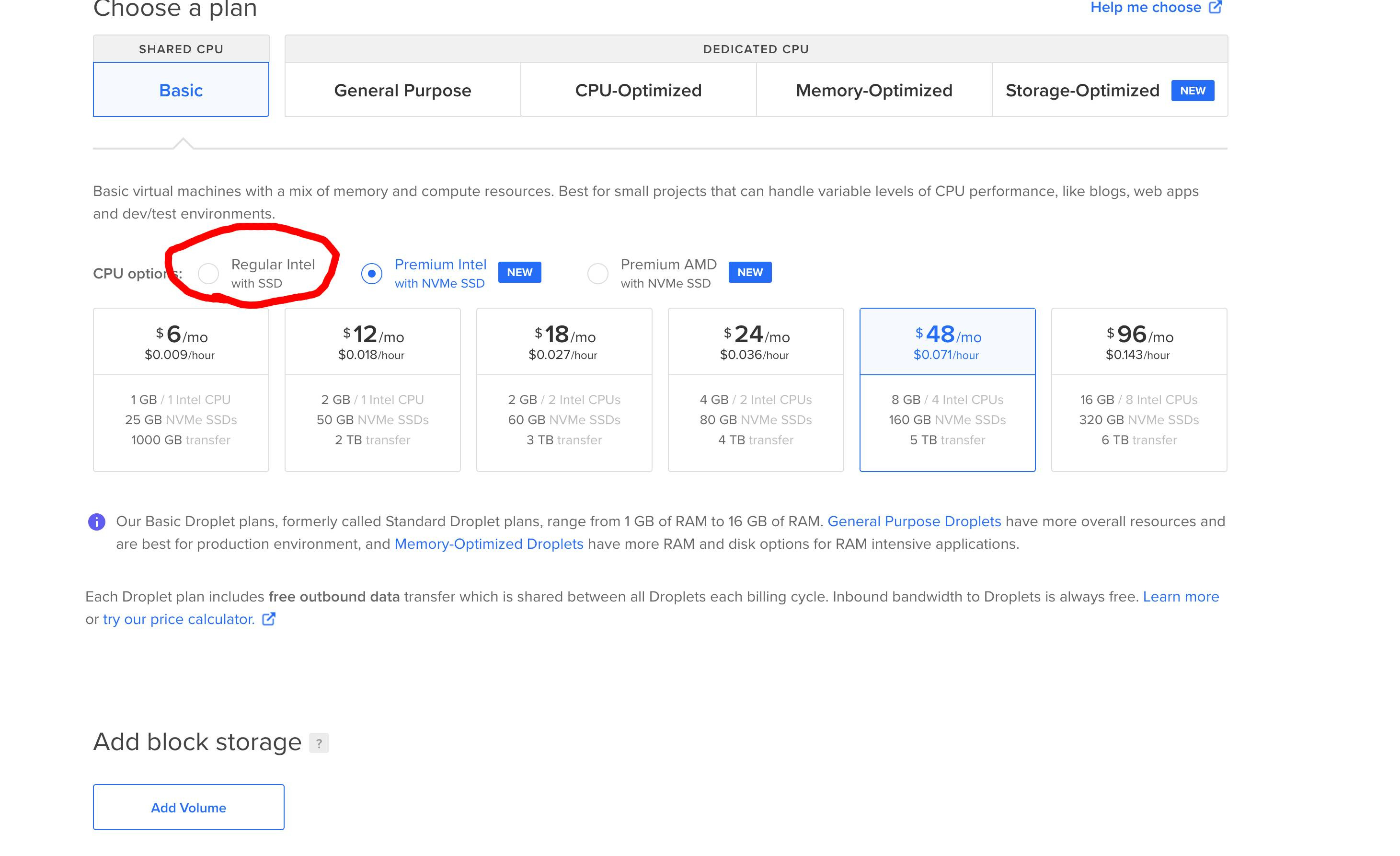
I wonder how many extra dollars cumulatively DO makes from the $1 premium on getting a better Intel CPU or AMD CPU and/or NVMe up sell on the smallest droplets.
I pay the extra dollar as well. I doubt I actually see the difference for what I use it for. I feel no desire to pay a dollar less though, so they are making another 20% from me on that product than they would have.
Ah, interesting. Was it offered at the time and you didn't choose it, or is it an older droplet that didn't have the choice?
I've had a lot of different droplets of different sizes over the last 6-7 years. Recently when I created a new one for a new project, I noticed that option and chose it. I'm not sure I would if buying a larger droplet, or a lot of small ones (I've done that for certain projects), but $1/mo is the point where it feels like nothing.
DigitalOcean is going downhill fast after the layoffs, I'm not optimistic about them in the long term. I'd love to know what they burn on marketing, because their video ads on YouTube are crazy.
> I think it's a little scummy that they go out of their way to hide it and make the more expensive options the default
Eh, I wouldn't call that hiding it so much as making the current market default the one they default to. If you're looking for the lowest end droplet, then yeah, it makes sense you would want the lower end Intel without SSD, but if you're buying something more expensive at all, there's more of a choice to be made.
Also, I'm not going to fault them for putting forth the option that allows them to more easily decommission what are probably older hardware and disks for newer offerings, especially when the "hiding" is just a radio button above the droplets. It's not that hidden. I suspect eventually the newer gen Intel/AMD offerings will lower in price and replace the current default.
> I'd love to know what they burn on marketing, because their video ads on YouTube are crazy.
That's interesting. I remember seeing some like 6-12 months ago on youtube for the first time, but I haven't seen any for a long while. I must have just been flagged as not part of their target audience (or Google has determined I already use them).
A while ago I noticed they set the default droplet to a more expensive one and moved the $5 option off the screen to the left so you have to scroll to see it, but it all lines up so it looks like there’s no more options. Minor change but a sneaky one.
OK, I find it hilarious that your open analytics say zero hits for the past few weeks until 70+ hits from today because you linked your open analytics on an HN comment... :-D :-D
Analytics of what? Analytics of your own stuff is not spying.
Entertainingly https://cpcchina.chinadaily.com.cn/ uses Google Analytics, while http://english.www.gov.cn/ (yes, no https) uses Alexa metrics. You can't even access the Chinese Communist party website without being "spied on" by US-based metrics companies. I don't think this proves anything but it's amusing to contemplate.
I switched my professional website to Plausible, and I am very happy with it. It gives me enough data to make business decisions, without tracking my users across websites. I also prefer its interface, which quickly lets me combine filters by clicking on things (visited this URL + triggered this event + came from this source).
It was satisfying to remove the cookie notice, and to update the privacy policy with "we do not collect any personal data". That's much more in line with how I want to operate a website.
On my personal blog, I got rid of analytics altogether. I don't care to know who visits my website.
I think he's looking at it from the user's perspective. Some privacy advocates may say that analytics have to be private not to make user's private data public. However, the point was that the only reason making the data public would violate user's privacy is that the data is already violating user's privacy, although only one party can access it.
I would imagine the main thing is not wanting people to or derive confidential company information, like how a certain marketing strategy is going or some other piece of data you can get from analytics.
I've been doing similar but with much more advanced bash script since about 2010 :-) I haven't used Google Analytics, after I learned how they use this data. I just never even thought about sharing this, because I thought no one would care. But I find like minded people on HN all the time ^_^ It's much cooler if you use this as a live script to watch for traffic. You can filter out only the pages you want to see for example. If there is any interest, I can share my scripts ;-)
I rather dislike the surveillance capitalism model Google promotes, but the article is a little unfair. As a payload, the snippet of code that calls the GA library is pretty lightweight and there are many ways to make this asynchronous: this really does not need to have a significant impact on user experience.
As an aside, I find Google's model to be less bad than Facebook's attention capitalism model because it permits a diverse, unoptimised and decentralised web, amp notwithstanding.
Google Analytics by itself is lightweight, but if you're at a large company with a marketing department, my experience has been that it never stops there. We've got pages with literally dozens of third-party Javascript trackers, and I've had to continually push back against requests from marketing to add more. While each one individually isn't a big performance hit, they add up fast.
Same principle applies to security: each of these trackers has basically full control over the page, and if one of them gets compromised and replaced by malicious code, it would be disastrous. The probability of any individual tracker getting compromised is low, but what you should be worried about is the probability of at least one being compromised, and that probability rises exponentially as you add more.
The probability that at least one tracker is compromised actually grows sub-linearly in the number of trackers.
Let n be the number of trackers, let p be the probability that an individual tracker is compromised, and assume compromises are independent. Then:
Prob(at least one comp.) = 1 - (1-p)^n ~~ np.
In other words, linear in n. This approximation is fine for small n*p. For large n*p, the probability has to be <= 1 of course, so the real probability is sublinear.
From my experience this is a function of client side libraries not having an "owner" in place to refactor. Marketing often doesn't know or care about performance, so of course they'll just want to add over time if it makes them more effective at their job.
When businesses invest in caring about this (and it can even be just one headcount for the biggest of businesses) there's opportunity to reign it in and maximize the value from a given platform, reduce it the need to add others. That helps with security, governance, and adoption of what's there.
Nevermind more forward looking solutions like server side which gets these injected scripts off your site completely and greatly improves security.
I think it's a tad disingenuous to focus only on the initial loading of Google Analytics. Presumably there is some ongoing cost to the user regardless of load time and it's probable that the blog was using the synchronous version. There may be many ways to make this asynchronous, but they chose the easiest way: removing it.
An alternative to rolling your own scripts is to use GoAccess for web lig analysis, which can both generate HTML statistics or you can open its ncurses based UI: https://goaccess.io/
Google Analytics has many more use cases than looking at vanity metrics to be replaced by a shell script. Something like https://hockeystack.com gets closer.
I run a self-hosted analytics tool called Matomo (via CapRover, a selfhosted PaaS) that I include on my static site pages. No third parties are involved unless you count Hetzner where I get my bare metal.
I wish Matomo/Piwik worked well on larger sites, or supported Postgres. It seems to start falling apart on my joke sites that get a few million PV/day.
You can also log requests and filter out obvious bots. Reading the logs, and using basic filters, gives you a decent idea very quickly. I suspect Google Analytics became so popular because people stopped running their own servers. And these days it's ridiculously easy to run your own server.
This works well if you run a server, but for a static site, you need client-side JS. I recently found 2 free AND open source services (though I did donate): GoatCounter[0] and Counter.dev[1]. I've added them to my static site[2]. Naturally they disagree on my (low in any case) traffic, but they're still fun to look at :)
If you don't want to pay for privacy-focused analytics (in case it's some non-commercial project/personal blog) then recently launched cloudflare analytics is the way to go.
That's what I did a couple days ago. Moved my blog from GH pages to cloudflare pages (and DNS). So far so good, and I'm seeing more views than before, when using goatcounter and seems more accurate.
If you want more out of your access logs, you can also use two free IP Tools we have recently created at IPInfo. This maybe less useful if your aim is to understand the website usage, since we are only creating a report based on IPs. But it can help you understand the type of traffic you're getting.
Summarize IPs takes in a list of IPs to create a report, like this[1], about location of IPs, if they are VPN/Proxy/Tor, and type of traffic. There's a limit of 1000 IPs here, but that can easily be circumvented by creating a free account.
Map IPs plots them on a world map, like this [2].
Both of them are free and can be used from command line. We will also filter out the text to find IPs, so you can just pass raw access logs.
The article approach requires access to apache access logs, so you'd need to host your static site on an apache (or other) server with logs you can access.
Yep, sounds like a lot of the authors found a cheap way to market their thing. I've been reading a bunch of the same type of Google 'replacements' promoting the same thing over and over. TBH, it gets annoying over time. HN should do something about this.
I wish there was something like this for JAMstack/JS only websites that you host on eg Netlify. I know Netlify has their own analytics but they're paid, which is fair enough, but hard to bite the bullet when Google Analytics is free.
Totally understandable that you would think that. Cloudflare also provides server analytics if you use them as a CDN. That doesn't work for single page apps which don't necessarily make server requests when the URL changes, so they introduced a new product ("Web Analytics") to handle this.
Sorry to hijack but I have a slightly related question: anyone know a good privacy-focussed analytics tool for apps that works nicely in React Native? Sort of like plausible.io but for apps
One of our [0] customers does something like that. He has developed a .NET framework [1] to send clicks to our API and monitor how his apps are used from our dashboard.
I’d actually argue that this would have detrimental effects. What’s stopping a company from visiting your site, seeing what’s popular, and stealing it all for themselves?
Half the point of GA is tracking users across sites for ad targeting. It is simply not possible without 3rd party cookies. First-party analytics can always be done with log analyzers or even just a CNAME on a hosted tool. That's just not what most marketers want or need.
{kind=link}
{kind=link}
A ton of them still exist : things like webalizer, goaccess, and the venerable analog. See the self-hosted category here (https://en.m.wikipedia.org/wiki/List_of_web_analytics_softwa...)
Like the article, I recently realized that, while I did use it, I didn’t take advantage of google analytics at all so decided to nuke it from my sites. I had additionally been running webalizer for over a decade, but recently replaced it with goaccess (took about 10 minutes to set up) which is more actively maintained and have been quite happy with the basic metrics it produces. Sure it won’t stalk a user as they browse my site but I don’t care, just having an idea of how many hits I get, from which countries and which browsers is enough for my few personal and hobby sites.