> Larrabee ran Compute Shaders and OpenCL very well - in many cases better (in flops/watt) than rival GPUs
Oh god the horror that was OpenCL on Xeon Phi.
1) It was extremely buggy. Any OpenCL program of decent complexity was bound to encounter bugs in their driver.
2) FLOPS are not the only measure for computations / simulations. The bandwidth is is extremely important for many applications. Whatever Xeon Phis OpenCL was doing was not achieving anything close to its peak. Any OpenCL kernels we had tuned would end up improving the performance of the host CPU (16 x 2 Xeon) as well. It would usually result in the Xeon CPU performing better than the Xeon Phis.
3) NVIDIA released multiple generations of their GPUs since Xeon Phi was released. The performance per watt on NVIDIA and AMD GPUs has been improving substantially over the last 3 years while Xeon Phi's stagnated in 2012.
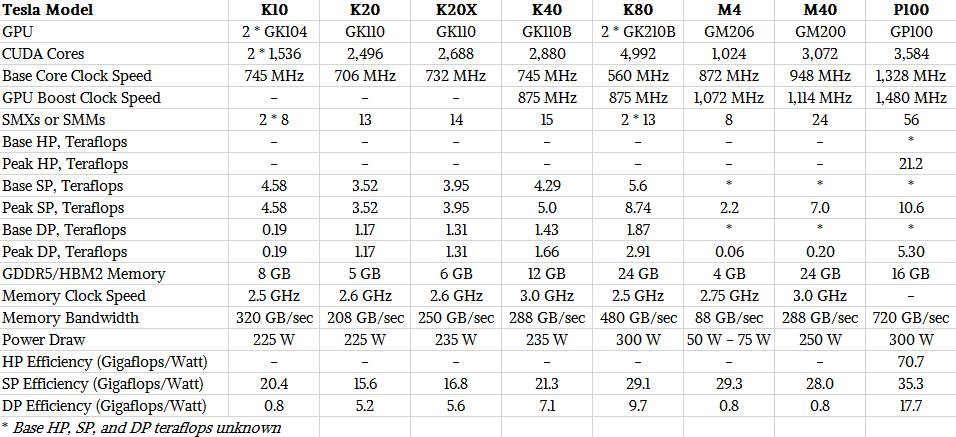
4) Even their claim for best FLOPS / WATT is wrong. The Tesla K20 released around the same time had the same power usage (225W) but about 50% higher FLOPS (2TFLOPS vs 3TFLOPS single precision).
The only selling point was that they were x86 cores and hence did not require rewriting your code. But you had to write additional directives indicating what part of your code you wanted to offload to your accelerator and when you wanted to get it back. The best performance ironically came after a lot of tuning for your application.
4 years down the line, GPU based accelerators still dominate the market and growing. and I wonder how many of the researchers who went with Xeon Phis regret their decision.
> The only selling point was that they were x86 cores and hence did not require rewriting your code.
Not quite; the selling point was that they were x86 cores and hence did not require hiring graphics programmers to write your GPGPU code. You certainly did have to rewrite and refactor to get code shoved onto the Phi, but a non-HPC-focused team could do such a rewrite+refactor with just the people they already had.
Cuda did not share many similarities to the graphics pipeline back then. Even now it's a stretch to compare the two.
x86 was and is still a weak selling point. Developers from all backgrounds are deploying their apps on varying architectures like ARM or the JVM without much stress. The hard part about writing code that is fast for an architecture is only made more complex by having your compute units be x86 rather than simple SP vector units of a GPU.
I know many folks without a graphics background writing cuda apps but no one outside of hpc research environments dabbling in the complexities of xeon phi.
The reason for this is simple; if you get your code to be in a cuda friendly structure you have created a data parallel rewrite that leverages the highly parallel memory bus of GPUs to get a pretty easy speedup. By being constrained to a semi opinionated programming interface people can see real speedups and not get bogged down in multithreading, multiprocessing, and buggy device drivers.
I agree with all of your points but I think KNL will be a turning point.
Traditional multi core CPUs simply aren't an option to advance in the HPC space any more. Per generation there's not enough of a performance improvement to make it effective. And buying more of them isn't feasible from a power perspective. So everyone is going to have to re-write for massive parallelism. I think Intel's KNL and future Knights will be the most attractive path for a lot of people. You have the tooling and familiarity of x86 and a simpler memory model than GPUs.
This is exactly the biggest downfall of the Larrabee/Phi programming model. The claim that you can just deploy your CPU code is simply wrong if vectorization isn't taken into account. I'd argue it's worse than porting it to GPU if you start with code that's "naively" parallelized for CPU with OpenMP statements without unrolling/vector intrinsics. The reason is that the actual kernel code can stay the same for CUDA, or it can be relatively easily transformed (something I'm working on [1]) - just take whatever was inside your OpenMP loops and move it into a CUDA kernel. Meanwhile for Phi I'd have to now care about two levels of parallelism instead of just one (multicore/vector).
The entire reason why GPU has been so successful, is that its performance is relatively predictable compared to x86 cores because of its much simpler architecture - and putting hundreds of them on a single chip doesn't change that. Granted, there are applications that will perform better on KNL than GPU (I expect), because it has a somewhat greater degree of freedom (although the bandwidth you get when actually using that freedom will be a deciding factor on whether it's actually worth it over the latest CPUs in those cases).
Right. The only thing that looks particularly different (compared with the typical HPC node intended for workhorse vectorized code) about KNL on paper is the memory system, and possibly integrated interconnect. Given the usual library support, I don't see why there should be significant re-writing to be done, any more than for other AVX transitions (unless you're developing BLAS etc.).
I've not dug into this enough yet but all prior generations of Nvidia GPUs have had caveats when adding steps to unify main memory. It certainly isn't "one address space" as far as the OS is concerned, perhaps Nvidia is saying this is sufficiently well enough abstracted in CUDA 8.
The true land of milk and honey is prophesied in Volta when paired with Power 9 and CAPI, first appearing in the Summit and Sierra systems.
The jury is still out. Larrabee is in the wild but it's a hell of a long way from 'not failed' -- every single deployment I'm aware of suffers from massive failure rates of the hardware and every single developer I've worked with much prefers to work with Tesla gear.
It's all well and good for them to aim for 'prestige buys' like Tianhe 2, but when the marketing smoke clears, the product is not achieving the things we in HPC buy products to achieve. Utilization rates are in the toilet across the ten or so Phi contracts I touch. I'm sure KNL's integrated architecture will change this, since everyone will just get this by default from vendors, but I don't know a single site who decided to buy Phi twice.
As far as I can tell, Phi is a play at a numbers game: you can ram up the Rmax of your system under LINPACK, regardless of whether it creates any actual value for your users. In other words, it's a cheap way to claw some false cred out of your top500 position, and not so much a useful HPC tool yet.
I am setting a unit up now for a customer. In the years I've been working on them, the toolchain you need has not gotten much better ... no ... it went from complete crap to meh.
You really can't not use the intel compilers for them. Gcc won't optimize well for it at all. This means that in addition to the higher entry price for the hardware, you have a sometimes painfully incompatible compiler toolchain to buy as well, and then code for. Which means you have to adapt your code to the vagaries of this compiler relative to gcc. These adaptations are sometimes non-trivial.
I am not saying gcc is the be-all/end-all, but it is a useful starting point. One that the competitive technology works very well with.
From the system administration side, honestly, the way they've built it is a royal pain. Trying to turn this into something workable for my customer has taken many hours. This customer saw many cores as the shiny they wanted. And now my job is (after trying to convince them that there were other easier ways of accomplishing their real goals) to make this work in an acceptable manner.
The tool chain is different than the substrate system. You can't simply copy binaries over (and I know they have not yet internalized this). The debugging and running processes are different. The access to storage is different. The connection to networks is different.
What I am getting to is that there too many deltas over what a user would normally want.
It is not a bad technology. It is just not a product.
That is, it isn't finished. It's not unlike an Ikea furniture SKU. Lots of assembly required. And you may be surprised by the effort to get something meaningful out of it.
As someone else mentioned elsewhere in the responses, the price (and all the other hidden costs) are quite high relative to the competition ... and their toolchain stack is far simpler/more complete.
The hardware isn't a failure. The software toolchain is IMO.
" Make the most powerful flops-per-watt machine. SUCCESS!"
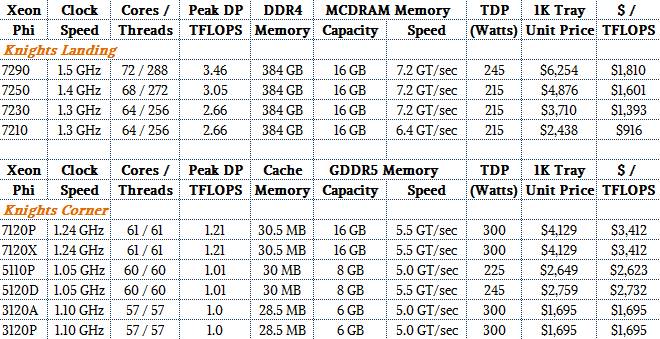
Hum not at all... Larrabee gets destroyed by the competition in terms of flops-per-watt. Knights Corner is rated 8 GFLOPS/W at the device level (2440 GFLOPS at 300 W). For comparison Nvidia Tesla P100 rates 4× better: 32 GFLOPS/W (9519 GFLOPS at 300 W) and AMD Pro Duo rates ~6× better: 47 GFLOPS/W (16384 GFLOPS at 350 W although in the real-world it probably often hits thermal limits and throttles itself, so real-world perf is probably closer to 30-40 GFLOPS/W).
Also, if Intel wants to make Larrabee gain mindshare and marketshare, they need to sell sub-$400 Larrabee PCIe cards. Right now, everybody and their mother can buy a totally decent $200 AMD or Nvidia GPU and try their hands at GPGPU development. And if they need more performance, they can upgrade to a multiple high-end cards, and their code almost runs as is. But because Larrabee's cheapest model (3120A/P) starts at $1695 (http://www.intc.com/priceList.cfm), it completely prices it out of many potential customers (think students learning GPGPU, etc).
Larrabee gets destroyed by the competition in terms of flops-per-watt
While I expect the graphics cards to have the edge in performance per watt for brute-force math, I'm surprised that the current GPU's would have that large of an advantage. Are you sure you are comparing the same size "flops" for each?
And while it's in keeping with the article, I don't think lumping all the generations together as "Larrabee" makes sense when comparing system performance. While availability is still minimal, Knights Landing is definitely the current generation (developer machines are shipping), and as you'd expect from a long-awaited update at a smaller process size, efficiency is a lot better than older generations.
2016 Tesla P100: 5.30 DP TFLOP using 300W == 18 DP GFLOPS/W.
I don't know if these numbers are particularly accurate (I think actual KNL numbers for the developer machines are still under NDA), but I think the real world performance gap will be something more like this than one approach "destroying" the other. If you are making full use of every cycle, the GPU's will win by a bit. If your problem requires significant branching, Phi won't be hurt quite as badly.
Also, if Intel wants to make Larrabee gain mindshare and marketshare, they need to sell sub-$400 Larrabee PCIe cards.
The interesting move Intel is making is to concentrate initially on KNL as heart of the machine rather than as an add-in card. This gets you direct access to 384GB of DDR4 RAM, which opens up some problems that current graphics cards are not well suited for. I think this plays better to their strengths: if your problem is embarrassingly parallel with moderate memory requirements, modern graphics cards are a better fit. But if you need more RAM, or your parallelism requires medium-strength independent cores, Phi might be a better choice.
But because Larrabee's cheapest model (3120A/P) starts at $1695
While it's true that Intel's list pricing shows they aren't targeting home use at this point, List Price may not be the best comparison. For a while last year, 31S1P's were available at blow out prices that beat all the graphic cards. In packs of 10, they were available at $125 each: http://www.colfax-intl.com/nd/xeonphi/31s1p-promo.aspx.
Would love to kick tires of one of those Knight's Landing cards.
It might be possible to pull off similar tricks as on normal Intel Xeons. I wonder what kind of memory controller it got. Does it for example have hardware swizzling and texture samplers accessible?
But we use exclusively Nvidia for our number crunching product. And since the relevant code is implemented in CUDA, we have an Nvidia platform lock-in. Other options are not even on the table, and will not be.
Intel would be very smart to offer a migration path from CUDA code.
You are right I shouldn't lump all generations together as "Larrabee". I didn't realize the definitive specs of Knights Landing came out (2 months ago?). KL does improve a lot over KC, and now almost matches current GPUs:
KC: 8 GFLOPS/W at the device level (Xeon Phi 7120: 2440 GFLOPS at 300 W).
KL: 28 GFLOPS/W at the device level (Xeon Phi 7290: 6912 GFLOPS at 245 W).
Compare this to 32-47 GFLOPS/W at the device level for current-generation AMD and Nvidia GPUs.
This article is a reminder to me that people are bloody critical of things that they don't really understand. Many products are killed, many research ideas never take off even if they're proven to work well. Ideas/products are often killed, not because they weren't great, but for a litany of other reasons having nothing to do with the awesomeness or usefulness of the idea. Products are killed b/c of politics, lack of a massive market, and most importantly poor execution. Even when things fail (research, products, otherwise), they often have a huge impact on the ecosystem. The product might fail (in this case, it really didn't), but the ideas will live on.
This is fun to read, I'm always amazed as the disconnect between public presentations and the engineering reality of what's really going on.
For me, "Larrabee" died during it's first public demo in IDF 2009 [1]. At the time I was working on CUDA libraries at NVIDIA. I remember everyone watching the stream to see how much of a threat it would be. When we saw the actual graphics, everyone started laughing. "Welcome to the 1990s!" At that point it was obvious that Larrabee would not be a graphics threat to NVIDIA, it just had too far to go. It was not a discrete GPU killer.
A graphics card where the graphics core is actually an x86 application running on FreeBSD running on the "GPU"? That you could even log in to? That sounds out-of-this-world-amazing. What a shame it wasn't released like that.
Actually Xeon Phi is almost the same thing except it's not sold as GPU. You can ssh into it or run software rasterizer on it's cores and only thing missing would be host graphics driver.
What I hear from my friend who works in the GPU industry, one of the main outcomes from the Larrabee research project was: It is possible to do most of graphical operations on a SIMDed general purpose CPU, with good performance. Everything except texture decoding, which really needs dedicated texture decoding silicon. And with texture units taking up 10% of the silicon, Intel really needs to decide if they want to sell it as a GPU or as a general purpose compute unit with 10% more cores. Intel chose the latter, and you can't really blame them, as you can sell dedicated compute units for more money.
Sony ran into the same problem with the PS3 and the cell. They originally designed it so the game developers could implement whatever rendering method they wanted, in software, on the SPUs. But the performance wasn't high enough, partly due to texture decoding taking up too much time. By the time it was discovered this was a problem, the cell was more or less finalises. Sony were considering adding a second cell to the console, to brute force through the problem, but eventually they asked Nvidia to hack together a traditional GPU.
> Intel really needs to decide if they want to sell it as a GPU or as a general purpose compute unit with 10% more cores. Intel chose the latter, and you can't really blame them, as you can sell dedicated compute units for more money.
From the article:
> Remember - KNC is literally the same chip as LRB2. It has texture samplers and a video out port sitting on the die. They don't test them or turn them on or expose them to software, but they're still there - it's still a graphics-capable part.
So the core space is still used right? They didn't choose 10% more cores, they just chose to turn it off an not test it, but it still uses the die space.
On knights corner, yes. The silicon design was finished by the time this decision was made.
It was a long term advantage, they removed the texture samplers for the next version, knights landing, which allowed them to fit more cores on that chip.
For the typical case of 2D uncompressed textures with some kind of trilinear/anisotropic filtering enabled, you are basically just calculating 8 addresses based on texture coordinates and clamping and mipmap levels, doing a gathered load (and CPUs hate doing gathered loads). Remember to optimise for the case that each group of 4 addresses are typically, but not always right next to each other in memory.
Then you use trilinear interpolation to filter your 8 raw texels into a single filtered texel. With the exception of the gathered load, none of these operations is actually that expensive on CPUs, but shaders do a lot of these texture reads and it's really cheap to and faster to implement it all in dedicated hardware.
You can also put these texture decoders closer to the memory, so the full 8 texels don't need to travel all the way to the shader core, just the final filtered texel. And since each texture decoder serves many threads of execution, you have chances to share resources between similar/identical texture sample operations.
And while the texture sampler is doing it's thing, the shader core is free to do other operations (typical another thread of execution). It's not that the CPU can't decode textures, its just that CPU cores without dedicated texture decoding hardware can't compete with the hardware which has the dedicated texture decoding hardware.
Also borders/mirroring, anisotropic filtering, decoding compressed formats like DXT# and BC#. To complicate things, there're also 1D and 3D textures, cubemaps, and texture arrays.
And most games on PS3 end up using SPU very little or completely leaving it for middleware used since it's was too complicated to work with for average programmer. Though there was really nice DICE presentation on their deferred shading using PS3 SPUs: http://www.dice.se/wp-content/uploads/2014/12/Christina_Coff...
The SPUs were basically the next evolution if the ps2's two vector units, which were often running middleware too. It was really hard to write code that ran fast (Sony were advocate of writing assembly in an excel spreadsheet), but generally the vector units were doing about the same thing for every game/developer (bruteforce stuff: transforming vertices, calculating vertex lighting, generating multi-pass command streams for the rasterizer). So most developers were just using Sony provides examples, or improved versions from middleware developers. Very few developers wrote their own VU programs, or even needed to.
The cell now has 7 vector units, with comparatively more memory, but there was no default job for them, all the vertex transformation now ran on the GPU's vertex shaders. And Sony initially stuck to their guns of "SPU programs should be written in assembly, in a spreadsheet"
Because the single PPU really sucked and was nowhere near fast enough for anything, Sony eventually relented and releases a version of GCC which would compile c++ code to the SPUs. Fast to develop, but nowhere near the performance of an excel spreadsheet designed SPU program.
This resulted in a whole bunch of games running code on the SPUs that was really badly optimised. But at least it reduced load on the PPU.
I'm not actually sure how they had their spreadsheets set up, probably had a bunch of conditional formatting setup to highlight pipeline hazards, along with formulas to show total and wasted cycles counts.
Both Architectures had exposed pipelines, meaning the result of an operation would take a few cycles to show up in the destination register and some operations would take longer than others. You might have to insert a bunch of NOPs to make sure the data would be ready for the next instruction that needed it. Both Architectures were also dual issue, meaning two completely independent operations, operating on completely independent registers would be manually packed into a single instruction by the programmer. There also would be restrictions on which types of instructions could go in each half of the instruction, if you didn't have an instruction, you have to put a NOP there.
I'm pretty sure Sony liked the spreadsheets because it forced the programmer to see where all the NOPs were. The programmer would be expected to refactor things and manually unroll loops until all the NOPs were filled with useful instructions and peak performance was reached.
Why the downvotes? It's true. If you stray from AAA titles, you get plenty of PS3-only games that had terrible lags and struggled to even manage 30fps on reduced resolution. GUST titles like the Atelier series come to mind.
On the PS3 they got around the problem by working together with the likes of Gran Turismo and other top AAA studios, to create a GPU profiler and also introduced their Phyre Engine.
I remember by the time Gran Turismo was launched, there was an event showing the new tooling to developers.
VirtualGL is here and working so I don't think it's hard to do. Sadly hardware pricing and lack of interest leave very little chance that anyone would ever implement it.
Well, the problem is that Intel started with something way worse than OpenCL when they brought their first Phi to market: OpenMP. The claim was to just wrap your loops in OpenMP directives and everything will be fine. Yea well...
If they had went full on OpenCL, including a unified programming for vector and multicore parallelism (the way CUDA works), I think Phi might have taken off much more already.
I'm not sold on the " 1. Make the most powerful flops-per-watt machine." success.
From my knowledge that claim only makes sense for the ever-shrinking domain of applications that haven't been ported to GPGPUs with _simpler_ cores. I also don't understand how the best "flops-per-watt" can be extrapolated from the fact that the Phi is used in top ranked TOP500 machines.
The Phi really just seems like an intermediate between CPUs and GPGPUs in the ease-of-programming vs. perf/watt pareto curve.
Correct, GPUs dominate the flops-per-watt charts. IBM's Blue Gene systems were also pretty good in this regard but that product line is now a dead end.
Back in the days of the Itanium debacle, Intel made the mistake of assuming everybody would be willing to rewrite their code to work efficiently on whatever hardware Intel wanted to give them. Instead, AMD won (briefly) by making a 64-bit chip that was much more x86-compatible.
Now, though, it sounds as if Intel may be making the opposite mistake. The Larrabee/KnightsThingummy family was built around x86 cores to make it easier to port existing code to it, but now it looks like this time people really are willing to rewrite their code to work on GPGPUs after all.
Yet, from the point of view of someone seating on the GDC Europe rooms hearing how Larrabee was going to change the world of game development, back in 2009, I think we can state it did fail.
Read again, the claims were very specific in regards to a discrete GPU. Also, the author worked at Intel on Larrabee so unless you have proof otherwise I think it's best to give them the benefit of the doubt as to accuracy of the claim.
At GDCE it was being sold as a way of doing graphics, AI and vector optimizations of code in more developer friendly than GPGPU.
Of course, framing the graphics feature is a nice way of sidelining the issue that it also didn't delivered those other features to the games development community.
> At GDCE it was being sold as a way of doing graphics, AI and vector optimizations of code in more developer friendly than GPGPU.
> Of course, framing the graphics feature is a nice way of sidelining the issue that it also didn't delivered those other features to the games development community.
There is clear evidence that the high-end cards that NVidia delivered at these time could outcompete (or keep pace) with Larrabee at that time. Thus when released Larrabee would not have been a strong contender to NVidia or AMD at that time. In this sense I stand by my position that Larrabee failed as GPU.
On the other hand I see no evidence that the rival products by AMD and NVidia could keep pace with Larrabee for AI and vector optimizations. Thus Larrabee was not a failure here. So Intel probably just concluded that in HPC there is much more money to be earned than for consumer devices and thus Larrabee was not released to consumers. And I can see good reasons: If game developers want to exploit the capabilities Larrabee has to offer, they have to depend on consumers having a Larrabee card in their computer. If Larrabee were an outstanding GPU the probability that some enthusiasts will get it was much higher than if Larrabee is just an add-on that some exotic applications/games additionally require.
> This page requires JavaScript to function properly.
Hint: For a page with nothing but text content you're doing it wrong. Even more so since this is a static site and you have to go to extra effort to break normal degradation of HTML content.
Once again someone down votes you because they disagree.
Personally I also browse with javascript disabled and thought the mandatory JS was silly. Hence I did view source, and lo and behold it is a tiddly wiki, with 2MB of html containing every article.
While github now has pages.github.com and the ability git pull/push your wiki (git clone git@github.com:username/project.wiki.git), I'm not sure how well that works for using on another web server or locally.
Isn't this a case where Intel should not of talked about their internal R&D until they had a clear product & message to bring the market? I wonder if this lack of discipline cost Larrabee the correct narrative that it should have.
If I remember correctly, the idea at the time was to catch up to Nvidia/ATI (leapfrog them, really) in the discrete GPU market. Thus by announcing the technology long before it was ready, this would put a damper on their competitor's sales and lead. Kind of like an externalized Osborne effect.
This might have something to do with their patent dispute with Nvidia that cost them $1.6 billion back in 2011. Probably Intel still want (able to) compete with Nvidia on compute, but not graphics market.
O.K. fucking major rant below. Disclaimer I worked for an vendor selling large
quantities pretty much anything in the HPC space at the time KNC came to market
and I now work for a different (larger) HPC vendor.
When I say "Larrabee" I mean all of Knights, all of MIC, all of Xeon Phi, all of
the "Isle" cards - they're all exactly the same chip and the same people and the
same software effort. Marketing seemed to dream up a new codeword every week,
but there was only ever three chips:
Knights Ferry / Aubrey Isle / LRB1 - mostly a prototype, had some performance gotchas, but did work, and shipped to partners.
Knights Corner / Xeon Phi / LRB2 - the thing we actually shipped in bulk.
Knights Landing - the new version that is shipping any day now (mid 2016).
I can kind of see what the author is getting at here but it's worth reminding
general readers KNL is a wildly different beast from KNF or KNC.
1. It's self hosting, it runs the OS itself/ there is no "host CPU".
- Yes KNC ran it's own OS but it was in the form of a PCI-E card which still had
to be put into a server of some kind.
- Yes KNL is slated to have PCI=E card style variants but the self hosting
variants are what will be appearing first and I honestly don't think the PCI-E
variants will gain much if any market traction.
2. It features MCDRAM which provides a massive increase in total memory
bandwidth within the chip. Arguably this is necessary with such large core
counts.
3. Some KNL variants will have Intel's Omni-Path interconnect directly
integrated which should further drive down latency in HPC clusters.
Behind all that marketing, the design of Larrabee was of a CPU with a very wide
SIMD unit, designed above all to be a real grown-up CPU - coherent caches,
well-ordered memory rules, good memory protection, true multitasking, real
threads, runs Linux/FreeBSD, etc.
Here's an interesting snippet, drop "Larrabee" from the above and replace it
with "Xeon". I'm just wanting the point here that the Xeon and Xeon Phi product
lines are only going to look more similar over time. For a while now the regular
Xeons have been getting wider. Which is to say more cores and fatter vector
units. The Xeon Phi line started out with more cores but is having to drive the
performance of those cores up. Over time we're going to see one line get
features before the other e.g. AVX512 is in KNL and will be in a "future Xeon"
(Skylake). And it's widely rumored that "future Xeons" will support some form of
non-volatile main memory, something not on any Xeon Phi product roadmap today.
The main differentiator will be that Xeon products need to continue to cater to
the mass market whereas Xeon Phi can do more radical things to drive compute
intensive workloads (HPC).
Larrabee, in the form of KNC, went on to become the fastest supercomputer in the
world for a couple of years, and it's still making a ton of money for Intel in
the HPC market that it was designed for, fighting very nicely against the GPUs
and other custom architectures.
Yes at the time Tianhe 2 made it's debut it was largely powered by KNC and it
placed at number 1 on the top 500.
Did KNC as a product make a lot of money for Intel? Probably not. Yes they
shipped a lot of parts for Tianhe 2 but for other HPC customers, not so much. At
the time putting a KNC card against a Sandy Bridge CPU it wasn't leaps and
bounds faster. Yes you're always going to have to re-factor when making such
a change in architecture but the gains just weren't worth it in most cases. Not
to say there haven't been useful deployments of KNC that have contributed to
"real science", but it was not a wild success by any measure.
As for "fighting very nicely against the GPUs and other custom architectures",
I don't think so. When KNC got to the market Nvidia GPUs already had a pretty
well established base in the HPC communities. Many scientific domains already
had GPU optimized libraries users could pick off the self and use. Whilst KNC
was cheaper than the Kepler GPUs on the market at the time it wasn't much
cheaper. Again back to regular Xeons, for a cost/ performance benefit KNC wasn't
worth it for a lot of people.
Its successor, KNL, is just being released right now (mid 2016) and should do
very nicely in that space too.
I do agree with this, KNL is going to do very well. There are whole systems
being built with KNL rather than large clusters with some KNC or some GPUs.
1. Make the most powerful flops-per-watt machine.
Not sure what is mean here, most efficient machine in the top 10? Tianhe 2 is
not an efficient machine by any stretch of the imagination. For reference here's
the top 10 of the Green 500 for when Tianhe 2 placed as number 1 on the Top
500.
SUCCESS! Fastest supercomputer in the world, and powers a whole bunch of the
others in the top 10. Big win, covered a very vulnerable market for Intel, made
a lot of money and good press.
Yes KNC provides the bulk of the computing power for Tianhe 2 but at the time of
writing of the above is number 2, not number 1. Secondly that is the ONLY
machine in the top 10 that uses KNC AT ALL.
Just yesterday ASRock announced a Xeon Phi x200 (Knights Landing) system. This is now using a main CPU socket instead of a PCIe extension card and it seems to support only a single LGA-3647 socket (that's a LOT of tiny legs). So ASRock took four of these, each taking half a U (Supermicro had similar formats with their Twins) and packed four into 2U.
Thinking of the Phi as a special-purpose part misses an important point: CPUs will not get much faster. Vector units will get wider and core count will increase. Programming for Xeon Phi gives you a view of what a CPU will be a couple years from now. Right now my laptop has 4 cores running 8 threads and the only reason it has exquisitely fast cores that dedicate large areas to extract performance from every thread (rather than investing all those transistors on something else) is because our software is built for ridiculously fast versions of computers from the 90s.
I think Larrabee was interesting because it had the potential to go the other way - it could emulate existing rasterization APIs decently but would allow for new realtime rendering approaches - like raytracing in to some sparse voxel tree structure for non-animated geometry - maybe do hybrid rendering where you would do deferred shading/rasterization for dynamic scene and then ray trace in to the tree for global illumination with static scene and similar stuff.
I'm sure emulating OpenGL on the CPU has it's uses outside of being a reference for drivers and such - but it's not really that exciting, GPUs are already excellent at doing that kind of rendering.
Actually it's was not only possible to use it for ray tracing, but Intel had it working back in 2008. They also sponsored Uber Entertainment implement it into their game and that was ready before Intel cancelled it: http://www.polygon.com/features/2013/3/19/4094472/uber-hail-...
I also wish that had taken off; 3d-graphics via a software ray tracing engine would in a sense be a return to the way things worked in the 90's before hardware rendering, where every game had its own custom engine and developers were always trying crazy new things. In some sense, GPU hardware has gotten flexible enough that we're sort of back in that world again, but writing GPU code isn't quite the same as writing a renderer from scratch.
When it comes to ray-tracing in particular, as far as I know there really doesn't exist (except perhaps as research prototypes) any hardware platform that's great at ray tracing. CPUs are okay but they need more parallelism. GPUs are okay but (as far as I understand it) they aren't good with lots of branches and erratic memory accesses. It seems like KNC/KNL ought to be ideal for this kind of thing (and in fact, it appears a fair bit of effort has gone into optimizing Embree for Xeon Phi).
I joined up in 2009 (really too late), and somehow ended up with the "non polygon" rasterization path (Mike Abrash split rasterization: he had the polygon path). After the second time LRB was canceled, my team was shuttled off elsewhere.
I had a number of long conversations with D about soft texturing; I didn't understand Tom Forsyth's arguments about why soft texturing wouldn't work. (My back-of-the-envelope numbers were encouraging.) So, in winter of 2011 (12?) I decided to write my own soft texturing unit. What I found was that soft texturing is completely do-able---just not in any sort of reasonable power budget.
At the same time a friend, S, decided he wanted to implement a rasterizer (I'd gotten my fill). Between the two of us, we had a rockin' still-frame bilinearly sampled Stanford bunny. A third friend, W, decided to implement a threading model. Threading models for very-high count processors are enormously difficult. I ended up writing much of an OpenGL driver, a shader compiler (through LLVM), and part of a pipeline JIT, i.e., a vertex loader, fixed-function-to-programmable compiler, etc. That project was called SWR; the sanitized projection is OpenSWR.
(Looking at the current sources, I'd say that I probably no longer have any code in there.)
A simple answer would be to raise market share in the gpu market.
Also a lot of non-gaming software uses the gpu for various tasks, even office and photoshop nowadays. But they do not need a full-fledged gpu.
{kind=link}
{kind=link}
Oh god the horror that was OpenCL on Xeon Phi.
1) It was extremely buggy. Any OpenCL program of decent complexity was bound to encounter bugs in their driver.
2) FLOPS are not the only measure for computations / simulations. The bandwidth is is extremely important for many applications. Whatever Xeon Phis OpenCL was doing was not achieving anything close to its peak. Any OpenCL kernels we had tuned would end up improving the performance of the host CPU (16 x 2 Xeon) as well. It would usually result in the Xeon CPU performing better than the Xeon Phis.
3) NVIDIA released multiple generations of their GPUs since Xeon Phi was released. The performance per watt on NVIDIA and AMD GPUs has been improving substantially over the last 3 years while Xeon Phi's stagnated in 2012.
4) Even their claim for best FLOPS / WATT is wrong. The Tesla K20 released around the same time had the same power usage (225W) but about 50% higher FLOPS (2TFLOPS vs 3TFLOPS single precision).
The only selling point was that they were x86 cores and hence did not require rewriting your code. But you had to write additional directives indicating what part of your code you wanted to offload to your accelerator and when you wanted to get it back. The best performance ironically came after a lot of tuning for your application.
4 years down the line, GPU based accelerators still dominate the market and growing. and I wonder how many of the researchers who went with Xeon Phis regret their decision.